Manuel de référence
 Anakeen Labs <labs@anakeen.com>
Anakeen Labs <labs@anakeen.com>
Table des matières
- Chapitre 1 Présentation
- 1.1 Dynacase Platform
- 1.2 Manuel de référence de Dynacase Core
- 1.3 État de la documentation
- 1.4 Historique de la documentation
- Chapitre 2 Introduction à Dynacase
- 2.1 Famille et document et attributs
- 2.2 Cycle de vie
- 2.3 Applications, actions et ACL
- 2.4 Comptes : utilisateurs, groupes et rôles
- 2.5 Sécurité : authentification, droit applicatif, droit documentaire
- 2.6 Internationalisation
- Chapitre 3 Le modèle objet de Dynacase
- 3.1 Les classes standard de Dynacase Core
- 3.2 Les Hooks
- 3.3 Lignée documentaire et révisions
- Chapitre 4 Familles et documents
- 4.1 Présentation
- 4.2 Les attributs
- 4.3 Visibilité des attributs
- 4.4 Les paramètres de famille
- 4.5 Les attributs calculés
- 4.6 Les contraintes
- 4.7 Les aides à la saisie
- 4.8 Déclaration de familles
- Chapitre 5 Document système
- 5.1 Les recherches
- 5.2 Les dossiers
- 5.3 Masque
- 5.4 Contrôle de vue
- 5.5 Modèle de mail
- 5.6 Minuteur
- Chapitre 6 Vues et représentations
- 6.1 Utilisation des templates
- 6.2 Principe d'une vue de document
- 6.3 Vue spécifique de document
- 6.4 Vue d'attribut
- 6.5 Vue de rangée de tableau
- 6.6 Vue OpenDocument Text
- Chapitre 7 Importation et exportation de documents
- 7.1 Importation de documents par CSV
- 7.2 Importation de documents par XML
- 7.3 Importation d'archive
- 7.4 Importer des documents par ligne de commande
- 7.5 Exportation de documents
- 7.6 Exportation de documents en Xml
- 7.7 Exportation des profils
- Chapitre 8 Utilisateurs, groupes et rôles
- 8.1 Présentation des comptes
- 8.2 Description des utilisateurs
- 8.3 Description des groupes d'utilisateurs
- 8.4 Description des rôles
- 8.5 Importation des comptes en XML
- 8.6 Exportation XML des comptes
- 8.7 Importations de comptes (document)
- Chapitre 9 Sécurité - droits et profils
- 9.1 Niveaux de sécurité
- 9.2 Paramètres de profilage
- 9.3 Paramétrage des droits applicatifs
- 9.4 Droits définis sur les applications fournies par Dynacase Core
- 9.5 Paramétrage des droits documentaires
- 9.6 Paramétrage des droits pour un contrôle de vue
- 9.7 Paramétrage des droits pour un cycle de vie
- Chapitre 10 Cycles de vie
- 10.1 Vocabulaire
- 10.2 Définition du cycle de vie
- 10.3 Paramétrage des cycles de vie
- 10.4 Manipulation par le code des documents liés à un workflow
- Chapitre 11 Dynacase en ligne de commande
-
11.1
wsh.php -
11.2 Gestion des erreurs
wsh - 11.3 Exécuter des scripts avec wsh
- 11.4 Exécuter des actions avec wsh
- 11.5 Retour d'erreur
- 11.6 Écrire un script CLI
- Chapitre 12 Applications et actions
- 12.1 Écrire une application
- 12.2 Écrire une action
- 12.3 Les paramètres applicatifs
- 12.4 Les droits applicatifs
- 12.5 Application héritée
- Chapitre 13 Les essentiels de l'API
- 13.1 Classe Action
- 13.2 Classe ActionUsage
- 13.3 Classe ApiUsage
- 13.4 Classe Application
- 13.5 Classe Dir
- 13.6 Classe Doc
- 13.7 Classe Docfam
- 13.8 Classe DocumentList
- 13.9 Classe Layout
- 13.10 Classe Log
- 13.11 Classe ApplicationParameterManager
- 13.12 Classe SearchAccount
- 13.13 Classe SearchDoc
- 13.14 Utilitaires de gestion de documents
- Chapitre 14 Actions et zones de référence
-
14.1
[ZONE FDL:HTMLHEAD] -
14.2
[ZONE FDL:HTMLFOOT] -
14.3
[ZONE FDL:INPUTATTRIBUTE] -
14.4
[ZONE FDL:VIEWFRAME] -
14.5
[ZONE FDL:EDITFRAME] -
14.6
[ZONE FDL:VIEWARRAY] -
14.7
[ZONE FDL:EDITARRAY] - 14.8 Zones spécifiques d'administration
-
14.9
[ACTION FDL:OPENDOC] -
14.10
[ACTION FDL:IMPCARD] -
14.11
[ACTION FDL:EXPORTFILE] -
14.12
[ACTION FDL:FDL_METHOD] - 14.13 Paramétrage du pied de documents
- Chapitre 15 Paramètres applicatifs de référence
- 15.1 Paramètres d'accès
- 15.2 Système
- 15.3 SMTP
- 15.4 TE
- 15.5 Interface client
- Chapitre 16 Scripts CLI de référence
- 16.1 refreshGroups
- 16.2 manageApplications
- 16.3 cleanFamily
- 16.4 cleanFamilyParameter
- 16.5 manageContextCrontab
- 16.6 initializeDocrelTable
- 16.7 cleanContext
- 16.8 generateDocumentClass
- 16.9 destroyFamily
- 16.10 fixMultipleAliveRevision
- 16.11 getApplicationParameter
- 16.12 importDocuments
- 16.13 refreshDocuments
- 16.14 setApplicationParameter
- 16.15 setStyle
- 16.16 checkVault
- 16.17 refreshVaultIndex
- 16.18 cleanVaultOrphans
- 16.19 wstop
- 16.20 wstart
- Chapitre 17 Techniques avancées avec Dynacase
- 17.1 Gestion des styles
- 17.2 Internationalisation
- 17.3 Cinématique de dynacase
- 17.4 La base de données
- 17.5 Mécanismes de persistance
- 17.6 Manipulation des comptes utilisateur
- 17.7 Migration de modules
- 17.8 Mécanismes de recherche
- 17.9 Authentification
- 17.10 Contrôles d'accès
- 17.11 Usage avancé des templates
- 17.12 Les autres familles systèmes
- 17.13 Autoloader
- 17.14 MIME
- 17.15 Installation et ou mise à jour d'applications et de familles
- 17.16 Utilisation des documents partagés du noyau
- 17.17 Mise à jour d'attribut sur des collections de documents
Chapitre 1 Présentation
1.1 Dynacase Platform
Dynacase est une plate-forme de développement d'applications métier dont l'objectif principal est de fournir un cadre facilitant et accélérant les développements.
Elle s'articule autour des composants suivants :
- un concept de document permettant à la fois la persistance des données et la génération de formulaire;
- des workflows permettant de faire évoluer les documents, d'automatiser l'application de règles métiers;
- un système de gestion de sécurité et des utilisateurs permettant d'indiquer finement les permissions;
- un système de modules permettant d'étendre les fonctionnalités de base.
Ces composants sont proposés et mis en oeuvre par le module principal Dynacase Core.
1.2 Manuel de référence de Dynacase Core
Ce manuel est destiné à des développeurs devant créer une application en utilisant Dynacase comme socle applicatif. Il a pour but de présenter une documentation précise et exhaustive de l'ensemble des fonctionnalités de la plate-forme maintenue par Anakeen.
Il propose au travers de sa structure une approche logique des concepts et techniques de développement.
Les premiers chapitres présentent les objets et mécanismes Dynacase. Leur compréhension est importante car ils introduisent des concepts qui sont utilisés dans la suite du manuel. Les suivants détaillent des fonctionnements de Dynacase Core, pour arriver au détail de l'API de programmation et aux techniques avancées.
Bon développement...
1.3 État de la documentation
Nous marquons les chapitres pour informer le lecteur sur les modifications fonctionnelles.
| Balise | Signification |
|---|---|
| nouveauté | Ce marquage indique qu'une nouvelle fonction est disponible dans la version. |
| mis à jour | Ce marquage indique qu'une fonction a évoluée dans la version. |
| 3.2.x | Ce marquage met en évidence des fonctions nouvelles ou des mises à jour qui sont opérationnelles que depuis la release indiquée de dynacase-core. |
Note : Si un chapitre est 'marqué', son contenu, incluant ses sous-chapitres, est considéré comme marqué à l'identique -sauf marquage particulier-.
1.4 Historique de la documentation
Ce chapitre contient un descriptif des améliorations entre les releases de Dynacase.
1.4.1 Édition 13
| Modifications | Chapitre | Version |
|---|---|---|
Clarification directive RESET;properties
|
Instructions de réinitialisation | Mis à jour |
1.4.2 Édition 12
| Modifications | Chapitre | Version |
|---|---|---|
Contrôle des types MIME servis inline
|
Contrôle des types MIME servis inline |
Nouveau |
1.4.3 Édition 11
| Modifications | Chapitre | Version |
|---|---|---|
| Possibilité de mettre le jeton dans les headers | Authentification par jeton | Mis à jour |
| Possibilité d'utilisé le header d'authentification Basic | Authentification Basic | Nouveau |
| Ordre relatif des attributs | Ordre relatif | Nouveau |
| Modification du calcul des ordres absolus | Ordre absolu | Mis à jour |
Ajout du paramètre CORE_NOTIFY_SENDMAIL
|
CORE_NOTIFY_SENDMAIL |
Nouveau |
| Ajout de vérifications lors de l'import des masques | Masque | Mis à jour |
| Ajout des mails d'erreur sur wsh |
CORE_WSH_MAILTO, CORE_WSH_MAIL_SUBJECT
|
Nouveau |
| Ajout de la gestion d'erreur pour les processus et les minuteurs | Processus, minuteurs | Mis à jour |
| gestion des caractères de contrôle dans les templates odt | Gestion des caractères de contrôle | Mis à jour |
| Possibilité d'importer des tags applicatifs sur les documents | Importation tag applicatif | Nouveau |
1.4.4 Édition 10
| Modifications | Chapitre | Version |
|---|---|---|
| Explications de l'objet de partage de document | Objet de partage de document | Nouveau |
| Précision sur les exportations vis-à-vis des révisions | Révision et exportation, Révision XML | Mis à jour |
| Ajout information sur la révision pour formatCollection | Formatage des relations | Mis à jour |
| Paramétrage du pied de document | Document footer | Nouveau |
| Ajout de parties variables dans le paramètre MAIL_ACTION | Paramètre MAIL_ACTION | Mis à jour |
| Facilité d'importation et d'exportation de comptes | Importation XML de comptes, Exportation XML de comptes | Nouveau |
| Ajout de la propriété "exists" pour les énumérés | Formatage des énumérés | Mis à jour |
Explication classe UpdateAttribute
|
Mise à jour par lot | Nouveau |
| Modification sur l'identifiant de fichier | Table vaultdiskstorage | Mis à jour |
| Enregistrement des valeurs affichées | Hook customSearchValues | Nouveau |
| Nouvelle option d'importation de droits | Pose de droits sur les documents, Exportation des profils | Mis à jour |
| Précision sur l'include path | include_path | Mis à jour |
| Précision sur ActionUsage | Classe ActionUsage | Mis à jour |
| Précisions sur les paramètres de familles | Les paramètres de famille | Mis à jour |
| Échappement des paramètres dans les templates | Layout::eset | Mis à jour |
| Modification du script de suppression des fichiers orphelins | script checkvault et cleanVaultOrphans | Mis à jour |
1.4.5 Édition 9
| Modifications | Chapitre | Version |
|---|---|---|
| Nouveau hook Doc::preAffect / postAffect | Hook d'affectation | Nouveau |
| Nouvelle option d'attribut htmltext et vérification de la validité | allowedcontent | Nouveau |
| Ajout description des méthodes addWarningMsg et addLogMsg | Action::addwarningmsg(), Action::addLogmsg() | Mis à jour |
| Précision sur la détection paramètre des CSV lors de l'importation | Précaution sur l'importation de document | Mis à jour |
| Orientation des images jpeg | Vue des attributs images | Mis à jour |
Script wstop et wstart
|
wstop, wstart
|
Mis à jour |
Ajout option --cmd=unregister-all à manageContextCrontab
|
manageContextCrontab | Mis à jour |
1.4.6 Édition 8
| Modifications | Chapitre | Version |
|---|---|---|
| Règle globale pour les styles | Règles de style | Nouveau |
| Ajout explication pour les paramètres CORE_TMPDIR, CORE_TMPDIRMAXAGE, CORE_LOGDURATION, CORE_SESSIONMAXAGE, CORE_SESSIONGCPROBABILITY, FREEDOM_UPLOADDIR | Paramètre système | Nouveau |
| Description de la table doclog | table doclog | Nouveau |
| Fichier openDocument Writer : Précisions sur les images insérées dans les attributs "htmltext" | Image et htmltext | Mis à jour |
| Précision sur les critères relations dans les recherches détaillées | Recherche détaillée | Mis à jour |
| Possibilité de déclarer des attributs obligatoires dans les tableaux | Attribut obligatoire | Nouveau |
| Nouvelle option pour les nombres dans l'exportation CSV pour les rapports | Rapport | Nouveau |
| Prise en compte de la préaffectation lors de la création de document pour les vues spécifiques | Action OPENDOC | Nouveau |
| Ajout lien vers les codes d'erreur de l'API PHP pour l'importation de documents | Importer des documents par ligne de commande | Mis à jour |
Si une ligne ORDER est erronée, l'import de documents de cette famille est ignoré |
Ordre des attributs | Mis à jour |
| Précisions sur les options de l'attribut Htmltext | Options Htmltext | Mis à jour |
| Comportement de la contrainte lorsque l'attribut passé est de type array | Syntaxe des contraintes | Mis à jour |
| Utilisation du contexte dans les traductions javascript | Traduction js | Mis à jour |
| Possibilité de sélectionner un "Document destinataire" ccomme destinataire pour un modèle de mail | Spécification de l'émetteur ou du destinataire | Nouveau |
Ajout options --status-file et --stop-on-error au script d'API refreshDocuments, et changement du comportement en cas d'erreur |
refreshDocuments | Mis à jour |
| Ajout "Fonction de rappel à l'extinction" | Fonction de rappel à l'extinction | Nouveau |
1.4.7 Édition 7
| Modifications | Chapitre | Version |
|---|---|---|
| Ajout callstack dans le retour d'erreur de wsh | Erreur wsh | Mise à jour |
| Précisions sur les fonctions de transaction | Transactions | Mise à jour |
| Précisions sur les minuteurs avec date dynamique | Minuteur dynamique | Mise à jour |
| Précisions sur les mécanismes d'exception | Exception | Nouveau chapitre |
| Ajout verrouillage de transaction | Transaction | Mise à jour |
| Niveau de log paramétrable par instance | Log::setLogLevel | Nouveauté |
| Nouveau test d'enregistrement des entiers | Type int | Nouveauté |
| Nouveaux hook dans formatCollection | Classe FormatCollection | Nouveauté |
| Modification du rendu (formatCollection) des longtext présents dans les tableaux | FormatCollection - longtext | Mise à jour |
| Impacts de la visibility I des attributs | Importation wsh, interface, exportation, format de collection | Mise à jour |
| Précision sur l'itération de document avec SearchDoc | SearchDoc::setObjectReturn | Mise à jour |
| L'authentification par jetons n'émet plus de cookies de session | Authentification par jetons | Mise à jour |
1.4.8 Édition 6
| Modifications | Chapitre | Version |
|---|---|---|
| Ajout des nouvelles options d'export CSV | CSV exportations | Mise à jour |
| Ajout de l'option displayrowcount sur les array | Array displayrowcount | Mise à jour |
| Ajout de l'option SET sur l'importation des profils | importation des profil | Mise à jour |
| Précision sur l'option showempty pour les images | showempty | Mise à jour |
| Précision sur la composition d'un titre | Titre de document | Mise à jour |
| Précision sur le retour d'un paramètre de famille | Doc::getFamilyParameter() | Mise à jour |
Modification du libellé du droit modify de dossier |
Droit modify |
Mise à jour |
| Précision sur l'inclusion de css | Application::addCssRef() | Mise à jour |
| Modification du retour SearchDoc::onlyCount() en cas d'erreur | SearchDoc::onlyCount() | Mise à jour |
| Avertissement sur l'utilisation de getCustomTitle dans les rapports | Doc::getCustomTitle() | Mise à jour |
Modification visuel des attributs de type file et image en modification |
Attributs file et image | Mise à jour |
Option d'attribut elabel indiqué comme options communes d'attribut |
Option elabel | Mise à jour |
| Gestion des minuteurs | Méthode pour les minuteurs | Nouveau chapitre |
1.4.9 Édition 5
| Modifications | Chapitre | Version |
|---|---|---|
| Précision pour les rapports | Doc::getCustomTitle | Mise à jour |
| Précision paramètre OPENDOC | FDL:OPENDOC | Mise à jour |
| Précision paramétrage du modèle de mail | Modèle de mail | Mise à jour |
1.4.10 Édition 4
L'édition 4 de la documentation a modifié les points suivants.
| Modifications | Chapitre | Version |
|---|---|---|
| Description de la mise en place des traductions | Internationalisation | Nouveau chapitre |
| Ajout chapitres sur les templates | Usage avancée des templates | Nouveau chapitre |
| Ajout graphe d'accès | Cinématique de dynacase | Nouveau chapitre |
| Description des principales tables | La base de données | Nouveau chapitre |
| Famille processus | Famille processus | Nouveau chapitre |
| Ajout chapitres Dbobj, QueryDb, Transaction | Mécanismes de persistance | Nouveau chapitre |
| Ajout chapitre compte | Manipulation des comptes utilisateur | Nouveau chapitre |
| Ajout chapitre migration | Migration des applications | Nouveau chapitre |
| Ajout chapitre contrôle d'accès | Contrôle des accès | Nouveau chapitre |
| Ajout chapitre zones et actions de référence | Zone et actions de référence | Nouveau chapitre |
| Ajout chapitre SearchDoc | Classe SearchDoc | Nouveau chapitre |
| Mise à jour des chapitres API | Les essentiels de l'API | Mise à jour |
| Ajout chapitre Utilitaire gestion de documents | Utilitaire gestion de documents | Nouveau chapitre |
1.4.11 Modification release 3.2.12
1.4.11.1 Internationalisation
Ajout de la possibilité d'utiliser les contextes et les formes plurielles dans les traductions.
1.4.11.2 SearchDoc::addGeneralFilter
La méthode SearchDoc::addGeneralFilter() retourne
systématiquement une exception en cas d'erreur.
1.4.11.3 SearchDoc::join
La méthode SearchDoc::join() retourne une
exception en cas d'erreur.
1.4.11.4 SearchDoc::onlyCount
La méthode SearchDoc::onlyCount() effectue
systématiquement un appel à la base de donnée pour récupérer le résultat.
1.4.11.5 SearchDoc::setRecursiveSearch
La méthode SearchDoc::setRecursiveSearch() a un
nouveau paramètre pour indiquer le niveau de profondeur. Ceci évite de mettre à
jour directement la propriété SearchDoc::folderRecursiveLevel.
1.4.11.6 Importation CSV
Le script importDocument a de nouvelles options
permettant de configurer l'importation des formats csv.
L'interface d'administration d'importation des documents permet aussi de
configurer les options d'importation pour les fichiers csv.
1.4.11.7 Layout::eSet, Layout::eSetBlockData
Les méthodes Layout::eSet() et
Layout::eSetBlockData() ont été ajoutées afin de faciliter
l'ajout de clefs correctement encodées dans des fichiers XML et HTML.
1.4.11.8 Dir::insertMultipleDocuments
La méthode Dir::insertMultipleDocuments a été
modifiée afin de faire remonter le message d'erreur de la méthode hameçon
Dir::postInsertMultipleDocuments dans son
retour d'erreur.
Chapitre 2 Introduction à Dynacase
Ce chapitre présente l'ensemble des notions de base composant Dynacase de manière succincte. Il permet a un nouvel utilisateur de faire un rapide tour de présentation de la plate-forme.
2.1 Famille et document et attributs
2.1.1 Résumé
Un élément central de Dynacase est le modèle documentaire. Celui-ci peut-être décrit par les concepts suivants :
- La famille
- Celle-ci correspond à une structure type permettant de stocker et de représenter des données (par exemple le type compte-rendu de réunion, composé d'un titre, d'une liste de participants, d'une description, etc.). Si on fait une analogie avec le paradigme objet, elle correspond à la classe.
- Le document
- Il correspond à un élément d'une famille (par exemple : un document de la famille compte-rendu contenant le compte rendu de la réunion marketing du 12 mai 2012 ayant pour invité Mickaël, Jean et Paul). Si on fait une analogie avec le paradigme objet, il correspond à un objet étant une instance de sa famille de référence.
- Les collections
-
Les collections sont des documents regroupant des documents. Il en existe plusieurs types :
- Dossier
- Un dossier permet à un utilisateur ou à des règles métier d'ajouter et d'enlever des documents à la collection qu'il représente.
- Recherche
- Une recherche est une collection qui est définie par des critères de recherches. Le contenu de cette collection est donc re-calculé à chaque consultation. Par exemple, la recherche Les documents dont je suis rédacteur sera exprimée sous la forme d'une recherche permettant de trouver l'ensemble des documents où l'utilisateur en cours est cité comme rédacteur.
2.1.2 La famille
Une famille est un élément permettant de décrire la structure et le comportement de documents.

Figure 1. Schéma théorique de famille
Le schéma ci-dessus indique qu'une famille Dynacase est constituée des éléments suivants :
- Des propriétés
- Elles définissent le comportement de la famille et des méta-données qui lui sont associées.
- Une structure
-
Elle définit l'organisation et le type des données contenues par les documents de la famille.
Elle est composée de deux types d'éléments :- Les attributs
- Ils sont de différent types (texte, date, énuméré, lien entre documents, etc.) et définissent le contenu de chaque document.
Par exemple, un compte-rendu de réunion est composé d' un titre de type texte, d'une date de réunion de type date, des annexes de type fichier, - Les paramètres
- Ils définissent des éléments de même valeur pour tous les documents d'une même famille.
Par exemple, les compte-rendus ont comme préfixe pour leur titre : "CR_".
- Des représentations
-
Elles permettent de modifier la mise en forme d'un document, cela peut se matérialiser de différentes manières :
- une mise en page simplifiée pour un certain type d'utilisateur (html par exemple);
- une représentation sous la forme de données brutes pour de la communication entre systèmes (xml par exemple);
- une représentation sous la forme d'un fichier bureautique ou PDF;
- etc.
- Des contrôles de vues
- Ces éléments permettent d'indiquer à quel type d'utilisateur correspond quelle(s) représentation(s). Par exemple, un manager peut voir plus d'éléments sur un compte-rendu qu'un simple participant.
- Des règles métiers
-
Elles sont l'ensemble des règles s'appliquant à un type de document. Elles peuvent être de type très divers (ajout d'une règle de calcul de numéro chrono, ajout de contraintes particulières sur la mise en forme des données, calcul automatique d'une valeur, aide aux utilisateurs pour la saisie des valeurs).
Elles se déclarent de deux manières :- via une classe associée à la famille : celle-ci permet de surcharger les comportements par défaut de Dynacase lors des étapes de la vie du document (création, sauvegarde, édition, etc.);
- via un fichier PHP : celui-ci liste des méthodes permettant de guider la saisie des utilisateurs (par exemple rechercher uniquement les salles disponibles).
2.1.2.1 Familles système et fonctionnelle
On distingue deux types de familles.
- Famille fonctionnelle
- Une famille fonctionnelle a un sens fonctionnellement et elle porte les documents des utilisateurs (une famille de compte rendu, de gestion de contrat, etc.).
- Famille système
-
Une famille système permet de créer des documents utilisés par le paramétrage de Dynacase, dont le contenu est recherchable uniquement pour les administrateurs. C'est le cas pour les familles suivantes :
- contrôle de vue : ce document permet de définir la représentation d'un document;
- modèle de mail : qui permet de définir un modèle d'envoi par mail pour un type de document;
- etc.
Ces documents n'ayant pas de sens particulier pour les utilisateurs non administrateurs, ils ne sont pas accessibles via les recherches par défaut pour ne pas les surcharger avec des informations non pertinentes.
NB : il est possible dans le cadre d'un développement Dynacase de définir ses propres familles systèmes et fonctionnelles
2.1.3 Le document
Un document est un objet de Dynacase. Il contient de l'information structurée et est persistant. Il est principalement présenté aux utilisateurs sous la forme de formulaires web à compléter ou de pages web.
Si on s'appuie sur une analogie avec le paradigme objet, il est un objet.
Le document est une instance d'une famille. En reprenant l'exemple des compte-rendus un document de la famille compte-rendu est donc le compte-rendu du 12 mai 2012 se référant à une réunion précise.
Il contient les éléments suivants :
- Des propriétés
- La date de création, la date de dernière modification, le créateur, le profilage associé…
- Des données
- L'ensemble des données contenues par le document.
- L'historique
- L'historique des actions ayant eu lieu autour du document (historique des modifications, des envoi de mail, etc.).
2.1.4 Les types d'attributs
Un type d'attribut est un type de données. Il est utilisé dans les familles pour définir leur structure et dans les documents pour représenter, traiter et sauvegarder les données associées au document.
Il existe trois catégories d'attributs :
- Structurant
-
Ces attributs permettent d'organiser les familles. Il en existe deux catégories :
- Onglet
- Il permet de regrouper des attributs de type frame.
Il est représenté par un onglet dans les formulaires. - Cadre
- Il permet de regrouper des attributs non-structurants.
Il est représenté par un cadre dans les formulaires.
Ces attributs permettent de définir des ensembles sémantiques. Par exemple, dans le compte-rendu, le cadre Description regroupe le titre, la date et le lieu de la réunion.
- Donnée
- Ces attributs permettent de structurer les données récoltées au sein d'un formulaire. Ils permettent d'indiquer qu'une famille est composée d'un champ texte, d'un champ date, etc. Leur présence permet à la plate-forme de générer à la fois les formulaires et la structure en base de données permettant de stocker les documents.
- Tableau
- Ce type d'attribut permet de créer une représentation tabulaire d'un ensemble d'attributs Donnée. Ceux-ci deviennent alors les colonnes d'un tableau pouvant avoir plusieurs lignes.
2.1.5 Les attributs
Un attribut correspond à un champ de données dans la définition d'une famille. L'ensemble des attributs définissent le contenu du document. Lors de la définition d'un attribut au sein d'une famille, on lui adjoint des caractéristiques parmi les suivantes :
- Type d'attribut
- Il permet d'indiquer de quel type est l'attribut (texte, date, numérique, etc.).
- Visibilité
- Elle définit la manière dont l'utilisateur pourra interagir avec l'attribut, qui peut être soit éditable, en lecture seule, etc. Cet élément peut-être surchargé via les mécanismes des masques / contrôles de vues pour présenter une visibilité de manière dynamique (suivant l'état du document, ou la personne le consultant par exemple).
- Label
- Il est affiché à côté de l'attribut dans les représentations des documents. Cet élément peut être traduit.
- Méthode de calcul (facultatif)
- Un attribut ayant une méthode de calcul est dit calculé. Sa valeur est automatiquement calculée par Dynacase à chaque sauvegarde du document. Elle se présente sous la forme d'une méthode PHP renvoyant la nouvelle valeur.
- Aide à la saisie (facultatif)
- Un attribut possédant une aide à la saisie suggère des valeurs possibles aux utilisateurs lors de sa valorisation. L'aide à la saisie se présente sous la forme d'une fonction PHP renvoyant la liste des valeurs possibles.
- Contrainte (facultatif)
- Elle permet de valider l'information avant sa sauvegarde. Celle-ci se présente sous la forme d'une méthode PHP renvoyant un statut et, en cas de non respect de la contrainte, un message permettant de guider l'utilisateur dans le choix de la valeur.
- Vue particulière (facultatif)
- Si cette propriété est présente la représentation de l'attribut peut-être totalement ou partiellement surchargée (présentation d'un graphique dans le formulaire par exemple).
- Options (facultatif)
- Des options peuvent être adjointes à l'attribut pour modifier son comportement. Celles-ci sont propres à chaque type d'attribut et permettent d'en modifier soit le comportement soit l'affichage.
2.1.6 Famille système
Une famille système permet de créer des documents utilisés par le paramétrage de Dynacase, dont le contenu est recherchable uniquement pour les administrateurs. C'est le cas pour les familles suivantes :
- contrôle de vue : ce document permet de définir la représentation d'un document;
- modèle de mail : qui permet de définir un modèle d'envoi par mail pour un type de document;
- etc.
Ces documents n'ayant pas de sens particulier pour les utilisateurs non administrateurs, ils ne sont pas accessibles via les recherches par défaut pour ne pas surcharger celles-ci avec des informations non pertinentes.
NB : il est possible dans le cadre d'un développement Dynacase de définir ses propres familles systèmes
2.1.7 Collection
Une collection est un document qui permet de regrouper un ensemble de documents. Elle peut-être utilisée comme base pour des recherches particulières ou comme moyen de permettre à un utilisateur de faire des requêtes. Il existe, notamment, les deux types de collections suivants :
- Dossier
- Un dossier permet à un utilisateur ou à des règles métier d'ajouter et d'enlever des documents à l'intérieur de ce dossier.
- Recherche
- Une recherche permet à un utilisateur ou un intégrateur de paramétrer des règles permettant de regrouper un ensemble de document (par exemple : l'ensemble des compte rendu de réunion entre le 01/01/2042 et 31/12/2042).
2.2 Cycle de vie
2.2.1 Résumé
Ce chapitre décrit un élément fondamental d'un projet Dynacase : le cycle de vie.
Le cycle de vie est un objet interne à Dynacase qui permet de faire évoluer un document au sein d'un processus. Lors de ce processus, différentes actions peuvent être appliquées au document :
- changement/calcul de valeurs (le numéro chrono n'est affecté qu'après la validation du document),
- changement des droits associés à un document (un document en rédaction ne peut être modifiable que par son rédacteur),
- évolution du formulaire (l'onglet validation n'apparaît que lors de l'étape validation),
- envoi de courriel (le validateur d'un document reçoit un courriel lorsque son avis est nécessaire),
- déclenchement d'un minuteur (si après 1 mois le document est toujours en validation, le valideur est relancé),
- plus généralement du code PHP peut-être déclenché (envoi à un autre élément du système d'informations de l'ordre de paiement après validation finale du document).
Les cycles de vie de Dynacase peuvent être représentés par des graphiques orientés (ceux-ci sont automatiquement générés par la plate-forme).
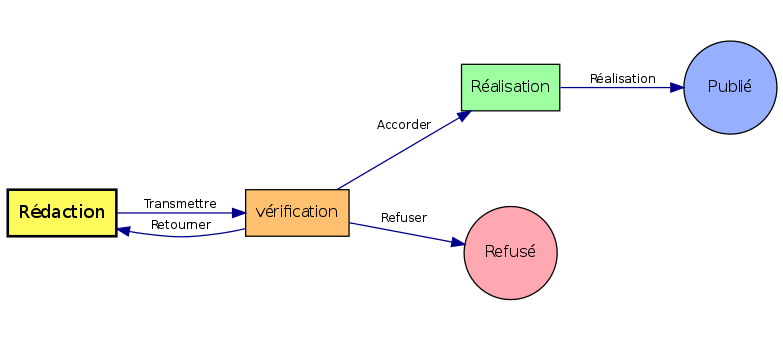
Figure 2. Exemple de schéma de cycle de vie
2.2.2 Composants d'un cycle de vie
Un cycle de vie est composé des éléments suivants :
- Propriétés
- Elles facilitent le paramétrage et l'exportation (famille associée, nom logique, etc.).
- Structure
- La structure est composée d'étapes et de transitions reliant les étapes. Elle constitue la base du cycle et indique comment le document peut évoluer.
- Profil du cycle de vie
- Un profil est associé au cycle, il permet de définir qui pourra effectuer quelle transition.
2.2.3 Étapes
Les étapes marquent un moment clef dans la vie du document. Une étape est constituée de :
- État
- L'état est le statut du document à un moment donné (brouillon, rédigé, validé, historique).
- Activité
- L'activité est la tâche en cours de réalisation sur un document donné (par exemple : en rédaction, en validation).
À une étape, on peut rattacher les éléments suivants :
- Courriel (un ou plusieurs)
- Ils sont alors envoyés à chaque passage dans cette étape,
- Un profil
- Il est alors attaché au document lors de son entrée dans l'étape et modifie la liste des comptes pouvant modifier, voir, supprimer le document en cours.
- Un contrôle de vue ou/un masque
- Il est alors attaché au document lors dans son entrée dans l'étape et modifie la représentation du document.
- Couleur
- Celle-ci est reprise dans l'IHM et permet aux utilisateurs d'avoir un moyen mémo-technique simple pour identifier rapidement les documents.
- Affectation
- L'affectation d'un utilisateur à une étape permet de réserver le document à cet utilisateur et d'éventuellement verrouiller le document à l'intention de cet utilisateur et de lui envoyer un courriel.
NB : On considère qu'une étape sans activité doit être terminale (c'est à dire qu'il n'existe pas de transition permettant de sortir de cette étape), car c'est uniquement durant ces étapes que le document n'évolue plus, qu'aucune activité ne s'y applique. Par exemple, un document gardé pour historique n'évolue plus et aucune activité ne s'y applique.
2.2.4 Transition
Les transitions indiquent la possibilité de passage entre une étape et une autre.
Une transition se déroule de la manière suivante :
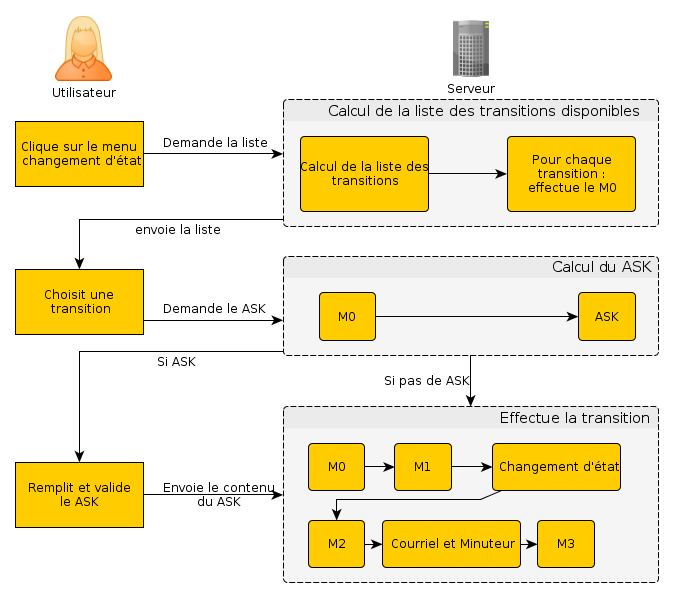
Figure 3. Déroulement d'une transition
- M0 (ou précondition)
-
La précondition ou M0 est une méthode PHP qui est systématiquement exécutée en début de transition, ce qui correspond aux cas suivants :
- lors de l'affichage de la liste des transitions possibles à une étape donnée,
- avant le déclenchement des ASK (voir entrée suivante),
- avant le changement d'état en lui même
Si la précondition n'est pas remplie alors elle renvoie un message qui est affiché à l'utilisateur et ne permet pas d'effectuer la transition.
- ASK
- Les ASK sont un ensemble d'attributs utilisés pour poser une question à l'utilisateur avant d'effectuer la transition. Ils peuvent servir à valider une valeur, demander un commentaire, etc. Les valeurs récupérées peuvent être utilisées dans les méthodes du cycle de vie lors des M1, M2, M3.
- M1
- Le M1 est une méthode PHP qui est appelée après les ASK et le M0 mais avant le changement d'état. On peut l'utiliser pour vérifier un ensemble d'éléments et annuler le passage d'une transition si besoin. Par exemple, on peut vérifier la présence d'un élément dans le document en cours de transition et annuler le passage de la transition si celui-ci n'est pas présent.
- M2
- Le M2 est une méthode PHP qui est appelée après le changement d'état. Elle est utilisée pour modifier le document une fois la transition effectuée mais avant les courriels et les minuteurs. Elle est utilisée pour modifier le contenu du document avant l'envoi des courriels.
- Courriel
- Il est possible d'attacher des courriels au passage d'une transition. Ceux-ci sont alors envoyés à chaque passage de cette transition, le contenu et les destinataires peuvent être composés à l'aide du contenu du document en cours de transition.
- Minuteur
- Il est possible d'attacher des minuteurs au passage d'une transition. Ceux-ci servent à déclencher une action de manière asynchrone (au bout d'un certain temps). Un des usages les plus typiques est la relance par mail (par exemple, si jamais le document est toujours à l'état relecture au bout de 15 jours le relecteur reçoit à nouveau un mail l'invitant à relire le document).
- M3
- Le M3 est une méthode PHP qui est appelée en tout dernier lors d'une transition. Elle est utilisée pour effectuer une action après le passage de la transition, l'envoi des mails et des minuteurs.
NB : M2 et M3 peuvent retourner un message, contrairement à celui de M0 et M1 il n'empêchera pas le passage de la transition mais sera présenté à l'utilisateur.
2.2.5 Cycle de vie, famille et document
Le cycle de vie se matérialise sous la forme d'un document Dynacase.
Ce document est ensuite lié à une ou plusieurs familles : tous les nouveaux documents de cette ou ces famille(s) :
- sont affectés à ce cycle de vie;
- sont automatiquement affectés à la première étape de ce cycle après leur création;
- utilisent ce cycle pour définir :
- leur représentation,
- leur accessibilité (qui a le droit de voir, modifier, supprimer).
NB : il est aussi possible d'affecter un cycle de vie à un document via de la programmation.
2.3 Applications, actions et ACL
2.3.1 Résumé
Toute requête effectuée sur le serveur exécute une action d'une application. L'action détermine la fonctionnalité attendue par la requête.
Vocabulaire :
- Application
- Une application est un conteneur permettant de regrouper des Actions, des ACL et des paramètres.
- Action
-
Une action est une fonction PHP. Cette fonction peut utiliser l'ensemble de l'API de Dynacase et est exécutée au nom de l'utilisateur en cours (les droits, visibilités et autres sont donc respectés). Elles peuvent être utilisées pour effectuer :
- des exports particuliers (textuel ou binaire),
- des traitements particuliers (dupliquer des documents, effectuer des modifications de groupes, créations automatiques, etc.),
- des IHM spécifiques (mise en place d'un portail d'accueil, d'interface de manipulation de documents, etc.)
- ACL
- Une ACL est un droit applicatif, elle a deux usages complémentaires. Au niveau d'une action, elle indique que l'utilisateur doit posséder cette ACL pour pouvoir utiliser cette action et associée à un compte (rôle, utilisateur, groupe) elle indique que ce compte possède cette ACL.
2.3.2 Application
Une application est caractérisée par :
- Des propriétés
-
Ces propriétés permettent d'identifier et de caractériser l'application. Il y a notamment :
- Nom logique
- C'est le nom logique de l'application, il est utilisé lors de son appel.
- Nom
- Ce nom est utilisé dans les interfaces d'administration, il peut-être traduit.
- Description
- Cette description est utilisée dans les interfaces d'administration, elle peut-être traduite.
- Icône
- Cette icône est utilisée dans les interfaces d'administration.
- Une liste d'ACL
- Cette liste est sous la forme d'un tableau PHP d'ACL. Elle est propre à chaque application
- Une liste de définition d'action
- Cette liste est présentée sous la forme d'un tableau PHP d'action. La liste des actions est propre à chaque application.
- Des paramètres applicatifs
- Les paramètres applicatifs sont présentés sous la forme d'une liste décrivant l'ensemble des paramètres applicatifs applicables pour l'application
NB : une application peut hériter d'une autre, elle hérite alors de son paramétrage et des actions et paramètres applicatifs.
2.3.3 ACL
Une ACL est un marqueur permettant d'indiquer que :
- un droit est nécessaire pour effectuer une action,
- un compte le possède et pourra donc effectuer les actions nécessitant l'ACL.
La vérification des ACL est incluse dans la plate-forme et est effectuée automatiquement lors de l'appel à une action. Si le compte utilisé pour faire l'appel ne possède pas l'ACL nécessaire un message d'erreur est alors généré.
2.3.4 Action
L'action est constituée d'une fonction PHP qui est utilisée lors de son appel.
Les principaux éléments constituant une action sont :
- Un nom logique
- Il est utilisé pour référencer l'action, notamment, lors de l'appel de l'action.
- Le nom logique d'une ACL (facultatif)
- S'il est présent la plate-forme n'exécute l'action que si le compte demandant l'exécution possède l'ACL.
- Un nom de layout (facultatif)
- Il permet d'indiquer avec quel layout (template utilisé par le moteur de template) l'action est rendue (par défaut, le template a le même nom que l'action). NB : si l'action n'a pas de représentation, ou renvoie un élément encodé (JSON, base64, etc.), il est possible d'indiquer à l'action de ne pas utiliser le moteur de template.
2.3.5 Paramètre applicatif
Un paramètre applicatif est un élément que l'on peut ajouter à une action pour stocker des données permettant de paramétrer l'action. Une fois le paramètre enregistré une API permet de le manipuler (récupérer, modifier sa valeur).
De plus, les paramètres applicatifs sont présentés via les interfaces d'administration de Dynacase et peuvent être modifiés par les administrateurs système. Il sont utilisés principalement dans deux cas :
- mettre en place une persistance au niveau d'une application pour l'ensemble des utilisateurs (par exemple le format du préfixe du nom de fichier que retourne une action d'export),
- mettre en place une persistance au niveau d'un utilisateur d'une application (par exemple les préférence d'export de l'utilisateur en cours).
Les principaux éléments constituant d'un paramètre applicatif sont :
- Un nom logique
- Il permet de manipuler le paramètre applicatif.
- Une valeur par défaut
- Elle est utilisée pour initier la valeur du paramètre.
- Une visibilité
- Elle indique si un paramètre applicatif est ou pas commun à l'ensemble des utilisateurs.
2.4 Comptes : utilisateurs, groupes et rôles
2.4.1 Résumé
La gestion des droits et de la sécurité dans Dynacase repose sur la notion de compte. Le compte est lui divisé en trois notions :
- Utilisateur
- Un utilisateur représente une personne (physique ou morale) ayant la capacité de se connecter à la plate-forme, il possède donc à minima un login.
- Groupe
- Un groupe est un ensemble d'utilisateurs et de groupes.
Les groupes peuvent s'imbriquer et dans ce cas le groupe de plus haut niveau contient l'ensemble des utilisateurs de ses groupes fils (par exemple, le groupe 1 contient le groupe 2 et le groupe 2 contient l'utilisateur 3 alors le groupe 1 contient l'utilisateur 3). - Rôle
-
Un rôle marque une fonction. La notion de rôle est utilisée dans le cadre du profilage, il a deux usages complémentaires :
- au niveau d'un groupe, il indique que l'ensemble des utilisateurs (directement dans le groupe ou hérités de groupes fils) possèdent ce rôle,
- au niveau d'un profil, il indique que seul les utilisateurs ayant ce rôle peuvent effectuer un certain type d'action (par exemple : uniquement les utilisateurs ayant le rôle rédacteur peuvent modifier le document).
2.4.2 Utilisateur
Les utilisateurs Dynacase possèdent les principales caractéristiques suivantes :
- Nom et prénom
- Ils permettent d'identifier la personne.
- Login
- le login est l'identifiant unique d'un utilisateur, il est notamment utilisé pour identifier l'utilisateur lors de la phase de login.
- Mot de passe (optionnel)
- Le mot de passe est utilisé lors de la phase de login, il est stocké sous la forme d'une empreinte cryptographique (hash) en base de données.
- Adresse e-mail (optionnel)
- L'adresse e-mail de l'utilisateur est utilisée lors d'un envoi de mail à un utilisateur ou à un groupe d'utilisateurs, cette adresse e-mail est alors automatiquement récupérée par la plate-forme lors de la mise en forme d'un courriel.
- Date d'expiration du compte
- Cette date permet d'indiquer qu'un compte ne sera plus actif passé une certaine date. Lorsque le compte est inactif, l'utilisateur ne peut plus se connecter. Le compte n'est pas supprimé et peut-être réactivé par la suite.
Il est de plus possible de désactiver un compte et de gérer les groupes via les interfaces d'administration et l'API de Dynacase.
2.4.3 Groupe
Un groupe est un ensemble d'utilisateurs ou de groupes, il permet d'effectuer les actions suivantes :
- envoi d'un mail aux membres d'un groupe,
- affectation d'un ou plusieurs rôles à l'ensemble des membres du groupe,
- affectation d'ACL à l'ensemble des membres du groupe.
Les groupes possèdent les caractéristiques suivantes :
- Nom
- Nom du groupe
- Login
- Il sert à l'identification du groupe.
- Sans adresse mail de groupe
- Désactive la possibilité d'envoyer un mail aux membres du groupe.
- Rôle
- la liste des rôles associés à ce groupe
De plus, il est possible d'ajouter/supprimer des utilisateurs/groupes d'un groupe via les interfaces d'administration et l'API de Dynacase.
2.4.4 Rôle
Un rôle est uniquement composé de son titre et d'une référence, en effet le rôle n'a de sens que associé à un groupe et à un profil.
2.5 Sécurité : authentification, droit applicatif, droit documentaire
2.5.1 Résumé
Ce chapitre aborde la notion de sécurité au sein de Dynacase. Cela comprend les éléments suivants :
- Une mécanique d'authentification
-
Ce système permet d'identifier l'utilisateur essayant de se connecter. Il est composé d'un système de frontends et de backends d'authentification.
- Frontend d'authentification
- Système qui décrit la méthode (le protocole) d’interaction avec l'utilisateur pour demander les éléments nécessaires à l'authentification.
- Backend d'authentification
- Système qui permet de vérifier auprès d'une autorité la validité des informations d'authentification obtenues par le frontend d'authentification.
- Une mécanique d'autorisation
-
Ce système est composé de deux couches et permet de définir ce que l'utilisateur peut ou ne peut pas faire.
- La sécurité applicative
- Ce système est basé sur des ACL, seuls les utilisateurs possédant l'ACL requise peuvent exécuter l'application ou l'action.
- Sécurité documentaire
- Un système de droit, profil et rôle permet de désigner de manière statique ou dynamique (suivant l'état ou le contenu du document) quels utilisateurs peuvent consulter, modifier, supprimer, etc. des documents.
On peut résumer les mécanismes de sécurité avec le schéma suivant :
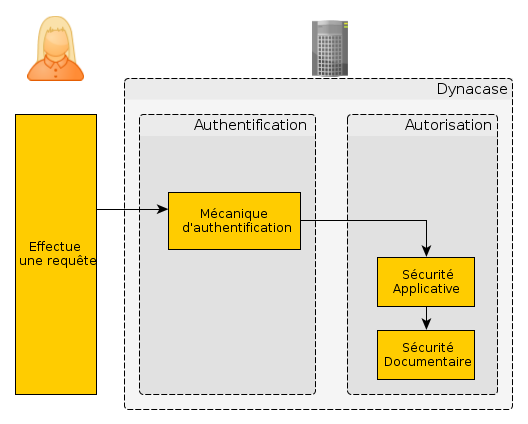
Figure 4. Sécurité : résumé
2.5.2 Mécanisme d'authentification
Le mécanisme d'authentification de Dynacase permet d'identifier les utilisateurs via différentes sources et différents moyens.
Les frontend d'authentification fournis par défaut par Dynacase sont :
- authentification par formulaire web,
- authentification par HTTP Basic,
- authentification par jeton.
Les backends d'authentification fournis par défaut par Dynacase sont :
- authentification sur base Dynacase,
- authentification par LDAP/Active Directory (via un module complémentaire).
Il est de plus possible de créer ses propres backend et frontend d'authentification et d'en indiquer l'ordre d'exécution (par exemple, on peut choisir que l'utilisateur sera d'abord authentifié par un reverse proxy puis, si le reverse proxy n'a pas donné l'authentification, par un login sous forme de formulaire).
2.5.3 Sécurité applicative
La sécurité applicative fonctionne avec un mécanisme d'ACL. Chaque action peut-être associée à une ACL et seuls les utilisateurs possédant cette ACL peuvent exécuter cette action.
NB : une action n'ayant pas d'ACL est accessible à tout utilisateur même si celui-ci n'est pas connecté mais les droits documentaires continuent de s'appliquer (dans le cas d'un utilisateur non connecté c'est l'utilisateur anonymous guest qui est utilisé pour le calcul des droits).
2.5.4 Sécurité documentaire
La sécurité documentaire est le mécanisme permettant de définir qui peut effectuer quelle opération avec un document.
2.5.4.1 Droits par défaut
Les droits par défaut sont les suivants :
- Consulter
- Permet de consulter et trouver le document.
- Modifier
- Permet de modifier le contenu du document que ce soit via le formulaire par défaut ou via l'API appelée en son nom. Si ce droit n'est pas présent les modifications ne peuvent être enregistrées.
- Supprimer
- Permet de supprimer le document que ce soit via l'IHM ou via l'API.
De plus, il existe au niveau d'une famille documentaire les droits suivants:
- Créer
- Un utilisateur ayant ce droit sur une famille peut créer un document de cette famille en exécutant une action effectuant cette tâche.
- Créer manuellement
- Un utilisateur ayant ce droit peut créer un document de cette famille, en passant par l'interface de création de document par défaut.
NB : D'autres éléments internes, de plus haut niveau, de Dynacase possèdent plus de droits. Par exemple, les dossiers, recherches et rapport possèdent des droits spécialisés propres à leur fonction (droit d'effectuer la recherche, droit d'ouvrir le dossier, etc.).
2.5.4.2 Profil
Le système d'attribution des droits à des utilisateurs repose sur la notion de profil. Un profil est un document interne comportant une matrice permettant d'indiquer quel rôle, groupe ou utilisateur possède quel droit.
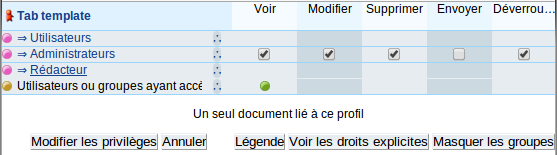
Figure 5. Sécurité : profil
On différencie deux usages de profil :
- Statique
- la liste des utilisateurs ayant droit ne varie pas suivant le contenu du document (par exemple : les utilisateurs ayant le rôle Rédacteur peuvent modifier ce document),
- Dynamique
- la liste des utilisateurs ayant droit varie alors suivant l'étape et/ou le contenu du document (par exemple : seul l'utilisateur cité dans l'attribut validateur de document peut le modifier lors de l'étape validation)
Il existe différents types de profils :
- Document
- Il concerne un document et n'indique que les droits de base (voir, modifier, supprimer).
- Famille
- Il concerne une définition de famille documentaire et indique les droits de base et les droits de création (via l'IHM par défaut, via le code).
- Les autres types de profil
- Les documents systèmes spécialisés de Dynacase possèdent des profils contenant des droits spécifiques (Dossier, Recherche, Rapport, etc.).
Une fois le profil créé, celui-ci doit être associé à un document. Pour ce faire, il existe plusieurs moyens :
- Via la famille
- Le profil est associé via une propriété de la définition de famille. Dans ce cas, tous les nouveaux documents de cette famille porteront ce profil.
- Via le cycle de vie
- Le profil est associé via le paramétrage du cycle de vie à une étape et tous les documents passant par cette étape se voient appliqué le profil.
- Via le code
- Le profil est attaché dynamiquement en utilisant les fonctions de l'API.
- Via l'interface de gestion
- Si l'utilisateur possède les droits suffisants, il lui est possible de changer le profil d'un document en cours.
NB : les moyens sont bien évidemment complémentaires et un document peut changer de nombreuses fois de profil au cours de sa vie.
2.5.4.2.1 Profil dédié
Le profil dédié est un profil qui n'est valable que pour un document. Il est défini directement au niveau du document et permet de gérer au plus près les accès à ce document.
Certain types de document système ne peuvent fonctionner qu'avec des profils dédiés, c'est notamment le cas des :
- Cycle de vie
- Le cycle de vie utilisant son profilage pour définir l'accessibilité des transitions, son profil est différent pour chaque cycle de vie.
- Contrôle de vue
- Le document de contrôle de vue utilise son profilage pour définir l'accessibilité des représentations qu'il contient, son profil est donc unique.
2.6 Internationalisation
2.6.1 Résumé
Dynacase comprend un mécanisme permettant l'internationalisation de l'application. Celui-ci permet de :
- traduire l'ensemble des labels présentés dans l'interface,
- présenter la date en fonction de la locale de l'utilisateur.
Par défaut, deux langues sont disponibles : le français et l'anglais.
2.6.2 Mécanisme de traduction
Dynacase utilise le mécanisme standard de traduction gettext et son implémentation en PHP (php-gettext) pour la gestion des traductions des messages.
Cet outil permet deux choses :
- lors du développement : la création de catalogues de traduction en extrayant les clefs directement du code PHP,
- lors de l'exécution : la récupération de la traduction d'une clef par rapport à la locale en cours (la langue choisie par l'utilisateur).
La mise en place des traductions lors du développement d'une application passe donc par les étapes suivantes :
-
Utilisation de l'API pour indiquer les éléments dont la traduction est nécessaire. Ceci se fait soit via :
- pour le code PHP, la fonction
_(); - pour le code javascript, la fonction
_()de l'api DATA; - pour les fichier de configuration des mots clefs spécifique au fichier.
- pour le code PHP, la fonction
- Extraction des clefs du code et construction des catalogues. Cette partie est soit manuelle, soit instrumentée à l'aide des outils de build des modules Dynacase.
- Déploiement du catalogue sur le serveur. Lors de la mise à jour du serveur applicatif, il faut fusionner les nouvelles définitions provenant du catalogue avec celles du catalogue principal.
- Lors de l'exécution du programme. lorsque le code passe par une méthode utilisée lors de l'étape 1, il va chercher dans le catalogue principal de la plate-forme le message traduit correspondant à la clef.
2.6.3 Mécanisme de mise à jour des paramètres régionaux
L'ajout de nouveaux paramètres régionaux (format de date, d'heure, etc.) passe par la mise à jour d'un fichier de configuration sur la plate-forme.
Chapitre 3 Le modèle objet de Dynacase
3.1 Les classes standard de Dynacase Core
Dynacase repose sur le modèle objet suivant :
Ce schéma présente une version simplifiée des héritages (les relations en pointillés omettent volontairement des classes intermédiaires).
Voici une brève explication des différentes classes.
3.1.1 DbObj
La classe DbObj sert à la persistance de données.
Son fonctionnement est détaillé dans la partie correspondante des techniques avancées.
3.1.2 Doc
La classe Doc est la classe de base des documents Dynacase.
Tous les documents héritent de la classe Doc.
3.1.3 DocFam
La classe DocFam est la classe d'une famille de documents.
Ainsi, une famille de document est aussi un type de document particulier, ce qui permet de la manipuler comme tel.
3.1.4 WDoc
La classe WDoc est la classe de base des cycles de vie.
Tous les cycles de vie héritent de la classe WDoc.
3.1.5 DocCollection
La classe DocCollection est la classe de base des collections.
Une collection est un ensemble de documents.
3.1.6 Dir
La classe Dir est la classe d'un dossier.
Un dossier est une collection statique de documents, à laquelle on peut ajouter ou supprimer des documents.
3.1.7 DocSearch
La classe DocSearch est la classe de base des recherches.
Une recherche est une collection dynamique de documents, dont le contenu est calculé à chaque accès en fonction des critères de la recherche.
3.2 Les Hooks
Le document offre de nombreux hooks permettant de modifier son comportement au cours des étapes telles que la création, modification, suppression, etc. de document.
Ces hooks viennent s'ajouter aux droits de l'utilisateur. Par exemple, lors de
la création d'un document, Dynacase vérifiera d'abord que l'utilisateur a bien
le droit de créer un document de la famille concernée, puis vérifiera ensuite
que le hook Doc::preCreated() ne bloque pas cette création.
3.2.1 Création de document
Les méthode surchargeables appelées lors de la création d'un document sont :
- Lors de la création avec
Doc::store() - Lors de la création avec
Doc::add()
3.2.2 Modification de document
Les méthode surchargeables appelées lors de la modification d'un document sont :
- Lors de la modification avec
Doc::store() - Lors de la modification avec
Doc::modify()- aucune
3.2.3 Suppression de document
Les méthode surchargeables appelées lors de la suppression d'un document
avec Doc::delete() sont :
3.2.4 Affectation de document
3.2.20 Les méthode surchargeables appelées lors de l'affectation d'un document sont
utilisé principalement par la fonction new_doc() et par la classe
SearchDoc.
3.2.5 Duplication de document
Les méthode surchargeables appelées lors de la duplication d'un document
avec Doc::duplicate()
Doc::preDuplicate()Doc::postDuplicate()
3.2.6 Import de document
Les méthode surchargeables appelées lors de l'import d'un document sont :
3.2.7 Ajout d'un document dans un dossier
Les méthode surchargeables appelées lors de l'ajout d'un document dans un dossier sont :
- Lors de l'insertion avec
Dir::insertDocument()Dir::preInsertDocument()Dir::postInsertDocument()
- Lors de l'insertion avec
Dir::insertMultipleDocuments()Dir::preInsertMultipleDocuments()Dir::postInsertMultipleDocuments()
3.2.8 Retrait d'un document d'un dossier
Les méthode surchargeables appelées lors du retrait d'un document
dans un dossier avec Dir::removeDocument() sont :
Dir::preRemoveDocument()Dir::postRemoveDocument()
3.3 Lignée documentaire et révisions
Afin de manipuler correctement les documents, il est important de comprendre les notions de révision et de lignée documentaire.
3.3.1 Révision
Une révision est une capture d'un document à un instant donné. Les valeurs (attributs, propriétés et fichiers) de ce document sont mémorisées et figées, et peuvent être consultées ultérieurement.
À un instant donné, une et une seule révision est active (c'est la révision courante) alors que les autres sont figées (ce sont les révisions passées).
Seule la révision active est modifiable, les révisions figées sont uniquement consultables.
3.3.2 Lignée documentaire
L'ensemble des révisions d'un document constituent une lignée documentaire.
Alors que chaque document est identifié de manière non ambigüe par son id,
unique, une lignée documentaire est identifiée par son initid.
3.3.3 révision, id et initid
Lors de l'enregistrement en base d'un document, s'il ne possède pas encore d'id,
un nouvel id est attribuée au document. Cette valeur est également
affectée à la propriété initid. La propriété révision, quand à elle, est
positionnée à 0.
Lorsqu'un document est révisé, techniquement, un nouveau document est créé
(c'est à dire qu'une nouvelle ligne est créée en base de données).
La propriété révision est incrémentée, la propriété initid est conservée, et un
nouvel id est affecté au document. L'ancienne révision est également marqué
comme figée (voir la propriété locked).
Exemple :
- création d'un nouveau document
- ancienne révision
- aucune
- nouvelle révision
- initid : 1234
- id : 1234
- revision : 0
- locked : 0
- ancienne révision
- révision du document
- ancienne révision
- initid : 1234
- id : 1234
- revision : 0
- locked : -1
- nouvelle révision
- initid : 1234
- id : 2345
- revision : 1
- locked : 0
- ancienne révision
Note : les valeurs des id et initid sont arbitraires, elles sont, dans les
faits, affectées par la base de données.
3.3.4 Révisions et relations
Dans l'interface d'édition, par défaut, les attributs de type docid
sont valués avec l'initid du document cible. Lors de la consultation, le lien
est ajusté pour pointer vers la dernière révision de sa lignée documentaire.
Ce comportement peut être modifié au moyen de l'option docrev des attributs
relation.
3.3.5 Révisions et new_doc
Par défaut, la fonction new_doc récupère la révision correspondant à
l'id passé en paramètre ; ce qui veut dire que ce n'est pas nécessairement la
révision courante. Le troisième paramètre de new_doc permet de récupérer
systématiquement la révision courante.
Si l'identifiant de la fonction new_doc désigne un nom logique, c'est toujours
la version courante qui est retournée.
Le nom logique est le même sur toute la lignée documentaire.
3.3.6 Révisions et recherche
Lors des recherches de documents avec un critère sur une relation, si la
relation ne contient pas l'initid, on risque de ne pas trouver le document.
C'est pour cette raison que les relations contiennent l'initid par défaut. Dans
le cas où d'autres révisions peuvent être référencées, il faut ajouter un
critère plus complexe tenant compte des ids de toutes les révisions.
Chapitre 4 Familles et documents
4.1 Présentation
Dans Dynacase, le Document est la structure de base. Le document est constitué d'attributs qui contiennent la donnée.
Un document est fortement structuré, c'est à dire que toutes les informations qu'il contient sont typées et ordonnées.
Cette structure est définie par la famille : Une famille est un type de document (Compte-rendu, Demande de congés, Véhicule, …).
Si on fait le parallèle avec la programmation orientée objet, alors on observe les correspondances suivantes :
- la famille est la classe,
- le document est l'instance
Ainsi, dans Dynacase, toute manipulation d'information passera par une manipulation de document :
- instanciation (depuis la base de données) ou création
- modification
- enregistrement
Ce chapitre présente les différents éléments de paramétrage permettant de définir des familles de document. Chaque mécanisme est décrit dans sa propre partie, alors que la dernière partie spécifie le format de définition des structures.
4.2 Les attributs
4.2.1 Présentation
Les attributs correspondent à des éléments de structure du document.
Techniquement, ils correspondent à :
- un champ de saisie en modification ;
- une représentation textuelle en consultation ;
- une colonne en base de données pour stocker la donnée.
Les attributs sont typés, et disposent d'options permettant de modifier leur comportement, leur représentation, etc.
Cette partie présente chaque type d'attribut, décrit son usage, ses représentations, et liste les options disponibles pour chacun de ces types.
Note sur les options : Dans Dynacase, les options sont libres, ce qui veut dire que vous pouvez utiliser vos propres options pour rajouter des informations sur certains attributs (par exemple, vous pourriez rajouter une option inSpecialView pour lister les attributs à afficher dans votre vue spéciale). De par leur nature extensible, les options n'ont pas de valeur par défaut ; aussi, dans leur description, nous indiquerons par (comportement par défaut) le comportement de l'option en l'absence de valeur.
4.2.2 Options communes à tous les types d'attributs
- searchcriteria
-
Indique quelle sera l'utilisation de l'attribut dans les recherches.
Les valeurs possibles sont :
-
visible(comportement par défaut) : Dans ce cas- l'attribut est indexé pour la recherche plein texte
- l'attribut est présenté dans les critères des recherches détaillées et des rapports
-
restricted: Dans ce cas- l'attribut est indexé pour la recherche plein texte
- l'attribut n'est pas présenté dans les critères des recherches détaillées et des rapports
-
hidden: Dans ce cas- l'attribut n'est pas indexé pour la recherche plein texte
- l'attribut n'est pas présenté dans les critères des recherches détaillées et des rapports
-
- showempty
-
Indique que l'attribut doit être présenté en consultation, même si sa valeur est vide.
Cela modifie le comportement par défaut, qui consiste à n'afficher en consultation que les attributs valués.
Les valeurs possibles sont :
- `` (une chaîne vide) : Dans ce cas, le libellé sera présenté, et aucune valeur ne sera affichée
- toute chaîne de caractères : Dans ce cas, le libellé est affiché, et la valeur est remplacée par le texte donné.
Remarque : Pour le type image, la valeur doit indiquer le chemin relatif à un fichier 'image'. L'image sera alors affichée si la valeur est vide.
- sortable
-
Indique les modalités de tri de l'attribut.
Par défaut, les attributs sont considérés comme non triable.
Les valeurs possibles sont :
-
asc: Dans ce cas- l'attribut sera présenté dans le menu de tri de ONEFAM et dans les rapports
- l'ordre de tri par défaut sera ascendant
-
desc: Dans ce cas- l'attribut sera présenté dans le menu de tri de ONEFAM et dans les rapports
- l'ordre de tri par défaut sera descendant
-
- version
-
Indique que l'attribut est utilisé pour la composition de la version. Se reporter aux propriétés de la classe Doc pour plus de détails.
Les valeurs possibles sont :
yesno(comportement par défaut)
- vlabel
-
Indique la position du libellé de l'attribut.
Les valeurs possibles sont :
-
pour les attributs de type frame et onglet :
up(comportement par défaut)none
-
pour les attributs de type array :
left(valeur par défaut en consultation)up(valeur par défaut en modification)none
-
pour les autres attributs :
left(comportement par défaut)upnone
-
- elabel
-
Texte du tooltip du label de l'attribut pour le document en mode modification.
Ne s'applique pas aux attributs de structure (tab, frame, array).
Les valeurs possibles sont :
- Toute chaîne de caractères. Attention, la plupart des navigateurs n'acceptent pas de retour chariot.
- ititle
- Texte du tooltip du bouton '...' de l'aide à la saisie. Par défaut : « choisissez une valeur »
- ltitle
- Texte affichable en tooltip sur l'hyperlien lorsque la souris passe dessus
- ltarget
- Nom de la fenêtre destinataire de l'hyperlien. Par défaut
_self. Siltarget=fhiddenalors la requête ira dans une fenêtre cachée. - lconfirm
- Indique si on veut un message de confirmation avant l'activation du
lien. Mettre
lconfirm=yespour activer la confirmation. - tconfirm
- Texte de la confirmation
- autosuggest
- En édition, sur une aide à la saisie, indique que la recherche est
lancée à chaque modification du texte saisi. (par défaut
yes). Mettre ànopour désactiver l'auto-suggestion - eltitle
- Options pour pour les extra liens (elink). Texte affichable surgissant sur le bouton généré par l'extra lien.
- elsymbol
- Caractère affiché sur le bouton généré par l'extra lien.
Par défaut c'est le caractère
+qui est affiché. - eltarget
- Nom de la fenêtre destinataire sur le bouton généré par l'extra lien.
- viewtemplate
- Référence de la vue d'attribut à utiliser lors de la consultation du document
- edittemplate
- Référence de la vue d'attribut à utiliser lors de la modification du document
4.2.3 Type account
4.2.3.1 Description
Les attributs de type account permettent de faire un lien vers un compte (utilisateur, groupe, ou rôle).
4.2.3.2 Représentation
-
consultation : Un hyperlien vers l'utilisateur cible, avec comme label le titre l'utilisateur cible, et son icone.

Figure 6. account simple - consultation html
-
modification :
Une aide à la saisie vers les comptes.

Figure 7. account simple - Modification html
-
odt :
Le titre du document cible.

Figure 8. account simple - consultation odt
4.2.3.3 Comportement
Lors du rendu d'un account, Dynacase récupère dynamiquement le titre des documents cibles.
Pour chaque document cible, si l'utilisateur n'a pas le droit de voir le document cible,
le titre est remplacé par le texte Information non disponible (se reporter à l'option noaccesstext pour personnaliser ce texte).
4.2.3.4 Format de stockage
La valeur stockée est l'identifiant du document associé.
Le type utilisé en base de donnée est text.
4.2.3.5 Options
En plus des options communes à tous les types d'attributs, ce type d'attribut dispose des options suivantes :
- group
-
Indique une restriction sur les comptes qui peuvent être référencés par la relation.
L'aide à la saisie générée ne présentera que les comptes appartenant à ces groupes.
Lorsque l'option match vaut group, seuls les sous-groupes des groupes référencés seront proposés.
Cette option est incompatible avec match=role
Les valeurs possibles sont :
- une liste de références de groupes (attribut us_login) séparés par des virgules
- match
-
Indique une restriction sur les types de comptes qui peuvent être référencés par la relation.
L'aide à la saisie générée ne présentera que les comptes dans les types listés.
Les valeurs possibles sont :
user(comportement par défaut)grouproleall
- multiple
-
Indique que plusieurs documents peuvent être référencés par la relation.
Les valeurs possibles sont :
yesno(comportement par défaut)
- noaccesstext
-
Indique le texte qui est affiché lorsque le document cible n'est pas visible.
Cette valeur sera automatiquement ajoutée au catalogue de traduction.
Les valeurs possibles sont :
- toute chaîne de caractères (sur une seule ligne).
- role
-
Indique une restriction sur les comptes qui peuvent être référencés par la relation.
L'aide à la saisie générée ne présentera que les comptes ayant ces rôles.
Les valeurs possibles sont :
- une liste de référence de rôles séparés par des virgules
4.2.4 Type action
4.2.4.1 Description
Les attributs action permette d'ajouter des boutons dans les interfaces de consultation. Ces boutons déclencheront l'action défini par l'attribut.
4.2.4.2 Représentation
-
consultation :
Un bouton placé en bas du document.
-
modification :
Non représenté
odt :
Non représenté
4.2.4.3 Comportement
Si l'utilisateur peut exécuter l'action alors le bouton est présenté.
4.2.4.4 Format de stockage
Cet attribut n'est pas stocké.
4.2.4.5 Options
En plus des options communes à tous les types d'attributs, ce type d'attribut dispose des options suivantes :
- batchfolder
-
Indique si l'action définie doit être appliquée sur tous les éléments du dossier.
Option utilisable uniquement dans les familles dérivées de la famille EXEC (Traitement). Se reporter à la documentation de la famille Traitement pour plus de détails.
Les valeurs possibles sont :
yesno(comportement par défaut)
4.2.5 Type array
4.2.5.1 Description
Les attributs de type array permettent de définir des tableaux.
Chacun des attributs contenu dans un array est alors dit multiple, et correspond à une colonne du dit array. Un tableau ne peut pas contenir d'autres attributs de type array.
4.2.5.2 Représentation
Les array sont représentés au moyen d'une table.
Chaque colonne correspond à un attribut contenu dans l'array. Le libellé de la colonne est le libellé de l'attribut correspondant.
-
consultation :
Un tableau.

Figure 9. array - consultation html
-
modification :
La première colonne contient les outils permettant la sélection, suppression, et le déplacement d'une colonne, alors que la dernière ligne contient les outils permettant de rajouter une ligne ou de dupliquer une ligne existante.

Figure 10. array - Modification html
-
odt :
Un tableau

Figure 11. array - consultation odt
4.2.5.3 Comportement
Aucun comportement particulier.
4.2.5.4 Format de stockage
Le tableau en lui même n'est pas stocké, mais modifie la façon dont les attributs qu'il contient sont stockés. En effet, une fois dans un tableau, un attribut est multiple, et nécessite donc le stockage de plusieurs valeurs. Pour rester simple, la valeur stockée sera une suite des valeurs de stockage simples séparées par un séparateur interne.
Pour plus de précisions, se reporter au chapitre avancé sur les formats de stockage.
4.2.5.5 Options applicables à l'array
- cellbodystyle
-
Indique le style css appliqué sur les cellules du corps de tableau.
Les valeurs possibles sont :
- toute définition css valide.
- cellheadstyle
-
Indique le style css appliqué sur les cellules de l'entête de tableau.
Les valeurs possibles sont :
- toute définition css valide.
- classname
-
Indique une classe css à appliquer aux cellules du corps tableau en consultation.
Les valeurs possibles sont :
- tout nom de classe valide.
- displayrowcount 3.2.17
-
Indique si le nombre de lignes du tableau est affiché dans l'entête de la première colonne.
Les valeurs possibles sont un entier n avec :
- n <= -1 pour ne jamais afficher le nombre de lignes ;
- n = 0 pour toujours afficher le nombre de lignes ;
- n > 0 pour afficher le nombre de lignes si celui-ci est > n.
Par défaut la valeur de
displayrowcountest10. - empty
-
Indique que le tableau, s'il est vide ne doit pas afficher la première rangée en modification. Dans le cas contraire, en modification, le tableau est initialisé avec une rangée vide.
Les valeurs possibles sont :
yesno(comportement par défaut)
- height
-
Indique la hauteur du corps du tableau. Si le corps du tableau dépasse la hauteur spécifiée, un ascenseur vertical apparaîtra.
Ne fonctionne qu'avec les navigateurs récents.
Les valeurs possibles sont:
- Une taille en pixels (par exemple
150px).
- Une taille en pixels (par exemple
- sorttable
-
Indique que le tableau est triable. L'utilisateur peut cliquer sur un en-tête de colonne pour trier cette colonne.
Le tri est effectué au moyen du script sorttable.js.
L'utilisation avancée de sorttable.js sort du sujet de cette documentation, et est à charge et de la responsabilité du développeur.
Les valeurs possibles sont :
yesno(comportement par défaut)
- twidth
-
Indique la largeur du tableau. Si le corps du tableau dépasse la largeur spécifiée, un ascenseur horizontal apparaîtra.
Les valeurs possibles sont :
- une valeur absolue en pixel (par exemple
100px), - une largeur relative en pourcentage (par exemple
30%)
La valeur par défaut est
100%. - une valeur absolue en pixel (par exemple
- userowadd
-
Indique si l'utilisateur est autorisé à ajouter des rangées au tableau. Dans ce cas, le bouton correspondant est affiché.
Cela permet de ne pas être en conflit si le tableau doit être rempli par un code spécifique sur l'interface, mais pas par l'utilisateur.
Les valeurs possibles sont :
yes(comportement par défaut)no
- rowviewzone
- Indique une vue spécifique de tableau pour la consultation.
- roweditzone
- Indique une vue spécifique de tableau pour la modification.
4.2.5.6 Options applicables aux attributs contenus dans un array
- align
-
Indique l'alignement horizontal pour les cellules de la colonne.
Les valeur possibles sont :
-
left, -
right, -
center, justify
-
- bgcolor
-
Indique la couleur de fond des cellules de la colonne.
Les valeurs possibles sont :
- toute couleur css valide
(exemple :
yellow,#FF335A, etc.)
- toute couleur css valide
(exemple :
- color
-
Indique la couleur du texte pour les cellules de la colonne.
Les valeurs possibles sont :
- toute couleur css valide
(exemple :
yellow,#FF335A, etc.)
- toute couleur css valide
(exemple :
- cwidth
-
Indique la largeur de la colonne.
Les valeurs possibles sont :
- une valeur absolue en pixel (par exemple
100px), - une largeur relative en pourcentage (par exemple
30%) auto(comportement par défaut)
- une valeur absolue en pixel (par exemple
4.2.6 Type color
4.2.6.1 Description
Les attributs de type color permettent d'insérer une couleur.
4.2.6.2 Représentation
-
consultation :
Un
spancontenant le code html de la couleur, et la couleur comme background.
Figure 12. color - consultation html
-
modification :
Un color picker basé sur JSColor.

Figure 13. color - Modification html
-
odt :
Non utilisable
4.2.6.3 Comportement
Aucun comportement particulier.
4.2.6.4 Format de stockage
La valeur stockée est le code html de la couleur.
Le type utilisé en base de donnée est text.
4.2.6.5 Options
options communes à tous les types d'attributs.
Ce type d'attribut ne dispose d'aucune option spécifique.
4.2.7 Type date
4.2.7.1 Description
Les attributs de type date permettent d'insérer une date.
4.2.7.2 Représentation
-
consultation :
La date formatée en accord avec la locale de l'utilisateur.

Figure 14. date - consultation html
La date peut avoir un format particulier en utilisant la notation de strftime.
Exemple :
date("%A %e %B %y")pour affichervendredi 17 mai 2013 -
modification :
Un date picker (basé sur JSCalendar).

Figure 15. date - Modification html
-
odt :
La date formatée en accord avec la locale de l'utilisateur.

Figure 16. date - consultation odt
4.2.7.3 Comportement
Lors de la saisie, la date est validée, c'est à dire que le format doit être :
- soit au format « français » ;
- soit au format « US » ;
- soit au format ISO8601.
4.2.7.4 Format de stockage
La date est stockée au format ISO8601 (yyyy-mm-dd).
Le type utilisé en base de donnée est date.
Si l'attribut est dans un tableau, le type en base donnée sera text.
4.2.7.5 Options
options communes à tous les types d'attributs.
Ce type d'attribut ne dispose d'aucune option spécifique.
4.2.8 Type docid
4.2.8.1 Description
Les attributs de type docid permettent de faire un lien vers un ou plusieurs documents. Ils sont appelés relations.
Les attributs de type docid sont typés, c'est à dire qu'on précise de quelle
famille doivent être les documents cible.
Cela se fait au moyen de la syntaxe docid("<family>") (Dans ce cas, les
documents doivent être de la famille <family> ou d'une de ses
ous-familles).
4.2.8.2 Représentation
-
consultation :
Un hyperlien vers le document cible, avec comme label le titre du document cible, et l'icône du document

Figure 17. docid simple - consultation html
-
modification :
une aide à la saisie vers les documents de la famille cible (et de ses sous-familles). L'aide à la saisie porte sur le titre uniquement, avec le filtre contient, insensible à la casse et aux accents.

Figure 18. docid simple - Modification html
-
odt :

Figure 19. docid simple - consultation odt
4.2.8.3 Comportement
Lors du rendu d'un docid, Dynacase récupère le titre des documents cibles. Pour chaque document cible, si l'utilisateur n'a pas le droit de voir le document cible, le titre est remplacé par le texte Information non disponible (se reporter à l'option noaccesstext pour personnaliser ce texte).
4.2.8.4 Format de stockage
La valeur stockée est l'identifiant interne du document cible.
Attention, bien que l'identifiant soit la plupart du temps un nombre, son format de stockage est un format texte.
Le type utilisé en base de donnée est text.
4.2.8.5 Options
En plus des options communes à tous les types d'attributs, ce type d'attribut dispose des options suivantes :
- creation
-
Indique qu'un document de la famille cible de la relation pourra être créé depuis le formulaire.
Dans ce cas, un bouton sera ajouté sur le formulaire. Ce bouton ouvre un formulaire de création de la famille cible. Lors de la sauvegarde du nouveau document, ce nouveau document est inséré dans l'attribut de départ.
Si l'utilisateur n'a pas le droit de créer un document de la famille cible, le bouton ne sera pas affiché.Pour les relations multiples, le nouveau document sera inséré dans la liste des documents.
Lorsque la relation est déjà renseignée, le bouton permet de modifier le document cible au lieu d'en créer un nouveau.
Si le document lié n'est pas accessible en modification, il sera alors affiché en consultation.Les valeurs possibles sont :
yes-
un objet (Attention: bien que cela y ressemble, ce n'est pas du JSON) construit de la manière suivante :
- Pour définir la valeur d'un attribut du document cible :
attrid_document_cible: "valeur"(si la valeur est fixe), ouattrid_document_cible: attrid_document_sourcesi la valeur est à recopier depuis le document source. - Pour fermer la fenêtre de création lors de la sauvegarde :
autoclose: "yes" -
Pour appeler de nouveau l'aide à la saisie lors de l'insertion de la valeur dans le document source :
recallhelper: "yes"Cela peut être utile dans le cas où l'aide à la saisie doit remplir plusieurs attributs du document source.
Par exemple,
creation={an_name:CT, an_reference :"une référence", an_target:en_source, recallhelper: "yes", autoclose: "yes"}indique que :- l'attribut an_name prendra comme valeur initiale *la valeur actuellement saisie par l'utilisateur dans le champ de l'aide à la saisie
- l'attribut an_reference prendra la valeur une référence
- l'attribut an_target prendra la valeur de l'attribut en_source du document source
- l'aide à la saisie sera rappelée lors de la sauvegarde du document nouvellement créé
- la fenêtre de création du nouveau document sera fermée lors de sa sauvegarde.
- Pour définir la valeur d'un attribut du document cible :
- docrev
-
Indique quelle est la révision pointée par la relation.
Les valeurs possibles sont :
-
latest(comportement par défaut) : Dans ce cas, la relation pointe vers la dernière révision de la lignée documentaire ; -
fixed: Dans ce cas, la relation pointe vers la révision ayant l'id référencé ; -
state(step), où step est une étape : Dans ce cas, la relation pointe vers le dernier document à l'étape step.
Cette option affecte le comportement de l'aide à la saisie générée :
- lorsque l'option a la valeur latest, c'est l'initid du document qui est retourné ;
- lorsque l'option a la valeur fixed, c'est le docid de la dernière révision au moment de l'appel qui est retourné ;
- lorsque l'option a la valeur state(step), seuls les documents à l'étape step sont listés, et c'est le docid de la dernière révision à l'étape step au moment de l'appel qui est retourné.
-
- doctitle
-
Indique qu'un attribut contenant le titre du document cible doit être automatiquement renseigné.
Cela est notamment utile pour la recherche plein texte, les tris, etc.
Les valeurs possibles sont :
-
no(comportement par défaut) ; - tout id d'attribut existant : Dans ce cas, l'attribut référencé contient le titre du document cible ;
-
auto: Dans ce cas, un attribut est généré (son id est <id_de_la_relation>_title et son titre est <titre_de_la_relation> (titre) )
-
- isuser
-
Indique quels attributs sont utilisables pour le profilage des documents.
Les valeurs possibles sont :
-
yes: Dans ce cas, il faut que le document lié soit de la familleIUSER(Utilisateur) ou dérivé deIUSER. no(comportement par défaut)
-
- multiple
-
Indique que plusieurs documents peuvent être référencés par la relation.
Les valeurs possibles sont :
yesno(comportement par défaut)
- noaccesstext
-
Indique le texte qui est affiché lorsque le document cible n'est pas visible.
Cette valeur sera automatiquement ajoutée au catalogue de traduction.
Les valeurs possibles sont :
- toute chaîne de caractères.
En l'absence de l'option, le texte affiché est Information non disponible
4.2.9 Type double
4.2.9.1 Description
Les attributs de type double permettent d'insérer un nombre avec décimales.
4.2.9.2 Représentation
-
consultation :
Le nombre, sans formatage

Figure 20. double - consultation html
Le formatage spécifique de double doit être conforme à celui utilisé dans la fonction sprintf. Par exemple
double("%.03f")pour avoir 3 chiffres maximum après la virgule. -
modification :
un
inputde typetextepermettant de saisir le nombre.
Figure 21. double - Modification html
-
odt :
Le nombre, sans formatage

Figure 22. double - consultation odt
4.2.9.3 Comportement
Lors de l'enregistrement, le nettoyage suivant est effectué :
- remplacement des
,par. - suppression des espaces
La valeur nettoyée est validée au moyen de la fonction is_numeric.
4.2.9.4 Format de stockage
La valeur stockée est la valeur nettoyée.
Le type utilisé en base de donnée est double.
Si l'attribut est dans un tableau, le type en base donnée sera text.
4.2.9.5 Options
Options communes à tous les types d'attributs.
- elabel
-
En plus du tooltip du label défini par les options communes pour
elabel, Cette option affecte sa valeur sur l'attributtitledu l'inputcorrespondant.Les valeurs possibles sont :
- Toute chaîne de caractères. Attention, la plupart des navigateurs n'acceptent pas de retour chariot.
4.2.10 Type enum
4.2.10.1 Description
Les attributs de type enum permettent d'insérer des listes de choix, sous la forme clé|libellé.
4.2.10.2 Représentation
-
consultation :
Le libellé, traduit le cas échéant.

Figure 23. enum - consultation html
-
modification :
Un input de type select présentant les libellés traduits le cas échéant.

Figure 24. enum - Modification html
-
odt :
Le libellé, traduit le cas échéant.

Figure 25. enum - consultation odt
4.2.10.3 Comportement
Aucun comportement particulier.
4.2.10.4 Format de stockage
La valeur stockée est la clé.
Le type utilisé en base de donnée est text.
4.2.10.5 Options
En plus des options communes à tous les types d'attributs, ce type d'attribut dispose des options suivantes :
- bmenu
-
Indique si l'énuméré doit apparaître en tant que filtre dans les interfaces de l'application GENERIC
Les valeurs possibles sont :
yes(comportement par défaut)no
- boolcolor
-
Indique que l'énuméré sera représenté (en consultation) par un carré de couleur.
Les valeurs possibles sont :
- Un couple de couleurs css valides séparées par une virgule (par exemple
blue,#FF0000). La première couleur indique la couleur de la première clé, et la seconde couleur celle de la seconde clé.
- Un couple de couleurs css valides séparées par une virgule (par exemple
- eformat
-
Indique le mode d'affichage de l'énuméré.
Les valeurs possibles sont :
-
list(comportement par défaut)-
Dans le cas d'un énuméré simple, il sera représenté
- en modification sous la forme d'un select traditionnel,
- en consultation sous la forme d'une chaîne contenant le label
-
Dans le cas d'un énuméré multiple, il sera représenté
- en modification sous la forme d'un select traditionnel (avec utilisation de la touche ctrl pour sélectionner plusieurs valeurs,
- en consultation sous la forme d'une liste de chaînes contenant le label alignées verticalement
-
-
vcheck-
Dans le cas d'un énuméré simple, il sera représenté
- en modification sous la forme de boutons radio alignés verticalement
- en consultation sous la forme d'une chaîne contenant le label
-
Dans le cas d'un énuméré multiple, il sera représenté
- en modification sous la forme de checkbox alignées verticalement
- en consultation sous la forme d'une liste de valeurs alignées verticalement
-
-
hcheck-
Dans le cas d'un énuméré simple, il sera représenté
- en modification sous la forme de boutons radio alignés horizontalement
- en consultation sous la forme d'une chaîne contenant le label
-
Dans le cas d'un énuméré multiple, il sera représenté
- en modification sous la forme de checkbox alignées horizontalement
- en consultation sous la forme d'une liste de valeurs alignées horizontalement
-
-
autola présentation de l'énuméré sera similaire à celle d'un attribut de type
docid -
boolNe s'applique qu'aux énumérés à 2 valeurs.
L'énuméré sera présenté
- en modification sous la forme d'une checkbox (coché sélectionne la seconde valeur, non coché reste sur la première valeur)
- en consultation sous la forme d'une chaîne contenant le label
-
- esort
-
Indique l'ordre dans lequel les entrées seront listées.
Les valeurs possibles sont :
-
none(comportement par défaut) Les énumérés sont présentés dans l'ordre de déclaration; -
key: Dans ce cas, les propositions sont triées par ordre alphabétique des clés ; -
label: Dans ce cas, les propositions sont triées par ordre alphabétique des traductions des libellés.
-
- etype
-
Indique si la valeur est restreinte aux valeurs de la liste.
Les valeurs possibles sont :
-
free: Dans ce cas, l'utilisateur peut saisir une valeur libre -
open: Dans ce cas, l'utilisateur peut également saisir une valeur libre. Cette valeur sera alors ajoutée à la liste des valeurs possibles pour les choix ultérieurs.
-
- eunset
-
Indiquer que l'énuméré sera vide par défaut.
S'il y a une valeur par défaut explicite pour l'attribut, l'option eunset est inopérante.
Les valeurs possibles sont :
yes-
no(par défaut) : Dans ce cas, la valeur par défaut est la première des valeurs de l'énuméré selon sa définition.
- mselectsize
-
Indique le nombre d'items présentés pour les énumérés multiples lorsque l'option eformat est
list.Les valeurs possibles sont :
- tout entier.
La valeur par défaut est
3. - multiple
-
Indique que l'énuméré peut être multivalué.
Les énumérés multiples ne peuvent pas être utilisés dans les tableaux.
Les valeurs possibles sont :
yesno(comportement par défaut)
- system
-
Indique que la gestion de l'énuméré ne peut pas être faite par l'IHM d'administration.
Dans ce cas, la définition est écrasée à chaque importation.
Les valeurs possibles sont :
yesno(comportement par défaut)
4.2.10.6 Définition de valeurs d'énumérés
Les énumérés sont structurés sous la forme de couples clé/valeur. La valeur stockée en base de données est la clé, alors que l'utilisateur voit la valeur correspondante.
Les labels peuvent ainsi être traduits, tout en n'altérant pas le stockage en base.
Lors de la Déclaration de familles, il est possible de
définir des couples de clé/valeur au moyen de la syntaxe
[cle1]|[label 1],[cle2]|[label 2],….
Pour chaque clé définie par ce moyen :
- si la clé existe déjà pour cet énuméré, le label correspondant est mis à jour,
- si la clé n'existe pas pour cet énuméré, elle est ajoutée.
4.2.10.6.1 Restrictions sur la valeur des clés
Lors de la composition des clés, il est interdit d'utiliser
- les caractères :
-
"(guillemet double), -
'(apostrophe), -
&(esperluette), -
|(pipe)
-
- les séquences :
-
-dot-, -comma-
-
En outre, les valeurs suivantes doivent être échappées au moyen du caractère
\ (anti-slash) :
-
.(point) : voir les énumérés multi-niveaux
4.2.10.6.2 Restrictions sur la valeur des labels
Lors de la composition des labels, il est interdit d'utiliser
- les caractères :
-
|(pipe)
-
- les séquences :
-
-dot-, -comma-
-
En outre, les valeurs suivantes doivent être échappées au moyen du caractère
\ (anti-slash) :
-
,(virgule)
4.2.10.6.3 Suppression de valeurs d'énumérés
Si l'énuméré est déclaré avec l'option system=yes, les définitions des
énumérés est réinitialisé à chaque importation.
Si l'énuméré n'a pas cette option, il faut ajouter un ordre
RESET;enums pour forcer la réinitialisation avec les nouvelles
valeurs définies.
Note : La suppression d'une valeur dans la définition ne supprime pas les valeurs déjà affectés aux documents. Si un document a une valeur non répertoriée dans la définition de l'énuméré ce sera cette valeur (brute) qui sera affichée car son ancien libellé aura été supprimé.
4.2.10.6.4 Énumérés multi-niveaux
Il est possible d'exprimer une arborescence des clés au moyen du séparateur
..
Par exemple, l'énuméré
france|France,france.midi|Midi-Pyrénées,france.midi.gers|Gers,france.midi.haute-garonne|Haute-Garonne,france.idf|Île-de-France,france.idf.paris|Paris
définit l'arborescence :
- France
- Midi-Pyrénées
- Gers
- Haute-Garonne
- Île-de-France
- Paris
- Midi-Pyrénées
Du point de vue interne, c'est la clé 'finale' qui est stockée. Cela permet de
modifier l'arborescence sans impacter les clés déjà stockées. Cependant, cela
implique aussi que toutes les clés finales d'un énuméré doivent être
non‑ambigües (par exemple, un|un,un.one|one,deux|deux,deux.one|one more
n'est pas valide, car la clé one désigne à la fois un.one et deux.one).
4.2.10.6.5 Valeurs dynamiques
La définition d'un énuméré peut être fournie par une fonction PHP.
Cette fonction est alors exprimée de la même façon qu'une aide à la saisie : la
caractéristique phpfile doit désigner un fichier publié dans le répertoire
EXTERNALS et la fonction de définition de l'énuméré doit être définie dans le
fichier référencé par phpfile.
Cette fonction doit retourner la définition sous la forme d'une chaîne de caractères comme décrit ci-dessus.
4.2.10.6.6 Localisation des énumérés
Les labels sont traduisibles. les clés de traductions sont composées sous la
forme <FAMILYNAME>#<ATTRID>#<ENUMKEY> (exemple MY_FAMILY#my_color#yellow).
4.2.11 Type file
4.2.11.1 Description
Les attributs de type file permettent d'insérer un fichier.
4.2.11.2 Représentation
-
consultation :
Un lien permettant de télécharger le fichier

Figure 26. file - consultation html
-
modification :
Un
inputde typetextprésentant le nom du fichier, suivi de 3 boutons :- pour choisir un nouveau fichier,
- restaurer le fichier préalablement enregistré,
- effacer le fichier.

Figure 27. file - Modification html
S'il s'agit d'une modification de document et que le fichier est déjà enregistré alors le clic sur le nom du fichier permet de le télécharger.
Des différences de comportement sont présentes en fonction des navigateur. Sur IE < 11, le bouton original "Parcourir" est affiché lorsqu'on clique sur le bouton "...". Le paramètre applicatif "FDL_OLDFILEINPUTCOMPAT" indique si l'attribut doit présenter, de manière systématique, le bouton original "Parcourir"

Figure 28. file - FDL_OLDFILEINPUTCOMPAT Modification html
-
odt :
Le titre du fichier

Figure 29. file - consultation odt
4.2.11.3 Comportement
Lors de l'enregistrement du document, le fichier est stocké dans le vault.
4.2.11.4 Format de stockage
La valeur stockée est l'identifiant vault du fichier
(sous la forme <type-mime>|<vaultid>|<file-name>).
Le type utilisé en base de donnée est text.
4.2.11.5 Options
En plus des options communes à tous les types d'attributs, ce type d'attribut dispose des options suivantes :
- hideindav
-
Indique si le fichier apparaît lors de l'accès au moyen du protocole webdav.
Les valeurs possibles sont :
yes(comportement par défaut)no
- inline
-
Si le paramètre est
yes, il indique que le fichier doit être consulté directement dans le navigateur. Seuls les types de fichiers supportés par le navigateur peuvent être affichés directement.
Si le paramètre estno, le téléchargement est proposé par le navigateur. Le nom du fichier proposé au téléchargement est celui du fichier enregistré. Si le nom du fichier comporte des double-quotes", ils sont remplacés par des tirets-.Les valeurs possibles sont :
yesno(comportement par défaut)
- pdffile
-
Utilisé conjointement avec l'option viewfiletype, indique l'attribut contenant le fichier pdf à afficher.
Les valeurs possibles sont :
- tout id d'attribut de la famille en cours.
- preventfilechange
-
Ajoute une contrainte pour que le fichier à remplacer provienne de la dernière version du serveur.
Cela ne bloque pas un changement de fichier mais avertit l'utilisateur dans le cas où le fichier ne correspond pas à cette dernière version.
Lors du téléchargement du fichier un code identifiant la version est ajouté dans le nom du fichier (exemple foo{i47307-56}.ods pour le fichier foo.ods). Lorsque l'utilisateur envoie à nouveau le fichier, le serveur vérifie ce numéro de version. Si le numéro correspond à la dernière version, alors le fichier est accepté. Dans le cas contraire, une confirmation est demandée à l'utilisateur.
Attention: si l'utilisateur renomme le fichier, la vérification échoue, et le serveur demande la confirmation.
Les valeurs possibles sont :
yesno(comportement par défaut)
- rn
-
Indique que le fichier sera renommé sur le serveur.
Les valeurs possibles sont :
- un nom de méthode de la famille courante (par exemple
::myNewName()). La méthode prend en entrée le nom du fichier et doit retourner le nouveau nom sous la forme d'une chaîne de caractères.
Note: Il est recommandé que la méthode fournisse une extension compatible avec le type mime pour l'utilisation ultérieure sur le poste client et les transformations. Pour récupérer l'extension d'un nom de fichier vous pouvez utiliser la fonction
getFileExtensionde la librairieLib.FileMime.php - un nom de méthode de la famille courante (par exemple
- search
-
Indique si l'attribut est indexé pour la recherche plein-texte.
Les valeurs possibles sont :
yes(comportement par défaut)no
- template
-
Indique si l'attribut file est un template.
se reporter à la documentation des templates OOO pour les explications
Les valeurs possibles sont :
staticdynamic
- viewfileheigth
-
Utilisé conjointement avec l'option viewfiletype, indique la hauteur du rendu affiché sur le navigateur.
Les valeurs possibles sont :
- Une taille en pixels (par exemple
150px). - Une taille en pourcentage de la hauteur de la fenêtre (par exemple
80%)
Il n'y a pas de valeur par défaut
- Une taille en pixels (par exemple
- viewfiletype
-
Indique qu'une prévisualisation du fichier sera disponible dans le navigateur, ne nécessitant donc pas de logiciel tiers.
Les valeurs possibles sont :
-
pdf: Dans ce cas, l'attribut indiqué par l'option pdffile sera utilisé comme prévisualisation ; -
image: Dans ce cas, le moteur de transformation génère une visualisation sous forme d'images avec tourne pages du pdf référencé par l'option pdffile.
-
4.2.12 Type frame
4.2.12.1 Description
Les attributs de type frame permettent de regrouper des attributs. Ce regroupement sera le plus souvent sémantique.
4.2.12.2 Représentation
-
consultation :
un
diventourant les attributs contenus dans cette frame. Le titre du cadre est dans une balisedivplacé avant le contenu.
Figure 30. frame - consultation html
-
modification :
un
fieldsetentourant les attributs contenus dans cette frame. Le titre du cadre est dans une baliselegend.
Figure 31. frame - Modification html
-
odt :
Aucune représentation
4.2.12.3 Comportement
Une frame est collapsible en cliquant sur son libellé.
4.2.12.4 Format de stockage
Cet attribut n'est pas stocké.
4.2.12.5 Options
En plus des options communes à tous les types d'attributs, ce type d'attribut dispose des options suivantes :
- bgcolor
-
Indique la couleur de fond du cadre.
Les valeurs possibles sont :
- toute couleur css valide
(exemple :
yellow,#FF335A, etc.)
- toute couleur css valide
(exemple :
4.2.13 Type htmltext
4.2.13.1 Description
Les attributs de type htmltext permettent d'insérer du texte avec mise en forme.
Le langage de mise en forme est le html, et un éditeur WYSIWYG (basé sur CKEditor) permet d'en simplifier la saisie.
4.2.13.2 Représentation
-
consultation :
une
divcontenant la valeur.
Figure 32. htmltext - consultation html
-
modification :
une
iframedans laquelle est initialisé une instance de CKEditor.
Figure 33. htmltext - Modification html
-
odt :
la mise en forme est conservée.
Se reporter au chapitre sur les vues odt pour les restrictions sur l'utilisation des attributs de type html dans les document openDocument text.
4.2.13.3 Comportement
L'éditeur CKeditor nettoit le code HTML inséré. Il ne conserve que les balises qui peuvent être insérées avec la barre de menu.
3.2.19 Lors de l'enregistrement sur le serveur, le nettoyage suivant est effectué :
- Suppression de tous les attributs commençant par "on" ou "xmlns"
- Suppression du javascript, applet et vbscript (le contenu est conservé sans les balises )
- Suppression des éléments avec namespace
- Les entités UTF-8 sont décodées ;
- Les commentaires sont supprimés.
En ce qui concerne les balises "script", elles ne sont pas autorisées par CKEditor quelque soit la configuration. Le nettoyage côté serveur est réalisé pour les données qui peuvent provenir d'une autre source que l'éditeur web.
3.2.20 Lors de l'affectation de l'attribut, le fragment HTML est controllé afin de vérifier s'il est bien formé et retourne une erreur si ce n'est pas le cas.
4.2.13.4 Format de stockage
La valeur stockée est le html nettoyé selon les règles précédentes.
Le type utilisé en base de donnée est text.
4.2.13.5 Options
En plus des options communes à tous les types d'attributs, ce type d'attribut dispose des options suivantes :
- doclink
-
Cette option nécessite l'installation du module dynacase-ckeditor-plugins.
Active l'option doclink du HTMLEditor. Cette option se présente sous la forme d'un nouveau bouton (dans la partie réservée au lien dans les toolbar et en fin de toolbar sur la Basic), en cliquant sur le bouton une interface vous propose de sélectionner un document et ajoute une balise de lien vers ce document.
Les valeurs possibles sont :
- un objet JSON (par exemple
{"famId": "DIR", "docrev" : "fixed"}), contenant les propriétés suivantes :-
famId(obligatoire) : nom logique de la famille des documents cible, -
docrev(facultatif) : les valeurs possibles sont les mêmes que l'option docrev des attributs de type docid (latest, fixed, state(keystate)), -
filter(facultatif) : un filtre SQL qui sera appliqué à la recherche
-
- un objet JSON (par exemple
- editheight
-
Indique la hauteur de la zone d'édition.
Les valeurs possibles sont :
- une taille en pixels (par exemple
400px)
La valeur par défaut est
150px. - une taille en pixels (par exemple
- htmlclean
-
Indique que le serveur nettoiera le contenu en supprimant toutes les balises de style, généralement issues d'un copier/coller :
- les attribut des balises
span(le contenu est conservé) etfontsont supprimés ; - les attributs
@classet@stylesont supprimés ; - les balises
stylesont supprimées.
De plus, le fragment HTML est réécrit sous une forme normalisée3.2.20
Les valeurs possibles sont :
yesno(comportement par défaut)
- les attribut des balises
- allowedcontent 3.2.20
-
Indique que la liste des balises autorisées n'est pas liée au menu. Toute balise html supportée peut être insérée à l'exception de la balise
script. Les attributs de ces balises peuvent aussi être utilisées à l'exception des attributs commençant parontel queonclickouonmouseover.Les valeurs possibles sont :
-
all: toute balise supportée est autorisée -
menu(comportement par défaut) en fonction de la barre de menu (voir optiontoolbarci-après).
Les balises supportées sont :
a,abbr,acronym,address,applet,area,article,aside,audio,b,base,basefont,bdi,bdo,big,blockquote,body,br,button,canvas,caption,center,cite,code,col,colgroup,command,datalist,dd,del,details,dfn,dialog,dir,div,dl,dt,em,embed,fieldset,figcaption,figure,font,footer,form,h1,h2,h3,h4,h5,h6,head,header,hgroup,hr,html,i,iframe,img,input,ins,isindex,kbd,keygen,label,legend,li,link,main,map,mark,menu,meta,meter,nav,noframes,noscript,object,ol,optgroup,option,output,p,param,pre,progress,q,rp,rt,ruby,s,samp,section,select,small,source,span,strike,strong,style,sub,summary,sup,table,tbody,td,textarea,tfoot,th,thead,time,title,tr,track,tt,u,ul,var,video,wbr. -
- jsonconf
-
Cette option permet de configurer finement l'éditeur de texte WYSIWYG.
Elle permet notamment de fixer finement le comportement de l'éditeur et le contenu des toolbar. Les options de configuration sont celles de CKEditor, et l'objet de configuration doit être présenté en JSON valide.
Les options propres à CKEditor (resize, correction orthographique, etc) ne sont pas maintenues par Anakeen et leur bon fonctionnement n'est pas garanti par Anakeen.
Aux options de CKEDITOR, dynacase ajoute les options suivantes :
-
addPlugin : permet de charger un plugin additionnel.
La valeur doit être un tableau (JSON) de noms logiques de plugins (par exemple:
"addPlugins": ["docattr"]). Dans ce cas, le plugin doit posséder une commande ayant le même nom que le nom logique du plugin. Cette commande est alors ajoutée en fin de toolbar.
Exemple de configuration permettant d'activer le plugin docattr et le plugin doclink et avec un menu basique et l'activation du mode resize :
jsonconf={"addPlugins" : ["docattr"], "doclink" : {"famId" : "DIR"}, "toolbar" : "basic", "resize_enabled" : true}Attention : l'utilisation de cette option bas niveau désactive les options suivantes :
- toolbar
- toolbarexpand
- editheight
- doclink
Il est par contre possible de construire une option jsonconf qui a le même effet que les options précédentes.
-
- toolbar
-
Indique le template à utiliser pour la barre de menu.
La barre de menu contraint par défaut la liste des éléments acceptés par l'éditeur de texte.
Pour supprrimer cette contrainte, il faut utiliser l'option
allowedContentde ckeditor. Exemple pour tout autoriser :jsonconf={"allowedContent" : true, "toolbar" : "Basic"}Les valeurs possibles sont :
-
Simple(comportement par défaut) :
Figure 34. toolbar Simple
Les balises et attributs autorisés sont :
- "a[tout attribut] "
- "address"
- "br"
- "caption[text-align]"
- "div[text-align]"
- "em"
- "h1[text-align]"
- "h2[text-align]"
- "h3[text-align]"
- "h4[text-align]"
- "h5[text-align]"
- "h6[text-align]"
- "img[tout attribut] "
- "li[text-align]"
- "ol"
- "p[text-align]"
- "pre[text-align]"
- "s"
- "span[font-size, color, background-color]"
- "strong"
- "table[width, height]"
- "tbody"
- "td[width, height, border-color, background-color, white-space, vertical-align, text-align, text-align]"
- "tfoot"
- "th[width, height, border-color, background-color, white-space, vertical-align, text-align, text-align]"
- "thead"
- "tr"
- "u"
- "ul"
-
Basic:
Figure 35. toolbar Basic
Les balises et attributs autorisés sont :
- "a[tout attribut] "
- "br"
- "em"
- "img[tout attribut] "
- "li"
- "ol"
- "p"
- "strong"
- "td[width, height, border-color, background-color, white-space, vertical-align, text-align]"
- "th[width, height, border-color, background-color, white-space, vertical-align, text-align]"
- "ul"
-
Default:
Figure 36. toolbar Default
Les balises et attributs autorisés sont :
- "a[tout attribut] "
- "address"
- "big"
- "blockquote"
- "br"
- "caption[text-align]"
- "cite"
- "code"
- "del"
- "div[text-align, padding, background, border]"
- "em"
- "h1[text-align]"
- "h2[text-align, font-style]"
- "h3[text-align, color, font-style]"
- "h4[text-align]"
- "h5[text-align]"
- "h6[text-align]"
- "hr"
- "img[tout attribut] "
- "ins"
- "kbd"
- "li[text-align]"
- "ol"
- "p[text-align]"
- "pre[text-align]"
- "q"
- "s"
- "samp"
- "small"
- "span[font-family, font-size, color, background-color]"
- "strong"
- "sub"
- "sup"
- "table[width, height, border-collapse, border-style, background-color]"
- "tbody"
- "td[width, height, border-color, background-color, white-space, vertical-align, text-align, text-align]"
- "tfoot"
- "th[width, height, border-color, background-color, white-space, vertical-align, text-align, text-align]"
- "thead"
- "tr"
- "tt"
- "u"
- "ul[list-style-type]"
- "var"
-
Full:
Figure 37. toolbar Full
Les balises et attributs autorisés sont :
- "a[tout attribut] "
- "address"
- "big"
- "blockquote"
- "br"
- "caption[text-align]"
- "cite"
- "code"
- "del"
- "div[text-align, padding, background, border]"
- "em"
- "h1[text-align]"
- "h2[text-align, font-style]"
- "h3[text-align, color, font-style]"
- "h4[text-align]"
- "h5[text-align]"
- "h6[text-align]"
- "hr"
- "img[tout attribut] "
- "ins"
- "kbd"
- "li[text-align]"
- "ol"
- "p[text-align]"
- "pre[text-align]"
- "q"
- "s"
- "samp"
- "small"
- "span[font-family, font-size, color, background-color]"
- "strong"
- "sub"
- "sup"
- "table[width, height, border-collapse, border-style, background-color]"
- "tbody"
- "td[width, height, border-color, background-color, white-space, vertical-align, text-align, text-align]"
- "tfoot"
- "th[width, height, border-color, background-color, white-space, vertical-align, text-align, text-align]"
- "thead"
- "tr"
- "tt"
- "u"
- "ul[list-style-type]"
- "var"
Pour les toolbars qui comportent le bouton "insérer une image", le widget permet d'insérer des documents "image" déjà enregistrés sur le serveur. Il permet aussi d'ajouter de nouvelles images si le droit "créer" sur la famille "image" (nom logique :
IMAGE) est donné à l'utilisateur. Les nouvelles images créées n'ont pas de profilage particulier et peuvent être réutilisées par d'autres utilisateurs. -
- toolbarexpand
-
Indique si la barre de menu doit être dépliée lors de l'affichage de l'éditeur. Dans le cas contraire, un petit bouton permet de la déplier.
Les valeurs possibles sont :
yes(comportement par défaut)no
4.2.14 Type idoc
Document intégré. Obsolète
4.2.15 Type ifile
permet d'intégrer directement la visualisation d'un fichier. Obsolète (préférer une vue d'attribut lorsque nécessaire)
En consultation, cet attribut sera représenté par une iframe affichant le fichier en mode inline.
4.2.16 Type image
4.2.16.1 Description
Les attributs de type image permettent d'insérer une image.
4.2.16.2 Représentation
-
consultation :
une balise
imgalignée à droite.L'image affichée par défaut est une miniature de l'image (sauf si l'option iwidth=auto) au format
Figure 38. image - consultation html
png.
3.2.20 Dans le cas d'imagejpeg, la miniature est réorientée automatiquement en fonction des données exif de l'image. Par contre, si c'est l'image originale qui est affichée, elle n'est pas réorientée par le navigateur.
Les navigateurs (pour l'instant) ne tiennent pas compte de l'orientation dans les tagsimagemais seulement lors de l'affichage direct sur une page. -
modification :
Un
inputde typetextprésentant une miniature de l'image précédemment enregistrée et le nom du fichier, suivi de 3 boutons :- pour choisir un nouveau fichier image,
- restaurer le fichier préalablement enregistré,
- effacer le fichier image.

Figure 39. image - Modification html
Au survol de la miniature, une version plus grande est affichée.
S'il s'agit d'une modification de document et que le fichier est déjà enregistré alors le clic sur le nom du fichier permet de télécharger l'image.
Des différences de comportement sont présentes en fonction des navigateur. Sur IE < 11, le bouton original "Parcourir" est affiché lorsqu'on clique sur le bouton "...". Le paramètre applicatif "FDL_OLDFILEINPUTCOMPAT" indique si l'attribut doit présenter, de manière systématique, le bouton original "Parcourir"

Figure 40. image - Modification html
-
odt :
Une image.

Figure 41. image - consultation odt
4.2.16.3 Comportement
Lors de l'upload du fichier, il est enregistré dans le vault.
4.2.16.4 Format de stockage
La valeur stockée est l’identifiant vault du fichier (sous la forme <type-mime>|<vaultid>|<file-title>).
Le type utilisé en base de donnée est text.
4.2.16.5 Options
En plus des options communes à tous les types d'attributs, ce type d'attribut dispose des options suivantes :
- hideindav
-
Indique si le fichier apparaît lors de l'accès au moyen du protocole webdav.
Les valeurs possibles sont :
yes(comportement par défaut)no
- inline
-
Indique si l'image' doit être consultée directement dans le navigateur. Dans le cas contraire, le téléchargement est forcé.
Les valeurs possibles sont :
yesno(comportement par défaut)
- iwidth
-
Indique la largeur de l'image dans l'interface web de consultation.
L'image est redimensionnée coté serveur, avec respect des proportions.
Les valeurs possibles sont:
- Une taille en pixels (par exemple
150px). -
auto(dans ce cas, l'image est affichée dans sa taille originale).
La valeur par défaut est
80px. - Une taille en pixels (par exemple
- preventfilechange
-
Ajoute une contrainte pour que le fichier à remplacer provienne de la dernière version du serveur.
Cela ne bloque pas un changement de fichier mais avertit l'utilisateur dans le cas où le fichier ne correspond pas à cette dernière version.
Lors du téléchargement du fichier un code identifiant la version est ajouté dans le nom du fichier (exemple foo{i47307-56}.ods pour le fichier foo.ods). Lorsque l'utilisateur uploade à nouveau le fichier, le serveur vérifie ce numéro de version. Si le numéro correspond à la dernière version, alors le fichier est accepté. Dans le cas contraire, une confirmation est demandée à l'utilisateur.
Attention: si l'utilisateur renomme le fichier, la vérification échoue, et le serveur demande la confirmation.
Les valeurs possibles sont :
yesno(comportement par défaut)
- rn
-
Indique que le fichier sera renommé sur le serveur.
Les valeurs possibles sont :
- un nom de méthode de la famille courante (par exemple
::myNewName()). La méthode prend en entrée le nom du fichier et doit retourner le nouveau nom sous la forme d'une chaîne de caractères.
Note: Il est recommandé que la méthode fournisse une extension compatible avec le type mime pour l'utilisation ultérieure sur le poste client et les transformations. Pour récupérer l'extension d'un nom de fichier vous pouvez utiliser la fonction
getFileExtensionde la librairieLib.FileMime.php - un nom de méthode de la famille courante (par exemple
4.2.17 Type int
4.2.17.1 Description
Les attributs de type int permettent d'insérer un nombre entier sur 32 bits signés.
4.2.17.2 Représentation
-
consultation :
Le nombre, sans formatage.

Figure 42. integer - consultation html
Le formatage spécifique de int doit être conforme à celui utilisé dans la fonction sprintf. Par exemple
int("%03d")pour avoir 3 chiffres. -
modification :
Un input de type texte permettant de saisir le nombre.

Figure 43. integer - Modification html
-
odt :
Le nombre, sans formatage

Figure 44. integer - consultation odt
4.2.17.3 Comportement
3.2.18
Lors de la sauvegarde, les vérifications suivantes sont faites :
- Le nombre est un entier compris entre -2 147 483 648 et +2 147 483 647
4.2.17.4 Format de stockage
La valeur stockée est la valeur brute du nombre.
Le type utilisé en base de donnée est int.
Si l'attribut est dans un tableau, le type en base donnée sera text.
4.2.17.5 Options
Options communes à tous les types d'attributs.
- elabel
-
En plus du tooltip du label défini par les options communes pour
elabel, Cette option affecte sa valeur sur l'attributtitledu l'inputcorrespondant.Les valeurs possibles sont :
- Toute chaîne de caractères. Attention, la plupart des navigateurs n'acceptent pas de retour chariot.
4.2.18 Type longtext
4.2.18.1 Description
Les attributs de type longtext permettent de saisir du texte multilignes, sans mise en forme.
4.2.18.2 Représentation
-
consultation :
La valeur brute.

Figure 45. longtext - consultation html
-
modification :
Un textarea.

Figure 46. longtext - Modification html
-
odt :
La valeur brute.

Figure 47. longtext - consultation odt
4.2.18.3 Comportement
Si un longtext est déclaré dans un tableau, les caractères <BR> sont remplacés par le caractère retour chariot \n lors de l'enregistrement.
4.2.18.4 Format de stockage
La valeur stockée est la valeur brute.
Le type utilisé en base de donnée est text.
4.2.18.5 Options
En plus des options communes à tous les types d'attributs, ce type d'attribut dispose des options suivantes :
- editheight
-
Indique la hauteur du
textareacorrespondant.Les valeurs possibles sont :
- une taille css valide (par exemple
400px)
La valeur par défaut est
2em - une taille css valide (par exemple
- elabel
-
En plus du tooltip du label défini par les options communes pour
elabel, Cette option affecte sa valeur sur l'attributtitledutextareacorrespondant.Les valeurs possibles sont :
- Toute chaîne de caractères. Attention, la plupart des navigateurs n'acceptent pas de retour chariot.
4.2.19 Type menu
4.2.19.1 Description
Les attributs de type menu se présentent sous la forme de liens présent dans la barre de menu en haut du document.
Ces menus permettent d'accéder à des urls, et ainsi de déclencher des actions, etc.
L'url du menu est indiqué dans la caractéristique link.
Cette caractéristique supporte, en plus des notations standards, la notation :
::myMethod()
Cette notation permet d'appeler directement une méthode exposée de la famille. L'appel de cette méthode retourne la page de consultation de document mis à jour.
La méthode appelée doit avoit le tag @apiExpose dans le commentaire associée
afin de la rendre exposable. Cette méthode doit assurer elle-même les contrôles
nécessaires à la sécurité du document.
4.2.19.2 Représentation
-
consultation :
Une entrée de menu supplémentaire.

Figure 48. menu - consultation html
-
modification :
Aucune représentation.
-
odt :
Aucune représentation.
4.2.19.3 Comportement
Le menu n'est pas représenté dans les cas suivants:
- link est vide,
- la visibilité est
H, - le menu référence des attributs au moyen de la syntaxe <attrid> et un de ces attributs est vide (cela peut être contourné par l'utilisation de la syntaxe ?<attrid>).
4.2.19.4 Format de stockage
Cet attribut n'est pas stocké.
4.2.19.5 Visibilité
Le menu est soumis à la visibilité standard.
Si la visibilité est H, ou si l'url est vide le menu n'est pas affiché.
Si le champ phpfunc indique une méthode, alors cette méthode sera utilisé pour avoir la visibilité du menu. Cette méthode outrepasse la visibilité indiqué dans l'attribut ou le masque. La méthode doit retourner une des constantes suivantes :
-
MENU_ACTIVE: Le menu est visible et actif (cliquable) -
MENU_INVISIBLE: Le menu n'est pas visible -
MENU_INACTIVE: Le menu est visible mais il est inhibé (grisé)
Exemple :
Utilisation de la fonction ::menuResetLoginFailure() déclarée dans la colonne
phpfunc :
class myFamily extends \Dcp\Family\Document public function menuResetLoginFailure() { // Do not show the menu if the user has no edit rights on the document if ($this->canEdit() != '') { return MENU_INACTIVE; } // Do not show the menu on the 'admin' user if ($this->getRawValue('us_whatid') == 1) { return MENU_INVISIBLE; } // Do not show the menu if the account has no failures if ($this->getRawValue("us_loginfailure") <= 0) { return MENU_INVISIBLE; } return MENU_ACTIVE; } }
4.2.19.6 Options
En plus des options communes à tous les types d'attributs, ce type d'attribut dispose des options suivantes :
- barmenu
-
Indique que la popup doit s'ouvrir avec la barre de menus du navigateur.
Les valeurs possibles sont :
yesno(comportement par défaut)
- global
-
Indique que l'action effectuée par le menu n'est pas liée à un document en particulier.
Dans ce cas, le menu apparaît aussi dans le menu 'outils' des applications issues de GENERIC, ainsi que dans le menu contextuel du document famille.
Les valeurs possibles sont :
yesno(comportement par défaut)
- lconfirm
-
Indique qu'une confirmation doit être demandée avant activation du lien.
Le texte de la confirmation est déterminé par l'option tconfirm.
Les valeurs possibles sont :
yesno(comportement par défaut)
- lcontrol
-
Indique que le menu est disponible uniquement dans le menu contextuel du document, lorsque la touche control est appuyée.
Les valeurs possibles sont :
yesno(comportement par défaut)
- mheight
-
Indique la hauteur de la fenêtre popup.
Les valeurs possibles sont :
- toute hauteur en pixels (par exemple
400px)
La valeur par défaut est
300px - toute hauteur en pixels (par exemple
- mtarget
-
Indique le name de la fenêtre cible de l'hyperlien.
Les valeurs possibles sont :
-
_blank(comportement par défaut) : Dans ce cas, la fenêtre cible est une nouvelle fenêtre ; -
_self: Dans ce cas, la fenêtre cible est la fenêtre en cours ; -
fhidden: Dans ce cas, la fenêtre cible est une fenêtre cachée ; -
fdoc: Dans l'application ONEFAM, la fenêtre cible est la fenêtre dans laquelle est affiché le document (utile pour les menus avec l'option global) ; - tout nom de fenêtre valide.
-
- mwidth
-
Indique la largeur de la fenêtre popup.
Les valeurs possibles sont :
- toute largeur en pixels (par exemple
400px)
La valeur par défaut est
400px - toute largeur en pixels (par exemple
- onlyglobal
-
Utilisé conjointement avec l'option global, indique que le menu ne doit pas apparaître sur le document.
Les valeurs possibles sont :
yesno(comportement par défaut)
- submenu
-
Indique que le menu doit avoir un menu parent.
Les valeurs possibles sont :
- toute chaîne alphanumérique.
- tconfirm
-
Indique la question apparaissant pour la confirmation (ce doit être une question fermée).
Cette question est automatiquement ajoutée au catalogue de traduction.
Les valeurs possibles sont :
- toute chaîne de caractères.
La valeur par défaut est
Êtes-vous sûr ?
4.2.20 Type money
4.2.20.1 Description
Permet de représenter un format monétaire.
4.2.20.2 Représentation
-
consultation :
Le nombre, formaté au moyen de la fonction
money_format('%!.2n', …).
Figure 49. money - consultation html
Le formatage spécifique de money doit être conforme à celui utilisé dans la fonction sprintf. Par contre, il faut utiliser
%set non%fcar le résultat donné à la fonction de formatage est ce qui est produit par money_format.Par exemple
money("%s €")pour ajouter la devise de l'euro. -
modification :
un input de type texte permettant de saisir le nombre.

Figure 50. money - Modification html
-
odt :
Le nombre, formaté au moyen de la fonction
money_format('%!.2n', ).
Figure 51. money - consultation odt
4.2.20.3 Comportement
Lors de l'enregistrement, le nettoyage suivant est effectué :
- remplacement des
,par. - suppression des espaces
La valeur nettoyée est validée au moyen de la fonction is_numeric.
4.2.20.4 Format de stockage
La valeur stockée est la valeur nettoyée.
Le type utilisé en base de donnée est double.
4.2.20.5 Options
En plus des options communes à tous les types d'attributs, ce type d'attribut dispose des options suivantes :
4.2.21 Type password
4.2.21.1 Description
Les attributs de type password permettent d'insérer des valeurs sans en dévoiler le contenu.
4.2.21.2 Représentation
-
consultation :
3.2.19La valeur du mot de passe est remplacée par 5 étoiles.

Figure 52. password - consultation html
-
modification :
Un
inputde typepassword. Le mot de passe n'est pas indiqué même s'il est déjà renseigné.
Figure 53. password - Modification html
-
odt :
Aucune représentation
4.2.21.3 Comportement
En édition, le champ password est systématiquement présenté vide. Lors de la sauvegarde, si la valeur est vide, alors l'ancienne valeur est conservée. Pour l'effacer, il faut mettre un seul caractère espace dans le champ.
4.2.21.4 Format de stockage
La valeur stockée est la valeur brute.
Le type utilisé en base de donnée est text.
4.2.21.5 Options
Options communes à tous les types d'attributs.
Ce type d'attribut ne dispose d'aucune option spécifique.
4.2.22 Type tab
4.2.22.1 Description
Les attributs de type tab permettent de créer des onglets.
4.2.22.2 Représentation
-
consultation :
Un onglet.

Figure 54. tab - consultation html
Note : Lors de l'impression d'un document, les onglets sont présentés comme des titres de paragraphes.
-
modification :
Un onglet.

Figure 55. tab - Modification html
-
odt :
Aucune représentation
4.2.22.3 Comportement
Aucun comportement particulier.
4.2.22.4 Format de stockage
Cet attribut n'est pas stocké.
4.2.22.5 Options
En plus des options communes à tous les types d'attributs, ce type d'attribut dispose des options suivantes :
- viewonfly
-
Indique que le contenu du tab est chargé en ajax lorsque l'utilisateur clique sur l'onglet. Cela réduit le temps de réponse pour les documents ayant de très nombreux attributs (plusieurs centaines).
Cela n'est applicable que pour les vues utilisant la zone FDL:VIEWBODYCARD. Les actions utilisant cette zone sont :
- FDL:FDL_CARD,
- FDL:IMPCARD,
- FDL:OPENDOC,
- FDL:VIEWEXTDOC.
Les valeurs possibles sont :
yesno(comportement par défaut)
- firstopen
-
Indique que cet onglet doit être sélectionné à l'ouverture du document.
Cela n'est applicable que pour les vues utilisant les zones FDL:VIEWBODYCARD et FDL:EDITBODYCARD. Les actions utilisant cette zone sont :
- FDL:FDL_CARD,
- FDL:IMPCARD,
- FDL:OPENDOC,
- FDL:VIEWEXTDOC,
- *GENERIC:GENER
Les valeurs possibles sont :
yesno(comportement par défaut)
4.2.23 Type text
4.2.23.1 Description
Les attributs de type text permettent d'insérer du texte simple, sur une seule ligne.
4.2.23.2 Représentation
-
consultation :
La valeur brute.

Figure 56. text - consultation html
-
modification :
un
inputde typetext.
Figure 57. text - Modification html
-
odt :
La valeur brute.

Figure 58. text - consultation odt
4.2.23.3 Comportement
Lors de la sauvegarde, la valeur est nettoyée :
- le caractère "\r" est remplacé par " " (espace).
4.2.23.4 Format de stockage
La valeur stockée est la valeur nettoyée.
Le type utilisé en base de donnée est text.
4.2.23.5 Options
En plus des options communes à tous les types d'attributs, ce type d'attribut dispose des options suivantes :
- elabel
-
En plus du tooltip du label défini par les options communes pour
elabel, cette option affecte sa valeur sur l'attributtitlede l'inputcorrespondant.Les valeurs possibles sont :
- Toute chaîne de caractères. Attention, la plupart des navigateurs n'acceptent pas de retour chariot.
- esize
-
Valeur de l'attribut
@sizede l'inputcorrespondant.Les valeurs possibles sont :
- Toute valeur entière.
4.2.24 Type thésaurus
4.2.24.1 Description
Les attributs de type thesaurus permettent de faire des relations vers des descripteurs de thésaurus.
Ce type d'attribut est à utiliser avec le module dynacase-thesaurus.
4.2.24.2 Représentation
- consultation :
Identique au type `docid`.
- modification :
une aide à la saisie indiquant une arborescence vers les descripteurs de thésaurus.
4.2.24.3 Comportement
4.2.24.4 Format de stockage
La valeur stockée est l'identifiant interne du descripteur.
Le type utilisé en base de donnée est text.
4.2.24.5 Options
Options communes à tous les types d'attributs.
Ce type d'attribut ne dispose d'aucune option spécifique.
4.2.25 Type time
4.2.25.1 Description
Les attributs de type time permettent d'insérer une heure.
4.2.25.2 Représentation
-
consultation :
La valeur brute.

Figure 59. time - consultation html
L'heure peut avoir un format particulier en utilisant la notation de [strftime][PHP_strftime].
Exemple : `date("%H heures %M minutes %S secondes")` pour afficher
`15 heures 23 minutes 04 secondes`
-
modification :
2 inputs de type text, séparés par le symbole :. Du javascript transforme les entrées pour en faire des heures valides (les nombres sont remplacés par leur modulo respectif avec 24 et 60, et les autres valeurs sont remplacées par 00).

Figure 60. time - modification time
-
odt :
La valeur brute.

Figure 61. time - consultation odt
4.2.25.3 Comportement
Lors de la sauvegarde, l'heure doit être comprise entre 0 et 23, les minutes entre 0 et 59 et les secondes facultatives entre 0 et 59.
La valeur est vérifiée, et doit correspondre à un des formats suivants :
- .\d\d?:.\d\d?
- .\d\d?:.\d\d?:.\d\d?
4.2.25.4 Format de stockage
La valeur stockée est la valeur nettoyée.
Le type utilisé en base de donnée est time.
Si l'attribut est dans un tableau, le type en base donnée sera text.
4.2.25.5 Options
En plus des options communes à tous les types d'attributs, ce type d'attribut dispose des options suivantes :
4.2.26 Type timestamp
4.2.26.1 Description
Les attributs de type timestamp permettent d'insérer une date et heure.
4.2.26.2 Représentation
-
consultation :
La date et heure formatée en accord avec la locale de l'utilisateur.

Figure 62. timestamp - consultation html
La date peut avoir un format particulier en utilisant la notation de [strftime][PHP_strftime].
Exemple : `date("%A %e %B %y à %H heures %M minutes")` pour afficher
`vendredi 17 mai 2013 à 15 heures 23 minutes`
-
modification :
date picker avec possibilité de définir l'heure.

Figure 63. timestamp - Modification html
-
odt :
La date et heure formatée en accord avec la locale de l'utilisateur.

Figure 64. timestamp - consultation odt
4.2.26.3 Comportement
Lors de la saisie, la valeur est validée, c'est à dire que le format doit être :
- soit au format « français » ;
- soit au format « US » ;
- soit au format ISO8601.
4.2.26.4 Format de stockage
La date est stockée au format ISO8601 « sans T » (yyyy-mm-dd hh:mm:ss).
Le type utilisé en base de donnée est timestamp without timezone.
Si l'attribut est dans un tableau, le type en base donnée sera text.
4.2.26.5 Options
options communes à tous les types d'attributs.
Ce type d'attribut ne dispose d'aucune option spécifique.
4.2.27 type xml
4.2.27.1 Description
Le type *XML n'est utilisable que pour des besoins internes de core. Seule la famille "SEARCH" l'utilise.
4.2.27.2 Représentation
Les attributs de type xml sont représentés comme du texte simple.
Le type utilisé en base de donnée est text.
4.2.27.3 Options
Options communes à tous les types d'attributs.
Ce type d'attribut ne dispose d'aucune option spécifique.
4.3 Visibilité des attributs
La visibilité d'un attribut est une caractéristique de présentation de sa valeur.
Seule la visibilité I permet d'ajouter un contrôle d'accès à la valeur. Les
autres visibilités ne contrôle pas l'accès mais seulement la présentation de la
valeur.
Les différentes visibilités disponibles sont les suivantes :
H- Attribut caché : présent dans la dom, il ne sera pas affiché.
I- Attribut invisible : cet attribut n'est accessible ni par l'IHM, ni par le code (pour le modifier par le code, il faut au préalable modifier explicitement sa visibilité). Cette visibilité est utilisée pour les importations, exportations et le format de collection de document.
O- Attribut visible en modification uniquement, et modifiable.
R- Attribut visible uniquement en consultation.
S- Attribut visible en consultation et en modification, mais non modifiable.
-
U(applicable uniquement au type array) - Array affiché en consultation et en modification, mais dont le nombre de lignes ne peut pas être modifié.
W- Attribut visible en consultation et en modification, et modifiable
| Visibilité | Mode | Visible sur la page | Présent dans la DOM | Modifiable par requête |
|---|---|---|---|---|
H |
Consultation | Non | Non | |
I |
Non | Non | ||
R |
Oui | Oui | ||
W |
Oui | Oui | ||
O |
Non | Non | ||
S |
Oui | Oui | ||
H |
Édition | Non | Oui | Oui |
I |
Non | Non | Non | |
R |
Non | Oui | Oui | |
W |
Oui | Oui | Oui | |
O |
Oui | Oui | Oui | |
S |
Oui | Oui | Oui |
Il est important de distinguer la visibilité et les droits :
La visibilité n'offre pas de protection contre l'accès à l'information
sauf pour la visibilité I.
4.3.1 Visibilité des attributs structurants
Les visibilités des attributs structurants impactent celle des attributs qu'ils
contiennent. Ainsi, par exemple, un attribut W dans un cadre H sera en fait
en H. Voici la table qui récapitule ces cas :
| Attribut structurant | Attribut | Visibilité résultante |
|---|---|---|
H |
H |
H |
H |
I |
I |
H |
O |
H |
H |
R |
H |
H |
S |
H |
H |
U |
H |
H |
W |
H |
I |
H |
I |
I |
I |
I |
I |
O |
I |
I |
R |
I |
I |
S |
I |
I |
U |
I |
I |
W |
I |
O |
H |
H |
O |
I |
I |
O |
O |
O |
O |
R |
R |
O |
S |
S |
O |
U |
U |
O |
W |
O |
R |
H |
H |
R |
I |
I |
R |
O |
R |
R |
R |
R |
R |
S |
R |
R |
U |
R |
R |
W |
R |
S |
H |
H |
S |
I |
I |
S |
O |
O |
S |
R |
R |
S |
S |
S |
S |
U |
U |
S |
W |
S |
W |
H |
H |
W |
I |
I |
W |
O |
O |
W |
R |
R |
W |
S |
S |
W |
U |
U |
W |
W |
W |
Les tableaux en visibilité U sont transparents lors de cette propagation.
Pour les attributs contenus dans un tableau en visibilité U, il faut donc
regarder l'attribut structurant du-dit tableau.
4.4 Les paramètres de famille
4.4.1 Présentation
Un paramètre de famille est une valeur stockée sur la famille directement, et accessible depuis tous les documents de cette famille.
Ils sont assimilables à des propriétés de classe (ou propriétés statiques) en programmation orientée objet, même si l'implémentation en diffère.
Ils peuvent être soumis à des contraintes. Dans ce cas, la méthode doit être statique.
Un paramètre de famille peut également être dynamique, lorsqu'il est défini par une méthode statique. Dans ce cas, la méthode doit être statique et sera lancée à chaque récupération du paramètre.
4.4.2 Exemple d'utilisation
Imaginons que l'on veuille calculer une référence unique pour tous les documents de la famille compte-rendu. Cette référence doit être sous la forme [PREFIXE] - [chrono] où [PREFIXE] est un préfixe commun à tous les documents, et [chrono] est un numéro chrono (incrémenté de 1 à chaque nouveau document).
Le préfixe étant commun à tous les documents, on le stockera sous la forme d'un paramètre de famille. Cela évite de devoir le stocker dans le code, ce qui rend ce préfixe paramétrable sans redéploiement.
4.5 Les attributs calculés
4.5.1 Présentation
Un attribut calculé est un attribut dont la valeur est calculée par Dynacase.
Ce calcul est effectué à chaque appel de la méthode Doc::refresh(), qui est
appelée très fréquemment sur les documents. Dans de nombreux cas, il sera
préférable d'utiliser les hooks du document (en particulier
Doc::postStore).
Le calcul de l'attribut peut être
-
local
Par exemple : attr_c = attr_a * attr_b
-
global
Par exemple : attr_d = nombre de documents du même auteur
-
externe
Par exemple : attr_e = quantité en stock dans l'ERP
Ce calcul peut être effectué au moyen :
- d'une méthode publique de la classe du document contenant l'attribut,
- d'une méthode statique d'une autre classe.
Elle doit retourner un résultat sous forme d'une chaîne de caractères. Le résultat est mis dans l'attribut sur lequel s'applique le calcul (sauf redirection explicite faite lors de la déclaration de l'attribut).
Le calcul est effectué lors du rafraîchissement des documents (voir la méthode
Doc::refresh()).
Les attributs en visibilité I ne sont pas modifiés lors de l'actualisation.
Pour que ces attributs soit modifiés, il est nécessaire qu'un contrôle de vue
modifie cette visibilité pour l'utilisateur courant. Si l'attribut est en
visibilité I au moment du calcul, un message d'avertissement sera écrit dans
les logs système.
D'un point de vue utilisateur, un attribut calculé est rafraîchi avant chaque consultation de document.
4.5.2 Syntaxe
La syntaxe définissant les attributs calculés est la suivante :
Ce qui donne en BNF :
computeMethod ::= callMethod ( ( ':' targetAttributeName ) | )
callMethod ::= ( staticClass | ) '::' methodName '(' ( methodInputs | ) ')'
methodInputs ::= methodInput ( ',' methodInput )*
methodInput ::= '<spaces>'* ( sourceAttributeName | familyParameterName | text | keyWord ) '<spaces>'*
text ::= ( "'" '<text>' ) | ( "'" "[^',]+" "'" ) | ( '"' '[^",]+' '"' )
keyWord ::= 'THIS' | 'K'
avec les éléments suivants :
- targetAttributeName
-
Un nom d'attribut existant dans la famille.
Le résultat de la méthode sera affecté à cet attribut.
Si targetAttributeName n'est pas renseigné, alors c'est l'attribut sur lequel est définie la méthode de calcul qui reçoit la valeur.
- sourceAttributeName
-
Un nom d'attribut existant dans la famille.
La méthode de calcul recevra la valeur de l'attribut au moment de l'appel.
Lorsque attributeName est dans un array, alors la valeur passée est :
- la valeur sur la même ligne si l'attribut calculé est dans le même tableau
- la valeur de la colonne (sous la forme d'un tableau php) si l'attribut calculé est en dehors du tableau
- la valeur sur la même ligne si l'attribut est dans un autre tableau, ce qui peut conduire à des comportements surprenants.
- familyParametername
-
Un nom de paramètre existant dans la famille.
La fonction de calcul recevra la valeur du paramètre au moment de l'appel.
- keyWord
-
Un mot clé qui est remplacé par une valeur dynamique
- THIS
-
L'objet du document en cours.
Cela est utile dans le cas d'un appel à une méthode statique.
- K
-
L'index de la ligne en cours si l'attribut est dans un tableau.
Si l'attribut n'est pas dans un tableau, la valeur passée est
-1
4.5.3 Exemples
4.5.3.1 Calcul d'un prix total
Extrait de la définition de la famille
| attrid | label | type | visibility | phpfunc |
|---|---|---|---|---|
| article_qte | Quantité | int | W | |
| article_prix_unitaire | Prix unitaire | double | W | |
| article_prix_total | Prix total | R | ::computePrice(article_qte,article_prix_unitaire) |
Extrait du fichier de méthodes associé
public function computePrice($qte, $price){ return intval($qte) * floatval($price); }
Note: on pourrait aussi utiliser une méthode statique, qui aurait sûrement plus de sens ici :
| attrid | label | type | visibility | phpfunc |
|---|---|---|---|---|
| article_qte | Quantité | int | W | |
| article_prix_unitaire | Prix unitaire | double | W | |
| article_prix_total | Prix total | R | MathUtils::mult(article_qte,article_prix_unitaire) |
class MathUtils { public static function mult($a, $b){ return floatval($a) * floatval($b); } }
4.6 Les contraintes
4.6.1 Présentation
Une contrainte permet de valider la saisie de l'utilisateur avant que le document soit enregistré.
La contrainte est vérifiée au moyen :
- soit d'une méthode publique de la classe du document contenant l'attribut,
- soit d'une méthode statique d'une autre classe.
Son retour doit être :
- soit une chaîne de caractères utilisée comme message d'erreur,
- soit un tableau associatif contenant
- un message d'erreur à l'index
err - un tableau de suggestions à l'index
sug
- un message d'erreur à l'index
Les suggestions seront proposées à l'utilisateur en remplacement de la valeur refusée par la contrainte.
Les contraintes sont aussi vérifiées lors de l'appel à la méthode Doc::store().
Un paramètre optionnel à cette méthode permet de ne pas vérifier les contraintes.
4.6.2 Syntaxe
La syntaxe définissant les contraintes est la suivante :
Ce qui donne en BNF :
constraint ::= ( staticClass | ) '::' methodName '(' ( methodInputs | ) ')'
methodInputs ::= methodInput ( ',' methodInput )*
methodInput ::= '<spaces>'* ( sourceAttributeName | familyParameterName | text | keyWord ) '<spaces>'*
text ::= ( "'" '<text>' ) | ( "'" "[^',]+" "'" ) | ( '"' '[^",]+' '"' )
keyWord ::= 'THIS' | 'K'
avec les éléments suivants :
- sourceAttributeName
-
Un nom d'attribut existant dans la famille.
La méthode de la contrainte recevra la valeur de l'attribut au moment de l'appel.
Lorsque attributeName est dans un array, alors la valeur passée est :
- la valeur sur la même ligne si l'attribut sur lequel est définie la contrainte est dans le même tableau
- la valeur de la colonne (sous la forme d'un tableau php) si l'attribut sur lequel est définie la contrainte est en dehors du tableau
- la valeur sur la même ligne si l'attribut est dans un autre tableau, ce qui peut conduire à des comportements surprenants.
Lorsque attributeName est un attribut structurant (e.g.
array,frame, etc.), alors la valeur passée est une chaîne vide. - familyParametername
-
Un nom de paramètre existant dans la famille.
La contrainte recevra la valeur du paramètre au moment de l'appel.
- keyWord
-
Un mot clé qui est remplacé par une valeur dynamique
- THIS
-
L'objet du document en cours.
Cela est utile dans le cas d'un appel à une méthode statique.
- K
-
L'index de la ligne en cours si l'attribut est dans un tableau.
Si l'attribut n'est pas dans un tableau, la valeur passée est
-1
4.6.3 Exemples
4.6.3.1 Vérification du format d'un entier
| attrid | label | type | visibility | phpfunc |
|---|---|---|---|---|
| article_qte | Quantité | int | W | GenericConstraints::isInt(article_qte,10,100) |
<?php Class GenericConstraints{ public static function isInt($value, $min=0, $max=PHP_INT_MAX, $customErrorMessage=''){ $options = array( 'options' => array( 'min_range' => $min, 'max_range' => $max ); ); if(false === filter_var($value, FILTER_VALIDATE_INT, $options)){ if('' === $customErrorMessage){ $customErrorMessage = "GenericConstraints:%s is not an integer between %s and %s"; } return sprintf(_($customErrorMessage), $value, $min, $max); } return ''; } } ?>
4.7 Les aides à la saisie
4.7.1 Présentation
Une aide à la saisie permet de compléter ou de remplir des zones de saisie lors de la modification d'un document, en proposant des suggestions à l'utilisateur.
Les suggestions sont calculées au moyen d'une fonction qui doit être définie dans
un fichier php placé dans le répertoire /EXTERNALS/ du contexte.
Elle doit retourner un résultat sous la forme d'un tableau à 2 dimensions :
- la première dimension correspond à la liste des suggestions ;
-
la seconde dimension correspond à la liste des valeurs à insérer dans le document lors du choix de cette suggestion.
Elle est traitée de manière positionnelle :
- La première valeur est affichée en tant que suggestion pour l'utilisateur ;
- les valeurs suivantes sont dépilées et affectées dans l'ordre aux attributs cible.
Elle peut également retourner une chaîne de caractères, qui servira de message d'erreur.
4.7.2 Syntaxe
La syntaxe définissant les aides à la saisie est la suivante :
Ce qui donne en BNF :
inputHelp ::= funcName '(' ( funcInputs | ) ')' ':' funcOutputs
funcInputs ::= funcInput ( ',' funcInput )*
funcInput ::= '<spaces>'* ( sourceAttributeName | familyParameterName | text | sourceKeyWord | propertyName | '{' appParameterName '}' | '{' familyName '}' ) '<spaces>'*
funcOutputs ::= funcOutput ( ',' funcOutput )*
funcOutput ::= ( targetAttributeName | targetKeyWord )
text ::= ( "'" '<text>' ) | ( "'" "[^',]+" "'" ) | ( '"' '[^",]+' '"' )
sourceKeyWord ::= ( 'CT' | 'CT' '[' relationAttributeName ']' | 'D' | 'I' | 'K' | 'T' | 'A' )
targetKeyWord ::= ( 'CT' | 'CT' '[' relationAttributeName ']' )
avec les éléments suivants :
- sourceAttributeName
-
Un nom d'attribut existant dans la famille.
La fonction de calcul recevra la valeur de l'attribut au moment de l'appel.
Lorsque attributeName est dans un array, alors la valeur passée est :
- la valeur sur la même ligne si l'attribut sur lequel est définie l'aide à la saisie est dans le même tableau,
- la valeur de la colonne (sous la forme d'un tableau php) si l'attribut sur lequel est définie l'aide à la saisie est en dehors du tableau
- la valeur sur la même ligne si l'attribut est dans un autre tableau, ce qui peut conduire à des comportements surprenants.
- familyParametername
-
Un nom de paramètre existant dans la famille.
La fonction de calcul recevra la valeur du paramètre au moment de l'appel.
- sourceKeyWord
-
Un mot clé qui est remplacé par une valeur dynamique.
- CT[relationAttributeName]
-
La valeur de l'input correspondant à la relation relationAttributeName.
Lorsque l'id est rempli, cela correspond au titre du document cible, sinon cela correspond au texte saisi dans cet input.
- CT
-
Raccourci pour CT[currentAttributeName] (où currentAttributeName est le nom de l'attribut sur lequel est définie l'aide à la saisie).
Ne peut être utilisé que sur les attributs de type relation.
- D
- Accès à la base de données.
- I
- Id du document courant.
- K
-
L'index de la ligne en cours si l'attribut est dans un tableau.
Si l'attribut n'est pas dans un tableau, la valeur passée est
-1 - T
-
L'objet php correspondant au document en cours.
L'objet récupéré est le document tel qu'il est en base de donnée.
- A
-
L'action courante (un objet de la classe
Action).Cela permet, par exemple, de récupérer des informations sur l'utilisateur courant.
- propertyName
-
Une propriété du document.
Elle sera remplacée par sa valeur.
- appParameterName
-
Un paramètre applicatif.
Ce paramètre doit obligatoirement être global.
- familyName
-
Un nom logique de famille.
Il sera remplacé par son id.
- targetAttributeName
-
Un nom d'attribut existant dans la famille.
Lors du choix d'une des suggestions, les valeurs correspondant à ces suggestions sont insérées dans l'ordre dans les attributs désignés par targetAttributeName
- targetKeyWord
-
Un mot clé désignant la cible de l'aide à la saisie.
- CT[relationAttributeName]
- L'input correspondant à la relation relationAttributeName.
- CT
- Raccourci pour CT[currentAttributeName] (où *currentAttributeName est le nom de l'attribut sur lequel est définie l'aide à la saisie).
- ?
-
permet de "sauter" une des valeurs de retour sans l'utiliser.
Est particulièrement utile dans le cas d'aides à la saisie génériques qui retournent plus de valeurs que d'attributs à compléter.
4.7.3 Exemples
4.7.3.1 Retour unique
| attrid | label | type | visibility | phpfile | phpfunc |
|---|---|---|---|---|---|
| city_name | Ville | text | W | cities.php | getCities(city_name):city_name |
<?php /** * EXTERNALS/cities.php */ function getCities($userInput=''){ $suggestions = array(); // Liste des villes utilisables $availableCities = array( "Paris", "Toulouse", "Souillac" ); //teste si les villes correspondent à la saisie de l'utilisateur foreach($availableCities as $city){ if( ''===$userInput || preg_match(strToLower($userInput), strToLower($city)) ){ $suggestions[] = array( $city, //le nom de la suggestion $city //la valeur qui ira dans attr_city ); } } return $suggestions; } ?>
4.7.3.2 Retour multiple
| attrid | label | type | visibility | phpfile | phpfunc |
|---|---|---|---|---|---|
| city_name | Ville | text | W | cities.php |
getCities(city_name):city_name |
| city_cedex | Code postal | int | W | cities.php |
getCedex(city_cedex):city_cedex,city_name |
<?php /** * EXTERNALS/cities.php */ function getCedex($userInput=''){ $suggestions = array(); // Liste des villes utilisables $availableCities = array( "75000" => "Paris", "31000" => "Toulouse", "46200" => "Souillac" ); //teste si les villes correspondent à la saisie de l'utilisateur foreach($availableCities as $cedex => $city){ if( ''===$userInput || preg_match($userInput, $cedex) ){ $suggestions[] = array( sprintf("[%d] %s", $cedex, $city), //le nom de la suggestion $cedex, //la valeur qui ira dans attr_cedex $city //la valeur qui ira dans attr_city ); } } return $suggestions; } ?>
4.7.4 Astuces
4.7.4.1 attributs relation
- Lorsqu'une aide à la saisie remplit un attribut de type docid, il faut penser à remplir l'id et le titre affiché (attrid et CT[attrid]).
- Lorsqu'un attribut est masqué (visibilité R ou H), alors le champ désigné par CT[attrid] n'existe pas, il est donc impossible de les désigner comme retour des aides à la saisie.
4.7.4.2 attributs htmltext
- Lorsqu'un attribut de type htmltext est utilisé en entrée d'une aide à la saisie, la valeur reçue est encodée. il est donc nécessaire de la décoder (au moyen de html_entity_decode)
4.8 Déclaration de familles
4.8.1 Introduction
Pour ajouter des familles de document à Dynacase, on va utiliser divers formats de fichier :
- Les familles seront définies dans des fichiers csv ;
- Le code php sera à déployer dans des fichiers php, à intégrer à la plate-forme ;
- Les documents systèmes seront importés au moyen de fichiers csv ou xml.
4.8.2 Définition de familles
Les familles sont définies dans un fichier csv respectant le format suivant :
- Encodage : UTF-8,
- Délimiteur de texte :
(vide), - séparateur de colonnes :
;.
Exemple de définition d'une famille :
BEGIN;;Animal;;;ZOO_ANIMAL;;;;;;;;;;;
//;properties;;;;;;;;;;;;;;;
//propid;value;;;;;;;;;;;;;;;
ICON;zoo_animal.png;;;;
CLASS;Zoo\Zoo_animal;;;;
DFLDID;FLD_ZOO_ANIMAL;;;;
;;;;;;;;;;;;;;;;
//;attributes;;;;;;;;;;;;;;;
//;idattr;idframe;label;T;A;type;ord;vis;need;link;phpfile;phpfunc;elink;constraint;option;Commentaires
;;;;;;;;;;;;;;;;
ATTR;AN_IDENTIFICATION;;Identification;N;N;frame;::auto;W;;;;;;;;
ATTR;AN_NOM;AN_IDENTIFICATION;nom;Y;N;text;::auto;W;Y;;;;;;edittemplate=ZOO:ANIMALNAME:U|viewtemplate=ZOO:ANIMALNAME;
ATTR;AN_TATOUAGE;AN_IDENTIFICATION;tatouage;N;N;int;::auto;W;;;;;;;edittemplate=ZOO:ANIMALTATOO:S|viewtemplate=ZOO:ANIMALTATOO:S;
ATTR;AN_ESPECE;AN_IDENTIFICATION;espèce;N;N;docid("ZOO_ESPECE");::auto;W;Y;;;;;;creation={es_nom:CT}|doctitle=an_espece_title;
ATTR;AN_ESPECE_TITLE;AN_IDENTIFICATION;espèce (titre);Y;N;text;::auto;H;;;;::getTitle(an_espece);;;;
ATTR;AN_ORDRE;AN_IDENTIFICATION;ordre;N;N;text;::auto;R;;;;::getdocvalue(an_espece,es_ordre);;;;
ATTR;AN_CLASSE;AN_IDENTIFICATION;classe;N;N;docid("ZOO_CLASSE");::auto;R;;;;::getdocvalue( an_espece , es_classe);;;doctitle=auto;
ATTR;AN_SEXE;AN_IDENTIFICATION;sexe;N;N;enum;::auto;W;;;;M|Masculin,F|Féminin,H|Hermaphrodite;;;;
ATTR;AN_PHOTO;AN_IDENTIFICATION;photo;N;N;image;::auto;W;;;;;;;;
ATTR;AN_NAISSANCE;AN_IDENTIFICATION;date naissance;N;N;date;::auto;W;;;;;;::validatePastDate(AN_NAISSANCE);;
ATTR;AN_ENTREE;AN_IDENTIFICATION;date entree;N;N;date;::auto;W;;;;;;::validatePastDate(AN_ENTREE);;
ATTR;AN_ENFANT_T;AN_IDENTIFICATION;liste enfant;N;N;array;::auto;W;;;;;;;;
ATTR;AN_ENFANT;AN_ENFANT_T;enfant;N;N;docid("ZOO_ANIMAL");::auto;W;;;;;;;creation={an_nom:CT,an_espece:an_espece};
ATTR;AN_CARNETSANTE;AN_IDENTIFICATION;Carnet Santé;N;N;menu;::auto;W;;%S%app=GENERIC&action=GENERIC_ISEARCH&id=%I%&famid=ZOO_CARNETSANTE&viewone=Y;;;;;;
ATTR;AN_ENCLOS;AN_IDENTIFICATION;Enclos;N;N;menu;::auto;W;;%S%app=GENERIC&action=GENERIC_ISEARCH&id=%I%&famid=ZOO_ENCLOS&viewone=Y;;;;;;
ATTR;AN_PARENT;AN_IDENTIFICATION;Parents;N;N;menu;::auto;W;;%S%app=GENERIC&action=GENERIC_ISEARCH&generic=Y&id=%I%&famid=ZOO_ANIMAL;;;;;;
ATTR;AN_PERE;AN_IDENTIFICATION;pere;N;Y;docid("ZOO_ANIMAL");::auto;R;;;;::getAscendant(M);;;doctitle=auto
ATTR;AN_MERE;AN_IDENTIFICATION;mere;N;Y;docid("ZOO_ANIMAL");::auto;R;;;;::getAscendant(F);;;doctitle=auto
ATTR;AN_FOLDER;;Dossier;N;N;menu;::auto;W;;%S%app=ZOO&action=ZOO_ANIMALFOLDER&id=%I%;;;;;
;;;;;;;;;;;;;;;;
END;;;;;;;;;;;;;;;;
Note : Le format ODS (openDocument Spread Sheet) peut aussi être utilisé
comme format de fichier d'importation de famille ou de document.
Ce qui donne, vu dans un tableau :
| BEGIN | Animal | ZOO_ANIMAL | ||||||||||||||||
| // | properties | |||||||||||||||||
| //propid | value | |||||||||||||||||
| ICON | zoo_animal.png | |||||||||||||||||
| CLASS | Zoo\Zoo_animal | |||||||||||||||||
| DFLDID | FLD_ZOO_ANIMAL | |||||||||||||||||
| // | attributes | |||||||||||||||||
| // | idattr | idframe | label | T | A | type | ord | vis | need | link | phpfile | phpfunc | elink | constraint | option | Commentaires | ||
| ATTR | AN_IDENTIFICATION | Identification | N | N | frame | ::auto | W | |||||||||||
| ATTR | AN_NOM | AN_IDENTIFICATION | nom | Y | N | text | ::auto | W | Y | edittemplate=ZOO:ANIMALNAME:U | viewtemplate=ZOO:ANIMALNAME | |||||||
| ATTR | AN_TATOUAGE | AN_IDENTIFICATION | tatouage | N | N | int | ::auto | W | edittemplate=ZOO:ANIMALTATOO:S | viewtemplate=ZOO:ANIMALTATOO:S | ||||||||
| ATTR | AN_ESPECE | AN_IDENTIFICATION | espèce | N | N | docid("ZOO_ESPECE") | ::auto | W | Y | creation={es_nom:CT} | doctitle=an_espece_title | |||||||
| ATTR | AN_ESPECE_TITLE | AN_IDENTIFICATION | espèce (titre) | Y | N | text | ::auto | H | ::getTitle(an_espece) | |||||||||
| ATTR | AN_ORDRE | AN_IDENTIFICATION | ordre | N | N | text | ::auto | R | ::getdocvalue(an_espece,es_ordre) | |||||||||
| ATTR | AN_CLASSE | AN_IDENTIFICATION | classe | N | N | docid("ZOO_CLASSE") | ::auto | R | ::getdocvalue( an_espece , es_classe) | doctitle=auto | ||||||||
| ATTR | AN_SEXE | AN_IDENTIFICATION | sexe | N | N | enum | ::auto | W | M|Masculin,F|Féminin,H|Hermaphrodite | |||||||||
| ATTR | AN_PHOTO | AN_IDENTIFICATION | photo | N | N | image | ::auto | W | ||||||||||
| ATTR | AN_NAISSANCE | AN_IDENTIFICATION | date naissance | N | N | date | ::auto | W | ::validatePastDate(AN_NAISSANCE) | |||||||||
| ATTR | AN_ENTREE | AN_IDENTIFICATION | date entree | N | N | date | ::auto | W | ::validatePastDate(AN_ENTREE) | |||||||||
| ATTR | AN_ENFANT_T | AN_IDENTIFICATION | liste enfant | N | N | array | ::auto | W | ||||||||||
| ATTR | AN_ENFANT | AN_ENFANT_T | enfant | N | N | docid("ZOO_ANIMAL") | ::auto | W | creation={an_nom:CT,an_espece:an_espece} | |||||||||
| ATTR | AN_CARNETSANTE | AN_IDENTIFICATION | Carnet Santé | N | N | menu | ::auto | W | %S%app=GENERIC&action=GENERIC_ISEARCH&id=%I%&famid=ZOO_CARNETSANTE&viewone=Y | |||||||||
| ATTR | AN_ENCLOS | AN_IDENTIFICATION | Enclos | N | N | menu | ::auto | W | %S%app=GENERIC&action=GENERIC_ISEARCH&id=%I%&famid=ZOO_ENCLOS&viewone=Y | |||||||||
| ATTR | AN_PARENT | AN_IDENTIFICATION | Parents | N | N | menu | ::auto | W | %S%app=GENERIC&action=GENERIC_ISEARCH&generic=Y&id=%I%&famid=ZOO_ANIMAL | |||||||||
| ATTR | AN_PERE | AN_IDENTIFICATION | pere | N | Y | docid("ZOO_ANIMAL") | ::auto | R | ::getAscendant(M) | doctitle=auto | ||||||||
| ATTR | AN_MERE | AN_IDENTIFICATION | mere | N | Y | docid("ZOO_ANIMAL") | ::auto | R | ::getAscendant(F) | doctitle=auto | ||||||||
| ATTR | AN_FOLDER | Dossier | N | N | menu | ::auto | W | %S%app=ZOO&action=ZOO_ANIMALFOLDER&id=%I% | ||||||||||
| END |
La définition d'une famille commence toujours par une ligne de la forme :
BEGIN;[fromid];[title];[id];[className];[logicalName]
et se termine toujours par une ligne de la forme :
END;
avec les correspondances suivantes:
- BEGIN
- Obligatoire, signale le début d'une définition de famille.
- [fromid]
-
Identifiant logique (nom logique ou identifiant interne numérique) de la famille de laquelle cette famille hérite.
Laisser vide s'il n'y a pas d'héritage.
L'utilisation d'un identifiant interne numérique à la place d'un nom logique est à réserver aux familles de core.
- [title]
-
Titre de la famille.
Ce titre est utilisé sur les IHM pour désigner la famille.
Il est automatiquement ajouté au catalogue de traduction, et peut ainsi être traduit.
- [id]
-
Identifiant numérique de la famille.
Laisser vide pour utiliser un identifiant logique (Dans ce cas, Dynacase affectera automatiquement un identifiant interne unique à la famille).
S'il est renseigné, il faut que cet identifiant ne soit pas déjà pris par un autre document.
Les valeurs entre 900 et 999 peuvent être utilisée pour vos besoins spécifiques, bien que l'usage de valeurs numériques fixes soit fortement déconseillée.
- [className] (déprécié)
-
Nom de la classe PHP utilisée pour cette famille.
Cette classe doit être présente sur le serveur dans un fichier appelé
/FDL/Class.[CLASSNAME].php.Permet un héritage autre que celui prévu par défaut par les classes documentaires.
L'utilisation de la propriété
CLASSpermet de réaliser cette fonctionnalité.Pour supprimer cette propriété, il faut mettre deux tirets
--comme valeur. Si la valeur est vide, la propriété conserve son ancienne valeur. - [logicalName]
-
Nom logique de la famille.
Doit commencer par une lettre. Il ne peut ensuite contenir que des caractères alphanumériques ainsi que les caractères _ et - (pas d'espace, ni de ponctuation).
- END
- Obligatoire, signale la fin d'une définition de famille.
Entre ces 2 lignes, chacune des lignes correspond à :
- un paramètre de propriété,
- une propriété de famille,
- un attribut,
- un paramètre de famille,
- une valeur par défaut,
- une valeur initiale de paramètre,
- une modification d'attribut père,
- une instruction de réinitialisation,
-
un commentaire.
Une ligne qui ne sera pas traitée lors du traitement de la définition de famille.
Un commentaire commence toujours par
//. Par exemple :// Ceci est un commentaire;;;;;;;;;;;;;;;;
4.8.2.1 Définition de paramètres de propriété
Des paramètres permettent de modifier le comportement des propriétés du document.
Leur syntaxe est toujours de la forme PROP;[propid];[param],
avec les correspondances suivantes :
- [propid]
- Nom de la propriété.
- [param]
- Définition du paramètre, sous la forme
[parameterName]=[parameterValue].
Par exemple :
PROP;title;sort=asc
Les paramètres de propriété disponibles sont :
- sort
-
Permet de spécifier si la propriété est disponible dans les recherches et les rapports, et quel est son ordre de tri par défaut.
Les valeurs possibles sont :
-
no: la propriété n'apparaîtra pas dans les recherches et rapports ; -
asc: la propriété est disponible dans les recherches et les rapports ; et est trié par défaut par ordre ascendant ; -
desc: la propriété est disponible dans les recherches et les rapports ; et est trié par défaut par ordre descendant.
Les propriétés suivantes ont un paramètre sort par défaut :
- initid : sort=desc,
- revdate : sort=desc,
- state : sort=asc,
- title : sort=asc
Les autres propriétés sont par défaut à sort=no.
-
4.8.2.2 Définition de propriétés de famille
Les propriétés de famille permettent, selon les cas, de définir un comportement particulier pour la famille, ou de définir les valeurs par défaut des propriétés des nouveaux documents de cette famille.
Leur syntaxe est toujours de la forme [propid];[value], avec les
correspondances suivantes :
- [propid]
- Identifiant de la propriété.
- [value]
- Valeur de la propriété.
Les différents identifiants de propriété sont les suivants :
- CPROFID
-
Indique le profil utilisé pour les documents créé avec cette famille. Affecte la valeur de la propriété
profidpour les nouveaux documents de cette famille.
Contient l'identifiant d'un document profil.Lors de l'importation, les vérifications suivantes sont effectuées :
- Si la famille hérite de dossier, le profil référencé doit être de la famille profil de dossier ;
- Si la famille hérite de recherche, le profil référencé doit être de la famille profil de recherche, ;
- Sinon le profil référencé doit être de la famille profil de document.
Si la valeur est vide le profil de document par défaut est enlevé.
Note : Cette propriété ne modifie pas les profils des documents de cette famille qui sont déjà créés au moment de la mise à jour de la famille.
- CVID
-
Indique le contrôle de vue qui sera associé aux documents créés avec cette famille. Affecte la valeur de la propriété
cvidpour les nouveaux documents de cette famille.
Contient l'identifiant d'un document contrôle de vue.Lors de l'importation, les vérifications suivantes sont effectuées :
- Ce document doit être de la famille contrôle de vue.
- Ce contrôle de vue doit être applicable à la famille en cours.
Si la valeur est vide le contrôle de vue par défaut est enlevé.
Note : Cette propriété ne modifie pas les contrôles de vue des documents de cette famille qui sont déjà créés au moment de la mise à jour de la famille.
- DFLDID
-
Identifiant du dossier principal permettant de constituer une arborescence spécifique à la famille .
Ce dossier est nécessaire pour manipuler les documents d'une famille depuis l'application "ONEFAM". Il peut être égal à
auto, ce qui a pour effet de créer un dossier principal automatiquement. Ce dossier aura les restrictions indiquant que seuls des documents de cette famille et des dossiers pourront être insérés dans ce dossier principal.Si cette propriété est déjà renseignée, deux cas de figure se présentent :
- La nouvelle valeur est 'auto' : Dans ce cas, l'ancienne valeur est conservée
- La nouvelle valeur n'est pas 'auto' : la nouvelle valeur est utilisée.
Si la valeur est vide le dossier principal par défaut est enlevé.
- ICON
-
Nom du fichier image définissant l'icône de la famille.
Cette icône doit être une image carré. La taille conseillée varie de 48 à 128 pixels. Le format d'image conseillé est
png. Les formats d'images supportés sontpngetgif.Si cette propriété est déjà renseignée, la nouvelle valeur ne sera pas prise en compte.
Si la famille n'a pas encore d'icône, alors la nouvelle valeur est prise en compte.
- CLASS
-
Indique le nom de la classe métier utilisée par la famille.
Ce nom de classe doit être unique parmi l'ensemble des classes PHP utilisées sur le serveur. Il est recommandé d'utiliser un namespace afin d'éviter un conflit de nom.
Si la famille définie n'a pas de parent alors la classe métier doit étendre la classe
Dcp\Family\Document. Cette classe est une classe héritant de la classeDoc.Exemple :
BEGIN Ma première famille MY_FIRST CLASS My\MyFirstFamily END namespace My; class MyFirstFamily extends \Dcp\Family\Document { public function myFirstProcedure($x) { return $x+1; } }
Si la classe est utilisée avec une famille héritant d'une autre famille, cette classe doit hériter de la classe générée de la famille parente.
Exemple :
BEGIN IMAGE Photographie MY_PHOTO CLASS My\MyPhotoFamily ATTR MYPHO_FR_INFO Informations N N frame ::auto ATTR MYPHO_EXIF MYPHO_FR_INFO Exif N N longtext ::auto END namespace My; class MyPhotoFamily extends \Dcp\Family\Image { public function postStore() { $err=parent::postStore(); if (! $err) { if (! $this->getRawValue(\Dcp\AttributeIdentifiers\Image::img_file)) { $err=_("my::image needed"); } if (! $this->getRawValue(\Dcp\AttributeIdentifiers\My\My_Photo::mypho_exif)) { $err=_("my::no exif detected"); } } return $err; } }
La classe peut étendre des classes intermédiaires, utiliser des interfaces ou des classes abstraites. La seule contrainte est que la classe générée de la famille parente doit faire partie de la hiérarchie de la classe métier. La classe générée de la famille hérite de cette classe. Elle apporte en plus la définition des attributs de la famille ainsi que le code généré pour les attributs calculés. Le nom de cette classe est
\Dcp\Family\<nom de la famille>.Hiérarchie de classe lorsque la famille MY_PHOTO est intégrée :
namespace Dcp\Core { // classe métier de la famille IMAGE class Images extends \Dcp\Family\Document {} } namespace Dcp\Family { // classe générée de la famille IMAGE class Images extends \Dcp\CoreFamily\Image {} } namespace My { // classe métier de la famille MY_PHOTO class MyPhotoFamily extends \Dcp\Family\Image {} } namespace Dcp\Family { // classe générée de la famille MY_PHOTO class My_photo extends \My\MyPhotoFamily {} }
Les attributs des classes sont disponibles sous forme de constantes. Une classe d'attributs est générée lors de l'enregistrement de la famille. Cette classe est nommée avec le nom de la famille dans le namespace
\Dcp\AttributeIdentifiers. L'usage des constantes permet de s'assurer de la validité des noms d'attributs. La classe d'attributs donne l'accès aux noms d'attribut de la famille et aussi à ceux de ses parents.Lors de l'importation de la famille les contraintes suivantes sont vérifiées :
- Le fichier PHP de la classe doit être accessible par l'autoloader.
Les fichiers de classe sont généralement publiés dans le sous-répertoire
de l'application livrée par le module.
- Le nom du fichier ne doit pas commencer par
Method. - L'extension du fichier doit être
php.
- Le nom du fichier ne doit pas commencer par
- La classe doit hériter de la classe générée de la famille parente.
En cas de famille sans héritage, la classe doit hériter de la classe
\Dcp\Family\Document. - La classe ne doit pas être abstraite.
- L'encodage du fichier doit être
utf-8(incluant l'encodageascii). - Le fichier PHP doit être syntaxiquement correct.
- Le nom de la classe doit être unique parmi l'ensemble des classes php utilisées par Dynacase.
- La propriété
classNamene peut pas être utilisée conjointement avec la propriétéCLASS.
- Le fichier PHP de la classe doit être accessible par l'autoloader.
Les fichiers de classe sont généralement publiés dans le sous-répertoire
de l'application livrée par le module.
- METHOD
-
Cette propriété sert à réutiliser des morceaux de code entre plusieurs familles (Elle est à voir comme une version simplifiée des traits pour les versions de php qui ne les supportent pas).
Indique le nom du fichier PHP contenant les méthodes supplémentaires de la famille.
Le fichier référencé doit être disponible dans le répertoire FDL.
Note : Le nom du fichier doit être unique parmi tous les fichiers présents dans le répertoire
FDL. Il est fortement conseillé d'indiquer l'identifiant de la famille dans le nom de fichier (par exemple :Method.MyFamily.phpoùMYFAMILYest l'identifiant de la famille). Le nom du fichier doit commencer parMethod.Cette propriété peut être utilisée plusieurs fois, avec la sémantique suivante :
- Lorsque le nom est préfixé par
+, son contenu est concaténé directement dans la classe générée. - Lorsque le nom est préfixé par
*, le fichier n'est pas intégré directement dans la famille, mais une classe intermédiaire est générée. Cela permet notamment une surcharge plus fine des méthodes. Le prefix '*' ne peut être utilisé qu'une seule fois par famille.
Si la valeur est vide, toutes les méthodes incluses au moyen de ce mot clé sont enlevées (y compris celles déclarées avec
*ou+).Exemple :
BEGIN IMAGE Photographie MY_PHOTO CLASS My\MyPhotoFamily METHOD Method.MyPhoto.php ATTR MYPHO_FR_INFO Informations N N frame ::auto ATTR MYPHO_EXIF MYPHO_FR_INFO Exif N N longtext ::auto END Hiérarchie de classe lorsque la famille MY_PHOTO est intégrée :
namespace Dcp\Core { // classe métier de la famille IMAGE class Images extends \Dcp\Family\Document {} } namespace Dcp\Family { // classe générée de la famille IMAGE class Images extends \Dcp\CoreFamily\Image {} } namespace My { // classe métier de la famille MY_PHOTO class MyPhotoFamily extends \Dcp\Family\Image {} } namespace { // classe méthode générée de la famille MY_PHOTO class _Method_MY_PHOTO_ extends \My\MyPhotoFamily { // inclus le contenu de Method.MyPhoto.php } } namespace Dcp\Family { // classe générée de la famille MY_PHOTO class My_photo extends _Method_MY_PHOTO_ {} }
À la place de
METHOD, l'utilisation de la propriétéCLASSest recommandée afin de définir les classes métier de la famille. - Lorsque le nom est préfixé par
- PROFID
-
Identifiant (nom logique ou identifiant interne) du document profil de famille pour cette famille.
Lors de l'importation, les vérifications suivantes sont effectuées :
- Ce document doit être de la famille 'profil de famille'.
Si la valeur est vide le profil de famille est enlevé.
- SCHAR
-
Indique les modalités de révision des documents de cette famille :
- R : Révision automatique à chaque modification,
- S : document non révisable
Si la valeur est vide la caractéristique spéciale par défaut est enlevée.
- TAG
-
Initialise les valeurs de la propriété atags.
Chaque utilisation de la balise TAG ajoutera une valeur à la propriété atags (tag applicatif).
Note : Les tags applicatifs ne peuvent être supprimés par cette directive. Il faut, pour ce cas utiliser la clef
DOCATAGCertains tags sont déjà prédéfinis par Dynacase :
- MAILRECIPIENT
-
Déclare la famille comme destinataire de mail. Cela permet aux documents de cette famille d'être présentés dans la liste de destinataires lors des envois de mail.
La famille doit alors implémenter l'interface
IMailRecipient. - TYPE
-
Valeur par défaut de la propriété type.
Si la valeur est vide, le type inféré est C.
- USEFOR
-
Caractère désignant une utilisation spéciale. Seulement pour les documents systèmes :
- W : pour les cycles de vie
- G : pour les intercalaires de chemise
- P : pour les profils
Si la valeur est vide l'utilisation spéciale par défaut est enlevée.
- WID
-
Indique le cycle de vie qui sera associé pour les documents créé avec cette famille. Affecte la valeur de la propriété
widpour les nouveaux documents de cette famille. Contient l'identifiant d'un document cycle de vie.Lors de l'importation, les vérifications suivantes sont effectuées :
- Ce document doit être un document cycle de vie ;
- Le cycle de vie doit être applicable à la famille en cours.
Si la valeur est vide le cycle par défaut est enlevé.
4.8.2.3 Définition d'attributs
Un attribut est défini par la syntaxe suivante :
ATTR;[id_attribut];[id_conteneur];[label];[in_title];[in_abstract];[type];[ordre];[visibility];[required];[link];[phpfile];[phpfunc];[elink];[constraint];[options]
avec les correspondances suivantes :
4.8.2.3.1 ATTR
Obligatoire
Signale que la ligne est une définition d'attribut.
4.8.2.3.2 Caractéristique [id_attribut]
Obligatoire
Identifiant système de l'attribut.
Il sera automatiquement converti en minuscules.
Cet item n'est plus modifiable une fois créé car il peut être utilisé dans les parties spécifiques de la famille.
Cet identificateur doit être unique dans la famille.
Il est conseillé d'adopter des règles de nommage des attributs, permettant
de simplifier leur manipulation.
Par exemple : [FAM]_[TYPE]_[NAME] avec :
- [FAM] : un préfixe indiquant la famille,
- [TYPE] : une lettre indiquant le type de l'attribut,
- [NAME] : le nom de l'attribut.
4.8.2.3.3 Caractéristique [id_conteneur]
Obligatoire (sauf pour les attributs de type frame ou tab)
Identifiant système de l'attribut structurant ou tableau contenant cet
attribut.
Le type tab ne peut pas avoir d'attribut conteneur.
Le type frame peut être contenu dans un tab, ou ne pas avoir d'attribut conteneur.
Le type array doit être contenu dans un frame.
Tous les autres type d'attributs doivent être contenus dans un array ou un frame.
4.8.2.3.4 Caractéristique [label]
facultatif
Libellé de l'attribut.
Ce libellé sera automatiquement traduit s'il est présent dans le catalogue
de traduction (la clé correspondante est de la forme [FAMNAME]#[attrid],
avec [FAMNAME] le nom logique de la famille et
[attrid] l'identifiant de l'attribut, en minuscule).
4.8.2.3.5 Caractéristique [in_title]
Obligatoire (Non applicable pour les types array, frame ou tab)
Indique que l'attribut sera utilisé dans la composition du titre du document.
Le titre du document est alors composé en concaténant toutes les valeurs brutes d'attributs définis, par ordre croissant de leur ordre et en les séparant par des espaces. Les options de formatage des attributs ne sont pas pris en compte pour le titre.
Cette caractéristique est ignorée sur les attributs de type array, frame ou tab.
Si aucun attribut n'est marqué comme composant le titre, ou si tous ces attributs sont vides, le titre sera Document sans titre suivi de l'identifiant interne du document.
Les valeurs possibles sont :
-
Ypour yes -
Npour no
La composition du titre peut aussi être définie par programmation en surchargeant la méthode Doc::getCustomTitle().
Le titre d'un document ne peut excéder 255 caractères. Il est automatiquement tronqué si cette limite est atteinte.
La visibilité des attributs n'est pas prise en compte : un attribut en visibilité cachée mais ayant la colonne titre à Y est visible dans le titre.
Les valeurs des attributs multiples seront concaténées et séparées par un espace.
4.8.2.3.6 Caractéristique [in_abstract]
Obligatoire (Non applicable pour les types menu, array, frame ou tab)
Indique que l'attribut sera utilisé dans le résumé du document.
Le résumé du document est utilisé pour construire la fiche résumé dans l'application ONEFAM.
Les valeurs possibles sont :
-
Ypour yes -
Npour no
4.8.2.3.7 Caractéristique [type]
Obligatoire Indique le type de l'attribut. Les types d'attributs supportés sont définis au chapitre Type de l'attribut.
Cette colonne permet également de définir le formatage de l'attribut :
-
attributs de type text
Le formatage est effectué avec la syntaxe sprintf.
Par exemple :
-
text("%s environ")ajoute environ après la valeur ; -
text("<b>%s</b>")affiche la valeur en gras.
-
-
attributs de type int ou double
Le formatage est effectué avec la syntaxe sprintf.
Par exemple :
-
double("%.02f")affiche le nombre avec 2 décimales ; -
integer("%d m³")affiche la valeur suivie de m³ ; -
double("%.02f %%")affiche % après le nombre.
-
-
attributs de type date, time et timestamp
Le formatage est effectué avec la syntaxe strftime.
Par exemple,
time("%H:%M:%S"), outimestamp("%A %d %B %Y %X").
4.8.2.3.8 Caractéristique [ordre]
Obligatoire
Les attributs ont un ordre dans la structure. Cet ordre est utilisé pour
représenter le document mais il est aussi utilisé pour ordonner le calcul des
attributs (phpfunc) et pour la composition du titre.
4.8.2.3.8.1 Ordre relatif
3.2.23 Pour que l'ordre suive
l'ordre de la déclaration des attributs dans le fichier
de déclaration il faut indiquer le mot-clef ::auto.
Soit la famille AA :
| BEGIN | The a | AA | ||
|---|---|---|---|---|
| // | attributes | parent | ... | order |
| ATTR | A1 | ::auto | ||
| ATTR | A2 | A1 | ... | ::auto |
| ATTR | A3 | A1 | ... | ::auto |
| ATTR | A4 | A1 | ... | ::auto |
| ATTR | A5 | A4 | ... | ::auto |
| ATTR | A6 | ... | ::auto | |
| ATTR | A7 | A6 | ... | ::auto |
Dans ce cas, la structure résultante de AA est :
- A1
- A2
- A3
- A4
- A5
- A6
- A7
En cas de surcharge de famille ou d'héritage de famille, l'ordre permet
d'indiquer où le nouvel attribut sera inséré. Le mot-clef ::auto
indique que l'attribut sera inséré à la fin de la structure de l'attribut
englobant (cadre, onglet, tableau), s'il n'y a pas d'attribut englobant, il sera
inséré à la fin du document.
Sot la famille BA héritant de la famille AA :
| BEGIN | AA | The b | BA | |
|---|---|---|---|---|
| // | attributes | parent | ... | order |
| ATTR | B1 | ::auto | ||
| ATTR | B2 | B1 | ... | ::auto |
| ATTR | B3 | B1 | ... | ::auto |
| ATTR | B4 | ... | ::auto | |
| ATTR | B5 | B5 | ... | ::auto |
| ATTR | B6 | A6 | ... | ::auto |
| ATTR | B7 | A4 | ... | ::auto |
| ATTR | B8 | A4 | ... | ::auto |
La structure résultante de BA est :
- A1
- A2
- A3
- A4
- A5
- B7
- B8
- A6
- A7
- B6
- B1
- B2
- B3
- B4
- B5
Le mot-clef ::first, permet d'insérer un attribut en premier dans la structure
englobante.
Soit la famille CA héritant de la famille AA :
| BEGIN | AA | The c | CA | |
|---|---|---|---|---|
| // | attributes | parent | ... | order |
| ATTR | C1 | ::first | ||
| ATTR | C2 | C1 | ... | ::auto |
| ATTR | C3 | C1 | ... | ::auto |
| ATTR | C4 | ... | ::first | |
| ATTR | C5 | C5 | ... | ::auto |
| ATTR | C6 | A4 | ... | ::first |
| ATTR | C7 | A4 | ... | ::first |
La structure résultante de CA est :
- C4
- C5
- C1
- C2
- C3
- A1
- A2
- A3
- A4
- C7
- C6
- A5
- A6
- A7
Dans ce cas, on remarque que B1 est derrière B4 alors qu'il a été déclaré avant
B4 dans le fichier. Ceci est du à l'ordre ::first qui est interprété dans
l'ordre de la déclaration. Au moment de l'interprétation B1 était déjà inséré.
Le même principe est visible pour les attributs C6 et C7.
L'ordre peut contenir une référence à un attribut. Cette référence indique que l'attribut sera placé après cette référence. Cette référence ne peut être qu'un attribut de même profondeur.
Soit la famille DA héritant de la famille AA :
| BEGIN | AA | The d | DA | |
|---|---|---|---|---|
| // | attributes | parent | ... | order |
| ATTR | D1 | A1 | ||
| ATTR | D2 | D1 | ... | ::auto |
| ATTR | D3 | D1 | ... | ::auto |
| ATTR | D4 | ... | D1 | |
| ATTR | D5 | D5 | ... | ::auto |
La structure résultante de DA est :
- A1
- A2
- A3
- A4
- A5
- D1
- D2
- D3
- D4
- D5
- A6
- A7
L'attribut D1 est inséré après A1. L'attribut D4 est inséré après D1.
L'ordre est appliqué suivant la hierarchie des héritages. C'est à dire que les ordres d'une famille fille sont calculés à partir des ordres calculés de la famille mère.
Soit la famille EA héritant de la famille AA :
| BEGIN | AA | The d | EA | |
|---|---|---|---|---|
| // | attributes | parent | ... | order |
| ATTR | E1 | ::auto | ||
| ATTR | E2 | D1 | ... | ::auto |
| MODATTR | A1 | ... | A6 |
Soit la famille FE héritant de la famille EA :
| BEGIN | EA | The d | FE | |
|---|---|---|---|---|
| // | attributes | parent | ... | order |
| ATTR | F1 | E1 | ||
| ATTR | F2 | F1 | ... | ::auto |
| MODATTR | E1 | ... | A6 |
La structure résultante de EA est :
- A6
- A7
- A1
- A2
- A3
- A4
- A5
- E1
- E2
La structure résultante de FE est :
- A6
- A7
- E1
- E2
- F1
- F2
- A1
- A2
- A3
- A4
- A5
4.8.2.3.8.2 Ordre absolu
L'ordre est un nombre entier.(Non applicable pour les types frame ou tab)
: Les tableaux (type array) doivent
toujours avoir un ordre inférieur aux attributs qui le composent.
Dans le cas d'un nombre, cette caractéristique est ignorée sur les attributs de type frame ou tab.
Il est déconseillé de mélanger des ordres absolus et relatifs sur une même famille. Dans ce cas, l'ordre résultant ne sera pas pertinent.
La structure suit l'ordre numérique donné.
Soit la famille AN :
| BEGIN | The a | AN | |||
|---|---|---|---|---|---|
| // | attributes | parent | ... | type | order |
| ATTR | A1 | frame | |||
| ATTR | A2 | A1 | ... | text | 10 |
| ATTR | A3 | A1 | ... | text | 20 |
| ATTR | A4 | A1 | ... | array | 30 |
| ATTR | A5 | A4 | ... | text | 40 |
| ATTR | A6 | ... | frame | ||
| ATTR | A7 | A6 | ... | text | 50 |
Dans ce cas la structure résultante de AN est :
- A1
- A2
- A3
- A4
- A5
- A6
- A7
Dans ce cas, les ordres des attributs englobant (tab et frame) sont déduits de l'ordre absolu de l'attribut.
Soit la famille BN :
| BEGIN | The b | BN | |||
|---|---|---|---|---|---|
| // | attributes | parent | ... | type | order |
| ATTR | B1 | frame | |||
| ATTR | B2 | B1 | ... | text | 100 |
| ATTR | B3 | B1 | ... | text | 110 |
| ATTR | B4 | B1 | ... | array | 120 |
| ATTR | B5 | B4 | ... | text | 130 |
| ATTR | B6 | ... | frame | ||
| ATTR | B7 | B6 | ... | text | 10 |
La structure résultante de BN est :
- B6
- B7
- B1
- B2
- B3
- B4
- B5
En cas de modification d'un ordre d'un attribut structurant, il est nécessaire de modifier tous les ordres des attributs le composant.
Soit la famille AN :
| BEGIN | CN | The a | AN | ||
|---|---|---|---|---|---|
| // | attributes | parent | ... | type | order |
| MODATTR | A2 | A1 | ... | text | 100 |
| MODATTR | A3 | A1 | ... | text | 110 |
| MODATTR | A4 | A1 | ... | array | 120 |
| MODATTR | A5 | A4 | ... | text | 130 |
| ATTR | C1 | ... | frame | ||
| ATTR | C2 | A6 | ... | text | 10 |
La structure résultante de CN est :
- C1
- C2
- A6
- A7
- A1
- A2
- A3
- A4
- A5
3.2.23 Il n'est plus possible d'avoir des cadres doublé (structure scindée).
Soit la famille DN dont l'attribut A3 à un ordre supérieur au frère de son père.
| BEGIN | The d | DN | |||
|---|---|---|---|---|---|
| // | attributes | parent | ... | type | order |
| ATTR | A1 | frame | |||
| ATTR | A2 | A1 | ... | text | 10 |
| ATTR | A3 | A1 | ... | text | 100 |
| ATTR | A4 | A1 | ... | array | 30 |
| ATTR | A5 | A4 | ... | text | 40 |
| ATTR | A6 | ... | frame | ||
| ATTR | A7 | A6 | ... | text | 50 |
3.2.22 Avant : Le cadre était doublé pour respecter l'ordre absolu.
- A1
- A2
- A4
- A5
- A6
- A7
- A1
- A3
3.2.23 Maintenant : L'ordre calculé du cadre est fonction du maximum des ordres des attributs fils.
- A6
- A7
- A1
- A2
- A3
- A4
- A5
4.8.2.3.9 Caractéristique [visibility]
Obligatoire
Définit la visibilité par défaut de l'attribut dans les interfaces
web de consultation et de modification du document.
Les valeurs possibles sont :
-
H(Hidden) : attribut caché. Généralement utilisé pour des attributs servant soit au calcul, soit à la génération des liens. -
I(Invisible) : attribut invisible : l’attribut n’est présent ni en consultation ni en modification dans le document.
Un attribut de visibilité I n'est pas modifiable et pour en modifier la valeur, il est nécessaire de modifier sa visibilité. -
O: attribut modifiable en modification mais non visible en lecture. -
R(Read-only) : attribut visible en lecture seulement. Généralement utilisé pour les attributs calculés. -
S(Statique) : attribut visible en lecture et en modification, mais non modifiable en modification. -
W(Writable) : attribut visible en lecture et modifiable en modification.
Le type array dispose en plus de la visibilité
-
U: Interdit l'ajout et la suppression de lignes dans le tableau.
Cette caractéristique peut être modifiée par les masques des contrôle de vues.
4.8.2.3.10 Caractéristique [required]
facultatif (Non applicable pour les types "frame", "tab", "array", "menu")
Indique si l'attribut est obligatoire pour la sauvegarde du document
depuis l'interface web de modification du document.
Cette caractéristique n'est pas prise en compte lors des sauvegardes faite
par le code (méthode Doc::store()) ni lors de l'importation de document.
Par contre, cette caractéristique est prise en compte lors d'un passage de
transition (document lié par un cycle de vie -workflow-).
Cette caractéristique peut être modifiée par les masques
des contrôle de vues.
3.2.19 Pour les attributs inclus dans un tableau, cette caractéristique indique que la valeur doit être renseignée pour chacune des rangées du tableau. Si aucune rangée, n'est indiquée dans le tableau, le document pourra être sauvé même si aucune valeur n'est renseignée. Le nombre de rangée minimum peut être indiqué à l'aide d'une contrainte.
Les valeurs possibles sont :
-
Ypour yes -
N(valeur par défaut) pour no
4.8.2.3.11 Caractéristique [link]
facultatif (Non applicable pour les types "frame", "tab", "array")
Ajoute un hyperlien sur l'attribut sur les interfaces web de consultation des documents.
Par défaut, le texte de l'hyperlien est la valeur de l'attribut. L'option
ltarget permet de changer ce texte.
L'hyperlien peut être :
- une URL statique ("http://www.dynacase.org"),
-
une URL paramétrée par
- des attributs du document,
- des propriétés du document,
- des paramètres applicatifs,
- des méthodes du document.
-
Utilisation d'attribut du document
Les références aux attributs du document sont écrites entre les caractères
%, en indiquant l'identifiant de l'attribut, en majuscules ou en minuscules.Le caractère
%est obtenu en le doublant :TEST%%25sera converti en TEST%25.Par exemple, soit l'attribut US_MAIL définissant le mail d'une personne. Pour déclencher l'édition d'un mail vers une personne, il suffit de mettre l'hyperlien suivant :
mailto:%US_MAIL%.Autre exemple, soit l'attribut SI_TOWN indiquant la ville de la famille société. Pour avoir la météo de la ville il suffit de mettre l'hyperlien suivant :
http://www.location.org/&strLocation=%SI_TOWN%&strCountry=EUR.Si la valeur est vide pour un des attributs de l'URL, l'hyperlien ne sera pas affiché (on ne pourra pas cliquer sur l'attribut).
Il est possible de désigner des attributs optionnels en utilisant la notation suivante :
%?[ATTRID]%. Le point d'interrogation placé après le pourcentage indique que la valeur de l'attribut peut être vide.Les valeurs insérées dans le lien sont encodés selon la RFC 3986 pour être utilisable comme valeur de paramètre web.
-
Utilisation de propriétés du document
Les références aux propriétés du document sont écrites entre les caractères
%, en indiquant l'identifiant de l'attribut, en majuscules ou en minuscules.Le caractère
%est obtenu en le doublant :TEST%%25sera converti en TEST%25.Les mots-clefs spéciaux suivants peuvent être utilisés pour la composition de l'URL :
-
%S%: est remplacé par l'URL relative vers dynacase, -
%U%: est remplacé par l'URL absolue 3.2.21, -
%I%: est remplacé par l'identifiant (équivalent à %ID%), -
%T%: est remplacé par le titre (équivalent à %TITLE%).
Les valeurs insérées dans le lien sont encodés selon la RFC 3986 pour être utilisable comme valeur de paramètre web.
-
-
Utilisation de paramètres applicatifs
Les références aux paramètres applicatifs sont écrites entre accolades, en indiquant l'identifiant de l'attribut, en majuscules ou en minuscules.
Par exemple :
%S%app=TEST&action=TESTONE&arg={CORE_CLIENT}: ici {CORE_CLIENT} sera remplacé par la valeur du paramètre CORE_CLIENT.Seuls les paramètres de CORE et les paramètres globaux sont accessibles pour la composition de l'URL.
-
Utilisation de méthodes du document
Les références aux méthodes du document sont écrites entre caractères
%, en notant la méthode comme pour les attributs calculés.Les parties variables peuvent aussi faire référence à une méthode du document. Cette méthode doit retourner une chaîne de caractère encodée selon la RFC 3986 qui sera insérée dans la variable.
Par exemple :
%::myTitleLink()%&x=3public function myTitleLink(){ return sprintf('http://www.example.net/?b=%s', rawurlencode($this->getTitle()) ); }
4.8.2.3.12 Caractéristique [phpfile]
Facultatif (Non applicable pour les types "frame", "tab", "array", "menu")
Nom du fichier php pour l'aide à la saisie.
Ce fichier doit être présent dans le répertoire EXTERNALS.
4.8.2.3.13 Caractéristique [phpfunc]
Facultatif (Non applicable pour les types "frame", "tab", "array")
Cette caractéristique est utilisée pour trois usages différents :
4.8.2.3.13.1 Définition d'une aide à la saisie
Nom et attributs de la fonction pour l'aide à la saisie.
Dans ce cas [phpfile][phpfile] doit être défini.
4.8.2.3.13.2 Définition d'un attribut calculé
Nom et attributs de la méthode de calcul s'il s'agit d'un
attribut calculé.
Dans ce cas [phpfile][phpfile] doit être vide.
4.8.2.3.13.3 Définition des valeurs d'un énuméré
Ne concerne que le cas des attributs de type enum.
Couples clé/label correspondant à l'énuméré.
4.8.2.3.13.4 Définition de la visibilité d'un menu
Ne concerne que le cas des attributs de type menu.
Méthode à utiliser pour la visibilité du menu.
4.8.2.3.14 Caractéristique [elink]
facultatif (Non applicable pour les types "frame", "tab", "array", "menu")
Extra lien supplémentaire.
Cet extra lien sera présenté dans les interfaces web de modification de document, sous la forme d'un bouton supplémentaire.
La syntaxe de l'extra lien est la même que celle de la colonne link.
4.8.2.3.15 Caractéristique [constraint]
facultatif (Non applicable pour les types "frame", "tab")
Nom et attributs de la méthode de contrainte.
4.8.2.3.16 Caractéristique [options]
facultatif
Liste des options à appliquer à l'attribut. Les options dépendent du type d'attribut.
Les options se présentent sous la forme de couples clé=valeur séparés par des |.
Par exemple: esize=3|elabel=saisissez votre prénom
4.8.2.4 Définition de paramètres de famille
Un paramètre de famille est défini par la syntaxe suivante :
PARAM;[id_attribut];[id_conteneur];[label];[in_title];[in_abstract];[type];[ordre];[visibility];[required];[link];[phpfile];[phpfunc];[elink];[constraint];[options]
avec les mêmes correspondances que pour les attributs, aux exceptions suivantes :
- Pour les paramètres calculés, le calcul est fait lors de l'accès au paramètre.
- Les méthodes de calcul et de contrainte doivent être statiques (elles sont
spécifiées par la syntaxe
class::method). - Le caractère obligatoire n'est applicable que dans le cadre de l'utilisation du paramètre dans un cycle de vie. Il n'est pas pris en compte dans les interfaces d'administration des paramètres.
4.8.2.5 Définition de valeurs par défaut
Les valeurs par défaut s'appliquent aux attributs comme aux paramètres.
Appliquées aux attributs, elles déterminent la valeur de l'attribut lors de la création d'un nouveau document, alors qu'appliquées aux paramètres, elles déterminent la valeur du paramètre lorsque l'utilisateur n'a saisi aucune valeur.
La valeur par défaut d'un attribut peut être modifiée depuis le document de la famille via l'interface "Valeurs par défaut et paramètres" puis "Modifier les valeurs par défaut".
Une valeur par défaut est définie par la syntaxe suivante :
DEFAULT;[attrid|paramid];[value];force=yes
avec les correspondances suivantes :
- DEFAULT
-
Obligatoire
Signale que la ligne est une définition de valeur par défaut. - [attrid|paramid]
-
Obligatoire
Identifiant de l'attribut ou du paramètre auquel s'applique la valeur par défaut. - [value]
-
La valeur par défaut, statique, ou la méthode de calcul.
Dans le cas d'une méthode de calcul, sa syntaxe est identique à celle d'un attribut calculé.
Par exemple,
DEFAULT;SGATE_RED;::getTitle(SGATE_IDRED)pré-remplit l'attribut avec le titre de l'attribut SGATE_IDRED, alors queDEFAULT;SGATE_ACTION;GATE_WEATHERpré-remplit l'attribut SGATE_RED avec la chaîne GATE_WEATHER.Cas particulier des array:
-
Pour définir quelles lignes seront présentes par défaut dans le tableau, on spécifie la valeur par défaut de l'attribut array.
Cette valeur par défaut est une structure JSON sous la forme d'un tableau d'objets.
Par exemple,
DEFAULT;ATTR_ARRAY;[{"c1":"1.1", "c2":"1.2"},{"c1":"2.1", "c2":"2.2"}]indique que le tableau ATTR_ARRAY sera pré-rempli avec 2 lignes.- La première ligne aura comme valeurs
- 1.1 dans la colonne correspondant à l'attribut c1
- 1.2 dans la colonne correspondant à l'attribut c2
- La seconde ligne aura comme valeurs
- 2.1 dans la colonne correspondant à l'attribut c1
- 2.2 dans la colonne correspondant à l'attribut c2
Si l'on souhaite utiliser une méthode de calcul pour cette valeur par défaut, la méthode doit retourner le tableau à 2 dimensions qui, une fois json_encodé, donne la structure précédente.
Par exemple, la méthode correspondant à la valeur par défaut précédente sera
DEFAULT;ATTR_ARRAY;::defaultArrayValue().public function defaultArrayValue(){ return array( array( "c1" => "1.1", "c2" => "1.2" ), array( "c1" => "2.1", "c2" => "2.2" ) ); }
- La première ligne aura comme valeurs
Pour définir les valeurs par défaut de chaque cellule lors de l'ajout d'une nouvelle ligne, on spécifie la valeur par défaut de l'attribut correspondant à cette colonne.
De fait, la valeur par défaut d'un attribut contenu dans un array doit être simple.
-
- [force=yes]
-
facultatif Indique, lors de la surcharge de valeur par défaut, que la nouvelle valeur par défaut écrase l'ancienne.
Dans le cas contraire, la nouvelle valeur par défaut n'est pas prise en compte lors des mises à jours.
Les valeurs par défaut peuvent être réinitialisées avec la clef
RESET default.
4.8.2.6 Définition de valeur initiale de paramètre
Les paramètres de familles peuvent avoir des valeurs par défaut, utilisées lorsque ces paramètres n'ont pas de valeur explicite ; mais il est parfois nécessaire de définir la valeur initiale du paramètre en plus de sa valeur par défaut.
La valeur d'un paramètre peut être modifiée depuis le document de la famille via l'interface "Valeurs par défaut et paramètres" puis "Modifier les paramètres".
Une valeur initiale de paramètre est définie par la syntaxe suivante :
INITIAL;[paramid];[value];force=yes
avec les correspondances suivantes :
- INITIAL
-
Obligatoire
Signale que la ligne est une définition de valeur initiale de paramètre. - [paramid]
-
Obligatoire
identifiant du paramètre auquel s'applique la valeur initiale. - [value]
-
la valeur initiale, statique, ou la méthode de calcul.
Dans le cas d'une méthode de calcul, sa syntaxe est identique à celle d'un attribut calculé.
- [force=yes]
-
Indique, lors de la surcharge de valeur initiale, que la nouvelle valeur initiale écrase l'ancienne.
Dans le cas contraire, la nouvelle valeur initiale n'est pas prise en compte. Les valeurs initiales peuvent être réinitialisées avec la clef
RESET parameters.
4.8.2.7 Modification d'attribut père
Lorsqu'une famille étend une autre famille, il peut être nécessaire de changer la définition d'un attribut. Cela se fait au moyen d'une ligne de la forme :
MODATTR;[id_attribut];[id_conteneur];[label];[in_title];[in_abstract];[type];[ordre];[visibility];[required];[link];[phpfile];[phpfunc];[elink];[constraint];[options]
avec les même correspondances que pour la définition d'un attribut, à quelques différences près :
4.8.2.7.1 MODATTR
Obligatoire
Signale que la ligne est une modification d'attribut.
4.8.2.7.2 Caractéristique [id_attribut]
Obligatoire
Identifiant système de l'attribut à surcharger.
Il sera automatiquement converti en minuscules.
L'attribut référencé doit obligatoirement exister dans la famille étendue.
4.8.2.7.3 Caractéristique [id_conteneur]
Identifiant système de l'attribut structurant ou tableau contenant cet attribut.
Si la valeur est vide, l'attribut conservera sa valeur héritée.
4.8.2.7.4 Caractéristique [label]
Libellé de l'attribut.
Si la valeur est vide, l'attribut conservera sa valeur héritée.
4.8.2.7.5 Caractéristique [in_title]
Indique que l'attribut sera utilisé dans la composition du titre du document.
Si la valeur est vide, l'attribut conservera sa valeur héritée.
4.8.2.7.6 Caractéristique [in_abstract]
Indique que l'attribut sera utilisé dans le résumé du document.
Si la valeur est vide, l'attribut conservera sa valeur héritée.
4.8.2.7.7 Caractéristique [type]
Si la valeur est vide, l'attribut conservera sa valeur héritée.
Le nouveau type d'attribut doit être compatible avec l'ancien (son stockage en base de données doit être de même type).
4.8.2.7.8 Caractéristique [ordre]
Définit l'ordre de présentation des attributs dans le document.
Si la valeur est vide, l'attribut conservera sa valeur héritée.
4.8.2.7.9 Caractéristique [visibility]
Définit la visibilité par défaut de l'attribut.
Si la valeur est vide, l'attribut conservera sa valeur héritée.
4.8.2.7.10 Caractéristique [required]
Indique si l'attribut est obligatoire pour la sauvegarde du document.
Si la valeur est vide, l'attribut conservera sa valeur héritée.
4.8.2.7.11 Caractéristique [link]
Ajoute un hyperlien sur l'attribut (en consultation uniquement).
Si la valeur est vide, l'attribut conservera sa valeur héritée.
Pour supprimer la valeur, il faut mettre -.
4.8.2.7.12 Caractéristique [phpfile]
Nom du fichier php pour l'aide à la saisie.
Si la valeur est vide, l'attribut conserve sa valeur héritée.
Pour supprimer la valeur, il faut mettre -.
4.8.2.7.13 Caractéristique [phpfunc]
Nom et attributs de la fonction pour l'aide à la saisie, ou nom et attributs de la méthode de calcul s'il s'agit d'un attribut calculé, ou définition des clés-valeurs dans le cas d'un attribut de type énuméré.
Si la valeur est vide, l'attribut conserve sa valeur héritée.
Pour supprimer la valeur, il faut mettre -.
4.8.2.7.14 Caractéristique [elink]
Extra lien supplémentaire.
Si la valeur est vide, l'attribut conserve sa valeur héritée.
Pour supprimer la valeur, il faut mettre -..
4.8.2.7.15 Caractéristique [constraint]
Nom et attributs de la méthode de contrainte.
Si la valeur est vide, l'attribut conserve sa valeur héritée.
Pour supprimer la valeur, il faut mettre -.
4.8.2.7.16 Caractéristique [options]
Liste des options à appliquer à l'attribut.
Si la valeur est vide, l'attribut conserve sa valeur héritée.
Pour supprimer la valeur, il faut mettre -.
Afin de modifier la valeur d'une seule option, il est nécessaire de toutes
les reporter, car la valeur - va effacer entièrement le contenu de la
colonne options.
4.8.2.8 Instructions de réinitialisation
Lors de la surcharge de famille, il est possible de réinitialiser certaines parties de la famille.
La syntaxe est la suivante :
RESET;[keyword]
avec les correspondantes suivantes :
- RESET
-
Obligatoire
Signale que la ligne est une réinitialisation. - [keyword]
-
Obligatoire
Indique quels éléments doivent être réinitialisés.Les valeurs possibles sont :
attributes-
Réinitialise les attributs.
La définition de tous les attributs sera effacée (les valeurs ne sont pas supprimées des documents existants).
Attention : la définition des paramètres de la famille est également effacée (bien que les valeurs soient également conservées).
default-
Réinitialise les valeurs par défaut.
Toutes les valeurs par défaut sont effacées.
properties-
Réinitialise les valeurs des paramètres des propriétés.
Tous les paramètres de propriétés (positionnés par les directives
PROP;[propid];[param]) seront remis à leur valeur par défaut. parameters-
Réinitialise les valeurs des paramètres de famille
Toutes les valeurs des paramètres de famille sont effacées. Ces paramètres utiliseront les valeurs par défaut si elles sont définies.
structure-
Réinitialise la liste des attributs aux seuls attributs définis entre le
BEGINet leENDde la famille.Les définitions des attributs qui ne sont plus définis sont supprimés. Cela veut dire que non seulement la définition de l'attribut est supprimé mais aussi les valeurs de ces attributs sur tous les documents de la famille et des familles dérivées. Cette action est irréversible.
enums- Réinitialise les définitions des énumérés de la famille.
Les nouvelles définitions remplaceront les anciennes définitions. Les énumérés définis par les utilisateurs ou les administrateurs seront perdus.
Ces instructions de réinitialisation doivent être placées avant la nouvelle définition des éléments réinitialisés.
Chaque instruction doit être sur sa propre ligne.
4.8.3 Surcharge de définition de famille
La définition d'une famille peut être surchargée, permettant ainsi une importation plus modulaire. Il est bien question ici de la notion de surcharge qui change la définition d'une famille, et à ne pas confondre avec le mécanisme d'héritage, qui crée une nouvelle famille.
Pour surcharger une définition de famille, il suffit d'utiliser le même nom logique (sur la ligne BEGIN).
Lors de la surcharge, le comportement est le suivant :
-
pour les paramètres de propriété
La nouvelle valeur écrase la valeur précédemment définie.
-
pour les propriétés de famille
La nouvelle valeur écrase la valeur précédemment définie.
-
pour les attributs
La nouvelle valeur écrase la valeur précédemment définie.
-
pour les paramètres de famille
La nouvelle valeur écrase la valeur précédemment définie.
-
pour les valeurs par défaut
La nouvelle valeur écrase la valeur précédemment définie si force=yes est utilisé.
-
pour les valeurs initiale de paramètre
La nouvelle valeur écrase la valeur précédemment définie si force=yes est utilisé.
Ce comportement peut être altéré par l'utilisation des Instructions de réinitialisation.
4.8.4 Prise en compte d'une définition de famille dans Dynacase
Une fois votre définition de famille créée, vous pouvez l'importer dans Dynacase.
Cette importation permettra à Dynacase de créer les tables nécessaires aux documents de cette famille, et de rendre la dite famille disponible dans les différentes IHM de Dynacase.
L'importation se fait en ligne de commande, avec la commande suivante :
./wsh.php --api=importDocuments --file=[chemin vers le fichier de définition]
Pour plus de détails sur l'API importDocuments, se référer à sa
documentation
4.8.5 Erreur d'importation d'attributs
La liste des codes d'erreur possibles lors de l'importation d'attributs est consultable dans la documentation de l'API PHP : ErrorCodeATTR Class Reference.
Chapitre 5 Document système
Dynacase core est livré avec un certain nombre de familles systèmes.
Ces familles permettent de créer des documents de paramétrage, tels que :
- des recherches pré-cablées,
- des modèles de mail,
- des minuteurs,
- etc.
Cette partie donne une explication de chacune de ces familles.
5.1 Les recherches
5.1.1 Présentation
Il est possible de définir des recherches et de les sauvegarder pour les réutiliser. Ce qui est sauvegardé au moyen d'une recherche, ce sont les critères et non pas les résultats.
Une recherche est donc une collection dynamique de documents.
5.1.2 Exemples d'utilisation
5.1.2.1 Paramétrage de l'interface une famille
Dans l'interface une famille, il est possible de proposer des recherches pré-cablées pour les utilisateurs : ces recherches doivent être :
- visibles par les utilisateurs concernés,
- dans le dossier système (cf DFLDID dans les propriétés des familles de la famille concernée).
5.1.2.2 Backend d'approvisionnement pour des interfaces spécifiques
Soit la demande suivante :
- une représentation des documents sous forme de grille,
- que cette grille puisse représenter
- Les documents créés cette semaine,
- Les documents créés par l'utilisateur courant,
- D'autres modalités qu'il définira plus tard au fur et à mesure de ses besoins.
L'IHM à construire peut se définir ainsi :
- une combobox permettant de choisir une recherche parmi toutes les recherches disponibles dans un dossier prédéfini
- une grille asservie à cette combobox :
- dès qu'une recherche est choisie dans la combobox, la grille est rechargée avec la recherche sélectionnée comme source de données.
Nous pouvons ensuite créer les recherches correspondant aux demandes spécifiques :
- Les documents créés cette semaine,
- Les documents créés par l'utilisateur courant.
Lorsque le client voudra ajouter des modalités de recherche, il lui suffira de créer des recherches dans le dossier correspondant.
5.1.3 Recherche simple
5.1.3.1 Présentation
Le type de recherche le plus simple est implémenté au moyen de la famille
SEARCH (implémentée par la classe DocSearch).
5.1.3.2 Éléments de paramétrage
Cette famille permet de rechercher les documents en spécifiant :
- des mots clés
- une famille
- avec ou sans ses sous-familles
-
les révisions dans lesquelles chercher
Prenons par exemple un document avec les révisions suivantes :rev1 → rev2 → rev3 ⇢ revC
Les choix possibles sont :
- courante
- permet de ne rechercher que dans les révisions courantes des documents (Ex. : recherche sur revC).
- toutes les révisions
- permet de rechercher dans toutes les révisions des documents (Ex. : recherche sur rev1, rev2, rev3, revC).
- dernière révision
- permet de ne rechercher que dans les dernières révisions des documents (Ex. : recherche sur rev3).
- sans la courante
- permet de rechercher dans toutes les révisions sauf la courante (Ex. : recherche sur rev1, rev2, rev3).
- dernière parmi les révisions effectuées
- permet de rechercher dans toutes les révisions (sauf la courante) des documents mais de ne retourner que la dernière des révision des documents qui correspond aux critères (Ex. : recherche sur rev1, rev2, rev3, mais ne retourne que rev3).
- une restriction aux documents
- modifiables par l'utilisateur
- supprimables par l'utilisateur
- comprenant ou non les documents supprimés
- une restrictions aux documents contenus dans un dossier donné
5.1.4 Recherche détaillée
5.1.4.1 Présentation
La recherche détaillée permet d'exprimer des critères de recherche avancés portant sur les attributs des documents, ainsi que sur l'état des documents soumis à un cycle de vie.
Elle est implémentée au moyen de la famille DSEARCH, qui étend la famille
SEARCH.
5.1.4.2 Éléments de paramétrage
5.1.4.2.1 Condition de la recherche
La document "recherche détaillée" permet de rechercher les documents en spécifiant :
- une famille
- avec ou sans ses sous-familles
-
les révisions dans lesquelles chercher Prenons par exemple un document avec les révisions suivantes :
rev1 → rev2 → rev3 ⇢ revC
Les choix possibles sont :
- courante
- permet de ne rechercher que dans les révisions courantes des documents (Ex. : recherche sur revC).
- toutes les révisions
- permet de rechercher dans toutes les révisions des documents (Ex. : recherche sur rev1, rev2, rev3, revC).
- dernière révision
- permet de ne rechercher que dans les dernières révisions des documents (Ex. : recherche sur rev3).
- sans la courante
- permet de rechercher dans toutes les révisions sauf la courante (Ex. : recherche sur rev1, rev2, rev3).
- dernière parmi les révisions effectuées
- permet de rechercher dans toutes les révisions (sauf la courante) des documents mais de ne retourner que la dernière des révision des documents qui correspond aux critères (Ex. : recherche sur rev1, rev2, rev3, mais ne retourne que rev3).
- une restriction aux documents
- modifiables par l'utilisateur
- supprimables par l'utilisateur
5.1.4.2.2 Critères de recherche
Les critères permettent d'exprimer les conditions sur les attributs, propriétés ou étapes du document.
5.1.4.2.2.1 les attributs de la famille sélectionnée,
La recherche par attributs se fait au moyen des colonnes
- attributs
- permet de sélectionner l'attribut ou la propriété qui servira de critère de recherche.
- fonctions
- permet de sélectionner l'opération de comparaison qui sera appliquée sur l'attribut. Le sélecteur de fonction dépend du type de l'attribut.
- mot-clefs
-
permet de spécifier la valeur de référence de la comparaison. Le sélecteur de mot-clefs varie en fonction du type d'attribut et de la fonction sélectionnée.
Par exemple, pour les attributs de type énuméré il présentera la liste des choix possibles ; alors que pour les attributs de type texte, il présentera un champ libre de saisie de texte.
- Opt
- permet de saisir un mot-clefs qui ne soit pas statique mais qui résulte de l'évaluation d'une méthode documentaire. Cela permet par exemple d'exprimer une valeur qui soit la date courante (avec la méthode "::getDate()").
La liste des attributs présentés est conditionnée par l'option
searchcriteria.
3.2.19Pour les attributs relations (type docid, account), si l'opérateur demandé est "identificateur égal" ou "identificateur est différent" alors une aide à la saisie est proposée pour faciliter la recherche du document. Cette aide à la saisie n'est pas celle de la famille cible mais simplement une aide pour rechercher l'identifiant du document en fonction de son type. L'identifiant du document peut aussi être donnée directement dans la champ situé à droite de l'aide à la saisie.
5.1.4.2.2.2 les étapes du workflow associé à la famille sélectionnée
Le critère état ne concerne que les documents figés.
Ce critère état n'est pas accessible avec l'option révision courante
La recherche par état se fait au moyen des colonnes
- attributs
- La colonne "attributs" ne peut pas être modifiée, et est positionnée sur "état" pour indiquer que ce critère est un critère sur l'état des documents.
- fonctions
- présente la liste des opérateurs de comparaison supportés par les états.
- mot-clefs
- La colonne "mot-clefs" présente la liste des états possibles du cycle de vie, et permet de sélectionner l'état de référence pour la comparaison.
Le critère "activité" ne concerne que les documents en dernière révision.
Ce critère n'est accessible qu'avec les options révision courante et toutes les révisions.
La recherche par activité se fait au moyen des colonnes
- attributs
- La colonne "attributs" ne peut pas être modifiée, et est positionnée sur "activité" pour indiquer que ce critère est un critère sur l'activité des documents.
- fonctions
- présente la liste des opérateurs de comparaison supportés par les activités.
- mot-clefs
-
présente la liste des activités possibles du cycle de vie, et permet de sélectionner l'activité de référence pour la comparaison.
Attention, si le cycle de vie ne décrit pas d'activités pour une étape, ce sera la libellé de l'état qui sera affiché. Cette notation reste cohérente avec ce qui est écrit dans les entêtes des documents.
5.1.4.2.3 Opérateurs logiques
L'opérateur logique (attribut "condition") peut avoir 3 valeurs :
-
and: "satisfait toutes les conditions" -
or: "satisfait au moins une condition" -
perso: "personnalisée"
Si la condition est personnalisée, les parenthèses permettent de prioriser les différents critères.
5.1.4.3 Erreur de requêtage
Lors de la création de la requête, les erreurs "statique" pouvant être détectées (problème de parenthèse, argument incorrect,...) empêche l'enregistrement.
Les autres erreurs de requête, comme par exemple, la référence à une famille qui n'existe plus, sont affichés lors de l'exécution de la recherche.
Voir aussi : Programmation des recherches.
5.1.5 Recherche groupée
5.1.5.1 Présentation
Une recherche groupée est une union (au sens ensembliste du terme) de plusieurs recherches (au niveau de la base de données, c'est également la construction UNION qui est utilisée).
Elle est implémentée au moyen de la famille MSEARCH, qui étend la famille
SEARCH.
La recherche groupée n'exécute que les documents "recherche" qui ont le droit "execute" pour l'utilisateur courant.
5.1.5.2 Éléments de paramétrage
Lors de la construction d'une recherche groupée, il suffit de spécifier la liste des recherches à utiliser. La recherche groupée est ensuite utilisable de façon identique à la recherche simple.
5.1.6 Recherche spécialisée
5.1.6.1 Présentation
Dans le cas d'une recherche très spécifique, il peut être nécessaire de construire cette recherche de toutes parts. La famille recherche spécialisée permet de fournir le code php de la recherche.
Elle est implémentée au moyen de la famille SSEARCH, qui étend la famille
SEARCH.
5.1.6.2 Éléments de paramétrage
Lors de l'édition d'une recherche spécialisée, vous devez renseigner
- le nom du fichier php où se trouve la fonction de recherche
(ce fichier doit être dans le répertoire/EXTERNALSdu serveur), -
le nom de fonction de recherche.
Les arguments de la fonctions sont au minimum de 3 :
- start : start index pour la recherche
- slice : nombre maximum d'éléments à retourner
- userid : identifiant de l'utilisateur courant
Des arguments supplémentaires peuvent être ajoutés dans l'attribut 'Argument PHP'.
Il sont ajoutés dans l'appel à partir de la quatrième position.Pour rajouter plusieurs arguments, il faut les séparer par une virgule (exemple : 1234,ceci est un test,dernier argument).
Dans ces arguments, il est possible de référencer
- des attributs du document recherche lui même.
Il faut alors utiliser la notation
-
%[PROPERTYID]%pour avoir la valeur de la propriété PROPERTYID, -
%[ATTRID]%pour avoir la valeur de l'attribut ATTRID -
%THIS%, pour avoir l'objet recherche.
-
La fonction de recherche doit retourner un tableau de documents.
Ces documents retournés doivent être de type array, et non des objets.
5.1.6.3 Exemples
5.1.6.3.1 Exemple issu du fichier fdlsearches.php (livré en standard).
/** * return all documents having user tag $tag */ function mytagdoc($start="0", $slice="ALL",$tag,$userid=0) { $s=new searchDoc(); //joins with table docutag, using id=docutag.id $s->join("id = docutag(id)"); //do not return objects $s->setObjectReturn(false); $s->setSlice($slice); $s->setStart($start); $s->addFilter("docutag.uid = %d", $userid); $s->addFilter("docutag.tag = '%s'", $tag); return $s->search(); } /** * function use for specialised search * return all document tagged TOVIEWDOC for current user * * @param int $start start cursor * @param int $slice offset ("ALL" means no limit) * @param int $userid user system identifier (NOT USE in this function) */ function mytoviewdoc($start="0", $slice="ALL",$userid=0) { return mytagdoc($start, $slice, "TOVIEW", $userid); }
5.1.7 Rapport
5.1.7.1 Présentation
Le rapport permet d'ajouter des options de mise en forme à une recherche détaillée.
Ainsi, il est possible d'exprimer les critères de recherche de la même manière que dans une recherche détaillée, et de choisir parmi les attributs et propriétés de la familles quelles sont celles qui seront présentées.
Le résultat est alors affiché sous la forme d'une table, qui peut ensuite être exportée au format csv.
Il est implémenté au moyen de la famille Report, qui étend la famille
DSEARCH.
5.1.7.2 Éléments de paramétrage
Un rapport dispose, en plus des éléments de paramétrage de la recherche détaillée des éléments de présentation suivants :
un texte de description qui sera présenté sur la page de résultat,
l'attribut en fonction duquel seront ordonnés les résultats dans le tableau,
une limite au nombre de résultats présentés. Lorsque le nombre d'éléments est supérieur à cette limite, alors la liste de résultats sera tronquée et seul les N premiers éléments seront présentés. La valeur par défaut est déterminée au moyen du paramètre
rep_maxdisplaylimitde la famille rapport (par défaut à 1000).-
les colonnes du tableau de résultat.
Chaque ligne du tableau "Colonnes" permet de sélectionner un attribut ou une propriété du document qui sera présenté sous forme de colonne dans le tableau des résultats.
Pour chaque colonne, il est possible d'indiquer :
l'attribut du document à l'aide du sélecteur "label"
la couleur de la colonne
-
une opération sur la colonne dont le résultat est présenté en pied de tableau.
Les opérations de pied de tableau disponibles sont :
- Somme
- effectue la somme des éléments de la colonne (attention : le calcul de la somme ne sera correct que pour des valeurs numériques).
- Moyenne
- effectue la moyenne des éléments de la colonne (attention : le calcul de la moyenne ne sera correct que pour des valeurs numériques).
- Cardinal
- effectue un décompte du nombre de lignes dans la colonne.
De plus, il est possible d'exporter le résultat d'un rapport en csv via un assistant d'export.
5.1.7.3 Assistant d'export csv
L'assistant d'export CSV est présent sur les rapports via le menu "export CSV" en consultation, il permet d'exporter le rapport en CSV de deux manières :
-
simple : Dans ce cas un document est une ligne et chaque colonne une
cellule de cette ligne. Lorsque l'attribut est multiple, les valeurs sont séparées
par des
\npour le premier niveau de multiplicité et des,pour le second. - pivot : Ce mode permet l'export à des fins de traitement dans un tableur avec la fonctionnalité pivot. Les données sont alors dissociées par groupe de multiplicité, c'est à dire que chaque attribut multiple génère un ensemble de colonnes identifiées par le pivot (qui est un attribut ou une propriété du document).
De plus, l'assistant d'export permet de définir différentes propriétés du fichier CSV généré (encodage, séparateur, format de date, etc.).

Figure 65. Export CSV
Options d'exportation :
- le caractère de séparation des cellules : valeur par défaut ";"
- le caractère de séparation de texte : valeur par défaut "
- le caractère de séparation des valeurs décimal : valeur par défaut ,
-
3.2.19 le format des nombre : par défaut
les nombres sont exportés avec leur format
comme par exemple la devise pour le type
money - le jeu de caractère : valeur par défaut "iso 8859-15"
- le format de la date :
- US : Format AAAA-MM-JJ HH:MM
- FR : Format JJ/MM/AAAA HH:MM
- ISO : Format AAAA-MM-JJTHH:MM
- les balises HTML : pour les attribut HTML permet de ne conserver que le texte brut si on enlève les balises
Les options modifiées sont conservées pour chaque utilisateur et sont réutilisées à chaque nouvelle exportation.
Voir aussi : Programmation des rapports.
5.2 Les dossiers
Les dossiers permettent de grouper des documents. Un dossier est un type de collection, comme les recherches et rapport.
Cette fonction est analogue à la fonction de répertoires présents dans les systèmes de fichiers mais présente de notables différences.
Un dossier ne gère que des références à des documents. Au contraire du répertoire qui, dans un système de fichiers, impose que les fichiers soient liés physiquement à un répertoire. Cela implique les faits suivants :
- la suppression d'un dossier n'entraîne pas la suppression de ses références,
- l'accès à un dossier ne contraint pas l'accès à une des ses références,
- les références entre dossiers peuvent conduire à des boucles dans l'arborescence,
- un document ou un dossier peut être référencé dans aucun, un seul ou plusieurs dossiers.
Par défaut, n'importe quelle famille de document peut être insérée dans un dossier. Un dossier peut être paramétré pour ne contenir que certaines familles de documents, c'est ce qu'on nomme la restriction.
5.2.1 Restrictions
La restriction d'un dossier est paramétrée à l'aide des attributs :
5.2.1.1 Attribut FLD_ALLBUT
L'attribut FLD_ALLBUT est un énuméré qui peut prendre deux
valeurs (0 ou 1) et qui permet de spécifier le mode de restriction :
-
0(tout sauf) - Autorise l'insertion de toutes les familles de documents à l'exception d'une liste déterminée de famille à exclure.
-
1(seulement) - N'autorise que l'insertion de documents des familles déterminées.
5.2.1.2 FDL_FAMIDS
L'attribut FLD_FAMIDS est un attribut multivalué qui contient
des identifiants de familles, et qui permet de spécifier la liste des familles à
autoriser ou à exclure (en fonction de la valeur de l'attribut
FDL_ALLBUT).
L'attribut FLD_SUBFAM est un attribut multivalué qui indique si la famille
indiquée dans la restriction FLD_FAMIDS concerne aussi les sous-famille ou non.
Les valeurs possible de FLD_SUBFAM sont :
-
yes: avec les sous-familles, -
no: sans les sous-familles.
5.2.1.3 Exemple de paramétrage de restriction
N'autoriser que l'insertion de documents issus des familles FAM_A (et ses
dérivées) et FAM_B (sans ses dérivées) dans le dossier My_FOLDER.
/** * @var Dir $myFolder */ $myFolder = new_doc(getDbAccess(), "My_FOLDER"); $idFamA = getIdFromName(getDbAccess(), 'FAM_A'); $idFamB = getIdFromName(getDbAccess(), 'FAM_B'); $myFolder->setAttributeValue(\Dcp\AttributeIdentifiers\Dir::fld_allbut, 1); $myFolder->setAttributeValue(\Dcp\AttributeIdentifiers\Dir::fld_famids, array($idFamA, $idFamB)); $myFolder->setAttributeValue(\Dcp\AttributeIdentifiers\Dir::fld_subfam, array("yes","no")); $myFolder->store();
5.2.2 Profil de dossier
Le profil de dossier hérite du profil de document.
La famille PDIR est le profil de dossier. En plus des droits du document
"classique", deux droits spécifiques sont ajoutés :
-
open: Permet d'accéder au contenu du dossier. -
modify: Permet d'ajouter ou de supprimer des références au dossier.
Note : Le droit edit n'est pas utilisé pour vérifier la modification du
contenu mais il est utilisé pour vérifier la modification des informations sur
le document dossier tel que son titre et sa description.
5.2.3 Profil de contenu
En terme de droit, le dossier possède une fonctionnalité spécifique. Il peut modifier les droits des documents qui sont insérés dans le dossier.
L'attribut fld_pdocid et fld_pdirid permettent d'indiquer le profil qu'
acquiert un document lorsqu'il est inséré dans le dossier.
-
fld_pdocid: profil utilisé pour les documents "classique" -
fld_pdirid: profil utilisé pour les documents "dossier"
Attention : Le profil d'un document inséré est modifié seulement s'il n'est
pas déjà profilé (profid = 0) et seulement lors d'une
insertion unitaire et non lors d'une
insertion multiple.
5.2.4 Hook (hameçons) propres aux documents dossiers
La modification d'un profil de document inséré peut être personnalisée en
utilisant les hameçons (hook) Dir::postInsertDocument() et
postInsertMultipleDocuments().
5.2.5 Voir aussi
Voir la classe Dir qui contient les méthodes spécifiques aux dossiers.
5.3 Masque
Les masques permettent de changer la visibilité des attributs d'un document.
Ainsi, il est possible de définir pour chaque attribut de la famille sa nouvelle visibilité, ainsi que de changer son caractère obligatoire.
Remarques :
- il est important ici de rappeler que la visibilité des attributs ne garantit aucunement la confidentialité des informations, puisque les attributs Hidden sont quand même présents dans la dom
- comme dans le document, les visibilités des attributs structurants impactent celles des attributs qu'ils contiennent. Ainsi, il est souvent plus efficace de changer la visibilité d'une frame que de l'ensemble de ses attributs (voir le calcul de visibilité pour plus de détails).
- Lors de l'import de masques, une contrainte vérifie que l'ensemble des attributs référencés dans le masque existent dans la famille à laquele est rattachée le masque.
5.4 Contrôle de vue
Les contrôles de vue permettent de spécifier des représentations alternatives pour un document. L'utilisateur pourra choisir parmi ces représentations, en fonction de ses droits, ou alors le contrôle de vue peut déterminer dynamiquement la vue en fonction des droits de l'utilisateur.
Chaque modalité de représentation est appelée une vue.
Chaque vue est composées de :
- un identifiant système (obligatoire)
- une chaîne alphanumérique, qui doit être unique au sein du contrôle de vue. Elle permet de désigner la vue de manière non ambiguë.
- un libellé (obligatoire)
- une chaîne permettant de désigner la vue à l'utilisateur. Traduisible, elle sera notamment utilisée dans les menus.
- un type (obligatoire)
- consultation ou édition, détermine pour quelle type de représentation la-dite vue est utilisable.
- une zone (sous la forme
APP:ZONE:OPTIONS:TRANSFORMATION) - permet d'indiquer un template de représentation. se reporter à vues de documents pour plus de précisions.
- un masque
- permet de spécifier un masque à appliquer lors de l'utilisation de cette vue
- un numéro d'ordre
- entier utilisé pour le choix automatique, il permet d'indiquer un ordre de préférence pour les vues.
- un caractère affichable
-
indique si la vue doit être présentée à l'utilisateur sous forme de menu (pour lui permettre de choisir cette représentation), ou ne sera accessible que par programmation.
Si la vue est affichable, alors elle sera présentée au moyen de son libellé.
Si la vue affichable est la vue d'édition par défaut, celle-ci est affichée à la place du menu "Modifier" avec le nom de la vue. Elle n'est pas affichée ailleurs même si le paramètre "menu" est défini.
- un nom de menu
- si la vue est affichable, indique le libellé du menu sous lequel doit être présentée la vue
5.4.1 Profilage du contrôle de vue
Il est possible d'appliquer un profil à un contrôle de vue. Ce profile détermine alors pour chaque vue qui a le droit d'y accéder.
Le profil en question peut être statique, mais également dynamique.
5.4.2 Choix automatique de la vue
La vue à utiliser peut être explicitement spécifiée au moyen du paramètre d'url
vid=[VIEW_ID] où [VIEW_ID] est l'identifiant système de la vue à
utiliser. Dynacase va alors vérifier que l'utilisateur a bien accès à la vue
spécifiée. Dans le cas contraire, un message d'erreur est retourné. Si le
paramètre vid référence une vue non existante, ou lorsqu'aucune vue n'est
spécifiée, la vue est automatiquement choisie selon le mécanisme suivant :
-
Restriction à la liste des vues pour lesquelles
- le type (consultation/édition) correspond à l'action courante,
- l'utilisateur est autorisé à y accéder ,
- l'ordre est strictement positif (≥ 1).
Classement des vues restantes par numéro d'ordre croissant.
Utilisation de la première des vues restantes (n° d'ordre le plus petit ≥ 1). Si aucune des vues n'est utilisable, c'est la vue par défaut qui est utilisée.
Exemple : Soit le contrôle de vue suivant
| Identifiant de la vue | Label | Type | Ordre de sélection | Affichable | Droit User #1 | Droit User #2 |
|---|---|---|---|---|---|---|
| VUE1 | Vue n°1 | Consultation | 0 | Oui | X | X |
| VUE2 | Vue n°2 | Consultation | 10 | Non | X | |
| VUE3 | Vue n°3 | Consultation | 30 | Non | X | |
| VUE4 | Vue n°4 | Consultation | 20 | Oui | X | |
| VUE5 | Vue n°5 | Édition | 0 | Oui | X | |
| VUE6 | Vue n°6 | Édition | 10 | Non | X | |
| VUE7 | Vue n°7 | Édition | Non | X | X | |
| VUE8 | Vue n°8 | Édition | 20 | Oui | X |
Soit l'url : ?app=FDL&action=OPENDOC&mode=view&id=1234
Pour l'utilisateur n°1 :
- Vue utilisée : VUE3
- Vue de modification proposée dans le menu "Modifier" : Défaut (aucune vue d'édition n'est sélectionnable automatiquement)
- Vue proposée sur le menu : VUE1, VUE5, VUE7
Pour l'utilisateur n°2 :
- Vue utilisée : VUE2
- Vue de modification proposée dans le menu "Modifier" : VUE6
- Vues proposées sur le menu : VUE1, VUE4, VUE8
5.4.3 Libellé du menu modifier
Lors de la consultation, le libellé du menu modifier correspondra au libellé de la vue de modification choisie selon l'algorithme précédent.
5.4.4 Astuces
Les ordres ne sont pas obligés de se suivre. Aussi, vous pouvez numéroter vos vues de 10 en 10, afin de faciliter l'ajout futur d'une nouvelle vue.
Il est recommandé de restreindre la visibilité des attributs sur la famille, et d'élargir ces visibilités au moyen des contrôles de vue et des masques associés. Ainsi, il devient aisé d'avoir une vue d'administration, utilisant un masque dédié, et ayant le plus faible ordre, et les autres vues restreintes, sans masque et avec un ordre supérieur.
5.5 Modèle de mail
Les modèles de mail permettent de paramétrer les mails qui seront envoyés par Dynacase. Un modèle de mail permet de définir :
- l'expéditeur,
- le(s) destinataire(s),
- le sujet du mail,
- le corps du mail,
- les pièces jointes
Chacune de ces parties pourra être dynamique en fonction des valeurs du document auquel le mail envoyé est rattaché.
Le modèle de mail porte les informations suivantes :
- Titre (Obligatoire)
- Titre sous lequel sera enregistré le modèle de mail. Cette valeur ne sert que dans Dynacase, et ne sera pas exposée à l'utilisateur final (sauf dans l'historique système).
- Famille
-
Famille à laquelle est rattaché le modèle de mail. Cette famille permet de lister les attributs qui seront utilisables pour la composition du mail.
Note : Dans l'éditeur du corps de message, les clefs d'attributs ne sont accessibles que lors d'une modification du document après avoir sélectionné la famille et non directement lors de l'ouverture du formulaire d'édition du modèle de mail.
- Famille cycle
- Famille du cycle de vie auquel est rattaché ce modèle de mail. Cette famille permet de lister les attributs qui seront utilisables pour la composition du mail.
- L'émetteur
- Il peut être choisi au moyen de règles avancées à partir des valeurs du document.
- Les destinataires
- Ils peuvent être choisis au moyen de règles avancées à partir des valeurs du document.
- Le sujet
-
Le sujet est un texte libre. Il peut contenir des parties variables issues du document qui va être envoyé, sous la forme
[BALISE]. Les balises sont générées par le document, et peuvent être complétées par le second paramètre de la méthodeMailTemplate::sendMail().Note: attention, le sujet d'un mail ne devant pas contenir de html, il est déconseillé d'utiliser les balises
[V_TITLE]ou[V_ATTRID]. - Le corps
- Le corps est un texte html avec mise en forme. Il peut contenir des parties
variables issues du document qui va être envoyé, sous la forme
[BALISE]. Les balises sont générées par le document, et peuvent être complétées par le second paramètre de la méthodeMailTemplate::sendMail(). - Les pièces jointes
-
Les fichiers attachés font référence à des attributs de type file (ou image) du document. Les fichiers seront alors en pièce jointe du courriel. Bien sûr, ces attributs peuvent être des listes de fichiers (attribut file ou image dans un tableau).
Il est possible d'utiliser la notation
:pour aller chercher des valeurs sur les documents liés (par exemple :TST_MYID:THE_FILErécupère la valeur de l'attributTHE_FILEdans le document référencé par l'attribut relationTST_MYID). La notation:peut être utilisée plusieurs fois pour aller de relation en relation (par exemple :TST_RELATIONONEID:OTHER_RELATIONID:THE_FILE).
5.5.1 Spécification de l'émetteur ou du destinataire
L'émetteur ou les destinataires peuvent être choisis parmi :
5.5.1.1 Adresse fixe
Le destinataire est alors statique. Une aide à la saisie permet de récupérer l'adresse d'un utilisateur existant, mais une fois la valeur saisie, elle ne sera jamais mise à jour.
L'adresse indiquée doit être dans une forme acceptable pour le champ from
d'une requête SMTP (ie. de la forme "nom expéditeur" <mail@host.net.
5.5.1.2 Valeur du document lié
5.5.1.2.1 Attribut texte
Le destinataire est alors dynamique, et est rattaché à un attribut textuel du
document. Cet attribut doit contenir une adresse email dans une forme
acceptable pour le champ from d'une requête SMTP (ie. de la forme
"nom expéditeur" <mail@host.net).
Il est possible d'utiliser la notation : pour aller chercher des valeurs sur
les documents liés (par exemple : TST_MYID:THE_MAIL récupère la valeur de
l'attribut THE_MAIL dans le document référencé par l'attribut relation
TST_MYID.)
La notation : peut être utilisée plusieurs fois pour aller de relation en
relation (par exemple : TST_RELATIONONEID:OTHER_RELATIONID:THE_MAIL).
5.5.1.2.2 Attribut relation
Le destinataire est alors dynamique, et est rattaché à un attribut de type relation (account ou docid) du document.
Si le document cible implémente une méthode ::getMail(), alors elle sera
utilisée pour renseigner l'émetteur. Sinon, il sera récupéré à partir de
l'attribut US_MAIL du document cible.
Note : Pour l'émetteur, les adresses de groupes ne peuvent être utilisés (il est en effet interdit de spécifier un émetteur multiple au niveau de la norme SMTP.
5.5.1.3 Paramètre de famille texte
Le destinataire est alors dynamique, et est rattaché à un paramètre de la
famille du document. Ce paramètre doit contenir une adresse email dans une
forme acceptable pour le champfrom d'une requête SMTP (ie. de la forme
"nom expéditeur" <mail@host.net).
Note : La notation : n'est pas autorisée pour les paramètres.
5.5.1.4 Paramètre de famille relation
Le destinataire est alors dynamique, et est rattaché à un paramètre de famille de type relation (account ou docid).
Si le document cible implémente une méthode ::getMail(), alors elle sera
utilisée pour renseigner l'émetteur. Sinon, il sera récupéré à partir de
l'attribut US_MAIL du document cible.
Note : Pour l'émetteur, les adresses de groupes ne peuvent être utilisés (il est en effet interdit de spécifier un émetteur multiple au niveau de la norme SMTP.
5.5.1.5 Valeur du workflow lié
5.5.1.5.1 Attribut cycle
Il se comporte comme un attribut texte, mais est récupéré sur le workflow associé au document.
5.5.1.5.2 Relation cycle
Il se comporte comme un attribut relation, mais est récupéré sur le workflow associé au document.
5.5.1.5.3 Paramètre cycle
Il se comporte comme un paramètre de famille texte, mais est récupéré sur la famille du workflow associé au document.
5.5.1.6 Document destinataire
3.2.19 Le destinataire est obtenu dynamiquement, lors de l'envoi du mail, à partir d'un document qui implémente l'interface IMailRecipient.
Les documents sélectionnables dans ce champ sont tous les documents dont la
classe implémente l'interface IMailRecipient.
Le destinataire est obtenu de manière dynamique lors de l'envoi du mail par
l'appel à la méthode ::getMail() de ce document.
5.5.2 Sujet et corps du mail
Le sujet et le corps du mail sont considérés comme des layouts et les balises applicables sont utilisables à l'exception de la balise BLOCK car il n'est pas possible de faire un setBlockData sur un modèle de mail.
De plus, le contrôleur par défaut est appelé avant le rendu du template donc toutes les clefs de ce contrôleur sont disponibles dans le sujet et le corps du mail.
La balise [TITLE] est notamment disponible, elle permet d'intégrer la version textuelle du titre du document associé au template.
5.5.3 Hyperliens
5.5.3.1 Calcul des liens
Les liens sont générés au moyen de la
méthode Doc::getDocAnchor.
Les URLS dans les modèles de mail sont composées à partir de la valeur du
paramètre CORE_MAILACTIONURL, lui-même composé à partir
du paramètre CORE_MAILACTION.
5.5.3.2 Désactivation des liens
Lorsque le mail est envoyé à des personnes qui n'ont pas de compte sur le système d'information, il est inutile de leur envoyer des liens vers des ressources auxquelles ils n'ont pas accès. Il est donc possible de désactiver tous les liens vers les documents, au moyen de l'attribut avec liens, qui doit alors être décoché.
5.5.4 Enregistrement des messages envoyés
Les messages envoyés peuvent être enregistrés. Dans ce cas, le message est stocké dans la famille message envoyé, et son profil est identique à celui du document servant à l'envoi.
Pour stocker le message il faut cocher l'attribut Enregistrer une copie.
Note : Attention, cela peut générer un grand nombre de documents, ce qui peut conduire à terme à une dégradation des performances.
5.5.5 Historique
Pour chaque message envoyé, un message est ajouté à l'historique du document servant à l'envoi. Ce message contient :
- le titre du modèle de mail
- le sujet du message
- les destinataires.
Si une erreur survient lors de l'envoi du message, elle est ajoutée à l'historique du document servant à l'envoi, et est retournée à l'utilisateur.
5.5.6 Limitations
Les messages ainsi générés ne sont pas des listes de diffusion : un seul mail est envoyé. Aussi, lors de l'envoi d'un message à plusieurs destinataires, tous recevront le même message, et il n'est pas possible de personnaliser le message par utilisateur.
Le sujet et le corps du mail ne peuvent pas faire appel à l'instruction BLOCK.
5.6 Minuteur
Les minuteurs permettent de déclencher des actions à des dates prédéfinies. Ces dates peuvent être statiques, ou liées à des valeurs du document qui porte le minuteur.
C'est utile, par exemple, pour répondre à une exigence de la forme :
Le délai de validation par défaut est de 15 jours, mais il est modifiable par l'utilisateur.
5 jours avant la date butoir, un mail de relance est envoyé au valideur
À la date butoir, si le document n'est pas relu, il est passé dans l'état Non validé.
5.6.1 Actions
Un minuteur effectue une séquence d'action. Chaque action peut être :
- un envoi de mail
- un changement d'état
- l'exécution d'une méthode du document portant le minuteur
- une combinaison des 3 types d'actions précédentes. Dans ce cas l'ordre
d'exécution est :
- le changement d'état
- l'envoi de mail
- l'exécution de la méthode.
Chaque action est définie par un délai, et un nombre d'itérations.
5.6.2 Séquençage des actions
- la première itération de la première action est déclenchée à date de référence + délai
- Une fois une itération d'une action effectuée,
- s'il reste des itérations, l'itération suivante sera effectuée à à date de référence + Σ(actions passées x itérations passées )
- s'il ne reste plus d'itération, l'action suivante sera effectuée à à date de référence + Σ(actions passées x itérations passées )
- Une fois toutes les itérations de toutes les actions effectuées, le minuteur est détaché du document.
Si le date de référence est dynamique, le minuteur revient à la première itération à chaque modification de cette date de référence.
5.6.3 Date de référence
Par défaut, la date de référence d'un minuteur est sa date d'attachement au document. Il est possible de modifier cette date de référence de 2 manières :
- Date de référence dynamique
-
La date de référence peut être reliée à un attribut de type date ou timestamp du document auquel est rattaché le minuteur.
Dans ce cas, la date de référence est recalculée à chaque mise à jour du document.
3.2.18 Si la date reliée est vide, le minuteur n'est pas activé. Il reste en attente d'activation jusqu'à ce que cette date reliée soit valorisée. De même, si la date reliée devient vide, les actions du minuteur sont inhibées.
- Décalage de la date de référence
-
Il est possible d'appliquer un delta à cette date de référence, qu'elle soit dynamique ou non. Ce delta peut servir, par exemple, à effectuer une action, N jours avant la date cible : dans ce cas, on appliquera un delta de -N jours.
Ainsi, pour répondre au besoin donné en introduction, on appliquera le paramétrage suivant :
- Lors de l'envoi en validation, la date butoir est demandée à l'utilisateur (et sa valeur par défaut est positionnée à aujourd'hui + 15 jours)
- La date saisie est enregistrée dans l'attribut date_butoir_validation
- Un minuteur est paramétré comme suit :
- date de référence dynamique : date_butoir_validation
- delta : -5 jours
- Action 1 :
- délai : 0
- occurrences : 1
- mail : [le modèle de mail de notre choix]
- changement d'état : aucun
- méthode : aucune
- Action 2 :
- délai : 5 jours
- occurrences : 1
- mail : aucun
- changement d'état : non validé
- méthode : aucune
Note : Le délai peut aussi être négatif. Il est donc également possible d'appliquer le paramétrage suivant :
- Lors de l'envoi en validation, la date butoir est demandée à l'utilisateur (et sa valeur par défaut est positionnée à aujourd'hui + 15 jours)
- La date saisie est enregistrée dans l'attribut date_butoir_validation
- Un minuteur est paramétré comme suit :
- date de référence dynamique : date_butoir_validation
- delta : 0
- Action 1 :
- délai : -5 jours
- occurrences : 1
- mail : [le modèle de mail de notre choix]
- changement d'état : aucun
- méthode : aucune
- Action 2 :
- délai : 0
- occurrences : 1
- mail : aucun
- changement d'état : non validé
- méthode : aucune
5.6.4 Historique
Lors de l’exécution d'une action, une entrée d'historique est ajoutée au document auquel est attaché le minuteur.
5.6.5 Administration
Les minuteurs peuvent être administrés depuis le centre d'administration. (application : DOCADMIN, action : TIMERS_ADMIN).
5.6.6 Programmation
Les minuteurs peuvent être gérés par programmation. Cette programmation permet d'attacher ou de détacher les minuteurs associés à un document.
5.6.7 Gestion des erreurs
Lorsqu'un shell non interactif[^core-ref:shell non interactif] sort en erreur, un mail contenant le détail de l'erreur peut être envoyé.
Ce mail est envoyé uniquement si le paramètre CORE_WSH_MAILTO est non vide.
Lorsque le traitement d'un minuteur provoque une erreur, le document concerné est à nouvau traité par les minuteurs suivants tant que sa date de déclenchement reste valide (voir FDL_TIMERHOURLIMIT).
Chapitre 6 Vues et représentations
Dynacase offre une représentation par défaut pour l'ensemble des éléments (documents, attributs, …). En outre, il est possible de définir ses propres représentations, à plusieurs niveaux :
- la représentation d'un document entier,
- la représentation d'un attribut,
- la représentation d'une rangée de tableau,
- un pied de page,
- une représentation bureautique.
6.1 Utilisation des templates
Les templates utilisés pour les vues de documents sont gérés par la
classe Layout. Cette classe permet de renseigner des
parties variables définies dans un fichier texte.
Le mécanisme de template utilisé dans Dynacase utilise des placeholders de la
forme [keyword].
6.1.1 Valeurs atomiques
Elles sont définies au moyen de la méthode Layout::set. Par exemple :
Le template atomic.xml :
La somme de [X] + [Y] = [XplusY] Le produit de [X] * [Y] = [XfoisY]
Associé au fichier atomic.php :
$lay = new Layout("atomic.xml"); $x=34; $y=78; $lay->set("X",$x); $lay->set("Y",$y); $lay->set("XplusY",$x+$y); $lay->set("XfoisY",$x*$y); print $lay->gen();
Donne :
La somme de 34 + 78 = 112 Le produit de 34 * 78 = 2652
6.1.2 valeurs multiples
Elles sont définies au moyen de la méthode Layout::setBlockData. Par exemple :
Le template multiplication.xml :
Table de multiplication de [X] [BLOCK MUL] - [X] * [Y] = [XfoisY][ENDBLOCK MUL]
Associé au fichier multiplication.php :
$lay = new Layout("multiplication.xml"); $x=3; $tmul = array(); // tableau pour le bloc MUL for ($i=1; $i<10; $i++) { $tmul[] = array( "Y" => $i, "XfoisY" => $i*$x ); } $lay->set("X",$x); $lay->setBlockData("MUL",$tmul); print $lay->gen();
Donne :
Table de multiplication de 3 - 3 * 1 = 3 - 3 * 2 = 6 - 3 * 3 = 9 - 3 * 4 = 12 - 3 * 5 = 15 - 3 * 6 = 18 - 3 * 7 = 21 - 3 * 8 = 24 - 3 * 9 = 27 - 3 * 10 = 30
6.1.3 Conditions
Elles sont définies au moyen de la méthode Layout::set. Par exemple :
Le template cond.xml :
[IF Interdit]Interdit is true[ENDIF Interdit] [IFNOT Interdit]Interdit is false[ENDIF Interdit]
Associé au fichier cond.php :
$lay = new Layout("cond.xml"); $lay->set("Interdit",false);
Donne :
Interdit is false
6.1.4 Internationalisation de texte
Pour rendre du texte traduisible, il faut utiliser la syntaxe
[TEXT:translate me]. Ce texte sera automatiquement ajouté au catalogue de
traduction, et sera remplacé par sa traduction lors du rendu du template.
Pour plus de détail, voir le chapitre Internationalisation.
6.2 Principe d'une vue de document
Les vues de documents permettent de définir la représentation d'un document.
Une vue de document est composée de :
- un fichier de template, définissant la structure,
- un contrôleur de vue permettant de remplir le template. Ce contrôleur est une méthode de la famille qui complète le template.
- Un masque déterminant les visibilités (facultatif).
6.2.1 Syntaxe d'une zone documentaire
Pour référencer une zone documentaire, la syntaxe suivante est utilisée :
APP:DOCVIEW:OPTIONS:TRANSFORMATION, avec les correspondances suivantes :
-
APP(obligatoire) - Le nom de l'application dans laquelle se trouve le template.
-
DOCVIEW(obligatoire) - La nom du template et du contrôleur à utiliser.
-
OPTIONS(facultatif) -
Une option de représentation. ces options dépendent du type de vue :
-
TRANSFORMATION(facultatif) -
Une transformation peut être appliquée après la composition de la vue. Cette transformation est effectuée par le module de transformation.
Il suffit d'indiquer le nom du moteur à utiliser comme
pdfpour une transformation en PDF. La transformation n'est possible qu'avec l'optionB(binary).
Des paramètres supplémentaires peuvent être fournis en utilisant une syntaxe
identique aux paramètres des URL. Les valeurs des paramètres doivent être
encodées comme les URL (l'utilisation de la fonction urlencode est recommandée).
La syntaxe complète avec les paramètres est donc :
APP:DOCVIEW:OPTIONS:TRANSFORMATION?param1=valeur1[¶m=valeur]*.
Ces paramètres supplémentaires sont accessibles depuis le contrôleur avec la
fonction dynacase getHttpVars().
Le couple APP:DOCVIEW indique le template et le contrôleur à utiliser.
- Le fichier template est recherché avec la logique suivante :
- Si
DOCVIEWne comporte pas d'extension, alors l'extension.xmlest ajoutée. - Le fichier template est recherché par la fonction
getLayoutFiledans le répertoireAPP/Layout.- Le fichier est d'abord recherché avec le nom
DOCVIEWtel qu'il est décrit - Si le fichier n'est pas trouvé, le nom en minuscule est recherché.
- Le fichier est d'abord recherché avec le nom
- Si
- Le nom de la méthode est le nom
DOCVIEW.
Dans ce cas, la casse du nom de la méthode n'est pas prise en compte (comme pour les méthodes de PHP en général).
Exemples :
| Identifiant de zone | Template valide | Contrôleur valide |
|---|---|---|
FDL:EDITBODYCARD |
FDL/Layout/EDITBODYCARD.xml | ::editbodycard() |
| FDL/Layout/editbodycard.xml | ::editBodyCard() | |
FDL:VIEWBODYCARD:T |
FDL/Layout/VIEWBODYCARD.xml | ::viewBodyCard() |
| FDL/Layout/viewbodycard.xml | ::viewbodycard() | |
MYAPP:myview.html |
MYAPP/Layout/myview.html | ::myView() |
MYAPP:MYVIEW?extra=yes |
MYAPP/Layout/MYVIEW.xml | ::myview() |
MYAPP:mySimpleview.html |
MYAPP/Layout/mysimpleview.html | ::mySimpleView() |
6.2.2 Définition de la vue de consultation
Lors de la consultation d'un document, Dynacase génère une page html complète. Cette page est structurée comme suit :
+-------------------------------------------------+ | FDL:FDL_CARD | |-------------------------------------------------| | | | +-------------------------------------------+ | | | FDL:VIEWCARD | | | |-------------------------------------------| | | | | | | | +-------------------------------------+ | | | | | Vue de document (FDL:VIEWBODYCARD) | | | | | |-------------------------------------| | | | | | | | | | | | | | | | | | | | | | | +-------------------------------------+ | | | | | | | +-------------------------------------------+ | | | +-------------------------------------------------+
Pour plus de précisions, se reporter à la liste des Zones de référence.
La vue de consultation par défaut est la zone FDL:VIEWBODYCARD. Elle utilise
donc le template FDL/Layout/viewbodycard.xml et le contrôleur
Doc::viewbodycard().
L'url ?app=FDL&action=FDL_CARD&id=9 affiche le document avec sa vue par défaut.
Si la famille ne comporte pas de paramétrage spécifique de vue, cette url est
équivalente à ?app=FDL&action=FDL_CARD&id=9&zone=FDL:VIEWBODYCARD
6.2.2.1 Options des vues documentaires en consultation
Les options disponibles en consultation sont les suivantes :
V-
Pour les squelettes HTML, il signifie que le document est affiché comme suit :
- inclusion des CSS systèmes Dynacase,
- pas de titre, pas d'icônes,
- affichage de la barre de menus.
T-
Pour les squelettes HTML, il signifie que le document est affiché comme suit :
- inclusion des CSS systèmes Dynacase,
- pas de titre, pas d'icônes,
- pas de barre de menus.
U-
Pour les squelettes HTML, il signifie que le document est affiché comme suit :
- pas d'inclusion des CSS systèmes Dynacase,
- pas de titre, pas d'icônes,
- pas de barre de menus.
S- Signifie que la zone documentaire est autonome, qu'elle ne nécessite pas
d'encapsulation HTML. Cette option est obligatoire pour tous les
templates non HTML.
Lorsque cette option est utilisée avec un template html, la zone doit générer une page complète. B- Pour les squelettes non HTML binaires.
Cas notamment des fichiers openDocumentText (
*.odt). Dans ce cas le retour de la vue par la méthodeDoc::viewDoc()est le nom d'un fichier temporaire et non le contenu comme pour les zones textuelles.
6.2.3 Définition de la vue de modification
Lors de la modification d'un document, Dynacase génère une page html complète. Cette page est structurée comme suit :
+-------------------------------------------------+ | GENERIC:GENERIC_EDIT | |-------------------------------------------------| | | | +-------------------------------------------+ | | | FDL:EDITCARD | | | |-------------------------------------------| | | | | | | | +-------------------------------------+ | | | | | Vue de document (FDL:EDITBODYCARD) | | | | | |-------------------------------------| | | | | | | | | | | | | | | | | | | | | | | +-------------------------------------+ | | | | | | | +-------------------------------------------+ | | | +-------------------------------------------------+
La vue de modification par défaut est la zone documentaire FDL:EDITBODYCARD.
Elle utilise donc le template FDL/Layout/editbodycard.xml et le contrôleur
Doc::editbodycard().
La vue de modification de document est toujours rendue encapsulée dans
FDL:EDITCARD,elle-même rendue au sein de GENERIC:GENERIC_EDIT. Aussi
cette vue retourne un fragment de formulaire, qui est inséré dans
le form de la page.
6.2.3.1 Options des vues documentaires en modification
Les options disponibles en modification sont les suivantes :
S-
Le document est affiché comme suit :
- l'entête n'est pas affiché,
- les boutons sauver et annuler ne sont pas affichés.
V-
Le document est affiché comme pour
S(Obsolète) utilisé pour compatibilité version précédente.
U- Le squelette est affiché de manière brute et n'est pas encapsulé dans un formulaire.
T-
Le document est affiché comme suit :
- l'entête n'est pas affiché,
- les boutons sauver et annuler sont affichés
6.3 Vue spécifique de document
La définition d'une nouvelle vue de document nécessite un contrôleur de vue et un template.
Le contrôleur de vue peut être omis. Dans ce cas, Dynacase fera appel au contrôleur de vue par défaut.
6.3.1 Le contrôleur de vue
Pour qu'une méthode du document soit utilisable en tant que contrôleur d'une
vue, il est nécessaire de lui ajouter la phpDoc @templateController afin
de se prémunir d'une éventuelle exécution arbitraire de code.
Les paramètres reçus par la méthode sont au nombre de 3 :
-
$target(string) : nom de la fenêtre graphique qui est utilisée pour les hyperliens ("_self"par défaut), -
$ulink(booléen) : indique s'il faut générer les hyperliens (truepar défaut), -
$abstract(booléen) : indique s'il faut générer uniquement les attributs de la fiche résumé (falsepar défaut).
Par convention :
- le fichier de template porte l'extension
.xml, - son nom (en minuscule) détermine le nom de la vue,
- la méthode associée doit porter le même nom (la casse du nom de la méthode
n'est pas prise en compte).
L'objetLayoutest accessible au moyen de la propriétélayde l'objet courant ($this->lay).
Par exemple, considérons la méthode mySpecialView :
/** * default view for a family * @templateController special view * @return void */ function mySpecialView($target = "_self", $ulink = true, $abstract = false) { $this->viewdefaultcard($target, $ulink, $abstract); $myItems = $this->getMultipleRawValues("my_items"); $items = array(); foreach ($myItems as $cle => $val) { $items[] = array( "itemValue" => $val ); } $this->lay->setBlockData("ITEMS", $items); }
Le template associé peut être :
MYAPP/Layout/myspecialview.xml
<ol>[TEXT:myapp:List of items] [BLOCK ITEMS]<li>[itemValue]</li>[ENDBLOCK ITEMS] </ol>
6.3.2 Vue spécifique de consultation
La vue spécifique d'un document doit retourner un fragment HTML qui est inclus dans le corps de la page HTML.
La vue personnalisée est toujours rendue encapsulée dans FDL:VIEWCARD, elle-
même rendue au sein de FDL:FDL_CARD(sauf si l'option S
est utilisée) . Aussi cette vue personnalisée doit générer un fragment qui est
inséré dans le body de la page HTML.
+-------------------------------------------------+ | FDL:FDL_CARD | |-------------------------------------------------| | | | <body>... | | | | +-------------------------------------------+ | | | FDL:VIEWCARD | | | |-------------------------------------------| | | | | | | | <div> | | | | | | | | +-------------------------------------+ | | | | | Vue spécifique de document | | | | | |-------------------------------------| | | | | | | | | | | | | | | | | | | | | | | +-------------------------------------+ | | | | | | | | </div> | | | | | | | +-------------------------------------------+ | | | | </body> | | | +-------------------------------------------------+
Afin de définir une vue personnalisée, il est possible :
- d'utiliser un contrôle de vue,
- de spécifier une zone en paramètre HTTP : pour ce faire, il suffit de passer
l'identifiant de la zone documentaire dans le paramètre
zonede l'url d'accès au document, - d'indiquer la zone documentaire dans l'attribut
defaultViewdu fichier CLASS de la famille pour avoir cette vue par défaut lors de la consultation.
public $defaultView='MYAPP:MYSPECIALVIEW'
6.3.2.1 Contrôleur par défaut
6.3.2.1.1 Définition du contrôleur par défaut
En l'absence de méthode correspondant à la vue, le contrôleur par défaut
Doc::viewDefaultCard() est appelé.
Ce contrôleur est fait pour les vues de consultations et n'est pas adapté pour les vues de modification.
6.3.2.1.2 Utilisation des valeurs du document
Le contrôleur par défaut fait automatiquement appel
aux méthodes Doc::viewAttr() et Doc::viewProp(). Elles
initialisent les clés suivantes :
- viewAttr va créer :
-
L_ATTRIDpour chaque attribut : le libellé (traduit) de l'attribut, -
V_ATTRIDpour chaque attribut : la valeur (au format html) de l'attribut, -
S_ATTRIDpour chaque attribut :truesi l'attribut est vide,falsesinon
-
- viewProp va créer :
-
ATTRIDpour chaque attribut : la valeur brute de l'attribut, -
PROPIDpour chaque propriété : la valeur brute de la propriété, -
V_TITLEune ancre vers le document lui-même avec son titre.
-
Note : Toutes ces clefs sont en majuscules.
Lors de l'utilisation d'un contrôleur personnalisé, il est possible d'appeler
ces méthodes afin de générer les clés correspondantes. Il est également possible
de définir d'autres clés en utilisant les différentes méthodes du Layout.
Attention : toutes ces clés respectent les visibilités : si la visibilité
d'un attribut est H pour un utilisateur, les clés L_ATTRID et V_ATTRID
sont des chaînes vides. S_ATTRID, pour sa part, n'est pas affecté par les
visibilités.
Exemple d'un template sans contrôleur :
MYAPP/Layout/mysimpleview.xml
<h1>[V_TITLE]</h1> <p>L'attribut [L_MY_TEXT] a la valeur : <strong>[V_MY_TEXT]</strong></p>
Dans cet exemple l'attribut MY_TEXT fait partie de la définition du document.
6.3.3 Vue spécifique de modification
Le template d'une vue de modification s'insère dans un formulaire HTML. Il est composé de champs de formulaire afin de permettre à l'utilisateur d'effectuer la saisie.
Il est aussi possible d'ajouter des css et des js spécifique
(Se reporter au chapitre Moteur de template).
+-------------------------------------------------+ | GENERIC:GENERIC_EDIT | |-------------------------------------------------| | | | <body> | | | | +-------------------------------------------+ | | | FDL:EDITCARD | | | |-------------------------------------------| | | | | | | | <form> | | | | | | | | +-------------------------------------+ | | | | | Vue spécifique de formulaire | | | | | |-------------------------------------| | | | | | | | | | | | | | | | | | | | | | | +-------------------------------------+ | | | | | | | | </form> | | | | | | | +-------------------------------------------+ | | | | </body> | | | +-------------------------------------------------+
6.3.3.1 Utilisation des champs de formulaire du document
Pour les vues de modifications de documents, le contrôleur par défaut n'est pas adapté car il ne fournit que des valeurs d'attributs et non des champs de saisie pour un formulaire.
Pour avoir l'équivalent du contrôleur par défaut en modification il faut
utiliser la méthode Doc::editAttr. Cette méthode initialise les clés
suivantes :
-
L_ATTRIDpour chaque attribut : le libellé (traduit) de l'attribut, (entouré d'une balise<b/>si l'attribut est obligatoire), -
V_ATTRIDpour chaque attribut : un input pour l'attribut, -
W_ATTRIDpour chaque attribut :truesi l'attribut est visible,falsesinon.
Note : Toutes ces clefs sont en majuscules.
Attention : toutes ces clés respectent les visibilités : si l'attribut a
une visibilité H (caché) pour l'utilisateur, la clé V_ATTRID génère un
<input value="the value" type="hidden"/>. Si la visibilité est I (invisible)
aucun champ n'est retourné. Les clés L_ATTRID ne sont pas affectées par la
visibilité.
Lors de l'utilisation d'un contrôleur personnalisé, il est possible d'appeler
ces méthodes afin de générer les clés correspondantes. Il est également possible
de définir d'autres clés en utilisant les différentes méthodes du Layout.
6.3.3.2 Utilisation d'un contrôleur spécifique de modification
Le contrôleur de modification n'est applicable qu'au formulaire HTML.
/** * default edit for a family * @templateController special edit * @return void */ function mySpecialEdit($target = "_self", $ulink = true, $abstract = false) { $this->lay->set("textValue", $this->getRawValue("my_text")); $textAttribute=$this->getAttribute("my_text"); $this->lay->set("textLabel", $textAttribute->getLabel()); }
Le template associé peut être :
MYAPP/Layout/myspecialedit.xml
<h1>Modifier la valeur de [textLabel]</h1> <input name="_my_text" value="[textValue]"/>
Le nom (attribut name) des champs de formulaire doit être précédé de _
(underscore) pour être pris en compte lors de la soumission de façon automatique.
Sinon, il est possible de récupérer tout autre champ dans le hook preStore
avec la fonction getHttpVars().
6.4 Vue d'attribut
Les vues d'attribut permettent de définir la représentation d'un attribut. Elles peuvent être utilisées lorsque la représentation par défaut du document correspond, à l'exception de quelques attributs isolés.
Les vues d'attributs sont déclarées au moyen des options :
-
viewtemplate: pour les vues de consultation, -
edittemplate: pour les vues de modification.
Une vue d'attribut est composée de :
- un fichier de template, définissant la structure,
- une méthode (appelée contrôleur de vue) du document à représenter,
définissant les valeurs.
Cette méthode peut également être omise. dans ce cas, dynacase fait appel au contrôleur de vue par défaut.
Par convention :
- le fichier de template porte l'extension
.xml, - son nom détermine le nom de la vue,
- la méthode associée doit porter le même nom.
L'objetLayoutest accessible au moyen de la propriétélayde l'objet courant ($this->lay).
6.4.1 Le contrôleur de vue d'attribut
Pour qu'une méthode du document soit utilisable en tant que contrôleur d'une
vue, il est nécessaire de lui ajouter la phpDoc @templateController afin
de se prémunir d'une éventuelle exécution arbitraire de code.
Les paramètres reçus par la méthode sont au nombre de 3 :
-
$target(string) : nom de la fenêtre graphique qui est utilisée pour les hyperliens ("_self"par défaut) , -
$ulink(booléen) : indique s'il faut générer les hyperliens (truepar défaut) , -
$abstract(booléen) : indique s'il faut générer uniquement les attributs de la fiche résumé (falsepar défaut).
6.4.1.1 Contrôleur d'attributs par défaut
En l'absence de méthode correspondant à la vue, le contrôleur d'attributs par défaut est appelé. Cette méthode dépend de l'option :
-
viewtemplate: en consultation, la méthode appelée estDoc::viewDefaultCard, -
edittemplate: en modification, la méthode appelée estDoc::viewPropsuivi deDoc::editAttr.
6.4.2 Syntaxe d'une zone de vue d'attribut
Une zone de vue d'attribut s'exprime sous la forme APP:DOCVIEW:OPTIONS :
-
APP(obligatoire) - Le nom de l'application dans laquelle se trouve le template.
-
DOCVIEW(obligatoire) - La nom du template et du contrôleur à utiliser.
-
OPTIONS(facultatif) -
Une option de représentation. ces options dépendent du type de vue :
Des paramètres supplémentaires peuvent être fournis en utilisant une syntaxe
identique aux paramètres des URL. Les valeurs des paramètres doivent être
encodés comme les URL (l'utilisation de la fonction urlencode est recommandée).
La syntaxe complète avec les paramètres est donc :
APP:DOCVIEW:OPTIONS?param1=valeur1[¶m=valeur]*.
Ces paramètres supplémentaires sont accessibles depuis le contrôleur avec la
fonction getHttpVars().
Le couple APP:DOCVIEW indique le template et le contrôleur à utiliser.
- Le fichier template est recherché avec la logique suivante :
- Si
DOCVIEWne comporte pas d'extension, alors l'extension.xmlest ajoutée. - Le fichier template est recherché par la fonction
getLayoutFiledans le répertoireAPP/Layout.- Le fichier est d'abord recherché avec le nom
DOCVIEWtel qu'il est décrit - Si le fichier n'est pas trouvé, le nom en minuscule est recherché.
- Le fichier est d'abord recherché avec le nom
- Si
- Le nom de la méthode est le nom
DOCVIEW.
Dans ce cas, la casse du nom de la méthode n'est pas prise en compte (comme pour les méthodes de PHP en général).
6.4.3 Vue de consultation d'attribut
La vue d'attribut remplace la valeur d'un attribut.
Elle s'insère à la place de la valeur d'un attribut depuis la zone
FDL:VIEWBODYCARD.
Extrait d'une consultation de document avec la zone FDL:VIEWBODYCARD :
<table> <tr> <td>Label 1</td> <td>:</td> <td>valeur 1</td> </tr> <tr> <td>Label 2</td> <td>:</td> <td>valeur 2</td> </tr> </table>
Afin de spécifier la vue d'attribut à utiliser en consultation, il faut utiliser
l'option viewtemplate. Si l'attribut n°2 a une vue d'attribut le document de
consultation est :
<table> <tr> <td>Label 1</td> <td>:</td> <td>valeur 1</td> </tr> <tr> <td>Label 2</td> <td>:</td> <td>ICI LE RESULTAT DE LA VUE D'ATTRIBUT</td> </tr> </table>
La vue d'attribut est présentée dans une cellule de tableau HTML comme représenté ci-dessous.
| Label1 | : | Valeur1 |
| Label2 | : | ICI LE RESULTAT DE LA VUE D'ATTRIBUT |
Si l'option est portée sur un attribut tableau (array), la vue remplace tout
le tableau.
Si l'option est portée sur un attribut cadre (frame) la vue remplace tout le
contenu du cadre mais le contour avec le libellé est conservé.
6.4.3.1 Options des vues d'attribut en consultation
Les options disponibles en consultation sont les suivantes :
S-
signifie que le libellé de l'attribut n'est pas affiché et le template prend toute la largeur du document. Cette option n'est pas applicable si l'attribut est de type
frame.Dans ce cas le document de consultation est :
<table> <tr> <td>Label 1</td> <td>:</td> <td>valeur 1</td> </tr> <tr> <td colspan="3">ICI LE RESULTAT DE LA VUE D'ATTRIBUT POUR L'ATTRIBUT N°2</td> </tr> </table>
La vue d'attribut avec l'option
Sest présentée dans une cellule de tableau HTML comme représenté ci-dessous :Label 1 : valeur 1 ICI LE RESULTAT DE LA VUE D'ATTRIBUT
POUR L'ATTRIBUT N°2
6.4.3.2 Utilisation des valeurs du document en consultation
Le contrôleur par défaut fait automatiquement appel
aux méthodes Doc::viewAttr et Doc::viewProp. Elles initialisent les clés
suivantes :
- viewAttr va créer :
-
L_ATTRIDpour chaque attribut : le libellé (traduit) de l'attribut, -
V_ATTRIDpour chaque attribut : la valeur (au format html) de l'attribut, -
S_ATTRIDpour chaque attribut :truesi l'attribut est vide,falsesinon
-
- viewProp va créer :
-
ATTRIDpour chaque attribut : la valeur brute de l'attribut -
PROPIDpour chaque propriété : la valeur brute de la propriété -
V_TITLEune ancre vers le document lui-même avec son titre
-
Note : Toutes ces clefs sont en majuscules.
Lors de l'utilisation d'un contrôleur personnalisé, il est possible d'appeler
ces méthodes afin de générer les clés correspondantes. Il est également possible
de définir d'autres clés en utilisant les différentes méthodes du Layout.
Attention : Toutes ces clés respectent les visibilités : si la visibilité
d'un attribut est H pour un utilisateur, les clés L_ATTRID et V_ATTRID
seront des chaînes vides. S_ATTRID, pour sa part, n'est pas affecté par les
visibilités.
Exemple d'un template d'attribut sans contrôleur :
MYAPP/Layout/mySpecialText.html
<h2> La valeur de [L_MY_TEXT] est <strong>[V_MY_TEXT]</strong> </h2>
Dans cet exemple le template est associé à l'attribut MY_TEXT avec l'option
viewtemplate=MYAPP:mySpecialText.html.
6.4.3.3 Utilisation d'un contrôleur d'attribut spécifique
Le contrôleur d'attribut est identique à un contrôleur de vue de documents.
La seule différence est qu'il ne contrôle qu'un attribut ou un ensemble d'attributs dans le cas d'un tableau ou d'un cadre.
Exemple :
Class.MyFamily.php
namespace My; class MyFamily extends \Dcp\Family\Documents { /** * Affiche le nombre sur 3 chiffres * @templateController affichage en rouge si négatif, en vert sinon */ public function mySpecialNumber($target = "_self", $ulink = true, $abstract = false) { $number=$this->getRawValue("my_number"); if ($number > 0) { $this->lay->set("color", "green"); } else { $this->lay->set("color", "red"); } $this->lay->set("theNumber", sprintf("%.03d",$number)); } }
MYAPP/Layout/mySpecialNumber.html
<h2> La valeur est <strong style="color:[color]">[theNumber]</strong> </h2>
Dans cet exemple le template est associé à l'attribut MY_NUMBER avec l'option
viewtemplate=MYAPP:mySpecialNumber.html.
La méthode mySpecialNumber() est déclarée dans le fichier CLASS
de la famille.
6.4.4 Vue de modification d'attribut
La vue d'attribut remplace le champ de saisie d'un attribut du formulaire.
Elle s'insère à la place de la valeur d'un attribut depuis la zone
FDL:EDITBODYCARD.
Extrait d'un formulaire de document avec la zone FDL:EDITBODYCARD :
<table> <tr> <td>Label 1 :</td> <td><input value="Value 1"/> …</td> <td><input type="button"/> aide à la saisie/ extra link </td> </tr> </table> <table> <tr> <td>Label 2</td> <td><input value="Value 2">…</td> <td><input type="button"/> aide à la saisie/ extra link </td> </tr> </table>
Afin de spécifier la vue d'attribut à utiliser en modification, il faut utiliser
l'option edittemplate.
La vue d'attribut remplace le champ de saisie de l'attribut.
Si l'attribut n°2 a une vue d'attribut le formulaire de saisie est :
<table> <tr> <td>Label 1 :</td> <td><input value="Value 1"/>…</td> <td><input type="button"/> aide à la saisie/ extra link </td> </tr> </table> <table> <tr> <td>Label 2</td> <td>ICI LE RESULTAT DE LA VUE D'ATTRIBUT</td> </tr> </table>
La vue d'attribut est présentée dans une cellule de tableau HTML comme représenté ci-dessus. Le template d'un champ doit retourner deux éléments :
- le champ de saisie,
- les éventuelle boutons de contrôle.
Ces éléments doivent être séparé par des éléments de cellule </td><td>, car au
final le tableau doit comporter trois colonnes pour avoir un alignement correct.
6.4.4.1 Options des vues d'attribut en modification
Les options disponibles en modification sont les suivantes :
S-
Signifie que le libellé de l'attribut ne est pas affiché et le template prend toute la largeur du document.
L'insertion se fait dans le fragment html suivant :
<table> <tr> <td>Label 1 :</td> <td><input value="Value 1"/> ...</td> <td><input type="button"/> aide à la saisie/ extra link </td> </tr> </table> <table> <tr> <td colspan="3">ICI LE RÉSULTAT DE LA VUE D'ATTRIBUT </td> </tr> </table>
U-
Signifie que l'input généré par le mot-clef
[V_ATTRNAME]prend toute la largeur disponible. Elle n'ajoute pas de</td><td>supplémentaire. Cette option est à utiliser si les mots-clefs[V_ATTRNAME]sont présents dans le template.<table> <tr> <td>Label 1 :</td> <td><input value="Value 1"/> ...</td> <td><input type="button"/> aide à la saisie/ extra link </td> </tr> </table> <table> <tr> <td>Label 2 :</td> <td>RÉSULTAT DE LA VUE SANS AUTRE TD : Tableau à 2 cellules</td> </tr> </table>
6.4.4.2 Utilisation des valeurs du document en modification
le contrôleur par défaut fait automatiquement appel
aux méthodes Doc::editAttr et Doc::viewProp. Elles initialisent les clés
suivantes :
- editAttr va créer :
-
L_ATTRIDpour chaque attribut : le libellé (traduit) de l'attribut, entouré d'une balise<b/>si l'attribut est obligatoire), -
V_ATTRIDpour chaque attribut : un input pour l'attribut, -
W_ATTRIDpour chaque attribut :truesi l'attribut est visible,falsesinon.
-
- viewProp va créer :
-
ATTRIDpour chaque attribut : la valeur brute de l'attribut -
PROPIDpour chaque propriété : la valeur brute de la propriété -
V_TITLEune ancre vers le document lui-même avec son titre
-
Lors de l'utilisation d'un contrôleur personnalisé, il est possible d'appeler
ces méthodes afin de générer les clés correspondantes. Il est également possible
de définir d'autres clés en utilisant les différentes méthodes du Layout.
Les clefs V_ATTRID fournies par Doc::editattr() retournent par défaut les 2
élements champ de saisie et boutons de contrôle séparés par </td><td>
pour une insertion dans le formulaire. La méthode Doc::editAttr() possède un
argument qui permet d'omettre le séparateur </td><td> pour des constructions
de vues plus spécialisées.
Attention : toutes ces clés respectent les visibilités : si l'utilisateur
n'a pas le droit de voir un attribut, la clé V_ATTRID génère un
<input type="hidden"/>. Les clés L_ATTRID ne sont pas affectées par la
visibilité.
Exemple :
Class.MyFamily.php
namespace My; class MyFamily extends \Dcp\Family\Documents { /** * Affiche le nombre sur 3 chiffres * @templateController affichage en rouge si négatif, en vert sinon */ public function myEditSpecialNumber($target = "_self", $ulink = true, $abstract = false) { $this->editAttr(); } }
MYAPP/Layout/myEditSpecialNumber.html
Nombre à saisir
[V_MY_NUMBER]
Dans ce cas le résultat est :
<table> <tr> <td>Label 1 :</td> <td><input value="Value 1"/> ...</td> <td><input type="button"/> aide à la saisie/ extra link </td> </tr> </table> <table> <tr> <td>My number</td> <td>Nombre à saisir <input name=_"my_number" value="45"/></td><td></td> </tr> </table>
Ce qui donne la représentation suivante :
| Label 1 : | ||
| My number | Nombre à saisir |
6.4.5 Limitations
Les vues d'attribut ne sont pas gérées par Dynacase dans les vues de document
personnalisées. Elles ne sont utilisées que dans les vues FDL:VIEWBODYCARD
pour la consultation et FDL:EDITBODYCARD pour la modification.
Chaque vue d'attribut utilise la même instance de l'objet Doc
correspondant au document en cours de consultation ou de modification.
Les vues d'attributs ne sont pas applicables aux attributs de type tab, ni
aux attributs insérés dans un tableau. Dans ce dernier cas, il faut utiliser une
vue de tableau.
6.5 Vue de rangée de tableau
Les vues de rangée de tableau permettent de mettre en forme un tableau. Cela est particulièrement utile pour des tableaux contenant beaucoup d'attributs, ou dont la structure est complexe. Il est ainsi possible de changer la disposition des éléments pour, par exemple, regrouper plusieurs attributs dans la même colonne.
Contrairement aux vues de document, ou aux vues d'attribut, les vues de rangée de tableau ne contiennent pas de code. Elles sont donc uniquement composées de :
- un fichier de template, définissant la structure.
Par convention :
- le fichier de template porte l'extension
.xml, - son nom détermine le nom de la vue.
6.5.1 Syntaxe du template de rangée de tableau
Un template de vue de rangés de tableau est un fichier XML valide.
Il doit respecter la DTD suivante :
<!ELEMENT table (table-head*,table-body*)>
<!ELEMENT table-head (cell)*>
<!ELEMENT table-body (cell)*>
<!ELEMENT cell ANY>
<!ATTLIST cell
class CDATA #IMPLIED
style CDATA #IMPLIED>
]>
Voici un exemple de fichier valide (ici, la DTD est déclarée inline, mais elle n'est pas obligatoire) :
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE table [ <!ELEMENT table (table-head*,table-body*)> <!ELEMENT table-head (cell)*> <!ELEMENT table-body (cell)*> <!ELEMENT cell ANY> <!ATTLIST cell class CDATA #IMPLIED style CDATA #IMPLIED> ]> <table> <table-head> <cell>…</cell> </table-head> <table-body> <cell>…</cell> </table-body> </table>
- Le bloc
table-headdéfinit letheaddu tableau généré, - le bloc
table-bodydéfinit une rangéetrdutbodydu tableau généré. - Chaque balise
celldéfinit une cellule et est donc retranscrite sous la forme d'une balisetd.- les attributs
styleetclassde la balisecellsont transmis tels-quels à la balisetdrésultante, - les autres attributs sont ignorés,
- le contenu de la balise
tdrésultante est exactement le contenu de la balisecell. ce dernier doit donc être du xhtml valide.
Attention : puisque le document est interprété en XML pur, pour utiliser des entités HTML, il faut les déclarer dans la DTD (par exemple:<!ENTITY nbsp " ">).
- les attributs
6.5.2 Vue de consultation de rangée de tableau
La représentation spécifique de tableaux est insérée en lieu et place de la représentation standard de tableau.
La représentation standard d'un tableau en consultation est :
<fieldset ><legend>Nom du tableau</legend> <table> <thead> <tr><th>Label 1</th><th>Label 2</th></tr> </thead> <tbody> <tr><td>Valeur 1.1</td><td>Valeur 2.1</td></tr> <tr><td>Valeur 1.2</td><td>Valeur 2.2</td></tr> </tbody> </table> </fieldset>
Afin de spécifier la vue d'attribut à utiliser en consultation, il faut utiliser
l'option rowviewzone.
6.5.2.1 Utilisation des valeurs du document
Lors de l'utilisation des vues de rangés de tableau, les clés suivantes sont instanciées :
-
L_ATTRIDpour chaque attribut : le libellé (traduit) de l'attribut, -
V_ATTRIDpour chaque attribut : la valeur (au format HTML) de l'attribut.
Attention : les clés V_ATTRID respectent les visibilités : si la
visibilité est H (caché) ou I (invisible) ou
O (écriture seule), les clés V_ATTRID sont des chaînes vides. Les clés
L_ATTRID ne sont pas affectées par la visibilité.
De plus, il est possible, comme dans tous les templates, d'utiliser :
- les paramètres globaux,
- les chaînes traduisibles (syntaxe
[TEXT:…]).
Exemple :
Le template suivant :
<?xml version="1.0"?> <table> <table-head> <cell class="special">[TEXT:Identification]</cell> <cell style="background-color:[COLOR_C3]">[L_MY_NUMBERS]</cell> </table-head> <table-body> <cell style="background-color:[COLOR_B6]"> <b>[V_MY_NUMBERID]</b><br/>[V_MY_NUMBERLABEL] </cell> <cell style="background-color:[COLOR_C5];text-align:center"> [V_MY_NUMBERS] </cell> </table-body > </table>
produit pour l'exemple le code HTML suivant :
<fieldset ><legend>Nom du tableau</legend> <table> <thead> <tr><th class="special">Identification</th> <th style="background-color:#E5DD57">Mes nombres</th></tr> </thead> <tbody> <tr><td style="background-color:#8EC5F4"><b>1.1</b><br/>numéro 1</td> <td style="background-color:#EDE787;text-align:center">001</td></tr> <tr><td style="background-color:#8EC5F4"><b>1.2</b><br/>numéro 2</td> <td style="background-color:#EDE787;text-align:center">002</td></tr> </tbody> <table> </fieldset>
Ce qui représente le tableau suivant :
| Identification | Mes nombres |
|---|---|
|
1.1 numéro 1 |
001 |
|
1.2 numéro 2 |
002 |
6.5.3 Vue de modification de rangée de tableau
Afin de spécifier la vue d'attribut à utiliser en modification, il faut utiliser
l'option roweditzone.
La représentation standard d'un tableau en modification est :
<fieldset ><legend>Nom du tableau</legend> <table> <thead> <tr><th class="tools"/> <th colspan="2">Label 1</th> <th colspan="2">Label 2</th></tr> </thead> <tbody> <tr><td>tools inputs</td> <td>Champ n°1.1</td><td>Boutons Champ n°1.1</td> <td>Champ n°1.2</td><td>Boutons Champ n°1.2</td> <tr><td>tools inputs</td> <td>Champ n°2.1</td><td>Boutons Champ n°2.1</td> <td>Champ n°2.2</td><td>Boutons Champ n°2.2</td></tr> </tbody> <tfoot> … autres champs cachés … </tfoot> </table> </fieldset>
6.5.3.1 Utilisation des champs de saisie du document
Lors de l'utilisation des vues de rangés de tableau, les clés suivantes sont instanciées :
-
L_ATTRIDpour chaque attribut : le libellé (traduit) de l'attribut, -
V_ATTRIDpour chaque attribut : le champs de saisie correspondant à l'attribut,
Attention : les clés V_ATTRID respectent les visibilités : si la
visibilité est H (caché) ou R (lecture seule) les clefs sont
des champs cachés <input type="hidden" />.
Si la visibilité est I (invisible), les clés V_ATTRID sont des chaînes
vides. Les clés L_ATTRID ne sont pas affectées par la visibilité.
De plus, il est possible, comme dans tous les templates, d'utiliser :
- les paramètres globaux,
- les chaînes traduisibles (syntaxe
[TEXT:…]).
Le template suivant :
<?xml version="1.0"?> <table> <table-head> <cell class="special">[TEXT:Identification]</cell> <cell style="background-color:[COLOR_C3]">[L_MY_NUMBERS]</cell> </table-head> <table-body> <cell style="background-color:[COLOR_B6]"> <b>[V_MY_ROMANNUMBER]</b> <br/> [V_MY_NUMBERLABEL] </cell> <cell> <span>style="text-align:center">[V_MY_NUMBERS]</span> </cell> </table-body > </table>
produit pour l'exemple le code HTML suivant :
À la différence d'un tableau standard, les champs de saisie d'attribut ne sont
plus répartis sur deux cellules mais sur une seule cellule (plus de colspan)
dans l'entête de tableau.
<fieldset ><legend>Nom du tableau</legend> <table> <thead> <tr><th class="tools"/> <th class="special">Identification</th> <th style="background-color:#E5DD57"> Mes nombres</th></tr> </thead> <tbody> <tr><td>Tool inputs</td> <td style="background-color:#8EC5F4"> <b><input name="_my_romannumber[]" value="1.1"/> </b><br/> <input name="_my_numberlabel[]" value="numéro 1"/> <input type="button" value="..." /><input type="button" value="x" /> </td> <td><span style="text-align:center"> <input name="_my_numbers[]" value="1"/> <input type="button" value="..." /><input type="button" value="x" /> </span></td></tr> <tr>...Deuxième rangée...</tr> </tbody> <tfoot> ... autres champs cachés ... </tfoot> </table> </fieldset>
Cet exemple produit la représentation suivante :
6.6 Vue OpenDocument Text
Une vue openDocument text permet de générer une représentation bureautique du document. Cette représentation est au format odt, et peut être convertie en pdf, ou autre format bureautique, au moyen du moteur de transformation.
Étant donné que cette représentation est binaire, il y a de nombreuses différences entre les vues openDocument text et les représentations html.
Il est à noter que les vues openDocument text ne sont utilisables que pour la consultation.
Une vue openDocument text est composée de :
- un fichier de template (au format odt), définissant la structure,
- une méthode (appelée contrôleur de vue) du document à représenter,
définissant les valeurs.
Cette méthode peut également être omise. Dans ce cas, dynacase fera appel au contrôleur de vue par défaut.
La syntaxe de la zone documentaire d'une vue openDocument
text doit obligatoirement comporter l'option binaire (option B).
Exemple :
MY_APP:my_Document.odt:B
Dans cet exemple le fichier MY_APP/Layout/my_Document.odt sera utilisé comme
template.
6.6.1 Référence d'un template à partir d'un paramètre de famille
Si la famille possède un paramètre de type file. Celui-ci peut être utilisé
comme template. Dans ce cas, la syntaxe de la zone est de la forme :
THIS:MY_ARGFILE:B
Dans cet exemple MY_ARGFILE peut être soit un paramètre de la famille, soit un
attribut du document.
Si le paramètre ou l'attribut est un attribut fichier inclus dans un tableau, il est nécessaire d'ajouter l'index pour préciser le template :
THIS:MY_ARGFILES[2]:B
Dans cet exemple, le template est la troisième valeur de l'attribut multiple
MY_ARGFILES.
6.6.2 Le contrôleur de vue
Pour qu'une méthode du document soit utilisable en tant que contrôleur d'une
vue, il est nécessaire de lui ajouter la phpDoc @templateController afin
de se prémunir d'une éventuelle exécution arbitraire de code.
Les paramètres reçus par la méthode sont au nombre de 3 :
-
$target(string) : toujours"ooo"(ne sert que pour les vues non odt), -
$ulink(booléen) : toujoursfalse(ne sert que pour les vues non odt), -
$abstract(booléen) : indique s'il faut générer uniquement les attributs de la fiche résumé (falsepar défaut).
Par convention :
- le fichier de template porte l'extension
odt, - son nom (en minuscule) détermine le nom de la vue,
- la méthode associée doit porter le même nom (la casse du nom de la méthode
n'est pas prise en compte).
L'objetOooLayoutest accessible au moyen de la propriétélayde l'objet courant ($this->lay).
6.6.2.1 Contrôleur par défaut
En l'absence de méthode correspondant à la vue, le contrôleur par défaut est
appelé. Ce contrôleur est Doc::viewDefaultCard.
6.6.2.2 Utilisation des valeurs du document en consultation
Le contrôleur par défaut fait automatiquement appel
aux méthodes Doc::viewAttr et Doc::viewProp. Elles initialisent les clés
suivantes :
- viewAttr va créer :
-
L_ATTRIDpour chaque attribut : le libellé (traduit) de l'attribut, -
V_ATTRIDpour chaque attribut : la valeur (au format html) de l'attribut, -
S_ATTRIDpour chaque attribut :truesi l'attribut est vide,falsesinon
-
- viewProp va créer :
-
ATTRIDpour chaque attribut : la valeur brute de l'attribut, -
PROPIDpour chaque propriété : la valeur brute de la propriété, -
V_TITLEune ancre vers le document lui-même avec son titre.
-
Note : Toutes ces clefs sont en majuscules.
Lors de l'utilisation d'un contrôleur personnalisé, il est possible d'appeler
ces méthodes afin de générer les clés correspondantes. Il est également possible
de définir d'autres clés en utilisant les différentes méthodes de la classe
OooLayout.
Attention : Toutes ces clés respectent les visibilités : si la visibilité
d'un attribut est H pour un utilisateur, les clés L_ATTRID et V_ATTRID
sont des chaînes vides. S_ATTRID, pour sa part, n'est pas affecté par les
visibilités.
6.6.3 Spécificités du système de template pour les vues openDocument text
Bien que la syntaxe soit très proche de celle des vues textuelles, il y a quelques différences à prendre en compte.
Ces différences sont liées à la structuration des documents odt, qui sont en fait des documents xml, et dont la structure doit rester valide.
Parmi ces différences, il y a notamment :
- les balises
ZONEne sont pas prises en compte, -
les balises
BLOCKetENDBLOCKne sont pas prises en compte et la gestion des éléments répétables se fait de manière spécifiqueEn effet, la notion de répétable existe au sein des documents odt sous la forme des
- listes à puce,
- tableaux.
- La gestion des images se fait de manière spécifique.
6.6.3.1 Placer une clé dans le template odt
Les clés utilisent la même notation que dans les templates non odt : [KEY].
Bien que cela ne soit pas obligatoire, il est recommandé d'utiliser des champs utilisateur dont :
- le nom est libre et n'est pas utilisé par le système de templates,
- la valeur est la clé souhaitée,
- le format est text (vous pouvez utilisez d'autres formats, mais dans ce cas, à vous de savoir comment sera rendue la valeur générée).
L'utilisation de champs plutôt que du texte libre présente plusieurs avantages :
- cela simplifie la modification ultérieure par des utilisateurs,
- cela permet de recenser l'ensemble des attributs, y compris ceux qui ne sont pas utilisés,
- le remplacement étant fait au niveau du xml sous-jacent, si l'on n'utilise
pas les champs, il est possible que des balises viennent couper la clé. Par
exemple,
[MA_KEY]peut en fait avoir été stocké sous la forme[<span>MA</span>_KEY]qui n'est alors pas reconnue par le moteur de template.

Figure 66. champ utilisateur
6.6.3.2 Placer une clé dans les propriétés du template odt
Il est également possible d'utiliser les clés dans les propriétés du fichier, où elles sont aussi remplacées.
6.6.3.3 Images
Pour incorporer des images issues d'un attribut de type image, il faut insérer
dans le template une image quelconque qui sert de placeholder et qui est
ensuite remplacée par l'image issue de l'attribut du document lors de la
composition du template.
Pour cela, il faut :
Insérer une image quelconque dans le fichier, au moyen du menu ,
Cliquer sur le menu contextuel de l'image et choisir ,
-
Renseigner les clés (qui référencent la valeur et le label de l'attribut de type
image) dans l'onglet [Options], champ nom.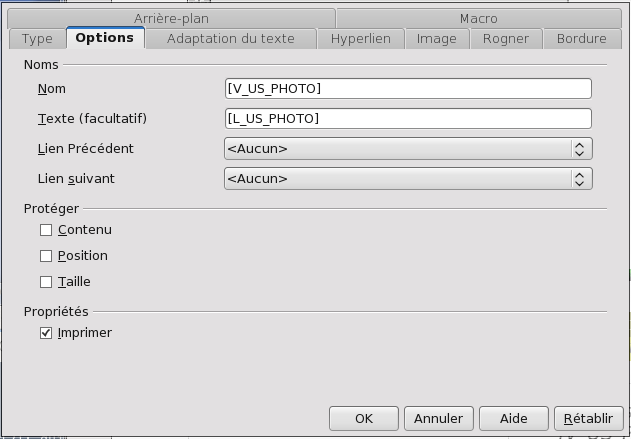
Figure 67. nom de l'image
En ce qui concerne la taille de l'image, la largeur est conservée. La hauteur est calculée en fonction du ratio de l'image.
Attention : chaque image « placeholder » doit être insérée de cette façon, et il ne faut surtout pas faire de copier-coller d'une image. En effet, en cas de copier-coller, les 2 images font référence en interne à la même image, même en définissant des noms différents.
6.6.3.4 Répétables
La gestion des éléments multiples est intrinsèque à la structure d'un fichier odt : les listes et tableaux sont multiples par nature. Aussi, utiliser la clé d'un attribut multiple dans une liste ou un tableau va automatiquement insérer le nombre d'éléments nécessaires.
6.6.3.4.1 Déclarer des éléments répétables dans des listes
Le template :

Figure 68. template
peut donner le fichier :

Figure 69. résultat
6.6.3.4.2 Déclarer des éléments répétables dans des tableaux
Le template :
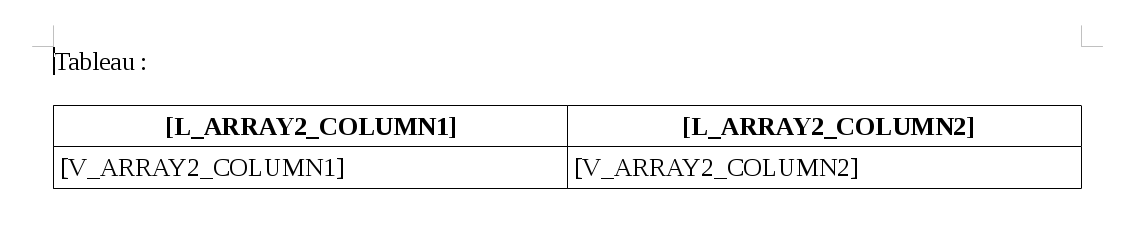
Figure 70. template
peut donner le fichier :
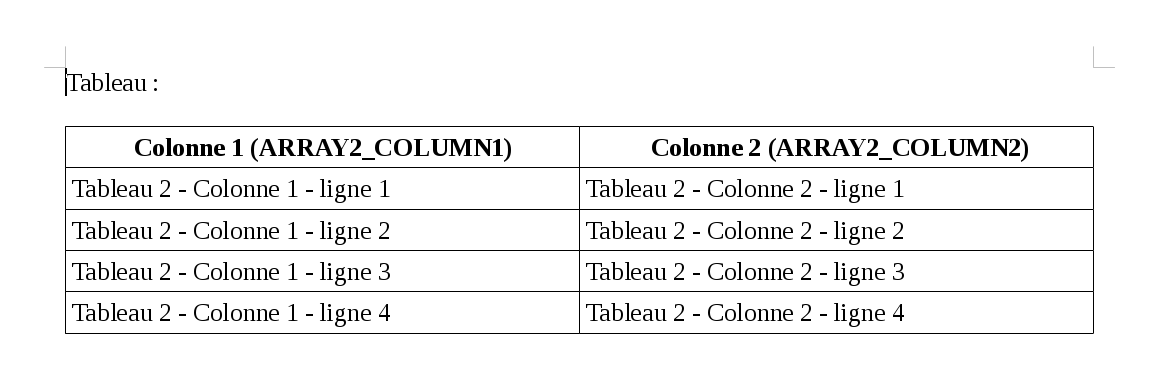
Figure 71. résultat
6.6.3.5 Conditions
Les conditions ([IF] / [ENDIF]) sont utilisables, à condition de respecter
la structure du document (Un fichier ODT étant, en interne, un XML, ce fichier
doit conserver son intégrité).
Aussi, les balises ouvrante et fermante doivent être au même niveau. Par exemple, on ne peut pas mettre un IF au milieu d'un tableau et le ENDIF à l'extérieur du tableau : le IF et le ENDIF doivent être dans la même cellule du tableau. Il est possible de les utiliser dans le même paragraphe ou entre plusieurs paragraphes de même niveau.
En cas d'erreur de structure, un message d'erreur apparaît lors de la consultation du document généré :

Figure 72. Erreur de structure
6.6.3.6 attributs htmltext
Le type htmltext implique des restrictions d'usage : La valeur de l'attribut est filtrée lors de l'incorporation dans un fichier openDocument. Seules certaines balises HTML sont supportées. Les balises non supportées sont ignorées et leur contenu n'est pas affiché.
Une clef correspondant à un attribut htmltext doit être placée seule dans le paragraphe, et ne doit pas contenir de texte autour.
6.6.3.7 Limitations
6.6.3.7.1 Limitation pour les attributs de type Htmltext
- Les couleurs, police, taille de police ne sont pas prises en compte,
- pour la mise en forme, seuls les mises en gras, souligné et en italique sont supportées,
- seuls les titres de niveau 1 à 4 sont pris en compte,
- lors de l'utilisation dans une liste, les tableaux ne sont pas interprétés et sont traités comme du texte brut,
- un attribut htmltext ne peut pas être utilisé dans les entêtes et pied de pages,
- un attribut htmltext ne peut pas être utilisé dans les propriétés du document,
- les styles (css) ne sont pas pris en compte,
-
les imbrications de paragraphes, exemple :
<div>Texte ext 1<div>Texte int</div>texte ext 2</div>
ne sont pas supportées. L'exemple précédent provoquera une erreur d'affichage de fichier openDocument.
6.6.3.7.2 Limitations pour les répétables
- les répétables ne sont pas gérés dans les entêtes et pied de pages,
- les répétables ne sont pas gérés dans les propriétés du document,
- les mots-clefs BLOCK/ENDBLOCK ne sont pas gérés,
- les listes ne peuvent pas avoir plusieurs niveaux d'imbrication.
6.6.3.7.3 Limitations pour les relations
- Les relations de document sont partiellement gérées : seul le titre du document est affiché (sans lien).
6.6.3.7.4 Autres limitations
- les zones (ZONE) ne sont pas gérés,
- les attributs de type fichier, couleur ne sont pas gérés.
6.6.4 Utilisation avancée
L'utilisation d'un contrôleur spécifique ainsi que les manipulations avancées sont détaillées dans la partie avancée sur les vues OpenDocument Text.
Chapitre 7 Importation et exportation de documents
Ce chapitre décrit comment des documents peuvent être importés dans Dynacase et exportés depuis Dynacase. Pour l'importation de famille, consulter le chapitre Déclaration de familles.
7.1 Importation de documents par CSV
Ce chapitre indique comme importer des documents au format CSV ou ODS.
7.1.1 Constitution du fichier d'importation
Le fichier d'importation peut être au format :
- CSV
- Encodage : UTF-8,
- Séparateur de colonnes :
;(point-virgule par défaut - configurable en 3.2.12). - Délimiteur de texte :
(vide par défaut - configurable en 3.2.12),
- ODS OpenDocument Spreadsheet (tableur OpenOffice.org .ods)
Ce fichier d'importation est auto-descriptif ; c'est à dire qu'il
- définit l'ordre et la signification des colonnes
- liste les documents à importer
7.1.1.1 Ordre des attributs
Avant de décrire les valeurs des attributs d'un document il est nécessaire d'indiquer à quel attribut correspond chaque valeur.
Pour définir l'ordre des attributs, il faut utiliser une ligne ORDER.
Chaque ligne ORDER est propre à une famille (et ne concerne donc pas les
familles qui en héritent).
Cette ligne doit être présente avant les lignes décrivant les documents de la famille concernée.
Les 4 premières colonnes contiennent :
- 1ère colonne :
ORDER, - 2ème colonne : identifiant de la famille (nom logique)
- 3ème colonne : vide (utilisée pour l'alignement avec la ligne
DOC), - 4ème colonne : vide (utilisée pour l'alignement avec la ligne
DOC).
Les autres colonnes définissent l'ordre des attributs à utiliser dans les
lignes DOC de la même famille qui suivent.
Si plusieurs lignes ORDER référençant la même familles sont écrites à la suite,
les documents sont importés avec le dernier ordre interprété.
Exemple :
| # | famille | |||||
|---|---|---|---|---|---|---|
| ORDER | ZOO_CLASSE | cl_latinname | cl_commonname | cl_caracteristic | ||
| DOC | ZOO_CLASSE | Actinopterygii | Poissons | Nage | ||
| DOC | ZOO_CLASSE | Reptilia | Reptiles | Rampe | ||
| ORDER | ZOO_CLASSE | cl_commonname | cl_caracteristic | cl_latinname | ||
| DOC | ZOO_CLASSE | Oiseaux | Vole | Aves | ||
| DOC | ZOO_CLASSE | Mammifères | Allaite | Mammalia |
Dans ce cas, les deux premiers documents utilisent le premier ORDER, et les
documents suivants le deuxième ORDER (la deuxième ligne ORDER a écrasé les
directives de la première).
3.2.19 Lorsque la ligne ORDER
est invalide (e.g. l'attribut déclaré n'existe pas pour la famille), alors
l'import de documents de cette famille est ignoré et une erreur est remontée.
La liste des codes d'erreur relatifs à la directive ORDER est consultable sur
la documentation PHP de la classe ErrorCodeORDR.
7.1.1.2 Description d'un document
Les quatre premières ont une signification particulière :
- 1ère colonne : toujours
DOC, 2ème colonne : identifiant de la famille (nom logique)
-
3ème colonne : identifiant du document (numérique ou nom logique)
- s'il est saisi
- si le document référencé existe, il sera mis à jour,
- sinon, le document créé portera cet identifiant,
- sinon
- si l'option d'importation est à mise à jour (option par défaut) et qu'un document est trouvé au moyen des clés d'importation, il est mis à jour,
- sinon, un nouveau document est créé, et porte un nouvel identifiant généré par la base de données.
Il n'est pas possible d'importer une révision figée d'un document. Seules les révisions courantes peuvent faire l'objet de modification. Si un identifiant pointe sur une révision passée c'est la révision courante qui sera modifiée par l'importation.
- s'il est saisi
-
4ème colonne : identifiant du dossier dans lequel le document importé doit être inséré.
- Si un identificateur est précisé le document est référencé dans le dossier (s'il n'y est pas déjà).
- Si l'identificateur n'est pas précisé (vide ou zéro), le document est référencé dans le dossier courant (celui qui est sélectionné dans l'arborescence en cas d'utilisation avec l'interface web d'importation).
- Si l'identifiant est
-alors le document ne sera référencé dans aucun dossier.
Les colonnes suivantes décrivent les valeurs brutes des attributs du document.
7.1.2 Mécanique d'importation
7.1.2.1 Valeurs des attributs pour l'importation
Les valeurs inscrites dans le document sont insérés avec la
méthode Doc::setValue().
7.1.2.1.1 Relations
Les attributs relations (docid, account, thesaurus) peuvent contenir :
- soit le nom logique du document cible;
-
soit l'identifiant système du document cible.
Attention, dans ce cas, le document cible peut ne pas être valable sur n'importe quelle instance de Dynacase.
Si le document référencé est un nom logique qui n'existe pas alors la valeur sera ignorée (un message de warning est émis avec le nom logique qui n'est pas connu). Si la référence est un nombre qui ne fait pas référence à un document, ce nombre sera enregistré. Il sera considéré comme une référence inconnue.
7.1.2.1.2 Énumérés
Les attributs de type énuméré (enum) doivent contenir la clef.
7.1.2.1.3 Dates
Les dates (date, timestamp) doivent être renseignés au format ISO
(YYYY-MM-DD ou YYYY-MM-DD HH:MM:SS ou YYYY-MM-DDTHH:MM:SS).
Dans le cas contraire, la date est interprétée en fonction de la locale de
l'utilisateur réalisant l'importation :
- Si la locale de l'utilisateur est français (paramètre
CORE_LANGpositionné à la valeurfr_FR), alors la date est interprétée selon le formatDD/MM/YYYY; - Si la locale de l'utilisateur est anglais (paramètre
CORE_LANGpositionné à la valeuren_US), alors la date est interprétée selon le formatMM/DD/YYYY.
Dans tous ces cas la valeur de la date stockée sera au format ISO.
7.1.2.1.4 Attributs multivalués
- Pour les attributs multivalués à un seul niveau (attribut contenu dans un
tableau, ou ayant l'option
multiple=yeset n'étant pas contenu dans un tableau) :- la chaîne
\ndélimite deux valeurs consécutives, - la chaîne
<BR>correspond à un saut de ligne au sein d'une valeur.
- la chaîne
- Pour les attributs multivalués à 2 niveaux (cas des relations ayant l'option
multiple=yeset contenues dans un tableau) :- la chaîne
\ndélimite deux valeurs de premier niveau, - la chaîne
<BR>délimite deux valeurs de second niveau.
- la chaîne
Par exemple :
-
pour un attribut de type
longtextcontenu dans un tableau, la valeurPremière rangée<BR>suite du texte\nDeuxième rangéecorrespond à la structure suivante :index relations 1 Première rangée
suite du texte2 Deuxième rangée -
pour un attribut de type
docid, ayant l'optionmultiple=yeset contenu dans un tableau, la valeur1236\n6375<BR>8755<BR>564\n567<BR><BR>4569correspond à la structure suivante :index relations 1 • 1236 2 • 6375
• 8755
• 5643 • 567
•
• 4569
Note 3.2.12 : Si un
délimiteur de texte est défini, le retour chariot est alors possible sur une
ligne et est interprété comme la chaîne \n.
7.1.2.2 Hameçons déclenchés lors de l'importation
Les hameçons sont lancés après la mise à jour des valeurs du document.
Lors d'un ajout de documents les hameçons suivants sont lancés :
Doc::preRefresh()Doc::postRefresh()Doc::preImport($extra)Doc::preCreated()Doc::postCreated()Doc::postStore()Doc::postImport($extra)
Lors d'une mise à jour de documents les hameçons suivants sont lancés :
preRefresh()postRefresh()preImport($extra)postStore()postImport($extra)
Note : Les contraintes ne sont pas vérifiées lors de l'importation des documents. Le caractère obligatoire des attributs n'est pas vérifié non plus.
7.1.2.3 Informations supplémentaires
Lors de l'importation d'un document, il est possible d'indiquer des informations supplémentaires pour réaliser des traitements conditionnels.
Ces informations sont identifiées par des clés commençant par extra: : ces
valeurs sont passées en paramètre des méthodes preImport et
postImport de la famille associée, sous forme d'un tableau
associatif de forme clé => valeur, avec pour clé la chaîne de caractères
suivant le extra: dans la description du nom de l'attribut, et comme valeur,
celle correspondante à la colonne.
Exemple :
| ORDER | ZOO_CLASSE | cl_latinname | extra:status | extra:special | ||
|---|---|---|---|---|---|---|
| DOC | ZOO_CLASSE | - | Actinopterygii | alive | protected |
Dans cette exemple, le document Actinopterygii de la famille ZOO_CLASSE aura
comme paramètre passé à preImport et postImport :
array( 'status' => 'alive', 'special' => 'protected' );
7.1.2.4 Clés d'importation
Lors d'une importation, Dynacase utilise une heuristique pour déterminer si un document existant doit être mis à jour ou s'il faut un créer un nouveau. Cette heuristique se base sur les clés d'importation de la famille : si un et un seul document de la même famille ou d'une sous-famille a ses clés d'importations égales à celles du document en cours d'importation, alors Dynacase fait une mise à jour dans le cas contraire, Dynacase fait une création de document.
Les clés d'importation pour une famille sont déterminées au moyen d'une ligne
KEYS.
Chaque ligne KEYS est propre à une famille (et ne concerne donc pas les
familles qui en héritent).
La clé utilisée par défaut pour reconnaître le document est la propriété title
de ce document.
L'ordre des colonnes est :
- 1ère colonne : toujours
KEYS, - 2ème colonne : Identifiant de la famille,
- 3ème colonne : vide,
- 4ème colonne : vide,
- 5ème colonne : clef primaire,
- 6ème colonne : clef secondaire.
Les colonnes 5 et 6 servent à définir les attributs ou propriétés qui sont utilisés comme clé. On peut avoir un maximum de deux clés par ligne (dans ce cas, il faudra que les deux clés correspondent pour que le document soit reconnu).
Exemple :
| # | famille | |||||
|---|---|---|---|---|---|---|
| ORDER | ZOO_CLASSE | cl_latinname | cl_commonname | cl_caracteristic | ||
| KEYS | ZOO_CLASSE | cl_latinname | ||||
| DOC | ZOO_CLASSE | - | Actinopterygii | Poissons | ||
| DOC | ZOO_CLASSE | - | Reptilia | Reptiles | Rampe | |
| DOC | ZOO_CLASSE | - | Actinopterygii | Nage |
Dans cet exemple, les documents sont reconnus par leur attribut 'cl_latinname'. Donc pour le premier document, la clé est 'Actinopterygii', et pour le deuxième 'Reptilia'. Dans cet exemple le document Actinopterygii est d'abord créé avec le nom Poissons, puis il est mis à jour avec la caractéristique Nage.
Les lignes KEYS sont appliquées dans l'ordre dans
lesquelles elles ont été écrites.
7.1.3 Modifier l'icône d'un document
Par défaut, l'icône d'un document est l'icône de la famille au moment de la création du document.
Il est possible de modifier l'icône d'un document au moyen d'une ligne
DOCICON.
L'ordre des colonnes est :
- 1ère colonne : toujours
DOCICON, - 2ème colonne : identifiant du document (nom logique),
- 3ème colonne : nom du fichier image.
| # | famille | |||||
|---|---|---|---|---|---|---|
| ORDER | ZOO_CLASSE | cl_latinname | cl_commonname | cl_caracteristic | ||
| DOC | ZOO_CLASSE | CL_ACTI | - | Actinopterygii | Poissons | |
| DOCICON | CL_ACTI | fish.png | - |
Le nom de l'image doit référencer un fichier présent dans le répertoire
./Images à la racine du répertoire d'installation sur le serveur.
7.1.4 Modifier un tag applicatif d'un document
3.2.23 Les tags applicatifs peuvent être ajoutés ou supprimés par le fichier d'importation CSV.
Il est possible de modifier le tag applicatif d'un document au moyen d'une ligne
DOCATAG.
L'ordre des colonnes est :
- 1ère colonne : toujours
DOCATAG, - 2ème colonne : identifiant du document (nom logique),
- 3ème colonne : non utilisée
- 4ème colonne : action à réaliser : ADD, DELETE ou SET (par défaut ADD)
- ADD : Ajout d'un nouveau tag
- DELETE : Suppression du tag indiqué
- SET : Suppression des précédents tag, puis ajout des nouveaux
- Colonnes suivantes : autres tags à ajouter ou à supprimer
| # | famille | ||||
|---|---|---|---|---|---|
| ORDER | ZOO_CLASSE | cl_latinname | cl_commonname | ||
| DOC | ZOO_CLASSE | CL_ACTI | - | Actinopterygii | Poissons |
| DOC | ZOO_CLASSE | CL_AVES | - | Aves | Oiseau |
| #TAGKEY | DOC IDENTIFIER | TAG ACTION | First Tag | Second tag | |
| DOCATAG | CL_ACTI | ADD | MyFishTag | ||
| DOCATAG | CL_AVES | SET | MyBirdTag | MyOtherTag |
Le tag ne doit pas contenir de retour chariot \n.
7.1.5 Précautions d'utilisation
Lors de l'import de documents quelques précautions d'usage sont à prendre en compte :
- Les attributs calculés peuvent devenir incohérent, ils sont en effet initialisés avec les valeurs lors de l'import. Ceci peut créer des incohérences.
- Les documents de faisant référence à un
accountne sont pas ré-importables tel que. Il faut suivre la procédure de ré-import tel que décrite dans ce chapitre.
3.2.18 Les documents ayant des attributs en visibilité "I" ne sont pas importés depuis l'interface d'importation sauf depuis le centre d'administration ou par ligne de commande.
7.2 Importation de documents par XML
Ce chapitre indique comment importer des documents au format XML.
L'importation de document peut être faite à l'aide de fichiers XML tels que ceux produits par l'exportation XML.
Le type de fichier accepté est soit un fichiers XML avec la balise root
<documents>, soit un fichier archive zip contenant un ensemble de
fichiers XML. Ces fichiers XML doivent être conformes au schéma XML associé à la
famille de document.
7.2.1 Schéma XML d'une famille
En ligne de commande, l'action FDL:FDL_FAMILYSCHEMA permet de récupérer ce
schéma XML. L'argument id doit contenir l'identifiant de la
famille dont on veut le schéma.
./wsh.php --app=FDL --action=FDL_FAMILYSCHEMA --id=ZOO_ANIMAL > zoo_animal.xsd
Les fichiers XML à importer doivent être conforme au schéma de la famille. Il est recommandé de valider les fichiers XML produits à l'aide du schéma avant importation.
7.2.2 Relation
Pour déclarer une relation avec un autre document, l'attribut name permet
d'indiquer la référence (nom logique) du document lié.
<an_classe name="Reptilia">Reptile</an_classe>
L'attribut id permet d'indiquer la référence système (numérique). Ceci ne peut
fonctionner que sur une base de données identifiée car les références systèmes
varient d'une base à une autre.
<an_espece id="4563">Alligator</an_espece>
Si ni l'attribut name ni l'attribut id n'est indiqué, une recherche par
titre sera faite afin de trouver automatiquement le document qui a le même titre
en cohérence avec la famille déclarée dans la relation au niveau de la famille.
Si aucun identifiant n'est trouvé l'exportation sera abandonnée.
<an_espece>Alligator</an_espece>
7.2.3 Fichier inline
Des fichiers peuvent être enregistrés pour les attributs de type file ou image.
Les fichiers encodés contenus dans le XML sont insérés dans le document et remplace le fichier original. Le contenu du fichier doit être encodé en base64.
<zoo_animal xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="zoo_animal.xsd" name="aliRotor" title="Rotor" > <an_identification><an_nom>Rotor</an_nom> <an_tatouage xsi:nil="true"/> <an_espece name="ZOO_ESP_ALLI">Alligator</an_espece <an_ordre>Crocodiliens</an_ordre> <an_classe name="Reptilia">Reptilia</an_classe> <an_sexe>M</an_sexe> <an_photo mime="image/jpeg; charset=binary" title="1387_IMG_1684AFC2.jpg">/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAYEBQYFBAYGBQYHBwYIChAKCgkJChQODwwQFxQYGBcUFhYaHSUfGhsjHBYWICwgIyYnKSopGR8tMC0oMCUoKSj/2wBDAQcHBwoIChMKChMoGhYaKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgQFFAH/9k=</an_photo> <an_gardien xsi:nil="true"/> <an_naissance>2012-08-03</an_naissance> <an_entree xsi:nil="true"/> <an_pere>Théodor</an_pere> <an_mere>Éléonore</an_mere> </an_identification> </zoo_animal>
Dans cet exemple la balise an_pĥoto contient l'image. L'attribut title
contient le nom du fichier. S'il est vide, le nom du fichier sera noname.
L'attribut mime est obligatoire, il contient le typemime du
fichier attaché.
7.2.4 Entêtes des fichiers XML
L'entête d'un document importé en XML contient les informations suivantes :
<zoo_animal xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="zoo_animal.xsd" title="Babette Junior" revision="1" modification-date="2012-08-01T09:51:14" version="" state="alive">
Les attributs title, revision, modification-date, version présents lors
d'une exportation XML sont calculés. Ils sont ignorés lors de l'importation.
De même l'attribut state n'est pas pris en compte. En revanche, les valeurs
de ces attributs sont disponibles en informations complémentaires dans
les méthodes ::preImport() et ::postImport() pour réaliser un traitement
particulier.
Les attributs optionnels id, name, folders sont pris en compte lors de
l'importation.
- name
-
Indique l'identifiant logique d'un document.
L'utilisation de cette propriété indique qu'on va créer un document avec ce nom logique ou mettre à jour le document portant ce nom logique.
- folders
-
Indique les noms logiques des dossiers dans lesquels le document doit être inséré.
S'il y a plusieurs dossiers, il faut séparer les noms par des virgules.
- id
-
Indique l'identifiant système d'un document.
L'utilisation de cette propriété indique qu'on va créer ou mettre à jour le document portant cet identifiant.
En son absence, la base génère un nouvel identifiant.
Attention : cet identifiant est propre à une base, et ne peut qu'exceptionnellement être utilisé d'une base à l'autre.
Note : Si l'id et le name sont présent simultanément alors l'id est utilisé
et pas le name.
7.2.5 Clefs d'importation XML
Avec la politique de mise à jour de document (par défaut), les documents sans
identifiants recherchent un document similaire avec les clefs d'importation. La
clef d'importation par défaut est title. Si un document et un seul de la même
famille avec le même titre a été trouvé alors il sera considéré comme une mise à
jour.
La clef d'importation peut être changée en utilisant l'attribut key :
<zoo_animal xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="zoo_animal.xsd" key="an_tatouage" revision="0" modification-date="2010-06-16T09:07:37" version="" state=""> <an_identification> <an_nom>Gérard</an_nom> <an_espece id="1131">Antilope</an_espece> <an_tatouage>32</an_tatouage> <an_enfant_t><an_enfant id="1148">Totor Alligator</an_enfant></an_enfant_t> <an_enfant_t><an_enfant id="1147">Alli Alligator</an_enfant></an_enfant_t> </an_identification> </zoo_animal>
Dans cet exemple, ce sera le tatouage qui sera pris comme référence. Si un
animal de même tatouage est trouvé il sera mis à jour sinon il sera ajouté. Il
est possible d'avoir une clef secondaire en ajoutant après une virgule un
deuxième attribut : key="an_tatouage,an_espece".
Cette directive est équivalente à la clef KEYS de l'importation CSV.
7.2.6 Importer des documents avec un simple fichier XML
Le fichier XML à importer doit contenir l'ensemble des documents correspondants.
La balise principale est documents.
animaux.xml
<documents> <zoo_animal> <an_identification> <an_nom>Gérard</an_nom> <an_espece id="1131">Alligator</an_espece> <an_tatouage>32</an_tatouage> <an_enfant_t><an_enfant id="1148">Totor Alligator</an_enfant></an_enfant_t> <an_enfant_t><an_enfant id="1147">Alli Alligator</an_enfant></an_enfant_t> </an_identification> </zoo_animal> <zoo_animal> <an_identification> <an_nom>Bob</an_nom> <an_espece id="1134">Agouti</an_espece> <an_tatouage>31</an_tatouage> </an_identification> </zoo_animal> </documents>
La commande à lancer pour l'importation en console est :
./wsh.php --api=importDocuments --file=animaux.xml
7.2.7 Importer des documents en XML avec une archive
7.2.7.1 Structure de l'archive XML
La structure de l'archive doit contenir un ensemble de fichiers XML correspondant chacun à un seul document. Chaque fichier est un XML qui est conforme au schéma XML de la famille. Les fichiers XML doivent être placés uniquement à la racine de l'archive. Le format du fichier archive pour l'importation XML est de type zip.
Exemple :
$ unzip -l animals.zip
Archive: animals.zip
Length Date Time Name
--------- ---------- ----- ----
983 2013-05-29 10:19 Gator.xml
947 2013-05-29 10:29 Olgator.xml
15159 2013-05-29 09:59 zoo_animal.xsd
--------- -------
17089 3 files
Cette archive contient deux documents. Le fichier schéma zoo_animal.xsd est
facultatif. Il est enregistré à titre indicatif pour pouvoir l'utiliser dans des
éditeurs XML. Il est ignoré lors de l'importation.
La commande à lancer pour l'importation en console est :
./wsh.php --api=importDocuments --file=animals.zip
Note : L'option --archive=yes n'est pas à utiliser dans ce cas. Elle est
réservée à l'importation d'archive.
7.2.7.2 Insérer un fichier avec le format d'archive XML
Les fichiers attachés peuvent être insérés inline ou par référence à un fichier local à l'archive.
Les fichiers à attacher doivent être insérés dans des sous-répertoires.
$ unzip -l animals.zip
Archive: animals.zip
Length Date Time Name
--------- ---------- ----- ----
0 2013-05-29 10:27 Photos/
2523262 2013-05-29 09:53 Photos/Gator.png
168900 2013-05-29 10:27 Photos/Reptilia_American_alligator.jpg
983 2013-05-29 10:19 Gator.xml
947 2013-05-29 10:29 Olgator.xml
15159 2013-05-29 09:59 zoo_animal.xsd
--------- -------
2709251 6 files
Dans ce exemple, les deux photos à insérer dans les documents sont dans le répertoire Photos.
Gator.xml
<?xml version="1.0" encoding="UTF-8"?> <zoo_animal xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" > <an_identification> <an_nom>Gator</an_nom> <an_tatouage xsi:nil="true"/> <an_espece name="ZOO_ESP_ALLI">Alligator</an_espece> <an_ordre>Crocodiliens</an_ordre> <an_classe name="Reptilia">Reptilia</an_classe> <an_sexe>F</an_sexe> <an_photo mime="image/png; charset=binary" href="Photos/Gator.png" title="Gator.png"/> </an_identification> </zoo_animal>
Le fichier lié doit être indiqué dans l'attribut XML href correspondant à la
balise de l'attribut fichier. Dans ce cas, il faut que la balise XML soit
autofermante, sinon cela sera considéré comme un fichier inline et une erreur
d'importation se produira car le fichier inline ne doit pas contenir
d'attribut href.
7.3 Importation d'archive
Ce chapitre décrit comment il est possible d'importer des documents avec des fichiers liés aux documents.
7.3.1 Importation de fichiers brute
Une archive brute permet d'importer un ensemble de fichiers. Ces fichiers sont inclus dans des familles qui ont au moins un attribut de type file ou image.
L'association entre la famille et le fichier est la suivante :
- Fichier image : Famille Image
IMAGE - Autre fichier : Famille Fichiers
FILE - Répertoire : Famille Dossier
DIR
L'éventuelle arborescence du contenu de l'archive est conservée.
$ unzip -l Files.zip
Archive: Files.zip
Length Date Time Name
--------- ---------- ----- ----
0 2012-08-30 16:19 Dossier un/
1321 2012-08-30 16:19 Dossier un/design.odt
3321 2012-08-30 16:19 Dossier un/presentation.odp
0 2009-02-26 16:07 Dossier deux/
152726 2007-07-06 10:36 Dossier deux/notes techniques.doc
63728 2007-07-06 10:36 Dossier deux/architecture.png
Cet extrait d'archive va créer deux dossiers, 3 documents de la famille fichiers et un document de la famille image.
Les fichiers sont insérés dans le premier (suivant la caractéristique order)
attribut fichier trouvé de la famille associée.
7.3.2 Importation d'archive
Pour associer plus précisément les fichiers et les documents, il est nécessaire
d'indiquer ces relations dans un fichier fdl.csv qui est un format CSV
d'importation de document.
Si ce fichier est présent à la racine de l'archive, alors seul ce fichier
est importé. Les autres fichiers peuvent dans ce cas être référencés par le
fichiers fdl.csv.
| //FAM | animal(ZOO_ANIMAL) | Identifiant | Dossier | nom | espèce | photo |
|---|---|---|---|---|---|---|
| ORDER | ZOO_ANIMAL | an_nom | an_espece | an_photo | ||
| DOC | ZOO_ANIMAL | aliRotor | Rotor | ZOO_ESP_ALLI | Photos/1387_IMG_1684AFC2.jpg | |
| DOC | ZOO_ANIMAL | Théodor | ZOO_ESP_ALLI | Photos/250px-Alligator.jpg | ||
| DOC | ZOO_ANIMAL | Éléonore | ZOO_ESP_ALLI | Photos/alligator-9112.jpg | ||
| DOC | ZOO_ANIMAL | Gator | ZOO_ESP_ALLI | Images/Gator.png | ||
| DOC | ZOO_ANIMAL | Olgator | ZOO_ESP_ALLI | Images/Reptilia_American_alligator.jpg |
Dans cet exemple les chemins des fichiers devant être insérés dans l'attribut
an_photo sont indiqués. Ces chemins sont relatifs à la racine de l'archive
(Les fichiers doivent être présents dans l'archive pour être intégrés dans le
document).
Cela donne une archive telle que celle-ci :
$ unzip -l Animals.zip
Archive: Animals.zip
Length Date Time Name
--------- ---------- ----- ----
1205 2012-08-30 16:19 fdl.csv
0 2012-08-30 16:19 Photos/
12689 2012-08-30 16:19 Photos/1387_IMG_1684AFC2.jpg
11321 2012-08-30 16:19 Photos/250px-Alligator.jpg
21521 2012-08-30 16:19 Photos/alligator-9112.jpg
0 2009-02-26 16:07 Images/
83728 2007-07-06 10:36 Images/Gator.png
163728 2007-07-06 10:36 Images/Reptilia_American_alligator.jpg
7.3.3 Commande d'importation d'archive
La commande à lancer pour l'importation en console est :
./wsh.php --api=importDocuments --archive=yes --file=animals.zip
Note : L'option --archive=yes doit être indiquée pour ne pas confondre
avec une importation classique de fichier CSV ou XML.
7.4 Importer des documents par ligne de commande
La commande wsh importDocuments permet d'importer des
documents en ligne de commande. Les types suivants sont supportés par le script
:
-
CVS
- Encodage : UTF-8,
- Séparateur de colonnes :
;(point-virgule par défaut - configurable en 3.2.12). - Délimiteur de texte :
(vide par défaut - configurable en 3.2.12),
- ODS,
- XML,
- ZIP,
- TGZ
./wsh.php --api=importDocuments --help
Import documents from description file
Usage :
--file=<the description file path>
Options:
--userid=<user system id or login name to execute function - default is (admin)>, default is '1'
--analyze=<analyze only> [yes|no], default is 'no'
--archive=<description file is an standard archive (not xml)> [yes|no], default is 'no'
--log=<log file output>
--policy=<policy import -
[update] to auto update same document (the default),
[add] to always create new document,
[keep] to do nothing if same document already present> [update|add|keep]
--htmlmode=<analyze report mode in html> [yes|no], default is 'yes'
--reinitattr=<reset attribute before import family update (deprecated)> [yes|no]
--reset=<reset options> [default|parameters|attributes|structure|properties|enums]
--to=<email address to send report>
--dir=<folder where imported documents are put>
--strict=<don't import if one error detected> [yes|no], default is 'yes'
--csv-separator=<character to delimiter fields - generaly a comma> use single character or "auto", default is ';'
--csv-enclosure=<character to enclose fields - generaly double-quote> use single character or "auto", default is ''
--csv-linebreak=<character sequence to be import like CRLF>, default is '\n'
--help (Show usage)
L'option --analyze=yes permet de réaliser une importation à blanc. Dans ce
cas, l'importation est réalisée mais aucune modification n'est enregistrée en
base de données. Cela permet de récupérer le rapport d'importation :
./wsh.php --api=importDocuments --analyze=yes --htmlmode=yes --file=animal.xml > report.html
Pour envoyer le rapport par courriel, l'option --to permet de désigner
l'adresse du destinataire :
./wsh.php --api=importDocuments --to=someone@somewhere.org --file=animal.xml
Pour avoir un fichier de log, l'option --log permet de spécifier l'emplacement
auquel enregistrer le fichier de log :
./wsh.php --api=importDocuments --file=animaux.xml --htmlmode=yes --analyze=yes --log=/var/tmp/log.txt
$ cat /var/tmp/log.txt
IMPORT BEGIN OK : 02/07/2010 17:10:29
IMPORT DOC OK : [title:Isabelle] [id:0] [action:added] [changes:{nom:Isabelle}{espèce:1132}] [message:Isabelle à ajouter]
IMPORT DOC OK : [title:Alli2 Agouti] [id:3296] [action:updated] [changes:] [message:]
IMPORT DOC KO : [title:] [id:0] [action:ignored] [changes:] [message:] [error:DOMDocument::load(): Opening and ending tag mismatch: r line 5 and zoo_animal in /var/tmp/xmlsplit4c2e10009374f/3299.xml, line: 10DOMDocument::load(): Premature end of data in tag zoo_animal line 2 in /var/tmp/xmlsplit4c2e10009374f/3299.xml, line: 11]
IMPORT COUNT OK : 2
IMPORT COUNT KO : 1
IMPORT END OK : 02/07/2010 17:10:31
3.2.18 Les documents ayant des
attributs en visibilité I sont importés sans tenir compte de
cette contrainte.
7.4.1 Options pour les importations de familles
L'option reset permet d'influer sur l'interprétation de l'importation en
rajoutant des instructions de RESET au(x) définition(s) de famille(s).
L'option reset rajoute l'instruction RESET correspondant après chaque
BEGIN du fichier. Toutes les familles définies ont cette instruction
ajoutée.
./wsh.php --api=importDocuments --file=my_family.csv --reset=attributes
Cette option peut être multivaluée pour indiquer plusieurs instructions de
RESET.
./wsh.php --api=importDocuments --file=my_family.csv --reset[]=enums --reset[]=default
L'option reinitattr est dépréciée. Cette option est équivalente à
reset=attributes.
7.4.2 Gestion des erreurs
Si une seule erreur est détectée sur le fichier d'importation, aucun document du fichier d'importation ne sera ajouté ou modifié.
La liste des codes d'erreur reportés est consultable dans la documentation de l'API PHP : "Error codes".
7.5 Exportation de documents
L'accès à l'interface d'exportation se fait depuis le centre d'administration. avec l'application Explorateur de documents.
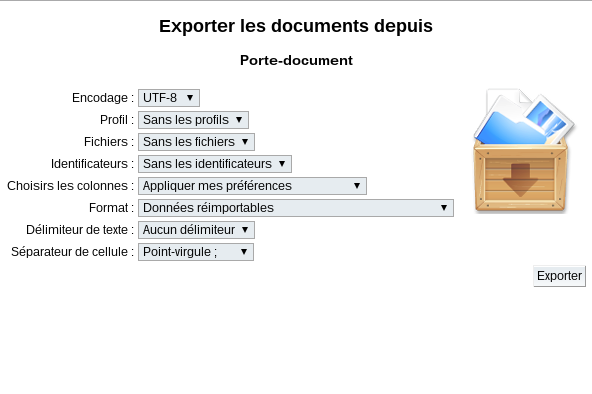
Figure 73. Exportation de documents
Pour exporter, il faut cliquer sur le menu Outils/Exportation du dossier depuis la fenêtre d'ouverture de dossier (ou de recherche). L'accès à l'exportation est aussi disponible sur le menu contextuel affichable en cliquant sur les icônes de dossier ou de recherche présentes dans l'arborescence.
3.2.18 Les documents ayant des
attributs en visibilité I sont exportés uniquement si cette
interface est utilisée depuis le centre d'administration. Si l'interface est
utilisée hors de ce contexte, les valeurs des attributs en visibilité I ne
sont pas exportés.
7.5.1 Options d'exportation
L'exportation propose les options suivantes :
- Encodage
-
Permet de spécifier l'encodage du fichier d'exportation.
-
ISO 8859-15: est utile pour les systèmes ne gérant pas correctement l'UTF8 (cas par exemple d'Excel sous Windows) -
UTF-8: valeur préférée lorsque le système gère correctement cet encodage.
Lors d'une importation, l'encodage est détecté automatiquement et ces 2 encodages sont supportés.
-
- Profil
-
Permet d'exporter les profils associés aux documents.
Si des profils sont liés à des documents, le document profil et son profilage sont aussi exportés.
Cette option est utile lorsqu'un concepteur de famille veut récupérer son paramétrage profil.
3.2.21 Une option supplémentaire permet de récupérer les droits avec les références aux comptes (utilisation de
:useAccount) ou avec les références aux documents (utilisation de:useDocument) - Fichiers
-
Permet d'exporter également les fichiers attachés aux documents.
-
sans les fichiers: indique que seul le fichier csv contenant les valeurs des attributs sera exporté. Les fichiers liés aux attributs de type file ou image ne sont pas exportés. -
avec les fichiers: indique que l'exportation doit générer un fichier archive de type Zip. Cette archive contiendra- le fichier
fdl.csv, contenant les valeurs des attributs - les fichiers attachées aux documents exportés.
Cette archive peut être réimporté à au moyen de l'importation d'archive.
Pour des raisons de compatibilité avec les différents systèmes d'exploitations les noms des fichiers exportés ne comportent pas d'accents.
- le fichier
-
- Identificateur
-
Permet de sauvegarder les identificateurs systèmes numériques des documents.
-
Avec les identificateurs: Cela implique que votre fichier n'est ré-importable que dans la même base. En contrepartie, les documents sont identifiés de manière non ambiguë dans l'objectif d'une restauration. -
Sans les identificateurs: permet de réimporter les documents dans n'importe quelle base. Cela implique que lors d'une réimportation dans la même base, la mise à jour des documents existants n'est pas garantie (voir pour cela la notion de Clés d'importation).
Dans tous les cas, si les documents comportent des noms logiques (propriété
name), ces noms sont exportés à la place des identifiants systèmes. -
- Choisir les colonnes
-
Permet de n'exporter que certains attributs du documents.
Chaque administrateur peut définir et sauvegarder les attributs qu'il veut exporter pour chaque famille.
L'interface de choix des colonnes est présentée lorsqu'une famille est sélectionnée. Une fois le choix sélectionné et sauvegardé alors seuls les attributs choisis seront exportés. Le choix "Ne pas tenir compte des préférences" permet d'exporter l'ensemble des attributs.
- Format
- Voir le chapitre suivant
- Délimiteur de texte 3.2.17
-
Permet de configurer le format du CSV produit (uniquement dans le cas d'un format non XML)
Ce paramètre permet de définir le délimiteur de cellule (enclosure) du CSV produit. Le défaut de Dynacase est
Aucun délimiteur(chaîne vide), le standard du CSV est". - Séparateur de cellule 3.2.17
-
Permet de configurer le format du CSV produit (uniquement dans le cas d'un format non XML)
Ce paramètre permet de définir le séparateur de cellule du CSV produit. Le défaut de Dynacase est
;, le standard CSV est,.
Attention : A chaque utilisation de l'exportation de documents, le délimiteur de texte et le séparateur de cellule utilisés sont sauvés automatiquement pour l'utilisateur en cours et utilisés pour les exportations suivantes.
7.5.2 Différents formats d'exportation
7.5.2.1 Données réimportables
Le fichier produit est réimportable. Son format dépend de l'option Fichiers :
-
Si l'option Sans les fichiers est choisie, le fichier produit est un fichier csv conforme au format d'importation CSV.
Exemple de fichier csv produit : (ici avec l'option avec les identificateurs)
//FAM animal(ZOO_ANIMAL) Identifiant Dossier nom espèce classe ORDER ZOO_ANIMAL an_nom an_espece an_classe DOC ZOO_ANIMAL aliRotor Rotor ZOO_ESP_ALLI Reptilia DOC ZOO_ANIMAL 2079 Théodor ZOO_ESP_ALLI Reptilia DOC ZOO_ANIMAL 2080 Éléonore ZOO_ESP_ALLI Reptilia Si l'option avec les fichiers est choisie, le fichier produit est une archive de type zip conforme au format d'importation d'archive
7.5.2.2 Données brutes
Le fichier produit est un fichier csv. ce fichier n'est pas réimportable. Il ne contient que les valeurs brutes d'attributs.
Pour les relations c'est le nom logique qui est exporté s'il existe, sinon c'est l'identifiant système.
| nom | espèce | classe |
|---|---|---|
| Rotor | ZOO_ESP_ALLI | Reptilia |
| Théodor | ZOO_ESP_ALLI | Reptilia |
| Bouti | 2456 | Mammalia |
| Germiné | 2476 | 1678 |
La première ligne contient les libellés des attributs exportés. Ces libellés peuvent différer d'une locale à une autre si des traductions ont été enregistrées. Dans ce cas, ce sont les libellés correspondant à la locale de l'utilisateur qui a fait l'exportation.
7.5.2.3 Données formatées
Le fichier produit est un fichier csv. Ce fichier n'est pas réimportable. Il ne contient que les valeurs formatées d'attributs :
- Les relations sont remplacées par le titre du document cible à la place de son identifiant,
- Les énumérés sont remplacés par leur libellé à la place de la clé.
- Les attribut de type
moneysont affichés avec séparation des milliers.
À la différence des données brutes, l'espèce contient le titre et non
l'identifiant. De même, les énumérés contiendront le libellé et non la clefs. La
valeur formatée exportée est celle rendue sur les interfaces web à l'exception
des hyperliens. Les éventuelles formats d'affichages sont pris en compte comme par
exemple double("%.03f %%") qui donnera 2.000 % au lieu de 2.
| nom | espèce | classe |
|---|---|---|
| Rotor | Alligator | Reptile |
| Théodor | Alligator | Reptile |
| Bouti | Agouti | Mammifère |
| Germiné | Caille des blés | Oiseau |
La première ligne contient les libellés des attributs exportés.
7.5.2.4 Données XML Zip
Chaque document est enregistré dans un fichier XML. Ces fichiers sont insérés dans un fichier d'archive Zip.
7.5.2.5 Données XML simple
Tous les documents sont enregistrés dans un seul et même fichier XML.
7.5.3 Exportations et révisions
Les documents révisés peuvent faire partie du résultat de l'exportation si la recherche spécifie l'option "toutes les révisions".
Si un document révisé (document figé) à un nom logique, il ne sera pas utilisé comme identificateur. C'est son identifiant numérique qui sera utilisé dans ce cas.
Si un document référence une révision précise d'un document (option docrev
différente de "latest"), c'est son identifiant numérique qui sera utilisé même
s'il possède un nom logique. Dans ce cas, un avertissement sera affiché.
La réimportation d'une exportation qui comporte des révisions va créer de nouveaux documents si les identifiants n'existent pas déjà ou mettre à jour la révision courante avec les valeurs de révisions précédentes.
7.6 Exportation de documents en Xml
Les documents, hormis les familles, peuvent être exportés en XML. Les fichiers XML produits suivent un schéma de famille imposé par dynacase. Chaque famille de document a son propre schéma XML. L'exportation Xml d'un contenu de dossier ou de recherche peut se faire de deux façons : en générant un fichier par document ou dans un seul fichier xml.
Si vous voulez utiliser le fichier Xml pour une exportation vers un autre contexte, il faut absolument indiquer l'option "sans les identificateurs" , sinon les documents importés sont incohérents et peuvent corrompre le contexte.
Les fichiers produits par l'exportation Xml sont conformes au format d'importation XML.
7.6.1 Archive avec un fichier Xml par document
Dans ce cas une archive (zip) est constituée avec un fichier par document.
Chaque fichier est nommé à l'aide du titre et de l'identifiant du document (par
exemple : alligator {4567}.xml. Chaque fichier fait
référence à un schéma xml issus de la famille. Ce schéma est aussi
présent dans l'archive.
7.6.2 Un fichier Xml seul
Dans ce cas, la sortie est un seul fichier xml contenant l'ensemble des
documents. La balise racine est dans ce cas documents. La balise documents
porte la date de génération et l'auteur.
<documents date="2010-06-07T12:46:45" author="Default Master" name="recherche_animal"> <zoo_animal .> </zoo_animal> <zoo_animal .> </zoo_animal> </documents>
Avec cette option les schémas Xml des familles ne sont pas exportés.
7.6.3 Format du XML de document
Les attributs non structurant sont insérés dans les attributs de structure (tab, frame, array).
<my_tab><!-- Onglet --> <my_frame><!-- Cadre --> <my_array><!-- Tableau : rangée par rangée --> <my_attr_col1>Rangée 1 Colonne 1</my_attr_col1> <my_attr_col2>Rangée 1 Colonne 2</my_attr_col2> </my_array> <my_array> <my_attr_col1>Rangée 2 Colonne 1</my_attr_col1> <my_attr_col2>Rangée 2 Colonne 2</my_attr_col2> </my_array> <my_attribute1>Valeur</my_attribute1> <my_attribute2>Valeur</my_attribute2> </my_frame> </my_tab>
Les valeurs brutes des attributs non structurant sont contenus dans le contenu de la balise.
7.6.3.1 Attributs spécifiques
Les attributs de type "docid" et "file" ont des attributs supplémentaires.
7.6.3.1.1 Attribut XML docid, account, thésaurus
-
id: Identifiant numérique de la relation -
name: Nom logique de la relation -
revision: 3.2.21 Contient le numéro de la révision si l'option "docrev=fixed". Contient "state:<état>" si l'option est "docrev=state(<état>)".
7.6.3.1.2 Attribut XML file, image
-
vid: Identifiant du fichier dans le coffre -
mime: Type mime du fichier -
href: Url de download du fichier -
title: Nom du fichier
Le contenu de la balise est le fichier encodé si l'option "Avec les fichiers" a été sélectionnée.
7.6.4 Exemple d'un document exporté
<zoo_animal xsi:noNamespaceSchemaLocation="zoo_animal.xsd" id="3296" name="" title="Alli Alligator" revision="0" modification-date="2010-06-02T13:53:33" version="" state=""> <an_tab1> <an_identification> <an_nom>Alli</an_nom> <an_descr xsi:nil="true"/> <an_tatouage xsi:nil="true"/> <an_espece_title>Alligator</an_espece_title> <an_espece id="1127">Alligator</an_espece> <an_ordre>Crocodiliens</an_ordre> <an_classe id="1123" name="Reptilia">Reptilia</an_classe> <an_sexe>M</an_sexe> <an_photo xsi:nil="true"/> <an_photo vid="27" mime="image/png" href="http://localhost:8080/dev/file/3296/743/an_photo/-1/Gator.png?cache=no&inline=no" title="alligator.png"/> <an_naissance>2010-05-12</an_naissance> <an_entree>2010-05-18</an_entree> <an_pere id="1289">Viel Ali Alligator</an_pere> </an_identification> </an_tab1> </zoo_animal>
7.6.5 Exportation Xml avec fichier
Si vous cochez l'option avec les fichiers ceux-ci seront importés "inline" dans les fichiers xml. La balise de l'attribut contiendra dans ce cas le fichier encodé en base 64.
<an_photo vid="27" mime="image/png" title="alligator.png"> iVBORw0KGgoAAAANSUhEUgAAAQAAAAEACAYAAABccqhmAAAACXBIWXMAAAsTAAALEwEAmpwYAAAABGdBTUE AALGOfPtRkwAAACBjSFJNAAB6JQAAgIMAAPn/AACA6QAAdTAAAOpgAAA6mAAAF2+SX8VGAAEoA0lEQVR42m L8//8/wwgE==</an_photo>
7.6.6 Exportation Xml par ligne de commande
L'exportation en ligne de commande est :
./wsh.php --app=FDL --action=EXPORTXMLFLD --id=[folderid] --eformat=[X|Y] --wfile=[N|Y]
Les paramètres sont :
id- Identifiant d'un dossier ou d'une recherche
eformat-
Format d'export :
- X : Archive XML
- Y : Xml simple
wfile-
Avec ou sans les fichiers :
- Y : Avec fichiers
- N : Sans fichier
flat-
Export à plat
-
Y : Les balises de structure de type "tab" et "frame" ne sont pas représentées. Seule la structure concernant les tableaux est maintenue.
Ce type d'exportation ne permet pas une réimportation.
N : Export normal
-
log-
Générer un fichier de log
Cette option permet de connaître le nombre de documents exportées ainsi que leur liste.
./wsh.php --app=FDL --action=EXPORTXMLFLD --id=1180 --eformat=Y --log=/var/tmp/log.txt > t.xml $ more /var/tmp/log.txt EXPORT BEGIN OK : 02/07/2010 15:49:47 EXPORT OPTION FLAT : no EXPORT OPTION WFILE : yes EXPORT OPTION CONFIG : yes EXPORT OPTION ID : ANIMAUX <Les animaux> EXPORT DOC OK : <a Agouti> [3300] EXPORT DOC OK : <Albert baleine blanche> [3266] EXPORT DOC OK : <Alli Baleine à bosse ou jubarte> [3248] EXPORT DOC OK : <Zoé Antilope> [3317] EXPORT COUNT OK : 3 EXPORT END OK : 02/07/2010 15:49:47
config-
Spécifie une liste de paramètres à exporter
Cela est paramétrable à l'aide d'un fichier de configuration au format xml
Exemple :
configexport.xml
<?xml version="1.0" encoding="UTF-8"?> <configuration> <family name="ZOO_ANIMAL"> <attribute name="AN_NOM"/> <attribute name="AN_ESPECE"/> <attribute name="AN_ENFANT"/> </family> <family name="ZOO_ENCLOS"> <attribute name="EN_NOM"/> <attribute name="EN_SURFACE"/> </family> </configuration>
./wsh.php --app=FDL --action=EXPORTXMLFLD --id=ANIMAUX --eformat=Y --config=configexport.xml > animaux.xml
Chaque balise
familydéfinit les attributs à exporter pour cette famille. Seuls les attributs feuille non structurants sont pris en compte.Les attributs
namedésignent les identifiants de familles et d'attributs.Si on exporte un document d'une famille qui n'est pas dans le fichier de configuration, l'ensemble de ses attributs est exporté.
7.7 Exportation des profils
L'option d'exportation "Avec les profils" permet d'enregistrer les profils associés aux documents en plus des données du documents.
Cette option n'est applicable qu'avec le format "Données réimportables".
Si le document a un profil lié alors le document Profil sera aussi exporté.
Si le document a un profil dédié, la clef PROFIL portera sur le document même.
Si le profil lié est un profil dynamique, le profil calculé ne sera pas exporté, mais le profil dynamique sera exporté.
Soit les 4 documents suivants :
- Rotor :
- Profil lié : ZOO_PRF_CLASSIFICATION.
- Nom logique : aliRotor.
- Théodor :
- Profil lié : ZOO_PRF_CLASSIFICATION.
- Pas de nom logique.
- Éléonore :
- Profil lié : ZOO_PRF_CLASSIFICATION.
- Pas de nom logique.
- Gastor :
- Profil dédié.
- Pas de nom logique.
Le fichier csv produit sera comme décrit ci-dessous :
| //FAM | animal(ZOO_ANIMAL) | Identifiant | Dossier | nom | espèce | classe | |
|---|---|---|---|---|---|---|---|
| ORDER | ZOO_ANIMAL | an_nom | an_espece | an_classe | |||
| DOC | ZOO_ANIMAL | aliRotor | Rotor | ZOO_ESP_ALLI | Reptilia | ||
| //FAM | _profil de document(PDOC) _ | Identifiant | Dossier | titre | _description _ | family id | famille |
| ORDER | PDOC | ba_title | prf_desc | dpdoc_famid | dpdoc_fam | ||
| DOC | PDOC | ZOO_PRF_CLASSIFICATION | Classification | ||||
| PROFIL | ZOO_PRF_CLASSIFICATION | :useAccount | view=role_vetérinaire | edit=role_vetérinaire | view=role_surveillant | view=attribute(an_gardien) | |
| PROFIL | aliRotor | ZOO_PRF_CLASSIFICATION | |||||
| ORDER | ZOO_ANIMAL | an_nom | an_espece | an_classe | |||
| DOC | ZOO_ANIMAL | TEMPORARY_ZOO_ANIMAL_2079_51a707c53aa48 | Théodor | ZOO_ESP_ALLI | Reptilia | ||
| PROFIL | TEMPORARY_ZOO_ANIMAL_2079_51a707c53aa48 | ZOO_PRF_CLASSIFICATION | |||||
| DOC | ZOO_ANIMAL | TEMPORARY_ZOO_ANIMAL_2080_51a707c54ae36 | Éléonore | ZOO_ESP_ALLI | Reptilia | ||
| PROFIL | TEMPORARY_ZOO_ANIMAL_2080_51a707c54ae36 | ZOO_PRF_CLASSIFICATION | |||||
| DOC | ZOO_ANIMAL | TEMPORARY_ZOO_ANIMAL_3296_51a707c54ce55 | Gastor | ZOO_ESP_ALLI | Reptilia | ||
| PROFIL | TEMPORARY_ZOO_ANIMAL_3296_51a707c54ce55 | :useAccount | view=role_surveillant | view=role_vetérinaire | edit=role_vetérinaire |
Un nom logique temporaire est généré pour les documents n'ayant pas de nom
logique. Cet identifiant temporaire est supprimé tous les soirs avec le
programme wsh cleanContext.
La clef PROFIL contient l'ensemble des droits explicites mis sur les
profils.
3.2.21 L'affectation des droits
est faite par défaut avec les références (:useAccount) des
comptes Utilisateurs, Groupes et Rôles . Si l'option "Utiliser
les références aux comptes" est indiquée depuis l'interface
d'exportation, l'exportation sera effectuée en utilisant l'option
:useDocument.
Les différents notations de profils sont :
[aclName]=[accountIdentifier]-
[attributeName]=attribute([attributeIdentifier])// Cas des profils dynamiques
Attention : Par défaut, l'importation des éléments ci-dessus ne fait qu'ajouter les nouveaux droits et ne supprime pas les droits supprimés. Il existe différentes options pour l'importation des profils permettant de modifier ce comportement.
7.7.1 Exportation de profil de famille
Si le dossier à importer comporte un document famille alors l'exportation du profil exportera les documents suivants :
- Le document profil de la famille
- La définition du profil de la famille
- Le document cycle de vie par défaut de la famille et son profil
- Les masques du cycles de vie et leur profil
- Les modèles de mail du cycles de vie et leur profil
| //FAM | profil de document(PDOC) | Identifiant | Dossier | titre | description |
| ORDER | PDOC | ba_title | prf_desc | ||
| DOC | PDOC | ZOO_PRF_CLASSIFICATION | Classification | ||
| PROFIL | ZOO_PRF_CLASSIFICATION | :useAccount | view=gadmin | viewacl=gadmin | |
| //FAM | modèle de mail(MAILTEMPLATE) | Identifiant | Dossier | Titre | Famille |
| ORDER | MAILTEMPLATE | tmail_title | tmail_family | ||
| DOC | MAILTEMPLATE | TEMPORARY_MAILTEMPLATE_3801_51a8c23b99679 | Couriel rédacteur | ZOO_DEMANDEADOPTION | |
| //FAM | profil de document(PDOC) | Identifiant | Dossier | titre | description |
| ORDER | PDOC | ba_title | prf_desc | ||
| DOC | PDOC | PRF_ADMIN_EDIT | Administration | lecture seule sauf pour groupe admin | |
| PROFIL | PRF_ADMIN_EDIT | :useAccount | view=all | edit=gadmin | |
| PROFIL | TEMPORARY_MAILTEMPLATE_3801_51a8c23b99679 | PRF_ADMIN_EDIT | |||
| //FAM | Cycle demande Adoption(ZOO_WDEMANDEADOPTION) | Identifiant | Dossier | titre | description |
| ORDER | ZOO_WDEMANDEADOPTION | ba_title | wf_desc | ||
| DOC | ZOO_WDEMANDEADOPTION | ZOO_CYCLEDA | Défaut | ||
| //FAM | profil de document(PDOC) | Identifiant | Dossier | titre | description |
| ORDER | PDOC | ba_title | prf_desc | ||
| DOC | PDOC | ZOO_PRF_HYGIENE | Hygiène | ||
| PROFIL | ZOO_PRF_HYGIENE | :useAccount | view=gadmin | viewacl=gadmin | |
| //FAM | masque de saisie(MASK) | Identifiant | Dossier | titre | Famille |
| ORDER | MASK | ba_title | msk_famid | ||
| DOC | MASK | TEMPORARY_MASK_3802_51a8c23bac7c6 | Initialisé | ZOO_DEMANDEADOPTION | |
| PROFIL | TEMPORARY_MASK_3802_51a8c23bac7c6 | PRF_ADMIN_EDIT | |||
| //FAM | profil de famille(PFAM) | Identifiant | Dossier | titre | description |
| ORDER | PFAM | ba_title | prf_desc | ||
| DOC | PFAM | ZOO_PRF_FAM | Profil Zoo | Pour les familles du zoo | |
| PROFIL | ZOO_PRF_FAM | :useAccount | edit=gadmin | viewacl=gadmin | |
| BEGIN | ZOO_DEMANDEADOPTION | ||||
| PROFID | ZOO_PRF_FAM | ||||
| WID | ZOO_CYCLEDA | ||||
| END |
Les masques et les modèles de mail auront un nom logique temporaire s'ils n'ont
pas de nom logique.
Le fichier exporté comporte aussi, à la fin, le paramétrage du profil et du
cycle pour la famille exportée.
Note : Les documents "famille" (caractéristiques et structures) ne sont pas exportables. Seul leur profil est exportable avec cette option.
Attention : Par défaut, l'import des éléments ci-dessus ne fait qu'ajouter les nouveaux droits et ne supprime pas les droits supprimés. Il existe différentes options pour l'import des profils permettant de modifier ce comportement.
Chapitre 8 Utilisateurs, groupes et rôles
8.1 Présentation des comptes
Le terme "compte" regroupe les termes utilisateur, groupe et rôle.
Les comptes sont composés de :
-
Un objet système
Il permet les manipulations internes de comptes comme l'affectation de rôle, de groupe, etc.
C'est également cet objet qui est utilisé pour tout ce qui concerne le profilage de document et les accessibilités des actions.
Cet aspect système sera traité dans le chapitre consacré à la classe Account
-
un document.
Il offre une interface permettant d'effectuer certaines opérations sur l'objet système.
Ce chapitre concerne l'aspect document des comptes.
La gestion des utilisateurs peut être faite avec le centre d'administration. L'application gestion des utilisateurs permet de gérer les rôles, groupes et utilisateurs.
8.1.1 Vocabulaire
Utilisateur-
Un document
utilisateurregroupe les informations permettant à une personne de se connecter sur l'interface web de Dynacase. Par extension, unutilisateurest une personne qui peut se connecter à Dynacase.La famille décrivant les utilisateurs est
IUSER. Groupe-
Un document
groupe d'utilisateursest une collection qui peut contenir un ensemble d'utilisateurs ou de groupe d'utilisateurs.
Une arborescence de groupes peut ainsi être constituée à l'aide de ces groupes.
Un utilisateur ou un groupe d'utilisateurs peut appartenir à plusieurs groupes.
La seule contrainte est que le graphe des groupes ne doit pas contenir de cycle (Le groupe A ne peut pas appartenir au groupe B si B appartient déjà au groupe A).La famille décrivant les groupes d'utilisateurs est
IGROUP.Note : Il existe aussi la famille "groupe" (
GROUP) qui est la famille mère de "groupe d'utilisateur". Cette famille de plus haut niveau permet de regrouper aussi des documents qui ne sont pas forcément des utilisateurs mais des contacts. Dans ce chapitre, le termegroupedésignera les groupes d'utilisateurs. Rôle-
Un document "rôle" identifie une fonction dans l'organisation. Ce rôle sera utilisé pour définir les droits. Un utilisateur peut avoir plusieurs rôles.
Contrairement aux groupes, les rôles n'ont pas de hiérarchie.
La famille décrivant les rôles est
ROLE.
8.2 Description des utilisateurs
8.2.1 Principales caractéristiques des utilisateurs
Les principaux attributs de la famille Utilisateur sont :
- Nom
us_lname - Nom de famille de l'utilisateur
- Prénom
us_fname - Prénom de l'utilisateur
- Mail principal
us_mail - Adresse de courriel de l'utilisateur
- Login
us_login -
Identifiant de connexion. Cet identifiant doit être unique pour l'ensemble des comptes; unique pour les utilisateurs mais aussi pour les références de groupe et de rôle.
Note : Le login doit toujours être en minuscules. S'il comporte des majuscules elle seront transformées en minuscules lors de l'enregistrement.
Cependant, depuis l'interface de connexion, la vérification du login est insensible à la casse. - Rôles
us_roles - Liste des rôles associés à l'utilisateur. Ces rôles peuvent être affectés directement sur l'utilisateur ou obtenus en fonction de ses groupes d'appartenance.
- Identifiant système
us_whatid -
Identifiant numérique système unique.
Cet identifiant est donné par le système lors de l'enregistrement. Il sert d'identifiant pour l'objet système associé au document. Voir Account.
8.2.2 Mot de passe
Le mot de passe exigé par défaut n'a pas de contrainte. Cependant les paramètres applicatifs suivant permettent d'imposer une force minimum au mot de passe :
AUTHENT_PWDMINLENGTH- Nombre minimum de caractères d'un mot de passe
AUTHENT_PWDMINDIGITLENGTH- Nombre minimum de chiffre d'un mot de passe
AUTHENT_PWDMINUPPERALPHALENGTH- Nombre minimum de lettres majuscule d'un mot de passe
AUTHENT_PWDMINLOWERALPHALENGTH- Nombre minimum de lettres minuscules d'un mot de passe
AUTHENT_PWDMINSYMBOLLENGTH- Nombre minimum de caractères qui ne sont ni des lettres ni des chiffres
Le mot de passe utilisé pour les comptes internes peut également contenir des lettres accentuées.
Le mot de passe n'est pas stocké en clair dans la base. Seul son empreinte (SHA256) est stocké afin de vérifier le mot de passe lors de la connexion.
8.2.3 Validation du compte utilisateur
8.2.3.1 Date d'expiration des comptes
Il est possible d'indiquer une date d'expiration du compte sur le document utilisateur. Lorsque cette date est atteinte, toute connexion avec ce compte est refusée et un message indique à l'utilisateur que le compte a expiré.
Cette date est contenue dans l'attribut us_accexpiredate de la fiche
utilisateur.
Il est également possible de définir une durée de validité par défaut au moyen
du paramètre applicatif AUTHENT_ACCOUNTEXPIREDELAY de l'application AUTHENT
(Délai par défaut avant expiration du compte (jours)).
Ce délai exprimé en jour, est utilisé lors de la création d'un compte afin de
calculer la date d'expiration de ce compte.
La date d'expiration est contrôlée quelque soit le mode d'authentification (Dynacase, AD/LDAP, SSO, …). Si elle n'est pas renseignée, le compte n'expire pas.
Ce contrôle n'est pas réalisé pour le super administrateur Dynacase (admin).
8.2.3.2 Limitation des tentatives de connexion
Il est possible d'interdire la connexion pour un compte suite à un trop grand nombre de mots de passe incorrects.
Ce nombre maximal de tentatives est défini au moyen du paramètre
AUTHENT_FAILURECOUNT de l'application AUTHENT (Nombre d'échecs
d'authentification avant la désactivation du compte).
Lors d'une demande d'authentification :
- si le compte est activé
- si le mot de passe est valide
- le compteur est remis à 0
- si le mot de passe est erroné
- un compteur est incrémenté
- si ce compteur dépasse la valeur du paramètre
AUTHENT_FAILURECOUNT, le compte est désactivé
- si le mot de passe est valide
- si le compte est désactivé
- si le mot de passe est erroné
- un compteur est incrémenté
- dans tous les cas, un message est retourné
- si le mot de passe est erroné
Lors de l'installation de dynacase, le paramètre AUTHENT_FAILURECOUNT est
positionné à 0. La valeur 0 indique que le contrôle n'est pas réalisé.
Le compteur est disponible sur la fiche utilisateur au moyen de l'attribut
us_loginfailure. Un menu permet de réinitialiser cette valeur
()
Le contrôle est réalisé quelque soit le mode d'authentification (Dynacase, AD/LDAP, SSO, …).
Ce contrôle n'est pas réalisé pour le super administrateur Dynacase (admin).
8.2.3.3 Activation / désactivation du compte à la demande
Il est possible d'activer ou de désactiver un compte utilisateur à la demande (par défaut, un compte est actif à sa création).
La fiche utilisateur présente les menus et .
L'activation / désactivation de compte n'influe pas sur les droits applicatifs ou documentaires liés aux comptes.
Un compte utilisateur désactivé ne peut plus être utilisé pour se connecter.
Le contrôle est réalisé quelque soit le mode d'authentification (Dynacase, AD/LDAP, SSO, …).
Ce contrôle n'est pas réalisé pour le super administrateur Dynacase (admin).
8.2.4 Droit d'accès
par défaut, les documents de comptes sont accessibles à tous les utilisateurs,
mais leur modification est réservée aux administrateurs (utilisateurs
appartenant au groupe administration - identifiant GADMIN).
Pour le document utilisateur, le détenteur du compte peut modifier ses nom,
prénom, mail et mot de passe.
8.2.5 Création d'un utilisateur
Il est possible de créer manuellement un utilisateur en créant un document de la
famille IUSER depuis l'interface, à condition de bénéficier des privilèges
suffisants.
Par programmation il suffit de créer un document de la famille IUSER.
$du = createDoc("","IUSER"); if ($du) { $du->setValue("us_login","jean.martin"); $du->setValue("us_lname","martin"); $du->setValue("us_fname","jean"); $du->setValue("us_passwd1","secret"); $du->setValue("us_passwd2","secret"); // nécessaire de doubler à cause des contraintes $err = $du->store(); if (!$err) { print "nouvel utilisateur n°".$du->getValue("us_whatid"); // affichage de l'identifiant numérique système } else { print "erreur : $err"; } }
La méthode _IUSER::getAccount() permet de récupérer l'objet système "Account". Voir le paragraphe Account.
8.2.6 Titulaires et suppléants
Un utilisateur peut désigner un suppléant. Le suppléant reçoit tous les privilèges de celui qui l'a désigné. Ce dernier est nommé le titulaire.
- Un suppléant peut
- voir, modifier tous les documents que le titulaire peut voir et modifier,
- accéder à toutes les applications auxquelles le titulaire a accès.
- Un suppléant ne peut pas
- modifier le document utilisateur de ses titulaires. Ainsi le mot de passe du titulaire ne peut pas être changé par son suppléant.
Un titulaire ne peut désigner qu'un seul suppléant. Par contre, un suppléant peut avoir plusieurs titulaires.
Le suppléant est ajouté aux destinataires des courriels qui ont été lancés à partir d'un modèle de mail à destination du titulaire (Le texte « suppléant » est ajouté dans le nom des adresses email des suppléants afin de les différencier des titulaires).
Lors d'une création ou d'une modification d'un document par un suppléant ou lors d'un changement d'état, le texte de l'historique indique que cela est fait par un suppléant dans le cas où celui-ci n'a pas directement (c'est à dire sans qu'il soit suppléant) le droit de le faire.
Les droits sur les suppléants ne sont pas propagés. Ainsi :
- Si l'utilisateur C est suppléant de B
- et l'utilisateur B est suppléant de A
alors
- l'utilisateur C a seulement les privilèges d'origine de B en plus des siens,
- l'utilisateur B a les privilèges d'origine de A en plus des siens.
L'utilisateur C n'a pas les privilèges de A.
La modification d'un suppléant par l'interface est soumis au droit ESUBSTITUTE
du contrôle de vue confidentiel utilisateur qui est associé à la famille
IUSER.
Par défaut aucun utilisateur n'a la droit de désigner un suppléant.
8.2.7 Dérivation de la famille utilisateur
La famille utilisateur IUSER peut être dérivée comme les autres familles.
Cependant, la famille IUSER déclarant des hameçons sur le postStore,
postCreate et postDelete, il faut bien faire attention à rappeler le parent
en cas de surcharge des hameçons.
De même, un contrôle de vues est attaché par défaut aux utilisateurs, il faut aussi reprendre ses vues si la famille dérivée nécessite un autre contrôle de vue.
8.3 Description des groupes d'utilisateurs
8.3.1 Caractéristiques des groupes d'utilisateurs
Les principaux attributs de la famille Groupe d'utilisateurs sont :
- Nom
grp_name - Dénomination du groupe.
- Identifiant
us_login -
Identifiant système.
Il doit être unique sur l'ensemble des comptes (utilisateurs, rôles et groupe).
Note : L'identifiant doit toujours être en minuscules. S'il comporte des majuscules elle seront transformées en minuscules lors de l'enregistrement.
- Mail
grp_mail -
adresse mail du groupe.
Elle est constituée de la concaténation des mails des membres du groupe.
- Sans adresse mail de groupe
grp_hasmail -
Permet de désactiver la génération du mail.
Les valeurs possibles sont :
-
yes(valeur par défaut): génère l'adresse du groupe. -
no: ne génère pas l'adresse du groupe.
Cette option peut être intéressante pour les groupes possédant un très grand nombre de membres. En effet, dans ce cas, le temps de calcul et notamment le temps d'écriture en base sont élevés.
En contrepartie, il sera impossible d'envoyer un mail à ce groupe. -
- Rôles associés
grp_roles -
Tableau indiquant les rôles joués par les utilisateurs membres du groupes.
Les rôles sont des éléments déterminants pour la mise en place des droits
- Fonction
grp_type - Permet de caractériser le groupe
- Identifiant système
us_whatid -
Identifiant numérique système unique.
Cet identifiant est donné par le système lors de l'enregistrement. Il sert d'identifiant pour l'objet système associé au document. Voir Account.
8.3.2 Création d'un groupe
Il est possible de créer manuellement un groupe en créant un document de la
famille IGROUP depuis l'interface, à condition de bénéficier des privilèges
suffisants.
Par programmation il suffit de créer un document de la famille groupe IGROUP.
$dg = createDoc("","IGROUP"); if ($dg) { $dg->setValue("us_login","driver"); $dg->setValue("grp_name","Conducteurs"); $err = $dg->store(); if (!$err) { print "nouveau groupe n°".$dg->getValue("us_whatid"); // affichage de l'identifiant numérique système } else { print "erreur:$err"; } }
La méthode _IGROUP::getAccount() permet de récupérer l'objet système "Account". Voir le paragraphe AccountAjouter le lien vers le chapitre de la classe Account.
8.3.3 Ajout d'un groupe à un utilisateur
L'ajout direct d'un groupe à un utilisateur se fait depuis le groupe au moyen de
la méthode _IGROUP::insertDocument().
$g = new_Doc($dbaccess,"GADMIN"); $u = new_Doc($dbaccess,1075); // 1075 est la référence documentaire de l'utilisateur if ( $g->isAlive() && $u->isAlive() ) { printf("ajout de l'utilisateur %s [%d] au groupe %s [%d]\n", $u->getTitle(),$u->id,$g->getTitle(),$g->id); printf("Liste des groupes avant\n"); print_r($u->getAllUserGroups()); $err = $g->insertDocument($u->initid); if ($err) { print "Error:$err\n"; } else { printf("Liste des groupes après\n"); print_r($u->getAllUserGroups()); } }
8.4 Description des rôles
Les rôles représentent les fonctions des utilisateurs dans l'organisation. Ils sont utilisés dans la définition des droits.
8.4.1 Caractéristiques des rôles
Les principaux attributs de la famille Rôle sont ::
- Nom
role_name - Dénomination du rôle.
- Référence
role_login -
référence système.
Il doit être unique sur l'ensemble des comptes (utilisateurs, rôles et groupes).
Note : la référence doit toujours être en minuscules. Si elle comporte des majuscules elle seront transformées en minuscules lors de l'enregistrement.
Depuis l'interface du centre d'administration, cette référence ne peut pas être renseignée, elle est calculée automatiquement avec un identifiant unique (par exemple : role51949e892a469).
- Identifiant système
us_whatid -
Identifiant numérique système unique.
Cet identifiant est donné par le système lors de l'enregistrement. Il sert d'identifiant pour l'objet système associé au document. Voir Account.
8.4.2 Création d'un rôle
Il est possible de créer manuellement un rôle en créant un document de la
famille ROLE depuis l'interface, à condition de bénéficier des privilèges
suffisants.
Par programmation il suffit de créer un document de la famille rôle ROLE.
$dr = createDoc("","ROLE"); if ($dr) { $dr->setValue("role_login","designer"); $dr->setValue("role_name","Concepteurs"); $err=$dr->store(); if (!$err) { print "nouveau rôle n°".$dr->getValue("us_whatid"); // affichage de l'identifiant numérique système } else { print "erreur:$err"; } }
La méthode _ROLE::getAccount() permet de récupérer l'objet système "Account". Voir le paragraphe Account.
8.4.3 Ajout d'un rôle à un utilisateur
L'ajout direct d'un groupe à un utilisateur se fait depuis le document
Utilisateur.
C'est l'attribut us_roles qu'il faut modifier pour changer les associations de
rôles aux utilisateurs.
$dr = new_doc("",2435); // Rôle à ajouter $du = new_doc("",1073); // Utilisateur if ($du->isAlive()) { $uRoles = $du->getMultipleRawValues("us_roles"); printf("Ajout rôle %s pour %s\n",$dr->getTitle(),$du->getTitle()); $uRoles[] = $dr->getProperty('initid'); $uRoles = array_unique($uRoles); // éviter les doublons si déjà présent $err = $du->setValue("us_roles",$uRoles); if (!$err) { $err = $du->store(); } if ($err) { print "Erreur: $err\n"; } else { print "Nouvelle liste de rôles:\n"; print_r($du->getAttributeValue("us_t_roles")); } }
8.4.4 Association d'un rôle à un groupe
L'association va propager le rôles à l'ensemble des membres du groupes et des
sous-groupes.
C'est l'attribut grp_roles qu'il faut modifier pour changer les associations
de rôles aux groupes.
$dr = new_doc("",2435); // Rôle à ajouter $dg = new_doc("",2434); // Groupe if ($dg->isAlive()) { $gRoles = $dg->getMultipleRawValues("grp_roles"); printf("Ajout rôle %s pour %s\n",$dr->getTitle(),$dg->getTitle()); $gRoles[] = $dr->initid; $gRoles = array_unique($gRoles); // éviter les doublons si déjà présent $err=$dg->setValue("grp_roles",$gRoles); if (!$err) { $err = $dg->store(); } if ($err) { print "Erreur: $err\n"; } else { print "Nouvelle liste de rôles:\n"; print_r($dg->getAttributeValue("grp_roles")); } }
8.5 Importation des comptes en XML
3.2.21 Les comptes utilisateurs peuvent être créés ou modifiés en important un fichier XML de description de comptes. Ce fichier permet d'indiquer les données systèmes des comptes comme le login, le mot de passe, les groupes d'appartenance et les rôles associés.
L'importation purement système utilise le schéma qui ne référence que les données système et aucune donnée documentaire fonctionnelle.
L'importation en plus des données systèmes peut aussi importer des données fonctionnelles si des familles personnalisées ont été définies pour être associées aux comptes.
8.5.1 Importation de compte (XML) depuis l'interface d'administration
Depuis le centre d'administration, dans le gestion des utilisateurs, il est possible d'importer les comptes (utilisateurs, groupes, rôles) depuis un fichier XML.
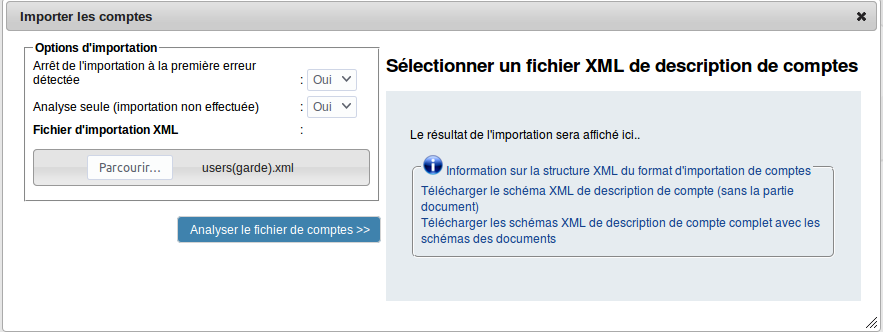
Figure 74. Options d'importation de comptes
8.5.2 Importation de compte (XML) en ligne de commande
L'importation peut être réalisée en ligne de commande :
./wsh.php --api=importAccounts --file=/tmp/myUsers.xml --report=/tmp/myReport.json
Son usage est le suivant :
Usage :
--file=<the input XML file>
Options:
--report-file=<the output report file>
--dry-run (Analyse file only - no import is proceed)
Le rapport est une sortie texte. Si le nom du fichier à l'extension ".csv" le rapport est au format CSV. Si l'extension est ".json", le format du rapport est en json.
Les informations retournées dans le rapport sont :
- login : identifiant du compté traité
- action : code du traitement effectué
- error : message d'erreur (vide si pas d'erreur)
- message : message du traitement effectuée
- node : nœud XML qui est à l'initiative du traitement au traitement (non retourné pour le type texte)
Si une erreur est détectée aucun compte n'est mis à jour.
8.5.3 Format d'importation XML d'utilisateurs
8.5.3.1 Importation minimaliste d'utilisateurs
Les informations obligatoires pour importer un utilisateur sont :
-
login: identifiant du compte servant à l'authentification -
lastname: nom à afficher pour le compte
: le login est toujours en caractère
minuscule. L'authentification est "case insensitive" pour le login.
Le login sert d'identifiant unique. Si un compte existe avec le login défini, ses informations seront mises à jour. S'il n'existe pas, le compte sera créé.
Exemple minimaliste d'importation de 2 comptes "un" et "deux":
<?xml version="1.0" encoding="utf-8"?> <accounts> <users> <user> <login>un</login> <lastname>Premier</lastname> </user> <user> <login>deux</login> <lastname>Deuxième</lastname> </user> </users> </accounts>
Ce fichier importe 2 comptes utilisateur. Ces comptes n'ont aucun rôle et n'appartiennnent à aucun groupe. Ils n'ont pas de mot de passe et ne peuvent se connecter. Par contre, ils sont opérationnels pour être utilisés dans les profils.
8.5.3.2 Autres informations optionnelles sur le compte
Les informations systèmes optionnelles sont :
mail: adresse courriel pour le compte. Cette adresse est notamment utilisée pour la procédure de changement de mot de passe et pour les envois de document par courriel.firstname: prénom de l'utilisateur. Le nom et le prénom constituent le nom à afficher (displayName).status: (booléen) Permet d'activer ou désactiver un compte. Par défaut, le compte est actif. Mettrefalsepour le désactiver. Un compte désactivé ne peut plus se connecter.substitute: (référence) Permet de référencer un suppléant. La référence est le login du compte suppléant. Le suppléant doit être défini avant le titulaire.
Exemple d'importation avec les données optionnelles :
Ce fichier vient compléter les informations du fichier ci-dessus en ajoutant un suppléant pour "un" et les adresses courriels pour les 2 comptes "un" et "deux".
<?xml version="1.0" encoding="utf-8"?> <accounts> <users> <user> <login>deux</login> <lastname>Deuxième</lastname> <firstname>Gérard</firstname> <mail>second@example.net</mail> <status activated="true"/> </user> <user> <login>un</login> <lastname>Premier</lastname> <firstname>Isabelle</firstname> <mail>first@example.net</mail> <status activated="true"/> <substitute reference="deux"/><!-- la référence est défini avant --> </user> </users> </accounts>
8.5.3.3 Mettre un mot de passe
Il est possible de définir un mot de passe lors de la création ou de la modification du compte utilisateur.
La balise password peut contenir le mot de passe en clair ou crypté.
S'il est en clair, il sera crypté avant enregistrement, sinon il sera enregistré
directement. Le mode de cryptage à utiliser est le SHA256.
Mot de passe crypté :
<password crypted="true">$5$6gyojNc42P8GMDB4$QbHmquZLRNwye3TjHaiHuoR6JnYmfwp8eWMD/hGLp93</password>
Mot de passe en clair :
<password crypted="false">Mon secret</password>
8.5.3.4 Affecter l'utilisateur à des groupes
Les groupes d'appartenance directe sont définis dans la balise parentGroups.
Cette balise indique les références aux groupes parents (balises parentGroup).
L'attribut reset est un booléen qui indique si les groupes parents déjà
enregistrés doivent être enlevés avant d'ajouter les nouvelles références. Cet
attribut ne sert que dans le cas de mise à jour de compte. Si reset vaut
false (valeur par défaut), les références aux groupes sont ajoutés aux
anciens groupes sinon les anciens groupes sont retirés du compte utilisateur.
L'attribut reference indique la référence du compte groupe et non le nom
logique du document représentant le groupe.
Exemple : ajout des groupes "vigilance" et "security"
<parentGroups reset="false"> <parentGroup reference="vigilance"/> <parentGroup reference="security"/> </parentGroups>
8.5.3.5 Donner des rôles à un utilisateur
Les rôles de l'utilisateur sont définis dans la balise associatedRoles.
Cette balise indique les références aux différents rôles donnés (balises associatedRole).
L'attribut reset est un booléen qui indique si les rôle déjà
enregistrés doivent être enlevés avant d'ajouter les nouvelles références. Cet
attribut ne sert que dans le cas de mise à jour de compte. Si reset vaut
false (valeur par défaut), les références aux rôles sont ajoutés aux
anciens rôles sinon les anciens rôles sont retirés du compte utilisateur.
L'attribut reference indique la référence du rôle et non le nom
logique du document représentant le rôle.
Exemple : ajout des rôles "veterinary" et "surgeon"
<associatedRoles reset="false"> <associatedRole reference="veterinary"/> <associatedRole reference="surgeon"/> </associatedRoles>
8.5.3.6 Exemple récapitulatif
Importation du compte "garde" qui est dans le groupe "security" et qui a le rôle "surveillant".
<?xml version="1.0" encoding="utf-8"?> <accounts date="2016-04-14T09:54:18"> <roles> <role> <reference>surveillant</reference> <displayName>Gardien surveillant</displayName> </role> </roles> <groups> <group > <reference>security</reference> <displayName>Surveillants</displayName> <parentGroups reset="false"> <parentGroup reference="all"/> </parentGroups> </group> </groups> <users> <user> <login>garde</login> <firstname>Robert</firstname> <lastname>Dogue</lastname> <mail>garde@example.net</mail> <status activated="true"/> <password crypted="true">$5$PsPOxUFpskK25TY4$LjEnQqJw76duTmA9G7dd/XC9zexKgNanxz.3virIIRD</password> <associatedRoles reset="false"> <associatedRole reference="surveillant"/> </associatedRoles> <parentGroups reset="false"> <parentGroup reference="security"/> </parentGroups> </user> </users> </accounts>
8.5.4 Importation XML de groupes
8.5.4.1 Importation minimaliste de groupe
Les informations obligatoires pour importer un groupe sont :
-
reference: référence unique du compte groupe -
displayName: nom du groupe à afficher
: la reference est toujours en caractère
minuscule.
Exemple : création du groupe "business".
<?xml version="1.0" encoding="utf-8"?> <accounts> <groups> <group> <reference>business</reference> <displayName>Service commercial</displayName> </group> </groups> </accounts>
8.5.4.2 Définir une arborescence de groupe
Les balises d'affectation de groupe est identique aux celles des utilisateurs.
Exemple :
business sponsor
⇘angels⇙
<?xml version="1.0" encoding="utf-8"?> <accounts > <groups> <group> <reference>business</reference> <displayName>Service commercial</displayName> </group> <group> <reference>sponsor</reference> <displayName>Mécènes</displayName> </group> <group > <reference>angels</reference> <displayName>Business angels</displayName> <parentGroups reset="false"> <parentGroup reference="business"/> <parentGroup reference="sponsor"/> </parentGroups> </group> </groups> </accounts>
8.5.4.3 Donner des rôles à un groupe
Les rôles sont associés à un groupe de la même manière que pour les utilisateurs.
8.5.5 Importation XML de rôles
Les informations obligatoires pour importer un rôle sont :
-
reference: référence unique du compte rôle -
displayName: nom du rôle à afficher
: la reference est toujours en caractère
minuscule.
<?xml version="1.0" encoding="utf-8"?> <accounts> <roles> <role> <reference>watcher</reference> <displayName>Surveillant</displayName> </role> <role> <reference>veterinary</reference> <displayName>Vétérinaire</displayName> </role> </roles> </accounts>
8.5.6 Importation d'utilisateurs avec données fonctionnelles personnalisées
Les comptes sont représentés par des documents. Ces documents permettent d'interagir avec les comptes systèmes.
Les familles utilisées par défaut pour chaque type de compte sont :
La balise document permet de modifier le document lié au compte.
Elle contient la représentation XML du document lié.
8.5.6.1 Poser un nom logique sur le document associé au compte
Le nom logique est indiqué sur l'attribut name de la balise du document lié.
Exemple : Mettre le nom logique "USER_CONTROL" sur le compte "control".
<?xml version="1.0" encoding="utf-8"?> <accounts date="2016-04-14T11:40:22"> <users> <user id="1"> <login>control</login> <firstname>Robert</firstname> <lastname>Watson</lastname> <document family="IUSER"> <iuser name="USER_CONTROL" /> </document> </user> </users> </accounts>
8.5.6.2 Modifier le date d'expiration du compte
La date d'expiration n'est pas une donnée du compte système. Elle est définie
dans la famille IUSER dans l'attribut us_accexpiredate.
<?xml version="1.0" encoding="utf-8"?> <accounts> <users> <user> <login>watch.garde</login> <firstname>Robert</firstname> <lastname>Dogue</lastname> <mail>garde@example.net</mail> <document family="IUSER"> <iuser name="MY_BIGGARDE" > <us_tab_system> <us_fr_security> <us_accexpiredate>2016-04-13</us_accexpiredate> </us_fr_security> </us_tab_system> </iuser> </document> </user> </users> </accounts>
8.5.6.3 Associer un compte avec une famille personnalisée
Pour utiliser une famille personnalisée, il est nécessaire que celle-ci soit
dérivée des familles par défaut (IUSER, IGROUP ou ROLE).
Le format XML du document associé doit suivre le schéma de la famille donné. L'ensemble des schémas XML nécessaires peut être obtenu depuis le centre d'administration. Il est accessible en cliquant sur le bouton "Importer les comptes" depuis l'interface de gestion des utilisateurs.
Exemple : associer le compte avec un document de la famille "my_watcher". Cette
famille héritant de la famille IUSER, permet d'indiquer les heures de gardes
et la zone à garder.
<?xml version="1.0" encoding="utf-8"?> <accounts> <users> <user> <login>watch.garde</login> <firstname>Robert</firstname> <lastname>Watson</lastname> <mail>watch.garde@example.net</mail> <associatedRoles reset="false"> <associatedRole reference="surveillant"/> </associatedRoles> <parentGroups reset="false"> <parentGroup reference="all"/> <parentGroup reference="security"/> </parentGroups> <document family="MY_WATCHER"> <my_watcher name="MY_BIGWATCH" > <watch_tab_watching> <watch_fr_watching> <watch_beginhour>10:00:00</watch_beginhour> <watch_endhour>18:00:00</watch_endhour> <watch_array_zone> <watch_zone name="MY_ZONE51">Zone protégée</watch_zone> </watch_array_zone> </watch_fr_watching> </watch_tab_watching> </my_watcher> </document> </user> </users> </accounts>
8.6 Exportation XML des comptes
3.2.21 Les formats d'exportation des comptes suivent les mêmes schémas que ceux de l'importation XML.
Les fichiers produits par l'exportation peuvent être réutilisés pour l'importation. Ils ne contiennent pas de données calculées exploitables par l'importation.
Exemple d'exportation : 1 utilisateur et 2 groupes
<?xml version="1.0" encoding="utf-8"?> <accounts date="2016-04-14T14:42:15"> <groups> <group id="2"> <reference>all</reference> <displayName>Utilisateurs</displayName> <document family="IGROUP"/> </group> <group id="10"> <reference>security</reference> <displayName>Surveillants</displayName> <parentGroups reset="false"> <parentGroup reference="all"/> </parentGroups> <document family="IGROUP"/> </group> </groups> <users> <user id="15"> <login>watcher</login> <firstname>Robert</firstname> <lastname>Dogue</lastname> <mail>watcher@example.net</mail> <status activated="true"/> <password crypted="true">$5$PsPOxUFpfkK25TY4$LjEnQaJw76duTzM9G7dq/XC9zexKgNOnxz.3virIIRD</password> <associatedRoles reset="false"> <associatedRole reference="surveillant"/> </associatedRoles> <parentGroups reset="false"> <parentGroup reference="security"/> </parentGroups> <document family="IUSER"/> </user> </users> </accounts>
L'exportation fournie la date d'exportation sur la balise racine (attribut
date). Sur chaque compte, l'identifiant numérique interne est indiqué
(attribut id). Cet attribut n'est pas utilisé pour l'importation. Il est
donné à titre indicatif.
8.6.1 Exportation par l'interface d'administration
L'exportation des comptes peut être réalisée depuis le centre d'administration dans la gestion des utilisateurs.
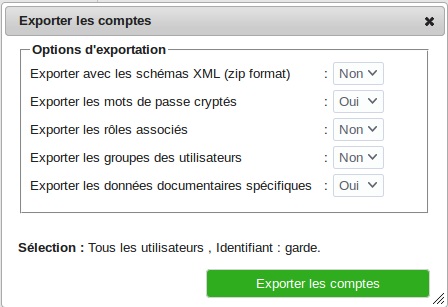
Figure 75. Options d'exportation de comptes
- Exporter avec les schémas XML (zip format)
- Inclus un répertoire XSD dans lequel tous les schémas XML nécessaires à la validation de fichiers d'importation sont présents
- Exporter les mots de passe cryptés
- Inclus la balise
passwordavec le mot de passe crypté pour les utilisateurs (le mot de passe en clair n'est pas enregistré)
- Exporter les rôles associés
- Inclus la définitions des rôles associés pour les utilisateurs et les groupes
- Exporter les groupes des utilisateurs
- Inclus la définition des groupes d'appartenances (groupes directs et indirects)
- Exporter les données documentaires spécifiques
- Inclus la définition du document associé au compte. Les données redondantes avec les données systèmes inclus dans le document ne sont pas exportés.
L'exportation via l'interface, exporte les comptes affichés au moment de l'exportation.
8.6.2 Exportation de comptes en ligne de commande
L'exportation en ligne de commande est réalisé avec le script "exportAccounts"
./wsh.php --api=exportAccounts --help
Export accounts definition
Usage :
--file=<the output file (use - for stdout)>
Options:
--schema-directory=<directory where produce xsd for documents>
--memberOf=<Restrict to account which are member of this group or role reference>
--type=<restricted to account type> [user|role|group]
--login-filter=<filter login contains>
--help (Show usage)
--crypt-password (add crypt password)
--roles (export associated roles)
--groups (export parent groups)
--document (export specific document information)
Sans aucun argument autre que le fichier, cette commande exporte l'ensemble des comptes dans le fichier XML défini en sortie.
8.7 Importations de comptes (document)
3.2.21 Ce chapitre décrit une alternative à l'importation XML en utilisant l'importation de document. Il est toutefois préférable d'utiliser l'importation XML qui permet de mieux contrôler les caractéristiques spécifique à l'importation de comptes. Ce mode d'importation reste néanmoins opérationnel et est adapté pour la mise à jour de données fonctionnelles enregistré sur les documents liés aux comptes.
L'importation de groupes, d'utilisateurs et de rôles est effectuée à l'aide d'un
fichier d'importation CSV (texte séparé par des point-virgules) ou ODS comme
pour les importations de documents en général.
8.7.1 Importation d'utilisateurs
La création de compte utilisateur nécessite les 6 informations suivantes :
- le nom
us_lname - le prénom
us_fname - le login
us_login - le mot de passe
us_passwd1etus_passwd2. Les deux mots de passe doivent être identiques. - le mail
us_extmailfacultatif, mais nécessaire pour récupérer son mot de passe oublié.
| # | IUSER | Identifiant | Groupe | login | prénom | nom | mot de passe | confirmation | adresse mail |
|---|---|---|---|---|---|---|---|---|---|
| ORDER | IUSER | us_login | us_fname | us_lname | us_passwd1 | us_passwd2 | us_extmail | ||
| DOC | IUSER | robert.martin | Robert | Martin | secret | secret | roby@somewhere.net | ||
| DOC | IUSER | isabelle.dujardin | Isabelle | Dujardin | secret | secret | isa@somewhere.net |
8.7.2 Importation de groupes
La création de groupes nécessite les 2 informations suivantes :
- le nom
grp_name - la référence
us_login
| # | IGROUP | Identifiant | Groupe | nom | référence |
|---|---|---|---|---|---|
| ORDER | IGROUP | grp_name | us_login | ||
| DOC | IGROUP | Laboratoire recherche | labord | ||
| DOC | IGROUP | Comité d'entreprise | ce |
8.7.3 Importations de rôles
La création de groupes nécessite les 2 informations suivantes :
- le nom
grp_name - la référence
us_login
| # | ROLE | Identifiant | Groupe | nom | référence |
|---|---|---|---|---|---|
| ORDER | ROLE | role_name | role_login | ||
| DOC | ROLE | Concepteurs | designers | ||
| DOC | ROLE | Conducteurs | drivers |
Note : Le rôle ne peut pas être inséré dans un groupe.
8.7.4 Affectation de groupes par importation
L'affectation de groupes se fait en indiquant l'identifiant du groupe dans la colonne Identifiant du fichier.
Dans l'exemple suivant :
- l'utilisateur Robert Martin sera inséré dans le groupe
- Laboratoire de recherche
- l'utilisatrice Isabelle Dujardin sera insérée dans les groupes
- Laboratoire de recherche
- Comité d'entreprise.
| # | IGROUP | Identifiant | Groupe | nom | référence |
|---|---|---|---|---|---|
| ORDER | IGROUP | grp_name | us_login | ||
| DOC | IGROUP | GRP_LABORECHERCHE | Laboratoire de recherche | labord | |
| DOC | IGROUP | GRP_CE | Comité d'entreprise | ce |
| ## | IUSER | Identifiant | Groupe | login | prénom | nom | mot de passe | confirmation | adresse mail |
|---|---|---|---|---|---|---|---|---|---|
| ORDER | IUSER | us_login | us_fname | us_lname | us_passwd1 | us_passwd2 | us_extmail | ||
| DOC | IUSER | GRP_LABORECHERCHE | robert.martin | Robert | Martin | secret | secret | roby@somewhere.net | |
| DOC | IUSER | US_ISA | GRP_CE | isabelle.dujardin | Isabelle | Dujardin | secret | secret | isa@somewhere.net |
| DOC | IUSER | US_ISA | GRP_LABORECHERCHE |
8.7.5 Affectation de rôles par importation
L'affectation de rôle à un utilisateur est fait avec l'attribut us_roles.
L'association de rôle à un groupe est fait avec l'attribut grp_roles. Ces deux
attributs sont multivalués et ils peuvent contenir plusieurs références séparé
par les deux caractères \n.
Dans l'exemple suivant, "Robert Martin" aura les rôles "Concepteurs" et
"Conducteur" car il appartient au groupe "Laboratoire annexe" qui est un sous-
groupe de "Laboratoire de recherche". "Isabelle Dujardin" aura les rôles
"Concepteur" et "Conducteur" car elle appartient au groupe "Laboratoire de
recherche" et "Chimiste" car ce rôle est explicitement indiqué dans l'attribut
us_roles.
| # | ROLE | Identifiant | Groupe | nom | référence |
|---|---|---|---|---|---|
| ORDER | ROLE | role_name | role_login | ||
| DOC | ROLE | ROLE_DESIGN | Concepteurs | designers | |
| DOC | ROLE | ROLE_DRIVE | Conducteurs | drivers | |
| DOC | ROLE | ROLE_CHEMIST | Chimiste | chemist |
| # | IGROUP | Identifiant | Groupe | nom | référence | roles |
|---|---|---|---|---|---|---|
| ORDER | IGROUP | grp_name | us_login | grp_roles | ||
| DOC | IGROUP | GRP_LABORECHERCHE | Laboratoire de recherche | labord | ROLE_DESIGN\nROLE_DRIVE | |
| DOC | IGROUP | GRP_CE | Comité d'entreprise | ce | ROLE_DESIGN | |
| DOC | IGROUP | GRP_LABOANX | GRP_LABORECHERCHE | Recherches annexes | anx |
| # | IUSER | Identifiant | Groupe | login | prénom | nom | mot de passe | confirmation | adresse mail | rôles |
|---|---|---|---|---|---|---|---|---|---|---|
| ORDER | IUSER | us_login | us_fname | us_lname | us_passwd1 | us_passwd2 | us_extmail | us_roles | ||
| DOC | IUSER | GRP_LABOANX | robert.martin | Robert | Martin | secret | secret | roby@somewhere.net | ||
| DOC | IUSER | US_ISA | GRP_CE | isabelle.dujardin | Isabelle | Dujardin | secret | secret | isa@somewhere.net | ROLE_CHEMIST |
| DOC | IUSER | US_ISA | GRP_LABORECHERCHE |
Chapitre 9 Sécurité - droits et profils
Ce chapitre décrit quels sont les éléments de sécurité qui doivent être mis en place afin de garantir l'accès aux documents et aux interfaces en général.
9.1 Niveaux de sécurité
Pour accéder à une information documentaire, trois niveaux de sécurité sont utilisés.
- l'authentification. Ce premier niveau est en charge de vérifier l'identité de l'utilisateur,
- le deuxième niveau de sécurité permet de vérifier que l'utilisateur a le droit d'exécuter une action,
- le troisième niveau de sécurité permet de vérifier l'accès à un document.
9.2 Paramètres de profilage
Les profils indiquent un ensemble de règles permettant de déterminer si un utilisateur a le droit requis pour exécuter une requête.
Un profil comprend un ensemble de droits. Ces droits n'ont pas de hiérarchie, l'obtention d'un droit ne nécessite jamais l'obtention d'un autre droit. Chaque droit peut être posé sur les rôles, les groupes et les utilisateurs du système.
Les vérifications d'accès ne se font que sur les utilisateurs. Les rôles et les groupes ne pouvant pas se connecter, ils ne servent qu'à propager des droits vers les utilisateurs.
Règles d'affectation :
- Affectation des rôles :
- Un utilisateur peut avoir un ou plusieurs rôles.
- Un groupe peut être associé à un ou plusieurs rôles.
- Un rôle ne peut pas avoir de rôle.
- Affectation des groupes :
- Un utilisateur peut appartenir à un ou plusieurs groupes.
- Un groupe peut appartenir à un ou plusieurs groupes (arborescence).
- Un groupe fils ne peut pas avoir comme enfant un de ses groupes parents (pas de cycle).
- Un rôle ne peut pas appartenir à un groupe.
Règles de propagation :
Si un rôle est donné à un utilisateur
alors cet utilisateur récupère tous les droits posés sur le rôle.Si un rôle est associé à un groupe
alors tous les membres (utilisateurs) du groupe et de ses sous-groupes récupèrent les droits posés sur le rôle.Les droits posés sur un groupe sont propagés sur tous les membres (utilisateurs) du groupe et de ses sous-groupes.
9.2.1 Exemple
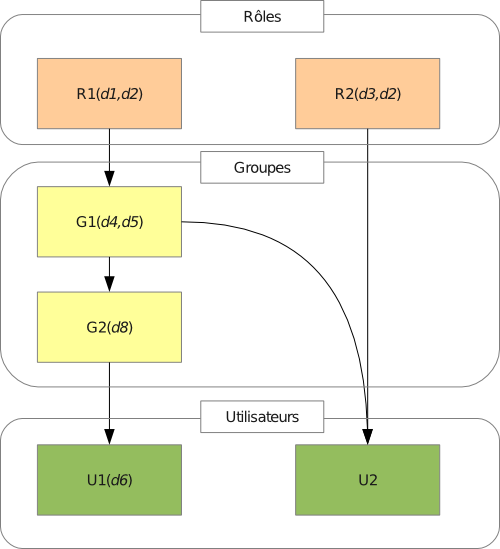
Figure 76. Sécurité : Exemple de hiérarchie
Description de l'exemple ci-dessus :
- le rôle R1 a les droits d1 et d2,
- le rôle R2 a les droits d3 et d2,
- le rôle R1 est associé au groupe G1,
- le groupe G1 a les droits d4 et d5,
- le groupe G2 appartient au groupe G1,
- le groupe G2 a le droit d8,
- l'utilisateur U1 a le droit d6,
- l'utilisateur U1 appartient au groupe G2,
- l'utilisateur U2 n'a pas de droit propre,
- l'utilisateur U2 appartient au groupe G1,
- l'utilisateur U2 a le rôle R2.
L'exemple ci-dessus, donne les droits suivants :
- L'utilisateur U1 a les droits d1, d2, d4, d5, d6, d8 obtenus
comme suit :
- d1, d2 récupérés de R1,
- d4, d5 récupérés de G1,
- d6 qu'il a en propre,
- d8 récupéré de G2.
- L'utilisateur U2 a les droits d1, d2, d3, d4, d5 obtenus comme
suit :
- d1 récupéré de R1,
- d2 récupéré de R1 et R2,
- d3 récupéré de R2,
- d4, d5 récupérés de G1.
À ces règles, s'ajoute la notion de suppléant. Le suppléant récupère les droits du titulaire.
Dans notre cas, si U2 est suppléant de U1, alors les droits de U2 sont :
-
d1, d2, d3, d4, d5, d6, d8 obtenus comme suit :
- d1, d2, d3, d4, d5 qu'il a en propre,
- d6, d8 obtenus par suppléance.
9.2.2 Accès anonyme
Si l'accès est fait en mode anonyme, l'utilisateur utilisé pour
vérifier les droits est anonymous guest (login : anonymous, nom logique :
USER_GUEST). Sur une installation initiale, cet utilisateur n'appartient à
aucun groupe et n'a aucun rôle.
9.3 Paramétrage des droits applicatifs
Afin d'exécuter une action, l'utilisateur doit disposer du droit applicatif requis.
Les droits peuvent être défini avec le centre d'administration ou par importation.
9.3.1 Format d'importation de droit applicatif
Le format de fichier est :
Le contenu du fichier suit la syntaxe suivante :
-
ACCESS: mot-clef indiquant la pose d'un droit - Identifiant du compte
- Nom logique d'un document Rôle (
ROLE), Groupe (IGROUP) ou Utilisateur (IUSER); - Identifiant système numérique d'un compte. Ceci n'est pas l'identifiant
du document. C'est le numéro indiqué dans l'attribut
us_whatiddu document correspondant;
- Nom logique d'un document Rôle (
- Nom de l'application;
- Nom du droit applicatif;
- Nom d'un autre droit, etc.
Exemple de fichier d'importation de droit applicatifs.
| Clef | Compte | Application | Droit | Droit | Droit |
|---|---|---|---|---|---|
| ACCESS | MY_LITTEROLE | MY_APP | MY_FIRSTACL | MY_SECONDACL | |
| ACCESS | MY_BIGROLE | MY_APP | MY_FIRSTACL | MY_THIRDACL | MY_EXTRAACL |
| ACCESS | MY_ADMINUSER | MY_APP | MY_FIRSTACL | MY_ADMINACL |
La clef ACCESS ne fait qu'ajouter des droits. L'importation ne permet pas de
supprimer les droits.
L'importation se fait par la commande wsh.
9.3.2 Les droits applicatifs négatifs
Les droits applicatifs peuvent aussi être posés de manière à restreindre un accès donné par un rôle ou un groupe.
Pour poser un droit applicatif négatif, il faut préfixer le nom du droit avec le
caractère - (moins).
Exemple :
| Clef | Compte | Application | Droit | Droit | Droit |
|---|---|---|---|---|---|
| ACCESS | MY_BIGROLE | MY_APP | MY_FIRSTACL | MY_THIRDACL | MY_EXTRAACL |
| ACCESS | MY_BIGGROUP | MY_APP | -MY_THIRDACL | ||
| ACCESS | MY_SPECIALUSER | MY_APP | -MY_EXTRAACL | MY_SPECIALACL |
Si :
- L'utilisateur MY_SPECIALUSER est membre du groupe MY_BIGGROUP.
- Le rôle MY_BIGROLE est associé au groupe MY_BIGGROUP.
Alors :
- L'utilisateur MY_SPECIALUSER a les droits MY_FIRSTACL et MY_SPECIALACL.
- Les membres du groupes MY_BIGGROUP (autre que MY_SPECIALUSER) ont les droits MY_FIRSTACL et MY_EXTRAACL.
9.4 Droits définis sur les applications fournies par Dynacase Core
La colonne Mis par défaut indique que ce droit est posé sur le groupe
GDEFAULT (Groupe "Utilisateurs") qui est le groupe par défaut des
utilisateurs.
| Application | Droit | Mis par défaut | Description |
|---|---|---|---|
| FDL | EDIT | Oui | Autorise le verrouillage et le déverrouillage de document. Accès aux menus spécifiques liés au méthodes du document |
| FDL | NORMAL | Oui | Autorise les accès aux interfaces standards de consultation de document |
| FDL | SYSTEM | Non | Autorise la modification des paramètres pour les documents famille. Doit être utilisé en corrélation avec FREEDOM_MASTER. |
| FDL | FAMILY | Non | Autorise le paramétrage spécifique de famille (énuméré, valeur par défaut, etc.). |
| FDL | EXPORT | Non | Autorise l'exportation de dossiers ou de recherches. Doit être utilisé en corrélation avec FREEDOM_MASTER. |
| GENERIC | GENERIC_READ | Oui | Autorise les accès aux interfaces standards de liste de documents |
| GENERIC | GENERIC | Oui | Autorise les accès aux interfaces standards de modification de document |
| FREEDOM | FREEDOM_HISTO | Oui | Autorise la consultation de l'historique du document |
| FREEDOM | FREEDOM_READ | Oui | Accès aux interfaces de consultation de l'application FREEDOM (liste de document, arborescence de dossier) |
| FREEDOM | FREEDOM | Oui | Accès aux interfaces de modification (déplacement de dossier, duplication, ...) |
| FREEDOM | FREEDOM_ADMIN | Non | Accès aux interfaces de traitement par lot |
| FREEDOM | FREEDOM_MASTER | Non | Accès aux interfaces d'importation et d'exportation. |
| FGSEARCH | FGSEARCH_READ | Oui | Accès à la recherche générale |
| DAV | DAV_USER | Oui | Accès à l'espace d'échange de fichiers via le protocole WebDav. (non configuré par défaut) |
9.5 Paramétrage des droits documentaires
9.5.1 Le profil de documents
Un profil de documents permet de déterminer les droits acquis pour les rôles, les groupes et les utilisateurs pour un document donné.
Le profil contient la matrice permettant d'associer comptes et droits.
Exemple de matrice de droits :
| Droit D1 | Droit D2 | Droit D3 | |
|---|---|---|---|
| Rôle R1 | X | X | |
| Rôle R2 | X | ||
| Groupe G1 | X | ||
| Utilisateur U1 | O | O | O |
Quatre familles de profils sont définies :
- profil de famille (droit de créer des documents ou de voir la famille),
- profil de document (droit de voir, modifier ou supprimer des documents),
- profil de dossier (droit de voir le contenu du dossier),
- profil de recherche (droit d'exécuter la recherche).
Liste des droits définis pour ces quatre familles de profils :
Légende :
-
D: Pour les profils de Document, -
F: Pour les profils de Dossier (Folder), -
S: Pour les profils de Recherche (Search), -
C: Pour les profils de Famille (Class).
| Nom interne | Description | Description longue | D |
F |
S |
C |
|---|---|---|---|---|---|---|
| view | Voir | Voir les caractéristiques du document, du dossier ou de la recherche. Le fait de ne pas voir un dossier n'implique pas de ne pas voir les documents contenus dans le dossier. | X | X | X | |
| edit | Modifier | Modifier les caractéristiques du document, du dossier. | X | X | X | |
| delete | Supprimer | Supprimer le document, le dossier, la recherche Suppression logique. | X | X | X | |
| unlock | Déverrouiller | Déverrouiller le document. | X | X | X | |
| viewacl | Voir les droits | Voir les droits du document. | X | X | X | |
| modifyacl | Modifier les droits | Modifier les droits du document. | X | X | X | |
| confidential | Voir document confidentiel | Permet d'utiliser normalement un document qui est confidentiel. (Confidentiel est une propriété de document). | X | X | X | |
| send | Envoyer | Envoyer par courriel le document. | X | |||
| open | Ouvrir | Ouvrir le dossier. Permet de voir le contenu du dossier. | X | |||
| modify | Contenu | Modifier le contenu du dossier. Permet d'ajouter ou de supprimer des documents dans le dossier. | X | |||
| execute | Executer | Permet d'exécuter la recherche. | X | |||
| create | Créer | Autorise la création de document de cette famille. | X | |||
| icreate | Créer manuellement | Autorise la création de document de cette famille à partir de l'interface. Si ce droit n'est pas mis et que create est mis, l'utilisateur ne pourra créer le document que de manière indirecte (soit sur une transition, soit sur toute autre action particulière mis en place par l'administrateur). Sans ce droit les menus de création de cette famille sont inaccessibles. Si ce droit est mis il faut que le droit create soit aussi mis. |
X | |||
9.5.2 Profil liés
Un document Profil est fait pour être appliqué à des documents. Un document qui est lié à un profil obtient les mêmes droits que ceux définis sur le profil. Dès que les droits du profils sont changés alors tous les documents liés à ce profils ont également leurs droits mis à jour.
Une famille peut indiquer un profil par défaut pour les documents de cette famille. Une fois cette propriété de famille enregistrée, tous les documents sont liés au même profil lors de leur création. Les documents déjà existants ne sont donc pas affectés.
Un document sans profil n'est pas protégé. Il est alors accessible et modifiable par tous les utilisateurs.
9.5.2.1 Lier un profil par fichier d'importation
Le profil d'un document peut être modifié avec un fichier d'importation en
utilisant la clef PROFID. La syntaxe est celle décrite pour
l'exportation de profil.
| Identifiant du document | Identifiant du profil | |
|---|---|---|
| PROFIL | MY_DOCUMENT | MY_PROFIL |
9.5.2.2 Affecter les droits d'un profil par importation
Un droit peut être posé sur un rôle, un groupe ou un utilisateur.
3.2.21 Le compte peut être identifié avec son login pour les utilisateurs et la "référence" pour les groupes et rôles. Le type de compte peut être indiqué dans la troisième colonne ou directement dans l'expression de la référence au compte. Le type précisé dans la référence est prioritaire au type indiqué dans la troisième colonne.
Pour indiquer ce compte, le nom logique du document lié à ce compte aussi être utilisé.
Pour compatibilité avec les anciennes versions (3.2.20) l'identifiant système du compte (attribut us_whatid donné sur le document) est utilisable si le type de compte n'est pas indiqué.
Exemple :
| Identifiant du profil | Type de compte | Option | Droit | Droit | Droit | |
|---|---|---|---|---|---|---|
| PROFIL | MY_FIRST_PROFIL | :useAccount |
RESET |
view=attribute(tst_writer), john.doe | edit=attribute(tst_writer) | delete=gadmin |
| PROFIL | MY_SECOND_PROFIL | :useDocument |
RESET |
view=DOC_JOHN, SPECIAL_GROUP | edit=DOC_JOHN | delete=GADMIN |
Soit le compte utilisateur X : login : john.doe (id système : 23), nom
logique : DOC_JOHN. Le profil est dynamique et son document lié à un attribut
account nommé my_account.
| Type | Référence | Résultat |
|---|---|---|
| vide | john.doe | KO |
| vide | DOC_JOHN | OK |
| vide | my_account | OK |
| vide | 23 | OK |
| tout type | account(john.doe) | OK |
| tout type | document(DOC_JOHN) | OK |
| tout type | attribute(my_account) | OK |
:useAccount |
john.doe | OK |
:useAccount |
DOC_JOHN | KO |
:useAccount |
my_account | KO |
:useAccount |
23 | KO |
:useDocument |
john.doe | KO |
:useDocument |
DOC_JOHN | OK |
:useDocument |
my_account | KO |
:useDocument |
23 | KO |
:useAttribute |
john.doe | KO |
:useAttribute |
DOC_JOHN | KO |
:useAttribute |
my_account | OK |
:useAttribute |
23 | KO |
Quatre options permettent de spécifier le comportement d'importation des droits :
-
ADD: Ajout de droits (option par défaut).
Les anciens droits sont conservés, les droits spécifiés seront ajoutés. -
DELETE: Suppression de droits.
Les droits spécifiés sont retirés. -
SET: Synchronisation des droits sans mise à jour systématique des documents. 3.2.17 Les droits à importer sont comparés aux droits en base et la mise à jour des documents n'est effectuée uniquement si les droits à importer sont différents de ceux présents en base. -
RESET: Réinitialisation des droits.
Les anciens droits sont retirés, les droits spécifiés sont ajoutés et un calcul des droits est lancé sur tous les documents associés à ce profil. Attention : Cette opération peut-être consommatrice en temps et en ressources.
Dans le fichier d'importation chaque droit posé est déclaré après la quatrième colonne. Pour chacun des droits, un ou plusieurs identifiant de compte doit être indiqué. Si plusieurs comptes sont associés à un droit ils doivent être dans la même cellule séparés par une virgule ou alors dans des cellules séparées.
| Identifiant du profil | Type de compte | Option | Droit | Droit | Droit | |
|---|---|---|---|---|---|---|
| PROFIL | MY_PROFIL | :useAccount |
RESET |
view=all, gadmin | edit=gadmin | delete=gadmin |
| PROFIL | MY_OTHER_PROFIL | :useAccount |
view=all | edit=myfirstrole | view=myfirstgroup | |
9.5.2.3 Lier un profil par programmation
La méthode Doc::setProfil($profilIdentifier) permet de lier un profil à un
document.
Note : Un document Profil ne peut pas être lié à un autre profil.
9.5.3 Profil dédié
Un document qui porte son propre profil est déclaré comme profil dédié. Cela implique que la modification du profil du document n'impacte que lui-même.
Les documents "profil" ont tous un profil dédié.
En utilisant un fichier d'importation., l'exemple suivant déclare un profil dédié :
| Identifiant du document | Identifiant du profil | |
|---|---|---|
| PROFIL | MY_DOCUMENT | MY_DOCUMENT |
9.5.4 Profil dynamique
Un document profil est dynamique si l'attribut "dynamique/famille"
(dpdoc_famid) est valorisé. Cet attribut doit contenir un identifiant de
famille. Dans ce cas, ce profil ne peut être lié qu'à un document de cette
famille ou dérivé de cette famille.
Cette caractéristique permet de rajouter des droits en fonction des attributs
account présents dans le document. Les attributs de type
docid avec l'option isuser=yes sont aussi utilisables comme
paramètre de droit.
Exemple :
| BEGIN | Recette | TST_RECETTE | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| // | idattr | idframe | label | T | A | type | ord | vis | need | ... | option |
| ATTR | TST_IDENTIFICATION | Identification | N | N | frame | 100 | W | ||||
| ATTR | TST_SUBJECT | AN_IDENTIFICATION | Sujet | Y | N | text | 110 | W | Y | ||
| ATTR | TST_WRITER | AN_IDENTIFICATION | Rédacteur | N | N | account | 120 | W | |||
| ATTR | TST_OBSERVERS | AN_IDENTIFICATION | Observateurs | N | N | account | 130 | W | match=group |
Dans cette famille, le rédacteur et le groupe d'observateurs peuvent être utilisés dans la définition des droits. Il est possible d'avoir les règles suivantes :
- le rédacteur a le droit de voir et de modifier le document,
- les observateurs ont le droit de voir le document.
Si le rédacteur est modifié alors les droits sur le document sont
automatiquement (et en temps réel) mis à jour en conséquence. De même si un
utilisateur devient membre du groupe référencé par l'attribut tst_observers
alors il aura aussitôt le droit de voir ce document.
L'importation de droits pour un profil dynamique se fait en utilisant l'identifiant de l'attribut à la place de l'identifiant d'un rôle, d'un groupe ou d'un utilisateur. Un profil dynamique peut aussi avoir une partie statique comme les profils standards.
| Identifiant du profil | Type de compte | Option | Droit | Droit | Droit | |
|---|---|---|---|---|---|---|
| PROFIL | MY_DYNAMIC_PROFIL | :useAttribute |
RESET |
view=tst_writer, tst_observers | edit=tst_writer | delete=account(gadmin) |
| PROFIL | MY_DYNAMIC_OTHER_PROFIL | :useAccount |
RESET |
view=attribute(tst_writer), john.doe | edit=attribute(tst_writer) | delete=gadmin |
Les noms des attributs peuvent être écrits sans prendre en compte la casse dans le fichier d'importation.
: Si l'identifiant d'un attribut est le même qu'un nom logique de compte c'est le nom logique du compte qui est utilisé dans le cas où le type de compte n'est pas précisé.
: Si la référence d'un compte est en
conflit avec la notation de type (exemple "attribute(test)"), il est
nécessaire de préciser sa référence avec le type explicite :
"account(attribute(test))"
9.5.5 Profil privé
Le profil privé est un profil personnel associé à chacun des utilisateurs. C'est un profil de dossier. Il est applicable aussi aux documents.
Le nom logique de ce profil est PERSONAL-PROFIL-<uid>. uid est l'identifiant
système (numérique) du compte.
La fonction getMyProfil() permet de récupérer le profil privé de l'utilisateur
courant. Par défaut, le profil privée donne tous les droits à l'utilisateur
associé et aucun droit aux autres utilisateurs. L'utilisateur peut alors décider
d'ajouter d'autres groupes ou d'autre utilisateurs à son profil pour accéder à
ces documents privés.
9.6 Paramétrage des droits pour un contrôle de vue
Le contrôle de vue ne peut qu'avoir un profil dédié. Les droits d'un contrôle de vue sont ceux d'un document auquel sont ajoutés un droit par vue déclarée dans le contrôle de vue.
Les identifiants des droits spécifiques sont les noms des vues (attribut
cv_idview, Id vues dans le tableau ci-dessous).
Les droits classiques sont ceux du contrôle de vue et non ceux du document auquel le contrôle de vue est attaché.
Les droits spécifiques indiquent les droits d'accès à la vue indiquée.
L'accès aux vues de consultation nécessite d'avoir le droit de consulter (droit
view) le document associé. De même, l'accès aux vues d'édition nécessite le
droit de modifier (droit edit) le document associé.
Le droit de voir le contrôle de vue n'est pas nécessaire pour accéder aux vues.
Les droits ainsi définis sont utilisés pour déterminer la vue à utiliser à chaque accès au document.
Les contrôles de vues ont la possibilité d'avoir un profil dynamique
en indiquant la famille dans l'attribut "dynamique\famille" (dpdoc_famid).
Dans ce cas, ce sont les valeurs des attributs du document associé qui sont
utilisées pour vérifier les droits d'accès aux vues.
9.6.1 Exemple
| Id vues | Label | Type | Zone | Masque | Ordre | Affichable |
|---|---|---|---|---|---|---|
| VueA | Administration | Consultation | Masque admin | 1 | non | |
| VueB | Impression | Consultation | TST:MYIMP | oui | ||
| VueC | Avis | Édition | Masque avis | non | ||
| VueD | Notations | Consultation | Masque notation | 2 | non |
Pour plus d'informations sur les différentes caractéristiques des éléments du tableau ci-dessus, veuillez vous référer au chapitre contrôle de vue.
Ce contrôle de vue déclare quatre vues. Il dispose de quatre droits
spécifiques : VueA, VueB, VueC et VueD.
Avec le profil suivant :
| Compte | VueA | VueB | VueC | VueD |
|---|---|---|---|---|
| MY_FIRSTROLE | X | X | ||
| MY_SECONDROLE | X | X | X |
- les utilisateurs ayant le rôle
MY_FIRSTROLEauront accès aux vuesVueAetVueB; - les utilisateurs ayant le rôle
MY_SECONDROLEauront accès aux vuesVueB,VueCetVueD; - les utilisateurs ayant les deux rôles auront accès à toutes les vues.
Cependant ces utilisateurs ne pourront pas accéder à la vue
VueDpar l'interface standard car l'ordre de cette dernière est supérieure à l'ordre de laVueAet elle est non-affichable.
Synthèse des vues en fonction des rôles :
| Rôles | Vue par défaut consultation | Vue par défaut de modification | Autres vues accessibles |
|---|---|---|---|
| MY_FIRSTROLE | VueA | Standard | VueB |
| MY_SECONDROLE | VueD | VueC | VueB |
| MY_FIRSTROLE et MY_SECONDROLE | VueA | VueC | VueB, VueD |
Pour l'importation de droits sur un contrôle de vue, les noms des vues (Id vues) sont
utilisés pour référencer les droits spécifiques :
| Identifiant du profil | / | Option | Droit | Droit | Droit | Droit | |
|---|---|---|---|---|---|---|---|
| PROFIL | MY_VIEWCONTROL | RESET | VueA=MY_FIRSTROLE | VueB=MY_FIRSTROLE, MY_SECONDROLE | VueC=MY_SECONDROLE | VueD=MY_SECONDROLE |
9.7 Paramétrage des droits pour un cycle de vie
Le cycle de vie ne peut qu'avoir un profil dédié. Les droits d'un workflow sont ceux d'un document auquel sont ajoutés un droit par type de transition définie dans le cycle de vie.
9.7.1 Transitions
Le profil du cycle de vie permet de donner les droits sur le passage de la
transition. Le nom du droit pour la transition est l'identifiant de la
transition utilisé dans la propriété $transitions de la
classe de cycle de vie.
Extrait d'une classe de cycle de vie :
const TFirst = "my_firstTransition"; const TSecond = "my_secondTransition"; public $transitions = array( self::TFirst => array(), self::TSecond => array() ); public $cycle = array( array( "e1" => "EA", "e2" => "EB", "t" => self::TFirst ) , array( "e1" => "EB", "e2" => "EC", "t" => self::TSecond ) , array( "e1" => "EA", "e2" => "EC", "t" => self::TSecond ) );
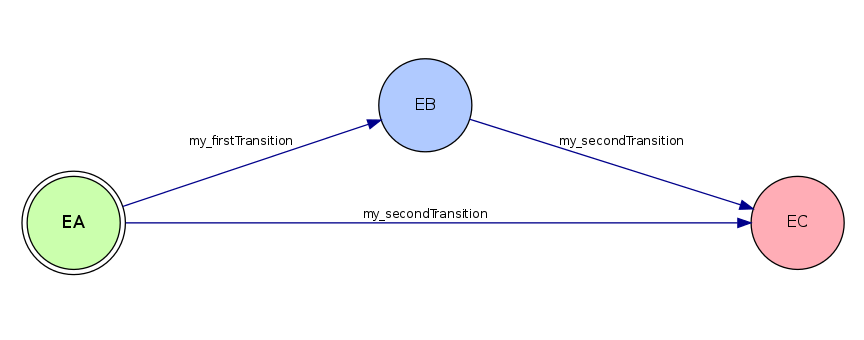
Figure 77. Graphe du cycle à 3 états
my_firstTransition et my_secondTransition sont
ajoutés au profil de ce cycle.
Les cycles de vie ont la possibilité d'avoir un profil dynamique
en indiquant la famille dans l'attribut "dynamique\famille" (dpdoc_famid).
Dans ce cas, ce sont les valeurs des attributs du document associé qui seront
utilisées pour vérifier les droits d'accès aux transitions.
Avec le profil suivant :
| Compte | my_firstTransition | my_secondTransition |
|---|---|---|
| MY_FIRSTROLE | X | |
| MY_SECONDROLE | X |
les droits suivants sont obtenus sur les transitions :
| Rôles | Transition | Transition | Transition |
|---|---|---|---|
| MY_FIRSTROLE | EA → EB | ||
| MY_SECONDROLE | EB → EC | EA → EC | |
| MY_FIRSTROLE et MY_SECONDROLE | EA → EB | EB → EC | EA → EC |
Pour l'importation de droits sur un cycle de vie, les identifiants des transitions sont utilisés pour référencer les droits spécifiques.
| Identifiant du profil | / | Option | Droit | Droit | |
|---|---|---|---|---|---|
| PROFIL | MY_WORKFLOW | RESET | my_firstTransition=MY_FIRSTROLE | my_secondTransition=MY_SECONDROLE |
9.7.2 Profil d'étape
Pour chacune des étapes du cycle de vie, un profil peut être défini. Ce profil sera associé au document attaché au cycle de vie lorsqu'il passera dans l'étape. Ce profil lié doit être compatible avec le document associé.
Si aucun profil n'est attaché à une étape, le document conserve son profil actuel lorsqu'il passe dans cette étape.
Chapitre 10 Cycles de vie
Le cycle de vie (workflow) permet de gérer la vie d'un document en lui imposant un ensemble d'étapes pour aller de sa création jusqu'à sa fin (moment à partir duquel le document n'évolue plus).
Dans la suite de ce chapitre, l'exemple suivant de cycle de vie sera utilisé :
Le cycle présenté est un cycle standard de rédaction :
- Le document est rédigé par un rédacteur.
- Il est ensuite soumis à un contrôle.
- Suite à ce contrôle, le vérificateur peut :
- accepter le document,
- le renvoyer en rédaction
- Une fois le document vérifié, il peut être :
- diffusé
- renvoyé en rédaction
- Enfin, une fois diffusé, le document finira par être archivé.
- De plus, tant qu'il n'a pas été diffusé (et donc été publiquement accessible), le document peut être abandonné.
10.1 Vocabulaire
Les éléments de vocabulaires utilisés dans la définition d'un cycle de vie sont les suivants :
- L'
étape -
c'est un moment clef de la vie document.
Elle peut être caractérisée par une activité ou un état.
- L'
activité - Elle désigne ce qui doit être fait sur un document pour une étape donnée.
- L'
état -
Il désigne le statut du document.
On parle d'état lorsque le document est inerte, soit parce que l'on consulte des anciennes révisions du document soit parce qu'on est sur un état final. Il est à noter qu'ici, final ne désigne pas forcément un état en bout de cycle, mais plutôt un état pour lequel il n'y a rien à faire. Dans notre exemple, diffusé est un état final, sans activité, car le document reste inerte, même s'il finira à terme par être archivé.
On peut résumer ces concepts comme suit :
Pour une étape donnée,
l'état désigne comment le document est arrivé à cette étape
l'activité désigne ce qui doit être fait.
10.2 Définition du cycle de vie
Un cycle de vie est structuré au moyen d'une famille de workflow et d'un document de workflow.
La famille de workflow permet de spécifier :
- le graphe du cycle :
- la liste des étapes,
- la liste des méthodes déclenchées par chaque transition,
- les attributs spécifiques au cycle. Ces attributs peuvent être utilisés dans les traitements des transitions et sont différents pour chaque instance de cycle de vie.
- les paramètres de familles qui seront utilisables lors des traitements spécifiques liés aux cycles : pour chaque étape et chaque transition, un ensemble de paramètres est généré à partir de la structure.
Le document de workflow permet de spécifier le paramétrage :
- des minuteurs, mails, etc. déclenchés à chaque étape ou transition
- des acteurs et de leurs droits au fil des différentes étapes du cycle
Généralement une famille de workflow ne produit qu'un seul document workflow. Ce document workflow est ensuite utilisé pour gérer la vie de tous les documents d'une famille. Il est toutefois possible de créer plusieurs documents workflow issus d'une même famille avec des paramétrages différents. Ils auront en commun la définition du cycle mais pourront avoir des paramétrages différents. Ainsi, par exemple :
- sur une étape E1,
- un courriel sera envoyé au directeur pour le cycle C1
- un courriel sera envoyé au contrôleur pour le cycle C2.
De plus chacun des documents workflow possède sa propre définition de droits. Ainsi, ce ne sont pas les mêmes acteurs qui jouent les différents rôles de contrôleur, ou de rédacteur.
10.2.1 Les transitions
Un type de transition est composé :
- de deux conditions de passage de transition :
m0etm1, - d'une confirmation du passage de la transition :
nr, - d'une demande de paramètres de transition :
ask, - de deux traitements :
m2etm3.
Lors de l'utilisation de l'IHM, une transition se déroule en plusieurs transactions :
-
L'utilisateur demande la liste des transitions disponibles. Pour chaque transition :
- Dynacase vérifie que l'utilisateur est autorisé à effectuer cette transition
- Dynacase vérifie que les conditions préalables à la transition sont
remplies (
m0) :- si les conditions sont remplies, la transition est disponible
- sinon, le message d'erreur est disponible au clic et au survol de la transition, et cette dernière est grisée

Figure 78. Processus d'affichage du menu des transitions
-
L'utilisateur clique sur une des transitions :
-
Si une confirmation de passage de transition ou des paramètres de transition sont requis, une IHM est présentée pour les demander (dans le cas contraire, on passe directement au point suivant) :

Figure 79. Processus de demande des paramètres
-
la transition à proprement parler est lancée :
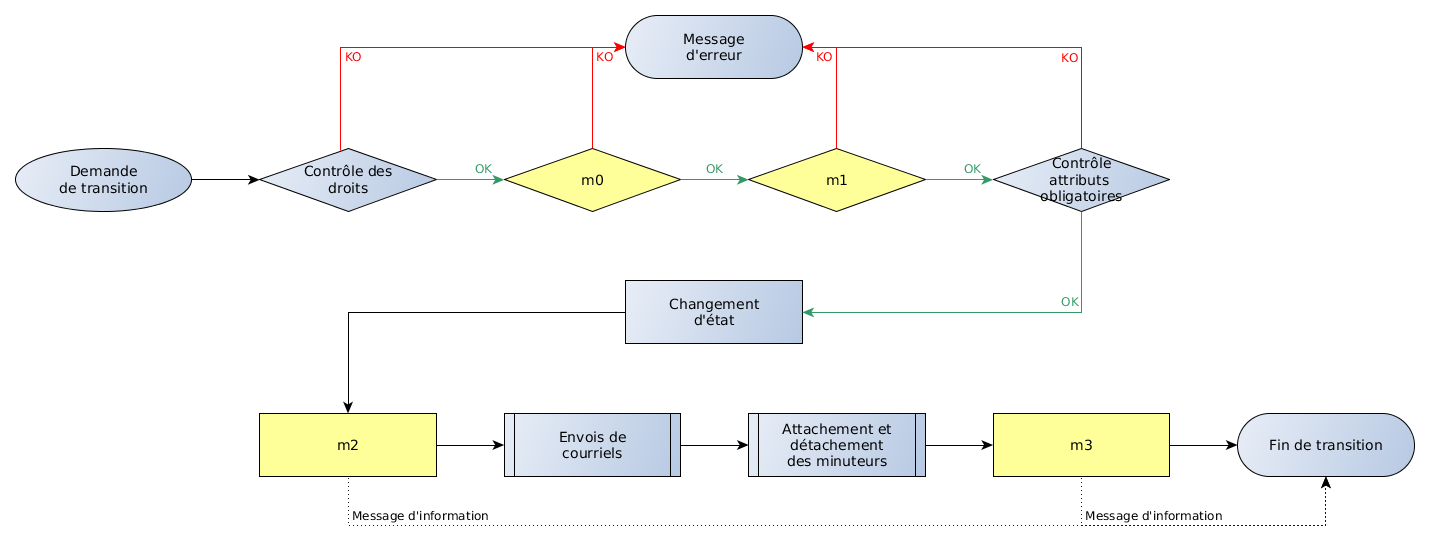
Figure 80. Processus de transition
-
10.2.1.1 Précondition m0
m0 fait référence à une méthode de la classe de workflow. Cette méthode sert
à déterminer si le document est tel qu'il permet d'envisager la transition.
C'est la toute première méthode appelée lors d'une demande de transition.
En cas d'erreur, la transition est abandonnée, et le message d'erreur est retourné à l'utilisateur.
10.2.1.2 Paramètres de transition ask
Les paramètres de transition référencent des
paramètres ou des attributs du cycle de vie, qui sont
demandés à l'utilisateur lors de la transition. Ils doivent être définis sur la
famille de cycle de vie, et référencés dans la transition au moyen de la clé
ask. Cette clé contient un tableau des identifiants de tous les paramètres à
utiliser.
Comme dans un document, l'interface correspondant à ces paramètres sera générée par Dynacase ; les paramètres sont demandés par l'intermédiaire d'une fenêtre modale.
10.2.1.3 Confirmation nr
si nr n'est pas positionné à true, alors une confirmation est demandée.
Cette confirmation demande la raison de la transition. Cette raison est
facultative.
Cette raison est affichée dans la même fenêtre que les paramètres de transition. Elle est enregistrée dans l'historique du document.
10.2.1.4 Condition m1
m1 fait référence à une méthode de la classe de workflow. Cette méthode
sert à modifier le document juste avant le changement d'état.
C'est le document tel qu'il est à l'issue de la méthode m1 qui sera sauvegardé
dans l'historique du document.
Puisque m1 est appelée après la demande des paramètres de transition, elle
peut servir à valider les valeurs saisies par l'utilisateur.
10.2.1.5 Post-traitement m2
m2 fait référence à une méthode de la classe de workflow. Cette méthode
sert à modifier le document juste après le changement d'état. C'est le document
tel qu'il est à la suite de m2 qui sera soumis aux minuteurs et envoyé par
mail.
Puisque m2 intervient après le changement d'état, cette méthode n'est pas
bloquante. Aussi, retourner un message n'interrompt pas le processus
(mais le message d'information sera bien affiché à l'utilisateur à l'issue de la
transition).
10.2.1.6 Traitement final m3
m3 fait référence à une méthode de la classe de workflow. Cette méthode
est la dernière exécutée au cours de la transition (c'est à dire qu'elle
intervient après les différents traitements automatiques effectués par
Dynacase).
Elle n'est utile que dans de très rares cas, et est en particulier utilisée lorsqu'une seconde transition doit être déclenchée automatiquement à l'issue de la première.
10.2.2 Le graphe
Le graphe est constitué d'un ensemble de triplets
- État de départ
- État d'arrivée
- Une transition
Une fois assemblés, ces triplets définissent un Cycle de vie.
10.3 Paramétrage des cycles de vie
Les cycles de vie se paramètrent en 4 étapes :
- Importation de la famille de Workflow
- Création et paramétrage via l'IHM du document de Workflow
- Exportation du document de Workflow
- Association du workflow et de la famille de documents (cf.
WIDdans les propriétés de famille)
En effet, lors de l'importation de la famille de workflow, de nombreux attributs pour chaque état et chaque transition sont crées. Ces attributs vont permettre de définir le paramétrage avancé pour chacun de ces éléments (couleur de l'état, envoi de courriel automatique, droits, etc.).
Une fois ces attributs créés, il suffit de les remplir via l'IHM puis d'exporter le paramétrage ainsi obtenu. Dans l'absolu, il serait possible de générer à la main le fichier de paramétrage correspondant, mais étant donné le grand nombre d'attributs générés, cela serait très fastidieux, et donnerait lieu à de nombreuses erreurs.
10.3.1 La famille de Workflow
La famille de workflow permet de spécifier :
- le graphe du cycle ainsi que les attributs spécifiques au cycle,
- les paramètres de familles qui seront utilisables lors des traitements spécifiques liés aux cycles.
10.3.1.1 Définition de la famille
Au même titre que les autres familles, une famille de workflow est caractérisée par :
son code dans un fichier php
sa définition dans un fichier csv.
Cette famille doit :
- Hériter de la famille
WDOC, - être liée à une classe définissant les états et transitions du cycle.
La propriété USEFOR est SW par défaut, cela indique que
la famille est :
- Système (
S), - utilisable comme workflow (
W).
10.3.1.1.1 Exemple
| Famille parente | Libellé | / | / | Nom logique | |
|---|---|---|---|---|---|
| BEGIN | WDOC | Cycle Demo | WFL_DEMO | ||
| CLASS | Demo\WflDemo | ||||
| END |
10.3.1.2 La classe de workflow
La classe correspondante à un workflow doit définir la structure de ce workflow.
Cette structure s'exprime sous la forme d'un graphe, exprimé notamment au moyen
des propriétés de classe $cycle et $transitions.
10.3.1.2.1 $cycle
La propriété $cycle définit le graphe à proprement parler. C'est une liste
d'éléments de la forme :
array( "e1" => "<état de départ>", "e2" => "<état d'arrivée>", "t" => "<transition à utiliser>" )
où
-
e1est l'identifiant de l'état de départ, -
e2est l'identifiant de l'état d'arrivée, -
test l'identifiant de la transition à utiliser pour passer de l'état de départ à l'état d'arrivée.
Exemple :
public $cycle = array( array( "e1" => "<état de départ 1>", "e2" => "<état d'arrivée 1>", "t" => "<transition à utiliser 1>" ), …, array( "e1" => "<état de départ N>", "e2" => "<état d'arrivée N>", "t" => "<transition à utiliser N>" ) );
10.3.1.2.2 $transitions
La propriété $transitions définit l'ensemble des types de transitions
utilisables. C'est un tableau associatif dont la clé est le nom de la
transition, et la valeur est un élément de la forme :
array( "nr" => true, "m0" => "myFirstCondition", "m1" => "mySecondCondition", "m2" => "myFirstProcess", "m3" => "myLastProcess", "ask" => array("askId1", …) )
où
-
nrest un booléen indiquant qu'il ne faut pas demander de raison au passage de transition (nr pour No Reason).
La valeur par défaut est àfalse; dans ce cas, une popup demande à l'utilisateur de préciser la raison du passage de transition. -
m0,m1,m2,m3sont chacune le nom d'une méthode de la classe de workflow. -
askest un tableau d'identifiants de paramètres ou d'attributs du workflow, qui seront utilisés pour générer la demande des paramètres de transition.
Exemple :
public $transitions = array( "<transition à utiliser 1>" => array( "nr" => true, "m0" => "myFirstCondition_1", … ), …, "<transition à utiliser N>" => array( "nr" => true, "m0" => "myFirstCondition_N", … ) );
10.3.1.2.3 $firstState
La propriété $firstState définit l'état initial des documents liés à ce cycle
de vie. Elle désigne l'identifiant d'un état.
10.3.1.2.4 $attrPrefix
Lors de la génération d'un cycle de vie, Dynacase génère un grand nombre
d'attributs pour paramétrer finement chaque état et chaque transition. ces
attributs sont préfixés par $attrPrefix pour éviter les éventuelles collisions
en base de données.
10.3.1.2.5 $stateactivity
La propriété $stateactivity définit l'ensemble des activités. C'est un tableau
associatif ; la clé est l'identifiant de l'état et la valeur est le libellé
de l'activité.
10.3.1.2.6 Les méthodes de transition
Les méthodes appelées lors des transitions en m0, m1, m2, m3 sont des
méthodes de la famille de workflow.
- Les méthodes appelées en
m0doivent être en visibilitépublic; - les méthodes appelées en
m1,m2, etm3peuvent être en visibilitéprotectedoupublicmais elles ne peuvent pas êtreprivate.
10.3.1.2.6.1 Définition méthode m0
La méthode appelée en m0 est de la forme :
m0 ( $nextStep, $currentStep, $confirmationMessage)
où :
-
$nextStepest l'identifiant de la prochaine étape, (étape d'arrivée) -
$currentStepest l'identifiant de l'étape actuelle, (étape de départ) -
$confirmationMessageest le message de confirmation (si la méthode est exécuté pour l'affichage des menus, le message est vide)
Si elle retourne une chaîne vide, alors la transition peut être effectuée. dans le cas contraire, elle doit retourner un message localisé qui indiquera à l'utilisateur la raison pour laquelle la transition ne peut pas être effectuée.
Le message retourné par la méthode est présenté dans un "tooltip" lors du
survol de l'entrée de l'étape dans le menu Étapes, ou dans un "popover" lors
du clic sur l'entrée de l'étape.
Note : Cette méthode est aussi appelée lors de l'affichage de la liste des transitions accessibles. Cela permet notamment de signaler à l'utilisateur les transitions qu'il a le droit d'effectuer, mais pour lesquelles il doit faire des modifications sur le document. De fait, cette méthode ne doit pas modifier le document.
10.3.1.2.6.2 Définition méthode m1
La méthode appelée en m1 est de la forme :
m1 ( $nextStep, $currentStep, $confirmationMessage)
où :
-
$nextStepest l'identifiant de la prochaine étape, (étape d'arrivée) -
$currentStepest l'identifiant de l'étape actuelle, (étape de départ) -
$confirmationMessageest le message de confirmation
Si elle retourne une chaîne vide, alors la transition peut être effectuée. dans le cas contraire, elle doit retourner un message localisé qui indiquera à l'utilisateur la raison pour laquelle la transition ne peut pas être effectuée.
10.3.1.2.6.3 Définition méthode m2
La méthode appelée en m2 est de la forme :
m2 ( $currentStep, $previousStep, $confirmationMessage)
où :
-
$currentStepest l'identifiant de l'étape actuelle, (étape d'arrivée) -
$previousStepest l'identifiant de l'ancienne étape, (étape de départ) -
$confirmationMessageest le message de confirmation
Si elle retourne une chaîne non vide, cette chaîne est considérée comme un message d'erreur qui sera affiché à l'utilisateur à l'issue de la transition (Cette méthode n'est pas bloquante).
10.3.1.2.6.4 Définition méthode m3
La méthode appelée en m3 est de la forme :
m3 ( $currentStep, $previousStep, $confirmationMessage)
où :
-
$currentStepest l'identifiant de l'étape actuelle, (étape d'arrivée) -
$previousStepest l'identifiant de l'ancienne étape, (étape de départ) -
$confirmationMessageest le message de confirmation
Si elle retourne une chaîne non vide, cette chaîne est considérée comme un message d'erreur qui sera affiché à l'utilisateur à l'issue de la transition (Cette méthode n'est pas bloquante).
10.3.1.2.6.5 Utilisation des paramètres de transition ask
Les paramètres de transition sont envoyés lors de la requête de transition effectuée par l'interface web.
Les valeurs présentées sur l'interface sont les valeurs des paramètres ou des attributs référencés au moment de la demande de transition.
Les valeurs des paramètres de transition utilisées sont enregistrés dans l'historique du document.
Si le paramètre référencé est obligatoire, l'interface exigera que le paramètre soit complété. Cette contrainte n'est pas testée lorsqu'il s'agit de passer une transition par programmation. Elle est prise en compte que par l'interface web. De même, les valeurs des paramètres de transition ne sont remplies que lors d'une transition effectuée par l'interface.
Attention : Contrairement aux paramètres de famille ordinaires, les contraintes ne sont pas prises en compte dans les paramètres de transition.
Dans les méthodes m0, m1, m2, m3, la récupération des valeurs des
paramètres de transition s'effectuent au moyen de la méthode
WDoc::getValue() (bien que ces valeurs soient utilisées dans des paramètres,
ce n'est pas la méthode getParameterValue qui est utilisée).
Lors de la recherche des transitions
accessibles, La méthode m0 ne peut accèder aux paramètres de transition (ils
ne sont pas encore demandés).
10.3.1.2.7 Exemple
Considérons le workflow de l'introduction. La classe le définissant contiendra :
namespace Demo; class WflDemo extends \Dcp\Family\WDoc { public $attrPrefix = "DEMO"; public $firstState = self::etat_created; public $viewlist = "none"; //region States const etat_created = "myapp_demo_e1"; const etat_redacted = "myapp_demo_e2"; const etat_verified = "myapp_demo_e3"; const etat_diffused = "myapp_demo_e4"; const etat_archived = "myapp_demo_e5"; const etat_abandonned = "myapp_demo_e6"; //endregion //region Transitions const transition_created_redacted = "myapp_demo_t1"; const transition_redacted_created = "myapp_demo_t2"; const transition_redacted_verified = "myapp_demo_t3"; const transition_verified_created = "myapp_demo_t4"; const transition_verified_diffused = "myapp_demo_t5"; const transition_diffused_archived = "myapp_demo_t6"; const transition_created_abandonned = "myapp_demo_t7"; const transition_redacted_abandonned = "myapp_demo_t8"; const transition_verified_abandonned = "myapp_demo_t9"; //endregion public $stateactivity = array( self::etat_created => "demo:activity:etat_created", self::etat_redacted => "demo:activity:etat_redacted", self::etat_verified => "demo:activity:etat_verified", self::etat_diffused => "demo:activity:etat_diffused", self::etat_archived => "demo:activity:etat_archived", self::etat_abandonned => "demo:activity:etat_abandonned" ); public $transitions = array( self::transition_created_redacted =>array( "m0" => "", "m1" => "", "m2" => "", "m3" => "", "ask" => array(\Dcp\Family\AttributeIdentifiers\MyDemo::wdemo_deadline_date), "nr" => true ), self::transition_redacted_created =>array( "m0" => "", "m1" => "", "m2" => "", "m3" => "", "nr" => true ), self::transition_redacted_verified =>array( "m0" => "", "m1" => "", "m2" => "", "m3" => "", "nr" => true ), self::transition_verified_created =>array( "m0" => "", "m1" => "", "m2" => "", "m3" => "", "nr" => true ), self::transition_verified_diffused =>array( "m0" => "", "m1" => "", "m2" => "", "m3" => "", "nr" => true ), self::transition_diffused_archived =>array( "m0" => "", "m1" => "", "m2" => "", "m3" => "", "nr" => true ), self::transition_created_abandonned =>array( "m0" => "", "m1" => "", "m2" => "", "m3" => "", "nr" => true ), self::transition_redacted_abandonned =>array( "m0" => "", "m1" => "", "m2" => "", "m3" => "", "nr" => true ), self::transition_verified_abandonned =>array( "m0" => "", "m1" => "", "m2" => "", "m3" => "", "nr" => true ) ); public $cycle = array( array( "e1" => self::etat_created, "e2" => self::etat_redacted, "t" => self::transition_created_redacted ), array( "e1" => self::etat_redacted, "e2" => self::etat_created, "t" => self::transition_redacted_created ), array( "e1" => self::etat_redacted, "e2" => self::etat_verified, "t" => self::transition_redacted_verified ), array( "e1" => self::etat_verified, "e2" => self::etat_created, "t" => self::transition_verified_created ), array( "e1" => self::etat_verified, "e2" => self::etat_diffused, "t" => self::transition_verified_diffused ), array( "e1" => self::etat_diffused, "e2" => self::etat_archived, "t" => self::transition_diffused_archived ), array( "e1" => self::etat_created, "e2" => self::etat_abandonned, "t" => self::transition_created_abandonned ), array( "e1" => self::etat_redacted, "e2" => self::etat_abandonned, "t" => self::transition_redacted_abandonned ), array( "e1" => self::etat_verified, "e2" => self::etat_abandonned, "t" => self::transition_verified_abandonned ) ); }
Quelques remarques sur ce code :
-
Toutes les activités et tous les états ont été définis au moyen de constantes.
Cela n'est en aucun cas obligatoire, mais permet d'éviter les erreurs de copier-coller ; en effet, les identifiants des états, ainsi que les noms des transitions sont utilisés à de nombreux endroits.
-
Les noms des états et des transitions ont été anonymisés, et seules les constantes ont des labels intelligibles.
Puisque les états et transitions vont générer des attributs, ils vont également générer des colonnes en base de données. Ces colonnes sont nommées à partir des identifiants de l'état ou de la transition. Aussi, si demain il est nécessaire de renommer l'état archivé en classé, il faudra soit accepter que le nom affiché et le nom stocké soient différents, soit renommer des colonnes en base de données et mettre à jour des fichiers de paramétrage. Aucun de ces 2 choix n'est pérenne ou dénué de risque.
Avec des constantes anonymisées, il n'y a rien à changer en base de données, ni dans les fichiers de paramétrage, il suffit de changer la traduction de ce libellé. Accessoirement, on peut renommer la constante en bénéficiant de l'assistance d'outils de refactoring.
10.3.1.3 Internationalisation
Dans un workflow, les éléments qui peuvent être internationalisés sont :
- le nom des états
- le nom des activités
- le nom des transitions
Pour être internationalisés, ces éléments doivent être ajoutés aux catalogues de traduction.
10.3.2 Le document de workflow
Une fois la classe de workflow correctement importée, il est possible de créer un document de cette famille.
Le document ainsi créé permet de paramétrer finement le comportement des documents liés à ce workflow.
Il est possible de paramétrer :
- le titre du workflow
- une description
- la famille à laquelle ce workflow peut être attaché
- la famille à utiliser pour le profilage dynamique
- pour chaque étape
- le profil à appliquer aux documents à cette étape
- le masque à appliquer aux documents à cette étape
- la couleur de cette étape
- le contrôle de vue à appliquer aux documents à cette étape
- les mails à envoyer lorsqu'un document arrive dans cette étape
- les minuteurs à attacher à un document lorsqu'il arrive dans cette étape
- pour chaque transition
- les mails à envoyer lorsque cette transition est effectuée
- les minuteurs à attacher à un document lorsqu'il suit cette transition
- les minuteurs persistants à attacher à un document lorsqu'il suit cette transition
- les minuteurs persistants à détacher d'un document lorsqu'il suit cette transition
10.3.2.1 Titre
Le titre permet d'identifier le workflow.
10.3.2.2 Description
La description n'est pas utilisée en dehors du document de workflow.
10.3.2.3 La famille
La famille permet de restreindre les documents auxquels ce workflow peut être attaché : seuls les documents de cette famille et de ses sous-familles peuvent dépendre de ce workflow.
10.3.2.4 Paramétrage par étape
10.3.2.4.1 Profil
Lorsqu'un document arrive dans cette étape, le profil identifié par cette relation lui est attaché.
Attention, cet attachement ne se fait que lors du changement d'état. Aussi, si la valeur de cet attribut est changée, les documents qui sont déjà dans cette étape garderont leur profil.
10.3.2.4.2 Masque
Lorsqu'un document est dans cette étape, sa consultation et sa modification sont soumises au masque identifié par cette relation.
Attention, cette valeur est récupérée à chaque accès au document. Aussi, si la valeur de cet attribut est changée, les documents à cette étape sont directement impactés.
10.3.2.4.3 Couleur
Lorsqu'un document est dans cette étape, cette couleur lui est associée. Elle est utilisée par les interfaces standard de Dynacase.
Cette couleur doit être au format hexadécimal (#RRGGBB).
Attention, cette valeur est récupérée à chaque accès au document. Aussi, si la valeur de cet attribut est changée, les documents à cette étape sont directement impactés.
10.3.2.4.4 Contrôle de vue
Lorsqu'un document arrive dans cette étape, le contrôle de vue identifié par cette relation lui est attaché.
Attention, cet attachement ne se fait que lors du changement d'état. Aussi, si la valeur de cet attribut est changée, les documents qui sont déjà dans cet état garderont leur contrôle de vue.
Attention, si un état définit un masque et un contrôle de vue, seul le contrôle de vue sera pris en compte, et le masque sera ignoré.
10.3.2.4.5 Modèle de courriel
Lorsqu'un document arrive dans cette étape, les Modèle de mail identifiés par cette relation sont envoyés à partir du document.
En plus des clés spécifiques au document, le workflow ajoute :
- les Paramètres de transition
- le commentaire fourni à la confirmation (dans la
clé
WCOMMENT)
10.3.2.4.6 Minuteur
Lorsqu'un document arrive dans cette étape, les minuteurs identifiés par cette relation sont attachés au document.
Si le document possède déjà des minuteurs, les nouveaux seront ajoutés.
Attention, cet attachement ne se fait que lors du changement d'état. Aussi, si la valeur de cet attribut est changée, les documents qui sont déjà dans cet état garderont leurs minuteurs.
Attention Si le document possède déjà une instance du minuteur à attacher, alors l'instance existante est réinitialisée.
Lorsque le minuteur quitte cette étape, les minuteurs étant définis à cette étape sont détachés du document.
Attention Lorsque le document quitte cette étape, les instances de tous les minuteurs correspondant à cette étape sont détachées, qu'ils aient été attachés par cette étape, ou par tout autre moyen.
10.3.2.5 Paramétrage des transitions
10.3.2.5.1 Modèle de courriel
Lorsqu'un document suit cette transition, les Modèle de mail identifiés par cette relation sont envoyés à partir du document.
En plus des clés spécifiques au document, le workflow ajoute :
- les Paramètres de transition
- le commentaire fourni à la confirmation (dans la
clé
WCOMMENT)
10.3.2.5.2 Minuteur
Lorsqu'un document suit cette transition, les minuteurs identifiés par cette relation sont attachés au document.
Si le document possède déjà des minuteurs, les nouveaux seront ajoutés.
Attention, cet attachement ne se fait que lors du changement d'état. Aussi, si la valeur de cet attribut est changée, les documents qui sont déjà dans cet état garderont leurs minuteurs.
Attention Si le document possède déjà une instance du minuteur à attacher, alors l'instance existante est réinitialisée
Les minuteurs sont détachés à la suite du prochain changement d'état.
10.3.2.5.3 Minuteurs persistant à attacher
Lorsqu'un document suit cette transition, les minuteurs identifiés par cette relation sont attachés au document.
Si le document possède déjà des minuteurs, les nouveaux seront ajoutés.
Attention, cet attachement ne se fait que lors du changement d'état. Aussi, si la valeur de cet attribut est changée, les documents qui sont déjà dans cet état garderont leurs minuteurs.
Attention Si le document possède déjà une instance du minuteur à attacher, alors l'instance existante est réinitialisée.
Ces minuteurs ne seront jamais détachés automatiquement, et doivent être détachés au moyen de l'attribut Minuteurs persistant à détacher.
10.3.2.5.4 Minuteurs persistant à détacher
Lorsqu'un document suit cette transition, les minuteurs identifiés par cette relation sont détachés du document.
Attention Lorsque le document effectue cette transition, les instances de tous les minuteurs correspondant à cet attribut sont détachées, qu'ils aient été attachés par cette étape, ou par tout autre moyen.
10.3.3 Profilage du workflow
Pour chaque document de workflow, il est possible de définir qui a le droit de passer chacune des transitions au moyen d'un profil dédié.
Voir le chapitre Paramétrage des droits pour un cycle de vie.
10.4 Manipulation par le code des documents liés à un workflow
Lorsqu'un document est lié à un workflow, sa propriété wid porte l'identifiant
du document de workflow concerné.
Il est possible de :
- demander un changement d'état au moyen de la méthode
Doc::setState; - récupérer l'état du document au moyen de la méthode
Doc::getState;
Chapitre 11 Dynacase en ligne de commande
L'exécution de programmes permettant de gérer les documents et le paramétrage en
général peut être fait en ligne de commande. Le point d'entrée de la ligne de
commande dans Dynacase est le script wsh.php.
11.1 wsh.php
Ce script permet de :
Son aide est disponible au moyen de l'option --help :
./wsh.php --help
usage wsh.php --app=APPLICATION --action=ACTION [--ARG=VAL] ...: execute an action
wsh.php --api=API [--ARG=VAL] .... : execute an api function
wsh.php --listapi : view api list
Note :
- Le script
wsh.phpdoit être exécuté, en ligne de commande, sous le même compte utilisateur que celui du serveur Apache (afin que les fichiers produits soient accessibles par Dynacase en mode Web) et ne doit en aucun cas être lancé sous le compte utilisateurroot.
11.1.1 Utilisateur effectuant l'opération
Par défaut, les opérations sont lancées sous l'identité Dynacase de
l'utilisateur Master Default (administrateur principal - compte admin). Il
est possible de changer cette identité au moyen de l'option --userid, qui
prend comme paramètre le login d'un utilisateur Dynacase, ou son identifiant
système Dynacase.
11.1.2 Passage d'arguments
11.1.2.1 Arguments simples
Il est possible de passer des arguments nommés en rajoutant des options avec la
notation --argumentName=argumentValue. Le nom de l'argument correspond au nom
de l'option. Ainsi, --foo=bar assignera la valeur "bar" à l'argument foo.
Attention : les arguments ne sont pas typés : ils sont systématiquement
envoyés au format texte. Aussi, lors de l'utilisation du paramètre --foo=true,
le script appelé recevra l'argument "true" (string) et non pas le booléen
true.
11.1.2.2 Arguments multivalués
Si la valeur de l'argument comporte des espaces les double-quotes "ou les
quotes ' peuvent être utilisées.
./wsh.php --api=my_test --my_number=3 --my_text="l'argument texte"
Le passage d'arguments multivalués se fait au moyen de la notation
--argumentName=argumentValue répétée autant de fois que nécessaire. Ainsi,
--my_numbers[]=2 --my_numbers[]=4 assignera la valeur array("2","4") à
l'argument my_numbers.
Pour la récupération des arguments, se référer à la documentation de la
classe ApiUsage.
11.1.2.3 Arguments booléens
Enfin, il est possible de passer des arguments booléens avec la notation
--argumentName (sans valaur). Ainsi, --foo assignera la valeur true à
l'argument foo.
11.2 Gestion des erreurs wsh
Lorsqu'un shell non interactif1 sort en erreur, un mail contenant le détail de l'erreur peut être envoyé.
Ce mail est envoyé uniquement si le paramètre CORE_WSH_MAILTO est non vide.
11.3 Exécuter des scripts avec wsh
Exemple d'appel :
./wsh.php --api=cleanContext
Cela appellera le script /API/cleanContext.php.
La liste des scripts disponibles est obtenu au moyen de la commande listapi :
./wsh.php --listapi
application list :
- AppSwitcherSetCoreStartApp
- DocRelInit
- […]
- vault_init
- wdoc_graphviz
Afin de connaître l'usage d'un script, il est possible d'utiliser l'option
--help :
./wsh.php --api=cleanContext --help
Clean base
Usage :
Options:
--userid=<user system id or login name to execute function - default is (admin)>, default is '1'
--real=<real (yes or no)>
--help (Show usage)
11.4 Exécuter des actions avec wsh
Il est possible au moyen de wsh de lancer n'importe quelle action de n'importe quelle application.
Exemple d'appel :
./wsh.php --app=MY_APP --action=MY_ACTION
Les arguments spécifiques de l'action doivent être indiqués au moyen de la syntaxe idoine
Le résultat de l'action est retournée sur la sortie standard.
Exemple d'exécution de l'action FDL_FAMILYSCHEMA de l'application FDL :
./wsh.php --app=FDL --action=FDL_FAMILYSCHEMA --id=DIR > dir.xsd
Toute action ou tout script exécuté avec wsh n'utilise pas les sessions. Les sessions, étant utilisées pour une connexion avec le client web, n'ont pas lieu d'être utilisées.
11.5 Retour d'erreur
Le script retourne un exit status indiquant si une erreur s'est produite. Lorsqu'une erreur se produit, son message est retourné sur la sortie standard (stdout), et non sur la sortie d'erreur (stderr).
Codes retournés :
-
0: Pas d'erreur -
1: Déclenchement d'une exception, appel àAction::exitError(), ou action inconnue -
2: Utilisateur inconnu ou non actif (option--userid) -
4: Le script indiqué par--apiest introuvable.
Exemple :
$ ./wsh.php --api=pastrouve fichier API API/pastrouve.php non trouvé $ echo $? 4
3.2.17 Si le code retourné est 1, le
message d'erreur est affiché avec la fonction error_log(). Par
défaut, l'affichage est effectué sur la sortie stderr. Ce message est
accompagné de la callstack qui est à l'origine de l'erreur.
Exemple :
$ ./wsh.php --api=refreshDocuments --famid=389
17208> Dynacase got an uncaught exception 'Dcp\Core\Exception' with message '{CORE0001} family 389 not exists' in file /var/www/tmp32/WHAT/Class.Action.php at line 651:
17208> #0 /var/www/tmp32/API/refreshDocuments.php(74): Action->exitError('family 389 not ...')
17208> #1 /var/www/tmp32/wsh.php(133): include('/var/www/tmp32/...')
17208> #2 {main}
17208> End Of Exception.
$ echo $?
1
Si le code est 2 ou 4, le message d'erreur est affiché sur la sortie
standard (stdout).
11.6 Écrire un script CLI
Les scripts exécutables avec wsh doivent être des fichiers php présents dans le
sous-répertoire ./API du contexte d'installation. Ces fichiers doivent porter
l'extension php (le basename du fichier détermine le nom de l'api).
Lors du lancement d'un script, la variable $action est initialisée avec un
objet de la classe Action. L'autoloader est initialisé, et
l'intégralité des fonctions et méthodes de Dynacase peuvent être utilisées sans
contrainte spécifique.
-
Il s'agit d'un script lancé via le
CLI PHP SAPI, qui n'a niTTY, niSTDIN, niSTDOUT, niSTDERR. ↩
Chapitre 12 Applications et actions
Ce chapitre contient toutes les informations pour pouvoir créer une application Dynacase.
12.1 Écrire une application
Pour créer une nouvelle application, il faut au minimum un dossier et deux fichiers :
MYAPP |-- MYAPP.app `-- MYAPP_init.php
où MYAPP est le nom de l'application.
Si l'application est visible, l'icône de l'application doit être ajoutée (image carrée entre 48 et 64 px) :
Images/votre_image.png
Toutes les images utilisées par l'application doivent se trouver dans le
répertoire Images/.
L'application peut aussi contenir une ou plusieurs actions.
Tous les fichiers de template (XML/HTML/JS/CSS) doivent se trouver dans un
répertoire Layout/.
Tous les autres fichiers doivent se trouver à la racine du dossier.
Exemple : Arborescence d'une application avec deux actions :
MYAPP |-- Images | `-- MYAPP.png |-- Layout | |-- myaction1.css | |-- myaction1.xml | |-- myaction2.js | `-- myaction2.xml |-- myaction1.php |-- myaction2.php |-- MYAPP.app `-- MYAPP_init.php
Le dossier doit avoir le même nom que l'application et être mis à la racine du contexte.
12.1.1 MYAPP.app
Ce fichier PHP décrit l'application. Il contient au moins une variable de configuration :
-
$app_desc(array) - contient les éléments de présentation de l'application.
Il peut également contenir les variables suivantes :
-
$action_desc(array) - contient la définition des actions de l'application.
-
$app_acl(array) - contient la définition des droits applicatifs (acls).
Exemple de contenu :
<?php $app_desc = array( "name" => "MYAPP", "short_name" => "Mon application", "description" => "Mon application de test", "icon" => "votre_image.png", "displayable" => "Y", "childof" => "ONEFAM" );
12.1.1.1 Contenu possible pour $app_desc
Les différentes clés utilisables dans $app_desc sont :
- name (obligatoire)
-
Nom système de l'application.
C'est le nom qui apparaît dans les menus de configuration de Dynacase.
Ce nom doit également correspondre au nom du dossier contenant l'application, ainsi qu'à celui des fichiers .app et _init.php (la comparaison est sensible à la casse).
- short_name (facultatif)
-
Nom de l'application
Il apparaît dans le menu déroulant de la barre d'application (si l'application est visible). Il n'est pas multiligne.
- description (facultatif)
- Nom qui apparaît en titre du sous-menu de l'application APP_SWITCHER fourni par le module dynacase-appswitcher. Le sous-menu apparaît lors de la sélection de l'application dans le menu déroulant de la barre d'application (si l'application est visible). Il sert à décrire l'application et peut être multiligne.
- icon (facultatif)
-
Nom du fichier image qui sera publié dans
MYAPP/Images/.Ce fichier est l'icône qui répresente l'application MYAPP. Il doit se trouver dans le dossier
Images/des sources. - displayable (facultatif)
-
Un caractère pouvant avoir deux valeurs :
-
Y: l'application apparaît dans le menu déroulant de la barre d'application du module dynacase-appswitcher. -
N: l'application sera invisible. (par défaut)
Remarque : Une application invisible peut quand même avoir ses actions appelées. Par exemple l'application "GENERIC" est invisible mais nombre de ses actions sont utilisées par l'application "ONEFAM". Ce paramètre est pris en compte par l'application APP_SWITCHER pour afficher ou non l'application dans les menus.
Cette valeur ne peut pas être changée lors des mises à jour. Elle ne peut être modifiée que via le centre d'administration. -
- childof (facultatif)
-
Indique si cette application hérite d'une autre.
Il est possible de faire dériver une application de n'importe quelle autre application existante (ex: ONEFAM,GENERIC...).
Limitation : Un seul niveau d'héritage est pris en compte.
- available (facultatif)
-
Indique si l'application est disponible. Deux valeurs possibles :
-
Y: application disponible (valeur par défaut) -
N: application non disponible.
Une application indisponible ne peut exécuter aucune de ses actions. Dans le cas d'une requête HTTP, le status "503 Application unavalaible" est renvoyé.
Cette valeur ne peut pas être changée lors des mises à jour. Elle ne peut être modifiée que via le centre d'administration.
-
- tag (facultatif)
- Permet d'indiquer un tag. Les applications de Dynacase Core sont
marquées "CORE". Ceci peut être utile pour réaliser des interfaces
qui donnent accès à plusieurs applications suivant leur tag. Pour
préciser plusieurs tags sur une même application, il faut les séparer par un
espace. Exemple : Une application avec comme valeur dans tag
"CORE ADMIN"a le tag"CORE"et le tag"ADMIN".
Le tag "ADMIN" est réservé. Il signifie que l'application ne pourra pas être utilisée depuis le point d'entrée par défaut ("index.php") mais qu'à partir du centre d'administration ("admin.php").
Ces clés correspondent aux propriétés de la classe Application
12.1.2 MYAPP_init.php
Ce fichier PHP contient les paramètres déclarées par l'application (globales, applicatives, utilisateurs). Il doit au moins contenir la version de l'application.
Ces paramètres sont accessibles par l'administrateur, via le centre d'administration.
Plus d'informations sur les paramètres applicatifs.
12.1.3 Initialisation ou mise à jour de l'application
Pour initialiser l'application, il faut:
- Publier les sources dans un répertoire portant le même nom que l'application à la racine du contexte sur le serveur.
- Lancer le script
programs/record_applicationqui se trouve sur le serveur. Ce script prend deux arguments:- une chaîne de caractère représentant le nom de l'application.
- la lettre
I(pour l'installation) ouU(pour la mise à jour)
- Lancer le script
programs/update_catalogpour mettre à jour les traductions.
Exemple d'initialisation d'application:
# Dans cet exemple, # Le répertoire courant est la racine du contexte sur le serveur, # l'utilisateur est celui du serveur web `apache`. $> cp -r /chemin_vers_mes_sources/MYAPP . $> ./programs/record_application MYAPP I $> ./programs/update_catalog
Pour la mise à jour, la suite de commandes est la même en remplaçant
./programs/record_application MYAPP I par
./programs/record_application MYAPP U.
Remarque: Une fois l'application initialisée, il est possible de faire la mise à jour en passant par l'interface graphique du [centre d'administration] [admin_center].
12.2 Écrire une action
Une action est le déroulement d'une fonction PHP.
12.2.1 Principe et spécification
12.2.1.1 Introduction
Toutes les actions sont définies au sein d'une application.
La description de l'action se fait dans le fichier MYAPP.app
dans la variable $action_desc.
Une action est définie à l'aide d'un fichier PHP et/ou d'un template XML/HTML. Le fichier PHP ou le template est optionnel, mais il faut au moins un des deux. Chaque action peut définir son droit d'accès (ACL). Si l'utilisateur n'a pas le droit défini, l'exécution de l'action est interdite. Si l'action n'a pas d'ACL, l'action est considérée comme libre ainsi tout utilisateur a le droit de l'exécuter.
Le nom du fichier PHP, du template et de la fonction, doivent être définis dans
MYAPP.app.
Exemple:
Pour la définition de $app_desc se reporter au chapitre applications.
Fichier MYAPP.app:
<?php $app_desc = array(...);// voir le chapitre sur les applications $action_desc = array( array( "name" => "MYACTION1", "short_name" => N_("action one"), "acl" => ... "root" => "Y" ), array( "name" => "MYACTION2", "short_name" => N_("action two"), "acl" => .. "root" => "N", "script" => "myaction1.php", "function" => "mafonctionpouraction2", "layout" => "monlayoutpouraction2.xml" ) ); ?>
12.2.1.2 Contenu possible pour $action_desc
- name (obligatoire)
-
Indique le nom de référence de l'action.
L'appel de l'action se fait en utilisant la valeur de ce paramètre.
attention : Il ne doit pas dépasser 30 caractères.
- short_name (obligatoire)
- Description courte de l'action
- long_name (facultatif)
-
Description longue de l'action.
S'il est omis le long_name est égal au short_name.
- script (facultatif)
-
Nom du fichier PHP qui est inclus lors de l'exécution de l'action.
S'il est omis, le nom du script est le nom (name) de l'action en minuscules, suivi de l'extension
.php. - function (facultatif)
-
Nom de la fonction PHP qui est appelée lors de l'exécution de l'action. Elle doit se trouver dans le fichier défini par script.
S'il est omis, le nom de la fonction est le nom (name) de l'action en minuscules.
- layout (facultatif)
-
Nom du fichier template utilisé lors de l'exécution de l'action.
S'il est omis, le nom du template est le nom (name) de l'action en minuscules suivi de l'extension
.xml. - available (facultatif)
-
Indique si l'action est disponible. Deux valeurs possibles :
-
Y: action disponible (valeur par défaut) -
N: action non disponible.
Une action indisponible ne peut pas être exécutée. Dans le cas d'une requête HTTP, le status "503 Action unavalaible" est renvoyé.
-
- acl (facultatif)
-
Nom du droit nécessaire pour exécuter l'action.
Le nom du droit doit être une des valeurs définies par la variable
$app_acl. Une absence de valeur indique qu'il n'est pas nécessaire d'avoir un droit particulier pour exécuter l'action. Si un utilisateur tente d'exécuter une action dont il n'a pas le droit alors dans le cas d'une requête HTTP, le status "503 Action forbidden" est renvoyé.Note : l'utilisateur "admin" peut exécuter toutes les actions sans restriction de droits.
- root (facultatif)
-
Indique que cette action est l'action principale de l'application. Deux valeurs possibles:
-
Yaction principale. Dans ce cas l'action est lancée avec l'URL?app=MYAPP; -
Naction non principale (valeur par défaut).
Une seule action peut être notée "root". Dans le cas où plusieurs actions sont notées "root", aucune erreur n'est levée, mais, le résultat n'est pas garanti : l'action qui est lancée est la première trouvée par la requête sql.
-
- openaccess (facultatif)
-
(
YouN) Indique que l'action est exécutable avec un jeton d'authentification.Par défaut, une action n'est pas accessible en via une authentifiactin par jeton. Pour autoriser, l'action à être exécutée, il faut mettre
Ydans ce paramètre.
12.2.1.3 Contenu d'un fichier exemple d'action: myaction1.php
Le fichier myaction1.php contient une fonction du même nom que l'action avec
comme paramètre une référence à l'objet [Action][class_action].
Fichier myaction1.php
function myaction1(Action &$action) { // … }
12.2.1.3.1 Récupération de valeurs d'environnement
Pour récupérer :
-
la valeur d'un paramètre applicatif :
$parameterValue = $action->getParam("nom_du_paramètre");
-
le service d'accès à la base de données :
$dbaccess = $action->dbaccess;
-
l'utilisateur courant :
$user = $action->user; // Objet de type `Account`
-
l'application liée à l'action (retourne une instance d'objet de la classe Application :
$application = $action->parent; // Objet de type `Application`
-
les valeurs passées dans l'URL :
Une action peut être lancée par l'activation d'un lien hypertexte ou la soumission d'un formulaire. L'URL appelée peut contenir des paramètres, dont les valeurs sont récupérées par l'intermédiaire de la méthode
Action::getArgument. Toutefois, il faut préférer l'utilisation de la classe ActionUsage pour la récupération des paramètres.$val = $action->getArgument("url_val", "val_par_defaut");
12.2.1.3.2 Vérifier les arguments et donner l'usage
La classe ActionUsage permet de valider que les arguments reçus sont valides (attribut obligatoire/optionnel).
Si l'option strict est mise à true (valeur par défaut), tout argument non
compris dans l'usage provoquera une erreur et l'action sera déroutée dès l'appel
à verify().
Exemple d'utilisation de ActionUsage :
function my_color(Action &$action) { $usage = new ActionUsage($action); $usage->setText(_("Get color map")); $red = $usage->addOptionalParameter("red", "red level", array(), 128); $quality = $usage->addOptionalParameter("quality", "quality", array(), 20); $usage->verify(); if (!is_numeric($red)) $usage->exitError('red must be a integer'); if (!is_numeric($quality)) $usage->exitError('quality must be a integer'); }
12.2.1.3.3 Afficher/Transmettre des données dans le template
Il faut utiliser l'attribut lay de l'objet $action qui est passé en
paramètre. L'attribut lay est un objet de la classe Layout :
$action->lay->set("mydata", "val_to_be_sent");
Plus d'informations sur les templates sont disponibles ici.
12.2.1.3.4 Mise en garde et astuces
- Pour sortir de la fonction et afficher un message d'erreur à l'utilisateur,
il faut utiliser la méthode
exitError():
$action->exitError("Message d'erreur");
12.2.1.4 Contenu d'un fichier exemple de template d'action : myaction1.xml
Le template de l'action peut faire référence à ou plusieurs zones.
Le reste de la page entre les deux balises doit être du code HTML valide ou utiliser le système de template de Dynacase.
Note : Bien que la plupart des templates produisent des pages
HTML, le template peut aussi produire tout type de données textuelles
(HTML, JS, CSS, JSON, XML, CSV, etc.).
Une action peut aussi retourner des fichiers binaires mais dans ce cas ce n'est
pas l'objet lay qui sera utilisé pour le retour.
12.2.2 Exécuter une action
Une action est exécutée sur le serveur en indiquant le nom de l'application et le nom de l'action dans l'url d'accès.
Le nom de l'application est indiqué dans le paramètre app et le nom de
l'action dans le paramètre action.
Exemple :
?app=MY_APP&action=MY_ACTION
Les actions peuvent aussi être exécutées en mode console avec wsh.
12.3 Les paramètres applicatifs
Une application peut requérir différentes variables pour fonctionner.
Ces variables doivent être inscrites en paramètre dans le fichier
MYAPP_init.php.
Elles sont ensuite modifiables par l'administrateur via le centre d'administration.
12.3.1 Déclaration des paramètres
Pour déclarer des paramètres, il faut ajouter un tableau $app_const dans le
code du fichier MYAPP_init.php :
<?php global $app_const; $app_const = array( "VERSION" => "1.0.3-1", // Paramètre minimum obligatoire "Name_of_the_parameter" => array( "val" => "1", "descr" => N_("Description of the parameter"), "global" => "Y", "user" => "N" ) ); ?>
Les index du tableau $app_const définissent les identifiants des paramètres.
Le tableau définissant le nouveau paramètre peut contenir les mots-clés
suivants :
- val (obligatoire)
-
Indique la valeur par défaut du paramètre.
Cette valeur peut par la suite être modifiée par l'administrateur dans le centre d'administration (Menu "Gestion des applications"/"Paramètres applicatifs").
- descr (facultatif)
-
Permet de noter une description qui est affichée au même endroit que la valeur.
Cette valeur fait l'objet d'une traduction dans les interfaces du centre d'administration.
- global (facultatif)
-
Indique si le paramètre est global.
Ce mot-clé peut prendre deux valeurs :
-
Y: indique que le paramètre est global. -
N: indique que le paramètre n'est pas global (valeur par défaut).
Un paramètre global est accessible depuis toutes applications. Dans ce cas, il est affiché en gras dans le menu "Paramètres applicatifs" du centre d'administration. Dans le cas contraire, le paramètre est accessible uniquement par l'application qui le déclare et les applications qui en sont hérités.
-
- user (facultatif)
-
Indique si la valeur du paramètre est personnalisable pour chaque utilisateur ayant accès à l'application. Il peut prendre deux valeurs :
-
Y: indique que le paramètre est personnalisable pour chaque utilisateur. Dans ce cas, le paramètre apparaît aussi dans le menu du Paramètres utilisateurs du centre d'administration. -
N: indique que le paramètre ne peut pas être personnalisable par utilisateur (valeur par défaut).
-
- kind (facultatif)
-
Le type du paramètre. Les valeurs acceptées sont :
text- Indique que le paramètre est une chaîne de caractère. C'est la valeur par défaut.
enum-
Indique que le paramètre est un énuméré.
Dans ce cas il faut préciser les valeurs possibles de l'énuméré dans la déclaration du kind. Exemple:
enum(yes|no) color-
Indique que le paramètre est une couleur.
Dans ce cas, un color picker est proposé lors du changement de valeur du paramètre dans le centre d'administration.
password-
Indique que le paramètre est de type "mot de passe".
Dans ce cas, la valeur n'est pas affichée, elle est remplacée par "*****".
Attention : le mot de passe est stocké en clair en base de données.
static-
Indique que la valeur est non modifiable dans le centre d'administration. Dans ce cas, le paramètre n'est affiché que lors du clic sur le bouton "Afficher les paramètres non modifiables", et il est affiché en gris.
Lors d'une mise à jour de l'application sa valeur est modifiée.
readonly- Comme pour
staticindique que la valeur est non modifiable dans le centre d'administration. A la différence destatic, lors d'une mise à jour de l'application sa valeur n'est pas modifiée.
Le paramètre VERSION est un paramètre obligatoire qui doit contenir la version
de l'application sous la forme suivante : X.Y.Z-R où X.Y.Z définissent la
version et R la release. X,Y et Z sont des nombres entiers.
Exemple de version : "3.5.12-4". Ce paramètre est utilisé pour les
migrations.
Pour les paramètres hérités seule la valeur doit être mise à l'index correspondant dans le tableau, il ne faut pas, dans ce cas, mettre le tableau de définition du paramètre.
12.3.2 Règles :
- Une valeur d'un paramètre global ne peut pas être redéfinie dans une application fille ni dans aucune autre application.
- Le nom d'un paramètre global doit être unique pour l'ensemble des applications installées. Sinon aucune erreur n'est levée et la valeur retournée n'est pas garantie.
- Seule la valeur d'un paramètre applicatif (non global) peut être redéfinie dans une application fille. Les caractéristiques d'un paramètre ne peuvent pas être redéfinies.
- Lors des mises à jour d'application, les valeurs des paramètres ne sont
pas modifiées sauf pour le type
static.
12.3.3 Forcer la mise à jour des paramètres
Les paramètres d'une application peuvent être mis à jour de manière explicite
par la commande manageApplications via le programme wsh.
www-data@test:~$ ./wsh.php --api=manageApplications --help
Manage application
Usage :
--appname=<application name>
Options:
--userid=<user system id or login name to execute function - default is (admin)>, default is '1'
--method=<action to do> [init|update|reinit|delete], default is 'init'
--help (Show usage)
Exemple :
www-data@test:~$ ./wsh.php --api=manageApplications --appname=MYAPP --method=update MYAPP...update 15/05/2013 13:31:56 LOG::[I] Dynacase:DbObj:application : Init : MYAPP 15/05/2013 13:31:56 LOG::[I] Dynacase:DbObj:acl : Acl Modify : MYAPP_VERIFICATION, Access to ticket sales 15/05/2013 13:31:56 LOG::[I] Dynacase:DbObj:action : Update Action MYAPP_ACTION1 15/05/2013 13:31:56 LOG::[I] Dynacase:DbObj:action : Update Action MYAPP_ACTION2
Si la commande est :
init- ajoute les paramètres à l'application à initialiser (ne pas utiliser si application déjà initialisée).
update- modifie les paramètres / ajoute les nouveaux paramètres.
reinit- force mise à jour des valeurs des paramètres telles quelles sont décrites
dans le fichier
MYAPP_init.php. delete- supprime les paramètres de l'application ainsi que l'application elle-même.
12.4 Les droits applicatifs
Une application définit un ensemble de droits applicatifs. ils sont définis dans
le fichier MYAPP.app.
Chaque action peut être soumise à un droit applicatif (ACL). Ces droits permettent de gérer l'accès à ces actions : seuls les utilisateurs possédant cette ACL peuvent exécuter cette action.
Exemple de MYAPP.app avec les droits applicatifs :
Pour la définition de $app_desc se reporter au chapitre
applications
<?php $app_desc = array(...); $app_acl = array( array( "name" => "NORMAL", "description" => N_("Access to common action"), "group_default" => "Y" ), array( "name" => "EDIT", "description" => N_("Access to edit action"), "group_default" => "Y" ), array( "name" => "EXPORT", "description" => N_("For export functions"), "group_default" => "N" ) );
Chaque ACL doit se trouver dans un tableau. Ce tableau peut contenir les clés :
- name (obligatoire)
-
Nom logique de l'ACL.
Il est utilisé pour référencer l'ACL (dans la description des actions par exemple).
- description (facultatif)
- Description de l'ACL. (non multiligne).
- group_default (facultatif)
-
Indique si l'ACL est affectée au groupe Utilisateurs (GDEFAULT). Peut prendre deux valeurs:
-
Y: l'ACL est affectée au groupe Utilisateurs -
N: l'ACL n'est affectée à aucun groupe (valeur par défaut)
-
Plus d'informations sur le fonctionnement des ACLs sont disponibles dans le chapitre sur le fonctionnement de la sécurité dans Dynacase.
12.5 Application héritée
Une application peut hériter d'une application déjà installée.
Un seul niveau d'héritage d'application est pris en compte.
La propriété childof de la description de l'application permet
d'indiquer l'application parente.
La partie description ($app_desc) de l'application ne fait pas partie des
caractéristiques héritées. Cette description complète est obligatoire même en
cas d'héritage.
Lorsqu'une application héritée est installée, toutes les déclarations des actions de l'application parente sont copiées dans l'application héritée au moment de l'installation ou de la mise à jour de l'application héritée.
Lorsque l'application parente est mise à jour, les applications héritant sont mise à jour également : les nouvelles actions sont ajoutées et les éventuelles actions qui ne sont plus décrites sont supprimés des applications. De même les actions modifiées sont aussi modifiés dans les applications héritant de l'application parente.
12.5.1 Surcharge des descriptions d'actions
Le fichier de description de l'application héritée peut modifier les caractéristiques des actions de l'application parente.
Pour modifier une action parente il faut la déclarer dans le tableau
$action_desc en indiquant obligatoirement son nom (name) pour l'identifier.
Les caractéristiques des actions nécessitant d'être modifiée doivent être
indiquées. Les caractéristiques non indiquées seront celles de l'application
parente au moment de l'installation ou de la mise à jour.
Extrait de l'application parente :
$action_desc = array( array( "name" => "ONEFAM_ROOT", "short_name" => N_("one family root"), "acl" => "ONEFAM_READ", "root" => "Y" ) );
Extrait de l'application héritée :
$action_desc = array ( array( "name" =>"ONEFAM_ROOT", "root" => "N" ) );
Dans cet exemple, l'action ONEFAM_ROOT a les caractéristiques suivantes
provenant de l'application héritée :
- name : "ONEFAM_ROOT",
- short_name : N_("one family root"),
- acl : "ONEFAM_READ",
- root : "N"
- script : "onefam_root.php"
- function : "onefam_root"
- layout : "onefam_root.xml"
L'action ONEFAM_ROOT n'est plus l'action principale dans ce cas.
12.5.1.1 Surcharge du contrôleur de l'action
Le contrôleur de l'action peut être changé en modifiant la description.
Extrait de l'application parente MY_FIRSTAPP:
$action_desc = array( array( "name" => "MY_FIRSTACTION", "short_name" => N_("my action"), "acl" => "MY_ACL" ) );
Extrait de l'application héritée MY_SPEAPP:
$action_desc = array ( array( "name" =>"MY_FIRSTACTION", "function" => "spe_firstaction" "script" => "spe_firstaction.php" ) );
Dans cet exemple, l'action MY_FIRSTACTION a les caractéristiques suivantes
dans l'application héritée :
- name : "MY_FIRSTACTION",
- short_name : N_("my action"),
- acl : "MY_ACL",
- root : "N
- script : "spe_firstaction.php"
- function : "spe_firstaction"
- layout : "my_firstaction.xml"
Le fichier spe_firstaction.php proviendra du répertoire MY_SPEAPP, le
fichier my_firstaction.xml proviendra du répertoire MY_FIRSTAPP/Layout.
Note : la fonction surchargée peut appeler la fonction parente si les noms des fonctions sont différents.
spe_firstaction.php
require_once "MYAPP/my_firstaction.php"; function spe_firstaction(Action $action) { my_firstaction($action); // call parent action // ... do specific custom }
12.5.1.2 Surcharge du template de l'action
Le template de l'action peut être changé en modifiant la description.
Extrait de l'application parente MY_FIRSTAPP:
$action_desc = array( array( "name" => "MY_FIRSTACTION", "short_name" => N_("my action"), "acl" => "MY_ACL" ) );
Extrait de l'application héritée MY_SPEAPP:
$action_desc = array ( array( "name" =>"MY_FIRSTACTION", "layout" => "spe_firstaction.xml" ) );
Dans cet exemple, l'action MY_FIRSTACTION a les caractéristiques suivantes
dans l'application héritée :
- name : "MY_FIRSTACTION",
- short_name : N_("my action"),
- acl : "MY_ACL",
- root : "N
- script : "my_firstaction.php"
- function : "my_firstaction"
- layout : "spe_firstaction.xml"
Le fichier my_firstaction.php provient du répertoire MY_FIRSTAPP, le
fichier spe_firstaction.xml provient du répertoire MY_SPEAPP/Layout.
12.5.2 Surcharge par publication
Les contrôleurs et les template peuvent aussi être surchargés si l'application dérivée contient un fichier PHP contrôleur de même nom que l'application parente ou si elle contient un template de même nom.
Le contrôleur est d'abord recherché dans le répertoire de l'application dérivée
et ensuite dans le répertoire de l'application parente. De même, le template est
d'abord recherché dans le répertoire Layout de l'application dérivée et
ensuite dans le répertoire Layout de l'application parente.
12.5.3 Ajouter de nouvelles actions
La description des nouvelles actions est insérée dans le tableau
$action_desc comme pour la modification des actions hérités.
Ces actions peuvent utiliser les droits déclarés sur l'application parente.
12.5.4 Héritage des droits
Les déclarations des droits inscrits dans le tableau $app_acl sont
copiés dans l'application héritée.
Au niveau de la pose des droits aux utilisateurs, groupes et rôles aucun héritage n'est effectué. Les droits d'une application parente et d'une application héritée sont totalement dissociés. Seuls les noms et description des droits sont réutilisés.
De nouveaux droits peuvent être indiqués dans le tableau $app_acl. Lors de
l'installation ou de la mise à jour, ces nouveaux droits sont ajoutés aux
droits hérités. Il n'est pas possible d'enlever des descriptions de droits
fournies par l'application parente.
12.5.5 Modification des paramètres applicatifs
Pour les paramètres de l'application parente seuls les paramètres non globaux pourront être redéfinis par les applications filles. Les valeurs des paramètres globaux sont communs à l'ensemble des applications dérivées.
Paramètres de l'application parente :
$app_const = array( "VERSION" => "3.2.7-0", "ONEFAM_IDS" => array( "val" => "", "global" => "N", "user" => "Y", "kind" => "static", "descr" => N_("visible user families") ) , "ONEFAM_MIDS" => array( "val" => "", "global" => "N", "user" => "N", "descr" => N_("visible master families") ) , "ONEFAM_GLOBALMAX" => array( "val" => "", "global" => "Y", "user" => "N", "descr" => N_("Seuil maximum") ) );
Modification des paramètres sur l'application héritée
$app_const = array( "VERSION" => "1.0.1-0", "ONEFAM_IDS" => "MY_FAMILYONE,MY_FAMILYTWO", "ONEFAM_MIDS" => "MY_FAMILYTHREE" );
Dans cet exemple les paramètres "ONEFAM_IDS" et "ONEFAM_MIDS" peuvent être initialisés avec leur propre valeur. Le paramètre "ONEFAM_GLOBALMAX" lui ne peut faire l'objet d'une modification.
L'application héritée peut ajouter ces propres paramètres dans le tableau
$app_const.
12.5.6 Créer une application pouvant être dérivée
Si une application n'a pas été prévue pour être dérivée alors il n'est pas possible à l'application hérité de modifier le comportement des actions et des interfaces. Seuls des ajouts d'actions seront possibles.
Pour réaliser une application dérivable, il faut utiliser le paramètre
applicatif APPNAME pour construire l'ensemble des identifiants de zones et
d'actions. Ce paramètre applicatif contient le nom de l'application courante.
Exemple :
<h1>Application [APPNAME]</h1> <a href="?app=[APPNAME]&action=MY_ACTION">Entrez dans l'action</a> [ZONE [APPNAME]:MY_ZONE]
Le template ci-dessus, est différent en fonction des différentes applications
dérivées. Si une application dérivée modifie le comportement de l'action
MY_ACTION alors dans ce cas l'url de l'ancre pointera sur l'action modifiée
et non sur l'originale. De même avec l'action MY_ZONE qui est l'action
modifiée en cas de dérivation.
Chapitre 13 Les essentiels de l'API
Ce chapitre détaille les méthodes et les fonctions essentielles pour réaliser le développement d'un module Dynacase. Les API décrites dans ce chapitre abordent les notions principales de Dynacase qui sont :
- la manipulation de documents,
- la recherche de documents,
- les actions et les applications.
La signature (arguments et retour) et le comportement de ces API sont stables tout au long de la version. Si des modifications de signature ou de comportements sont toutefois nécessaires dans une release, ces modifications sont notées dans la release note associée à l'annonce ainsi que dans l'historique et dans la documentation de l'API concernée en précisant les différences entre les releases.
13.1 Classe Action
La classe Action gère les actions des applications Dynacase. Cette classe
gère la sécurité, l'exécution et le rendu de l'action. Une action est toujours
liée à une application. L'accès web à une action se fait via une url du type :
?app=APPLICATION_NAME&action=ACTION_NAME.
13.1.1 Caractéristiques de la classe Action
Ces propriétés sont issues du fichier ".app" de description de l'application. Leurs valeurs sont définies lors de l'enregistrement de l'application.
Ces caractéristiques ne doivent pas être modifiées par programmation sauf pour des besoins précis d'administration des applications. La mise à jour de l'application et par conséquent l'enregistrement du fichier ".app" écrase les modifications qui auront pu être faites si les caractéristiques de l'action ont été modifiées.
- (int) id
- Identifiant numérique de l'action. Il est différent suivant les contextes car il est calculé en prenant le prochain numéro disponible lors de l'enregistrement de l'action. Cette propriété ne doit pas être modifiée car elle est calculée par le système lors de l'enregistrement.
- (int) id_application
- Identifiant numérique de l'application portant l'action. Pour les mêmes raisons que celles de l'id celui-ci est différent suivant les contextes. Cette propriété ne doit pas être modifiée car elle est calculée par le système de part son appartenance à son application.
- (string) name
- Référence de l'action. Contient le nom donné dans le fichier ".app" de description de l'application.
- (string) short_name
- Description courte de l'action. Issu du fichier ".app" de description de l'application.
- (string) long_name
- Description longue de l'action. Issu du fichier ".app" de description de l'application.
- (string) script
- Nom du fichier PHP qui sera inclus lors de l'exécution de l'action. Il est issu du fichier ".app" de description de l'application si celui-ci est renseigné. Il est calculé s'il n'est pas renseigné. Dans ce dernier cas, le nom du script est le nom (name) de l'action en minuscule suivi de l'extension ".php". Le fichier PHP utilisé est doit être dans le répertoire de l'application (le nom du répertoire est le nom de l'application).
- (string) function
- Nom de la fonction PHP qui sera appelée lors de l'exécution de l'action. Il est issu du fichier ".app" de description de l'application si celui-ci est renseigné. Il est calculé s'il n'est pas renseigné. Dans ce dernier cas, le nom de la fonction est le nom (name) de l'action en minuscule.
- (string) layout
- Nom du fichier template utilisé lors de l'exécution de l'action.
Il est issu du fichier ".app" de description de l'application si celui-ci
est renseigné. Il est calculé s'il n'est pas renseigné. Dans ce dernier cas,
le nom du template est le nom (name) de l'action en minuscule suivi de
l'extension ".xml". Le fichier template référencé doit être dans le
sous-répertoire "
Layout" du répertoire d'installation de l'application. - (string) available
-
Indique la disponibilité de l'action. Valeurs possibles :
-
Y: action disponible, -
N: action non disponible.
Yindique que cette action peut être exécutée. Si cette propriété vautN, l'action ne pourra être exécutée et un message d'erreur sera renvoyé à la place du résultat de l'action. -
- (string) acl
- Nom du droit nécessaire pour exécuter l'action.
- (string) grant_level
- Obsolète - non utilisé
- (string) openaccess
-
Indique que l'action peut être exécutée avec un jeton d'authentification sans demande de mot de passe.
Valeurs possibles :
-
Y: action autorisée en mode open, -
N: action non autorisée en mode open, -
vide : idem
N.
L'accès avec jeton n'est autorisé que si la valeur est
Y. -
- (string) root
-
Indique que cette action est l'action principale de l'application.
Valeurs possibles :
-
Y: action principale, -
N: action non principale.
C'est celle qui sera lancée avec l'url "?app=APPNAME" sans préciser d'action. Elle contient soit
YsoitN. L'action est déclarée principale si la valeur estY. Une seule des actions de l'application doit être principale. -
- (string) icon
- Icône de l'action. Non utilisé
- (string) toc
- Obsolète. Indique que l'action peut faire l'objet d'une présentation en onglets
- (string) toc_order
- Obsolète. Rang de l'action pour une présentation en onglets
- (string) father
- Obsolète. Non utilisé
13.1.2 Principales propriétés de la classe Action
Ces propriétés sont renseignées une fois que l'objet Action est initialisé
avec un identifiant valide. Elles sont accessibles depuis l'objet Action passé
en paramètre de la fonction PHP de l'action.
- (Account) user
- Objet
Accountidentifiant l'utilisateur courant - (Application) parent
- Objet
Applicationidentifiant l'application de l'action. - (Layout) lay
- Objet
Layoutidentifiant le template de représentation de l'action - (Session) session
- Objet
Sessionidentifiant la session de paramètres de l'utilisateur courant. - (Log) log
- Objet
Logidentifiant de l'objetLogpermettant d'écrire des messages dans le système.
13.1.3 Action::canExecute
13.1.3.1 Description
string canExecute ( string $actname [, int $appid = ""] )
Permet de vérifier si l'utilisateur connecté a le droit d'exécuter une action donnée.
13.1.3.2 Avertissements
N/A
13.1.3.3 Liste des paramètres
- (string)
actname - Le nom de l'action dont on souhaite vérifier le droit d'exécution pour l'utilisateur connecté.
- (int)
appid - Identifiant de l'application de l'action dont on souhaite vérifier le droit
d'exécution. Par défaut, l'application de l'objet
Actionest utilisée.
13.1.3.4 Valeur de Retour
Retourne une chaîne vide si l'utilisateur a le droit d'exécuter l'action donnée, ou une chaîne non vide lorsque l'utilisateur n'a pas le droit d'exécuter l'action donnée ou s'il y a une erreur dans la vérification du droit.
13.1.3.5 Erreurs / Exceptions
En cas d'erreur dans la vérification des droits (ex. application ou action non existante), une chaîne non vide est retournée avec le message d'erreur rencontré.
13.1.3.6 Historique
N/A
13.1.3.7 Exemples
- Exemple #1 Vérifier si l'utilisateur a le droit d'exécuter l'action
MY_ACTIONde l'application de l'action courante
$err = $action->canExecute('MY_ACTION'); if ($err != '') { /* * User is not allowed to execute MY_ACTION, * or MY_ACTION does not exists */ [...] } /* * User is allowed to execute MY_ACTION */ [...]
- Exemple #2 Vérifier si l'utilisateur a le droit d'exécuter l'action
MY_ACTIONde l'applicationMY_APP
$null = null; $application = new \Application(); $err = $application->set('MY_APP', $null); if ($err != '') { throw new Exception(sprintf("Could not find application with name 'MY_APP': %s", $err)); } $err = $action->canExecute('MY_ACTION', $application->id); if ($err != '') { /* * User is not allowed to execute MY_ACTION from MY_APP, * or MY_ACTION from MY_APP does not exists */ [...] } /* * User is allowed to execute MY_ACTION from MY_APP */ [...]
13.1.3.8 Notes
N/A
13.1.3.9 Voir aussi
N/A
13.1.4 Action::exitError
13.1.4.1 Description
void exitError ( string $texterr )
Permet de mettre fin à l'exécution de l'action et de remonter un message d'erreur à l'utilisateur.
- Si l'action est exécutée en mode Web (variable PHP
$_SERVER['HTTP_HOST']non vide), alors une page HTML d'erreur est générée avec le message d'erreur donné en argument. - Si l'action n'est pas exécutée en mode Web, une exception
Dcp\Core\Exceptionest levée avec le message d'erreur donné en argument.
13.1.4.2 Avertissements
N/A
13.1.4.3 Liste des paramètres
- (string)
texterr - Le message d'erreur.
13.1.4.4 Valeur de Retour
La méthode ne retourne pas de valeur.
13.1.4.5 Erreurs / Exceptions
N/A
13.1.4.6 Historique
N/A
13.1.4.7 Exemples
- Exemple #1
$errmsg = sprintf("Document with id '%d' does not exists.", $docId); $action->exitError($errmsg);
13.1.4.8 Notes
N/A
13.1.4.9 Voir aussi
N/A
13.1.5 Action::getImageUrl()
13.1.5.1 Description
string getImageUrl ( string $name [, bool $detectstyle = true [, int $size = null]] )
L'image demandée doit être une image fournie par l'application associée à l'action ou une autre application.
13.1.5.1.1 Avertissements
N/A
13.1.5.2 Liste des paramètres
- (string)
name - nom du fichier image (basename).
- (bool)
detectstyle -
indique si la détection de style doit être pris en compte.
valeur par défaut :
trueSi la détection de style est activée, l'image sera recherchée dans différents répertoires dans l'ordre suivant :
L'image est recherchée dans le répertoire "
Images" du répertoire du style société (nom provenant du paramètre application "CORE_SOCSTYLE").L'image est recherchée dans le répertoire du style utilisateur (paramètre applicatif "
STYLE"). De même, l'image est recherchée dans le sous- répertoire "Images" du répertoire de style.L'image est recherchée dans le sous-répertoire "
Images" du répertoire d'installation de l'application associée à l'action instanciée.Si l'image n'est pas trouvée, elle est recherchée en dernier recourt dans le répertoire "
Images" général du répertoire d'installation de Dynacase. Ce répertoire contient des liens symboliques vers les images fournies par les applications installées.
Si la détection de style n'est pas activée, les recherches n°1 et n°2 ne sont pas effectuées.
- (int)
size -
indique la largeur de l'image en pixel.
valeur par défaut :
nullindique qu'aucun redimensionnement ne sera effectué.Si la valeur n'est pas renseignée la taille originale est conservée sinon une conversion d'image sera appliquée afin d'avoir la largeur indiquée. Cette conversion d'image est effectuée sur le serveur lors du premier appel de l'url donnée. Ensuite le résultat de cette conversion d'image est mis en cache (répertoire
var/cache/images) pour un accès plus rapide lors des prochains appels. Cette conversion retourne toujours une image au format png.
13.1.5.3 Valeur de retour
L'URL relative d'accès à l'image, par rapport à la racine du contexte, est retournée.
Si l'image n'est pas trouvée, c'est l'image définie dans l'attribut "noimage" de la classe Application qui est retournée. Cette image est 'CORE/Images/noimage.png' :

Figure 81. image non trouvée
13.1.5.4 Erreurs / Exceptions
N/A
13.1.5.5 Historique
N/A
13.1.5.6 Exemples
Le résultat de cette fonction peut être mis dans le layout d'une action qui permet de référence des URL relatives. Pour avoir une url absolue, il faut ajouter le paramètre "CORE_EXTERNURL" pour compléter l'URL.
// myaction.php function myAction(Action &$action) { $imageUrl=$action->getImageUrl('myImage.png'); // image originale $smallImageUrl=$action->getImageUrl('myImage.png',true, 20); // 20 pixels de largeur // constitution d'une URL absolue $absoluteUrl=$action->getParam("CORE_EXTERNURL").$imageUrl; }
13.1.5.7 Notes
Bien que cette méthode soit définie sur la classe Action, elle est un
raccourci pour accéder à la méthode Application::getImageUrl() de
l'application dont est issu l'action.
13.1.5.8 Voir aussi
N/A
13.1.6 Action::addWarningMsg
13.1.6.1 Description
void addWarningMsg ( string $msg )
Le message est affiché sous forme de fenêtre de dialogue si l'interface dispose de la fonction jquery ui dialog (ce qui est le cas d'une vue de document). Sinon le message est affichée avec la fonction window.alert().
Si plusieurs messages sont envoyés, ils sont affichés dans la même fenêtre les uns au dessous des autres.
13.1.6.2 Avertissements
N/A
13.1.6.3 Liste des paramètres
- (string)
msg - Texte brut (pas de html) à afficher
13.1.6.4 Valeur de Retour
Aucun.
13.1.6.5 Erreurs / Exceptions
Aucune.
13.1.6.6 Historique
N/A
13.1.6.7 Exemples
$err = $action->addWarningMsg('Mon premier message');
13.1.6.8 Notes
Les messages ainsi enregistrés sont stockés sur la session de l'utilisateur. Ainsi, même s'ils ne sont pas affichés immédiatement (voir Action::getWarningMsg), ils restent disponibles tant que l'utilisateur ne s'est pas déconnecté.
Les interfaces standard de Dynacase, ainsi que toutes les interfaces utilisant la classe Layout
récupèrent automatiquemenet ces messages (lors de l'appel à Layout::gen()).
Ils sont ensuite injectés dans la page au moyen de la balise [JS:CODE].
Pour que les messages ne soient ni récupérés, ni affichés, il faut utiliser la balise [JS:CODENLOG].
Les messages affichés par le code de la balise [JS:CODE] peuvent être capturés par la fenêtre parente
si celle ci déclare la fonction dcp.displayWarningMessage(messages).
Cette fonction reçoit en paramètre la liste des messages d'avertissement sous la forme d'un array.
window.dcp = window. dcp || {}; window.dcp.displayWarningMessage = function (messages) { for (var i=0;i<messages.length;i++) { // Do something with messages[i] } }
13.1.6.9 Voir aussi
13.1.7 Action::getWarningMsg
13.1.7.1 Description
void getWarningMsg ()
Retourne un tableau de messages.
13.1.7.2 Avertissements
N/A
13.1.7.3 Liste des paramètres
Aucun
13.1.7.4 Valeur de Retour
Un tableau dans lequel chaque entrée est un message.
13.1.7.5 Erreurs / Exceptions
Aucune.
13.1.7.6 Historique
N/A
13.1.7.7 Exemples
foreach( $action->getWarningMsg() as $msg ) { //do something with the message }
13.1.7.8 Notes
Les messages ainsi récupérés ne sont pas effacés de la session. Il faut, pour cela, utiliser la méthode Action::clearWarningMsg.
13.1.7.9 Voir aussi
13.1.8 Action::clearWarningMsg
13.1.8.1 Description
void clearWarningMsg ()
13.1.8.2 Avertissements
N/A
13.1.8.3 Liste des paramètres
Aucun.
13.1.8.4 Valeur de Retour
Aucun.
13.1.8.5 Erreurs / Exceptions
Aucune.
13.1.8.6 Historique
N/A
13.1.8.7 Exemples
$err = $action->clearWarningMsg();
13.1.8.8 Notes
Aucune.
13.1.8.9 Voir aussi
13.1.9 Action::addLogMsg
13.1.9.1 Description
void addLogMsg ( string $msg, $cut = 0 )
Le message est affiché dans la console du navigateur.
Si plusieurs messages sont envoyés, ils sont affichés chacun séparément dans la console. Chaque message est préfixé par l'heure (heure et minute) de l'appel à la fonction.
13.1.9.2 Avertissements
N/A
13.1.9.3 Liste des paramètres
- (string)
msg - Texte brut (pas de html) à afficher
- (string)
cut - Taille limite du texte, si
$cutest strictement positif le texte est tronqué au delà de cette limite
13.1.9.4 Valeur de Retour
Aucun.
13.1.9.5 Erreurs / Exceptions
Aucune.
13.1.9.6 Historique
N/A
13.1.9.7 Exemples
$err = $action->addLogMsg('Mon premier message');
Affichera sur la console web :
09:20 Mon premier message
13.1.9.8 Notes
Aucune.
13.1.9.9 Voir aussi
N/A
13.2 Classe ActionUsage
La classe ActionUsage gère la définition et la validation des paramètres d'une
action.
Elle permet de spécifier et contrôler la présence de paramètres requis ou optionnels, et de retourner un texte d'aide précisant les paramètres requis lorsque la validation échoue.
La classe ActionUsage hérite de la classe ApiUsage.
13.2.1 Constructeur
new ActionUsage ( Action & $action )
13.2.1.1 Liste des paramètres
- (Action)
action - L'objet
$actioncourant.
13.2.1.2 Exemples
function mon_action(Action & $action) { $usage = new ActionUsage($action); $docId = $usage->addRequiredParameter("id", "document identifier"); $usage->verify(); doSomethingWith($docId); }
13.2.1.3 Notes
Cette classe est utilisée pour les actions déclenchés par le serveur web ou via le script wsh.
Lorqu'il est déclenché par le serveur web, les paramètres sont récupérées par les variables suivantes dans l'ordre indiqué :
-
$_GET: Variable HTTP GET -
$_POST: Variable HTTP POST (formulaire) -
$_FILES: 3.2.21 Formulaire avec fichier
Les variables GET sont prioritaires aux variables POST qui sont prioritaires aux variables FILES.
Les variables HTTP suivantes sont déclarées :
-
sole: indicateur du format de la page (obsolète) - gardé pour compatibilité -
authtype: mode d'authentification 3.2.23 -
dcpopen-authorization: jeton d'authentification 3.2.23 -
privateid: si authtype=open (obsolète) - gardé pour compatibilité. 3.2.23
Si le mode strict n'est pas désactivé, ces variables restent
autorisées.
Dans le cas d'un fichier, la valeur retournée par les méthodes add*Parameter()
est un tableau contenant le contenu de la variable HTTP :
-
name: Le nom original du fichier, tel que sur la machine du client web. -
type:Le type MIME du fichier, si le navigateur a fourni cette information. -
size: La taille, en octets, du fichier téléchargé. -
tmp_name: Le nom temporaire du fichier qui sera chargé sur la machine serveur. -
error: Le code d'erreur associé au téléchargement de fichier.
13.2.1.4 Voir aussi
13.2.2 ActionUsage::getUsage()
13.2.2.1 Description
string getUsage ()
Le texte d'aide retourné est un texte multi-ligne avec le retour chariot Unix
(\n) comme séparateur de lignes.
13.2.2.1.1 Avertissements
Aucun.
13.2.2.2 Liste des paramètres
Aucun.
13.2.2.3 Valeur de retour
Le message texte d'aide d'usage sur plusieurs lignes.
13.2.2.4 Erreurs / Exceptions
Aucune.
13.2.2.5 Historique
Aucun.
13.2.2.6 Exemples
function myaction1( Action & $action ) { $usage = new ActionUsage($action); $usage->setDefinitionText("Sample action"); $docid = $usage->addRequiredParameter( "id", "Document id" ); $format = $usage->addOptionalParameter( "format", "Paper format", array( "a3", "a4", "a5" ), "a4" ); $usage->verify(); ... }
Web :
.-------------------------------------------------------------------. | .-------------. | | / Erreur x \ | |-' '-----------------------------------------------| | [ http://localhost/?app=MYAPP&action=MYACTION1 ________________ ] | |-------------------------------------------------------------------| | | | .-------------------------------------------------------------. | | | argument 'id' expected | | | | | | | | | | | | Sample action | | | | | | | | Usage : | | | | | | | | &app=MYAPP : <application name> | | | | | | | | &action=MYACTION1 : <action name> | | | | | | | | &id=<Document id> | | | | | | | | Options: | | | | | | | | &format=<Paper format> [a3|a4|a5], default is 'a4' | | | '-------------------------------------------------------------' | | | | | '-------------------------------------------------------------------'
CLI :
$ ./wsh.php --app=MYAPP --action=MYACTION1
Erreur : {CORE0001} argument 'id' expected
Sample action
Usage :
--app=MYAPP : <application_name>
--action=MYACTION1 : <action_name>
--id=<Document id>
Options:
--format=<Paper format> [a3|a4|a5], default is 'a4'
13.2.2.7 Notes
Aucune.
13.2.2.8 Voir aussi
13.3 Classe ApiUsage
La classe ApiUsage gère la définition et la validation des paramètres lors
l'appel et l'exécution de scripts CLI.
Elle permet de spécifier et contrôler la présence de paramètres requis ou optionnels, et de retourner un texte d'aide précisant les paramètres requis lorsque la validation échoue.
13.3.1 Constructeur
new ApiUsage ( Action & $action )
13.3.1.1 Liste des paramètres
- (Action)
action - L'objet
$actioncourant.
13.3.1.2 Exemples
global $action; $usage = new ApiUsage($action); $docId = $usage->addRequiredParameter("id", "document id"); $usage->verify(); doSomeThingWith($docId);
$ ./wsh.php --api=test
Erreur : {CORE0001} argument 'id' expected
Usage :
--id=<document id>
Options:
--userid=<user system id or login name to execute function - default is (admin)>, default is '1'
--help (Show usage)
13.3.1.3 Notes
Aucune.
13.3.1.4 Voir aussi
Aucun.
13.3.2 ApiUsage::addEmptyParameter()
13.3.2.1 Description
mixed addEmptyParameter ( string $argName, string $argDefinition = "" )
13.3.2.1.1 Avertissements
Aucun.
13.3.2.2 Liste des paramètres
- (string)
argName - Le nom du paramètre.
- (string)
argDefinition - Un texte (simple ligne) de description du paramètre.
13.3.2.3 Valeur de retour
Si le paramètre est présent dans les arguments, alors une chaîne vide est
retournée, sinon false est retourné.
13.3.2.4 Erreurs / Exceptions
Aucune.
13.3.2.5 Historique
- Remplace la méthode
addEmpty()qui est dépréciée depuis la version 3.2.5.
13.3.2.6 Exemples
$usage = new ApiUsage(); $debug = $usage->addEmptyParameter("debug", "Turn on debug messages."); $usage->verify(); $debug = ($debug === false) ? false : true; if ($debug) { printf("Debug mode ON\n"); } else { printf("Debug mode OFF\n"); }
$ ./wsh.php --api=sampleApi Debug mode OFF
Le paramètre n'est pas présent.
$ ./wsh.php --api=sampleApi --debug Debug mode ON
Le paramètre est présent.
13.3.2.7 Notes
Aucune.
13.3.2.8 Voir aussi
13.3.3 ApiUsage::addHiddenParameter()
13.3.3.1 Description
string addHiddenParameter ( string $argNAme, string $argDefinition = "" )
La présence du paramètre est vérifiée et sa valeur retournée.
Un paramètre hidden n'est pas requis, et il est traité comme un paramètre
optionnel (ApiUsage::addOptionalParameter).
13.3.3.1.1 Avertissements
N/A
13.3.3.2 Liste des paramètres
- (string)
argName - Le nom du paramètre.
- (string)
argDefinition - Un texte (simple ligne) de description du paramètre.
13.3.3.3 Valeur de retour
Retourne la valeur du paramètre ou null si le paramètre n'est pas présent.
13.3.3.4 Erreurs / Exceptions
N/A
13.3.3.5 Historique
- Remplace la méthode
addHidden()qui est dépréciée depuis la version 3.2.5.
13.3.3.6 Exemples
$usage = new ApiUsage(); $hidden = $usage->addHiddenParameter("hidden", "Hidden option"); $usage->verify(); printf("hidden = '%s'\n", $hidden);
$ ./wsh.php --api=test --help Usage : Options: --userid=<user system id or login name to execute function - default is (admin)>, default is '1' --help (Show usage)
L'utilisation du paramètre --hidden n'apparaît pas dans le texte d'usage.
$ ./wsh.php --api=test --hidden=foo hidden = 'foo'
13.3.3.7 Notes
N/A
13.3.3.8 Voir aussi
13.3.4 ApiUsage::addRequiredParameter()
13.3.4.1 Description
string addRequiredParameter ( string $argName, string $argDefinition = "", string[]|callable $restriction = null )
La présence du paramètre est vérifiée et sa valeur retournée.
13.3.4.1.1 Avertissements
Aucun.
13.3.4.2 Liste des paramètres
- (string)
argName - Le nom du paramètre.
- (string)
argDefinition - Un texte (simple ligne) de description du paramètre.
- (string[]|callable)
restriction -
Liste des valeurs possibles pour le paramètre ou un [callable][callable_information] vérifiant une contrainte à appliquer à la valeur du paramètre.
Si la restriction est un
array, alors la valeur passée doit obligatoirement être scalaire, et sa valeur doit être parmi les valeurs du tableau.Pour une autre restriction, se reporter à la description du [callable de restriction][callable_information].
13.3.4.2.1 Le callable de restriction
Le paramètre de restriction peut être un callable. Il permet de vérifier une contrainte que l'on souhaite appliquer aux valeurs passées en argument du paramètre.
string function ( string|string[] $values string $argName ApiUsage $apiusage )
Ce callable reçoit trois arguments:
- (string|string[])
values - La ou les valeurs du paramètre
- (string)
argName - Le nom du paramètre
- (ApiUsage)
apiusage - L'objet courant de type ApiUsage contenant les informations des autres paramètres
Il est déclenché lors de l'appel à apiUsage::verify() et
doit retourner :
- Une chaîne vide si la valeur est valide,
- Un message d'erreur si la valeur n'est pas valide,
- une chaîne d'usage si la valeur est la constante
ApiUsage::GET_USAGE.
Les callables suivants sont disponibles pour les cas standard :
-
ApiUsage::isScalar: vérifie que la valeur est scalaire.
C'est la restriction appliquée par défaut. -
ApiUsage::isArray: vérifie que la valeur est multiple.
13.3.4.3 Valeur de retour
Retourne la valeur du paramètre.
Si la valeur n'est pas conforme à la restriction spécifiée au moyen du paramètre
restriction, alors la validation est mise en erreur.
13.3.4.4 Erreurs / Exceptions
Aucune.
13.3.4.5 Historique
- Remplace la méthode
addNeeded()qui est dépréciée depuis la version 3.2.5.
13.3.4.6 Exemples
13.3.4.6.1 Restriction par un array
<?php $usage = new ApiUsage(); $docid = $usage->addRequiredParameter("docid", "Document id"); $format = $usage->addRequiredParameter("format", "Paper format", array("a4", "a3")); $usage->verify(); printf("docid = '%s'\n", $docid); printf("format = '%s'\n", $format);
Omission d'un paramètre obligatoire :
$ ./wsh.php --api=test
Erreur : {CORE0001} argument 'docid' expected
Usage :
--docid=<Document id>
--format=<Paper format> [a4|a3]
Options:
--userid=<user system id or login name to execute function - default is (admin)>, default is '1'
--help (Show usage)
Passage d'une valeur ne respectant pas la restriction :
$ ./wsh.php --api=test --docid=1234 --format=foo
Erreur : {CORE0001} argument 'format' must be one of these values : a4, a3
Usage :
--docid=<Document id>
--format=<Paper format> [a4|a3]
Options:
--userid=<user system id or login name to execute function - default is (admin)>, default is '1'
--help (Show usage)
Appel valide :
$ ./wsh.php --api=test --docid=1234 --format=a4 docid = '1234' format = 'a4'
13.3.4.6.2 Restriction par un callable
<?php $usage = new ApiUsage(); $numberpositive = $usage->addRequiredParameter( "number", "A number", function($values, $argname, $apiusage) { if (ApiUsage::GET_USAGE === $values){ return "A positive number"; } if (is_array($values)) { $invalidValues = array_filter($values, function($var){return($var < 0);}); if(count($invalidValues) > 0){ return sprintf("Following values are not positive : [%s]", implode("],[", $invalidValues)); } } elseif ($values < 0){ return sprintf("Following value is not positive : [%s]", $values); } return ""; } ); $usage->verify(); printf("number = '%s'\n", $numberpositive);
Omission d'un paramètre obligatoire :
$ ./wsh.php --api=test
Erreur : {CORE0001} argument 'number' expected
Usage :
--number=<A number>A positive number
Options:
--userid=<user system id or login name to execute function - default is (admin)>, default is '1'
--help (Show usage)
Passage d'une valeur ne respectant pas la restriction :
$ ./wsh.php --api=test --number=-12
Erreur : {CORE0001} Error checking argument number type: Following value is not positive : [-12]
Usage :
--number=<A number>A positive number
Options:
--userid=<user system id or login name to execute function - default is (admin)>, default is '1'
--help (Show usage)
Appel valide :
$ ./wsh.php --api=test --number=12 number = '12'
13.3.4.7 Notes
Aucune.
13.3.4.8 Voir aussi
13.3.5 ApiUsage::addOptionalParameter()
13.3.5.1 Description
string addOptionalParameter ( string $argName, string $argDefinition, string[]|callable $restriction = null, string $default = null )
La présence du paramètre est vérifiée et sa valeur retournée.
13.3.5.1.1 Avertissements
Aucun.
13.3.5.2 Liste des paramètres
- (string)
argName - Le nom du paramètre.
- (string)
argDefinition - Un texte (simple ligne) de description du paramètre.
- (string[]|callable)
restriction -
Liste des valeurs possibles pour le paramètre ou un callable vérifiant une contrainte à appliquer à la valeur du paramètre.
Si la restriction est un
array, alors la valeur passée doit obligatoirement être scalaire, et sa valeur doit être parmi les valeurs du tableau.Pour une autre restriction, se reporter à la description du callable de restriction.
- (string)
default - Valeur retournée par défaut si le paramètre n'est pas présent.
13.3.5.3 Valeur de retour
Si le paramètre est présent, alors la valeur du paramètre est retournée.
Si le paramètre n'est pas présent et qu'une valeur par défaut est fournie, alors
c'est la valeur par défaut qui est retournée, sinon null est retourné.
Si la valeur n'est pas conforme à la restriction spécifiée au moyen du paramètre
restriction, alors la validation est mise en erreur.
13.3.5.4 Erreurs / Exceptions
Aucune.
13.3.5.5 Historique
- Remplace la méthode
addOption()qui est dépréciée depuis la version 3.2.5.
13.3.5.6 Exemples
Définition du paramètre format :
$usage = new ApiUsage(); $format = $usage->addOptionalParameter('format', 'Paper format', array('a3', 'a4'), 'a4'); $usage->verify(); printf("format = '%s'\n", $format);
Chaîne d'usage générée :
$ ./wsh.php --api=test --help
Usage :
Options:
--userid=<user system id or login name to execute function - default is (admin)>, default is '1'
--format=<Paper format> [a3|a4], default is 'a4'
--help (Show usage)
Valeur par défaut :
$ ./wsh.php --api=test format = 'a4'
Passage de la valeur :
$ ./wsh.php --api=test --format=a3 format = 'a3'
13.3.5.7 Notes
Aucune.
13.3.5.8 Voir aussi
13.3.6 ApiUsage::setDefinitionText()
13.3.6.1 Description
void setDefinitionText ( string $text )
13.3.6.1.1 Avertissements
Aucun.
13.3.6.2 Liste des paramètres
- (string)
text - Le texte (simple ligne) de description du script.
13.3.6.3 Valeur de retour
La méthode ne retourne pas de valeur.
13.3.6.4 Erreurs / Exceptions
Aucune.
13.3.6.5 Historique
- Remplace la méthode
setText()qui est dépréciée depuis la version 3.2.5.
13.3.6.6 Exemples
$usage = new ApiUsage(); $usage->setDefinitionText("Script de test de la classe ApiUsage"); $usage->verify();
$ ./wsh.php --api=test --help
Script de test de la classe ApiUsage
Usage :
Options:
--userid=<user system id or login name to execute function - default is (admin)>, default is '1'
--help (Show usage)
13.3.6.7 Notes
Aucune.
13.3.6.8 Voir aussi
13.3.7 ApiUsage::setStrictMode()
13.3.7.1 Description
void setStrictMode ( bool $strict = true )
Lorsque le mode de validation strict est activé, la présence d'arguments non enregistrés auprès de l'instance d'ApiUsage en cours met en échec la validation des paramètres.
Par défaut, le mode de validation strict est actif.
13.3.7.1.1 Avertissements
Aucun.
13.3.7.2 Liste des paramètres
- (bool)
strict - Active ou désactive le mode de validation strict.
13.3.7.3 Valeur de retour
Aucune.
13.3.7.4 Erreurs / Exceptions
Aucune.
13.3.7.5 Historique
- Remplace la méthode
strict()qui est dépréciée depuis la version 3.2.5.
13.3.7.6 Exemples
$usage = new ApiUsage(); $usage->verify();
$ ./wsh.php --api=test --foo=bar
Erreur : {CORE0001} argument 'foo' is not defined
Usage :
Options:
--userid=<user system id or login name to execute function - default is (admin)>, default is '1'
--help (Show usage)
Une erreur est remontée concernant le paramètre foo inconnu.
$usage = new ApiUsage(); $usage->setStrictMode(false); $usage->verify();
$ ./wsh.php --api=test --foo=bar
Aucune erreur n'est remonté concernant le paramètre foo inconnu.
13.3.7.7 Notes
Si l'action a pour vocation d'être appelée par une autre action, il est
préférable de passer le mode strict à false pour ne pas déclencher d'erreur
si l'action appelante n'a pas la même liste de paramètres.
13.3.7.8 Voir aussi
13.3.8 ApiUsage::verify()
13.3.8.1 Description
void verify ( bool $useException = false )
Lance la validation des paramètres précédemment définis et génère une erreur si les paramètres ne sont pas conformes.
13.3.8.1.1 Avertissements
Aucun.
13.3.8.2 Liste des paramètres
- (bool)
useException - Active (
true) ou désactive (false) la remontée d'erreur par exception lors de l'échec de la validation des paramètres.
13.3.8.3 Valeur de retour
Aucune.
13.3.8.4 Erreurs / Exceptions
Par défaut, l'erreur est remontée via un appel à
Action::exitError.
Si le mode de remontée d'erreur par exception est
actif, alors une exception \Dcp\ApiUsage\Exception est levée.
13.3.8.5 Historique
Aucun.
13.3.8.6 Exemples
$usage = new ApiUsage(); try { $usage->verify(true); } catch(\Dcp\ApiUsage\Exception $e) { printf("Bad parameters!\n"); } printf("Done.");
$ ./wsh.php --api=test --foo=bar Bad parameters! Done.
13.3.8.7 Notes
Aucune.
13.3.8.8 Voir aussi
Aucun.
13.4 Classe Application
La classe Application gère les applications Dynacase. Cette classe gère l'accès aux fonction globales liées à l'application comme les paramètres applicatifs. Elle permet d'instancier les objets Action en vu de leur exécution.
13.4.1 Propriétés de la classe Application
Ces propriétés sont pour la plupart initialisées avec le contenu du fichier ".app" de description de l'application.
- id
- Identifiant numérique de l'application. Il est différent suivant les contextes car il est calculé en prenant le prochain numéro disponible lors de l'enregistrement de l'application.
- name
- Référence de l'application. Contient le nom donnée dans le fichier ".app" de description de l'application.
- short_name
- Description courte de l'application. Issu du fichier ".app" de description de l'application.
- description
- Description longue de l'application. Issu du fichier ".app" de description de l'application.
- available
- Indique la disponibilité de l'application.
Elle contient soit
YsoitN.Yindique qu'aucune action de l'application ne peut être exécutée. Si cette propriété vaut 'N', les actions ne pourront être exécutées et un message d'erreur est renvoyé à la place du résultat de l'action. - access_free
- Indique que toutes les actions de l'application ne nécessitent pas de droit
d'exécution.
Elle contient soit
YsoitN.Yindique que les actions n'ont pas d'ACL définies. - icon
- Icone de l'application.
- childof
- Nom de l'application parente. Cela indique que les actions de l'application parente sont disponibles sur cette application.
- with_frame
- Obsolète. Indique que les actions de l'application utilisent une entête commune.
- objectclass
- Obsolète. Non utilisé
- ssl
- Obsolète. Indique que l'application doit être exécutée avec le protocole https.
- machine
- Obsolète. Indique l'application est déployée sur un autre serveur.
- iorder
- Ordre d'installation des applications pour un module déclarant plusieurs applications.
- tag
- Permet d'indiquer une marque. Les applications de Dynacase Core sont marquées "CORE".
13.4.2 Propriétés fonctionnelles
Ces propriétés sont renseignées une fois que l'objet Application est initialisé avec un identifiant valide.
- user
- Objet Account identifiant l'utilisateur courant
- parent
- Objet Application identifiant l'application parente. Généralement elle pointe vers l'application "CORE".
- session
- Objet Session identifiant la session de paramètres de l'utilisateur courant.
13.4.3 Application::addCssCode
13.4.3.1 Description
void addCssCode ( string $code )
Permet d'ajouter des instructions CSS (code) qui seront insérées dans les
éléments [CSS:CODE] des templates utilisées lors du rendu d'une vue.
13.4.3.2 Avertissements
N/A
13.4.3.3 Liste des paramètres
- (string)
code - Bloc d'instructions CSS.
13.4.3.4 Valeur de Retour
La méthode ne retourne pas de valeur.
13.4.3.5 Erreurs / Exceptions
N/A
13.4.3.6 Historique
N/A
13.4.3.7 Exemples
- Exemple #1
Contrôleur de l'action MY_ACTION (my_action.php) :
function my_action(Action &$action) { /* Get the Application of the current Action */ $application = $action->parent; $cssCode = <<<'CSS' .question { color: blue; voice-family: Bridgekeeper, male; } CSS; $application->addCssCode($cssCode); }
Vue de l'action MY_ACTION (Layout/my_action.xml) :
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>My Action</title> <style type="text/css"> [CSS:CODE] </style> </head> <body> <h1 class="question">What is your favourite colour?</h1> </body> </html>
Résultat du rendu de la vue de l'action :
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>My Action</title> <style type="text/css"> .question { color: blue; voice-family: Bridgekeeper, male; } </style> </head> <body> <h1 class="question">What is your favourite colour?</h1> </body> </html>
13.4.3.8 Notes
N/A
13.4.3.9 Voir aussi
13.4.4 Application::addCssRef
13.4.4.1 Description
string addCssRef ( string $ref [, bool $needparse = false [, string $packName = '']] )
Permet d'ajouter un lien vers une feuille de style CSS qui sera insérée dans les
éléments [CSS:REF] des templates utilisées lors du rendu d'une vue.
13.4.4.2 Avertissements
N/A
13.4.4.3 Liste des paramètres
- (string)
ref -
La référence à la feuille de style CSS. La référence peut être :
si
needparseest faux :- un chemin d'accès relatif au contexte Dynacase (ex.
MY_APP/Layout/my_css.css,lib/my/my_css.css), - un chemin d'accès relatif au
répertoire
Layoutdu style actuellement appliqué, - une URL (ex.
http://www.example.net/my_css.css).
si
needparseest vrai :- un chemin d'accès
relatif au répertoire
Layoutde l'application courante ou d'une application particulière (ex.MY_APP:my_css.css),
- un chemin d'accès relatif au contexte Dynacase (ex.
- (bool)
needparse -
Permet d'indiquer si le contenu de la feuille de style doit être interprété comme un template.
Seuls les fichiers référencés comme template peuvent être parsés. La notation
APP:file.cssindique que le modèle à parser seraAPP/Layout/file.css. - (string)
packName - Les feuilles de style peuvent être concaténées afin de réduire le nombre de
fichiers chargés par le client. Dans ce cas, toutes les feuilles de style
ajoutées avec un même identifiant
packNameseront concaténées pour ne donner qu'un seul fichier à charger. DespackNamedifférents peuvent être utilisés pour faire des groupes de feuilles de style qui seront servis chacun dans un fichier unique et distinct parpackName.
13.4.4.4 Valeur de Retour
La méthode retourne une chaîne de caractères non vide avec l'emplacement de la feuille de style CSS ajoutée, ou une chaîne de caractères vide si l'emplacement de la feuille de style n'est pas valide.
13.4.4.5 Erreurs / Exceptions
N/A
13.4.4.6 Historique
N/A
13.4.4.7 Exemples
13.4.4.7.1 Exemple simple
Feuille de style CSS MY_APP/Layout/mycss.css :
.question { color: blue; }
Contrôleur de l'action MY_ACTION (my_action.php) de l'application MY_APP :
function my_action(Action &$action) { /* Get the Application of the current Action */ $application = $action->parent; $application->addCssRef('MY_APP/Layout/my.css'); }
Vue de l'action MY_ACTION (Layout/my_action.xml) :
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>My Action</title> [CSS:CUSTOMREF] </head> <body> <h1 class="question">What is your favourite colour?</h1> </body> </html>
Résultat du rendu de la vue de l'action :
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>My Action</title> <link rel="stylesheet" type="text/css" href="MY_APP/Layout/my.css?wv=3220"> </head> <body> <h1 class="question">What is your favourite colour?</h1> </body> </html>
L'url composée dans le fichier contient une clef identifiant une version du système. Le fichier css permet d'être mis en cache par le navigateur jusqu'à que cette clef soit modifiée. Cette clef est modifiée à chaque modification de module (installation ou mise à jour).
13.4.4.7.2 Exemple parse
Feuille de style CSS MY_APP/Layout/myParsecss.css :
.question { [IF ISIE7]color: [COLOR_A5];[ENDIF ISIE7] [IFNOT ISIE7]color: [COLOR_B5];[ENDIF ISIE7] }
Les clefs entres crochets sont des paramètres globaux de l'application. Elles seront remplacées sur le serveur lors de la demande du fichier css.
Contrôleur de l'action MY_ACTION (my_action.php) de l'application MY_APP :
function my_action(Action &$action) { /* Get the Application of the current Action */ $application = $action->parent; $application->addCssRef('MY_APP:my.css', true); }
Vue de l'action MY_ACTION (Layout/my_action.xml) :
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>My Action</title> [CSS:CUSTOMREF] </head> <body> <h1 class="question">What is your favourite colour?</h1> </body> </html>
Résultat du rendu de la vue de l'action :
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>My Action</title> <link rel="stylesheet" type="text/css" href="?app=CORE&action=CORE_CSS&ukey=6149df19b262da225264b7e96b0498c2&layout=MY_APP:my.css.css&type=css"> </head> <body> <h1 class="question">What is your favourite colour?</h1> </body> </html>
L'url composée dans le fichier contient une clef propre à l'utilisateur et à sa session. Le fichier css est de nouveau téléchargé à chaque changement de session.
13.4.4.7.3 Exemple Pack
Feuille de style CSS MY_APP/Layout/css_1.css :
.question { color: blue; }
Feuille de style CSS MY_APP/Layout/css_2.css :
.question { voice-family: Bridgekeeper, male; }
Contrôleur de l'action MY_ACTION (my_action.php) de l'application MY_APP :
function my_action(Action &$action) { /* Get the Application of the current Action */ $application = $action->parent; $application->addCssRef('MY_APP/Layout/css_1.css', false, 'my_css'); $application->addCssRef('MY_APP:css_2.css', false, 'my_css'); }
Vue de l'action MY_ACTION (Layout/my_action.xml) :
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>My Action</title> [CSS:CUSTOMREF] </head> <body> <h1 class="question">What is your favourite colour?</h1> </body> </html>
Résultat du rendu de la vue de l'action :
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>My Action</title> <link rel="stylesheet" type="text/css" href="pack.php?type=css&pack=my_css&wv=4253" /> </head> <body> <h1 class="question">What is your favourite colour?</h1> </body> </html>
13.4.4.8 Notes
- Les feuilles de style ajoutées via cette méthode seront servies avec une directive indiquant au client de mettre en cache le résultat obtenu et minimiser ainsi les requêtes au serveur.
- L'expiration de la mise en cache est gérée via un argument
wv=<version>dont le numéro de version est incrémenté à chaque mise à jour d'un module. - Les
packNamesont composés par utilisateur et sont mis en cache sur le navigateur de l'utilisateur : ils ne sont donc pas partagés et/ou mis en cache sur le serveur.
13.4.4.9 Voir aussi
13.4.5 Application::addJsCode
13.4.5.1 Description
void addJsCode ( string $code )
Permet d'ajouter des instructions JavaScript (code) qui seront insérées dans
les éléments [JS:CODE] des templates utilisées lors du rendu d'une vue.
13.4.5.2 Avertissements
N/A
13.4.5.3 Liste des paramètres
- (string)
code - Bloc de code d'instructions JavaScript.
13.4.5.4 Valeur de Retour
La méthode ne retourne pas de valeur.
13.4.5.5 Erreurs / Exceptions
N/A
13.4.5.6 Historique
N/A
13.4.5.7 Exemples
- Exemple #1
Contrôleur de l'action MY_ACTION (my_action.php) :
function my_action(Action &$action) { /* Get the Application of the current Action */ $application = $action->parent; $jsCode = <<<'JS' alert('Hello world'); JS; $application->addJsCode($jsCode); }
Vue de l'action MY_ACTION (Layout/my_action.xml) :
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>My Action</title> </head> <body> <script type="text/javascript"> [JS:CODE] </script> <h1>Have you seen any alert lately?</h1> </body> </html>
Résultat du rendu de la vue de l'action :
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>My Action</title> </head> <body> <script type="text/javascript" language="JavaScript"> alert('Hello world'); </script> <h1>Have you seen any alert lately?</h1> </body> </html>
13.4.5.8 Notes
N/A
13.4.5.9 Voir aussi
13.4.6 Application::addJsRef
13.4.6.1 Description
string addJsRef ( string $ref [, bool $needparse = false [, string packName = '']] )
Permet d'ajouter un lien vers un script JavaScript qui sera inséré dans les
éléments [JS:REF] des templates utilisées lors du rendu d'une vue.
13.4.6.2 Avertissements
N/A
13.4.6.3 Liste des paramètres
- (string)
ref - La référence au script JavaScript.
La référence peut être : un chemin d'accès relatif au contexte Dynacase (ex.
MY_APP/Layout/my_script.js,my_script.js), un chemin d'accès relatif au répertoireLayoutdu style actuellement appliqué, un chemin d'accès relatif au répertoireLayoutde l'application courante ou d'une application particulière (ex.MY_APP:my_script.js), une URL (ex.http://www.example.net/my_script.js). - (bool)
needparse - Permet d'indiquer si le contenu du script doit être interprété comme un template.
- (string)
packName - Les scripts peuvent être concaténés afin de réduire le nombre de fichiers
chargés par le client. Dans ce cas, tous les scripts ajoutés avec un même
identifiant
packNameseront concaténés pour ne donner qu'un seul fichier à charger. DespackNamedifférents peuvent être utilisés pour faire des scripts qui seront servis chacun dans un fichier unique et distinct parpackName.
13.4.6.4 Valeur de Retour
La méthode retourne une chaîne de caractère non vide avec l'emplacement du script JavaScript ajouté, ou une chaîne de caractère vide si l'emplacement du script n'est pas valide.
13.4.6.5 Erreurs / Exceptions
N/A
13.4.6.6 Historique
N/A
13.4.6.7 Exemples
- Exemple #1
Script JavaScript MY_APP/Layout/js_1.js :
alert('This is JS#1');
Script JavaScript MY_APP/Layout/js_2.js :
alert('This is JS#2');
Contrôleur de l'action MY_ACTION (my_action.php) de l'application MY_APP :
function my_action(Action &$action) { /* Get the Application of the current Action */ $application = $action->parent; $application->addJsRef('MY_APP/Layout/js_1.js', false, 'my_js'); $application->addJsRef('MY_APP:js_2.js', false, 'my_js'); }
Vue de l'action MY_ACTION (Layout/my_action.xml) :
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>My Action</title> </head> <body> [JS:REF] <h1>Have you seen any alert lately?</h1> </body> </html>
Résultat du rendu de la vue de l'action :
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>My Action</title> </head> <body> <script type="text/javascript" language="JavaScript" src="pack.php?type=js&pack=my_js&wv=4253" /></script> <h1>Have you seen any alert lately?</h1> </body> </html>
13.4.6.8 Notes
- Les scripts ajoutées via cette méthode seront servis avec une directive indiquant au client de mettre en cache le résultat obtenu et minimiser ainsi les requêtes au serveur.
- L'expiration de la mise en cache est gérée via un argument
wv=<version>dont le numéro de version est incrémenté à chaque mise à jour d'un module. - Les
packNamesont composés par utilisateur et sont mis en cache sur le navigateur de l'utilisateur : ils ne sont donc pas partagés et/ou mis en cache sur le serveur.
13.4.6.9 Voir aussi
13.4.7 Application::getCSSLink
13.4.7.1 Description
string getCSSLink ( string $ref [, bool $needparse = false [, string $packName = '']] )
Permet de retourner le lien de téléchargement (URL) d'une feuille de style CSS servie par Dynacase avec gestion de la version du cache (Voir [Notes](#core-ref :9C309FEA-C54A-48C3-AD9C-03F20D532D1D)).
13.4.7.2 Avertissements
N/A
13.4.7.3 Liste des paramètres
- (string)
ref - La référence à la feuille de style CSS.
La référence peut être : un chemin d'accès relatif au contexte Dynacase (ex.
MY_APP/Layout/my_css.css,my_css.css), un chemin d'accès relatif au répertoireLayoutdu style actuellement appliqué, un chemin d'accès relatif au répertoireLayoutde l'application courante ou d'une application particulière (ex.MY_APP:my_css.css), une URL (ex.http://www.example.net/my_css.css). - (bool)
needparse - Permet d'indiquer si le contenu de la feuille de style doit être interprété comme un template.
- (string)
packName - Les feuilles de style peuvent être concaténées afin de réduire le nombre de
fichiers chargés par le client. Dans ce cas, toutes les feuilles de style
ajoutées avec un même identifiant
packNameseront concaténées pour ne donner qu'un seul fichier à charger. DespackNamedifférents peuvent être utilisés pour faire des groupes de feuilles de style qui seront servis chacun dans un fichier unique et distinct parpackName.
13.4.7.4 Valeur de Retour
La méthode retourne une chaîne de caractère non vide avec le lien de téléchargement de la feuille de style CSS ajoutée, ou une chaîne de caractère vide si l'emplacement de la feuille de style n'est pas valide.
13.4.7.5 Erreurs / Exceptions
N/A
13.4.7.6 Historique
N/A
13.4.7.7 Exemples
- Exemple #1
Feuille de style CSS MY_APP/Layout/css_1.css :
.question { color: blue; voice-family: Bridgekeeper, male; }
Contrôleur de l'action MY_ACTION (my_action.php) :
function my_action(Action &$action) { /* Get the Application of the current Action */ $application = $action->parent; $cssLink = $application->getCSSLink('MY_APP/Layout/css_1.css'); $action->lay->set('CSS_LINK', htmlspecialchars($cssLink)); }
Vue de l'action MY_ACTION (Layout/my_action.xml) :
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>My Action</title> <link rel="stylesheet" type="text/css" href="[CSS_LINK]" /> </head> <body> <h1 class="question">What is your favourite colour?</h1> </body> </html>
Résultat du rendu de la vue de l'action :
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>My Action</title> <link rel="stylesheet" type="text/css" href="MY_APP/Layout/css_1.css?wv=4253" /> </head> <body> <h1 class="question">What is your favourite colour?</h1> </body> </html>
13.4.7.8 Notes
- Les feuilles de style ajoutées via cette méthode seront servies avec une directive indiquant au client de mettre en cache le résultat obtenu et minimiser ainsi les requêtes au serveur.
- L'expiration de la mise en cache est gérée via un argument
wv=<version>dont le numéro de version est incrémenté à chaque mise à jour d'un module. - Les
packNamesont composés par utilisateur et sont mis en cache sur le navigateur de l'utilisateur : ils ne sont donc pas partagés et/ou mis en cache sur le serveur.
13.4.7.9 Voir aussi
13.4.8 Application::getJSLink
13.4.8.1 Description
string getJSLink ( string $ref [, bool $needparse = false [, string $packName = '']] )
Permet de retourner le lien de téléchargement (URL) d'un script JavaScript servie par Dynacase avec gestion de la version du cache (Voir [Notes](#core- ref:3CD6C795-A11C-4128-B467-E221A81A0DF5)).
13.4.8.2 Avertissements
N/A
13.4.8.3 Liste des paramètres
- (string)
ref - La référence au script JavaScript.
La référence peut être : un chemin d'accès relatif au contexte Dynacase (ex.
MY_APP/Layout/my_script.js), une URL (ex.http://www.example.net/my_script.js), une action d'une application (ex.MY_APP:JS). La référence peut être : un chemin d'accès relatif au contexte Dynacase (ex.MY_APP/Layout/my_script.js,my_script.js), un chemin d'accès relatif au répertoireLayoutdu style du theme actuellement appliqué, un chemin d'accès relatif au répertoireLayoutde l'application courante ou d'une application particulière (ex.MY_APP:my_script.js), une URL (ex.http://www.example.net/my_script.js). - (bool)
needparse - Permet d'indiquer si le contenu du script doit être interprété comme un template.
- (string)
packName - Les scripts peuvent être concaténées afin de réduire le nombre de fichiers
chargés par le client. Dans ce cas, toutes les scripts ajoutées avec un même
identifiant
packNameseront concaténées pour ne donner qu'un seul fichier à charger. DespackNamedifférents peuvent être utilisés pour faire des groupes de scripts qui seront servis chacun dans un fichier unique et distinct parpackName.
13.4.8.4 Valeur de Retour
La méthode retourne une chaîne de caractère non vide avec le lien de téléchargement du script JavaScript ajouté, ou une chaîne de caractère vide si l'emplacement du script n'est pas valide.
13.4.8.5 Erreurs / Exceptions
N/A
13.4.8.6 Historique
N/A
13.4.8.7 Exemples
- Exemple #1
Script JavaScript MY_APP/Layout/script.js :
alert('Here I am!');
Contrôleur de l'action MY_ACTION (my_action.php) :
function my_action(Action &$action) { /* Get the Application of the current Action */ $application = $action->parent; $jsLink = $application->getJSLink('MY_APP/Layout/script.js'); $action->lay->set('JS_LINK', htmlspecialchars($jsLink)); }
Vue de l'action MY_ACTION (Layout/my_action.xml) :
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>My Action</title> </head> <body> <script type="text/javascript" language="JavaScript" src="[JS_LINK]"></script> </body> </html>
Résultat du rendu de la vue de l'action :
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>My Action</title> </head> <body> <script type="text/javascript" language="JavaScript" src="MY_APP/Layout/script.js&wv=4253"></script> </body> </html>
13.4.8.8 Notes
- Les scripts ajoutées via cette méthode seront servis avec une directive indiquant au client de mettre en cache le résultat obtenu et minimiser ainsi les requêtes au serveur.
- L'expiration de la mise en cache est gérée via un argument
wv=<version>dont le numéro de version est incrémenté à chaque mise à jour d'un module. - Les
packNamesont composés par utilisateur et sont mis en cache sur le navigateur de l'utilisateur : ils ne sont donc pas partagés et/ou mis en cache sur le serveur.
13.4.8.9 Voir aussi
13.5 Classe Dir
La famille DIR est la famille "Dossier". Cette famille permet de référencer
des documents au sein d'une même collection. Cette famille hérite de la classe
Dir.
Un document de la famille DIR est appelé un dossier.
Cette classe, comme la classe DocSearch (pour la famille
SEARCH), hérite de la classe DocCollection qui
apporte les méthodes de contenus commune aux dossiers et aux recherches tel que
::getContent().
Les méthodes de la famille DIR permettent de gérer le référencement (ajout ou
suppression) de documents dans des dossiers.
Lors de l'ajout ou de la suppression des documents du dossier, des hameçons peuvent être appelés.
13.5.1 Méthodes de la classe Dir
Ce chapitre décrit les méthodes essentielles de la classe Dir.
13.5.1.1 Dir::insertDocument()
La méthode insertDocument permet d'insérer un document dans le dossier.
13.5.1.1.1 Description
string insertDocument ( string $docid, string $mode = "latest", bool $noprepost = false, bool $forcerestrict = false, bool $nocontrol = false )
Cette méthode permet d'ajouter une référence au dossier. Une référence
correspond à un document sans tenir compte de ses révisions. La
référence correspond à l'identifiant initial du document (initid).
13.5.1.1.1.1 Avertissements
Si la référence existe déjà dans le dossier, la référence est ignorée.
13.5.1.1.2 Liste des paramètres
- (string)
docid - L'identifiant (identifiant numérique ou nom logique) du document à insérer dans le dossier. Cet identifiant peut correspondre à n'importe quelle révision du document.
- (string)
mode - Seule la valeur
latest(valeur par défaut) est supportée. - (bool)
noprepost -
noprepostpermet de désactiver l'appel des méthodes hameçonspreInsertDocumentetpostInsertDocumentappelées respectivement avant et après l'insertion du document dans le dossier.Valeur par défaut :
false(activation des hameçons).Si
falseles hameçonspreInsertDocumentetpostInsertDocumentsont appelés.
Sitrue, les hameçons ne sont pas appelés. - (bool)
forcerestrict -
forcerestrictpermet de désactiver le contrôle des restrictions d'insertion.Valeur par défaut :
false(contrôle des restrictions effectuée).Si
false: le contrôle des restrictions d'insertion est effectué.
Sitrue: le contrôle des restrictions d'insertion n'est pas effectué. - (bool)
nocontrol -
nocontrolpermet de désactiver le contrôle du droit d'insertion de documents dans le dossier.Valeur par défaut :
false(contrôle de droits effectué).Si
false: le contrôle du droit d'insertion est effectué.
Sitrue: le contrôle du droit d'insertion n'est pas effectué.
13.5.1.1.3 Valeur de retour
La méthode retourne une chaîne vide s'il n'y a pas d'erreurs, ou une chaîne non- vide contenant le message d'erreur dans le cas contraire.
13.5.1.1.4 Erreurs / Exceptions
Les erreurs peuvent êtres :
- L'utilisateur ne possède pas le droit d'insertion (droit
modify) de documents dans le dossier - Le dossier est verrouillé par un autre utilisateur.
(voir paramètre
nocontrolci-dessus). - Le document inséré n'est pas compatible par rapport aux
restrictions appliqués sur le dossier (voir paramètre
forcerestrictci-dessus). - Les méthodes d'hameçon
preInsertDocumentoupostInsertDocumentont retourné une erreur (voir paramètrenoprepostci-dessus).
13.5.1.1.5 Historique
13.5.1.1.5.1 Release 3.2.5
La méthode insertDocument remplace la méthode précédemment nommée addFile.
L'utilisation de addFile est obsolète depuis la version 3.2.5 de dynacase-
core.
13.5.1.1.6 Exemples
La famille Groupe d'utilisateurs (IGROUP) hérite de GROUP qui hérite de
DIR et permet de gérer l'affectation d'utilisateurs dans les groupes.
L'exemple ci-dessous montre comment insérer l'utilisateur ayant pour nom logique
USR_EMMA_PEEL dans le groupe ayant pour nom logique GRP_THE_AVENGERS :
<?php global $action; include_once 'FDL/freedom_util.php'; $grpName = 'GRP_THE_AVENGERS'; $usrName = 'USR_EMMA_PEEL'; /* * Instancier le groupe */ $group = new_Doc('', $grpName); /* * Instancier l'utilisateur */ $user = new_Doc('', $usrName); /* * Afficher le contenu du groupe */ printf("* Content of DIR '%s':\n", $grpName); $s = new SearchDoc(); $s->useCollection($group->id); $members = $s->search(); if (count($members) <= 0) { printf("\t<empty>\n"); } else { foreach ($members as $elmt) { printf("\t(%d) '%s'\n", $elmt['id'], $elmt['title']); } } /* * Insérer l'utilisateur dans le groupe */ printf("* Inserting '%s' into '%s'.\n", $usrName, $grpName); $err = $group->insertDocument($user->id); if ($err != '') { throw new \Exception(sprintf("Error inserting user (%d) '%s' into group (%d) '%s': %s", $user->id, $user->title, $group->id, $group->title, $err)); } /* * Afficher le contenu du groupe */ printf("* Content of DIR '%s':\n", $grpName); $s = new SearchDoc(); $s->useCollection($group->id); $members = $s->search(); if (count($members) <= 0) { printf("\t<empty>\n"); } else { foreach ($members as $elmt) { printf("\t(%d) '%s'\n", $elmt['id'], $elmt['title']); } }
Résultat :
* Content of DIR 'GRP_THE_AVENGERS':
<empty>
* Inserting 'USR_EMMA_PEEL' into 'GRP_AVENGERS'.
* Content of DIR 'GRP_THE_AVENGERS':
id = 1057 / title = 'Peel Emma'
13.5.1.1.7 Notes
Ordre d'appel des hameçons :
.-(1)--------------------------------------. | $this->preInsertDocument($docId, false); | '------------------------------------------' <Insertion du document $docId dans le dossier> .-(2)---------------------------------------. | $this->postInsertDocument($docId, false); | '-------------------------------------------'
13.5.1.1.8 Voir aussi
13.5.1.2 Dir::insertMultipleDocuments()
La méthode insertMultipleDocuments permet d'insérer plusieurs documents dans
le même dossier.
13.5.1.2.1 Description
string insertMultipleDocuments ( array $tdocs, string $mode = "latest", bool $noprepost = false, & $tinserted = array(), & $twarning = array(), & $info = array() ) )
13.5.1.2.1.1 Avertissements
Aucun.
13.5.1.2.2 Liste des paramètres
- (array)
tdocs -
tdocsest une liste de documents bruts (voir Retour de documents bruts avecSearchDoc) à insérer dans le dossier. - (string)
mode - Seule la valeur
latest(valeur par défaut) est supportée. - (bool)
noprepost -
noprepostpermet de désactiver l'appel des méthodes hameçonspreInsertMultipleDocuments,preInsertDocument,postInsertDocumentetpostInsertMultipleDocumentsappelées avant ou après l'insertion des documents dans le dossier.Valeur par défaut :
false.Si
false, les hameçonspreInsertMultipleDocuments,preInsertDocumentetpostInsertMultipleDocumentssont appelés. - [out] (string[])
tinserted -
tinsertedréférence un array associatif retourné par la méthode.Les clés sont les identifiants (
initid) des documents insérés dans le dossier et la valeur est un message indiquant que le document a été inséré dans le dossier.Exemple de valeur retournée dans le array référencé :
array( 1234 => 'Document 1234 inséré', 2345 => 'Document 2345 inséré' )
- [out] (string[])
twarning -
twarningréférence un array associatif retourné par la méthode.Les clés sont les identifiants des documents qui n'ont pas pu être insérés dans le dossier et la valeur est le message d'erreur de l'insertion.
- [out] (array)
info -
inforéférence un array associatif retourné par la méthode.Il contient les erreurs retournés par les différents hameçons, et est de la forme suivante :
array( 'error' => "Message d'erreur global de insertMultipleDocuments", 'modifyError' => "Erreur lié au droit de modification" 'preInsertMultipleDocuments' => "Message d'erreur de preInsertMultipleDocuments", 'preInsertDocument' => array( "Message d'erreur de preInsertDocument#1", ... "Message d'erreur de perInsertDocument#N" ), 'postInsertDocument' => array( "Message d'erreur de postInsertDocument#1", ... "Message d'erreur de postInsertDocument#N" ), 'postInsertMultipleDocuments' => "Message d'erreur de postInsertMultipleDocuments()" )
13.5.1.2.3 Valeur de retour
La méthode retourne une chaîne vide s'il n'y a pas d'erreurs, ou une chaîne non- vide contenant le message d'erreur.
13.5.1.2.4 Erreurs / Exceptions
Les erreurs peuvent êtres :
- L'utilisateur ne possède pas le droit d'insertion de documents dans le dossier.
- Le dossier est verrouillé par un autre utilisateur.
- Le document inséré n'est pas compatible par rapport aux documents supportés par le dossier.
- Les méthodes d'hameçon
preInsertMultipleDocuments,preInsertDocument,postInsertDocumentoupostInsertMultipleDocumentsont retourné une erreur (voir paramètrenoprepostci-dessus).
Les documents qui n'ont pas pu être insérés dans le dossier peuvent être
consultés via l'argument retour $twarning passé à la méthode
insertMultipleDocuments.
13.5.1.2.5 Historique
13.5.1.2.5.1 Release 3.2.5
La méthode insertMultipleDocuments remplace la méthode précédemment nommée
InsertMDoc.
L'utilisation de InsertMDoc est obsolète depuis la version 3.2.5 de dynacase-
core.
13.5.1.2.5.2 Release 3.2.12
3.2.12 La méthode
Dir::insertMultipleDocuments a été modifiée afin de faire remonter le message
d'erreur de la méthode hameçon Dir::postInsertMultipleDocuments dans son
retour d'erreur.
La méthode Dir::insertMultipleDocuments ajoute un 6ème paramètre optionnel
info qui permet de récupérer les
différents messages d'erreurs rencontrés.
13.5.1.2.6 Exemples
L'exemple suivant va rechercher tous les utilisateurs dont l'adresse mail
contient @the-avengers.net, et les insérer dans un nouveau groupe
GRP_THE_AVENGERS :
include_once "FDL/freedom_util.php"; /* * Créer un nouveau groupe GRP_EXAMPLE_NET */ /** * @var \dcp\Family\Igroup $group */ $group = createDoc('', 'IGROUP'); $group->setAttributeValue('us_login', 'grp_the_avengers'); $group->setAttributeValue('grp_name', 'Groupe @the-avengers.net'); $group->store(); /* * Affecter un nom logique au groupe */ $group->setLogicalName('GRP_THE_AVENGERS'); /* * Rechercher tous les utilisateurs ayant une * adresse mail en "@the-avengers.net". */ $s = new SearchDoc('', 'IUSER'); $s->addFilter("us_extmail LIKE '%@the-avengers.net'"); $userList = $s->search(); if (count($userList) > 0) { /* * Insérer tous ces utilisateurs dans le groupe. */ $insertedList = array(); $warningList = array(); $err = $group->insertMultipleDocuments( $userList, "latest", false, $insertedList, $warningList ); if ($err != '') { printf("* Some documents have not been inserted: %s", $err); } printf("* %d insertions :\n", count($insertedList)); foreach ($insertedList as $docId => $msg) { printf("\t[%s] %s\n", $docId, $msg); } printf("* %d warnings :\n", count($warningList)); foreach ($warningList as $docId => $warningMsg) { printf("\t[%d] %s\n", $docId, $warningMsg); }
}
Résultat :
* 2 insertions :
[1057] Insertion document Peel Emma
[1058] Insertion document Steed John
* 0 warnings :
13.5.1.2.7 Notes
Ordre d'appel des hameçons :
.-(1)-------------------------------------------------------.
| $this->preInsertMultipleDocuments($rawDocumentList); |
'-----------------------------------------------------------'
foreach ($rawDocumentList as $rawDoc) {
.-(2)--------------------------------------.
| $this->preInsertDocument($rawDoc, true); |
'------------------------------------------'
<Insertion du document $rawDoc['id'] dans le dossier>
.-(3)---------------------------------------.
| $this->postInsertDocument($rawDoc, true); |
'-------------------------------------------'
}
.-(4)-------------------------------------------------------.
| $this->postInsertMultipleDocuments($rawDocumentList); |
'-----------------------------------------------------------'
13.5.1.2.8 Voir aussi
13.5.1.3 Dir::removeDocument()
La méthode removeDocument permet d'enlever un document du dossier.
13.5.1.3.1 Description
string removeDocument ( string $docid, bool $noprepost = false, bool $nocontrol = false )
Cette méthode enlève une reférence de document au dossier.
13.5.1.3.1.1 Avertissements
Le document n'est pas supprimé. Seule sa référence au dossier est supprimée.
13.5.1.3.2 Liste des paramètres
- (string)
docid - L'identifiant (identifiant numérique ou nom logique) du document à enlever du dossier.
- (bool)
noprepost -
noprepostpermet de désactiver l'appel des méthodes hameçonspreRemoveDocumentetpostRemoveDocumentappelées respectivement avant et après la suppression du document dans le dossier.Valeur par défaut :
false.Si
false, les hameçonspreRemoveDocumentetpostRemoveDocumentsont appelés.
Sitrue, les hameçons ne sont pas appelés. - (bool)
nocontrol -
nocontrolpermet de désactiver le contrôle du droit de modification du dossier .Valeur par défaut :
false.Si
false, le contrôle du droit de modification du dossier est effectué.
Sitrue, le contrôle de droit n'est pas effectué.
13.5.1.3.3 Valeur de retour
La méthode retourne une chaîne vide s'il n'y a pas d'erreurs, ou une chaîne non- vide contenant le message d'erreur dans le cas contraire.
13.5.1.3.4 Erreurs / Exceptions
Les erreurs peuvent êtres :
- L'utilisateur ne possède pas le droit de modifier le contenu du dossier (voir
paramètre
nocontrolci-dessus). - Les méthodes d'hameçon
preRemoveDocumentoupostRemoveDocumentont retourné une erreur (voir paramètrenoprepostci-dessus).
Si le document à enlever n'est pas présent, aucune erreur n'est retournée.
13.5.1.3.5 Historique
13.5.1.3.5.1 Release 3.2.5
La méthode removeDocument remplace la méthode précédemment nommée delFile.
L'utilisation de delFile est obsolète depuis la version 3.2.5 de dynacase-
core.
13.5.1.3.6 Exemples
$dossier = new_Doc('', 'MY_FOLDER'); /* * Rechercher tous les documents référencés dans le dossier */ $s = new SearcDoc(''); $s->useCollection($dossier->id); $docList = $s->search(); /* * Enlever les documents du dossier */ foreach ($docList as $doc) { $err = $dossier->removeDocument($doc['initid']); if ($err != '') { printf("Error removing document '%d' from DIR: %s", $doc['id'], $err); } }
13.5.1.3.7 Notes
Ordre d'appel des hameçons :
.-(1)-------------------------------. | $this->preRemoveDocument($docId); | '-----------------------------------' <Suppression du document $docId dans le dossier> .-(2)--------------------------------. | $this->postRemoveDocument($docId); | '------------------------------------'
13.5.1.3.8 Voir aussi
13.5.2 Hameçons (hooks) de la classe Dir
Ce chapitre décrit les méthodes hameçons de la classe Dir.
Ces méthodes sont toutes vides. Elles ne contiennent aucun code à part la valeur de retour. Par contre, si la famille dérive d'une autre famille, il est nécessaire d'appeler l'hameçon du parent afin de garantir l'intégrité. Il est toutefois possible de ne pas appeler la méthode parente si le comportement doit être radicalement modifié.
13.5.2.1 Dir::preInsertDocument()
La méthode preInsertDocument est appelée par la méthode
insertDocument ou
insertMultipleDocuments avant l'insertion du
document dans le Dossier (si l'argument
noprepost est égal à false).
13.5.2.1.1 Description
string preInsertDocument ( string $docid, bool $multiple = false )
13.5.2.1.1.1 Avertissements
Aucun.
13.5.2.1.2 Liste des paramètres
- (string)
docid - L'identifiant (identifiant numérique ou nom logique) du document qui va être inséré dans le Dossier.
- (bool)
multiple -
multipleest positionné par la méthodeinsertMultipleDocumentspour indiquer quepreInsertDoucmentest appelé dans le cadre de l'insertion de plusieurs documents.Valeurs possibles :
-
true: Indique que le document inséré l'est dans le cadre de l'insertion de plusieurs documents. -
false: Indique qu'un seul document est inséré dans le dossier.
-
13.5.2.1.3 Valeur de retour
La méthode retourne une chaîne vide s'il n'y a pas d'erreurs, ou une chaîne non- vide contenant le message d'erreur dans le cas contraire.
13.5.2.1.4 Erreurs / Exceptions
Si la méthode preInsertDocument retourne une chaîne non-vide, alors
l'insertion n'est pas faite, et la méthode
insertDocument retourne avec le message retourné par
preInsertDocument.
13.5.2.1.5 Historique
13.5.2.1.5.1 Release 3.2.5
La méthode preInsertDocument remplace la méthode précédemment nommée
preInsertDoc.
L'utilisation de preInsertDoc est obsolète depuis la version 3.2.5 de
dynacase-core.
13.5.2.1.6 Exemples
namespace Facturation; class ArchiveFacture extends \Dcp\Family\Dir { public function preInsertDocument($docId, $multiple = false) { $err=parent::preInsertDocument($docId, $multiple); if (empty($err)) { $facture = new_Doc('', $docId, true); // prendre la dernière révision if ($facture->isAlive()) { /* * Seule les factures payés peuvent * être insérées dans ce dossier. */ if ($facture->isPaid()) { return sprintf( "La facture '%s' ne peut être archivée car elle n'est pas payée.", $facture->getTitle() ); } } } return $err; } protected function isPaid() { // Test de facturation } }
13.5.2.1.7 Notes
Aucune.
13.5.2.1.8 Voir aussi
13.5.2.2 Dir::postInsertDocument()
La méthode postInsertDocument est appelée par la méthode
insertDocument ou
insertMultipleDocuments après l'insertion du
document dans le Dossier (si noprepost est
égal à false).
13.5.2.2.1 Description
string postInsertDocument ( string $docid, bool $multiple = false )
13.5.2.2.1.1 Avertissements
Aucun.
13.5.2.2.2 Liste des paramètres
- (string)
docid - L'identifiant (identifiant numérique ou nom logique) du document qui a été inséré dans le Dossier.
- (bool)
multiple -
multipleest positionné par la méthodeinsertMultipleDocumentspour indiquer quepostInsertDoucmentest appelé dans le cadre de l'insertion de plusieurs document.Valeurs possibles :
-
true: Indique que le document inséré l'est dans le cadre de l'insertion de plusieurs documents. -
false: Indique qu'un seul document est inséré dans le dossier.
-
13.5.2.2.3 Valeur de retour
La méthode retourne une chaîne vide s'il n'y a pas d'erreurs, ou une chaîne non- vide contenant le message d'erreur dans le cas contraire.
13.5.2.2.4 Erreurs / Exceptions
Aucune.
13.5.2.2.5 Historique
13.5.2.2.5.1 Release 3.2.5
La méthode postInsertDocument remplace la méthode précédemment nommée
postInsertDoc.
L'utilisation de postInsertDoc est obsolète depuis la version 3.2.5 de
dynacase-core.
13.5.2.2.6 Exemples
namespace Facturation; class ArchiveFacture extends \Dcp\Family\Dir { public function postInsertDocument($docId, $multiple = false) { $err=parent::postInsertDocument($docId, $multiple); if (empty($err)) { /* * Appeler la méthode archiverFacture() des * factures insérées dans le dossier. */ $facture = new_Doc('', $docId, true);// prendre la dernière révision $facture->archiverFacture(); } return $err; } protected function archiverFacture() { // Archivage facturation } }
13.5.2.2.7 Notes
Aucune.
13.5.2.2.8 Voir aussi
13.5.2.3 Dir::preInsertMultipleDocuments()
La méthode preInsertMultipleDocuments est appelée par la méthode
insertMultipleDocuments avant l'insertion des
documents dans le Dossier (si
noprepost est égal à false).
13.5.2.3.1 Description
string preInsertMultipleDocuments ( string[]|int[] $tdocids )
13.5.2.3.1.1 Avertissements
Aucun.
13.5.2.3.2 Liste des paramètres
- (string[]|int[]
tdocids - Liste d'identifiants (identifiant numérique ou nom logique) des documents qui vont être insérés dans le dossier.
13.5.2.3.3 Valeur de retour
La méthode retourne une chaîne vide s'il n'y a pas d'erreurs, ou une chaîne non- vide contenant le message d'erreur dans le cas contraire.
13.5.2.3.4 Erreurs / Exceptions
Si la méthode preInsertMultipleDocuments retourne une chaîne non-vide, alors
l'insertion n'est pas faite, et la méthode
insertMultipleDocuments retourne avec le
message retourné par preInsertMultipleDocuments.
13.5.2.3.5 Historique
Aucun.
13.5.2.3.6 Exemples
namespace Facturation; class ArchiveFacture extends \Dcp\Family\Dir { public function preInsertMultipleDocument($rawDocList) { $err=parent::preInsertMultipleDocument($rawDocList); if (empty($err)) { if (count($rawDocList) > 10) { return sprintf("Vous ne pouvez insérer que jusqu'à 10 documents à la fois."); } } return $err; } }
13.5.2.3.7 Notes
Aucune.
13.5.2.3.8 Voir aussi
13.5.2.4 Dir::postInsertMultipleDocuments()
La méthode postInsertMultipleDocuments est appelée par la méthode
insertDocument après l'insertion de documents
dans le Dossier (si noprepost est
égal à false).
13.5.2.4.1 Description
string postInsertMultipleDocuments ( int[]|string[] $tdocids )
13.5.2.4.1.1 Avertissements
Aucun.
13.5.2.4.2 Liste des paramètres
- (int[]|string[])
tdocids - Liste d'identifiants (identifiant numérique ou nom logique) des documents qui ont été insérés dans le dossier.
13.5.2.4.3 Valeur de retour
La méthode retourne une chaîne vide s'il n'y a pas d'erreurs, ou une chaîne non- vide contenant le message d'erreur dans le cas contraire.
13.5.2.4.4 Erreurs / Exceptions
Aucune.
13.5.2.4.5 Historique
13.5.2.4.5.1 Release 3.2.5
La méthode postInsertMultipleDocuments remplace la méthode précédemment nommée
postMInsertDoc.
L'utilisation de postMInsertDoc est obsolète depuis la version 3.2.5 de
dynacase-core.
13.5.2.4.6 Exemples
La fonction d'archivage ne doit être déclenchée qu'une seule fois lors de l'insertion de plusieurs documents. Par contre, cette fonction d'archivage doit aussi être déclenché lors d'une insertion unitaire.
namespace Facturation; class ArchiveFacture extends \Dcp\Family\Dir { public function postInsertMultipleDocument($docIdList) { $err=parent::postInsertMultipleDocument($docIdList); if (empty($err)) { /* * Faire une archive du lot des documents insérés */ $this->archiveDocuments($docIdList); } return $err; } public function postInsertDocument($docId, $multiple = false) { $err=parent::postInsertDocument($docId, $multiple); if (empty($err) && ($multiple == false)) { /* * Faire une archive du document inséré */ $this->archiveDocuments(array($docId)); } return $err; } protected function archiveDocuments(array $docIds) { // Archivage d'une liste de document } }
13.5.2.4.7 Notes
Aucune.
13.5.2.4.8 Voir aussi
13.5.2.5 Dir::preRemoveDocument()
La méthode preRemoveDocument est appelée par la méthode
removeDocument avant la suppression d'un document dans
le dossier (si noprepost est égal à false).
13.5.2.5.1 Description
string preRemoveDocument ( string $docid )
13.5.2.5.1.1 Avertissements
Aucun.
13.5.2.5.2 Liste des paramètres
- (string)
docid - L'identifiant (identifiant numérique ou nom logique) du document à enlever du dossier.
13.5.2.5.3 Valeur de retour
La méthode retourne une chaîne vide s'il n'y a pas d'erreurs, ou une chaîne non- vide contenant le message d'erreur dans le cas contraire.
13.5.2.5.4 Erreurs / Exceptions
Si la méthode preRemoveDocument retourne une erreur, alors la suppression du
document dans le dossier n'est pas effectuée.
13.5.2.5.5 Historique
13.5.2.5.5.1 Release 3.2.5
La méthode preRemoveDocument remplace la méthode précédemment nommée
preUnlinkDoc.
L'utilisation de preUnlinkDoc est obsolète depuis la version 3.2.5 de
dynacase-core.
13.5.2.5.6 Exemples
namespace Facturation; class ArchiveFacture extends \Dcp\Family\Dir { public function preRemoveDocument($docId) { $facture = new_Doc('', $docId, true); // prendre la dernière révision if (!$facture->isPaid()) { return sprintf( 'La facture doit être payée pour pouvoir être enlevée du dossier.' ); } return ''; } }
13.5.2.5.7 Notes
Aucune.
13.5.2.5.8 Voir aussi
13.5.2.6 Dir::postRemoveDocument()
La méthode postRemoveDocument est appelée par la méthode
removeDocument après que le document ait été enlevé du
dossier (si noprepost est égal à false).
13.5.2.6.1 Description
string postRemoveDocument ( string $docid )
13.5.2.6.1.1 Avertissements
Aucun.
13.5.2.6.2 Liste des paramètres
- (string)
docid - L'identifiant (identifiant numérique ou nom logique) du document qui a été supprimé dans le dossier.
13.5.2.6.3 Valeur de retour
La méthode retourne une chaîne vide s'il n'y a pas d'erreurs, ou une chaîne non- vide contenant le message d'erreur dans le cas contraire.
13.5.2.6.4 Erreurs / Exceptions
Aucune.
13.5.2.6.5 Historique
13.5.2.6.5.1 Release 3.2.5
La méthode postRemoveDocument remplace la méthode précédemment nommée
postUnlinkDoc.
L'utilisation de postUnlinkDoc est obsolète depuis la version 3.2.5 de
dynacase-core.
13.5.2.6.6 Exemples
namespace Facturation; class ArchiveFacture extends \Dcp\Family\Dir { public function postRemoveDocument($docId) { /* * Mettre la facture dans l'état 'Brouillon' * lorsqu'elle est enlevé du dossier */ $facture = new_Doc('', $docId, true); $facture->setState('ST_Brouillon'); return ''; } }
13.5.2.6.7 Notes
Aucune.
13.5.2.6.8 Voir aussi
13.6 Classe Doc
Classe de Document.
Toutes les familles de documents héritent de cette classe. Cette classe décrit l'ensemble des propriétés communes aux documents de toutes les familles. Elle donne accès aux méthodes communes de manipulation de document comme la modification de document, la récupération de valeur d'attributs ou le mécanisme de hook.
13.6.1 Propriétés de la classe Doc
La classe Doc dispose de plusieurs propriétés.
Ces propriétés peuvent être récupérées au moyen de la méthode
Doc::getPropertyValue.
De façon générale, bien que ces propriétés ne soient pas marquées comme
private, leur affectation ne doit passer que par les setters appropriés. Les
propriétés n'ayant pas de setter spécifiques sont modifiées par effet de bord
d'autres méthodes du document (par exemple, Doc::revision ne doit pas être
modifié, mais Doc::revise incrémente cette propriété).
- adate
- Date de dernier accès au document.
- allocated
- Identifiant système de l'utilisateur auquel le document est affecté.
- archiveid
-
Id de l'archive dans laquelle est contenue ce document.
Note : cette propriété n'est portée que par le document archivé. Pour trouver la liste des lignées documentaires archivées, il faut faire une recherche sur toutes les révisions.
- atags
-
Balises applicatives (Tags positionnés sur le document).
Ces tags permettent aux applications de marquer les documents pour des traitements spécifiques.
Les tags sont stockés dans une chaîne de caractères et sont séparés par des
\n.La méthode
Doc::getATag()vérifie la présence d'une balise applicative. - cdate
-
Date de création de la révision.
Pour obtenir la date de création de la lignée documentaire, il faut récupérer celle de la révision 0.
Le format de la date est
YYYY-MM-DD HH:MM:SS. - classname
- Nom de la classe associée au document. Utilisé uniquement pour les familles.
- comment
- Commentaire de révision. Obsolète (voir Objet DocHisto).
- confidential
-
Indique si le document est confidentiel.
Dans ce cas, confidential vaut 1.
- cvid
- Identifiant du document contrôle de vue associé à ce document.
- doctype
-
Type de document.
Utilisé en interne pour des optimisations de performance et des contrôles.
- F : Document normal (historiquement, F pour Freedom Document),
- D : Dossier (D pour Dir),
- S : Recherche (S pour Search),
- P : Profil,
- T : Temporaire,
- I : Incomplet,
- Z : Document supprimé (Z pour Zombie),
- W : Cycle de vie (W pour Workflow),
- C : Famille (C pour Class).
- domainid
- Voir la documentation de l'application offline.
- dprofid
-
Identifiant du profil dynamique associé à ce document.
Lorsque le document est soumis à un profil dynamique, ce profil dynamique lui permet de calculer le profil qui lui sera appliqué, lequel est stocké sur le document lui-même. Ainsi, lorsque la propriété dprofid est renseignée, la propriété profid est égale à l'id du document (ce qui correspond à un profil dédié).
- forumid
- Obsolète
- fromid
- Id de la famille d'appartenance.
- icon
-
Référence au fichier d'icone du document.
La valeur est :
- le nom de l'icone
- ou la référence d'un fichier du vault (sous la forme <type-mime>|<vaultid>|<file-title>).
- id
-
Identifiant unique du document.
Il est calculé automatiquement par la base de données lors de l'ajout du document en base.
- initid
-
Id du premier document de la lignée documentaire.
Il est notamment utile pour les recherches.
- ldapdn
- Chemin LDAP dans le cas d'une copie sur un serveur LDAP. obsolète
- lmodify
-
Permet de savoir si le document a été modifié depuis sa dernière révision.
Les valeurs sont :
-
Y: La révision est la révision courante et a été modifiée depuis la dernière révision ; -
L: La révision est la dernière révision avant la révision courante ; -
D: La révision est supprimée ; -
N:- Toute révision figée du document (autre que la N-1) : dans ce cas, locked vaut -1 ;
- La révision est la révision courante du document, mais identique à la révision N-1.
-
- lockdomainid
- Voir la documentation de l'application offline.
- locked
-
Indique l'identifiant système de l'utilisateur qui a verrouillé le document :
-
Chiffre négatif (inférieur à -1) : La valeur absolue indique l'identifiant système de l'utilisateur ayant verrouillé le document automatiquement.
Ce verrou est posé lorsqu'un utilisateur clique sur le bouton de modification d'un document, et est supprimé automatiquement lors de la fin de l'édition, à la fermeture du navigateur (au moyen de l'événement
onBeforeUnload), ainsi que par le scriptcleanContext. Chiffre positif : Identifiant système de l'utilisateur ayant verrouillé le document manuellement.
0: Pas de verrou.-1: Document révisé (figé).
-
- name
-
Nom logique du document.
Référence toujours la version courante d'un document. Le nom logique est identique quelque soit la révision d'un même document. Lorsqu'on affecte un nom logique il est affecté sur l'ensemble de la lignée documentaire. Si le nom logique est utilisé comme référence pour accèder à un document, c'est la dernière révision qui sera retourné.
- owner
-
Identifiant système de l'utilisateur ayant créé le document.
Cette valeur est spécifique à chaque révision.
- postitid
- Identifiant du document post-it associé (famille NOTE).
- prelid
-
Identifiant du document (dossier) de relation primaire.
Cela correspond au parent lors d'une représentation arborescente.
Cette propriété est gérée automatiquement avec les règles de gestion suivantes :
- Lorsque le document n'a jamais été inséré dans un dossier : le premier dossier dans lequel est inséré le document ;
- Lorsque le document est déplacé dans un nouveau dossier : le dernier dossier dans lequel est déplacé le document ;
- Lorsque le document est retiré d'un dossier : si le document est dans un autre dossier, alors celui-ci est sélectionné.
- profid
-
Identifiant du [profil de document][profdoc].
- Chiffre négatif : Profil non activé ;
- 0 : pas de profil ;
- Vide : Pas de profil ;
- Chiffre positif : profil actif ;
- Identique à l'id du document : contrôle dédié ;
- Autre valeur positive : profil lié, non dynamique.
- revdate
-
Date de révision.
Pour un document non révisé, c'est la date de dernière modification. Le format de cette date un entier (unix timestamp).
- revision
- Numéro d'ordre du document dans sa lignée documentaire.
- state
- Étape du document ou référence à un identifiant de document état libre.
- title
- Titre du document.
- usefor
-
Type d'utilisation du document :
-
S: La famille est Système : elle n'apparaît pas par défaut dans la liste des familles pour les recherches, recherches détaillées ou rapports.Le caractère 'S' peut aussi être placé devant les autres caractères décrits ci-dessous pour masquer la famille dans les recherches.
W: Le document est un cycle de vie (W pour Workflow) ;G: Le document est un intercalaire de chemise (G pour Guide) ;P: Le document est un profil (P pour Profile).
-
- version
-
Libellé de la version : il est vide par défaut.
La version est affichée à coté de l'état sur les documents et dans l'historique.
Note : La version n'est pas obligatoirement numérique, elle peut aussi être alphanumérique ; mais elle ne doit pas contenir de retour de chariot.
- wid
- Identifiant du document cycle de vie associé à ce document.
13.6.2 Hameçons (hooks) de la classe Doc
Ce chapitre décrit les méthodes hameçons de la classe Doc qui sont
utilisées dans les différentes méthodes de modification de document.
Ces méthodes sont toutes vides. Elles ne contiennent aucun code à part la valeur de retour. Par contre, si la famille dérive d'une autre famille, il est nécessaire d'appeler l'hameçon du parent afin de garantir l'intégrité. Il est toutefois possible de ne pas appeler la méthode parente si le comportement doit être radicalement modifié.
13.6.2.1 Doc::preCreated()
Hameçon (ou hook) utilisé par la méthode Doc::Store().
Elle est appelée avant l'enregistrement en base de données. Cette méthode est
principalement utilisée pour vérifier si les conditions de création / révision
de document sont valides.
Cette méthode est utilisable aussi pour pré-remplir des attributs avant l'enregistrement.
Attention :Cette méthode est aussi appelée lors de la révision d'un document.
13.6.2.1.1 Description
string preCreated ()
Si cette méthode retourne un message d'erreur alors la création est abandonnée
et la méthode Doc::store() retourne le message fourni par cette
méthode afin d'indiquer l'échec.
13.6.2.1.1.1 Avertissements
Cette méthode est appelée lors la création initiale et lors des révisions du document. Toutefois, il est possible de différencier la création de la révision car :
- lors d'une création les propriétés
idetinitidsont égales à chaîne vide, - lors d'une révisions la propriété
initidest valuée etidest égale à chaîne vide.
On peut donc reconnaître le cas de la révision de celui de la création initiale en faisant :
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; class MyFamily extends Dcp\Family\Document { public function preCreated() { error_log('initid '.var_export($this->initid, true)); error_log('id '.var_export($this->id, true)); if ($this->initid === "") { error_log("I'm in first creation"); } else { error_log("I'm in creation of a revision"); } } }
Ce qui donne les logs suivants, si l'on créée un document et que l'on révise celui-ci juste après :
- Lors de la création :
initid '' id '' I'm in first creation
- Lors de la révision :
initid '1453' id '' I'm in creation of a revision
13.6.2.1.2 Liste des paramètres
Aucun paramètre.
13.6.2.1.3 Valeur de retour
Message d'erreur. Si la méthode retourne une chaîne de caractères non vide, elle est considérée comme un message d'erreur et la création de document est abandonnée.
Ce message est aussi stocké dans le paramètre de sortie $info->error de la
méthode Doc::store().
13.6.2.1.4 Erreurs / Exceptions
Aucune.
13.6.2.1.5 Historique
Aucun.
13.6.2.1.6 Exemples
Dans la famille MyFamily, la création d'un document ne doit être possible que si la somme des attributs MY_NUMBERONE et MY_NUMBERTWO est inférieur au paramètre MY_MAX de la famille.
Soit la famille suivante :
| BEGIN | Ma famille | MYFAMILY | ||||||
|---|---|---|---|---|---|---|---|---|
| CLASS | My\MyFamily | |||||||
| // | idattr | idframe | label | T | A | type | ord | vis |
| ATTR | MY_IDENTIFICATION | Identification | N | N | frame | 10 | W | |
| ATTR | MY_NUMBERONE | MY_IDENTIFICATION | nombre 1 | Y | N | int | 20 | W |
| ATTR | MY_NUMBERTWO | MY_IDENTIFICATION | nombre 2 | N | N | int | 30 | W |
| PARAM | MY_PARAMETERS | Paramètres | N | N | frame | 10 | W | |
| PARAM | MY_MAX | MY_PARAMETERS | max | N | N | int | 20 | W |
| END |
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; class MyFamily extends \ Dcp\Family\Document { public function preCreated() { $err = parent::preCreated(); $n1 = $this->getAttributeValue(MyAttributes::my_numberone); $n2 = $this->getAttributeValue(MyAttributes::my_numbertwo); $max = $this->getFamilyParameterValue(MyAttributes::my_max); if (($n1 + $n2) > $max) { $err .= ($err ? "\n" : "") . sprintf("Max %d is reached", $max); } return $err; } }
13.6.2.1.7 Notes
En cas de famille héritée, il est nécessaire d'appeler l'hameçon du parent pour disposer des mêmes fonctionnalités.
Cette méthode est appelée par Doc::store() qu'en cas de création
ou de révision tandis que l'hameçon Doc::preStore() est appelé
systématiquement par la méthode Doc::store().
13.6.2.1.8 Voir aussi
13.6.2.2 Doc::postCreated()
Hameçon (ou hook) utilisé par la méthode Doc::store().
Cette méthode est appelée après l'enregistrement en base de données.
13.6.2.2.1 Description
string postCreated ()
Cette méthode est utilisable aussi pour réaliser un post-traitement après une création de document. Elle ne peut pas annuler l'enregistrement. Le document possède un identificateur et est déjà enregistré en base.
Cette méthode est aussi appelée par Doc::revise() lorsque le
document est révisé. Une révision entraîne une création en base de données.
13.6.2.2.1.1 Avertissements
Il ne faut pas appeler la méthode Doc::Store() dans cette méthode
au risque d'avoir une boucle de récursion infinie.
Si des modifications d'attributs sont réalisées dans cette méthode, elles sont
automatiquement enregistrées en base par la méthode Doc::Store().
13.6.2.2.2 Liste des paramètres
Aucun paramètre.
13.6.2.2.3 Valeur de retour
La valeur de retour est un message d'information. Ce message est enregistré dans l'historique du document.
13.6.2.2.4 Erreurs / Exceptions
Aucune.
13.6.2.2.5 Historique
Aucun.
13.6.2.2.6 Exemples
Dans la famille MyFamily, une référence unique est enregistrée lors de la création du document.
Soit la famille suivante :
| BEGIN | Ma famille | MYFAMILY | ||||||
|---|---|---|---|---|---|---|---|---|
| CLASS | My\MyFamily | |||||||
| // | idattr | idframe | label | T | A | type | ord | vis |
| ATTR | MY_IDENTIFICATION | Identification | N | N | frame | 10 | W | |
| ATTR | MY_NUMBERONE | MY_IDENTIFICATION | nombre 1 | Y | N | int | 20 | W |
| ATTR | MY_NUMBERTWO | MY_IDENTIFICATION | nombre 2 | N | N | int | 30 | W |
| ATTR | MY_REF | MY_IDENTIFICATION | Référence | N | N | frame | 10 | R |
| END |
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; class MyFamily extends \Dcp\Family\Document { public function postCreated() { $msg = ''; if ($this->revision == 0) { // création initiale $err = $this->setValue(MyAttributes::my_ref, uniqid('my')); if ($err) { $msg = sprintf("Pas d'identifiant"); } else { $msg = sprintf("Création identifiant %s", $this->getRawValue(MyAttributes::my_ref)); } } return $msg; } }
13.6.2.2.7 Notes
En cas de famille héritée, il est nécessaire d'appeler l'hameçon du parent pour disposer des mêmes fonctionnalités.
Cette méthode est appelée par Doc::store() qu'en cas de création
ou de révision tandis que l'hameçon Doc::postStore() est
appelé systématiquement par la méthode Doc::store().
13.6.2.2.8 Voir aussi
13.6.2.3 Doc::preDelete()
Hameçon (ou hook) utilisé par la méthode Doc::delete().
Cette méthode est appelée avant la suppression du document.
13.6.2.3.1 Description
string preDelete ( )
Cette méthode permet d'ajouter des conditions spécifiques avant la suppression du document.
13.6.2.3.1.1 Avertissements
Cette méthode est appelée après les contrôles de profils pour suppression du document.
13.6.2.3.2 Liste des paramètres
Aucun.
13.6.2.3.3 Valeur de retour
Message d'erreur. Si la méthode retourne une chaîne de caractères non vide, elle est considérée comme un message d'erreur et la suppression est abandonnée.
13.6.2.3.4 Erreurs / Exceptions
Aucune.
13.6.2.3.5 Historique
Aucun.
13.6.2.3.6 Exemple
Cet exemple, interdit la suppression si l'attribut sp_protectionlevel vaut
"top secret".
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; class MyFamily extends Dcp\Family\Document { public function preDelete() { if ($this->getAttributeValue(MyAttributes::sp_protectionlevel) == "top secret")) {} return "Protected document"; // blocage de la suppression } return ''; } }
13.6.2.3.7 Notes
Même le compte "admin" ne peut pas outrepasser les conditions de suppression de cette méthode.
13.6.2.3.8 Voir aussi
13.6.2.4 Doc::postDelete()
Hameçon (ou hook) utilisé par la méthode [Doc::Delete()][Delete].
Cette méthode est appelée après la suppression du document.
13.6.2.4.1 Description
string postDelete ( )
Cette méthode permet de réaliser un post-traitement après suppression du document.
13.6.2.4.1.1 Avertissements
Le document est déjà supprimé lors de l'appel. Dans le cas d'une suppression physique, il n'est plus en base de données.
13.6.2.4.2 Liste des paramètres
Aucun.
13.6.2.4.3 Valeur de retour
Message d'information. Ce message est enregistré dans l'historique du document.
13.6.2.4.4 Erreurs / Exceptions
Aucune.
13.6.2.4.5 Historique
Aucun.
13.6.2.4.6 Exemples
Cet exemple supprime un document lié.
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; class MyFamily extends Dcp\Family\Document { public function postDelete() { $linkedId=$this->getAttributeValue(MyAttributes::sp_linkeddoc); if (linkedId != "")) { $linked=new_doc($this->dbaccess, linkedId); if (linked->isAlive()) { return $linked->delete(); } } return ''; } }
13.6.2.4.7 Notes
Aucune.
13.6.2.4.8 Voir aussi
13.6.2.5 Doc::preDuplicate()
Hameçon (ou hook) utilisé par la méthode Doc::duplicate().
Cette méthode est appelée avant la duplication du document.
13.6.2.5.1 Description
string preDuplicate ( Doc &$origin )
Cette méthode permet d'ajouter des conditions spécifiques avant la duplication du document.
13.6.2.5.1.1 Avertissements
Cette méthode est appelée sur le document en cours de duplication. Son identificateur est vide, il n'est pas encore enregistré en base de donnée. Le document contient les valeurs des attributs du document d'origine.
13.6.2.5.2 Liste des paramètres
- (Doc)
origin - Document d'origine de la duplication.
13.6.2.5.3 Valeur de retour
Message d'erreur. Si la méthode retourne une chaîne de caractères non vide, elle est considérée comme un message d'erreur et la duplication est abandonnée.
Ce message est retourné par la méthode Doc::duplicate() si elle
est non vide.
13.6.2.5.4 Erreurs / Exceptions
Aucune.
13.6.2.5.5 Historique
Anciennement Doc::preCopy().
13.6.2.5.6 Exemples
Cet exemple, interdit la duplication d'un document révisé.
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; class MyFamily extends Dcp\Family\Document { public function preDuplicate(Doc &$origin) { if ($origin->isFixed()) return "Fixed document - not duplicated"; } return ''; } }
13.6.2.5.7 Notes
Même le compte "admin" ne peut pas outrepasser les conditions de duplication de cette méthode.
Le menu de duplication n'est pas accessible si cette méthode retourne un message d'erreur.
13.6.2.5.8 Voir aussi
13.6.2.6 Doc::postDuplicate()
Hameçon (ou hook) utilisé par la méthode Doc::duplicate().
Cette méthode est appelée après la duplication du document.
13.6.2.6.1 Description
string postDuplicate ( Doc &$origin )
Cette méthode permet de réaliser un post-traitement après la duplication du document.
13.6.2.6.1.1 Avertissements
Cette méthode est appelée sur le document en cours de duplication.
Le document vient d'être enregistré en base de donnée et contient un nouvel identificateur.
13.6.2.6.2 Liste des paramètres
- (Doc)
origin - Document d'origine de la duplication.
13.6.2.6.3 Valeur de retour
Message d'information. Ce message est enregistré dans l'historique du document.
13.6.2.6.4 Erreurs / Exceptions
Aucune.
13.6.2.6.5 Historique
Anciennement Doc::postCopy().
13.6.2.6.6 Exemple
Cet exemple, mémorise l'auteur de la duplication et ajoute une entrée dans l'historique du document originel.
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; class MyFamily extends Dcp\Family\Document { public function postDuplicate(Doc &$origin) { $origin->addHistoryEntry("duplicated target %d", $this->initid); $this->setAttributeValue(MyAttributes::sp_duplicateby, $this->getUserId()); $this->store(); return ''; } }
13.6.2.6.7 Notes
Aucune.
13.6.2.6.8 Voir aussi
13.6.2.7 Doc::preStore()
Hameçon (ou hook) utilisé par la méthode Doc::Store().
Elle est appelée avant l'enregistrement en base de données. Cette méthode doit
vérifier si les conditions de modification de document sont valides.
13.6.2.7.1 Description
string preStore ()
Si cette méthode retourne un message d'erreur alors la modification est
abandonnée et la méthode Doc::Store() retourne le message fourni
par cette méthode afin d'indiquer l'échec.
13.6.2.7.1.1 Avertissements
Le document n'a pas encore d'identificateur lors d'une création. Cette méthode n'est pas appelée lors d'une révision.
13.6.2.7.2 Liste des paramètres
Aucun paramètre.
13.6.2.7.3 Valeur de retour
Message d'erreur. Si la méthode retourne une chaîne de caractères non vide, elle est considérée comme un message d'erreur et la création de document est abandonnée.
Ce message est aussi stocké dans le paramètre de sortie $info->preStore de la
méthode Doc::Store().
13.6.2.7.4 Erreurs / Exceptions
Aucune.
13.6.2.7.5 Historique
Aucun.
13.6.2.7.6 Exemples
Dans la famille MyFamily, la modification d'un document ne doit être possible que si la somme des attributs MY_NUMBERONE et MY_NUMBERTWO est inférieure au paramètre MY_MAX de la famille.
Soit la famille suivante :
| BEGIN | Ma famille | MYFAMILY | ||||||
|---|---|---|---|---|---|---|---|---|
| CLASS | My\MyFamily | |||||||
| // | idattr | idframe | label | T | A | type | ord | vis |
| ATTR | MY_IDENTIFICATION | Identification | N | N | frame | 10 | W | |
| ATTR | MY_NUMBERONE | MY_IDENTIFICATION | nombre 1 | Y | N | int | 20 | W |
| ATTR | MY_NUMBERTWO | MY_IDENTIFICATION | nombre 2 | N | N | int | 30 | W |
| PARAM | MY_PARAMETERS | Paramètres | N | N | frame | 10 | W | |
| PARAM | MY_MAX | MY_PARAMETERS | max | N | N | int | 20 | W |
| END |
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; class MyFamily extends \Dcp\Family\Document { public function preStore() { $err = ''; $n1 = $this->getAttributeValue(MyAttributes::my_numberone); $n2 = $this->getAttributeValue(MyAttributes::my_numbertwo); $max = $this->getFamilyParameterValue(MyAttributes::my_max); if (($n1 + $n2) > $max) { $err = sprintf("Max %d is reached", $max); } return $err; } }
13.6.2.7.7 Notes
En cas de famille héritée, il est nécessaire d'appeler l'hameçon du parent pour disposer des mêmes fonctionnalités.
Cette méthode est appelée par Doc::store en cas de création, de
révision et de modification tandis que l'hameçon
Doc::preCreated() est appelé qu'en cas de création ou de
révision.
13.6.2.7.8 Voir aussi
13.6.2.8 Doc::postStore()
Hameçon (ou hook) utilisé par la méthode Doc::Store().
Cette méthode est appelée après l'enregistrement en base de données.
13.6.2.8.1 Description
string postStore ()
Cette méthode est aussi utilisable pour réaliser un post-traitement après une modification. Elle ne peut pas annuler l'enregistrement. Le document possède un identificateur et est déjà enregistré en base.
13.6.2.8.1.1 Avertissements
Il ne faut pas appeler la méthode Doc::Store() dans cette méthode
au risque d'avoir une boucle de récursion infinie.
Si des modifications d'attributs sont réalisées dans cette méthode, elles sont
enregistrées en base par la méthode Doc::Store().
13.6.2.8.2 Liste des paramètres
Aucun paramètre.
13.6.2.8.3 Valeur de retour
La valeur de retour est un message d'information. Il est stocké dans le
paramètre de sortie $info->postStore de la méthode Doc::Store().
13.6.2.8.4 Erreurs / Exceptions
Aucun.
13.6.2.8.5 Historique
Anciennement nommée postModify().
13.6.2.8.6 Exemples
Calcul de la somme des attributs my_numberone et my_numbertwo et
enregistrement dans l'attribut my_sum.
Soit la famille suivante :
| BEGIN | Ma famille | MYFAMILY | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| CLASS | My\MyFamily | ||||||||||
| // | idattr | idframe | label | T | A | type | ord | vis | … | phpfunc | |
| ATTR | MY_IDENTIFICATION | Identification | N | N | frame | 10 | W | ||||
| ATTR | MY_NUMBERONE | MY_IDENTIFICATION | nombre 1 | Y | N | int | 20 | W | |||
| ATTR | MY_NUMBERTWO | MY_IDENTIFICATION | nombre 2 | N | N | int | 30 | W | |||
| ATTR | MY_SUM | MY_IDENTIFICATION | nombre 1+2 | N | N | int | 30 | R | |||
| END |
Avec la classe :
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; class MyFamily extends \Dcp\Family\Document { public function mySum($x, $y) { return ($x + $y); } public function postStore() { $err=parent::postStore(); if (empty($err)) { $n1 = $this->getAttributeValue(MyAttributes::my_numberone); $n2 = $this->getAttributeValue(MyAttributes::my_numbertwo); $this->setAttributeValue(MyAttributes::my_sum, $this->mySum($n1, $n2)); } return $err; }
13.6.2.8.7 Notes
En cas de famille héritée, il est nécessaire d'appeler l'hameçon du parent pour disposer des mêmes fonctionnalités.
Cette méthode est appelée par Doc::store() en cas de création, de
révision et de modification tandis que l'hameçon
Doc::postCreated() est appelé qu'en cas de création ou de
révision.
13.6.2.8.8 Voir aussi
13.6.2.9 Doc::getCustomSearchValues()
Hameçon (ou hook) utilisé par la méthode Doc::Store().
Cette méthode permet d'ajouter des informations supplémentaires pour la recherche globale.
Les valeurs stockées dans les colonnes svalues et fulltext sont les
données brutes des attributs recherchables (option
searchcriteria).
3.2.21Les valeurs affichées des attributs sont aussi enregistrées. Pour une relation l'identifiant sera stocké ainsi que son titre, pour la date le format iso sera enregistré ainsi que le format dans les locales définies, le nom du jour et le nom du mois dans les différentes traductions disponibles et les nombres composant la date. Pour les énumérés la clef ainsi que les traductions des labels sont enregistrés.
13.6.2.9.1 Description
protected function string[] getCustomSearchValues ()
Cette méthode doit retourner un tableau de chaîne de caractères contenant des mots supplémentaires. Ces mots servent à retrouver le document en utilisant la recherche globale.
13.6.2.9.1.1 Avertissements
Ce hook n'est pas déclenché pour les documents temporaire. Ce hook est déclenché
par la méthode store en cas de création. En cas de modification,
il est déclenché uniquement si une valeur d'attribut a changé.
13.6.2.9.2 Liste des paramètres
Aucun.
13.6.2.9.3 Valeur de retour
Un tableau contenant les chaînes contenant les mots à ajouter.
13.6.2.9.4 Erreurs / Exceptions
Aucune.
13.6.2.9.5 Historique
Aucun.
13.6.2.9.6 Exemples
Dans la famille MyFamily, Un administrateur modifie le code du jour chaque jour. Ce message doit être enregistré dans les valeurs recherchables afin de réaliser des recherches par code. Le code étant enregistrés à chaque modification.
Soit la famille suivante :
| BEGIN | Ma famille | MYFAMILY | ||||||
|---|---|---|---|---|---|---|---|---|
| CLASS | My\MyFamily | |||||||
| // | idattr | idframe | label | T | A | type | ord | vis |
| ATTR | MY_IDENTIFICATION | Identification | N | N | frame | 10 | W | |
| ATTR | MY_RELATION | MY_IDENTIFICATION | Relation | Y | N | docid("MYFAMILY") | 20 | W |
| ATTR | MY_DATE | MY_IDENTIFICATION | Date | N | N | date | 30 | W |
| PARAM | MY_PARAMETERS | Paramètres | N | N | frame | 10 | W | |
| PARAM | MY_CODE | MY_PARAMETERS | Code du jour | N | N | text | 20 | W |
| END |
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; class MyFamily extends \Dcp\Family\Document { protected function getCustomSearchValues() { $customValues=parent::customSearchValue(); $customValues[]=$this->getFamilyParameterValue(MyAttributes::my_code); return $customValues; } }
Si my_relation="1234" (titre="Mon document lié"), my_date="2016-04-21", my_code="ATY67"
Alors les valeurs recherchables contiendront :
- 1234
- Mon document lié
- 2016-04-21
- 21/04/2016
- 21
- 04
- 2016
- 04/21/2016
- avril
- april
- jeudi
- thursday
- ATY67
13.6.2.9.7 Notes
En cas de famille héritée, il est nécessaire d'appeler l'hameçon du parent pour conserver les éventuelles valeurs ajoutées par les familles mères..
13.6.2.9.8 Voir aussi
13.6.2.10 Doc::preRefresh()
Hameçon (ou hook) utilisé par la méthode Doc::refresh().
13.6.2.10.1 Description
string preRefresh ()
Cette méthode est appelée par la méthode Doc::refresh()
avant la mise à jour des attributs calculés.
13.6.2.10.1.1 Avertissements
Les contrôles relatifs au droit de modification sont désactivés pendant l'appel
de cette méthode. Ceci permet à la méthode Doc::setValue() de
ne pas vérifier les droits de modification.
13.6.2.10.2 Liste des paramètres
Aucun.
13.6.2.10.3 Valeur de retour
Cette méthode doit retourner une chaîne de caractères. Ce message est retourné
par la méthode Doc::refresh().
13.6.2.10.4 Erreurs / Exceptions
Aucun.
13.6.2.10.5 Historique
Aucun.
13.6.2.10.6 Exemples
Récupération de l'adresse mail du rédacteur et mise à jour. Si l'adresse est différente un message est retourné.
Soit la famille suivante :
| BEGIN | Ma famille | MYFAMILY | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| CLASS | My\MyFamily | ||||||||||
| // | idattr | idframe | label | T | A | type | ord | vis | … | phpfunc | |
| ATTR | MY_IDENTIFICATION | Identification | N | N | frame | 10 | W | ||||
| ATTR | MY_REDACTOR | MY_IDENTIFICATION | rédacteur | N | N | account | 30 | W | ::mySum(MY_NUMBERONE, MY_NUMBERTWO) | ||
| ATTR | MY_MAIL | MY_IDENTIFICATION | Adresse courriel | N | N | text | 10 | R | |||
| END |
Avec la classe :
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; use \Dcp\AttributeIdentifiers\Iuser as Aiuser; class MyFamily extends \Dcp\Family\Document { public function preRefresh() { $msg = ''; $redactorId = $this->getRawValue(MyAttributes::my_redactor); if ($redactorId) { $du = new_doc($this->dbaccess, $redactorId); if ($du->isAlive()) { $redactorMail=$du->getRawValue(Aiuser::us_mail); if ($redactorMail != $this->getRawValue(MyAttributes::my_mail)) { $err=$this->setValue(MyAttributes::my_mail, $du->getRawValue(Aiuser::us_mail)); if (empty($err)) { $msg=sprintf("L'adresse du rédacteur a été changée.\nNouvelle adresse : %s", $redactorMail); } else { $msg=sprintf("Erreur d'affectation : %s", $err); } } } } else { $this->clearValue(MyAttributes::my_mail); } return $msg; } }
13.6.2.10.7 Notes
En cas de famille héritée, il est nécessaire d'appeler l'hameçon du parent pour disposer des mêmes fonctionnalités.
13.6.2.10.8 Voir aussi
13.6.2.11 Doc::postRefresh()
Hameçon (ou hook) utilisé par la méthode Doc::refresh().
13.6.2.11.1 Description
string postRefresh ()
Cette méthode est appelée par la méthode Doc::refresh()
après la mise à jour des attributs calculés.
13.6.2.11.1.1 Avertissements
Les contrôles relatifs au droit de modification sont désactivés pendant l'appel
de cette méthode. Ceci permet à la méthode Doc::setValue() de
ne pas vérifier les droits de modification.
13.6.2.11.2 Liste des paramètres
Aucun.
13.6.2.11.3 Valeur de retour
Cette méthode doit retourner un message. Ce message est retourné par la méthode
Doc::refresh().
13.6.2.11.4 Erreurs / Exceptions
Aucun.
13.6.2.11.5 Historique
Cette méthode était anciennement nommée specRefresh().
13.6.2.11.6 Exemples
Affichage d'un message si l'attribut calculé my_sum est supérieur au paramètre
my_max. Dans ce cas l'attribut my_sum est mis à jour juste avant l'appel à
l'hameçon postRefresh().
Soit la famille suivante :
| BEGIN | Ma famille | MYFAMILY | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| CLASS | My\MyFamily | ||||||||||
| // | idattr | idframe | label | T | A | type | ord | vis | … | phpfunc | |
| ATTR | MY_IDENTIFICATION | Identification | N | N | frame | 10 | W | ||||
| ATTR | MY_NUMBERONE | MY_IDENTIFICATION | nombre 1 | Y | N | int | 20 | W | |||
| ATTR | MY_NUMBERTWO | MY_IDENTIFICATION | nombre 2 | N | N | int | 30 | W | |||
| ATTR | MY_SUM | MY_IDENTIFICATION | nombre 1+2 | N | N | int | 30 | R | ::mySum(MY_NUMBERONE, MY_NUMBERTWO) | ||
| PARAM | MY_PARAMETERS | Paramètres | N | N | frame | 10 | W | ||||
| PARAM | MY_MAX | MY_PARAMETERS | max | N | N | int | 20 | W | |||
| END |
Avec la classe :
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; class MyFamily extends \Dcp\Family\Document { public function mySum($x, $y) { return ($x + $y); } public function postRefresh() { $msg = ''; $sum = $this->getAttributeValue(MyAttributes::my_sum); $max = $this->getFamilyParameterValue(MyAttributes::my_max); if ($sum > $max) { $msg = sprintf("Max %d is reached", $max); } return $msg; } }
13.6.2.11.7 Notes
En cas de famille héritée, il est nécessaire d'appeler l'hameçon du parent pour disposer des mêmes fonctionnalités.
13.6.2.11.8 Voir aussi
13.6.2.12 Doc::preAffect()
3.2.20
Hameçon (ou hook) utilisée par la fonction new_doc() et pour
toute fonction qui récupère les données d'un document en base de données afin de
les affecter à l'objet comme par exemple lors de recherche de
document.
13.6.2.12.1 Description
void protected function preAffect (array &$data, bool &$more , bool &$reset )
Cette permet de contrôler l'affectation des données avant leur affectation dans l'objet. Au moment de l'appel, l'objet document contient les valeurs affectées du précédent document.
Cette méthode ne peut pas empêcher l'affectation mais peux modifier les données affectées.
13.6.2.12.1.1 Avertissements
Cette méthode est appelée pour toute affectation d'objet documentaire. Elle est appelée principalement par les fonctions de récupération de document et de recherche mais aussi par les méthode de révision et de changement d'état.
Cette méthode étant bas-niveau, les tests et traitement définis dans cette fonction peuvent pénaliser les temps de traitement.
Lors d'une recherche, cette méthode est appelée pour chacun des document trouvés si l'option de retour précise le retour d'objet. Dans le cas de retour brut, cette méthode n'est pas appelée car il n'y a pas de création d'objet.
13.6.2.12.2 Liste des paramètres
- (array)
data -
Contient les valeurs qui seront affectées à l'objet. Le tableau est indexé par les noms des attributs et propriétés du document.
Ces valeurs peuvent être modifiées. Le tableau "data" sert ensuite lors de l'affectation.
Les valeurs indexées "values" et "attrids" contiennent aussi l'ensemble des attributs sous une forme sérialisée.
- (bool)
more -
Indique que si les données fournies par le paramètre
datasont incomplètes, alors les données manquantes sont récupérées depuis l'index "values" (s'il existe) fourni dans ce même paramètredata.
Il est possible de modifier ce paramètre afin de forcer ou inhiber ce fonctionnement.Note: Dans le cas d'une recherche ce paramètre est mis à
true - (bool)
reset -
Indique que toutes les données de la précédente affectation seront effacées Cela concerne les propriétés et les attributs mais aussi les variables privées. Il est possible de modifier ce paramètre afin de forcer ou inhiber le
reset.Note: Dans le cas d'une recherche ce paramètre est mis à
true
13.6.2.12.3 Valeur de retour
Aucune.
13.6.2.12.4 Erreurs / Exceptions
Aucune.
13.6.2.12.5 Historique
Aucun.
13.6.2.12.6 Exemples
Forcer l'affectation d'un attribut suivant une certaine condition. Si aucun
message d'avertissement (my_warning) n'est indiqué et le niveau (my_order)
est supérieur à 10 alors on indique un message par défaut.
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; class MyFamily extends Dcp\Family\Document { protected function preAffect(array &$data, &$more, &$reset) { if (!$data[MyAttributes::my_warning]) { if ($data[MyAttributes::my_order] > 20 ) { $data[MyAttributes::my_warning]="Emergency level priority"; } elseif ($data[MyAttributes::my_order] > 10 ) { $data[MyAttributes::my_warning]="High level priority"; } } } }
En cas d'affichage de rapport ou de document, l'attribut my_warning
sera affiché suivant l'ordre my_order. Par contre, cela ne constitue pas une
affectation en base de donnée sauf si l'affectation est suivie d'une
sauvegarde.
13.6.2.12.7 Notes
Cette méthode n'est pas appelée si aucune donnée n'est fournie dans le tableau
data.
13.6.2.12.8 Voir aussi
13.6.2.13 Doc::postAffect()
3.2.20
Hameçon (ou hook) utilisée par la fonction new_doc() et pour
toute fonction qui récupère les données d'un document en base de données afin de
les affecter à l'objet comme par exemple lors de recherche de
document.
13.6.2.13.1 Description
void protected function postAffect (array $data, bool $more , bool $reset )
Cette méthode permet de réaliser un traitement sur le document après affectation. Au moment de l'appel, le document est initialisé avec les données founies par l'argument "data".
13.6.2.13.1.1 Avertissements
Voir avertissement preAffect().
13.6.2.13.2 Liste des paramètres
- (array)
data -
Contient les valeurs qui ont été affectées à l'objet. Le tableau est indexé par les noms des attributs et propriétés du document.
Les valeurs indexées "values" et "attrids" contiennent aussi l'ensemble des attributs sous une forme sérialisée.
- (bool)
more -
Indique que si les données fournies par le paramètre
dataétaient incomplètes, alors les données manquantes ont été récupérées depuis l'index "values" (s'il existe) fourni dans ce même paramètredata.Note: Dans le cas d'une recherche ce paramètre est mis à
true - (bool)
reset -
Indique que toutes les données de la précédente affectation ont été effacées Cela concerne les propriétés et les attributs mais aussi les variables privées.
Note: Dans le cas d'une recherche ce paramètre est mis à
true
13.6.2.13.3 Valeur de retour
Aucune.
13.6.2.13.4 Erreurs / Exceptions
Aucune.
13.6.2.13.5 Historique
Aucun.
13.6.2.13.6 Exemples
Réinitialisation d'une variable privée en cas de réaffectation.
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; class MyFamily extends Dcp\Family\Document { const MYINIT=4; private $myPrivate=self::MYINIT; protected function postAffect(array $data, $more, $reset) { if ($reset) { $this->myPrivate=self::MYINIT; } } }
13.6.2.13.7 Notes
Cette méthode n'est pas appelée si aucune donnée n'est fournie dans le tableau
data.
13.6.2.13.8 Voir aussi
13.6.2.14 Doc::preImport()
Hameçon (ou hook) utilisé par la méthode
ImportSingleDocument::import(). Cette méthode est
appelée avant l'enregistrement en base de données d'un document lors d'une
importation.
Cette méthode n'est pas utilisée pour les importations de familles de document.
13.6.2.14.1 Description
string preImport ( array $extra = array() )
Cette méthode permet d'ajouter une condition spécifique d'importation ou de réaliser un pré-traitement avant l'enregistrement.
Au moment de l'appel, le document contient les nouvelles valeurs indiquées dans le fichiers d'importation mais elles ne sont pas encore enregistrées en base de données.
13.6.2.14.1.1 Avertissements
Cette méthode est appelée qu'il s'agisse d'une création ou d'une mise à jour. Dans le cas d'une création, le document n'a pas encore d'identificateur.
La méthode Doc::store() ne doit pas être appelée depuis cette
méthode de manière explicite pour enregistrer les éventuelles modifications.
Dans le cas d'une création, cela provoquerait une création prématurée en base de
données.
13.6.2.14.2 Liste des paramètres
- (array)
extra -
Contient les valeurs supplémentaires indiquées dans le fichier d'importation. Ces paramètres supplémentaires peuvent servir à réaliser le pré- traitement.
13.6.2.14.3 Valeur de retour
Message d'erreur. Si la méthode retourne une chaîne de caractères non vide, elle est considérée comme un message d'erreur et l'importation du document est abandonnée.
13.6.2.14.4 Erreurs / Exceptions
Aucune.
13.6.2.14.5 Historique
Aucun.
13.6.2.14.6 Exemples
Soit la ligne d'importation suivante :
| ORDER | ZOO_SPECIES | spec id | folder id | sp_latinname | extra:status | extra:special |
|---|---|---|---|---|---|---|
| DOC | ZOO_SPECIES | MY_MAMMUTH | - | Mammuthus | disappeared | protected |
Dans cette exemple, le document Mammuthus de la famille ZOO_SPECIES aura
comme paramètre passé à preImport :
array( 'status' => 'disappeared', 'special' => 'protected' );
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; class MyFamily extends Dcp\Family\Document { public function preImport(array $extra=array()) { // ajout d'une condition d'importation if ($this->getRawValue(MyAttributes::sp_latinname) == '') { return _("Latin name must not be empty"); } // modification d'attribut en fonction des extra if (isset($extra["status"]) && $extra["status"]=="alive") { $this->clearValue(MyAttributes::sp_deathdate); } if (isset($extra["special"]) && $extra["special"]=="protected") { $this->setAttributeValue(MyAttributes::sp_protectionlevel, "2"); } return ''; } }
13.6.2.14.7 Notes
Dans le cas d'une modification de document, la méthode
Doc::getOldRawValue() peut être utilisée pour avoir la valeur
originelle d'un attribut.
13.6.2.14.8 Voir aussi
13.6.2.15 Doc::postImport()
[Hameçon][hook] (ou hook) utilisé par la méthode
ImportSingleDocument::import(). Cette méthode est
appelée après l'enregistrement en base de données d'un document lors d'une
importation.
Cette méthode n'est pas utilisée pour les importations de familles de document.
13.6.2.15.1 Description
string postImport ( array $extra = array() )
Cette méthode permet de réaliser un post-traitement après l'enregistrement.
13.6.2.15.1.1 Avertissements
Cette méthode est appelée qu'il s'agisse d'une création ou d'une mise à jour.
La méthode Doc::store() doit être appelée depuis cette
méthode si des attributs ont été modifiées par cette méthode.
13.6.2.15.2 Liste des paramètres
- (array)
extra -
Contient les valeurs supplémentaires indiquées dans le fichier d'importation. Ces paramètres supplémentaires peuvent servir à réaliser le post-traitement.
13.6.2.15.3 Valeur de retour
Message d'information. Ce message est indiqué dans le rapport d'importation.
13.6.2.15.4 Erreurs / Exceptions
Aucunes.
13.6.2.15.5 Historique
Aucun.
13.6.2.15.6 Exemples
Soit la ligne d'importation suivante :
| ORDER | ZOO_SPECIES | spec id | folder id | sp_latinname | extra:status | extra:special |
|---|---|---|---|---|---|---|
| DOC | ZOO_SPECIES | MY_MAMMUTH | - | Mammuthus | disappeared | protected |
Dans cette exemple, le document Mammuthus de la famille ZOO_SPECIES a
comme paramètre passé à postImport :
array( 'status' => 'disappeared', 'special' => 'protected' );
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; class MyFamily extends Dcp\Family\Document { public function postImport(array $extra=array()) { if (isset($extra["special"]) && $extra["special"]=="protected") { $this->setAttributeValue(MyAttributes::sp_protectionlevel, "2"); return $this->store(); // l'enregistrement en base doit être effectué // pour prendre en compte la modification } return ''; } }
13.6.2.15.7 Notes
Il est possible d'utiliser des attributs de classes (privées ou publiques) pour
partager des informations entre preImport() et postImport().
13.6.2.15.8 Voir aussi
13.6.2.16 Doc::preUndelete()
Hameçon (ou hook) utilisé par la méthode Doc::undelete().
Cette méthode est appelée avant la restauration du document.
13.6.2.16.1 Description
string preUndelete ( )
Cette méthode permet de contrôler la restauration d'un document.
13.6.2.16.1.1 Avertissements
Cette méthode est appelée après les contrôles de profils pour suppression du document.
Le document est encore en statut supprimé (locked=-1 et doctype=Z).
13.6.2.16.2 Liste des paramètres
Aucun.
13.6.2.16.3 Valeur de retour
Message d'erreur. Si la méthode retourne une chaîne de caractères non vide, elle est considérée comme un message d'erreur et la restauration est abandonnée.
Ce message est retourné par la méthode Doc::undelete() si elle
est non vide.
13.6.2.16.4 Erreurs / Exceptions
Aucune.
13.6.2.16.5 Historique
Anciennement preRevive().
13.6.2.16.6 Exemples
Cet exemple, interdit la suppression si l'attribut sp_protectionlevel vaut
"archived".
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; class MyFamily extends Dcp\Family\Document { public function preUndelete() { if ($this->getAttributeValue(MyAttributes::sp_protectionlevel) == "archived")) {} return "Archive document"; // blocage de la restauration } return ''; } }
13.6.2.16.7 Notes
Même le compte "admin" ne peut pas outrepasser les conditions de restauration de cette méthode.
Le menu de restauration n'est pas accessible si cette méthode retourne un message d'erreur.
13.6.2.16.8 Voir aussi
13.6.2.17 Doc::postUndelete()
Hameçon (ou hook) utilisé par la méthode Doc::undelete().
Cette méthode est appelée après la restauration du document.
13.6.2.17.1 Description
string postUndelete ( )
Cette méthode permet de réaliser un post-traitement après restauration du document.
13.6.2.17.1.1 Avertissements
Le document est de nouveau vivant.
13.6.2.17.2 Liste des paramètres
Aucun.
13.6.2.17.3 Valeur de retour
Message d'information. Ce message est affiché à l'utilisateur lorsqu'il réalise une restauration depuis l'interface web. Ce message est aussi enregistré dans l'historique du document.
13.6.2.17.4 Erreurs / Exceptions
Aucune.
13.6.2.17.5 Historique
Anciennement postRevive().
13.6.2.17.6 Exemples
Cet exemple, mémorise l'auteur de la restauration si l'attribut
sp_protectionlevel vaut "low".
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; class MyFamily extends Dcp\Family\Document { public function postUndelete() { if ($this->getAttributeValue(MyAttributes::sp_protectionlevel) == "low")) { $this->setAttributeValue(MyAttributes::sp_restoreby, $this->getUserId()); $this->store(); return "Low restauration"; } return ''; } }
13.6.2.17.7 Notes
Aucune.
13.6.2.17.8 Voir aussi
13.6.2.18 Doc::preConsultation()
Hameçon (ou hook) utilisé par l'action de consultation html du document
FDL:OPENDOC. Elle est appelée avant la composition du template.
13.6.2.18.1 Description
string preConsultation ( )
Cette méthode permet de réaliser des opérations afin d'ajuster l'affichage du document. Ces opérations peuvent être :
- ajout d'un fichier javascript ou css,
- modification des visibilités d'attributs,
- modification d'une propriété d'attributs,
- etc.
13.6.2.18.1.1 Avertissements
À la différence de Doc::preRefresh() qui est appelé lors de
consultation et lors de l'édition, cette méthode n'est appelée que lors de la
consultation. Elle est appelée après la méthode Doc::refresh().
Cette méthode n'est pas déclenchée lors de l'affichage de liste de documents.
13.6.2.18.2 Liste des paramètres
Aucun.
13.6.2.18.3 Valeur de retour
string : message d'information.
Ce message est affiché sur le document comme pour celui de la méthode
Doc::preRefresh().
13.6.2.18.4 Erreurs / Exceptions
Aucune.
13.6.2.18.5 Historique
Aucun.
13.6.2.18.6 Exemples
13.6.2.18.6.1 Ajout d'asset ccs et js
Cas d'une famille MyFamily qui possède un niveau d'urgence représenté par
l'attribut my_level.
Ajout d'un fichier css et d'un fichier javascript dans le cas ou
le niveau my_level du document est supérieur à 2.
class MyFamily extends \Dcp\Family\Document { public function preConsultation() { if ($this->getAttributeValue(\Dcp\AttributeIdentifiers\MyFamily::my_level) > 2) { global $action; $action->parent->addJsRef("MYAPP/Layout/mySpecial.js"); $action->parent->addCssRef("MYAPP/Layout/mySpecial.css"); if ($this->getAttributeValue(\Dcp\AttributeIdentifiers\MyFamily::my_level) > 10) { $action->parent->addCssRef("MYAPP/Layout/myRedAlert.css"); addWarningMsg("Red Alert"); } } return ''; }
Si le niveau est supérieur à 10 alors une deuxième css est ajouté ainsi qu'un message d'avertissement qui sera visible lors de la consultation.
Voir addjsRef et addCssRef pour l'ajout d'asset.
13.6.2.18.6.2 Modification de visibilité
Masquage d'un attribut my_informations si niveau my_level est égal à 0.
class MyFamily extends \Dcp\Family\Document { public function preConsultation() { if ($this->getAttributeValue(\Dcp\AttributeIdentifiers\MyFamily::my_level) == 0) { // l'attribut my_information est caché $myAttribute=$this->getAttribute(\Dcp\AttributeIdentifiers\MyFamily::my_information); $myAttribute->setVisibility('H'); } return ''; }
Attention : La méthode BasicAttribute::setVisibility() ne propage pas la
visibilité dans le cas où l'attribut est un attribut de structure (array,
frame ou tab).
13.6.2.18.7 Notes
Aucune.
13.6.2.18.8 Voir aussi
13.6.2.19 Doc::preEdition()
[Hameçon]hook] (ou hook) utilisé par l'action d'affichage du formulaire html du
document FDL:OPENDOC. Elle est appelée avant la composition du
template.
13.6.2.19.1 Description
void preEdition ( )
Cette méthode permet de réaliser des opérations afin d'ajuster l'affichage du formulaire de document. Ces opérations peuvent être :
- ajout d'un fichier javascript ou css,
- modification des visibilités d'attributs,
- modification d'une propriété d'attributs,
- etc.
13.6.2.19.1.1 Avertissements
À la différence de Doc::preRefresh() qui est appelé lors de
consultation et lors de l'édition, cette méthode n'est appelée que lors de
l'édition.
13.6.2.19.2 Valeur de retour
Aucune.
13.6.2.19.3 Erreurs / Exceptions
Aucune.
13.6.2.19.4 Historique
Aucun.
13.6.2.19.5 Exemples
13.6.2.19.5.1 Ajout d'asset ccs et js
Ajout d'une css et d'un fichier JavaScript spécifique si c'est un formulaire de
création de document.
class MyFamily extends \Dcp\Family\Document { public function preEdition() { if ($this->getProperty("initid") == 0) { global $action; $action->parent->addJsRef("MYAPP/Layout/mySpecialCreate.js"); $action->parent->addCssRef("MYAPP/Layout/mySpecialCreate.css"); } }
Voir addjsRef et addCssRef pour l'ajout d'asset.
13.6.2.19.5.2 Modification de visibilité et caractère obligatoire
Rendre obligatoire l'attribut my_level à la création.
class MyFamily extends \Dcp\Family\Document { public function preEdition() { if ($this->getProperty("initid") == 0) { $myAttribute=$this->getAttribute(\Dcp\AttributeIdentifiers\MyFamily::my_level); $myAttribute->setVisibility('W'); $myAttribute->setNeeded(true); } }
Attention, cela impacte juste le formulaire et non la caractère réellement obligatoire de l'attribut. Ce caractère obligatoire peut aussi être maîtrisé par les contrôles de vue.
13.6.2.19.6 Notes
Aucune.
13.6.2.19.7 Voir aussi
13.6.3 Méthodes de la classe Doc
Ce chapitre décrit les méthodes de manipulation de documents.
13.6.3.1 Doc::addArrayRow()
La méthode addArrayRow permet d'ajouter, ou d'insérer, une ligne dans un
attribut de type array.
13.6.3.1.1 Description
string addArrayRow ( string $idAttr, array $tv, int $index = -1 )
La méthode addArrayRow permet d'ajouter, ou d'insérer à un indice donné, une
ligne dans un attribut de type array.
La ligne insérée entraîne un décalage des lignes d'indice supérieur, qui montent alors toutes d'un cran.
13.6.3.1.1.1 Avertissements
Lors de chaque appel à addArrayRow, un setValue est effectué pour chacune des
colonnes de l'array. Pour ajouter de nombreuses lignes, il peut être plus
efficace de gérer manuellement l'ajout dans chaque colonne.
13.6.3.1.2 Liste des paramètres
- (string)
idAttr - Le nom de l'attribut de type
arrayauquel on souhaite ajouter, ou insérer, une ligne. - (array)
tv - Un tableau associatif dont la clef est le nom d'un attribut colonne du array, et la valeur est la valeur a affecter à cette colonne.
- (int)
index -
indexpermet de spécifier l'indice (à partir de 0) où insérer la ligne dans le tableau.Si
indexvaut0, alors la ligne est insérée au début du tableau. Siindexvaut -1 ou est supérieur ou égal au nombre de lignes du tableau, la ligne est alors ajoutée à la fin du tableau.
13.6.3.1.3 Valeur de retour
La méthode retourne une chaîne vide s'il n'y a pas d'erreur, ou une chaîne non-vide contenant le message d'erreur dans le cas contraire.
13.6.3.1.4 Erreurs / Exceptions
Une erreur est retournée si :
- l'attribut
idAttrn'est pas de typearray; - la valeur
tvn'est pas un array PHP ; - une clef de
tvn'est pas le nom d'un attribut attaché à l'attributidAttr.
13.6.3.1.5 Historique
Aucun.
13.6.3.1.6 Exemples
Soit un attribut faces de type array auquel sont rattachés les attributs
face_firstname et face_lastname de type text.
-
Exemple #1
/* * Vide le tableau */ $photo->clearArrayValues(\Dcp\AttributeIdentifier\MyPhoto::faces); /* * Ajoute une ligne */ $row = array( \Dcp\AttributeIdentifiers\MyPhoto::face_firstname => 'Marge', \Dcp\AttributeIdentifiers\MyPhoto::face_lastname => 'Simpson' ); $photo->addArrayRow(\Dcp\AttributeIdentifier\MyPhoto::faces, $row); /* * Ajoute une autre ligne */ $row = array( \Dcp\AttributeIdentifiers\MyPhoto::face_firstname => 'Homer', \Dcp\AttributeIdentifiers\MyPhoto::face_lastname => 'Simpson' ); $photo->addArrayRow(\Dcp\AttributeIdentifier\MyPhoto::faces, $row); /* * Insère une ligne entre Marge et Homer */ $row = array( \Dcp\AttributeIdentifiers\MyPhoto::face_firstname => 'Lisa', \Dcp\AttributeIdentifiers\MyPhoto::face_lastname => 'Simpson' ) $photo->addArrayRow(\Dcp\AttributeIdentifier\MyPhoto::faces, $row, 1); /* * Insère une ligne au début */ $row = array( \Dcp\AttributeIdentifiers\MyPhoto::face_firstname => 'Bart', \Dcp\AttributeIdentifiers\MyPhoto::face_lastname => 'Simpson' ) $photo->addArrayRow(\Dcp\AttributeIdentifier\MyPhoto::faces, $row, 0);
Le tableau
MyPhoto::facesrésultant est alors composé comme suit :+-----------+----------+ | Firstname | Lastname | +===========+==========+ #0 | Bart | Simpson | #1 | Marge | Simpson | #2 | Lisa | Simpson | #3 | Homer | Simpson | +-----------+----------+
13.6.3.1.7 Notes
Aucune.
13.6.3.1.8 Voir aussi
13.6.3.2 Doc::addHistoryEntry()
13.6.3.2.1 Description
string addHistoryEntry ( string $comment = '', int $level = DocHisto::INFO, string $code = '', int $uid = '')
Cette méthode permet d'enregistrer un nouveau message daté dans l'historique du document.
13.6.3.2.1.1 Avertissements
Les messages enregistrés ne sont pas localisables. Cela implique que les messages restitués par l'historique ne sont pas traduits.
13.6.3.2.2 Liste des paramètres
- (string)
comment - Message qui sera enregistré dans l'historique.
- (int)
level -
Niveau du message :
-
DocHisto::NOTICE: notification, -
DocHisto::INFO: message d'information (valeur par défaut), -
DocHisto::MESSAGE: message standard, -
DocHisto:: WARNING: message d'avertissement, -
DocHisto::ERROR: message d'erreur. Dans ce cas, le message est aussi ajouté au fichier log d'erreur du serveur Apache.
-
- (string)
code - Code du message : ce code peut être utilisé pour répertorier certaines
entrées dans l'historique. Par exemple, le code
CREATEest utilisé pour indiquer les messages relatifs à la création d'un document. La méthodeDoc::getHisto()permet de filtrer en fonction du code les messages de l'historique. - (int)
uid - Identifiant système du compte utilisateur. Si celui-ci est vide alors le message sera attribué à l'utilisateur courant.
13.6.3.2.3 Valeur de retour
Message d'erreur.
13.6.3.2.4 Erreurs / Exceptions
Une exception Dcp\Db\Exception peut être levée en cas de problème
d'enregistrement.
13.6.3.2.5 Historique
Cette méthode était anciennement nommée addComment.
13.6.3.2.6 Exemples
Enregistrement d'un nouveau message d'avertissement.
/** @var \Dcp\Family\MyFamily */ $d = new_Doc("", "MY_DOCUMENT"); if ($d->isAlive()) { // enregistrement $d->addHistoryEntry("Hello world", DocHisto:: WARNING); }
13.6.3.2.7 Notes
Il n'y a pas de méthode depuis la classe Doc permettant de supprimer des
messages de l'historique. Pour manipuler et gérer l'historique du document, il
faut utiliser la classe DocHisto.
13.6.3.2.8 Voir aussi
Aucun.
13.6.3.3 Doc::clearValue()
La méthode clearValue permet d'effacer la valeur d'un attribut de type non
array.
13.6.3.3.1 Description
string deleteValue ( string $attrid )
La méthode clearValue permet d'effacer la valeur d'un attribut de type non
array.
13.6.3.3.1.1 Avertissements
Aucun.
13.6.3.3.2 Liste des paramètres
- (string)
attrid - Le nom de l'attribut (de type non
array) à effacer.
13.6.3.3.3 Valeur de retour
La méthode retourne une chaîne vide s'il n'y a pas d'erreurs, ou une chaîne non-vide contenant le message d'erreur dans le cas contraire.
13.6.3.3.4 Erreurs / Exceptions
Les erreurs retournés sont les mêmes que celles retournées par la méthode
Doc::setValue.
13.6.3.3.5 Historique
13.6.3.3.5.1 Release 3.2.5
La méthode clearValue remplace la méthode précédemment nommée deleteValue.
L'utilisation de deleteValue est obsolète depuis la version 3.2.5 de
dynacase-core.
13.6.3.3.6 Exemples
- Exemple #1
$facture->clearValue(\Dcp\AttributeIdentifiers\MyFacture::montant);
13.6.3.3.7 Notes
Pour effacer un attribut de type array, utilisez la méthode
Doc::clearArrayValues.
Si l'attribut effacé est de type docid avec une option
doctitle, alors l'attribut portant le titre est lui aussi
effacé.
13.6.3.3.8 Voir aussi
Doc::clearArrayValues- Erreurs de
Doc::setValue
13.6.3.4 Doc::arrayToRawValue()
La méthode arrayToRawValue permet de sérialiser un ensemble de valeurs pour
les utiliser dans un attribut faisant partie d'un array ou un
attribut multi-valué.
13.6.3.4.1 Description
string arrayToRawValue ( array(string) $v, string $br = "<BR>" )
La métode arrayToRawValue permet de sérialiser un ensemble de valeurs sous la
forme d'une chaîne de caractères qui peut ensuite être utilisée pour
positionner la valeur d'un attribut faisant partie d'un array,
ou d'un attribut multi-valué, avec la méthode
Doc::setValue.
Les valeurs sont sérialisées par une concaténation avec le caractère \n
utilisé comme séparateur.
13.6.3.4.1.1 Avertissements
La méthode arrayToRawValue est une méthode de bas niveau que vous ne devriez
utiliser qu'en dernier recours.
Il faut privilégier l'utilisation de la méthode
setAttributeValue qui prend en charge
automatiquement ces opérations de sérialisation.
13.6.3.4.2 Liste des paramètres
- (array(string))
v - Une liste de chaînes de caractères.
- (string)
br -
brpermet de spécifier la chaîne de caractère utilisée pour substituer le caractère retour à la ligne\ndans les valeurs à sérialiser.Par défaut, la chaîne de caractères de substitution est la chaîne
<BR>.
13.6.3.4.3 Valeur de retour
La méthode arrayToRawValue retourne une chaîne de caractères correspondant à
la sérialisation des valeurs fournies.
13.6.3.4.4 Erreurs / Exceptions
Aucune.
13.6.3.4.5 Historique
13.6.3.4.5.1 Release 3.2.5
La méthode arrayToRawValue remplace la méthode précédemment nommée
_array2val.
L'utilisation de _array2val est obsolète depuis la version 3.2.5 de
dynacase-core.
13.6.3.4.6 Exemples
-
Exemple #1
L'attribut
PHOTO_KEYWORDSest un attribut de type texte multi-valué (option multiple).$motsCles = array( 'Tour Eiffel', 'Champ de Mars', 'Paris', 'France' ); $photo->setValue( \Dcp\AttributeIdentifiers\MyPhoto:photo_keywords, $doc->arrayToRawValue($motCles) );
13.6.3.4.7 Notes
Les valeurs de la liste doivent être des scalaires (string, int, float).
13.6.3.4.8 Voir aussi
13.6.3.5 Doc::hasPermission()
Cette méthode permet de vérifier que l'utilisateur courant possède un droit particulier sur le document.
13.6.3.5.1 Description
bool hasPermission ( string $aclName, bool $strict = false )
Cette méthode retourne true, si l'utilisateur possède le droit indiqué. Ce
droit est indiqué dans le profil du document et peut être obtenu par
un rôle ou un groupe.
13.6.3.5.1.1 Avertissements
Aucun.
13.6.3.5.2 Liste des paramètres
- (string)
aclName - Nom du droit a examiner.
- (bool)
strict -
Indique s'il faut tenir compte de la suppléance :
- Si
false(par défaut) : les droits des titulaires sont aussi pris en compte - Si
true: les droits des titulaires ne sont pas pris en compte.
- Si
13.6.3.5.3 Valeur de retour
Retourne true dans les cas suivants :
- si l'utilisateur possède le droit demandé,
- si l'utilisateur est "admin" (même si le droit n'existe pas).
Retourne false dans les cas suivants :
- si l'utilisateur ne possède pas le droit demandé (hors "admin"),
- si le droit n'est pas un des droits du document (hors "admin").
13.6.3.5.4 Erreurs / Exceptions
Aucune.
13.6.3.5.5 Historique
Cette méthode n'est disponible que depuis la version 3.2.5.
La méthode Doc::control() disponible dans les versions précédentes permet de
réaliser le même test de droit. À la différence de Doc::hasPermission(), cette
dernière retourne un message d'erreur si le droit n'est pas obtenu sinon elle
retourne un message vide.
13.6.3.5.6 Exemples
13.6.3.5.6.1 Vérification du droit de modification
Le droit de modifier est le droit edit.
require_once("FDL/Class.Doc.php"); $doc = new_doc("", "1420"); // document n°1420 if ($doc->isAlive()) { if ($doc->hasPermission('edit')) { printf('Utilisateur "%s" a le droit de modifier "%s"'."\n", getCurrentUser()->login, $doc->getTitle() ); } else { printf('Utilisateur "%s" n\'a pas le droit de modifier "%s"'."\n", getCurrentUser()->login, $doc->getTitle() ); } } else { printf("Document non trouvé\n"); }
Attention le droit edit ne suffit pas forcément pour autoriser la
modification. Il peut être nécessaire de vérifier aussi le verrou
(propriété locked).
13.6.3.5.6.2 Vérification de tous les droits
La liste des droits du documents est dans la propriété acls de l'objet.
require_once("FDL/Class.Doc.php"); $doc = new_doc("", "1420"); if ($doc->isAlive()) { $acls = $doc->acls; printf('Utilisateur "%s" a les droits suivants pour "%s" :'."\n", getCurrentUser()->login, $doc->getTitle() ); foreach ($acls as $acl) { printf("Droit %-12s : %s\n", $acl, ($doc->hasPermission($acl))?"Oui":"Non" ); } } else { printf("Document non trouvé\n"); }
Résultat :
Utilisateur "zoo.garde" a les droits suivants pour "Théodor" : Droit view : Oui Droit edit : Non Droit delete : Non Droit send : Non Droit unlock : Non Droit confidential : Non Droit wask : Non
13.6.3.5.7 Notes
Les méthodes Doc::enableEditControl() et
Doc::disableEditControl() n'ont pas d'impact sur cette méthode.
13.6.3.5.8 Voir aussi
13.6.3.6 Doc::delete()
Méthode utilisée pour supprimer un document.
13.6.3.6.1 Description
string delete ( bool $really = false, bool $control = true, bool $nopost = false )
Cette méthode met le statut du document à "supprimé". La propriété
doctype est affectée à Z (Zombie) et locked est affectée à -1 dans le
cas d'une suppression logique.
13.6.3.6.1.1 Avertissements
Cette méthode supprime toutes les révisions du document.
13.6.3.6.2 Liste des paramètres
- (bool)
really - Si
reallyesttrue, le document ainsi que toutes ses révisions sont supprimées de la base de données. Cette opération n'est pas annulable.
Sireallyestfalse, le document est supprimé de manière logique. il est donc toujours présent en base de données mais juste noté comme étant supprimé. - (bool)
control - Si
controlesttrue, le droitdeleteest vérifié pour l'utilisateur courant. Si l'utilisateur n'a pas ce privilège la suppression est abandonnée.
Sicontrolestfalse, la vérification des droits n'est pas effectuée. - (bool)
nopost - Si
nopostesttrue, alors les hameçonsDoc::preDelete()etDoc::postDelete()ne sont pas exécutés.
Sinopostestfalse, ces deux hameçons (hooks) sont exécutés.
13.6.3.6.3 Valeur de retour
Message d'erreur. Si la chaîne retournée est non nulle, le message indique l'erreur qui a interdit la suppression.
13.6.3.6.4 Erreurs / Exceptions
Une erreur est retournée si :
- le document n'existe pas ou plus,
- le document est déjà supprimé,
- l'utilisateur n'a pas le droit
deletesur le document, - l'hameçon
preDelete()retourne une erreur.
13.6.3.6.5 Historique
La méthode obsolète Doc::reallyDelete() est équivalente à cette méthode avec
le paramètre $really mis à true.
13.6.3.6.6 Exemples
Suppression du document référencé par l'identificateur $documentId.
$doc=new_doc('', $documentId); if ($doc->isAlive()) { $err=$doc->delete(); // maintenant le document est supprime if ($err == "") { printf("Suppression %s [%d]", $doc->getTitle(), $doc->id); } }
13.6.3.6.7 Notes
Une entrée dans l'historique est enregistrée à chaque suppression.
Les documents supprimés logiquement sont toujours accessibles avec leur identifiant. Ils ne peuvent par contre plus être modifiés par l'interface web.
La classe SearchDoc permet de rechercher les documents supprimés
en utilisant l'attribut trash.
13.6.3.6.8 Voir aussi
13.6.3.7 Doc::clearArrayValues()
La méthode clearArrayValues permet de vider les valeurs d'un attribut de type
array.
13.6.3.7.1 Description
string clearArrayValues ( string $idAttr )
La méthode clearArrayValues permet de vider les valeurs d'un attribut de type
array en vidant le contenu de tous les attributs rattachés à
cet array.
13.6.3.7.1.1 Avertissements
Aucun.
13.6.3.7.2 Liste des paramètres
- (string)
idAttr - Le nom de l'attribut de type
arraydont on souhaite vider le contenu.
13.6.3.7.3 Valeur de retour
La méthode retourne une chaîne vide s'il n'y a pas d'erreur, ou une chaîne non-vide contenant le message d'erreur dans le cas contraire.
13.6.3.7.4 Erreurs / Exceptions
Si l'attribut idAttr spécifié n'est pas de type array, un
message d'erreur est retourné.
13.6.3.7.5 Historique
13.6.3.7.5.1 Release 3.2.5
La méthode clearArrayValues remplace la méthode précédemment nommée
deleteArray.
L'utilisation de deleteArray est obsolète depuis la version 3.2.5 de
dynacase-core.
13.6.3.7.6 Exemples
-
Exemple #1
L'attribut
photo_listest un attribut de typearraycontenant les attributsphoto_filede typefileetphoto_commentde typehtmltext.$album->deleteArray(\Dcp\AttributeIdentifier\MyAlbum::photo_list);
Le contenu des attributs
photo_fileetphoto_commentest alors effacé.De la même manière, le tableau peut être vidé en vidant explicitement chacune des colonnes de l'array :
$album->clearValue(\Dcp\AttributeIdentifiers\MyAlbum::photo_file); $album->clearValue(\Dcp\AttributeIdentifiers\MyAlbum::photo_comment);
13.6.3.7.7 Notes
Aucune.
13.6.3.7.8 Voir aussi
13.6.3.8 Doc::disableEditControl()
Cette méthode permet aux méthodes de modification de ne pas tenir compte du droit de modification.
13.6.3.8.1 Description
void disableEditControl ( )
Les méthodes suivantes ne vérifient plus le droit de modification (edit) :
La méthode de vérification de modification Doc::canEdit() ne vérifie plus le
droit edit, mais continue à vérifier les verrous.
13.6.3.8.1.1 Avertissements
Les appels successifs à disableEditControl se cumulent. Ainsi, si une méthode
fait appel à disableEditControl et n'appelle pas enableEditControl, toutes
les méthodes qui se déclenchent ensuite outrepasseront les privilèges de
l'utilisateur. Aussi, à moins de vouloir explicitement ce comportement, tout
appel à disableEditControl doit être suivi d'un appel à enableEditControl
avant que la fonction ne retourne, même en cas de retour anticipé à cause d'une
erreur. Notamment, le code suivant laisse les contrôles désactivés :
$doc = new_Doc("", 1000); $doc->disableEditControl(); $doc->disableEditControl(); $doc->enableEditControl();
Cette inhibition de contrôle des droits ne contrôle pas la contrainte d'accès
liée à la visibilité I.
13.6.3.8.2 Liste des paramètres
Aucun.
13.6.3.8.3 Valeur de retour
void.
13.6.3.8.4 Erreurs / Exceptions
Aucune.
13.6.3.8.5 Historique
Aucun.
13.6.3.8.6 Exemples
L'utilisateur courant n'a pas le droit edit sur le document n°1420.
13.6.3.8.6.1 Sans suspension de contrôle de droit
require_once("FDL/Class.Doc.php"); $doc = new_doc("", "1420"); if ($doc->isAlive()){ $err1 = $doc->setValue(\Dcp\AttributeIdentifiers\Zoo_animal::an_nom,"Gastor"); $err2 = $doc->store(); printf( "Erreur : [1:%s] - [2:%s]\n", $err1, $err2); } else { printf("Document non trouvé\n"); }
Résultat :
Erreur : [1:Pas de privilège edit pour le document Théodor [1420]] - [2:]
Attention, la méthode Doc::store() ne retourne pas d'erreur dans ce
cas, car l'affectation n'a pas eu lieu et comme aucune modification n'a été
détectée, l'enregistrement en base de données n'a pas eu lieu.
13.6.3.8.6.2 Avec suspension de contrôle de droit sur l'affectation
require_once("FDL/Class.Doc.php"); $doc = new_doc("", "1420"); if ($doc->isAlive()){ $doc->disableEditControl(); $err1=$doc->setValue(\Dcp\AttributeIdentifiers\Zoo_animal::an_nom,"Gastor"); $doc->enableEditControl(); $err2=$doc->store(); printf( "Erreur : [1:%s] - [2:%s]\n", $err1, $err2); } else { printf("Document non trouvé\n"); }
Résultat :
Erreur : [1:] - [2:Pas de privilège edit pour le document Théodor [1420]]
13.6.3.8.6.3 Avec suspension complète de contrôle de droit
require_once("FDL/Class.Doc.php"); $doc = new_doc("", "1420"); if ($doc->isAlive()) $doc->disableEditControl(); $err1=$doc->setValue(\Dcp\AttributeIdentifiers\Zoo_animal::an_nom,"Gastor"); $err2=$doc->store(); $doc->enableEditControl(); printf( "Erreur : [1:%s] - [2:%s]\n", $err1, $err2); } else { printf("Document non trouvé\n"); }
Résultat :
Erreur : [1:] - [2:]
L'affectation ainsi que l'enregistrement ont bien pu être réalisés.
13.6.3.8.7 Notes
Aucune.
13.6.3.8.8 Voir aussi
13.6.3.9 Doc::duplicate()
Méthode utilisée pour dupliquer un document.
13.6.3.9.1 Description
Doc|string duplicate (bool $temporary = false, bool $control = true, bool $linkfld = false, bool $copyfile = false )
Cette méthode réalise une copie de l'objet Document. Cette copie est enregistrée en base de donnée avec un nouvel identificateur.
La révision de la copie est affectée à zéro. Le profil de la copie est affectée
au profil (cprofid) indiquée par la famille.
Si le document est lié à un cycle, l'état de la copie est l'état initial du cycle.
13.6.3.9.1.1 Avertissements
Aucun.
13.6.3.9.2 Liste des paramètres
- (bool)
temporary - Si
true, le document en base est créé comme document temporaire.
Aucun profil n'est associé au document s'il est temporaire.
Sifalse: le document est crée avec un identificateur non temporaire - (bool)
control - Si
true, la duplication est contrôlé par le droitcreate.
Sifalse: aucun contrôle de droit est réalisé. - (bool)
linkfld - Si
true, et si le document est un dossier. alors les documents contenus dans le dossier original sont liés aussi au dossier copié. Les documents contenus ne sont pas dupliqués mais juste liés.
Sifalse: seul le document dossier est copié. -
(bool)
copyfile - Si
true, les fichiers attachés au document (attribut de typefileouimage) sont dupliqués aussi. Sifalse: les fichiers sont liés aux fichiers originaux.
13.6.3.9.3 Valeur de retour
En cas d'erreur : Message d'erreur. Si la chaîne retournée est non nulle, le message indique l'erreur qui a interdit la suppression.
En cas de succès : retourne l'objet Doc dupliqué.
13.6.3.9.4 Erreurs / Exceptions
Retourne un message d'erreur dans les cas suivants :
- pas de droit de créer un document de la même famille,
- retour du
preDuplicate()non vide, - des attributs sont en visibilité
I.
Exceptions :
-
\Dcp\Exception('DOC0203')si le document à dupliquer est invalide.
13.6.3.9.5 Historique
Anciennement Doc::copy().
13.6.3.9.6 Exemples
Duplication du document référencé par l'identificateur $documentId.
$doc=new_doc('', $documentId); if ($doc->isAlive()) { $copyDoc=$doc->duplicate(); // maintenant le document est dupliqué if (is_string($copyDoc)) { $err=copyDoc; printf ("Erreur de duplication %s", $err ); } else { printf("Duplication de %s [%d] => %s [%d]", $doc->getTitle(), $doc->id, $copyDoc->getTitle(), $copyDoc->id); } }
13.6.3.9.7 Notes
Une entrée dans l'historique du document dupliqué indique l'origine de la duplication.
Lors de la duplication à l'aide du menu "Dupliquer" (action
GENERIC:GENERIC_DUPLICATE), le document dupliqué est inséré dans le même
dossier primaire (propriété prelid) que l'origine.
13.6.3.9.8 Voir aussi
Les hameçons (hooks) :
13.6.3.10 Doc::editattr()
Cette méthode permet d'ajouter les clefs correspondantes aux attributs du document pour la composition d'une vue de formulaire HTML spécifique de document.
13.6.3.10.1 Description
void editattr ( bool $withtd = true )
Cette méthode ajoute pour chaque attribut pouvant contenir une valeur :
- une clef contenant le champ de saisie de l'attribut pour le formulaire,
Pour tous les attributs pouvant contenir une valeur ainsi que les attributs encadrants :
- une clef pour le libellé de l'attribut.
La clef du champ de saisie est composée du préfixe V_ suivi de l'identifiant
de l'attribut en majuscule. Le champ de saisie est fourni par la méthode
DocFormFormat::getHtmlInput().
Si les attributs sont en visibilité H ou R, le champ de
saisie est un champ caché : <input type="hidden"/>.
Si l'attribut est en visibilité I, la clef pour le champ de saisie est vide.
La clef de libellé est composée du préfixe L_ suivi de l'identifiant de
l'attribut en majuscule. Le libellé est dépendant de la locale de
l'utilisateur. La valeur du libellé est fournie par la méthode
Doc::getLabel(). Si l'attribut est obligatoire, le libellé est entouré des
balises <b> et </b>.
13.6.3.10.1.1 Avertissements
Les attributs de type tab, frame, menu n'ont pas de clef
générée pour les champs de saisie.
Les rendus obtenus peuvent varier selon les différentes versions de Dynacase. Les noms des champs de saisie ("input name") restent stables.
13.6.3.10.2 Liste des paramètres
- (bool)
withtd - Indique si les champs de saisie sont incorporés dans un tableau HTML.
Sitrue, alors les balises</td><td>sont insérés entre le champs de saisie et les boutons d'aide à la saisie. Sifalse, les boutons d'aide à la saisie sont mis directement à la suite du champs de saisie.
13.6.3.10.3 Valeur de retour
void.
13.6.3.10.4 Erreurs / Exceptions
Aucune.
13.6.3.10.5 Historique
Aucun.
13.6.3.10.6 Exemples
13.6.3.10.6.1 Rendu en dehors d'un tableau.
Soit la famille MY_ANIMAL qui possède les attributs suivants :
| nom | type |
|---|---|
| AN_NOM | text |
| AN_PHOTO | image |
| AN_NAISSANCE | date |
Formulaire spécifique pour modifier le nom, la date de naissance et la photographie. Dans cet exemple, on affiche la photo en 200px.
Fichier de la classe associées à la famille :
namespace MyTest; class My_animal extends \Dcp\Family\Document { /** * @templateController edit original photo */ public function editPhoto() { $this->editAttr(false); $photoUrl=$this->getHtmlAttrValue("an_photo"); $this->lay->set("bigPhoto", $photoUrl); } }
Template editPhoto.html :
<div class="myname"> <label for="an_nom">[L_AN_NOM]</label> : [V_AN_NOM] </div> <div class="birthday"> <img title="[L_AN_NAISSANCE]" src="[IMG:birthday.png|64]"/> : [V_AN_NAISSANCE] </div> <div class="photo"> <img class="big" src="[bigPhoto]&width=200" /><br/> [V_AN_PHOTO] </div>
Résultat :
<div class="myname"> <label for="an_nom"><B>nom</B></label> : <input onchange="document.isChanged=true" type="text" name="_an_nom" value="Théodor" id="an_nom" > </div> <div class="birthday"> <img title="date de naissance" src="resizeimg.php?img=Images%2Fbirthday.png&size=64"/> : <input readonly="readonly" size="10" autocomplete="off" onfocus="if (this.readOnly) $('#ic_an_naissance').trigger('mousedown').trigger('click')" onblur="control_date(event,this)" type="text" name="_an_naissance" value="10/08/2011" id="an_naissance" /><input type="button" onmousedown="Calendar_Init('an_naissance','ic_an_naissance',false,'%d/%m/%Y')" class="inlineButton" id="ic_an_naissance" value="…" /><input type="button" value="♦" id="id_an_naissance" title="Date manuelle" onmousedown="document.getElementById('an_naissance').disabled=false;document.getElementById('an_naissance').readOnly=false" onclick="focus_date(event,'an_naissance')" class="inlineButton" /><input id="ix_an_naissance" type="button" class="inlineButton" value="×" title="effacer entrée(s)" onclick="clearInputs(['an_naissance'],'')"> </div> <div class="photo"> <img class="big" src="file/1420/42/an_photo/-1/250px-Alligator.jpg?cache=no&inline=no&width=200" /><br/> <span id="IFERRan_photo" class="Error"></span><span class="FREEDOMText"><a target="_self" href="file/1420/42/an_photo/-1/250px-Alligator.jpg?cache=no&inline=no" title="250px-Alligator.jpg"><img id="img_an_photo" style="vertical-align:bottom;border:none;width:30px" src="file/1420/42/an_photo/-1/250px-Alligator.jpg?cache=no&inline=yes&width=30"></a></span><br/><input name="_an_photo" type="hidden" value="image/jpeg; charset=binary|42|250px-Alligator.jpg" id="an_photo"><input type="hidden" value="image/jpeg; charset=binary|42|250px-Alligator.jpg" id="INIVan_photo"><span><input onchange="document.isChanged=true;changeFile(this,'an_photo','')" accept="image/*" size=15 type="file" id="IF_an_photo" name="_UPL_an_photo" ></span> <input id="ix_an_photo" type="button" style="vertical-align:baseline" class="inlineButton" value="×" title="Effacer le fichier" title1="Effacer le fichier" value1="×" title2="Annuler l'effacement du fichier" value2="−" onclick="clearFile(this,'an_photo')"> </div>
Rendu HTML en ajoutant le style suivant :
div.photo { border : 2px solid grey; width:300px; padding:10px; } div.myname { border : 2px solid grey; width:300px; padding:10px; border-style: solid solid none solid; } div.birthday { border-style: none solid none solid; padding: 10px; width: 300px; border-width: 2px; border-color: grey; } div.photo img.big { width:300px; } div.photo input[type="file"] { width: 270px; } div.photo input, div.myname input { height: 30px; } .birthday > img { vertical-align: middle; } .birthday input, div.myname input { vertical-align: middle; font-size:20px; } .birthday input[type=button] { width:30px; } #img_an_photo { display:none; }
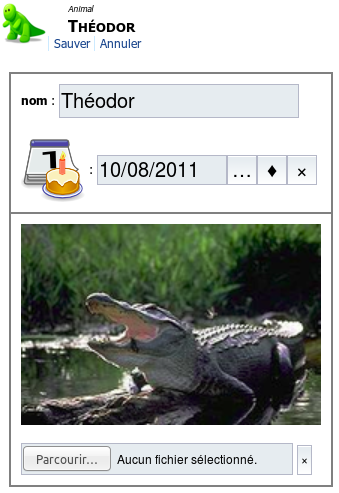
Figure 82. Usage de Doc::editAttr()
13.6.3.10.6.2 Rendu dans un tableau
Cet exemple affiche les champs de saisie dans un tableau. Les boutons d'aides à la saisies sont alignés car ils sont dans des cellules séparées.
Soit la famille MY_ANIMAL qui possède les attributs suivants :
| nom | type |
|---|---|
| AN_NOM | text |
| AN_ENTREE | date |
| AN_NAISSANCE | date |
| AN_GARDIEN | account |
| AN_SEXE | enum |
| AN_ESPECE | docid |
namespace MyTest; class My_animal extends \Dcp\Family\Document { /** * @templateController edit some data */ public function editData() { $this->editAttr(true); // affichage avec "</td><td>" } }
Template editData.html :
<table class="myTable"> <tr> <td class="myLabel">[L_AN_NOM]</td><td class="myInput">[V_AN_NOM]</td> <td class="myLabel">[L_AN_NAISSANCE]</td><td class="myInput">[V_AN_NAISSANCE]</td> </tr> <tr> <td class="myLabel">[L_AN_ESPECE]</td><td class="myInput">[V_AN_ESPECE]</td> <td class="myLabel">[L_AN_SEXE]</td><td class="myInput">[V_AN_SEXE]</td> </tr> <tr> <td class="myLabel">[L_AN_GARDIEN]</td><td class="myInput">[V_AN_GARDIEN]</td> <td class="myLabel">[L_AN_ENTREE]</td><td class="myInput">[V_AN_ENTREE]</td> </tr> </table>
Résultat :
<table class="myTable"> <tr> <td class="myLabel"><B>nom</B></td><td class="myInput"><input onchange="document.isChanged=true" class="fullresize" type="text" name="_an_nom" value="Théodor" id="an_nom" > </td><td class="nowrap"></td> <td class="myLabel">date de naissance</td><td class="myInput"><input readonly="readonly" size="10" autocomplete="off" onfocus="if (this.readOnly) $('#ic_an_naissance').trigger('mousedown').trigger('click')" onblur="control_date(event,this)" type="text" name="_an_naissance" value="10/08/2011" id="an_naissance" /><input type="button" onmousedown="Calendar_Init('an_naissance','ic_an_naissance',false,'%d/%m/%Y')" class="inlineButton" id="ic_an_naissance" value="…" /><input type="button" value="♦" id="id_an_naissance" title="Date manuelle" onmousedown="document.getElementById('an_naissance').disabled=false;document.getElementById('an_naissance').readOnly=false" onclick="focus_date(event,'an_naissance')" class="inlineButton" /><input id="ix_an_naissance" type="button" class="inlineButton" value="×" title="effacer entrée(s)" onclick="clearInputs(['an_naissance'],'')"></td><td class="nowrap"></td> </tr> <tr> <td class="myLabel"><B>espèce</B></td><td class="myInput"><input type="hidden" name="_an_espece" id="an_espece" value="1295"><input class="fullresize" autocomplete="off" autoinput="1" onfocus="activeAuto(event,1420,this,'','an_espece','')" onchange="addmdocs('_an_espece');document.isChanged=true" type="text" name="_ilink_an_espece" id="ilink_an_espece" value="Alligator"></td><td class="editbutton"><input id="ic_ilink_an_espece" type="button" class="inlineButton" value="…" title="choisir une valeur pour espèce" onclick="sendAutoChoice(event,1420,this,'ilink_an_espece','','an_espece','')"><input id="ix_an_espece" type="button" class="inlineButton" value="×" title="effacer entrée(s)" onclick="clearInputs(['an_espece','ilink_an_espece'],'','an_espece' )"><input id="icr_an_espece" class="add-doc" type="button" value=" " titleedit="créer un document espèce" titleview="Modifier le document" onclick="editRelation('ZOO_ESPECE',elinkvalue('an_espece'),'an_espece','&es_nom='+elinkvalue('ilink_an_espece')+'')"></td> <td class="myLabel">sexe</td><td class="myInput"><span id="sp_an_sexe"><select name="_an_sexe" id="an_sexe" onchange="disableReadAttribute();" > <option selected value="M">Masculin</option> <option value="F">Féminin</option> <option value="H">Hermaphrodite</option> </select> </span> </td><td class="nowrap"></td> </tr> <tr> <td class="myLabel">gardien responsable</td><td class="myInput"><input type="hidden" name="_an_gardien" id="an_gardien" value=""><input class="fullresize" autocomplete="off" autoinput="1" onfocus="activeAuto(event,1420,this,'','an_gardien','')" onchange="addmdocs('_an_gardien');document.isChanged=true" type="text" name="_ilink_an_gardien" id="ilink_an_gardien" value=""></td><td class="editbutton"><input id="ic_ilink_an_gardien" type="button" class="inlineButton" value="…" title="choisir une valeur pour gardien responsable" onclick="sendAutoChoice(event,1420,this,'ilink_an_gardien','','an_gardien','')"><input id="ix_an_gardien" type="button" class="inlineButton" value="×" title="effacer entrée(s)" onclick="clearInputs(['an_gardien','ilink_an_gardien'],'','an_gardien' )"></td> <td class="myLabel">date d'entrée</td><td class="myInput"><input readonly="readonly" size="10" autocomplete="off" onfocus="if (this.readOnly) $('#ic_an_entree').trigger('mousedown').trigger('click')" onblur="control_date(event,this)" type="text" name="_an_entree" value="" id="an_entree" /><input type="button" onmousedown="Calendar_Init('an_entree','ic_an_entree',false,'%d/%m/%Y')" class="inlineButton" id="ic_an_entree" value="…" /><input type="button" value="♦" id="id_an_entree" title="Date manuelle" onmousedown="document.getElementById('an_entree').disabled=false;document.getElementById('an_entree').readOnly=false" onclick="focus_date(event,'an_entree')" class="inlineButton" /><input id="ix_an_entree" type="button" class="inlineButton" value="×" title="effacer entrée(s)" onclick="clearInputs(['an_entree'],'')"></td><td class="nowrap"></td> </tr> </table>
Rendu HTML en ajoutant le style suivant :
.myLabel { background-color:#F2FF5F; } .myLabel:first-letter { text-transform:capitalize; } .myinput { background-color:white; } .myinput + td { background-color:white; } .myTable { border-collapse: separate; border-spacing: 10px; border: solid 1px grey; } .document table.myTable input[type=button] { width:20px; height:20px; font-size: 15px; }

Figure 83. Affichage dans un tableau avec Doc::editAttr()
13.6.3.10.6.3 Variante Rendu dans un tableau
Le contrôleur est identique au précédent exemple. Cette variante permet d'illustrer comment prendre en compte les champs de saisie dans un tableau personnalisé.
Dans cet exemple, les libellés des attributs sont placés dans des rangées au dessus des champs de saisies.
Template editData.html :
<table class="myLabelUp"> <tr> <td colspan="2" class="myLabel"><div class="myLabel">[L_AN_NOM]</div></td> <td colspan="2" class="myLabel"><div class="myLabel">[L_AN_NAISSANCE]</div></td> </tr> <tr> <td class="myInput">[V_AN_NOM]</td> <td class="myInput">[V_AN_NAISSANCE]</td> </tr> <tr> <td colspan="2" class="myLabel"><div class="myLabel">[L_AN_ESPECE]</div></td> <td colspan="2" class="myLabel"><div class="myLabel">[L_AN_SEXE]</div></td> </tr> <tr> <td class="myInput">[V_AN_ESPECE]</td> <td class="myInput">[V_AN_SEXE]</td> </tr> <tr> <td colspan="2" class="myLabel"><div class="myLabel">[L_AN_GARDIEN]</div></td> <td colspan="2" class="myLabel"><div class="myLabel">[L_AN_ENTREE]</div></td> </tr> <tr> <td class="myInput">[V_AN_GARDIEN]</td> <td class="myInput">[V_AN_ENTREE]</td> </tr> </table>
On notera dans ce template, l'utilisation du colspan dans les libellés pour
prendre en compte les balises </td><td> ajoutées par les clefs de champs de
saisies.
Résultat :
<table class="myLabelUp"> <tr> <td colspan="2" class="myLabel"><div class="myLabel"><B>nom</B></div></td> <td colspan="2" class="myLabel"><div class="myLabel">date de naissance</div></td> </tr> <tr> <td class="myInput"><input onchange="document.isChanged=true" class="fullresize" type="text" name="_an_nom" value="Théodor" id="an_nom" > </td><td class="nowrap"></td> <td class="myInput"><input readonly="readonly" size="10" autocomplete="off" onfocus="if (this.readOnly) $('#ic_an_naissance').trigger('mousedown').trigger('click')" onblur="control_date(event,this)" type="text" name="_an_naissance" value="10/08/2011" id="an_naissance" /><input type="button" onmousedown="Calendar_Init('an_naissance','ic_an_naissance',false,'%d/%m/%Y')" class="inlineButton" id="ic_an_naissance" value="…" /><input type="button" value="♦" id="id_an_naissance" title="Date manuelle" onmousedown="document.getElementById('an_naissance').disabled=false;document.getElementById('an_naissance').readOnly=false" onclick="focus_date(event,'an_naissance')" class="inlineButton" /><input id="ix_an_naissance" type="button" class="inlineButton" value="×" title="effacer entrée(s)" onclick="clearInputs(['an_naissance'],'')"></td><td class="nowrap"></td> </tr> <tr> <td colspan="2" class="myLabel"><div class="myLabel"><B>espèce</B></div></td> <td colspan="2" class="myLabel"><div class="myLabel">sexe</div></td> </tr> <tr> <td class="myInput"><input type="hidden" name="_an_espece" id="an_espece" value="1295"><input class="fullresize" autocomplete="off" autoinput="1" onfocus="activeAuto(event,1420,this,'','an_espece','')" onchange="addmdocs('_an_espece');document.isChanged=true" type="text" name="_ilink_an_espece" id="ilink_an_espece" value="Alligator"></td><td class="editbutton"><input id="ic_ilink_an_espece" type="button" class="inlineButton" value="…" title="choisir une valeur pour espèce" onclick="sendAutoChoice(event,1420,this,'ilink_an_espece','','an_espece','')"><input id="ix_an_espece" type="button" class="inlineButton" value="×" title="effacer entrée(s)" onclick="clearInputs(['an_espece','ilink_an_espece'],'','an_espece' )"><input id="icr_an_espece" class="add-doc" type="button" value=" " titleedit="créer un document espèce" titleview="Modifier le document" onclick="editRelation('ZOO_ESPECE',elinkvalue('an_espece'),'an_espece','&es_nom='+elinkvalue('ilink_an_espece')+'')"></td> <td class="myInput"><span id="sp_an_sexe"><select name="_an_sexe" id="an_sexe" onchange="disableReadAttribute();" > <option selected value="M">Masculin</option> <option value="F">Féminin</option> <option value="H">Hermaphrodite</option> </select> </span> </td><td class="nowrap"></td> </tr> <tr> <td colspan="2" class="myLabel"><div class="myLabel">gardien responsable</div></td> <td colspan="2" class="myLabel"><div class="myLabel">date d'entrée</div></td> </tr> <tr> <td class="myInput"><input type="hidden" name="_an_gardien" id="an_gardien" value=""><input class="fullresize" autocomplete="off" autoinput="1" onfocus="activeAuto(event,1420,this,'','an_gardien','')" onchange="addmdocs('_an_gardien');document.isChanged=true" type="text" name="_ilink_an_gardien" id="ilink_an_gardien" value=""></td><td class="editbutton"><input id="ic_ilink_an_gardien" type="button" class="inlineButton" value="…" title="choisir une valeur pour gardien responsable" onclick="sendAutoChoice(event,1420,this,'ilink_an_gardien','','an_gardien','')"><input id="ix_an_gardien" type="button" class="inlineButton" value="×" title="effacer entrée(s)" onclick="clearInputs(['an_gardien','ilink_an_gardien'],'','an_gardien' )"></td> <td class="myInput"><input readonly="readonly" size="10" autocomplete="off" onfocus="if (this.readOnly) $('#ic_an_entree').trigger('mousedown').trigger('click')" onblur="control_date(event,this)" type="text" name="_an_entree" value="" id="an_entree" /><input type="button" onmousedown="Calendar_Init('an_entree','ic_an_entree',false,'%d/%m/%Y')" class="inlineButton" id="ic_an_entree" value="…" /><input type="button" value="♦" id="id_an_entree" title="Date manuelle" onmousedown="document.getElementById('an_entree').disabled=false;document.getElementById('an_entree').readOnly=false" onclick="focus_date(event,'an_entree')" class="inlineButton" /><input id="ix_an_entree" type="button" class="inlineButton" value="×" title="effacer entrée(s)" onclick="clearInputs(['an_entree'],'')"></td><td class="nowrap"></td> </tr> </table>
Rendu HTML en ajoutant le style suivant :
.myLabel { background-color:#F2FF5F; } .myLabel:first-letter { text-transform:capitalize; } .myinput { background-color:white; } .myinput + td { background-color:white; } .myLabelUp { border-collapse: collapse; border-spacing: initial; } .myLabelUp td { vertical-align:bottom; } .myLabelUp td.myInput { width:300px; border-style: none none solid solid; border-width: 1px; border-color: grey; margin : 4px; } .myLabelUp td.myLabel { width:300px; border-style: solid solid none solid; border-width: 1px; border-color: grey; margin : 4px; } .myLabelUp td.myInput + td { border-style: none solid solid none; border-width: 1px; border-color: grey; margin : 4px; } .myLabelUp .myLabel { background-color:#F2FF5F; padding: 3px; }
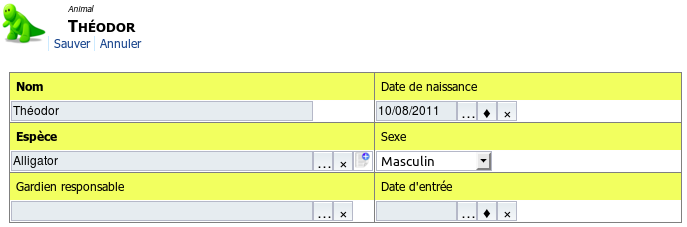
Figure 84. Variante d'affichage dans un tableau avec Doc::editAttr()
13.6.3.10.7 Notes
Aucune.
13.6.3.10.8 Voir aussi
13.6.3.11 Doc::enableEditControl()
Cette méthode permet de restaurer le contrôles des droits de modifications
précédemment suspendus par la méthode Doc::disableEditContol().
13.6.3.11.1 Description
void enableEditControl ( )
Cette méthode restaure le contrôle de droit de modification.
Si la méthode Doc::disableEditContol() a été appelée plusieurs fois
consécutivement, il est nécessaire d'appeler autant de fois cette méthode pour
restaurer le contrôle.
13.6.3.11.1.1 Avertissements
Les appels successifs à disableEditControl se cumulent. Ainsi, si une méthode
fait appel à disableEditControl et n'appelle pas enableEditControl, toutes
les méthodes qui se déclenchent ensuite outrepasseront les privilèges de
l'utilisateur. Aussi, à moins de vouloir explicitement ce comportement, tout
appel à disableEditControl doit être suivi d'un appel à enableEditControl
avant que la fonction ne retourne, même en cas de retour anticipé à cause d'une
erreur. Notamment, le code suivant laisse les contrôles désactivés :
$doc = new_Doc("", 1000); $doc->disableEditControl(); $doc->disableEditControl(); $doc->enableEditControl();
13.6.3.11.2 Liste des paramètres
Aucun.
13.6.3.11.3 Valeur de retour
void.
13.6.3.11.4 Erreurs / Exceptions
Aucune.
13.6.3.11.5 Historique
Aucun.
13.6.3.11.6 Exemples
13.6.3.11.6.1 Imbrication des suspensions de contrôle de modification.
L'utilisateur courant n'a pas le droit edit sur le document n°1420.
function modifyBirthday(Doc &$doc) { $doc->disableEditControl(); print "Suspension du contrôle\n"; $err = $doc->setValue(\Dcp\AttributeIdentifiers\Zoo_animal::an_naissance,"2013-01-01"); print "\tAffectation an_naissance\n"; $doc->enableEditControl(); print "Activation du contrôle\n"; return $err; } function modifyNameAndBirthday(Doc &$doc) { $doc->disableEditControl(); print "Suspension du contrôle\n"; $err = $doc->setValue(\Dcp\AttributeIdentifiers\Zoo_animal::an_nom,"Helitor"); print "\tAffectation an_nom\n"; if (empty($err)) { $err=modifyBirthday($doc); if (empty($err)) { $err=$doc->store(); print "\tEnregistrement\n"; } } $doc->enableEditControl(); print "Activation du contrôle\n"; return $err; } $doc=new_doc("", "1420"); if ($doc->isAlive()) { $err = modifyNameAndBirthday($doc); if (empty($err)) { printf("Document \"%s\" a été enregistré\n", $doc->getTitle()); } else { printf("Error: %s\n", $err); } } else { printf("Document non trouvé\n"); }
Résultat :
Suspension du contrôle
Affectation an_nom
Suspension du contrôle
Affectation an_naissance
Activation du contrôle
Enregistrement
Activation du contrôle
Document "Helitor" a été enregistré
La première activation de contrôle n'est pas effective car deux suspensions ont été réalisées précédemment. Seule la deuxième activation rétablit le contrôle.
13.6.3.11.7 Notes
Aucune.
13.6.3.11.8 Voir aussi
13.6.3.12 Doc::getArrayRawValues()
La méthode getArrayRawValues retourne les valeurs d'un attribut de type
array.
13.6.3.12.1 Description
array|bool(false) getArrayRawValues ( string $idAttr, int $index = -1 )
La méthode getArrayRawValues retourne les valeurs des attributs rattachés à
cet attribut de type array, sous la forme d'une liste de lignes
composées chacune d'un tableau associatif.
13.6.3.12.1.1 Avertissements
Aucun.
13.6.3.12.2 Liste des paramètres
- (string)
idAttr - Le nom de l'attribut de type
arraydont on souhaite obtenir les valeurs. - (int)
index -
indexpermet de ne retourner qu'une ligne en particulier en spécifiant l'indice (à partir de 0) de la ligne qu'on souhaite obtenir.Si
indexest égal à -1, alors toutes les lignes sont retournées. Siindexest supérieur ou égal au nombre de lignes du tableau, alors une ligne vide est retournée.
13.6.3.12.3 Valeur de retour
La méthode retourne le booléen false s'il y a une erreur.
Soit le tableau suivant :
| attr_1 | attr_2 | […] | attr_N |
|---|---|---|---|
| $L1_C1 | $L1_C2 | […] | $L1_CN |
| […] | […] | […] | […] |
| $LM_C1 | $LM_C2 | […] | $LM_CN |
S'il n'y a pas d'erreur, la méthode retourne les lignes sous la forme suivante :
array( /* Ligne 1 */ 0 => array( 'attr_1' => $L1_C1, /* Colonne 1 */ 'attr_2' => $L1_C2, /* Colonne 2 */ […] 'attr_N' => $L1_CN /* Colonne N */ ), [...] /* Ligne M */ M => array( 'attr_1' => $LM_C1, 'attr_2' => $LM_C2, […] 'attr_N' => $LM_CN ) )
Si une ligne particulière est demandée (utilisation du paramètre index), alors
seule la ligne demandée est retournée :
array( 'attr_1' => $L1_C1, /* Colonne 1 */ 'attr_2' => $L1_C2, /* Colonne 2 */ [...] 'attr_N' => $L1_CN /* Colonne N */ )
13.6.3.12.4 Erreurs / Exceptions
Une erreur est retournée (false) si :
- l'attribut
idAttrn'est pas de typearray.
13.6.3.12.5 Historique
13.6.3.12.5.1 Release 3.2.5
La méthode getArrayRawValues remplace la méthode précédemment nommée
getAValues.
L'utilisation de getAValues est obsolète depuis la version 3.2.5 de
dynacase-core.
13.6.3.12.6 Exemples
-
Exemple #1 :
L'attribut
us_groupsest de typearray, avec les colonnesus_idgroupde typedocid("IUSER")etus_groupde typetext./* * Retourner le contenu entier du tableau. */ $v = $iuser->getArrayRawValues( \Dcp\AttributeIdentifiers\Iuser::us_groups ); var_dump($v);
Résultat :
array(3) { [0]=> array(2) { ["us_group"]=> string(3) "Foo" ["us_idgroup"]=> string(4) "1058" } [1]=> array(2) { ["us_group"]=> string(3) "Bar" ["us_idgroup"]=> string(4) "1059" } [2]=> array(2) { ["us_group"]=> string(3) "Baz" ["us_idgroup"]=> string(4) "1060" } }
-
Exemple #2 :
L'attribut
us_groupsest de typearray, avec les colonnesus_idgroupde typedocid("IUSER")etus_groupde typetext./* * Retourner seulement les valeur de la deuxième ligne * (ligne à l'indice 1). */ $v = $iuser->getArrayRawValues( \Dcp\AttributeIdentifiers\Iuser::us_groups, 1 ); var_dump($v);
Résultat :
array(2) { ["us_group"]=> string(3) "Bar" ["us_idgroup"]=> string(4) "1059" }
13.6.3.12.7 Notes
Aucune.
13.6.3.12.8 Voir aussi
13.6.3.13 Doc::getAttribute()
La méthode getAttribute permet de récupérer l'objet d'un attribut du
document.
13.6.3.13.1 Description
BasicAttribute|bool(false) & getAttribute ( string $idAttr, mixed & $oa = null )
La méthode getAttribute permet d'obtenir l'objet PHP (classe BasicAttribute)
d'un attribut du document.
13.6.3.13.1.1 Avertissements
Aucun.
13.6.3.13.2 Liste des paramètres
- (string)
idAttr - Le nom de l'attribut dont on souhaite obtenir l'objet.
- [out] (mixed)
oa -
oapermet de spécifier une variable qui contiendra une référence à la valeur retournée par la méthode.Cet argument est présent pour compatibilité par rapport à l'historique de la méthode.
13.6.3.13.3 Valeur de retour
La méthode retourne un objet PHP de la classe BasicAttribute si l'attribut
demandé existe ou le booléen false si l'attribut demandé n'existe pas.
13.6.3.13.4 Erreurs / Exceptions
Si l'attribut demandé n'existe pas, le booléen false est retourné.
13.6.3.13.5 Historique
Aucun.
13.6.3.13.6 Exemples
- Exemple #1
/* * Obtenir le type de l'attribut `montant` */ $oa = $doc->getAttribute(\Dcp\AttributeIdentifiers\Facture::montant); printf("L'attribut '%s' est de type '%s'.", $oa->id, $oa->type);
Résultat :
L'attribut 'montant' est de type 'money'.
13.6.3.13.7 Notes
L'attribut demandé peut-être un attribut déclaré sur la famille du
document ou bien un attribut déclaré sur une famille mère. La famille d'origine
de l'attribut est alors consultable via la propriété docid de l'objet de
attribut qui contient l'identifiant de la famille qui déclare cet attribut.
Cette fonction permet entre autre de modifier les propriétés d'un attributs à la volée, ce qui permet de modifier :
- son libellé, s'il n'est pas traduit,
- sa visibilité,
- ses propriétés.
Généralement, ces modifications sont faites lors de la preEdition du document.
13.6.3.13.8 Voir aussi
13.6.3.14 Doc::getCustomTitle()
La méthode getCustomTitle permet de définir le titre du document.
13.6.3.14.1 Description
string getCustomTitle ( void )
La méthode getCustomTitle permet de surcharger la méthode de composition du
titre par défaut des documents, et de définir sa propre méthode de composition
du titre.
Par défaut, le titre est composé en concaténant la valeur des attributs
déclarés avec la caractéristique in_title.
13.6.3.14.1.1 Avertissements
Dans les rapports, la colonne titre est recalculée à l'aide de
cette méthode. La particularité des rapports est que la liste des documents
utilisée pour afficher son rapport est composée de document incomplets.
Un document incomplet ne contient qu'un sous ensemble des données du document. Dans le cas du rapport, il ne contient que les données à afficher. Par conséquent, si la composition du titre fait appel à des données non présentées, il sera affiché de manière partielle.
Il est possible de prendre en compte ce cas particulier en vérifiant le statut du document.
public function getCustomTitle() { if ($this->doctype === 'I') { // incomplete document return $this->title; // Titre original } else { // Doing special title return $this->myComplexDynamicTitle(); } }
13.6.3.14.2 Liste des paramètres
Aucun.
13.6.3.14.3 Valeur de retour
La méthode retourne une chaîne de caractères qui est le titre du document.
13.6.3.14.4 Erreurs / Exceptions
Aucune.
13.6.3.14.5 Historique
13.6.3.14.5.1 Release 3.2.5
La méthode getCustomTitle remplace la méthode précédemment nommée
getSpecTitle.
L'utilisation de getSpecTitle est obsolète depuis la version 3.2.5 de
dynacase-core.
13.6.3.14.6 Exemples
-
Exemple #1
namespace Facturation; class ArchiveFacture extends \Dcp\Family\Dir { /* * Compose le titre avec la valeur de l'attribut `ref_client` et * l'`id` du document. Ex. : "ACMECorp-1234" */ public function getCustomTitle() { return sprintf( "%s-%s", $this->getAttributeValue(\Dcp\AttributeIdentifiers\ArchiveFacture::ref_client), $this->getPropertyValue('id'), ); } }
13.6.3.14.7 Notes
Lors de la construction d'un rapport, le document est incomplet et les valeurs d'attributs sont partiellement présents en fonction des colonnes affichées. Si le titre est dépendant d'un attribut qui n'est pas présent, le titre présenté dans le rapport peut être incomplet.
Pour s'assurer que le titre présenté est correct, il est possible de retourner le titre "courant" lorsque le document est incomplet comme le montre l'exemple suivant.
public function getCustomTitle() { if ($this->doctype === 'I') { // incomplete document return $this->title; } else { // Doing special title $mySpecialTitle = sprintf("REF/%d/%d/%s", $this->initid, $this->revision, $this->getAttributeValue(\Dcp\AttributeIdentifiers\ArchiveFacture::ref_client)); return $mySpecialTitle; } }
13.6.3.14.8 Voir aussi
13.6.3.15 Doc::getDate()
La méthode getDate permet d'obtenir la date du jour au format texte.
13.6.3.15.1 Description
string getDate ( int $daydelta = 0, int $dayhour = "", int $daymin = "", bool $getlocale = false )
La méthode getDate permet d'obtenir une date du jour compensée par un certain
nombre de jours, d'heures ou de minutes.
La date retournée est au format texte international ou au format de la locale de l'utilisateur courant.
La valeur ainsi obtenue est utilisable pour affecter la valeur d'un attribut de
type date ou timestamp avec la méthode
Doc::setAttributeValue.
13.6.3.15.1.1 Avertissements
Aucun.
13.6.3.15.2 Liste des paramètres
- (int)
daydelta -
daydeltapermet d'appliquer une compensation de la date en nombre de jours.Si
daydeltaest < 0, alors la date retournée est la date courante moins le nombre de jours demandés.Si
daydeltaest > 0, alors la date retournée est la date courante plus le nombre de jours demandés.Par défaut,
daydeltaest égal à 0 et retourne donc la date courante. - (int)
dayhour -
dayhourpermet d'appliquer une compensation en nombre d'heures.Si
dayhourest différent de la chaîne vide, alors une compensation exprimée en nombre d'heures est appliquée.Par défaut
dayhourest égal à la chaîne vide. - (int)
daymin -
dayminpermet d'appliquer une compensation en nombre de minutes.Si
dayminest différent de la chaîne vide, alors une compensation exprimée en nombre de minutes est appliquée.Par défaut
dayminest égal à la chaîne vide. - (boo)
getlocale -
getlocalepermet de spécifier si la doit être retournée localisée en fonction de la locale de l'utilisateur courant.Par défaut
getlocaleest égal àfalseet la date retournée est au format international.
13.6.3.15.3 Valeur de retour
La date est retournée en texte au format international ou localisé.
Si getlocale est égal à false, alors la date est retournée au format
international Y-m-d ou Y-m-d H:i s'il y a eu ajout d'heures ou de minutes.
Si getlocale est égal à true, alors la date est retournée au format
défini par la locale de l'utilisateur courant.
13.6.3.15.4 Erreurs / Exceptions
Aucune.
13.6.3.15.5 Historique
Aucun.
13.6.3.15.6 Exemples
- Exemple #1
Obtenir la date d'hier, d'aujourd'hui et de demain :
/* * Date d'hier : -1 jour */ var_dump($doc->getDate(-1)); /* * Date du jour */ var_dump($doc->getDate()); /* * Date de demain : +1 jour */ var_dump($doc->getDate(1));
Résultat :
string(10) "2013-12-24" string(10) "2013-12-25" string(10) "2013-12-26"
- Exemple #2
Obtenir la date d'après demain (+2 jours) localisée (un utilisateur utilisant la
locale fr_FR) :
var_dump($doc->getDate(2, "", "", true));
Résultat :
string(10) "25/12/2013"
- Exemple #3
Compensation en heures et minutes :
/* * Aujourd'hui (25/12/2013 14:15) + 10 h 40 min */ var_dump($doc->getDate("", 10, 40, true));
Résultat :
string(16) "26/12/2013 00:55"
- Exemple #4
Affecter la date du jour à un attribut date_facturation de type date :
$doc->setAttributeValue( \Dcp\AttributeIdentifiers\Facture::date_facturation, $doc->getDate() ); $doc->store();
13.6.3.15.7 Notes
Les compensations daydelta, dayhour et dayminsont cumulatives.
13.6.3.15.8 Voir aussi
13.6.3.16 Doc::getDocAnchor()
13.6.3.16.1 Description
string getDocAnchor ( int $id, string $target = "_self" , bool $htmllink = true , bool|string $title = false , bool $js = true , string $docrev = "latest" , bool $viewIcon = false )
Permet de générer un fragment HTML, qui pourra être inséré dans un document
HTML, et qui contiendra une ancre HTML (<a href="…">…</a>) vers un document
Dynacase.
13.6.3.16.1.1 Avertissements
Aucun.
13.6.3.16.2 Liste des paramètres
- (int)
id - L'identifiant du document pour lequel on souhaite générer le code de l'ancre HTML.
- (string)
target -
Le nom du format du lien HTML. Les valeurs supportées sont :
_self(par défaut),-
mail(pour un fragment HTML inséré dans un mail)Dans ce cas, l'URL de l'ancre est composée à partir de la valeur du paramètre
CORE_MAILACTIONURL, lui-même composé à partir du paramètreCORE_MAILACTION.Cela permet d'effectuer des opérations spécifiques lorsqu'un document est accédé depuis un mail.
ext(pour un fragment HTML inséré dans une interface ExtJS),
toute autre valeur est prise en compte comme l'attribut
targetde l'ancre HTML générée. - (bool)
htmllink - Si
falsealors seul le fragment HTML contenant le titre, sans ancre, est généré. - (bool|string)
title - Si une chaîne est spécifiée, alors elle est utilisée à la place du titre du document.
- (bool)
js - Si
truealors du code JavaScript est inclus pour ouvrir le document dans une popup. - (string)
docrev -
Indique sur quelle révision du document pointera l'ancre HTML.
Les valeurs possibles sont :
-
latest, -
fixed, -
state(<state>).
Se reporter à l'option
docrevdes attributs docid pour plus de précisions. -
- (bool)
viewIcon - Si
truel'icone de la famille du document est présentée dans l'ancre HTML. Dans ce cas l'ancre html aura la classe "relation" avec une image de fond :<a class="relation" style="background-image:url("myicon.png")>myTitle</a>Sinon l'ancre html retournée est sans classe ni style particuliers.
13.6.3.16.3 Valeur de retour
La méthode retourne une chaîne contenant un fragment HTML avec une ancre vers le document.
13.6.3.16.4 Erreurs / Exceptions
Aucun.
13.6.3.16.5 Historique
Aucun.
13.6.3.16.6 Exemples
/* Générer une ancre HTML sans JS mais avec l'icône de la famille du document */ $htmlAnchor = $this->getDocAnchor($docId, "_self", true, false, false, "latest", true); /* Retourne : <a documentId="7202" class="relation" style="background-image:url(resizeimg.php?img=Images/myicon.png&size=14)" target="_self" href="?&app=FDL&action=OPENDOC&mode=view&id=7202&latest=Y">Mon Document</a> */ /* Insérer le fragment HTML dans le layout */ $this->lay->set('LINK_TO_DOCUMENT', $htmlAnchor);
13.6.3.16.7 Notes
Aucun.
13.6.3.16.8 Voir aussi
Aucun.
13.6.3.17 Doc::getFamilyDocument()
La méthode getFamilyDocument permet d'obtenir le document famille du
document courant.
13.6.3.17.1 Description
DocFam|null getFamilyDocument ( )
La méthode getFamilyDocument permet d'obtenir l'objet DocFam
de la famille du document courant.
13.6.3.17.1.1 Avertissements
Aucun.
13.6.3.17.2 Liste des paramètres
Aucun.
13.6.3.17.3 Valeur de retour
La méthode retourne l'objet DocFam de la famille du
document courant ou la valeur null en cas d'erreur.
13.6.3.17.4 Erreurs / Exceptions
La méthode retourne la valeur null s'il y a une erreur d'inclusion du fichier
PHP de déclaration de la famille du document courant.
13.6.3.17.5 Historique
13.6.3.17.5.1 Release 3.2.5
La méthode getFamilyDocument remplace la méthode précédemment nommée
getFamDoc.
L'utilisation de getFamDoc est obsolète depuis la version 3.2.5 de
dynacase-core.
13.6.3.17.6 Exemples
- Exemple #1
$fam = $doc->getFamilyDocument(); printf("Le document '%s' est issue de la famille '%s'.", $doc->getTitle(), $fam->getTitle() );
13.6.3.17.7 Notes
Aucune.
13.6.3.17.8 Voir aussi
13.6.3.18 Doc::getFamilyParameterValue()
La méthode getFamilyParameterValue permet d'obtenir la valeur des
paramètres de famille.
13.6.3.18.1 Description
string getFamilyParameterValue ( string $idp, string $def = "" )
La méthode getFamilyParameterValue permet d'obtenir la valeur des
paramètres de la famille du document courant.
13.6.3.18.1.1 Avertissements
Aucun.
13.6.3.18.2 Liste des paramètres
- (string)
idp - Le nom du paramètre dont on souhaite obtenir la valeur.
- (string)
def -
defpermet de spécifier la valeur par défaut retournée par la méthode si le nom du paramètreidpn'existe pas.Par défaut, la valeur par défaut est une chaîne vide.
13.6.3.18.3 Valeur de retour
La méthode retourne la valeur du paramètre demandé, ou la valeur par défaut
def si le paramètre demandé n'existe pas.
Dans le cas où le paramètre est défini sur une famille parente et que la valeur
pour la famille est vide, alors la valeur de la famille parente sera retournée.
La recherche de la valeur se fait sur toute l'ascendance jusqu'à trouver une
valeur non vide. Si en définitive, la valeur des parents est aussi vide alors la
valeur def sera retournée.
13.6.3.18.4 Erreurs / Exceptions
Si l'attribut demandé n'existe pas, la valeur par défaut def est retournée.
13.6.3.18.5 Historique
13.6.3.18.5.1 Release 3.2.5
La méthode getFamilyParameterValue remplace la méthode précédemment nommée
getParamValue.
L'utilisation de getParamValue est obsolète depuis la version 3.2.5 de
dynacase-core.
13.6.3.18.6 Exemples
- Exemple #1
La famille Facture comporte un paramètre qui permet de spécifier la valeur du
taux de TVA :
/* * Lire le taux de TVA défini sur le paramètre TAUX_TVA de la famille * du document `$facture`. */ $tva = $facture->getFamilyParameterValue('TAUX_TVA', 0); if ($tva <= 0) { throw new Exception(sprintf("Le taux de TVA doit être > 0 !")); }
13.6.3.18.7 Notes
Aucune.
13.6.3.18.8 Voir aussi
- Pour trouver la valeur d'un paramètre applicatif getParameterValue
13.6.3.19 Doc::getMultipleRawValues()
La méthode getMultipleRawValues permet de retourner les valeurs d'un attribut
multi-valué ou d'un attribut rattaché à un attribut de type
array.
13.6.3.19.1 Description
mixed getMultipleRawValues ( string $idAttr, string $def = "", int $index = - 1 )
La méthode getMultipleRawValues permet d'obtenir les valeurs d'attributs
multi-valués.
Les attributs multi-valués peuvent être :
- des attributs déclarés avec l'option
multiple=yes; - des attributs rattachés à un attribut de type
array.
13.6.3.19.1.1 Avertissements
Aucun.
13.6.3.19.2 Liste des paramètres
- (string)
idAttr - Le nom de l'attribut multi-valué dont on souhaite obtenir les valeurs.
- (string)
def -
defpermet de spécifier la valeur par défaut qui sera retournée si l'attribut n'est pas valué.Par défaut, la valeur par défaut est une chaîne vide.
- (int)
index -
indexpermet d'obtenir la valeur à un indice (à partir de 0) donné.Si
indexest égal à-1, alors toutes les valeurs de l'attribut sont retournées.Si
indexest supérieur ou égal au nombre de valeurs, alors la valeur par défaut définie pardefest retournée.
13.6.3.19.3 Valeur de retour
La méthode retourne
- la valeur (scalaire) si le paramètres
indexest différent de-1, - les valeurs (array) si
indexvaut-1, - ou la valeur scalaire par défaut
defsi l'attribut n'est pas valué.
13.6.3.19.4 Erreurs / Exceptions
Aucune.
13.6.3.19.5 Historique
13.6.3.19.5.1 Release 3.2.5
La méthode getMultipleRawValues remplace la méthode précédemment nommée
getTValue.
L'utilisation de getTValue est obsolète depuis la version 3.2.5 de
dynacase-core.
13.6.3.19.6 Exemples
-
Exemple #1
L'attribut
us_groupsest de typearray, avec les colonnesus_idgroupde typedocid("IUSER")etus_groupde typetext./* * Obtenir l'ensemble des valeurs de la colonne `us_group` */ $v = $iuser->getMultipleRawValues( \Dcp\AttributeIdentifiers\Iuser::us_group ); var_dump($v);
Résultat :
array(3) { [0]=> string(3) "Foo" [1]=> string(3) "Bar" [2]=> string(3) "Baz" }
-
Exemple #2
L'attribut
us_groupsest de typearray, avec les colonnesus_idgroupde typedocid("IUSER")etus_groupde typetext./* * Obtenir la deuxième valeur de la colonne `us_group` * (valeur à l'indice 1) */ $v = $iuser->getMultipleRawValues( \Dcp\AttributeIdentifiers\Iuser::us_group, "", 1 ); var_dump($v);
Résultat :
string(3) "Bar"
13.6.3.19.7 Notes
Aucune.
13.6.3.19.8 Voir aussi
13.6.3.20 Doc::getOldRawValue()
13.6.3.20.1 Description
string getOldRawValue ( string $idAttribute )
Récupère la valeur précédent l'appel aux méthodes de modification de valeurs
d'attributs. Si la valeur précédente est inchangée suite à l'appel d'une méthode
de modification, la méthode retournera le booléen false.
Les principales méthodes de modification de valeurs sont :
13.6.3.20.1.1 Avertissements
Cette méthode ne récupère que les valeurs changées que sur un objet. Si on
instancie deux fois le même document, alors les modifications de l'un ne sont
pas répercutées sur l'autre. Si l'attribut n'a pas encore été modifié la valeur
de retour est false (après une création). Les enregistrements de valeurs
modifiés sont remis à zéro lors d'une révision (Doc::revise).
13.6.3.20.2 Liste des paramètres
- (string)
info - Identifiant de l'attribut
13.6.3.20.3 Valeur de retour
La valeur de retour indique la valeur brute précédente à la modification.
| setValue | getRawValue | getOldValue |
|---|---|---|
| "vert" | "vert" | false |
| "jaune" | "jaune" | "vert" |
| "bleu" | "bleu" | "jaune" |
| "bleu" | "bleu" | "jaune" |
| " " | null | "bleu" |
Si la valeur n'a pas encore été changée, le retour est le booléen false. Si
l'identifiant de l'attribut n'existe pas le retour est aussi false.
13.6.3.20.4 Erreurs / Exceptions
Aucune.
13.6.3.20.5 Historique
Cette méthode était anciennement nommée getOldValue.
13.6.3.20.6 Exemples
13.6.3.20.6.1 Évolution du retour de getOldRawValue
Le document de l'exemple a son attribut my_numberone initialisé à -3.
use \Dcp\AttributeIdentifiers\MyFamily as Attributes\MyFamily; function printOldValue(Doc $doc) { printf( ' Valeur :'); var_dump($doc->getRawValue(Attributes\MyFamily::my_numberone)); printf( 'Ancienne Valeur :'); var_dump($doc->getOldRawValue(Attributes\MyFamily::my_numberone)); printf( "#---------------------\n"); } function updateValue(Doc $doc, $newValue){ if(null === $newValue){ printf(' efface valeur :null'); $doc->clearValue(Attributes\MyFamily::my_numberone, $newValue); } else { printf(' maj valeur :'); var_dump($newValue); $doc->setValue(Attributes\MyFamily::my_numberone, $newValue); } } /** @var \Dcp\Family\MyFamily */ $myDoc = new_Doc("", "MY_DOCUMENT"); if ($myDoc->isAlive()) { printOldValue($myDoc); updateValue($myDoc, 34); printOldValue($myDoc); updateValue($myDoc, 35); printOldValue($myDoc); updateValue($myDoc, 35); printOldValue($myDoc); updateValue($myDoc, null); printOldValue($myDoc); updateValue($myDoc, 35); printOldValue($myDoc); }
Le résultat :
Valeur :string(2) "-3" Ancienne Valeur :bool(false) #--------------------- maj valeur :int(34) Valeur :string(2) "34" Ancienne Valeur :string(2) "-3" #--------------------- maj valeur :int(35) Valeur :string(2) "35" Ancienne Valeur :string(2) "34" #--------------------- maj valeur :int(35) Valeur :string(2) "35" Ancienne Valeur :string(2) "34" #--------------------- efface valeur :null Valeur :string(0) "" Ancienne Valeur :string(2) "35" #--------------------- maj valeur :int(35) Valeur :string(2) "35" Ancienne Valeur :string(0) "" #---------------------
13.6.3.20.6.2 Utilisation dans un post-traitement
Mise à jour conditionnelle d'un attribut. L'attribut my_countchange enregistre
le nombre de fois que l'attribut my_numberone a été changé.
Soit la famille suivante :
| BEGIN | Ma famille | MYFAMILY | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| CLASS | My\MyFamily | ||||||||||
| // | idattr | idframe | label | T | A | type | ord | vis | … | phpfunc | |
| ATTR | MY_IDENTIFICATION | Identification | N | N | frame | 10 | W | ||||
| ATTR | MY_NUMBERONE | MY_IDENTIFICATION | nombre 1 | Y | N | int | 20 | W | |||
| ATTR | MY_COUTCHANGE | MY_IDENTIFICATION | nombre de changement | N | N | int | 30 | R | |||
| END |
Avec la classe :
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; class MyFamily extends \Dcp\Family\Document { protected function setMyCountChange() { $err=''; $oldValue=$this->getOldRawValue(MyAttributes::my_countchange); if ($oldValue !== false) { $cc=$this->getAttributeValue(MyAttributes::my_countchange); $err=$this->setAttributeValue(MyAttributes::my_countchange, $cc+1); } return $err; } public function postStore() { return $this->setMyCountChange(); } }
13.6.3.20.7 Notes
Dans le cas des attribut multi-valués, il est possible d'utiliser la méthode `Doc::rawValueToArray() pour avoir les différentes valeurs.
13.6.3.20.8 Voir aussi
13.6.3.21 Doc::getOldRawValues()
13.6.3.21.1 Description
string[] getOldRawValues ( )
Récupère la liste des valeurs des attributs modifié depuis l'instanciation de l'objet Document. Voir Doc::getOldRawValue() pour plus de détails.
13.6.3.21.1.1 Avertissements
Aucun.
13.6.3.21.2 Liste des paramètres
Aucun.
13.6.3.21.3 Valeur de retour
Retourne un tableau indexé par l'identifiant de l'attribut (en minuscules). Chaque attribut modifié a sa propre entrée dans le tableau. Les attributs non modifiés n'ont pas d'entrée dans le tableau.
13.6.3.21.4 Erreurs / Exceptions
Aucune.
13.6.3.21.5 Historique
Cette méthode était anciennement nommée getOldValues.
13.6.3.21.6 Exemples
Soit la famille suivante :
| BEGIN | Ma famille | MYFAMILY | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| CLASS | My\MyFamily | ||||||||||
| // | idattr | idframe | label | T | A | type | ord | vis | ... | phpfunc | |
| ATTR | MY_IDENTIFICATION | Identification | N | N | frame | 10 | W | ||||
| ATTR | MY_REDACTOR | MY_IDENTIFICATION | rédacteur | N | N | account | 30 | W | |||
| ATTR | MY_NUMBERONE | MY_IDENTIFICATION | nombre 1 | Y | N | int | 20 | W | |||
| ATTR | MY_NUMBERTWO | MY_IDENTIFICATION | nombre 2 | N | N | int | 30 | W | |||
| ATTR | MY_SUM | MY_IDENTIFICATION | nombre 1+2 | N | N | int | 30 | R | ::mySum(MY_NUMBERONE, MY_NUMBERTWO) | ||
| END |
Avec la classe :
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; class MyFamily extends \Dcp\Family\Document { public function mySum($x, $y) { return ($x + $y); } }
Le code suivant indique le résultat de getOldRawvalues().
if ($myDoc->isAlive()) { print "### Valeurs initiales ### \n"; print_r($myDoc->getValues()); $myDoc->setValue(Attributes\MyFamily::my_numberone, 342); $myDoc->setValue(Attributes\MyFamily::my_numbertwo, 352); $myDoc->refresh(); print "### Nouvelles valeurs ### \n"; print_r($myDoc->getValues()); print "### Anciennes valeurs modifiées ### \n"; print_r($myDoc->getOldRawValues()); }
Résultat :
### Valeurs initiales ### Array ( [my_numberone] => 34 [my_numbertwo] => 35 [my_sum] => 69 [my_redactor] => 5838 ) ### Nouvelles valeurs ### Array ( [my_numberone] => 342 [my_numbertwo] => 352 [my_sum] => 694 [my_redactor] => 5838 ) ### Anciennes valeurs modifiées ### Array ( [my_numberone] => 34 [my_numbertwo] => 35 [my_sum] => 69 )
13.6.3.21.7 Notes
Aucunes.
13.6.3.21.8 Voir aussi
13.6.3.22 Doc::getPropertyValue()
La méthode getPropertyValue permet d'obtenir les valeurs des
propriétés du document courant.
13.6.3.22.1 Description
string|bool(false) getPropertyValue ( string $prop )
La méthode getPropertyValue permet d'obtenir les valeurs des
propriétés du document courant (telles que id, initid,
revision, etc.).
13.6.3.22.1.1 Avertissements
Aucun.
13.6.3.22.2 Liste des paramètres
- (string)
prop - Le nom de la propriété dont on souhaite obtenir la valeur.
13.6.3.22.3 Valeur de retour
La méthode retourne la valeur de la propriété demandée, ou false si la
propriété demandée n'existe pas.
13.6.3.22.4 Erreurs / Exceptions
La méthode retourne false si la propriété demandée n'existe pas.
13.6.3.22.5 Historique
13.6.3.22.5.1 Release 3.2.5
La méthode getPropertyValue remplace la méthode précédemment nommée
getProperty.
L'utilisation de getProperty est obsolète depuis la version 3.2.5 de
dynacase-core.
13.6.3.22.6 Exemples
- Exemple #1
/* * Obtenir la date de création du document. */ $cdate = $doc->getPropertyValue('cdate');
13.6.3.22.7 Notes
Aucune.
13.6.3.22.8 Voir aussi
13.6.3.23 Doc::getState()
La méthode getState permet d'obtenir le nom de l'état du document sur son
cycle de vie associé.
13.6.3.23.1 Description
string getState ( void )
La méthode getState retourne le nom de l'état du document si
celui-ci est associé à un cycle de vie.
13.6.3.23.1.1 Avertissements
Aucun.
13.6.3.23.2 Liste des paramètres
Aucun.
13.6.3.23.3 Valeur de retour
La méthode retourne le nom de l'état du document si celui-ci est associé à un cycle de vie. Si le document ne possède pas de cycle, alors une chaîne vide est retournée.
13.6.3.23.4 Erreurs / Exceptions
Aucune.
13.6.3.23.5 Historique
Aucun.
13.6.3.23.6 Exemples
- Exemple #1
Contrôler que la facture est dans l'état Payée (PAID) :
$state = $facture->getState(); if ($state !== 'PAID') { throw new Exception(sprintf( "La facture '%s' n'est pas dans l'état payée.", $facture->getTitle() )); }
13.6.3.23.7 Notes
Cette fonction est un raccourci vers la propriété state du document.
Pour avoir la version affichée dans l'interface de l'état, il suffit de traduire
celui-ci avec la fonction _.
13.6.3.23.8 Voir aussi
13.6.3.24 Doc::getTitle()
La méthode getTitle permet de récupérer le titre d'un document.
13.6.3.24.1 Description
string getTitle ( mixed $id = -1, string $def = "", bool $latest = false )
La méthode getTitle permet de récupérer le titre
- du document courant,
- d'un document donné en spécifiant son identifiant (numérique ou logique),
- ou d'un ensemble de document en spécifiant leur identifiants (numérique ou logique).
13.6.3.24.1.1 Avertissements
Bien que la méthode getTitle accepte de travailler sur plusieurs documents,
il est préférable d'utiliser la classe DocTitle pour travailler sur un grand
nombre de documents.
13.6.3.24.2 Liste des paramètres
- (mixed)
id -
idpermet de spécifier le ou les documents dont on souhaite obtenir le titre.Si
idest égal à -1, alors le titre du document courant est retourné.Si
idest l'identifiant numérique ou le nom logique d'un document, alors le titre du document correspondant est retourné.Si
idest une chaîne de caractère contenant le caractère\nou la séquence<BR>, alorsidest traité comme étant une liste d'identifiants de documents (format issu deDoc::arrayToRawValue), et le résultat retourné est la concaténation avec le caractère de séparation\ndes titres des documents correspondant à ces identifiants.Attention : Dans le cas où
idest un array, la valeur par défaut est retournée, sans erreur.La valeur par défaut de
idest -1. - (string)
def -
defpermet de spécifier la valeur par défaut qui sera retournée si le document demandé n'existe pas.Par défaut, la valeur par défaut est une chaîne vide.
- (bool)
latest -
latestpermet de spécifier si l'on souhaite obtenir le titre de la dernière révision du document.Par défaut,
latestest égal àfalseet donc c'est le titre du document référencé par l'identifiant qui est retourné (et non celui de la dernière révision).
13.6.3.24.3 Valeur de retour
La méthode retourne une chaîne de caractère contenant le titre du document
demandé, ou les titres des documents demandés, séparés par le caractère \n.
13.6.3.24.4 Erreurs / Exceptions
Aucune.
13.6.3.24.5 Historique
Aucun.
13.6.3.24.6 Exemples
-
Exemple #1
var_dump($doc->getTitle());
Résultat :
string(22) "Titre document courant"
-
Exemple #2
var_dump($doc->getTitle(1234));
Résultat :
string(19) "Titre document 1234"
-
Exemple #3
var_dump($doc->getTitle($doc->arrayToRawValue(array(1234, 2345, 3456))));
Résultat :
string(59) "Titre document 1234 Titre document 2345 Titre document 3456"
13.6.3.24.7 Notes
Si le document, dont on souhaite obtenir le titre, est
confidentiel, et que l'utilisateur courant n'a pas le droit
confidential, alors la titre retourné est "document confidentiel".
13.6.3.24.8 Voir aussi
13.6.3.25 Doc::getRawValue()
13.6.3.25.1 Description
string getRawValue ( string $idAttribute, mixed $defaultValue = "" )
Cette méthode retourne la valeur d'un attribut telle qu'elle est inscrite en base de données. Le type retourné est toujours une chaîne de caractères quel que soit le type d'attribut.
13.6.3.25.1.1 Avertissements
Aucun.
13.6.3.25.2 Liste des paramètres
- (string)
idAttribute - Identifiant de l'attribut
- (string)
defaultValue - Valeur par défaut à retourner si la valeur est vide ou si l'attribut n'existe pas
13.6.3.25.3 Valeur de retour
Si l'attribut du document existe et s'il n'est pas vide, sa valeur brute est retournée.
Cette méthode retourne tout attribut de la classe sans vérification. Si cet attribut est non existant ou vide alors c'est la valeur par défaut qui sera retournée.
13.6.3.25.4 Erreurs / Exceptions
Aucune erreur retournée.
13.6.3.25.5 Historique
Cette méthode était anciennement nommée getValue.
13.6.3.25.6 Exemples
Soit la famille suivante :
| BEGIN | Ma famille | MYFAMILY | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| CLASS | My\MyFamily | ||||||||||
| // | idattr | idframe | label | T | A | type | ord | vis | … | phpfunc | |
| ATTR | MY_IDENTIFICATION | Identification | N | N | frame | 10 | W | ||||
| ATTR | MY_NUMBERONE | MY_IDENTIFICATION | nombre 1 | Y | N | int | 20 | W | |||
| ATTR | MY_NUMBERTWO | MY_IDENTIFICATION | nombre 2 | N | N | int | 30 | W | |||
| ATTR | MY_SUM | MY_IDENTIFICATION | nombre 1+2 | N | N | int | 30 | R | ::mySum(MY_NUMBERONE, MY_NUMBERTWO) | ||
| END |
Utilisation des valeurs de my_numberone et my_numbertwo pour la méthode
mySum de l'attribut calculé my_sum.
Avec la classe :
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; class MyFamily extends \Dcp\Family\Document { public function mySum($x, $y) { $n1 = intval($this->getRawValue(MyAttributes::my_numberone)); // si "my_number_two" est vide, alors, la valeur sera 543 $n2 = intval($this->getRawValue(MyAttributes::my_numbertwo, "543"));
return ($n1 + $n2);
}
}
Vérification de l'attribut my_sum en fonction des valeurs de my_numberone et
my_numbertwo
use \Dcp\AttributeIdentifiers\MyFamily as Attributes\MyFamily; /** @var \Dcp\Family\MyFamily */ $myDoc = new_Doc("", "MY_DOCUMENT"); if ($myDoc->isAlive()) { $n1=intval($myDoc->getRawValue(Attributes\MyFamily::my_numberone)); $n2=intval($myDoc->getRawValue(Attributes\MyFamily::my_numbertwo, "543")); $sum=intval($myDoc->getRawValue(Attributes\MyFamily::my_sum)); if ($sum != ($n1 +$n2)) { printf("La somme est incorrecte : %d + %d <> %d ! \n", $n1, $n2, $sum); } }
13.6.3.25.7 Notes
Format brut en fonction des types d'attributs :
date- les dates sont retournées sous la forme "YYYY-MM-DD".
timestamp- les horo-dates sont retournées sous la forme "YYYY-MM-DD HH:MM:SS".
time- les temps sont retournés sous la forme "HH:MM:SS".
-
file,image - les pointeurs de fichiers sous la forme "[mimeType]|[vaultId]|[fileName]"
htmltext- le texte retourné est un fragment html dont les entités html (caractères accentués notamment) ont été convertis en caractères utf-8.
Pour les autres types, aucun formatage spécial n'est appliqué, la valeur brute correspond à la valeur donnée.
Pour les valeurs multiples, chaque valeur est séparée par le caractère \n
(retour chariot). Si une des valeurs multiples contient un retour chariot,
celui-ci est remplacé par les caractères <BR>.
Pour les multiples à 2 niveaux (attribut multiple dans un tableau), le premier
niveau a comme séparateur le caractère '\n' et le deuxième niveau les caractères
"
".
Exemple : "1234\n567<BR>8876<BR>987\n678<BR>295"
indique la structure à 2 niveaux suivante :
- -
- 1234
- -
- 567
- 8876
- 987
- -
- 678
- 295
13.6.3.25.8 Voir aussi
13.6.3.26 Doc::getAttributeValue()
13.6.3.26.1 Description
mixed getAttributeValue ( string $idAttribute )
Retourne la valeur d'un attribut du document.
13.6.3.26.1.1 Avertissements
Le retour de cette méthode peut être utilisé pour mettre à jour des valeurs avec la méthode Doc::setAttributeValue(). Par contre, ces valeurs typées sont incompatibles avec la méthode Doc::setValue() qui prend en argument des valeurs brutes.
13.6.3.26.2 Liste des paramètres
- [int] (string)
idAttribute - Identifiant de l'attribut
13.6.3.26.3 Valeur de retour
Retourne la valeur typée de l'attribut en fonction des types d'attributs :
-
date,timestamp - Les dates sont retournées avec un objet de la classe
DateTime(classe interne de PHP). time- Les temps sont retournés avec le type
stringsous la forme "HH:MM:SS". -
file,image - Les pointeurs de fichiers sont retournés sous la forme "[mimeType]|[vaultId]|[fileName]".
int- Les nombres entiers sont retournés avec le type
int. -
double,money - Les nombres décimaux sont retournés avec le type
float.
Les autres types sont retournés sous forme de chaîne de caractère (type
string).
Les valeurs multiples sont retournées avec un objet de type array. Les valeurs
multiples ayant aussi des valeurs multiples (cas des attributs multiples dans
les tableaux) sont retournés avec un objet de type array[] (tableau à 2
dimensions).
Si une valeur est vide, la valeur null sera retournée. Dans le cas d'un
attribut multiple, le retour pour une valeur vide (aucune valeur) sera un
tableau vide array().
Pour les attributs de type array, la valeur retournée est un tableau à deux
dimensions. La première dimension est l'index (numérique - 0 à n) de la
rangée et la deuxième est l'identifiant de l'attribut. Chaque élément contient
une valeur typée.
13.6.3.26.4 Erreurs / Exceptions
Retourne une exception Dcp\Exception dans les cas suivants :
- L'attribut n'existe pas
- ou si l'attribut est un attribut ne contenant pas de valeur (type
tab,frameoumenu).
13.6.3.26.5 Historique
Aucun.
13.6.3.26.6 Exemples
Soit la famille suivante :
| BEGIN | Ma famille | MYFAMILY | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CLASS | My\MyFamily | |||||||||||
| DFLDID | auto | |||||||||||
| ICON | classe.png | |||||||||||
| // | idattr | idframe | label | T | A | type | ord | vis | need | link | phpfile | phpfunc |
| ATTR | MY_IDENTIFICATION | Identification | N | N | frame | 10 | W | |||||
| ATTR | MY_NUMBERONE | MY_IDENTIFICATION | nombre 1 | Y | N | int | 20 | W | ||||
| ATTR | MY_NUMBERTWO | MY_IDENTIFICATION | nombre 2 | N | N | int | 30 | W | ||||
| ATTR | MY_SUM | MY_IDENTIFICATION | Nombre 1+2 | N | N | int | 40 | R | ::mySum(MY_NUMBERONE, MY_NUMBERTWO) | |||
| ATTR | MY_REDACTOR | MY_IDENTIFICATION | Rédacteur | N | N | account | 50 | W | ||||
| ATTR | MY_REF | MY_IDENTIFICATION | référence | N | N | text | 70 | W | ||||
| ATTR | MY_T_PARTNER | MY_IDENTIFICATION | Participants | N | N | array | 80 | W | ||||
| ATTR | MY_COAUTHORS | MY_T_PARTNER | Co-auteurs | N | N | account | 90 | W | ||||
| ATTR | MY_CODATE | MY_T_PARTNER | Dates d'entrée | N | N | date | 100 | W | ||||
| END |
Vérification de l'attribut my_sum en fonction des valeurs de my_numberone et
my_numbertwo
use \Dcp\AttributeIdentifiers\MyFamily as Attributes\MyFamily; /** @var \Dcp\Family\MyFamily */ $myDoc = new_Doc("", "MY_DOCUMENT"); if ($myDoc->isAlive()) { $n1=$myDoc->getAttributeValue(Attributes\MyFamily::my_numberone); $n2=$myDoc->getAttributeValue(Attributes\MyFamily::my_numbertwo); $sum=$myDoc->getAttributeValue(Attributes\MyFamily::my_sum); if ($sum != ($n1 + $n2)) { printf("La somme est incorrecte : %d + %d <> %d ! \n", $n1, $n2, $sum); } }
Retour d'un tableau. Le document a deux rangées.
use \Dcp\AttributeIdentifiers\MyFamily as Attributes\MyFamily; /** @var \Dcp\Family\MyFamily */ $myDoc = new_Doc("", "MY_DOCUMENT"); if ($myDoc->isAlive()) { $partipants=$myDoc->getAttributeValue(Attributes\MyFamily::my_t_partner); print_r($partipants); }
Array ( [0] => Array ( [my_coauthors] => "5838" [my_codate] => DateTime Object ( [date] => "2013-07-04 00:00:00" [timezone_type] => 3 [timezone] => Europe/Paris ) ) [1] => Array ( [my_coauthors] => "5837" [my_codate] => DateTime Object ( [date] => "2013-06-11 00:00:00" [timezone_type] => 3 [timezone] => "Europe/Paris" ) ) )
13.6.3.26.7 Notes
Aucunes.
13.6.3.26.8 Voir aussi
13.6.3.27 Doc::isAlive()
La méthode isAlive permet de savoir si un document est vivant
(s'il existe et n'a pas été supprimé).
13.6.3.27.1 Description
bool isAlive ( void )
La méthode isAlive permet de savoir si un document est vivant.
Un document est vivant si :
- le document est stocké en base de données ;
- la propriété
doctypeest différente deZ.
13.6.3.27.1.1 Avertissements
Aucun.
13.6.3.27.2 Liste des paramètres
Aucune.
13.6.3.27.3 Valeur de retour
La méthode retourne true si le document est vivant ou false dans le
cas contraire.
13.6.3.27.4 Erreurs / Exceptions
Aucune.
13.6.3.27.5 Historique
Aucun.
13.6.3.27.6 Exemples
- Exemple #1
$facture = new_Doc('', $id); if (!$facture->isAlive()) { throw new Exception( sprintf("Le document avec l'identifiant '%d' n'existe pas ou a été supprimé.", $id) ); }
- Exemple #2
/* * $facture est un objet qui n'existe qu'en mémoire, * par conséquent, isAlive() retourne `false` */ $facture = createDoc('', 'FACTURE'); var_dump($facture->isAlive()); /* * Une fois l'objet sauvegardé en base de données * isAlive() retourne alors `true` */ $facture->store(); var_dump($facture->isAlive());
Résultat :
bool(false) bool(true)
13.6.3.27.7 Notes
Aucune.
13.6.3.27.8 Voir aussi
- Propriété
doctype - Méthode
DbObj::isAffected
13.6.3.28 Doc::isChanged()
La méthode isChanged permet de savoir si des valeurs d'attributs du document
ont été changées.
13.6.3.28.1 Description
bool isChanged ( void )
La méthode isChanged permet de savoir si des attributs du document ont été
changés via l'utilisation de méthodes de modification des valeurs d'attributs
(par exemple Doc::setValue ou
Doc::clearValue).
13.6.3.28.1.1 Avertissements
Aucun.
13.6.3.28.2 Liste des paramètres
Aucun.
13.6.3.28.3 Valeur de retour
La méthode retourne true si au moins une valeur a été changée, ou false si
aucune valeur n'a été changée.
13.6.3.28.4 Erreurs / Exceptions
Aucune.
13.6.3.28.5 Historique
Aucun.
13.6.3.28.6 Exemples
- Exemple #1
Lors de la validation du formulaire d'édition d'un document, il est possible de
détecter avec la méthode isChange si l'utilisateur a changé la valeur d'un
attribut ou non.
namespace Facturation; class Facture extends \Dcp\Family\Document { public postStore() { if (($err = parrent::postStore()) != '') { return $err; } /* * Régénérer le PDF seulement si quelque chose * a été changé sur la facture. */ if ($this->isChanged()) { return $this->generate_PDF(); } return ''; } }
13.6.3.28.7 Notes
Le statut de modification est remis à false après le déclenchement des
méthodes Doc::postInsert et Doc::postUpdate.
13.6.3.28.8 Voir aussi
13.6.3.29 Doc::getLatestId()
La méthode getLatestId permet d'obtenir l'identifiant de la dernière révision
du document.
13.6.3.29.1 Description
int|bool(false) getLatestId ( bool $fixed = false, bool $forcequery = false )
Si le document est révisable, ou est associé à un cycle de vie, alors la méthode
getLatestId permet d'obtenir l'identifiant de la dernière révision du
document.
13.6.3.29.1.1 Avertissements
Aucun.
13.6.3.29.2 Liste des paramètres
- (bool)
fixed -
fixedpermet d'indiquer qu'on souhaite obtenir l'identifiant de la dernière révision figée (voir propriétélmodify).Par défaut
fixedvautfalse, et c'est l'identifiant de la dernière révision qui est retourné (indépendamment du fait que ce soit une révision figée ou non). - (bool)
forcequery -
forcequerypermet de forcer l'exécution d'une requête en base de données pour rechercher la dernière révision.Par défaut
forcequeryvautfalse, et une nouvelle requête en base de données n'est pas exécutée pour la recherche de la dernière révision. Si ce paramètre n'est pas passé àtruel'idretourné est le dernieridconnu lors de la récupération du document en base.
13.6.3.29.3 Valeur de retour
La méthode retourne l'identifiant de la dernière révision lorsque cette dernière
est trouvée, sinon le booléen false est retourné en cas d'erreur.
13.6.3.29.4 Erreurs / Exceptions
La méthode retourne false si :
- la propriété
iddu document est vide.
13.6.3.29.5 Historique
13.6.3.29.5.1 Release 3.2.5
La méthode getLatestId remplace la méthode précédemment nommée latestId.
L'utilisation de latestId est obsolète depuis la version 3.2.5 de
dynacase-core.
13.6.3.29.6 Exemples
- Exemple #1
/* * Obtenir l'identifiant de la dernière révision * de la facture. */ $latestId = $facture->getLatestId(); /* * Imprimer cette dernière révision de la facture. */ imprimerFacture($latestId);
13.6.3.29.7 Notes
Aucune.
13.6.3.29.8 Voir aussi
13.6.3.30 Doc::rawValueToArray()
La méthode rawValueToArray permet de dé-sérialiser la valeur d'un attribut
faisant partie d'un array ou d'un attribut
multi-valué.
13.6.3.30.1 Description
array rawValueToArray ( string $v )
La méthode rawValueToArray permet de dé-sérialiser une valeur sous la forme
d'une chaîne de caractères issue d'un attribut faisant parti d'un
array, ou d'un attribut multi-valué, obtenue
via la méthode Doc::getRawValue.
13.6.3.30.1.1 Avertissements
La méthode rawValueToArray est une méthode de bas niveau que vous ne devriez
utiliser qu'en dernier recours.
Il faut privilégier l'utilisation de la méthode
getAttributeValue qui prend en charge
automatiquement ces opérations de dé-sérialisation.
13.6.3.30.2 Liste des paramètres
- (string)
v - La chaîne de caractères à dé-sérialiser.
13.6.3.30.3 Valeur de retour
La méthode rawValueToArray retourne un array contenant les valeurs issues de
la chaîne de caractères fournie.
13.6.3.30.4 Erreurs / Exceptions
Aucune.
13.6.3.30.5 Historique
13.6.3.30.5.1 Release 3.2.5
La méthode rawValueToArray remplace la méthode précédemment nommée
_val2array.
L'utilisation de _val2array est obsolète depuis la version 3.2.5 de
dynacase-core.
13.6.3.30.6 Exemples
-
Exemple #1
L'attribut
PHOTO_KEYWORDSest un attribut de type texte avec l'option multiple.$v = $photo->getRawValue(\Dcp\AttributeIdentifiers\MyPhoto:photo_keywords); var_dump($photo->rawValueToArray($v));
Résultat :
array(4) { [0]=> string(11) "Tour Eiffel" [1]=> string(13) "Champ de Mars" [2]=> string(5) "Paris" [3]=> string(6) "France" }
13.6.3.30.7 Notes
Aucune.
13.6.3.30.8 Voir aussi
13.6.3.31 Doc::removeArrayRow()
La méthode removeArrayRow permet de supprimer une ligne d'un attribut de
type array.
13.6.3.31.1 Description
string removeArrayRow ( string $idAttr, int $index )
La méthode removeArrayRow permet de supprimer une ligne à un indice donnée
dans un attribut de type array.
La ligne supprimée entraîne un décalage des lignes d'indice supérieur, qui descendent alors toutes d'un cran.
13.6.3.31.1.1 Avertissements
Lors de chaque appel à removeArrayRow, un setValue est effectué pour chacune
des colonnes de l'array. Pour supprimer de nombreuses lignes, il peut être plus
efficace de gérer manuellement la suppression dans chaque colonne.
13.6.3.31.2 Liste des paramètres
- (string)
idAttr - Le nom de l'attribut de type
arraydans lequel on souhaite supprimer une ligne. - (int)
index -
indexpermet de spécifier l'indice (à partir de 0) de la ligne qu'on souhaite supprimer.Si
indexest inférieur à 0 ou supérieur ou égal au nombre de lignes du tableau, alors le tableau n'est pas modifié et reste inchangé.
13.6.3.31.3 Valeur de retour
La méthode retourne une chaîne vide s'il n'y a pas d'erreur, ou une chaîne non-vide contenant le message d'erreur dans le cas contraire.
13.6.3.31.4 Erreurs / Exceptions
Une erreur est retournée si :
- l'attribut
idAttrn'est pas de typearray.
13.6.3.31.5 Historique
Aucun.
13.6.3.31.6 Exemples
-
Exemple #1
/* Soit le tableau `MyPhoto::faces` composé comme suit : +-----------+----------+ | Firstname | Lastname | +===========+==========+ #0 | Bart | Simpson | #1 | Marge | Simpson | #2 | Lisa | Simpson | #3 | Homer | Simpson | +-----------+----------+ */ $photo->removeArrayRow(\Dcp\AttributeIdentifier\MyPhoto::faces, 0) /* Après la suppression de la première ligne (indice 0) : +-----------+----------+ | Firstname | Lastname | +===========+==========+ #0 | Marge | Simpson | #1 | Lisa | Simpson | #2 | Homer | Simpson | +-----------+----------+ */ $photo->removeArrayRow(\Dcp\AttributeIdentifier\MyPhoto::faces, 1) /* Après la suppression de la ligne entre Marge et Homer (indice 1) : +-----------+----------+ | Firstname | Lastname | +===========+==========+ #0 | Marge | Simpson | #1 | Homer | Simpson | +-----------+----------+ */
13.6.3.31.7 Notes
Aucune.
13.6.3.31.8 Voir aussi
13.6.3.32 Doc::refresh()
Méthode utilisée pour mettre à jour les attributs calculés.
13.6.3.32.1 Description
string refresh ()
Cette méthode est appelée depuis l'interface lors de la consultation du document unitaire mais pas depuis les interfaces présentant les listes de documents.
Cette méthode est appelée depuis la méthode Doc::store().
13.6.3.32.1.1 Avertissements
Les attributs calculés en visibilité "I" ne sont pas mis à jour. La visibilité appliquée est celle donnée par le contrôle de vue (vue par défaut).
13.6.3.32.2 Liste des paramètres
Aucun paramètre.
13.6.3.32.3 Valeur de retour
Cette méthode retourne les message fournis par les hameçons
preRefresh() et postRefresh(). Ce message
est présenté sur l'interface web de consultation de document lors de l'affichage
du document.
13.6.3.32.4 Erreurs / Exceptions
Aucune.
13.6.3.32.5 Historique
Aucun.
13.6.3.32.6 Exemples
Actualisation d'un ensemble de documents.
$s=new SearchDoc("", "MYFAMILY"); $s->setObjectReturn(); $dl=$s->search()->getDocumentList(); $messages=array(); /** @var Doc $doc */ foreach ($dl as $doc) { $messages[$doc->id]=$doc->refresh(); }
13.6.3.32.7 Notes
Lors de l'actualisation du document les hameçons suivants sont lancés :
Doc::preRefresh()- Calcul des attributs calculés
Doc::postRefresh()- Enregistrement en base si modification détectée
Les affectations des attributs calculés sont réalisées par la
méthode specRefreshGen() qui est générée lors de l'importation de la famille.
Cette méthode est appelée entre les hameçons
Doc::preRefresh() et Doc::postRefresh().
Les méthodes Doc::preRefresh() et Doc::specRefreshGen() sont exécutés en
inhibant le contrôle des droits (utilisation
Doc::disableEditControl()).
13.6.3.32.8 Voir aussi
13.6.3.33 Doc::revise()
13.6.3.33.1 Description
string revise ( string $comment = '' )
Le document courant est enregistré en base et est figé. Sa propriété locked
vaut alors -1. La méthode Doc::isFixed() permet de savoir si un document est
figé.
Une copie du document est créée. Un nouvel identifiant est créé et est affecté à
la propriété id. Le document conserve le même identifiant initial (propriété
initid) et son numéro de révision (propriété revision) est incrémenté de un.
L'objet courant devient le nouveau document avec un nouvel identifiant.
13.6.3.33.1.1 Avertissements
Un document figé ne peut pas être révisé. Un document qui n'a pas d'identifiant ne peut pas être révisé.
13.6.3.33.2 Liste des paramètres
- (string)
comment - Si
commentn'est pas vide, le message sera ajouté à l'historique avant la révision.
13.6.3.33.3 Valeur de retour
Message d'erreur : Si un message non vide est retourné alors la révision a été abandonnée (la raison est donnée par le message d'erreur).
13.6.3.33.4 Erreurs / Exceptions
Les causes d'erreur sont :
- document figé,
- problème de droits : la révision nécessite le droit
editsur le document et le droitcreatesur la famille du document, - retour d'erreur de l'hameçon preRevise().
13.6.3.33.5 Historique
Cette méthode était anciennement nommée addRevision.
13.6.3.33.6 Exemples
Exemple de création d'une révision.
/** @var \Dcp\Family\MyFamily */ $d = new_Doc("", "MY_DOCUMENT"); if ($d->isAlive()) { printf("Identifiant %d\n", $d->id); $err=$d->revise(); if (empty($err)) { printf("Nouvel identifiant %d", $d->id); } else { printf("Erreur de révision %s", $err); } }
13.6.3.33.7 Notes
Lors d'un ajout de documents les hameçons suivants sont lancés :
-
Doc::preRevise() - Fige le document et enregistrement en base
-
Doc::preCreated() - Copie du document et création nouvel identifiant
Doc::postCreated()-
Doc::postRevise()
13.6.3.33.7.1 Hameçon preRevise
L'hameçon preRevise a pour rôle de valider les conditions de révision du
document. Si cette méthode retourne une chaîne de caractère non-vide alors elle
est considérée comme un retour d'erreur et la révision n'est pas effectuée.
Ce message est retourné par la méthode Doc::revise().
13.6.3.33.7.2 Hameçon postRevise
L'hameçon postRevise a pour rôle de réaliser un post-traitement après la
révision. Cette méthode utilise la nouvelle révision. Si cette méthode retourne
une chaîne de caractères non-vide alors elle est considérée comme un message
d'erreur. Ce message est enregistré dans l'historique du document.
13.6.3.33.8 Voir aussi
13.6.3.34 Doc::setState()
La méthode setState permet de changer l'état d'un document sur son cycle de
vie associé.
13.6.3.34.1 Description
string setState ( string $newstate, string $comment = '', bool $force = false, bool $withcontrol = true, bool $wm1 = true, bool $wm2 = true, bool $wneed = true, bool $wm0 = true, bool $wm3 = true, string & $msg = '' )
La méthode setState permet de changer l'état du document si celui-ci est
associé à un cycle de vie.
13.6.3.34.1.1 Avertissements
Aucun.
13.6.3.34.2 Liste des paramètres
- (string)
newstate -
newstateest le nom de l'état (de destination) dans lequel on souhaite mettre le document. - (string)
comment -
commentpermet de spécifier un commentaire facultatif qui est inscrit dans l'historique du document suite à son changement d'état.Par défaut
commentest une chaîne vide, et aucun message additionnel n'est inscrit dans l'historique du document. - (bool)
force -
forcepermet de forcer le changement d'état pour le cas ou l'état demandé n'est pas associé à une transition valide du cycle de vie.Par défaut
forceest àfalse, et le nouvel état demandé (de destination) doit alors avoir une transition valide avec l'état actuel (de départ) du document. - (bool)
withcontrol -
withcontrolpermet de désactiver le contrôle des droits sur les transitions du cycle.Par défaut
withcontrolest àtrue, et le contrôle des droits sur les transitions du cycle est appliqué. - (bool)
wm1 -
wm1permet de spécifier si la méthodem1de la transition doit être appliquée.Par défaut
wm1est àtrue, et la méthodem1de la transition est appliquée. - (bool)
wm2 -
wm2permet de spécifier si la méthodem2de la transition doit être appliquée.Par défaut
wm2est àtrue, et la méthodem2de la transition est appliquée. - (bool)
wneed -
wneedpermet de spécifier si le contrôle des attributs obligatoire du document doit être appliqué.Par défaut
wneedest àtrue, et le contrôle des attributs obligatoire du document est appliqué. - (bool)
wm0 -
wm0permet de spécifier si la méthodem0de la transition doit être appliquée.Par défaut
wm0est àtrue, et la méthodem0de la transition est appliquée. - (bool)
wm3 -
wm3permet de spécifier si la méthodem3de la transition doit être appliquée.Par défaut
wm3est àtrue, et la méthodem3de la transition est appliquée. - [out] (string)
msg -
msgest une référence facultative à une chaîne de caractères qui est retournée par la méthode et qui contient les messages retournées par les méthodesm1,m2et l'émission des mails déclarés sur le cycle.
13.6.3.34.3 Valeur de retour
La méthode retourne une chaîne vide s'il n'y a pas d'erreurs, ou une chaîne non-vide contenant un message d'erreur si la transition n'a pas pu être réalisée.
13.6.3.34.4 Erreurs / Exceptions
La méthode retourne un message d'erreur si :
- L'état
newstatedemandé est vide ; - Le document n'a pas de cycle de vie ;
- Le cycle de vie associé au document n'existe pas ;
- Le cycle de vie associé au document est corrompu (ex. syntaxe PHP invalide) ;
- L'état
newstatede destination n'existe pas ou n'est pas associé à une transition valide et queforceest àfalse; - L'état
newstatede destination n'existe pas ou n'est pas associé à une transition valide et que l'utilisateur n'est pas le super-utilisateuradmin; -
wm0est àtrueet la méthodem0n'existe pas ; -
wm0est àtrueet l'exécution de la méthodem0à retournée un message d'erreur ; -
wm1est àtrueet la méthodem1n'existe pas ; -
wm1est àtrueet l'exécution de la méthodem1à retournée un message d'erreur ; -
wneedest àtrueet le contrôle des attributs obligatoire à retourné un message d'erreur (ex. des attributs obligatoires ne sont pas remplis) ; - La revision ou l'inscription du document en base de données ont retourné un message d'erreur ;
-
wm2est àtrueet la méthodem2n'existe pas ; -
wm3est àtrueet la méthodem3n'existe pas ; - Le changement d'affectation du document déclaré sur le cycle à retourné un message d'erreur.
13.6.3.34.5 Historique
Aucun.
13.6.3.34.6 Exemples
- Exemple #1
/* * Mettre la facture dans l'état Archivé */ $err = $facture->setState('ST_ARCHIVED'); if ($err != '') { throw new Exception( sprintf("La facture n'a pu être archivée: %s", $err) ); }
13.6.3.34.7 Notes
Pour qu'il y ait changement d'état, il faut que l'état newstate de destination
demandé ait une transition valide depuis l'état de départ actuel du document.
S'il n'y a pas de transitons entre l'état de départ actuel du document et le
nouvel état newstate demandé, alors une erreur est remontée.
Dans ce cas, si vous voulez quand même mettre le document dans l'état
newstate, alors il faut utiliser le paramètre force avec la valeur true.
13.6.3.34.8 Voir aussi
13.6.3.35 Doc::setValue()
Modifie la valeur brute d'un attribut de document.
13.6.3.35.1 Description
string setValue ( string $attributeIdentifier, string|string[] $value, int $index = - 1, int &$kvalue = null )
Modifie la valeur d'un attribut de l'objet Document. La modification n'est pas enregistrée en base de données.
13.6.3.35.1.1 Avertissements
Pour enregistrer la modification , il est nécessaire d'appeler la méthode
Doc::store().
Les résultats fournis par la méthode
Doc::getAttributeValue() ne peuvent pas être utilisés
directement par cette méthode.
Si la valeur est une chaîne vide ou égale à null, alors la valeur de
l'attribut n'est pas modifiée. Si la valeur est égale à un espace , la
valeur est effacée.
Les espaces et certains caractères invisibles en début et fin de valeur sont
supprimés. La fonction trim est utilisée pour réaliser cette
suppression.
13.6.3.35.2 Liste des paramètres
- (string)
attributeIdentifier - Identifiant de l'attribut à modifier.
- (string|string[])
value - Nouvelle valeur brute. Dans le cas d'un attribut multiple, il est possible d'indiquer les différentes valeurs brutes dans un tableau.
- (int)
index - Dans le cas où l'attribut est multiple, indique l'index de la valeur à modifier.
- (int)
kvalue - En cas d'erreur et dans le cas où l'attribut est multiple, indique l'index de la première valeur erronée de l'attribut multiple.
13.6.3.35.3 Valeur de retour
Message d'erreur. Retourne une chaîne vide s'il n'y a pas d'erreur.
13.6.3.35.4 Erreurs / Exceptions
En cas d'erreur, un message non vide est retourné. Les principales causes d'erreurs sont :
- Insuffisance de privilèges. Nécessite le droit
edit. - Attribut inexistant.
- Contenu de la valeur incohérent par rapport au type d'attribut.
-
Visibilité
Isur l'attribut.
13.6.3.35.5 Historique
Aucun.
13.6.3.35.6 Exemples
Calcul de la somme des attributs my_numberone et my_numbertwo et
enregistrement dans l'attribut my_sum.
Soit la famille suivante :
| BEGIN | Ma famille | MYFAMILY | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| CLASS | My\MyFamily | ||||||||||
| // | idattr | idframe | label | T | A | type | ord | vis | … | phpfunc | |
| ATTR | MY_IDENTIFICATION | Identification | N | N | frame | 10 | W | ||||
| ATTR | MY_NUMBERONE | MY_IDENTIFICATION | nombre 1 | Y | N | int | 20 | W | |||
| ATTR | MY_NUMBERTWO | MY_IDENTIFICATION | nombre 2 | N | N | int | 30 | W | |||
| ATTR | MY_REDACTOR | MY_IDENTIFICATION | rédacteur | N | N | account | 30 | R | |||
| ATTR | MY_MAIL | MY_IDENTIFICATION | Adresse courriel | N | N | text | 10 | R | |||
| ATTR | MY_SUM | MY_IDENTIFICATION | nombre 1+2 | N | N | int | 30 | R | |||
| END |
13.6.3.35.6.1 Mise à jour d'attribut après modification du document
Le rédacteur est le dernier à avoir modifié le document.
Calcul de la somme des attributs my_numberone et my_numbertwo et
enregistrement dans l'attribut my_sum.
Avec la classe :
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; class MyFamily extends \Dcp\Family\Document { /** * Mise à jour de l'attribut `my_sum` */ protected function setMyRawSum() { $n1 = intval($this->getRawValue(MyAttributes::my_numberone)); $n2 = intval($this->getRawValue(MyAttributes::my_numbertwo)); return $this->setValue(MyAttributes::my_sum, ($n1 + $n2)); } /** * Le rédacteur est l'utilisateur courant */ protected function setMyRedactor() { return $this->setValue(MyAttributes::my_redactor, getCurrentUser()->fid); } public function postStore() { $err = parent::postStore(); if (empty($err)) { $err =$this->setMyRawSum(); $err.=$this->setMyRedactor(); } return $err; } }
13.6.3.35.7 Notes
Aucunes
13.6.3.35.8 Voir aussi
13.6.3.36 Doc::setAttributeValue()
13.6.3.36.1 Description
void setAttributeValue ( string $attributeIdentifier, mixed $value )
Modifie la valeur d'un attribut de l'objet Document. La modification n'est pas enregistrée en base de données.
13.6.3.36.1.1 Avertissements
Pour enregistrer la modification , il est nécessaire d'appeler la méthode
Doc::store().
Les résultats fournis par la méthode
Doc::getRawValue() ne peuvent pas être utilisés
directement par cette méthode.
Les espaces et certains caractères invisibles en début et fin de valeur sont
supprimés. La fonction trim est utilisée pour réaliser cette
suppression.
13.6.3.36.2 Liste des paramètres
- (string)
attributeIdentifier - Identifiant de l'attribut à modifier.
- (mixed)
value -
Nouvelle valeur typée. Le type de la valeur est fonction du type de l'attribut (voir les types en fonction de la valeur).
Il est possible d'affecter aussi les attributs de type
arrayavec un tableau à 2 dimensions. La première dimension est l'index de la rangée, la deuxième dimension est l'identifiant de l'attribut.
13.6.3.36.3 Valeur de retour
Void.
13.6.3.36.4 Erreurs / Exceptions
Retourne une exception de type \Dcp\Exception dans les cas suivants :
- L'attribut n'existe pas;
- Le type attribut ne peut recevoir de valeur (
frame,tab,menu)
Retourne une exception de type \Dcp\AttributeValue\Exception dans les cas
suivants :
- La valeur est incompatible avec le type d'attribut;
- Une valeur scalaire est donnée pour un attribut multiple.
13.6.3.36.5 Historique
Aucun.
13.6.3.36.6 Exemples
Calcul de la somme des attributs my_numberone et my_numbertwo et
enregistrement dans l'attribut my_sum.
Mise à jour de l'attribut my_mail avec l'adresse courriel du rédacteur.
Soit la famille suivante :
| BEGIN | Ma famille | MYFAMILY | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| CLASS | My\MyFamily | ||||||||||
| // | idattr | idframe | label | T | A | type | ord | vis | … | phpfunc | |
| ATTR | MY_IDENTIFICATION | Identification | N | N | frame | 10 | W | ||||
| ATTR | MY_NUMBERONE | MY_IDENTIFICATION | nombre 1 | Y | N | int | 20 | W | |||
| ATTR | MY_NUMBERTWO | MY_IDENTIFICATION | nombre 2 | N | N | int | 30 | W | |||
| ATTR | MY_REDACTOR | MY_IDENTIFICATION | rédacteur | N | N | account | 30 | W | |||
| ATTR | MY_MAIL | MY_IDENTIFICATION | Adresse courriel | N | N | text | 10 | R | |||
| ATTR | MY_SUM | MY_IDENTIFICATION | nombre 1+2 | N | N | int | 30 | R | |||
| END |
13.6.3.36.6.1 Mise à jour d'attribut après modification du document
Avec la classe :
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; use \Dcp\AttributeIdentifiers\Iuser as Aiuser; class MyFamily extends \Dcp\Family\Document { /** * Mise à jour de l'attribut `my_sum` */ protected function setMySum() { $n1 = $this->getAttributeValue(MyAttributes::my_numberone); $n2 = $this->getAttributeValue(MyAttributes::my_numbertwo); $this->setAttributeValue(MyAttributes::my_sum, ($n1 + $n2)); } /** * Mise à jour de l'attribut `my_mail` avec l'adresse courriel du rédacteur */ protected function setMyMail() { $redacId = $this->getAttributeValue(MyAttributes::my_redactor); if ($redacId === null) { $this->clearValue(MyAttributes::my_mail); } else { $redacDoc=new_doc($this->dbaccess,$redacId ); if ($redacDoc->isAlive()) { $this->setAttributeValue(MyAttributes::my_mail, $redacDoc->getAttributeValue(AIuser::us_mail)); } else { $this->clearValue(MyAttributes::my_mail); } } } public function postStore() { $err = parent::postStore(); if (empty($err)) { $this->setMySum(); $this->setMyMail(); } return $err; } }
13.6.3.36.6.2 Exemple avec traitement des exceptions
Calcul de la prochaine échéance dans 7 jours après la dernière modification.
Avec la classe :
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; use \Dcp\AttributeIdentifiers\Iuser as Aiuser; class MyFamily extends \Dcp\Family\Document { /** * Prochaine échéance dans 7 jours */ protected function setNextDate() { $d = new \DateTime('now'); $d->modify('+7 day'); $this->setAttributeValue(MyAttributes::my_nextdate, $d); } public function postStore() { $err = parent::postStore(); if (empty($err)) { try { $this->setNextDate(); } catch (\Dcp\AttributeValue\Exception $e) { $err = sprintf("Valeur erronée %s", $e->getDcpMessage()); } catch (\Dcp\Exception $e) { $err = sprintf("Erreur d'attribut %s", $e->getDcpMessage()); } } return $err; } }
13.6.3.36.6.3 Exemple d'affectation de tableau
Soit les familles suivantes :
| BEGIN | Ma famille | MYFAMILY | ||||||
|---|---|---|---|---|---|---|---|---|
| CLASS | My\MyFamily | |||||||
| DFLDID | auto | |||||||
| ICON | classe.png | |||||||
| // | idattr | idframe | label | T | A | type | ord | vis |
| ATTR | MY_IDENTIFICATION | Identification | N | N | frame | 10 | W | |
| ATTR | MY_REDACTOR | MY_IDENTIFICATION | Rédacteur | N | N | account | 50 | W |
| ATTR | MY_MAIL | MY_IDENTIFICATION | N | N | text | 60 | R | |
| ATTR | MY_REF | MY_IDENTIFICATION | référence | N | N | text | 70 | W |
| ATTR | MY_T_PARTNER | MY_IDENTIFICATION | Participants | N | N | array | 80 | W |
| ATTR | MY_COAUTHORS | MY_T_PARTNER | Co-auteurs | N | N | account | 90 | W |
| ATTR | MY_COMAIL | MY_T_PARTNER | Adresse mail | N | N | text | 110 | W |
| END |
| BEGIN | Contact | MYCONTACT | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| // | idattr | idframe | label | T | A | type | ord | vis | need | link | … | phpfunc | ... | option |
| ATTR | MY_FR_IDENT | État civil | N | N | frame | W | ||||||||
| ATTR | MY_NAME | MY_FR_IDENT | nom | Y | N | text | 30 | W | Y | |||||
| ATTR | MY_FNAME | MY_FR_IDENT | prénom | Y | N | text | 35 | W | Y | |||||
| ATTR | MY_MAIL | MY_FR_IDENT | N | Y | text | 40 | W | mailto:%MY_MAIL% | ||||||
| ATTR | MY_ISPARTNER | MY_FR_IDENT | Partenaire ? | N | Y | enum | 45 | W | no|Pas partenaire, yes|Partenaire | system=yes | ||||
| END |
La méthode setMyPartners va rechercher tous les contacts partenaire et va
les insérer dans le tableau my_t_partner en renseignant l'identifiant et
l'adresse mail de chaque partenaire.
namespace My; use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; use \Dcp\AttributeIdentifiers\MyContact as AMyContact; class MyFamily extends \Dcp\Family\Document { protected function setMyPartners() { // Recherche des partenaires $s = new \SearchDoc($this->dbaccess, \Dcp\Family\Mycontact::familyName); $s->setObjectReturn(true); $s->addFilter("%s = 'yes'", AMyContact::my_ispartner); $dl = $s->search()->getDocumentList(); // On affecte le tableau à 2 dimensions de valeurs $partners=array(); /** @var \Dcp\Family\MyContact $contact */ foreach ($dl as $contact) { $partners[] = array( MyAttributes::my_coauthors => $contact->id, MyAttributes::my_comail => $contact->getAttributeValue(AMyContact::my_mail)); } $this->setAttributeValue(MyAttributes::my_t_partner, $partners); } public function postStore() { $this->setMyPartners(); } }
13.6.3.36.7 Notes
Pour les attributs de type "numérique" et les types "date", plusieurs types de valeurs sont autorisés.
| type | valeur | autorisé |
|---|---|---|
| int | (int) 3 | OK |
| int | (string)"3" | OK |
| int | (float) 3.0 | KO |
| int | (string)"a" | KO |
| double | (float) 3.0 | OK |
| double | (int) 3 | OK |
| double | (string) "3.0" | OK |
| double | (string)"a" | KO |
| date | (DateTime) "2012-03-16" | OK |
| date | (string) "2012-03-16" | OK |
| date | (string) "2012-03" | KO |
| date | (string) "16/03/2012" | OK (dépendant de la locale) |
| timestamp | (DateTime) "2012-03-16" | OK |
| timestamp | (DateTime) "2012-03-16 12:54:34" | OK |
| timestamp | (string) "2012-03-16 12:54:34" | OK |
| timestamp | (string) "2012-03-16T12:54:34" | OK |
13.6.3.36.8 Voir aussi
13.6.3.37 Doc::store()
13.6.3.37.1 Description
string store (storeInfo &$info = null, bool $skipConstraint = false )
Cette méthode permet la modification ou la création de document. Si le document
n'a pas d'identifiant (id), une création de document est effectuée, sinon le
document est mis à jour.
13.6.3.37.1.1 Avertissements
Le document n'est enregistré en base de donnée que si un changement a été
détecté. Si un attrbut est affecté à sa valeur initiale, aucun changement n'est
détecté et le document ne sera pas enregistré. La détection de changement est
réalisée par la méthode Doc::setValue() ainsi que les méthodes
de plus hauts niveaux telles que Doc::setAttributeValue()
ou Doc::addArrayRow. Si les valeurs d'attributs sont
directement modifiées dans l'objet la méthode Doc::store() ne réalise pas
l'enregistrement.
13.6.3.37.2 Liste des paramètres
- (storeInfo)
info - Si
infoest fourni, il contiendra les différents messages fournis par les hameçons ainsi que le code d'erreur. - (bool)
skipConstraint - Si la valeur est
falsealors les contraintes sur le document ne sont pas testées.
13.6.3.37.3 Valeur de retour
La valeur de retour contient le message d'erreur.
Si l'enregistrement s'est bien passé le retour est une chaîne de caractères vide. Dans le cas contraire, le texte de l'erreur est retourné.
Des informations plus détaillées sont disponibles dans le paramètre $info.
13.6.3.37.4 Erreurs / Exceptions
Si l'enregistrement en base de donnée n'a pas pu être réalisée, alors la méthode retourne un message d'erreur.
Le code de retour du paramètre $info est indiqué dans l'attribut errorCode.
Les différents codes d'erreur de $info->errorCode sont :
- storeInfo::NO_ERROR
- Pas d'erreur.
- storeInfo::CREATE_ERROR
- Erreur lors de la création. Peut provenir de l'hameçon
Doc::preCreated(), d'un problème de droits ou d'un problème d'accès à la base de données. - storeInfo::UPDATE_ERROR
- Erreur lors de la mise à jour. Peut provenir d'un problème de droits ou d'un problème d'accès à la base de données.
- storeInfo::CONSTRAINT_ERROR
- Une des contraintes n'a pas été validée.
- storeInfo::PRESTORE_ERROR
- Erreur déclenchée par l'hameçon
Doc::preStore().
Une exception Dcp\Db\Exception peut être levée en cas de problème
d'enregistrement au niveau de la base de données (problème d'accès, problème
d'unicité d'index, problème d'incohérence de type).
13.6.3.37.5 Historique
Aucun.
13.6.3.37.6 Exemples
Soit la famille MY_FAMILY suivante :
| BEGIN | Ma famille | MYFAMILY | ||||||
|---|---|---|---|---|---|---|---|---|
| CLASS | My\MyFamily | |||||||
| // | idattr | idframe | label | T | A | type | ord | vis |
| ATTR | MY_IDENTIFICATION | Identification | N | N | frame | 10 | W | |
| ATTR | MY_NUMBERONE | MY_IDENTIFICATION | nombre 1 | Y | N | int | 20 | W |
| ATTR | MY_NUMBERTWO | MY_IDENTIFICATION | nombre 2 | N | N | int | 30 | W |
| END |
13.6.3.37.6.1 Modification d'un document
Exemple d'enregistrement d'une modification sans contrôle d'erreur.
use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; /** @var \Dcp\Family\MyFamily */ $d=new_Doc("","MY_DOCUMENT"); $d->setValue(MyAttributes::my_numberone, 234); $d->store($info); // enregistrement en base de données
13.6.3.37.6.2 Création d'un document
Exemple d'enregistrement d'un nouveau document sans contrôle d'erreur.
use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; /** @var \Dcp\Family\MyFamily */ $d=createDoc("","MY_FAMILY"); $d->setValue(MyAttributes::my_numberone, 234); $d->setValue(MyAttributes::my_numbertwo, 873); $d->store($info);// enregistrement en base de données printf("Nouvel identifiant : %d\n", $d->id);
13.6.3.37.6.3 Contrôle des erreurs d'enregistrement
Les codes erreurs de $info permettent de préciser l'origine du problème.
use \Dcp\AttributeIdentifiers\MyFamily as MyAttributes; /** @var \Dcp\Family\MyFamily */ $d = new_Doc("", "MY_DOCUMENT"); $err = $d->setValue(MyAttributes::my_numberone, 234); if (empty($err)) { /** @var storeInfo $info */ $err = $d->store($info); if (!empty($err)) { switch ($info->errorCode) { case storeInfo::NO_ERROR: // pas d'erreurs break; case storeInfo::CONSTRAINT_ERROR: printf("Erreurs de contrainte :\n"); foreach ($info->constraint as $constraintInfo) { printf("Contrainte sur l'attribut %s non respectée : %s\n", $constraintInfo["id"], $constraintInfo["err"]); } break; default: printf("Erreur d'enregistrement : %s", $err); } } }
13.6.3.37.7 Notes
Lors d'un ajout de documents les hameçons suivants sont lancés :
Doc::preStore()Doc::preCreated()- Enregistrement en base
Doc::postCreated()Doc::preRefresh()-
Doc::postRefresh() - Enregistrement en base si modification détectée depuis dernier enregistrement
-
Doc::postStore() - Enregistrement en base si modification détectée depuis dernier enregistrement
Lors d'une mise à jour de documents les hameçons suivants sont lancés :
Doc::preStore()Doc::preRefresh()-
Doc::postRefresh() - Enregistrement en base
-
Doc::postStore() - Enregistrement en base si modification détectée depuis dernier enregistrement
13.6.3.37.8 Voir aussi
13.6.3.38 Doc::undelete()
Méthode utilisée pour restaurer un document supprimé.
13.6.3.38.1 Description
string undelete ( )
Cette méthode permet d'annuler la suppression d'un document.
13.6.3.38.1.1 Avertissements
Cette méthode ne permet pas de restaurer un document qui a été supprimé physiquement.
13.6.3.38.2 Liste des paramètres
Aucun.
13.6.3.38.3 Valeur de retour
Message d'erreur. Si la chaîne retournée est non nulle, le message indique l'erreur qui a interdit la restauration.
13.6.3.38.4 Erreurs / Exceptions
Une erreur est retournée si :
- Le document n'existe pas ou plus (physiquement supprimé)
- Le document n'est pas supprimé
- L'utilisateur n'a pas le droit
deletesur le document - L'hameçon
preUndelete()retourne une erreur.
13.6.3.38.5 Historique
Anciennement Doc::revive().
13.6.3.38.6 Exemples
Restauration du document référencé par l'identificateur $documentId.
$doc=new_doc('', $documentId); if ($doc->isAffected() && !$doc->isAlive()) { $err=$doc->undelete(); // maintenant le document est vivant if ($err == "") { printf("Restauration %s [%d]", $doc->getTitle(), $doc->id); } }
13.6.3.38.7 Notes
Une entrée dans l'historique est enregistrée à chaque restauration.
13.6.3.38.8 Voir aussi
13.6.3.39 Doc::viewattr()
Cette méthode permet d'ajouter les clefs correspondantes aux attributs du document pour la composition d'une vue de consultation spécifique.
13.6.3.39.1 Description
void viewattr ( string $target = "_self", bool $ulink = true, bool $abstract = false, bool $viewhidden = false)
Cette méthode ajoute pour chaque attribut pouvant contenir une valeur :
- une clef contenant la valeur affichable de l'attribut,
- une clef pour le libellé de l'attribut.
- une clef pour indiquer si la valeur de l'attribut est vide ou non.
La clef de valeur est composée du préfixe V_ suivi de l'identifiant de
l'attribut en majuscule. La valeur affichable est fournie par la méthode
DocHtmlFormat::getHtmlValue(). Les attributs de type array ont aussi leur
clef générée.
La clef de libellé est composée du préfixe L_ suivi de l'identifiant de
l'attribut en majuscule. Le libellé est dépendant de la locale de
l'utilisateur. La valeur du libellé est fournie par la méthode
Doc::getLabel().
La clef de nullité de la valeur est composée du préfixe S_ suivi du nom de
l'identifiant de l'attribut en majuscule. Cette clef vaut false si la
valeur brute de l'attribut est vide (chaine ""). Elle vaut true dans le cas
contraire.
13.6.3.39.1.1 Avertissements
Les attributs de type tab, frame et menu n'ont pas de clef générée.
13.6.3.39.2 Liste des paramètres
- (string)
target - Indique la cible des hyperliens pour les
attributs qui en disposent.
Valeur spéciale :
-
ooo: Si on utilise les clefs pour une composition de template ODT. Dans ce cas, les valeurs en XML sont retournées.
- (bool)
ulink - Indique si les hyperliens doivent être générés. Si
targetégal àooo, aucun lien n'est généré quelque soit la valeur deulink.
Sitrue, alors les hyperliens sont générés
Sifalse, alors les hyperliens ne sont pas générés - (bool)
abstract - Si
true, alors seuls les attributs "résumé" sont affichés
Sifalse, alors la caractéristique "résumé" n'est pas prise en compte. - (bool)
viewhidden - Si
true, les attributs en visibilitéHsont affichés. - Si
false, les attributs en visibilitéHne sont pas affichés.
Les attributs en visibilitéIetOne sont pas affichés. Leur clefs sont générés vides.
13.6.3.39.3 Valeur de retour
void.
13.6.3.39.4 Erreurs / Exceptions
Aucune.
13.6.3.39.5 Historique
Aucun.
13.6.3.39.6 Exemples
Soit la famille MY_ANIMAL qui possède les attributs suivants :
| nom | type |
|---|---|
| AN_NOM | text |
| AN_PHOTO | image |
| AN_NAISSANCE | date |
Fichier de la classe associées à la famille :
namespace MyTest; class My_animal extends \Dcp\Family\Document { /** * @templateController view original photo */ public function viewPhoto($target="_self", $ulink=true, $abstract=false) { $this->viewAttr($target, $ulink, $abstract); } }
Template viewPhoto.html :
<h1>[TEXT:My name is] : [V_AN_NOM]</h1> <p>[TEXT:My birthday date is] : <strong>[V_AN_NAISSANCE]</strong></p> [IF S_AN_PHOTO]<img class="photo" src="[V_AN_PHOTO]"/>[ENDIF S_AN_PHOTO] [IFNOT S_AN_PHOTO]<p>[TEXT:No photo]</p>[ENDIF S_AN_PHOTO]
Résultat :
<h1>My name is : Rotor</h1> <p>My birthday date is : <strong>03/08/2012</strong></p> <img class="photo" src="file/1419/41/an_photo/-1/1387_IMG_1684AFC2.jpg?cache=no&inline=no"/>
Rendu HTML :
Figure 85. Usage de Doc::viewAttr()
13.6.3.39.7 Notes
Exemple de retour pour les valeurs formatées en fonction du type de l'attribut.
| Type | Format | Multiple | Valeur brute | Valeur HTML |
|---|---|---|---|---|
| text | Un | Un | ||
| text | Éléonore | Éléonore | ||
| longtext | Et\nLa suite en été... | Et<br /> La suite en été<b>... |
||
| money | 2.54 | 2,54 | ||
| double | 3.1415926 | 3.1415926 | ||
| int | 1 | 1 | ||
| date | 2013-04-20 | 20/04/2013 | ||
| time | 01:00:00 | 01:00 | ||
| timestamp | 2013-09-30 10:00:00 | 30/09/2013 10:00 | ||
| image | image/jpeg; charset=binary | 42| 1387_IMG_1684AFC2.jpg | file/1419/41/an_photo/-1/1387_IMG_1684AFC2.jpg?cache=no&inline=no | ||
| file | application/vnd.oasis.opendocument.spreadsheet| 1330| fdl.ods | <a onmousedown="document.noselect=true;" title="34Ko" target="_blank" type="application/vnd.oasis.opendocument.spreadsheet" href="file/5388/1330/fi_file/-1/fdl.ods?cache=no&inline=no"><img class="mime" needresize=1 src="Images/mime-spreadsheet.png"> fdl.ods</a> | ||
| docid | TST_MY_FAMILY | 5384 | <a oncontextmenu="popdoc(event,'?&app=FDL&action=OPENDOC&mode=view&id=5384&latest=Y');return false;" documentId="5384" class="relation" style="background-image:url(resizeimg.php?img=Images%2Fdoc.png&size=14)" target="_self" href="?&app=FDL&action=OPENDOC&mode=view&id=5384&latest=Y">Zéro</a> | |
| account | 6394 | <a oncontextmenu="popdoc(event,'?&app=FDL&action=OPENDOC&mode=view&id=6394&latest=Y');return false;" documentId="6394" class="relation" style="background-image:url(resizeimg.php?img=Images%2iuser.png&size=14)" target="_self" href="?&app=FDL&action=OPENDOC&mode=view&id=6394&latest=Y">John Doe</a> | ||
| enum | a|One,b|Two,c|Three | a | One | |
| color | #f3f | <span style="background-color:#f3f">#f3f</span> | ||
| enum | a|A,b|B,c|C | X | a\nb\nc | A<BR>B<BR>C |
| text | X | Un\nDeux | Un<BR>Deux | |
| money | X | 3 | 3,00 | |
| double | X | -54 | -54 | |
| date | X | 2013-04-20 | 20/04/2013 | |
| time | X | 10:00 | 10:00 | |
| timestamp | X | 2013-09-30 10:00 | 30/09/2013 10:00 | |
| enum | a|A,b|B,c|C | X | a | A |
| color | X | #ff33ff\n#45e098 | <span style="background-color:#ff33ff">#ff33ff</span><BR><span style="background-color:#45e098">#45e098</span> | |
| longtext | X | Un Deux\nTrois Quatre |
Un<br /> Deux<BR>Trois<br /> Quatre |
|
| int | X | 1\n2\n3 | 1<BR>2<BR>3 | |
| double | X | \n\n | <BR><BR> | |
| text | [%s] | Document Un | [Document Un] | |
| longtext | Et\nLa suite... | Et<br /> La suite... |
||
| money | %s € | 2.54 | 2,54 € | |
| double | %.03f | 3.1415926 | 3.142 | |
| int | %03d | 1 | 001 | |
| date | %A %e %B %Y | 2013-04-20 | samedi 20 avril 2013 | |
| time | %kh %Mmin %Ss | 01:00:00 | 1h 00min 00s | |
| timestamp | %A %e %B %Y %Hh %Mmin %Ss | 2013-09-30 10:00:00 | lundi 30 septembre 2013 10h 00min 00s | |
| text | [%s] | X | Un\nDeux | [Un]<BR>[Deux] |
| money | %s $ | 3 | 3,00 $ | |
| double | %.03f | -54 | -54.000 | |
| date | %A %e %B %Y | 2013-04-20 | samedi 20 avril 2013 |
13.6.3.39.8 Voir aussi
13.6.4 Gestion des minuteurs de document
Les minuteurs permettent de déclencher des actions différées sur le documents. Le paramétrage d'un cycle de vie permet de les attacher et de les détacher automatiquement lors des passages de transitions.
Ce chapitre présente les méthodes permettant de gérer les minuteurs de manière explicite sans forcément avoir recours à un cycle de vie.
13.6.4.1 Doc::attachTimer()
Méthode utilisée pour attacher un minuteur au document
13.6.4.1.1 Description
string attachTimer ( Dcp\Family\Timer $timer, Doc $origin = null, string $execdate = null)
Cette méthode permet d'attacher un minuteur particulier sur le document.
13.6.4.1.1.1 Avertissements
Le même minuteur ne peut pas être attaché plusieurs fois sur le même document.
Si le paramètre $execdate est non vide, la caractéristique
dynamique tm_dyndate d'un minuteur est ignorée.
Le minuteur ne peut pas être posé sur une révision précise du document. Les minuteurs sont attachés sur la dernière révision du document.
13.6.4.1.2 Liste des paramètres
- (Dcp\Family\Timer)
timer - Document Minuteur qui doit être attaché au document
- (Doc)
origin - Document ayant initié l'attachement. Ce paramètre optionnel permet
d'identifier un attachement. Il est utilisé par la méthode
Doc::unattachAllTimers(). - (string)
execdate -
Date au format
YYYY-MM-DD HH:MMouYYYY-MM-DD. Cette date sert de date de référence si elle est non vide.Si cette date est vide, la date de référence est calculée en fonction de la date de référence indiquée sur le minuteur (attribut
tm_dyndate). Si la date référence du minuteur est aussi vide, alors la date de référence est la date d'attachement.
13.6.4.1.3 Valeur de retour
La valeur de retour est le message d'erreur. Un retour vide indique que l'opération s'est bien déroulée.
13.6.4.1.4 Erreurs / Exceptions
Les cas de retours d'erreurs sont :
- Ce minuteur est déjà attaché
- Le document "minuteur" n'est pas un minuteur
- Le minuteur n'a déclaré aucune action
13.6.4.1.5 Historique
Aucun.
13.6.4.1.6 Exemples
13.6.4.1.6.1 Attacher un minuteur maintenant
Soit le minuteur n°13509 suivant :
| Attribut | Label | Valeur |
|---|---|---|
| tm_delay | Délai en jours | 1 |
| tm_hdelay | Délai en heure | 0 |
| tm_dyndate | Date de référence | null |
| tm_refdaydelta | Décalage en jours | 0 |
| tm_refhourdelta | Décalage en heure | 3 |
| tm_iteration | Nombre d'itération | 1 |
| tm_tmail | Courrier à envoyer | [null] |
| tm_method | Méthode à exécuter | [::myMethod()] |
qui décrit qu'il faut exécuter la méthode "myMethod" après une journée avec un décalage de 3 heures.
Attachement du minuteur n°13509 :
$myDocument=new_doc("", 1427); $myTimer=new_doc("", 13509); $err=$myDocument->attachTimer($myTimer); if (empty($err)) { print_r( $myDocument->getAttachedTimers()); } else { print "$err\n"; }
Résultat :
Array
(
[0] => Array
(
[timerid] => 13509
[level] => 0
[originid] =>
[docid] => 1427
[title] => Éléonore
[fromid] => 1059
[attachdate] => 2014-10-15 16:21:00
[referencedate] => 2014-10-15 19:21:00
[tododate] => 2014-10-16 19:21:00
[donedate] =>
[actions] => a:3:{s:5:"state";s:0:"";s:5:"tmail";s:0:"";s:6:"method";s:12:"::myMethod()";}
[result] =>
[id] => 16
)
)
La date d'exécution est positionné à la date de l'attachement plus une journée
et 3 heures (tm_delay + tm_refhourdelta).
13.6.4.1.6.2 Attachement avec une date donnée
Attachement du minuteur n°13509 :
$myDocument=new_doc("", 1427); $myTimer=new_doc("", 13509); $err=$myDocument->attachTimer($myTimer, null , "2014-12-25 12:00"); if (empty($err)) { print_r( $myDocument->getAttachedTimers()); } else { print "$err\n"; }
Résultat :
Array
(
[0] => Array
(
[timerid] => 13509
[level] => 0
[originid] =>
[docid] => 1427
[title] => Éléonore
[fromid] => 1059
[attachdate] => 2014-10-15 16:18:00
[referencedate] => 2014-12-25 15:00:00
[tododate] => 2014-12-26 15:00:00
[donedate] =>
[actions] => a:3:{s:5:"state";s:0:"";s:5:"tmail";s:0:"";s:6:"method";s:12:"::myMethod()";}
[result] =>
[id] => 14
)
)
La date d'exécution est positionnée à la date de référence indiquée plus une
journée et 3 heures (tm_delay + tm_refhourdelta).
13.6.4.1.7 Notes
Une entrée, de niveau notice, est enregistrée dans l'historique pour indiquer l'attachement du minuteur.
13.6.4.1.8 Voir aussi
13.6.4.2 Doc::getAttachedTimer()
Méthode utilisée récupérer les informations des minuteurs attachés au document.
13.6.4.2.1 Description
array getAttachedTimer ( )
Cette méthode renvoie les informations des minuteurs qui sont attachés au document.
13.6.4.2.1.1 Avertissements
Aucun.
13.6.4.2.2 Liste des paramètres
Aucun
13.6.4.2.3 Valeur de retour
Le retour est un tableau de valeur indexé. Si le tableau est vide, alors aucun minuteur n'est attaché au document.
| Clef | Description | Exemple |
|---|---|---|
| timerid | Identifiant du document Timer | 13510 |
| level | Nombre de fois qu'une action a été exécutée depuis l'attachement. Dépend du nombre d'itération et du nombre d'actions | 0 |
| originid | Identifiant du document Origine | |
| docid | Identifiant initial (initid) du document portant le minuteur |
1427 |
| title | Titre du document portant le minuteur | Éléonore |
| fromid | Identifiant de la famille du document portant le minuteur | 1059 |
| attachdate | Date d'attachement du minuteur | 2014-10-15 17:24:00 |
| referencedate | Date de référence du minuteur | 2012-10-01 05:00:00 |
| tododate | Date de prochaine échéance | 2012-10-01 05:00:00 |
| donedate | Date à laquelle l'action a été exécutée | |
| actions | Actions à faire (chaîne serialisée) | a:3:{s:5:"state";s:0:"";s:5:"tmail";s:0:"";s:6:"method";s:12:"::myMethod()";} |
| result | Résultat de l'action | |
| id | Identifiant de l'attachement | 22 |
Seuls les attachements actifs sont retournés. Les actions effectuées ne sont pas retournées.
13.6.4.2.4 Erreurs / Exceptions
Aucunes.
13.6.4.2.5 Historique
Aucun.
13.6.4.2.6 Exemples
Deux minuteurs sont attachés au document n°1427. Le premier minuteur n°13509 est lié à l'origine n°1090. Le deuxième minuteur n'est pas lié.
$myOrigin=new_doc("", 1090); $myDocument=new_doc("", 1427); $myFirstTimer=new_doc("", 13509); $mySecondTimer=new_doc("", 13510); $err=$myDocument->attachTimer($myFirstTimer, $myOrigin); $err=$myDocument->attachTimer($mySecondTimer); print "Attachements:\n"; if (empty($err)) { print_r( $myDocument->getAttachedTimers()); } else { print "$err\n"; }
Résultat :
Attachements
Array
(
[0] => Array
(
[timerid] => 13509
[level] => 0
[originid] => 1090
[docid] => 1427
[title] => Éléonore
[fromid] => 1059
[attachdate] => 2014-10-16 10:19:00
[referencedate] => 2014-10-16 13:19:00
[tododate] => 2014-10-17 13:19:00
[donedate] =>
[actions] => a:3:{s:5:"state";s:0:"";s:5:"tmail";s:0:"";s:6:"method";s:12:"::myMethod()";}
[result] =>
[id] => 31
)
[1] => Array
(
[timerid] => 13510
[level] => 0
[originid] =>
[docid] => 1427
[title] => Éléonore
[fromid] => 1059
[attachdate] => 2014-10-16 10:19:00
[referencedate] => 2012-10-01 05:00:00
[tododate] => 2012-10-01 05:00:00
[donedate] =>
[actions] => a:3:{s:5:"state";s:0:"";s:5:"tmail";s:0:"";s:6:"method";s:12:"::myMethod()";}
[result] =>
[id] => 32
)
)
13.6.4.2.7 Notes
Aucunes.
13.6.4.2.8 Voir aussi
13.6.4.3 Doc::unAttachTimer()
Méthode utilisée pour détacher un minuteur du document
13.6.4.3.1 Description
string unAttachTimer ( Dcp\Family\TIMER $timer )
Cette méthode permet de détacher un minuteur précis du document.
13.6.4.3.1.1 Avertissements
Aucuns.
13.6.4.3.2 Liste des paramètres
- (Dcp\Family\Timer)
timer - Document Minuteur qui doit être détaché du document
13.6.4.3.3 Valeur de retour
La valeur de retour est le message d'erreur. Un retour vide indique que l'opération s'est bien déroulée.
Si le minuteur n'est pas présent, aucun message d'erreur n'est retourné.
13.6.4.3.4 Erreurs / Exceptions
Les cas de retours d'erreurs sont :
- Le document "minuteur" n'est pas un minuteur
- Erreur d'accès interne à la base de donnée
13.6.4.3.5 Historique
Aucun.
13.6.4.3.6 Exemples
Détachement d'un minuteur :
$myDocument=new_doc("", 1427); $myTimer=new_doc("", 13510); print "Avant\n" print_r( $myDocument->getAttachedTimers()); $err=$myDocument->unattachTimer($myTimer); print "Après\n" if (empty($err)) { print_r( $myDocument->getAttachedTimers()); } else { print "$err\n"; }
Résultat :
Le minuteur n°13510 est présent à l'origine :
Avant:
Array
(
[0] => Array
(
[timerid] => 13510
[level] => 0
[originid] =>
[docid] => 1427
[title] => Éléonore
[fromid] => 1059
[attachdate] => 2014-10-15 17:24:00
[referencedate] => 2012-10-01 05:00:00
[tododate] => 2012-10-01 05:00:00
[donedate] =>
[actions] => a:3:{s:5:"state";s:0:"";s:5:"tmail";s:0:"";s:6:"method";s:12:"::myMethod()";}
[result] =>
[id] => 22
)
)
Le minuteur n'est plus enregistré
Après:
Array
(
)
13.6.4.3.7 Notes
Une entrée, de niveau notice, est enregistrée dans l'historique pour indiquer le détachement du minuteur.
13.6.4.3.8 Voir aussi
13.6.4.4 Doc::unattachAllTimers()
Méthode utilisée pour détacher tous les minuteurs du document.
13.6.4.4.1 Description
string unattachAllTimers(Doc $origin = null)
Cette méthode permet de supprimer tout ou un sous-ensemble de minuteurs associés au document.
Si l'origine est vide, tous les minuteurs sont détachés.
Si l'origine est indiquée, seuls les minuteurs issus de cette origine sont détachés.
13.6.4.4.1.1 Avertissements
Aucuns.
13.6.4.4.2 Liste des paramètres
- (Doc)
origin - Filtre permettant de détacher un sous-ensemble. L'origine est donné
par l'argument
originede la méthodeDoc::attachTimer().
13.6.4.4.3 Valeur de retour
La valeur de retour est le message d'erreur. Un retour vide indique que l'opération s'est bien déroulée.
13.6.4.4.4 Erreurs / Exceptions
Les cas de retours d'erreurs sont :
- Erreur d'accès interne à la base de donnée
13.6.4.4.5 Historique
Aucun.
13.6.4.4.6 Exemples
13.6.4.4.6.1 Détachement de tous les minuteurs
Deux minuteurs sont attachés au document n°1427. Le premier minuteur n°13509 est lié à l'origine n°1090. Le deuxième minuteur n'est pas lié.
Le but de cet exemple est de détacher les minuteurs liés à l'origine n°1090.
$myOrigin=new_doc("", 1090); $myDocument=new_doc("", 1427); $myFirstTimer=new_doc("", 13509); $mySecondTimer=new_doc("", 13510); $err=$myDocument->attachTimer($myFirstTimer, $myOrigin); $err.=$myDocument->attachTimer($mySecondTimer); print "Active timers:\n"; print_r( $myDocument->getAttachedTimers()); $err.=$myDocument->unattachAllTimers(); print "After origin deletion :\n"; if (empty($err)) { print_r( $myDocument->getAttachedTimers()); } else { print "$err\n"; }
Résultat :
Active timers:
Array
(
[0] => Array
(
[timerid] => 13509
[level] => 0
[originid] => 1090
[docid] => 1427
[title] => Éléonore
[fromid] => 1059
[attachdate] => 2014-10-16 10:12:00
[referencedate] => 2014-10-16 13:12:00
[tododate] => 2014-10-17 13:12:00
[donedate] =>
[actions] => a:3:{s:5:"state";s:0:"";s:5:"tmail";s:0:"";s:6:"method";s:12:"::myMethod()";}
[result] =>
[id] => 25
)
[1] => Array
(
[timerid] => 13510
[level] => 0
[originid] =>
[docid] => 1427
[title] => Éléonore
[fromid] => 1059
[attachdate] => 2014-10-16 10:12:00
[referencedate] => 2012-10-01 05:00:00
[tododate] => 2012-10-01 05:00:00
[donedate] =>
[actions] => a:3:{s:5:"state";s:0:"";s:5:"tmail";s:0:"";s:6:"method";s:12:"::myMethod()";}
[result] =>
[id] => 26
)
)
After origin deletion : Array ( )
Tous les minuteurs ont été détachés.
13.6.4.4.6.2 Détachement en fonction de l'origine
Deux minuteurs sont attachés au document n°1427. Le premier minuteur n°13509 est lié à l'origine n°1090. Le deuxième minuteur n'est pas lié.
Le but de cet exemple est de détacher les minuteurs liés à l'origine n°1090.
$myOrigin=new_doc("", 1090); $myDocument=new_doc("", 1427); $myFirstTimer=new_doc("", 13509); $mySecondTimer=new_doc("", 13510); $err=$myDocument->attachTimer($myFirstTimer, $myOrigin); $err.=$myDocument->attachTimer($mySecondTimer); print "Active timers:\n"; print_r( $myDocument->getAttachedTimers()); $err.=$myDocument->unattachAllTimers($myOrigin); print "After origin deletion :\n"; if (empty($err)) { print_r( $myDocument->getAttachedTimers()); } else { print "$err\n"; }
Résultat :
Active timers:
Array
(
[0] => Array
(
[timerid] => 13509
[level] => 0
[originid] => 1090
[docid] => 1427
[title] => Éléonore
[fromid] => 1059
[attachdate] => 2014-10-16 10:12:00
[referencedate] => 2014-10-16 13:12:00
[tododate] => 2014-10-17 13:12:00
[donedate] =>
[actions] => a:3:{s:5:"state";s:0:"";s:5:"tmail";s:0:"";s:6:"method";s:12:"::myMethod()";}
[result] =>
[id] => 25
)
[1] => Array
(
[timerid] => 13510
[level] => 0
[originid] =>
[docid] => 1427
[title] => Éléonore
[fromid] => 1059
[attachdate] => 2014-10-16 10:12:00
[referencedate] => 2012-10-01 05:00:00
[tododate] => 2012-10-01 05:00:00
[donedate] =>
[actions] => a:3:{s:5:"state";s:0:"";s:5:"tmail";s:0:"";s:6:"method";s:12:"::myMethod()";}
[result] =>
[id] => 26
)
)
After origin deletion :
Array
(
[0] => Array
(
[timerid] => 13510
[level] => 0
[originid] =>
[docid] => 1427
[title] => Éléonore
[fromid] => 1059
[attachdate] => 2014-10-16 10:12:00
[referencedate] => 2012-10-01 05:00:00
[tododate] => 2012-10-01 05:00:00
[donedate] =>
[actions] => a:3:{s:5:"state";s:0:"";s:5:"tmail";s:0:"";s:6:"method";s:12:"::myMethod()";}
[result] =>
[id] => 26
)
)
Seuls les minuteurs liés à l'origine n°1090 ont été détachés.
13.6.4.4.7 Notes
Une entrée, de niveau notice, est enregistrée dans l'historique pour indiquer le détachement des minuteurs.
13.6.4.4.8 Voir aussi
13.7 Classe Docfam
La classe DocFam est la classe utilisée pour les familles de
documents. Tous les documents "famille" héritent de la classe DocFam.
13.7.1 Propriétés de la classe DocFam
La classe DocFam hérite de la classe Doc. Elle dispose, par conséquent, des
propriétés de la classe Doc.
13.7.1.1 Particularités sur les propriétés héritées
- fromid
- Identifiant de la famille parente.
- icon
- Icone de la famille. Cette icone est aussi utilisée pour les documents de cette famille.
- classname
- Nom de la classe associée à la famille.
- initid
- Identifiant de la famille. Toujours égal à
idcar les familles ne sont pas révisables. - cvid
- Toujours vide. Non utilisable pour une famille.
- dprofid
- Toujours vide. Une famille ne peut pas avoir de profil dynamique.
- revision
- Toujours 0. Les familles ne sont pas révisables.
- state
- Toujours vide. Les familles ne peuvent avoir de cycle de vie.
- wid
- Identifiant du cycle qui sera lié aux nouveaux documents de cette famille.
- title
- Titre de la famille. Ce titre peut faire l'objet d'une traduction.
Le titre localisé est obtenu avec la méthode
DocFam::getTitle().
13.7.1.2 Propriétés spécifiques de famille
- schar
-
Indique les modalités de révision des documents de cette famille :
-
R: Révision automatique à chaque modification, -
S: document non révisable.
-
- cprofid
- Identifiant du profil qui sera lié aux nouveaux document de la famille.
- dfldid
- Dossier racine de la famille. Ce dossier est notamment utilisé par
l'application
ONEFAMvia l'actionGENERIC:GENERIC_TABqui liste les documents. - cfldid
- Identifiant de recherche ou de dossier par défaut. Cet identifiant est
utilisé par l'action
GENERIC:GENERIC_TAB. Cette recherche est effectuée si aucune autre n'est indiquée en paramètre de cette action. - ccvid
- Identifiant du contrôle de vue qui sera lié aux nouveaux documents de la famille.
- methods
- Liste des fichiers Méthod utilisés pour construire la classe de la famille.
- maxrev
- Nombre de révision maximum pour un document de cette famille.
Si vide ou 0, aucune limite du nombre de révision.
Si le nombre est positif, une fois le nombre de révision maximum atteint,
les révisions les plus anciennes seront supprimées au fur et à mesure des
nouvelles révisions. L'historique ne comportera que les
maxrevdernières révisions. - defval
- Valeurs par défaut pour les nouveaux documents. Ces valeurs sont linéarisés.
Elles sont accessibles avec la méthode
DocFam::getDefValues(). - param
- Valeurs des paramètres de la famille. Ces valeurs sont linéarisés.
Elles sont accessibles avec la méthode
DocFam::getParameterRawValue()ouDoc::getFamilyParameterValue().
13.8 Classe DocumentList
La classe DocumentList représente une abstraction permettant de manipuler une
liste de documents. Cette classe implémente les interfaces :
Les objets de cette classe peuvent donc être utilisés via la directive
foreach() et être utilisés par la fonction count().
Dans le cas d'une itération avec foreach(), les clefs sont
alors les identifiants des documents et les valeurs sont les documents sous la
forme d'un objet Doc ou de documents bruts.
Il existe plusieurs moyens d'obtenir un objet DocumentList, par exemple à partir:
- d'un array d'identifiant de documents,
- d'un objet
SearchDoc, - de la méthode
SearchDoc::getDocumentList.
13.8.1 Constructeur
L'objet DocumentList peut être construit à priori à partir d'un objet
SearchDoc de recherche de documents.
$search = new \SearchDoc(...); $documentList = new \DocumentList($search);
L'objet DocumentList peut aussi être initialisé à posteriori à l'aide de la
méthode addDocumentIdentifiers pour la
recherche des dernières révisions de documents :
$documentList = new \DocumentList(); $documentList->addDocumentIdentifiers(array($initId_1, [...], $initId_N));
13.8.2 Exemples
- Exemple #1
DocumentList avec des documents bruts :
$search = new SearchDoc('', 'FACTURE'); $search->addFilter("montant >= %d", 10000); /* * Par défaut, `searchDoc` retourne des documents bruts. * * La liste `DocumentList` obtenue contient alors des * documents bruts. */ $documentList = new \DocumentList($search); /* * On parcours la liste des résultats avec un foreach() */ printf("Nombre de factures : %d", count($documentList)); foreach ($documentList as $docId => $rawDoc) { printf("* Facture {id = '%d', title = '%s'}.", $docId, $rawDoc['title']) }
- Exemple #2
DocumentList avec des objets Doc :
$search = new SearchDoc('', 'FACTURE'); $search->addFilter("montant >= %d", 10000); /* * On configure la recherche pour retourner des objets `Doc` */ $search->setObjectReturn(true); /* * La liste `DocumentList` obtenue contient alors des objets `Doc`. */ $documentList = new \DocumentList($search); /* * On parcours la liste des résultats avec un foreach() */ printf("Nombre de factures : %d", count($documentList)); foreach ($documentList as $docId => $doc) { printf("* Facture {id = '%d', title = '%s'}.", $docId, $doc->getTitle()); }
13.8.3 Voir aussi
13.8.4 DocumentList::addDocumentIdentifiers()
La méthode addDocumentIdentifiers permet d'obtenir les dernières
révisions (latest) d'un ensemble de documents à partir de la liste
des identifiants de ces documents.
13.8.4.1 Description
void addDocumentIdentifiers ( array[int] $ids, bool $useInitId = true )
La méthode addDocumentIdentifiers permet d'obtenir les dernières
révisions (latest) des documents dont les identifiants sont passés
en argument sous la forme d'une liste d'identifiants.
Les identifiants de la liste peuvent être des initid, des id de révisions
intermédiaire ou bien des id de dernière révision (latest).
La méthode initialise alors l'objet DocumentList courant pour retourner tous
ces différents documents dans leur dernière révision (latest).
13.8.4.1.1 Avertissements
Aucun.
13.8.4.2 Liste des paramètres
- (array[int])
ids -
idscontient la liste des identifiants des documents avec lesquels on souhaite initialiser l'objetDocumentList. - (bool)
useInitId -
useInitIdpermet de spécifier si les identifiants fournis sont desinitidou des identifiants de dernière révision.Par défaut,
useInitIdvauttrue, et les identifiants spécifiés doivent être desinitid.
13.8.4.3 Valeur de retour
Les éléments accessibles par itération sur DocumentList sont des objet dérivés
de la classe Doc.
13.8.4.4 Erreurs / Exceptions
Aucune.
13.8.4.5 Historique
Aucun.
13.8.4.6 Exemples
Soit les documents suivants :
- Document #1 d'
initid3973 et les révisions suivantes.
initid | id | locked | revision | title --------+------+--------+----------+------------- 3973 | 3973 | -1 | 0 | Foo 3973 | 3974 | -1 | 1 | Foo Bar 3973 | 3975 | -1 | 2 | Foo Bar Baz 3973 | 3976 | 0 | 3 | Foo Bar Baz
- Document #2 d'
initid3977 et les révisions suivantes.
initid | id | locked | revision | title --------+------+--------+----------+--------------------- 3977 | 3977 | -1 | 0 | The 3977 | 3978 | -1 | 1 | The Quick 3977 | 3979 | -1 | 2 | The Quick Brown 3977 | 3980 | -1 | 3 | The Quick Brown Fox 3977 | 3981 | 0 | 4 | The Quick Brown Fox
13.8.4.6.1 Avec Initid
Lorsque useInitId est à true (valeur par défaut), les identifiants fournis
doivent être des initid.
Si un identifiant n'est pas un initid, alors il n'est pas retourné par l'objet
DocumentList.
$documentList = new \DocumentList(); $documentList->addDocumentIdentifiers( array( 3973, /* document #1 @ revision 0 (initid) */ 3981 /* document #2 @ revision 4 (latest) */ ) ); foreach ($documentList as $docId => $doc) { printf("* Document {id = '%d', revision = '%d', title = '%s'}.\n", $docId, $doc->getProperty('revision'), $doc->getTitle()); }
Résultat :
* Document {id = '3976', revision = '3', title = 'Foo Bar Baz'}.
Seul document#1 est retourné (car spécifié avec son initid) et à sa dernière
révision (3).
13.8.4.6.2 Avec Latest Id
Lorsque useInitId est à false, les identifiants fournis doivent être des
identifiants de dernière révision (latest).
Si un identifiant n'est pas un identifiant de dernière révision, alors il n'est
pas retourné par l'objet DocumentList.
$documentList = new \DocumentList(); $documentList->addDocumentIdentifiers( array( 3973, /* document #1 @ revision 0 (initid) */ 3981 /* document #2 @ revision 4 (latest) */ ), false ); foreach ($documentList as $docId => $rawDoc) { printf("* Document {id = '%d', revision = '%d', title = '%s'}.\n", $docId, $doc->getProperty('revision'), $doc->getTitle()); }
Résultat :
* Document {id = '3981', revision = '4', title = 'The Quick Brown Fox'}.
Seul document#2 est retourné (car spécifié avec son latest id) et à sa
dernière révision (4).
13.8.4.6.3 Pour n'importe quel identifiant
Si les identifiants fournis ne sont ni initid ni latest, alors, pour obtenir
les documents correspondants il faudra modifier la propriété latest de l'objet
SearchDoc sous-jacent comme suit :
$documentList = new \DocumentList(); /* * Fournir les identifiants avec `useInitId` à `false` */ $documentList->addDocumentIdentifiers( array( 3974, /* document #1 @ revision 1*/ 3978 /* document #2 @ revision 1 */ ), false ); /* * Récupérer l'objet `SearchDoc` sous-jacent */ $search = $documentList->getSearchDocument(); /* * Positionner SearchDoc->latest à `false` */ $search->latest = false; foreach ($documentList as $docId => $rawDoc) { printf("* Document {id = '%d', revision = '%d', title = '%s'}.\n", $docId, $doc->getProperty('revision'), $doc->getTitle()); }
Résultat :
* Document {id = '3974', revision = '1', title = 'Foo Bar'}.
* Document {id = '3978', revision = '1', title = 'The Quick'}.
Les documents #1 et #2 sont retournés avec les documents aux révisions des identifiants demandés.
13.8.4.7 Notes
Les documents obtenus via DocumentList sont ordonnés alphabétiquement par leur
titre.
13.8.4.8 Voir aussi
13.9 Classe Layout
La classe Layout permet d'évaluer un fichier de
template, ou une chaîne de caractère respectant la
syntaxe des templates, et de produire le résultat.
13.9.1 Constructeur
new Layout ( string $caneva = "", (Action) & $action = null, string $template = "[OUT]" )
13.9.1.1 Liste des paramètres
- (string)
caneva: - Chemin d'accès à un fichier de template textuel, c'est-à-dire non binaire
(e.g.
FOO/Layout/bar.html). Le contenu du fichier spécifié sert alors de template. - (Action)
action: - L'objet
Actionassociée à l'évaluation du template. L'action rend disponible les clefs des paramètres applicatifs. - (string)
template: - Contenu du template. Si
canevan'est pas spécifié, ou n'est pas accessible, alors le contenu du template sera affecté avec cette valeur. Dans le cas contraire, cette valeur est ignorée.
13.9.1.2 Exemples
- Exemple #1
Instanciation à partir d'un fichier de template FOO/Layout/bar.xml :
$layout = new Layout("FOO/Layout/bar.xml");
- Exemple #2
Instanciation à partir d'un template contenu dans une chaîne de caractères :
$layout = new Layout( "", null, "<p>Bonjour [NOM] [PRENOM].</p><p>La température est actuellement de [TEMPC]°C.</p>" ); $layout->eSet("NOM","Watson"); $layout->eSet("PRENOM","Robert"); $layout->eSet("TEMPC","23"); print $layout->gen();
13.9.1.3 Voir aussi
13.9.2 Layout::gen()
La méthode gen() permet de lancer la génération du template après avoir
positionné les valeurs des balises à l'aide des méthodes set() et
setBlockData().
13.9.2.1 Description
string gen ( void )
Le résultat est retourné sous la forme d'une chaîne de caractères.
13.9.2.1.1 Avertissements
Aucun.
13.9.2.2 Liste des paramètres
Aucun.
13.9.2.3 Valeur de retour
La méthode retourne une chaîne de caractère contenant le résultat de l'évaluation du template.
13.9.2.4 Erreurs / Exceptions
Aucune.
13.9.2.5 Historique
Aucun.
13.9.2.6 Exemples
- Exemple #1
Dans cet exemple, on va utiliser le mécanisme de template pour générer
dynamiquement des balises de blocs [BLOCK XXX]...[ENDBLOCK XXX].
Fichier de template MOVIES/Layout/movies.xml :
<ul> [BLOCK MOVIES] <li> <p><span class="movie_title">[MOVIE_TITLE]</span> (<span class="movie_date">[MOVIE_DATE]</span>)</p> <p>Characters: <ul>[BLOCK [CHARACTERS]] <li>[CHARACTER]</li>[ENDBLOCK [CHARACTERS]] </ul> </p> </li> [ENDBLOCK MOVIES] </ul> EOF;
Contrôleur :
$layout = new Layout("MOVIES/Layout/movies.xml"); $layout->setBlockData( 'MOVIES', array( array( 'MOVIE_TITLE' => htmlspecialchars('Star Wars: A New Hope'), 'MOVIE_DATE' => '1977', 'CHARACTERS' => 'CHARACTERS_SW_A_NEW_HOPE' ), array( 'MOVIE_TITLE' => htmlspecialchars('Star Wars: The Empire Strikes Back'), 'MOVIE_DATE' => '1980', 'CHARACTERS' => 'CHARACTERS_SW_THE_EMPIRE_STRIKES_BACK' ), array( 'MOVIE_TITLE' => htmlspecialchars('Star Wars: Return of the Jedi'), 'MOVIE_DATE' => '1983', 'CHARACTERS' => 'CHARACTERS_SW_RETURN_OF_THE_JEDI' ) ) ); $layout->setBlockData( 'CHARACTERS_SW_A_NEW_HOPE', array( array( 'CHARACTER' => 'Chewbacca' ), array( 'CHARACTER' => 'Luke Skywalker' ), array( 'CHARACTER' => 'Han Solo' ) ) ); $layout->setBlockData( 'CHARACTERS_SW_THE_EMPIRE_STRIKES_BACK', array( array( 'CHARACTER' => 'Yoda' ), array( 'CHARACTER' => 'Boba Fett' ) ) ); $layout->setBlockData( 'CHARACTERS_SW_RETURN_OF_THE_JEDI', array( array( 'CHARACTER' => 'Emperor Palpatine' ), array( 'CHARACTER' => 'Wicket' ) ) ); print $layout->gen();
Le premier niveau de blocs [BLOCK MOVIES] va dupliquer les chaînes
[BLOCK [CHARACTERS]] pour donner de nouveau blocs
-
[BLOCK CHARACTERS_SW_A_NEW_HOPE], -
[BLOCK CHARACTERS_SW_THE_EMPIRE_STRIKES_BACK]et -
[BLOCK CHARACTERS_SW_RETURN_OF_THE_JEDI.
Ensuite, ces blocs [BLOCK CHARACTERS_SW_xxx] sont évalués avec le contenu de
leur setBlockData('CHARACTERS_SW_xxx') respectif.
Résultat :
<ul> <li> <p><span class="movie_title">Star Wars: A New Hope</span> (<span class="movie_date">1977</span>)</p> <p>Characters: <ul> <li>Chewbacca</li> <li>Luke Skywalker</li> <li>Han Solo</li> </ul> </p> </li> <li> <p><span class="movie_title">Star Wars: The Empire Strikes Back</span> (<span class="movie_date">1980</span>)</p> <p>Characters: <ul> <li>Yoda</li> <li>Boba Fett</li> </ul> </p> </li> <li> <p><span class="movie_title">Star Wars: Return of the Jedi</span> (<span class="movie_date">1983</span>)</p> <p>Characters: <ul> <li>Emperor Palpatine</li> <li>Wicket</li> </ul> </p> </li> </ul>
13.9.2.7 Notes
L'expansion des balises est faite dans l'ordre suivant :
- balise de bloc (e.g.
[BLOCK xxx]...[ENDBLOCK xxx]) ; - balise conditionnelle (e.g.
[IF xxx]...[ENDIF xxx],[IFNOT xxx]...[ENDIF xxx]) ; - balise d'internationalisation de texte (e.g.
[TEXT:xxx]) ; - balise de clef atomique (e.g.
[xxx]) définie via les méthodeseSet()ouset(); - balise de paramètre applicatif (si $action présent dans le constructeur).
- balise de référence d'image (e.g.
[IMG:xxx]) ; - balise de zone (e.g.
[ZONE xxx]) ; - balise de référence ou de code JavaScript (e.g.
[JS:REF],[JS:CODE]) ; - balise de référence ou de code CSS (e.g
[CSS:REF],[CSS:CODE]).
13.9.2.8 Voir aussi
13.9.3 Layout::set()
La méthode set() permet de spécifier les valeurs des balises (e.g. [TAG])
du template.
13.9.3.1 Description
void set ( string $tag, string $val )
13.9.3.1.1 Avertissements
Les valeurs ne sont pas encodées. Si vous avez un template HTML, il faut utiliser la méthode eSet pour encoder les valeurs si ce n'est pas un fragment HTML.
Si la valeur contient une référence à une zone, (exemple : "[ZONE
MY:MYZONE]"), la zone sera interprétée au contrainte de la méthode
eSet.
13.9.3.2 Liste des paramètres
- (string)
tag - Le nom de la balise à affecter. Le nom de la balise est spécifié sans les
crochets ouvrant (
[) et fermant (]). - (string)
val - La valeur à affecter à la balise.
13.9.3.3 Valeur de retour
Aucune.
13.9.3.4 Erreurs / Exceptions
Aucune.
13.9.3.5 Historique
Aucun.
13.9.3.6 Exemples
- Exemple #1
Fichier de template FOO/Layout/bar.xml :
<div> <p>Bonjour [NOM] [PRENOM],</p> <p>La température est actuellement de [TEMPC]°C.</p> </div>
Contrôleur :
$nom = "Doe"; $prenom = "John"; $tempC = "20"; $layout->set("NOM", htmlspecialchars($nom)); $layout->set("PRENOM", htmlspecialchars($prenom)); $layout->set("TEMPC", sprintf("%02d",$temp)); print $layout->gen();
13.9.3.7 Notes
Pour se prémunir de toute attaque du type XSS (Cross-site scripting) il vous faudra potentiellement échapper les valeurs en fonction du contexte dans lesquelles elles seront utilisés.
Par exemple, pour un fragment (ou un document) HTML il vous faudra utiliser la
la méthode eSet() ou la fonction PHP
htmlspecialchars() afin d'échapper les caractères qui
pourraient être utilisés pour injecter du code HTML (ou JavaScript) dans le
résultat du template.
13.9.3.8 Voir aussi
- Méthode
Layout::setBlockData() - Méthode
Layout::eSet()
13.9.4 Layout::eSet()
La méthode eSet() permet de spécifier les valeurs des balises (e.g. [TAG])
de template HTML ou XML.3.2.12
13.9.4.1 Description
void eSet ( string $tag, string $val )
La différence entre cette méthode et la méthode set() est qu'elle
encode les valeurs lors de l'insertion. L'encodage est réalisée par la
fonction PHP htmlspecialchars().
Liste des caractères encodés :
| Caractère | Encodage |
|---|---|
| " | " |
| ' | &039; |
| > | > |
| < | < |
13.9.4.1.1 Avertissements
Cette méthode doit être utilisée si le champ est entre ' (quote) ou "
(double-quote).
Si la valeur contient une référence à une [zone][zone], (exemple : "[ZONE
MY:MYZONE]"), la zone ne sera pas interprétée.
3.2.21 Si la valeur contient une
référence à un paramètre applicatif, (exemple :
"[CORE_CLIENT]"), le paramètre ne sera pas interprété.
13.9.4.2 Liste des paramètres
- (string)
tag - Le nom de la balise à affecter. Le nom de la balise est spécifié sans les
crochets ouvrant (
[) et fermant (]). - (string)
val - La valeur à affecter à la balise.
13.9.4.3 Valeur de retour
Aucune.
13.9.4.4 Erreurs / Exceptions
Aucune.
13.9.4.5 Historique
Aucun.
13.9.4.6 Exemples
- Exemple #1
Fichier de template FOO/Layout/bar.xml :
<div> <p data-name="[NOM]" data-firstname="[PRENOM]"> [Message] </p> </div>
Contrôleur :
$nom = "Doe"; $prenom = 'John dit "l\'inconnu"'; $msg = "Écart admissible : 20 < x < 30"; $layout->eSet("NOM", $nom); $layout->eSet("PRENOM", $prenom); $layout->eSet("MESSAGE", $msg); print $layout->gen();
Résultat :
<div> <p data-name="Doe" data-firstname="John dit "l'inconnu"> Écart admissible : 20 < x < 30 </p> </div>
13.9.4.7 Notes
Attention, dans les cas de parties d'url, il faut utiliser la fonction
urlencode au lieu de htmlspecialchars
afin de garantir l'intégrité de l'url. Dans ce cas, il faut utiliser la méthode
Layout::set() et appeler manuellement urlencode.
13.9.4.8 Voir aussi
- Méthode
Layout::set() - Chapitre Encodage pour format HTML
13.9.5 Layout::setBlockData()
La méthode setBlockData() permet de spécifier les valeurs des balises
contenues dans les blocs (e.g. [BLOCK TAG]...[ENDBLOCK TAG]) du template.
13.9.5.1 Description
void setBlockData ( string $blockTag, array $data = NULL )
13.9.5.1.1 Avertissements
Aucun.
13.9.5.2 Liste des paramètres
- (string)
tag - Le nom de la balise du bloc à affecter. Le nom de la balise est spécifié
sans les crochets ouvrant (
[) et fermant (]). - (array)
data - La liste des couples (
TAG=>valeur) à affecter dans le bloc.
13.9.5.3 Valeur de retour
Aucune.
13.9.5.4 Erreurs / Exceptions
Aucune.
13.9.5.5 Historique
Aucun.
13.9.5.6 Exemples
- Exemple #1
Fichier de template MOVIES/Layout/movies.xml :
<ul> [BLOCK MOVIES] <li> <span class="movie_title">[MOVIE_TITLE]</span> (<span class="movie_date">[MOVIE_DATE]</span>) </li> [ENDBLOCK MOVIES] </ul>
Contrôleur :
$layout = new Layout("MOVIES/Layout/movies.xml"); $movies = array( array( 'MOVIE_TITLE' => htmlspecialchars('Star Wars: A New Hope'), 'MOVIE_DATE' => '1977' ), array( 'MOVIE_TITLE' => htmlspecialchars('Star Wars: The Empire Strikes Back'), 'MOVIE_DATE' => '1980' ), array( 'MOVIE_TITLE' => htmlspecialchars('Star Wars: Return of the Jedi'), 'MOVIE_DATE' => '1983' ) ); print $layout->gen();
13.9.5.7 Notes
Pour se prémunir de toute attaque du type XSS (Cross-site scripting) il vous faudra potentiellement échapper les valeurs en fonction du contexte dans lesquelles elles seront utilisés.
Par exemple, pour un fragment (ou un document) HTML il vous faudra utiliser la
méthode eSetBlockData() ou la fonction PHP
htmlspecialchars() afin d'échapper les caractères qui
pourraient être utilisés pour injecter du code HTML (ou JavaScript) dans le
résultat du template.
13.9.5.8 Voir aussi
- Méthode
Layout::set()
13.9.6 Layout::eSetBlockData()
La méthode eSetBlockData() permet de spécifier les valeurs des balises
contenues dans les blocs (e.g. [BLOCK TAG]...[ENDBLOCK TAG]) pour des
templates HTML ou XML.3.2.12
13.9.6.1 Description
void eSetBlockData ( string $blockTag, array $data = NULL )
La différence entre cette méthode et la méthode setBlockData()
et qu'elle encode les valeurs lors de l'insertion. L'encodage est réalisée par
la fonction PHP htmlspecialchars().
Liste des caractères encodés :
| Caractère | Encodage |
|---|---|
| " | " |
| ' | &039; |
| > | > |
| < | < |
13.9.6.1.1 Avertissements
Aucun.
13.9.6.2 Liste des paramètres
- (string)
tag - Le nom de la balise du bloc à affecter. Le nom de la balise est spécifié
sans les crochets ouvrant (
[) et fermant (]). - (array)
data - La liste des couples (
TAG=>valeur) à affecter dans le bloc.
13.9.6.3 Valeur de retour
Aucune.
13.9.6.4 Erreurs / Exceptions
Aucune.
13.9.6.5 Historique
Aucun.
13.9.6.6 Exemples
- Exemple #1
Fichier de template MOVIES/Layout/movies.xml :
<ul>[BLOCK MOVIES] <li> <span class="movie_title">[MOVIE_TITLE]</span> (<span class="movie_date">[MOVIE_DATE]</span>) </li>[ENDBLOCK MOVIES]</ul>
Contrôleur :
$layout = new Layout("MOVIES/Layout/movies.xml"); $movies = array( array( 'MOVIE_TITLE' => '"La guerre des étoiles": <Un nouvel espoir>', 'MOVIE_DATE' => '1977' ), array( 'MOVIE_TITLE' => '"La guerre des étoiles": <L\'empire contre-attaque>', 'MOVIE_DATE' => '1980' ), array( 'MOVIE_TITLE' => ('"La guerre des étoiles": <Le retour du Jedi>'), 'MOVIE_DATE' => '1983' ) ); $layout->eSetBlockData('MOVIES', $movies); print $layout->gen();
Résultat :
<ul> <li> <span class="movie_title">"La guerre des étoiles": <Un nouvel espoir></span> (<span class="movie_date">1977</span>) </li> <li> <span class="movie_title">"La guerre des étoiles": <L'empire contre-attaque></span> (<span class="movie_date">1980</span>) </li> <li> <span class="movie_title">"La guerre des étoiles": <Le retour du Jedi></span> (<span class="movie_date">1983</span>) </li> </ul>
13.9.6.7 Notes
Aucune.
13.9.6.8 Voir aussi
- Méthode
Layout::setBlockData()
13.10 Classe Log
La classe Log permet d'envoyer des messages dans un journal d'événements
(syslog ou fichier spécifique).
Chaque message comporte un niveau de log, et le paramètre applicatif
CORE_LOGLEVEL (ou la méthode
Log::setLogLevel()) permet de filtrer quels messages
seront journalisés par rapport à ce niveau de log.
Table de correspondance entre le niveau de log et le code de niveau de log :
| Niveau de log | Code de niveau de log |
|---|---|
| Log::CALLSTACK | C |
| Log::DEBUG | D |
| Log::DEPRECATED | O |
| Log::ERROR | E |
| Log::FATAL | F |
| Log::INFO | I |
| Log::TRACE | T |
| Log::WARNING | W |
La valeur par défaut du filtre de messages de la classe Log est spécifiée par
le paramètre applicatif CORE_LOGLEVEL.
La valeur du filtre de messages peut ensuite être modifiée avec la méthode
Log::setLogLevel().
La valeur par défaut du paramètre applicatif CORE_LOGLEVEL
étant IWE, seuls les messages émis avec les niveaux de log Log::INFO,
Log::WARNING et Log::ERROR seront journalisés.
Pour journaliser tous les messages, il faut positionner CORE_LOGLEVEL (ou
faire un appel à Log::setLogLevel()) avec la valeur
CDOEFITW (liste de tous les codes existants).
13.10.1 Constructeur
new Log ( string $logfile = "", string $application = "", string $function = "" )
13.10.1.1 Avertissements
Si plusieurs requêtes concurrentes utilisent le même fichier de journal
logfile, alors l'ordre et l'intégrité d'écriture des messages ne sont pas
garantis.
Pour garantir l'ordre et l'intégrité d'écriture des messages par des requêtes
concurrentes, il faut alors utiliser le journal syslog en spécifiant
une chaîne vide pour logfile.
13.10.1.2 Liste des paramètres
- (string)
logfile - Si
logfileest vide, alors les messages sont envoyés au journal d'événement système parsyslog. Sinon, les messages sont ajoutés au fichier référencé parlogfile(chemin absolu ou relatif au répertoire courant). - (string)
application - Le nom de l'application qui génère le message.
- (string)
function - Le nom de la fonction qui génère le message.
13.10.1.3 Exemples
function foo($id) { /* Log to syslog */ $log = new Log('', 'Sample', 'Test'); /* Log debug message if CORE_LOGLEVEL contains 'D' */ $log->debug(sprintf("id = '%s'", $id)); }
Sortie :
Jul 3 14:15:92 localhost [D] Dynacase:Sample:Test: [] : id = '123'
13.10.1.4 Notes
Si le fichier logfile n'est pas spécifié, alors les messages vont dans le
journal système syslog.
Les noms application et function sont utilisés pour composer un préfixe qui
est placé devant chaque message émis par l'objet Log (voir exemple ci-dessus
et dans la documentation des méthodes).
13.10.1.5 Voir aussi
13.10.2 Log::debug()
La méthode debug() journalise un message avec le niveau de log Log::WARNING.
13.10.2.1 Description
void debug ( string $message )
13.10.2.1.1 Avertissements
Le paramètre applicatif CORE_LOGLEVEL doit contenir la
lettre D pour que le message soit journalisé.
13.10.2.2 Liste des paramètres
- (string)
message - Le message à journaliser.
13.10.2.3 Valeur de retour
Aucune.
13.10.2.4 Erreurs / Exceptions
Aucune.
13.10.2.5 Historique
Aucun.
13.10.2.6 Exemples
$log = new Log(); $log->debug("I was here!");
Sortie :
Jul 3 14:15:92 localhost [D] Dynacase: [] : I was here!
13.10.2.7 Notes
Aucune.
13.10.2.8 Voir aussi
13.10.3 Log::deprecated()
La méthode deprecated() journalise un message avec le niveau de log
Log::DEPRECATED.
13.10.3.1 Description
void deprecated ( string $message )
13.10.3.1.1 Avertissements
Le paramètre applicatif CORE_LOGLEVEL doit contenir la lettre
O pour que le message soit journalisé.
13.10.3.2 Liste des paramètres
- (string)
message - Le message à journaliser.
13.10.3.3 Valeur de retour
Aucune.
13.10.3.4 Erreurs / Exceptions
Aucune.
13.10.3.5 Historique
Aucun.
13.10.3.6 Exemples
function foo() { bar(); } function bar() { baz(); } function baz() { $log = new Log(); $log->deprecated('Use of baz is deprecated. Please use qux() instead.'); } foo();
Sortie :
Jul 3 10:11:12 localhost [O] Dynacase: [] : Use of baz is deprecated. Please use qux() instead. bar called in foo(), file /…/….php:16
13.10.3.7 Notes
Aucune.
13.10.3.8 Voir aussi
13.10.4 Log::error()
La méthode error() journalise un message avec le niveau de log Log::ERROR.
13.10.4.1 Description
void error ( string $message )
13.10.4.1.1 Avertissements
Le paramètre applicatif CORE_LOGLEVEL doit contenir la lettre
E pour que le message soit journalisé.
13.10.4.2 Liste des paramètres
- (string)
message - Le message à journaliser.
13.10.4.3 Valeur de retour
Aucune.
13.10.4.4 Erreurs / Exceptions
Aucune.
13.10.4.5 Historique
Aucun.
13.10.4.6 Exemples
$log = new Log(); $log->error("Oops, something went wrong...");
Sortie :
Jul 3 14:15:92 localhost [E] Dynacase: [] : Oops, something went wrong...
13.10.4.7 Notes
Aucune.
13.10.4.8 Voir aussi
13.10.5 Log::fatal()
La méthode fatal() journalise un message avec le niveau de log Log::FATAL.
13.10.5.1 Description
void fatal ( string $message )
13.10.5.1.1 Avertissements
Le paramètre applicatif CORE_LOGLEVEL doit contenir la lettre
F pour que le message soit journalisé.
13.10.5.2 Liste des paramètres
- (string)
message - Le message à journaliser.
13.10.5.3 Valeur de retour
Aucune.
13.10.5.4 Erreurs / Exceptions
Aucune.
13.10.5.5 Historique
Aucun.
13.10.5.6 Exemples
$log = new Log(); $log->fatal("STOP: 0x00000019 (0x00000000, 0xC00E0FF0, 0xFFFFEFD4, 0xC0000000) BAD_POOL_HEADER");
Sortie :
Jul 3 14:15:92 localhost [D] Dynacase: [] : STOP: 0x00000019 (0x00000000, 0xC00E0FF0, 0xFFFFEFD4, 0xC0000000) BAD_POOL_HEADER
13.10.5.7 Notes
Aucune.
13.10.5.8 Voir aussi
13.10.6 Log::info()
La méthode info() journalise un message avec le niveau de log Log::INFO.
13.10.6.1 Description
void info ( string $message )
13.10.6.2 Avertissements
Le paramètre applicatif CORE_LOGLEVEL doit contenir la lettre
I pour que le message soit journalisé.
13.10.6.3 Liste des paramètres
- (string)
message - Le message à journaliser.
13.10.6.4 Valeur de retour
Aucune.
13.10.6.5 Erreurs / Exceptions
Aucune.
13.10.6.6 Historique
Aucun.
13.10.6.7 Exemples
$log = new Log(); $log->info("lp0 on fire");
Sortie :
Jul 3 14:15:92 localhost [I] Dynacase: [] : lp0 on fire
13.10.6.8 Notes
Aucune.
13.10.6.9 Voir aussi
13.10.7 Log::warning()
La méthode warning() journalise un message avec le niveau de log
Log::WARNING.
13.10.7.1 Description
void warning ( string $message )
13.10.7.1.1 Avertissements
Le paramètre applicatif CORE_LOGLEVEL doit contenir la lettre
W pour que le message soit journalisé.
13.10.7.2 Liste des paramètres
- (string)
message - Le message à journaliser.
13.10.7.3 Valeur de retour
Aucune.
13.10.7.4 Erreurs / Exceptions
Aucune.
13.10.7.5 Historique
Aucun.
13.10.7.6 Exemples
$log = new Log(); $log->warning("This is just a warning...");
Sortie :
Jul 3 14:15:92 localhost [W] Dynacase: [] : This is just a warning...
13.10.7.7 Notes
Aucune.
13.10.7.8 Voir aussi
13.10.8 Log::setLogLevel()
3.2.18
La méthode setLogLevel() permet de spécifier le filtre des messages à
journaliser.
13.10.8.1 Description
void setLogLevel ( string $logLevel )
13.10.8.1.1 Avertissements
Aucun.
13.10.8.2 Liste des paramètres
- (string)
logLevel - Une chaîne contenant la liste des codes des messages à journaliser (voir
classe
Log).
13.10.8.3 Valeur de retour
Aucune.
13.10.8.4 Erreurs / Exceptions
Aucune.
13.10.8.5 Historique
Aucun.
13.10.8.6 Exemples
$log = new Log(); /* Ne logger que les messages de debug et d'erreur*/ $log->setLogLevel("DE"); $log->info("You won't see me!"); $log->debug("I was here!");
Sortie :
Jul 3 14:15:92 localhost [D] Dynacase: [] : I was here!
13.10.8.7 Notes
Aucune.
13.10.8.8 Voir aussi
13.11 Classe ApplicationParameterManager
La classe ApplicationParameterManager permet de gérer les paramètres des
applications : récupérer la valeur d'un paramètre ou positionner la valeur d'un
paramètre.
13.11.1 Paramètre utilisateur : valeur principale et valeur personnalisée
Chaque paramètre a une valeur principale, qui est déclarée initialement lors de l'installation de l'application qui le fournit.
Un paramètre peut être déclaré comme personnalisable pour l'utilisateur
(propriété 'user' => 'Y')(voir
Les paramètres applicatifs). Dans ce cas on parlera
d'un paramètre utilisateur.
Les paramètres utilisateurs peuvent être vus comme une couche qui vient s'intercaler entre la valeur principale d'un paramètre et la valeur que l'on obtient quand on interroge ce paramètre :
+-------------------------+
| P1 | P2 | P3 | ... | Pn | Valeur principale
+-------------------------+
^
|
+----+-:--+---------------+
| U1 | : | U3 | ... | Un | Valeur personnalisée
+------:------------------+
^ |
| |
| |
U1 P2 Valeur appliquée
Dans le schéma ci-dessus, les paramètres Px sont déclarés comme étant des
paramètres personnalisables, et un utilisateur a une valeur personnalisée sur
certains de ces paramètres : U1 pour P1, U3 pour P3, mais il n'a pas de
valeur personnalisée pour P2 par exemple.
Lors de l'interrogation de la valeur d'un paramètre pour cet utilisateur,
l'interrogation du paramètre P1 retournera la valeur personnalisée U1, alors
que l'interrogation du paramètre P2 retournera la valeur principale P2 du
paramètre puisque l'utilisateur n'a pas de valeur personnalisée pour ce
paramètre.
Si le paramètre principal est déclaré comme n'étant pas personnalisable, alors
l'interrogation retournera systématiquement la valeur principale Px du
paramètre, puisque l'utilisateur ne pourra pas avoir de valeur personnalisée.
13.11.2 Paramètre global
Un paramètre global (propriété 'global' => 'Y')(voir
Les paramètres applicatifs) peut être adressé sans
son application : il est transverse et est accessible sans devoir
obligatoirement spécifier l'application qui le déclare.
Un paramètre global peut aussi être un paramètre utilisateur (propriété 'user'
=> 'Y'), dans ce cas pourra être personnalisé pour un utilisateur et sa
valeur sera soumise à la mécanique présentée ci-dessus de
Paramètre utilisateur : valeur principale et valeur personnalisée.
13.11.3 Héritage de paramètres
Dans le cas ou une application B hérite d'un application parente A,
l'ensemble des paramètres de l'application parente A, ainsi que leur valeur
principale, sont recopiés dans l'application B.
Les paramètres issus de l'application parente A sont donc dupliqués sur
l'application B et leur lecture, ou écriture, est indépendante de ceux de
l'application parente A.
13.11.4 ApplicationParameterManager::getCommonParameterValue()
La méthode getCommonParameterValue() permet de récupérer la valeur principale
d'un paramètre.
13.11.4.1 Description
string static getCommonParameterValue ( mixed $application, string $parameterName )
Retourne la valeur principale du paramètre $parameterName défini sur
l'application $application.
Pour obtenir la valeur personnalisée d'un utilisateur : voir la méthode
getUserParameterValue().
13.11.4.1.1 Avertissements
Aucun.
13.11.4.2 Liste des paramètres
- (string|int|Application)
application - Le nom, l'identifiant ou l'objet
Applicationde l'application dont on souhaite avoir la valeur principale d'un de ses paramètres. - (string)
parameterName - Le nom du paramètre dont on souhaite avoir la valeur principale.
13.11.4.3 Valeur de retour
Retourne une chaîne de caractères avec la valeur principale du paramètre, ou
null si le paramètre ou l'application demandé n'est pas trouvé.
13.11.4.4 Erreurs / Exceptions
Aucune.
13.11.4.5 Historique
Aucun.
13.11.4.6 Exemples
/* En utilisant le nom de l'application */ printf("CORE:CORE_START_APP = '%s'\n", ApplicationParameterManager::getCommonParameterValue('CORE', 'CORE_START_APP')); /* ou en utilisant l'objet Application de l'action courante */ printf("CORE:CORE_START_APP = '%s'\n", ApplicationParameterManager::getCommonParameterValue($action->parent, 'CORE_START_APP'));
Sortie :
CORE:CORE_START_APP = 'APP_SWITCHER' CORE:CORE_START_APP = 'APP_SWITCHER'
13.11.4.7 Notes
- L'argument
applicationpeut aussi être la constanteApplicationParameterManager::CURRENT_APPLICATION(pour référencer l'application courante) ouApplicationParameterManager::GLOBAL_PARAMETER(pour adresser des paramètres globaux).
13.11.4.8 Voir aussi
13.11.5 ApplicationParameterManager::getParameter()
La méthode getParameter() permet de récupérer la définition d'un paramètre.
13.11.5.1 Description
array static getParameter ( mixed $application, string $parameterName )
Retourne un array contenant les propriétés de la définition du paramètre de
l'application.
13.11.5.1.1 Avertissements
Cette méthode retourne la définition du paramètre et non la valeur (principale ou personnalisée) de celui-ci.
13.11.5.2 Liste des paramètres
- (string|int|Application)
application - Le nom, l'identifiant ou l'objet
Applicationde l'application dont on souhaite avoir la définition d'un de ses paramètres. - (string)
parameterName - Le nom du paramètre dont on souhaite avoir la définition.
13.11.5.3 Valeur de retour
Retourne un array contenant les propriétés de la définition du paramètre.
array(
'name' => $paramName, /* Nom du paramètre */
'isuser' => 'Y' | 'N', /* Paramètre personnalisable ? */
'isstyle' => 'Y' | 'N', /* Paramètre de style ? */
'isglob' => 'Y' | 'N', /* Paramètre global ? */
'appid' => $applicationId, /* Id de l'application */
'desc' => $paramDescription, /* Description du paramètre */
'kind' => $paramKind /* Type du paramètre */
)
13.11.5.4 Erreurs / Exceptions
Si le paramètre ou l'application spécifié n'est pas trouvé, alors une exception
\Dcp\ApplicationParameterManager\Exception est levée.
13.11.5.5 Historique
Aucun.
13.11.5.6 Exemples
try { $paramDef = ApplicationParameterManager::getParameter('CORE', 'CORE_LANG'); } catch (\Dcp\ApplicationParameterManager\Exception $e) { printf("Parameter or application not found.\n"); throw $e; } var_export($paramDef);
Sortie :
$ ./wsh.php --api=test array ( 'name' => 'CORE_LANG', 'isuser' => 'Y', 'isstyle' => 'N', 'isglob' => 'Y', 'appid' => '1', 'descr' => 'language', 'kind' => 'enum(en_US|fr_FR)', )
13.11.5.7 Notes
- L'argument
applicationpeut aussi être la constanteApplicationParameterManager::CURRENT_APPLICATION(pour référencer l'application courante) ouApplicationParameterManager::GLOBAL_PARAMETER(pour adresser des paramètres globaux).
13.11.5.8 Voir aussi
Aucun.
13.11.6 ApplicationParameterManager::getParameters()
La méthode getParameters() permet de récupérer la définition de tous les
paramètres d'une application.
13.11.6.1 Description
array[] static getParameters ( mixed $application )
Retourne une liste de array contenant la définition des paramètres de
l'application.
13.11.6.1.1 Avertissements
Aucun.
13.11.6.2 Liste des paramètres
- (string|int|Application)
application - Le nom, l'identifiant ou l'objet
Applicationde l'application dont on souhaite avoir la définition de tous ses paramètres.
13.11.6.3 Valeur de retour
Retourne une liste de array de définition de paramètres :
array(
0 => array(
'name' => …,
…
),
1 => array(
'name' => …,
…
),
…
)
Voir structure du array() de définition des paramètres dans
valeur de retour de getParameter().
13.11.6.4 Erreurs / Exceptions
Si l'application n'est pas trouvée ou si aucun paramètre n'est trouvé, une
exception \Dcp\ApplicationParameterManager\Exception est levée.
13.11.6.5 Historique
Aucun.
13.11.6.6 Exemples
try { $paramDefList = ApplicationParameterManager::getParameters('CORE'); } catch(\Dcp\ApplicationParameterManager\Exception $e) { printf("Application not found or no parameters found."); throw $e; } foreach ($paramDefList as $paramDef) { printf("name = '%s', isuser = '%s', kind = '%s'\n", $paramDef['name'], $paramDef['isuser'], $paramDef['kind']); }
Sortie :
name = 'INIT', isuser = 'N', kind = 'text' name = 'CORE_LOGLEVEL', isuser = 'N', kind = 'text' name = 'VERSION', isuser = 'N', kind = 'static' … name = 'CORE_ALLOW_GUEST', isuser = 'N', kind = 'enum(yes|no)' name = 'CORE_MAILACTION', isuser = 'N', kind = 'text' name = 'CORE_LANG', isuser = 'Y', kind = 'enum(en_US|fr_FR)'
13.11.6.7 Notes
- L'argument
applicationpeut aussi être la constanteApplicationParameterManager::CURRENT_APPLICATION(pour référencer l'application courante) ouApplicationParameterManager::GLOBAL_PARAMETER(pour adresser des paramètres globaux).
13.11.6.8 Voir aussi
13.11.7 ApplicationParameterManager::getParameterValue()
La méthode getParameterValue() permet de récupérer la valeur d'un paramètre
d'une application.
13.11.7.1 Description
string static getParameterValue ( mixed $application, string $parameterName )
Retourne la valeur du paramètre $parameterName appartenant à l'application
$application en suivant la logique de
Valeur principale et valeur personnalisée.
13.11.7.1.1 Avertissements
Aucun.
13.11.7.2 Liste des paramètres
- (string|int|Application)
application - Le nom, l'identifiant ou l'objet
Applicationde l'application dont on souhaite avoir la valeur d'un de ses paramètres. - (string)
parameterName - Le nom du paramètre dont on souhaite avoir la valeur.
13.11.7.3 Valeur de retour
Retourne une chaîne de caractère contenant la valeur du paramètre.
Si l'application ou le paramètre spécifié n'existe pas alors la valeur null
est retournée.
13.11.7.4 Erreurs / Exceptions
Aucune.
13.11.7.5 Historique
Aucun.
13.11.7.6 Exemples
/* Paramètre utilisateur CORE_LANG */ $paramVal = ApplicationParameterManager::getParameterValue('CORE', 'CORE_LANG'); printf("CORE:CORE_LANG = '%s'\n", $paramVal); /* Paramètre non-utilisateur CORE_START_APP */ $paramVal = ApplicationParameterManager::getParameterValue('CORE', 'CORE_START_APP'); printf("CORE:CORE_START_APP = '%s'\n", $paramVal);
Sortie :
CORE:CORE_LANG = 'fr_FR' CORE:CORE_START_APP = 'APP_SWITCHER'
13.11.7.7 Notes
- L'argument
applicationpeut aussi être la constanteApplicationParameterManager::CURRENT_APPLICATION(pour référencer l'application courante) ouApplicationParameterManager::GLOBAL_PARAMETER(pour adresser des paramètres globaux).
13.11.7.8 Voir aussi
13.11.8 ApplicationParameterManager::getScopedParameterValue()
La méthode getScopedParameterValue() permet de lire la valeur des paramètres
accessibles dans le contexte courant.
13.11.8.1 Description
string static getScopedParameterValue ( string $parameterName )
Retourne la valeur du paramètre $parametreName accessible dans le contexte
courant.
Le contexte courante contient :
- Les paramètres de l'application courante (valeurs principales) ;
- Les paramètres volatiles ;
- Les paramètres globaux.
13.11.8.1.1 Avertissements
Aucun.
13.11.8.2 Liste des paramètres
- (string)
parameterName - Le nom du paramètre dont on souhaite obtenir la valeur.
13.11.8.3 Valeur de retour
Retourne une chaîne de caractères contenant la valeur du paramètre.
Si une chaîne vide est retournée, c'est que soit le paramètre n'a pas été trouvé, soit que la valeur du paramètre est effectivement une chaîne vide.
13.11.8.4 Erreurs / Exceptions
Aucune.
13.11.8.5 Historique
Aucun.
13.11.8.6 Exemples
printf("CORE_ABSURL = '%s'", ApplicationParameterManager::getScopedParameterValue('CORE_ABSURL'));
Sortie :
CORE_ABSURL = 'http://www.example.net/'
13.11.8.7 Notes
Aucune.
13.11.8.8 Voir aussi
Aucun.
13.11.9 ApplicationParameterManager::getUserParameterDefaultValue()
La méthode getUserParameterDefaultValue() permet de récupérer la valeur
principale d'un paramètre d'une application.
13.11.9.1 Description
string getUserParameterDefaultValue ( mixed $application, string $parameterName )
Retourne la valeur principale du paramètre $parameterName appartenant à
l'application $application.
13.11.9.1.1 Avertissements
Aucun.
13.11.9.2 Liste des paramètres
- (string|int|Application)
application - Le nom, l'identifiant ou l'objet
Applicationde l'application dont on souhaite avoir la valeur principale d'un de ses paramètres. - (string)
parameterName - Le nom du paramètre dont on souhaite avoir la valeur principale.
13.11.9.3 Valeur de retour
Retourne une chaîne de caractères avec la valeur principale du paramètre, ou
null si le paramètre ou l'application demandé ne sont pas trouvés.
13.11.9.4 Erreurs / Exceptions
Aucune.
13.11.9.5 Historique
Aucun.
13.11.9.6 Exemples
/* Valeur principale du paramètre CORE_LANG */ $paramVal = ApplicationParameterManager::getUserParameterDefaultValue('CORE', 'CORE_LANG'); printf("CORE:CORE_LANG principal value = '%s'\n", $paramVal); /* Valeur personnalisée de CORE_LANG pour l'utilisateur courant */ $paramVal = ApplicationParameterManager::getUserParameterValue('CORE', 'CORE_LANG'); printf("CORE:CORE_LANG personalized value = '%s'\n", $paramVal); /* Valeur finale du paramètre CORE_LANG appliquée sur l'utilisateur */ $paramVal = ApplicationParameterManager::getParameterValue('CORE', 'CORE_LANG'); printf("CORE:CORE_LANG final value = '%s'\n", $paramVal);
Sortie :
CORE:CORE_LANG principal value = 'fr_FR' CORE:CORE_LANG personalized value = '' CORE:CORE_LANG final value = 'fr_FR'
Cet exemple montre que la valeur finale appliquée sur l'utilisateur est la valeur principale, puisqu'il n'y a pas de valeur personnalisée explicitement déclarée sur l'utilisateur.
13.11.9.7 Notes
L'argument
applicationpeut aussi être la constanteApplicationParameterManager::CURRENT_APPLICATION(pour référencer l'application courante) ouApplicationParameterManager::GLOBAL_PARAMETER(pour adresser des paramètres globaux).Cette méthode est équivalente à un appel à la méthode
getCommonParameterValue().
13.11.9.8 Voir aussi
13.11.10 ApplicationParameterManager::getUserParameterValue()
La méthode getUserParameterValue() permet de récupérer la valeur personnalisée
d'un paramètre d'une application.
13.11.10.1 Description
string static getUserParameterValue ( mixed $application, string $parameterName, string $userId = null )
Retourne la valeur personnalisée du paramètre $parameterName appartenant à
l'application $application.
Pour obtenir la valeur principale d'un paramètre : voir méthode
getCommonParameterValue().
13.11.10.1.1 Avertissements
Aucun.
13.11.10.2 Liste des paramètres
- (string|int|Application)
application - Le nom, l'identifiant ou l'objet
Applicationde l'application dont on souhaite avoir la valeur personnalisée d'un de ses paramètres. - (string)
parameterName - Le nom du paramètre dont on souhaite avoir la valeur personnalisée.
- (int)
userId - L'identifiant de l'utilisateur pour lequel on souhaite avoir la valeur
personnalisée du paramètre. Si l'identifiant n'est pas spécifié (ou si
nullest spécifié), alors c'est l'identifiant de l'utilisateur actuellement connecté qui est utilisé.
13.11.10.3 Valeur de retour
Retourne une chaîne de caractères avec la valeur personnalisée du paramètre, ou
null si le paramètre ou l'application demandé n'est pas trouvé.
13.11.10.4 Erreurs / Exceptions
Aucune.
13.11.10.5 Historique
Aucun.
13.11.10.6 Exemples
/* Valeur principale de CORE_LANG */ printf("CORE:CORE_LANG principal value = '%s'\n", ApplicationParameterManager::getCommonParameterValue('CORE', 'CORE_LANG')); /* Valeur principale de CORE_LANG pour l'utilisateur courant */ printf("CORE:CORE_LANG personalized value = '%s'\n", ApplicationParameterManager::getUserParameterValue('CORE', 'CORE_LANG')); /* Valeur appliquée de CORE_LANG pour l'utilisateur courant */ printf("CORE:CORE_LANG applied value = '%s'\n", ApplicationParameterManager::getParameterValue('CORE', 'CORE_LANG'));
Sortie :
CORE:CORE_LANG principal value = 'fr_FR' CORE:CORE_LANG personalized value = '' CORE:CORE_LANG applied value = 'fr_FR'
13.11.10.7 Notes
- L'argument
applicationpeut aussi être la constanteApplicationParameterManager::CURRENT_APPLICATION(pour référencer l'application courante) ouApplicationParameterManager::GLOBAL_PARAMETER(pour adresser des paramètres globaux).
13.11.10.8 Voir aussi
13.11.11 ApplicationParameterManager::resetCache()
La méthode resetCache() permet de vider le cache des valeurs des paramètres.
13.11.11.1 Description
void static resetCache ()
Lorsque des paramètres sont interrogés, via les méthodes de la classe
ApplicationParameterManager, les résultats sont mis en cache afin de minimiser
les requêtes en base de données lorsque ces mêmes paramètres sont ré-interrogés.
La méthode resetCache() permet alors de vider ce cache, et donc de forcer à ce
que les méthodes appelées fassent des requêtes sur la base de données pour
interroger la valeur d'un paramètre.
13.11.11.1.1 Avertissements
Le cache n'est pas partagé entre les différentes requêtes. Chaque requête à son propre cache et des incohérences peuvent donc apparaître lors de la lecture ou l'écriture d'un même paramètre par deux requêtes concurrentes.
13.11.11.2 Liste des paramètres
La méthode ne prend pas d'argument.
13.11.11.3 Valeur de retour
La méthode ne retourne rien.
13.11.11.4 Erreurs / Exceptions
Aucune.
13.11.11.5 Historique
Aucun.
13.11.11.6 Exemples
ApplicationParameterManager::resetCache();
13.11.11.7 Notes
Aucune.
13.11.11.8 Voir aussi
Aucun.
13.11.12 ApplicationParameterManager::setCommonParameterValue()
La méthode setCommonParameterValue() permet d'écrire la valeur principale d'un
paramètre d'une application.
13.11.12.1 Description
void setCommonParameterValue ( mixed $application, string $parameterName, string $value )
La valeur principale du paramètre $parameterName de l'application
$application est positionnée avec la valeur $value fournie.
13.11.12.1.1 Avertissements
Aucun.
13.11.12.2 Liste des paramètres
- (string|int|Application)
application - Le nom, l'identifiant ou l'objet
Applicationde l'application dont on souhaite écrire la valeur principale d'un de ses paramètres. - (string)
parameterName - Le nom du paramètre dont on souhaite écrire la valeur principale.
- (string)
value - La valeur à inscrire comme valeur principale pour ce paramètre.
13.11.12.3 Valeur de retour
La méthode ne retourne rien.
13.11.12.4 Erreurs / Exceptions
Si le paramètre ou l'application n'existe pas alors une exception
(\Dcp\ApplicationParameterManager\Exception) est levée.
13.11.12.5 Historique
Aucun.
13.11.12.6 Exemples
/* Affiche la valeur principale de CORE_LANG */ printf("CORE:CORE_LANG principal value = '%s'\n", ApplicationParameterManager::getCommonParameterValue('CORE', 'CORE_LANG')); /* Positionne la valeur principale à 'en_US' */ try { ApplicationParameterManager::setCommonParameterValue('CORE', 'CORE_LANG', 'en_US'); } catch(\Dcp\ApplicationParameterManager\Exception $e) { printf("Error setting parameter's default value."); throw $e; } /* Affiche la valeur principale de CORE_LANG */ printf("CORE:CORE_LANG principal value = '%s'\n", ApplicationParameterManager::getCommonParameterValue('CORE', 'CORE_LANG'));
Sortie :
CORE:CORE_LANG principal value = 'fr_FR' CORE:CORE_LANG principal value = 'en_US'
13.11.12.7 Notes
* L'argument `application` peut aussi être la constante `ApplicationParameterManager::CURRENT_APPLICATION` (pour référencer l'application *courante*) ou `ApplicationParameterManager::GLOBAL_PARAMETER` (pour adresser des *paramètres globaux*).
13.11.12.8 Voir aussi
Aucun.
13.11.13 ApplicationParameterManager::setParameterValue()
La méthode setParameterValue() permet d'écrire la valeur principale d'un
paramètre non-utilisateur, ou la valeur personnalisée d'un paramètre
utilisateur.
13.11.13.1 Description
voir static setParameterValue ( mixed $application, string $parameterName, string $value )
Si le paramètre est un paramètre utilisateur ('user' => 'Y') alors c'est la
valeur personnalisée qui est écrite
(setUserParameterValue), sinon c'est la valeur
principale qui est écrite
(setCommonParameterValue).
13.11.13.1.1 Avertissements
Aucun.
13.11.13.2 Liste des paramètres
- (string|int|Application)
application - Le nom, l'identifiant ou l'objet
Applicationde l'application dont on souhaite écrire la valeur d'un de ses paramètres. - (string)
parameterName - Le nom du paramètre dont on souhaite écrire la valeur.
- (string)
value - La valeur à inscrire comme valeur pour ce paramètre.
13.11.13.3 Valeur de retour
La méthode ne retourne rien.
13.11.13.4 Erreurs / Exceptions
Aucune.
13.11.13.5 Historique
Aucun.
13.11.13.6 Exemples
/* Écrit dans la valeur personnalisée car CORE_LANG est déclaré avec 'user' => 'Y' */ ApplicationParameterManager::setParameterValue('CORE', 'CORE_LANG', 'en_US'); /* Écrit dans la valeur principale car CORE_CLIENT est déclaré avec 'user' => 'N' */ ApplicationParameterManager::setParameterValue('CORE', 'CORE_CLIENT', 'ACME Corp.');
13.11.13.7 Notes
- L'argument
applicationpeut aussi être la constanteApplicationParameterManager::CURRENT_APPLICATION(pour l'application courante) ouApplicationParameterManager::GLOBAL_PARAMETERpour adresser des paramètres globaux.
13.11.13.8 Voir aussi
Aucun.
13.11.14 ApplicationParameterManager::setUserParameterDefaultValue()
La méthode setUserParameterDefaultValue() permet d'écrire la valeur principale
d'un paramètre utilisateur d'une application.
13.11.14.1 Description
void static setUserParameterDefaultValue ( mixed $application, string $parameterName, string $value )
13.11.14.1.1 Avertissements
Aucun.
13.11.14.2 Liste des paramètres
- (string|int|Application)
application - Le nom, l'identifiant ou l'objet
Applicationde l'application dont on souhaite écrire la valeur principale d'un de ses paramètres. - (string)
parameterName - Le nom du paramètre dont on souhaite écrire la valeur principale.
- (string)
value - La valeur à inscrire comme valeur principale pour ce paramètre.
13.11.14.3 Valeur de retour
La méthode ne retourne rien.
13.11.14.4 Erreurs / Exceptions
Si le paramètre n'existe pas ou est incorrect, alors une exception
(\Dcp\ApplicationParameterManager\Exception) est levée.
13.11.14.5 Historique
Aucun.
13.11.14.6 Exemples
/* * Change la langue par défaut à 'en_US' pour tous les utilisateurs qui * n'ont pas de valeur personnalisée. */ ApplicationParameterManager::setUserParameterDefaultValue('CORE', 'CORE_LANG', 'en_US');
13.11.14.7 Notes
L'argument
applicationpeut aussi être la constanteApplicationParameterManager::CURRENT_APPLICATION(pour l'application courante) ouApplicationParameterManager::GLOBAL_PARAMETERpour adresser des paramètres globaux.Cette méthode est équivalente à un appel à la méthode
setCommonParameterValue().
13.11.14.8 Voir aussi
Aucun.
13.11.15 ApplicationParameterManager::setUserParameterValue()
La méthode setUserParameterValue() permet d'écrire la valeur personnalisée
d'un paramètre utilisateur d'une application.
13.11.15.1 Description
void static setUserParameterValue ( mixed $application, string $parameterName, string $value, int $userid = null bool $check = true )
13.11.15.1.1 Avertissements
Aucun.
13.11.15.2 Liste des paramètres
- (string|int|Application)
application - Le nom, l'identifiant ou l'objet
Applicationde l'application dont on souhaite écrire la valeur personnalisée d'un de ses paramètres. - (string)
parameterName - Le nom du paramètre dont on souhaite écrire la valeur personnalisée.
- (string)
value - La valeur à inscrire comme valeur personnalisée pour ce paramètre.
- (int)
userId - L'identifiant de l'utilisateur pour lequel on souhaite écrire la valeur
personnalisée du paramètre. Si l'identifiant n'est pas spécifié (ou si
nullest spécifié), alors c'est l'identifiant de l'utilisateur actuellement connecté qui est utilisé. - (bool)
check - Permet de vérifier (
true) ou non (false) si le paramètre spécifié est bien un paramètre utilisateur.
13.11.15.3 Valeur de retour
La méthode ne retourne rien.
13.11.15.4 Erreurs / Exceptions
Si le paramètre n'existe pas, est incorrect, ou si le paramètre n'est pas un
paramètre utilisateur et que check est à true, alors une exception
(\Dcp\ApplicationParameterManager\Exception) est levée.
13.11.15.5 Historique
Aucun.
13.11.15.6 Exemples
/* Changer la langue par défaut de l'utilisateur courant epar 'en_US' */ ApplicationParameterManager::setUserParameterValue('CORE', 'CORE_LANG', 'en_US');
13.11.15.7 Notes
- L'argument
applicationpeut aussi être la constanteApplicationParameterManager::CURRENT_APPLICATION(pour l'application courante) ouApplicationParameterManager::GLOBAL_PARAMETERpour adresser des paramètres globaux.
13.11.15.8 Voir aussi
Aucun.
13.12 Classe SearchAccount
La classe SearchAccount permet de réaliser facilement la recherche de
comptes.
Le résultat de cette recherche peut retourner des utilisateurs, des groupes ou des rôles.
13.12.1 Constructeur
new SearchAccount( )
13.12.1.1 Liste des paramètres
Aucuns
13.12.1.2 Propriétés de la classe
Aucunes
13.12.1.3 Exemple
$searchAccount = new SearchAccount(); $searchAccount->addRoleFilter('writter'); $searchAccount->setObjectReturn($searchAccount::returnAccount); /** * @var \AccountList $accountList */ $accountList = $searchAccount->search(); /** * @var \Account $account */ foreach ($accountList as $account) { $login = $account->login; print "$login\n"; }
13.12.2 Voir aussi
13.12.3 SearchAccount::addFilter()
Cette méthode permet d'ajouter des filtres sur les caractéristiques des comptes.
13.12.3.1 Description
void addFilter( string $filter, [string|int|double $args…])
La recherche effectuée avec la classe SearchAccount porte sur la
table users. Les filtres ajoutés doivent donc porter sur une
ou plusieurs des colonnes de cette table, soit :
- login,
- firstname,
- lastname,
- mail,
- accounttype,
- status.
13.12.3.1.1 Avertissements
Aucun
13.12.3.2 Liste des paramètres
- (string)
filter -
Partie filtre de la recherche, cette partie doit être soit une chaîne de caractères contenant du SQL, soit une chaîne formatée celle-ci est alors complétée avec les valeurs passées dans les arguments suivants. Attention : Le point suivant est à prendre en compte :
- injections SQL : le premier argument de la méthode addFilter est ajouté tel quel dans la requête SQL, il est donc possible qu'il puisse déclencher une injection SQL. Les données doivent être échappées (par exemple à l'aide de pg_escape_string),
- (string|int|double)
value - Valeurs qui sont insérées à la partie
filterà l'aide de la fonctionsprintf.
Note : Cet argument doit être répété autant de fois que nécessaire en fonction du format du filtre.
Attention : Les valeurs des paramètres sont échappés à l'aide de la fonction pg_escape_string.
Attention : Dans le cas de l'utilisation d'un opérateur à base d'expression régulière, il faut utiliser la fonction preg_quote sans quoi les valeurs peuvent rendre l'expression régulière invalide.
13.12.3.3 Valeur de retour
void
13.12.3.4 Erreurs / Exceptions
Aucune
13.12.3.5 Historique
Aucun
13.12.3.6 Exemple
Recherche sur les mails contenant george :
$mailExpr='george'; $searchAccount = new SearchAccount(); $searchAccount->addFilter("mail ~ '%s'", preg_quote($mailExpr)); // filtre les mail qui contiennent george $accountList = $searchAccount->search(); foreach ($accountList as $account) { printf("\t %s => %s\n", $account->login, $account->mail); }
Résultat :
george.abitbol => george.abitbol@classe-americaine.com georges.de.hanovre => georges.V.de.hanovre@hanovre.com georgette.agutte => georgette.agutte@paris.com
13.12.3.7 Notes
Aucunes
13.12.3.8 Voir aussi
13.12.4 SearchAccount::addGroupFilter()
Cette méthode permet de rechercher les comptes qui appartiennent à un groupe.
13.12.4.1 Description
void addGroupFilter( string $groupName )
La méthode permet d'ajouter un filtre à la recherche, le groupName est basé sur le login du groupe.
Note : Il est possible de rechercher sur plusieurs groupes en utilisant plusieurs fois la méthode.
Note : La recherche par groupe prend aussi en compte les sous-groupes du groupe recherché.
Note : Si cette méthode est combinée à la méthode
SearchAccount::addRoleFilter cela filtre tous les comptes
qui appartiennent à un des groupes cités ou à un des rôles cités.
13.12.4.1.1 Avertissements
La recherche est basée sur l'objet account et pas sur l'objet documentaire associé au compte.
Par défaut, la recherche retourne des groupes et des utilisateurs, il est possible
de filtrer le type d'élément recherché à l'aide de
SearchAccount::setTypeFilter.
13.12.4.2 Liste des paramètres
- (string)
groupName - Nom de l'identifiant (colonne
login) du groupe de référence.
13.12.4.3 Valeur de retour
void
13.12.4.4 Erreurs / Exceptions
Si jamais le login de groupe demandé n'existe pas alors une exception de type
Dcp\Sacc\Exception est levée.
13.12.4.5 Historique
Aucun
13.12.4.6 Exemple
Avoir la liste des utilisateurs et des groupes contenus dans le groupe all:
$searchAccount = new SearchAccount(); $searchAccount->addGroupFilter("all"); $accountList = $searchAccount->search(); foreach ($accountList as $account) { printf("%s (type : %s)\n", $account->login, $account->accounttype); }
Résultat :
admin (type : U) care (type : G) gadmin (type : G) george.abitbol (type : U) georges.de.hanovre (type : U) georgette.agutte (type : U) security (type : G) zoo.cashone (type : U) zoo.cashtwo (type : U) zoo.garde (type : U) zoo.veto (type : U)
13.12.4.7 Notes
Un rôle ne peut pas être contenu dans un groupe d'utilisateur.
13.12.4.8 Voir aussi
13.12.5 SearchAccount::addRoleFilter()
Cette méthode permet de rechercher les comptes qui possède un rôle.
13.12.5.1 Description
void addRoleFilter( string $roleName )
La méthode permet d'ajouter un filtre à la recherche, l'argument roleName est
basé sur l'identifiant (colonne login) du rôle.
Note : Il est possible de rechercher sur plusieurs rôles en utilisant plusieurs fois la méthode.
Note : Le rôle étant propagé par les groupes, les membres des groupes ayant le rôle sont aussi retournés.
Note : Si cette méthode est combinée à la méthode
SearchAccount::addGroupFilter cela
indique tous les comptes qui appartiennent à un des groupes cités ou à un des
rôles cités.
13.12.5.1.1 Avertissements
Aucun
13.12.5.2 Liste des paramètres
- (string)
roleName - Nom de la référence (colonne
login) du rôle de référence.
13.12.5.3 Valeur de retour
void
13.12.5.4 Erreurs / Exceptions
Si jamais la référence du rôle demandé n'existe pas alors une exception de type
Dcp\Sacc\Exception est levée.
13.12.5.5 Historique
Aucun
13.12.5.6 Exemple
Avoir la liste des utilisateurs et des groupes ayant le rôle cash:
$searchAccount = new SearchAccount(); $searchAccount->addRoleFilter("cash"); $accountList = $searchAccount->search(); foreach ($accountList as $account) { printf("%s (type : %s)\n", $account->login, $account->accounttype); }
Résultat :
george.abitbol (type : U) zoo.cashone (type : U) zoo.cashtwo (type : U)
13.12.5.7 Notes
Seuls les comptes "user" et "groupe" peuvent être retournés avec ce filtre. Les rôles n'ont pas de rôles associé.
13.12.5.8 Voir aussi
13.12.6 SearchAccount::getLoginFromDocName()
Cette méthode permet de récupérer un identifiant de compte depuis un nom logique de document.
13.12.6.1 Description
string|null getLoginFromDocName( string $name )
L'identifiant retourné correspond à la colonne login de la table
users. La méthode est static, elle peut être utilisée sans
instancier d'objet SearchAccount.
13.12.6.1.1 Avertissements
Aucun
13.12.6.2 Liste des paramètres
- (string)
name - Nom logique du document contenant la référence vers le account.
13.12.6.3 Valeur de retour
string : identifiant du compte (colonne login).
13.12.6.4 Erreurs / Exceptions
S'il n'existe pas de compte associé au nom logique alors null est
renvoyé.
13.12.6.5 Historique
Aucun
13.12.6.6 Exemple
print "\nLe nom logique n'existe pas\n"; var_export(SearchAccount::getLoginFromDocName("toto")); print "\nLe nom logique existe mais le document associé n'est pas lié à un account\n";; var_export(SearchAccount::getLoginFromDocName("TEST")); print "\n"; print "Le nom logique existe et est associé à un document qui est associé à un account\n"; var_export(SearchAccount::getLoginFromDocName("ZOO_ROLE_VETO"));
Résultat :
Le nom logique n'existe pas false Le nom logique existe mais le document associé n'est pas lié à un account false Le nom logique existe et est associé à un document qui est associé à un account 'veto'
13.12.6.7 Notes
Aucunes
13.12.6.8 Voir aussi
13.12.7 SearchAccount::search()
La méthode permet d'exécuter la recherche paramétrée avec les autres méthodes de la classe pour obtenir une liste de account.
13.12.7.1 Description
DocumentList|AccountList search()
Cette méthode exécute la recherche auprès de la base de données et retourne soit :
- une
DocumentList: la documentList est un itérable sur les documents Dynacase associés aux comptes trouvés, - une
AccountList: l'accountList est un itérable sur les objets account.
Note : C'est la méthode SearchAccount::setReturnType qui
définit le type de retour.
13.12.7.1.1 Avertissements
Aucun
13.12.7.2 Liste des paramètres
Aucun
13.12.7.3 Valeur de retour
[DocumentList|AccountList]
La méthode SearchAccount::setReturnType définit le type de
retour. Par défaut, un objet de type AccountList est retourné.
13.12.7.4 Erreurs / Exceptions
Retourne une exception Dcp\Db\Exception en cas de filtre incorrect.
13.12.7.5 Historique
Aucun
13.12.7.6 Exemple
Avoir la liste des utilisateurs et des groupes ayant le rôle cash:
$searchAccount = new SearchAccount(); $searchAccount->addRoleFilter("cash"); $accountList = $searchAccount->search(); foreach ($accountList as $account) { printf("%s (type : %s)\n", $account->login, $account->accounttype); }
Ce qui donne :
george.abitbol (type : U) zoo.cashone (type : U) zoo.cashtwo (type : U)
13.12.7.7 Notes
Aucunes
13.12.7.8 Voir aussi
13.12.8 SearchAccount::setReturnType()
Permet de choisir le type de retour de l'objet searchAccount. Par défaut, le
retour est une AccountList.
13.12.8.1 Description
void setObjectReturn ( string $type )
Deux types de retour sont possibles soit :
- un objet
DocumentList: la documentList est un itérable sur les documents Dynacase associés aux comptes trouvés, - un objet
AccountList: l'accountList est un itérable sur les objets account.
13.12.8.1.1 Avertissements
Aucun
13.12.8.2 Liste des paramètres
- (string)
type -
Le type est une string qui est au choix entre deux constantes de classe, soit :
- SearchAccount::returnAccount : le retour est alors une accountList,
- SearchAccount::returnDocument : le retour est alors une documentList.
13.12.8.3 Valeur de retour
void
13.12.8.4 Erreurs / Exceptions
Si le type n'est pas une des deux constantes de classe alors une exception de
type Dcp\Sacc\Exception est levée.
13.12.8.5 Historique
Cette méthode remplace la méthode ::setObjectReturn().
13.12.8.6 Exemple
print "Return account \n"; $searchAccount = new SearchAccount(); $searchAccount->setReturnType(SearchAccount::returnAccount); $accountList = $searchAccount->search(); foreach ($accountList as $account) { printf("%s \n", get_class($account)); } print "\n"; print "Return document \n"; $searchAccount = new SearchAccount(); $searchAccount->setReturnType(SearchAccount::returnDocument); $documentList = $searchAccount->search(); foreach ($documentList as $currentDocument) { printf("%s \n", get_class($currentDocument)); }
Résultat :
Return account Account Account Account Account Account Account Account Account Account Account Account Account Account Account
Return document Dcp\Family\Igroup Dcp\Family\Role Dcp\Family\Iuser Dcp\Family\Zoo_gardien Dcp\Family\Role Dcp\Family\Iuser Dcp\Family\Iuser Dcp\Family\Iuser Dcp\Family\Role Dcp\Family\Igroup Dcp\Family\Zoo_veterinaire Dcp\Family\Igroup Dcp\Family\Igroup Dcp\Family\Role
13.12.8.7 Notes
Aucunes
13.12.8.8 Voir aussi
13.12.9 SearchAccount::setOrder()
Permet de définir l'ordre de tri des résultats.
13.12.9.1 Description
void setOrder ( string $order )
Cette méthode permet de définir l'ordre de tri des résultats de la recherche.
13.12.9.1.1 Avertissements
Aucun
13.12.9.2 Liste des paramètres
- (string)
order - L'order doit être une des propriété d'un objet account.
13.12.9.3 Valeur de retour
Aucune
13.12.9.4 Erreurs / Exceptions
Aucun
13.12.9.5 Historique
Aucun
13.12.9.6 Exemple
print "Default order \n"; $searchAccount = new SearchAccount(); $accountList = $searchAccount->search(); foreach ($accountList as $account) { printf("%s (type : %s)\n", $account->login, $account->accounttype); } print "Ordered by accounttype\n"; $searchAccount = new SearchAccount(); $searchAccount->setOrder("accounttype"); $accountList = $searchAccount->search(); foreach ($accountList as $account) { printf("%s (type : %s)\n", $account->login, $account->accounttype); }
Résultat :
Default order
admin (type : U) all (type : G) anonymous (type : U) care (type : G) cash (type : R) core_administrator (type : R) gadmin (type : G) security (type : G) surveillant (type : R) veto (type : R) zoo.cashone (type : U) zoo.cashtwo (type : U) zoo.garde (type : U) zoo.veto (type : U)
Ordered by accounttype
all (type : G) care (type : G) gadmin (type : G) security (type : G) cash (type : R) surveillant (type : R) veto (type : R) core_administrator (type : R) zoo.garde (type : U) zoo.cashone (type : U) zoo.cashtwo (type : U) admin (type : U) anonymous (type : U) zoo.veto (type : U)
13.12.9.7 Notes
Par défaut, les résultats sont triés par login.
13.12.9.8 Voir aussi
13.12.10 SearchAccount::setSlice()
Cette méthode permet de définir le nombre maximum d'éléments retournés par la recherche.
13.12.10.1 Description
void setSlice ( string|int $slice )
Cette fonction permet de définir la nombre maximum d'éléments retournés. Sa
valeur par défaut est all ce qui correspond à un retour de tous les éléments.
13.12.10.1.1 Avertissements
Aucun
13.12.10.2 Liste des paramètres
- (string|int)
slice - Le slice doit être une valeur numérique supérieure ou égale à 0
(si c'est un double, il est converti en entier) ou la chaîne de caractères
all.
13.12.10.3 Valeur de retour
void
13.12.10.4 Erreurs / Exceptions
Si le slice n'est pas valide alors une exception Dcp\Sacc\Exception est levée.
13.12.10.5 Historique
Aucun
13.12.10.6 Exemple
print "Without slice \n"; $searchAccount = new SearchAccount(); $accountList = $searchAccount->search(); printf("count : %d", count($accountList)); print "\n"; print "\n"; print "With a slice of 2 \n"; $searchAccount = new SearchAccount(); $searchAccount->setSlice(2); $accountList = $searchAccount->search(); printf("count : %d", count($accountList));
Résultat :
Without slice count : 14 With a slice of 2 count : 2
13.12.10.7 Notes
Aucune
13.12.10.8 Voir aussi
13.12.11 SearchAccount::setStart()
13.12.11.1 Description
void setStart ( int $start )
Les éléments retourné commence après avoir passé n résultats. Le n est défini par le paramètre de la fonction.
13.12.11.1.1 Avertissements
Aucun
13.12.11.2 Liste des paramètres
- (int)
start - Le start doit être une valeur numérique supérieure ou égale à 0 (si c'est un double, il est converti en entier).
13.12.11.3 Valeur de retour
void
13.12.11.4 Erreurs / Exceptions
Si le start n'est pas valide alors une exception Dcp\Sacc\Exception est levée.
13.12.11.5 Historique
Aucun
13.12.11.6 Exemple
print "Without slice \n"; $searchAccount = new SearchAccount(); $accountList = $searchAccount->search(); $i = 0; foreach ($accountList as $account) { printf("Login : %s \n", $account->login); $i++; if ($i == 3) { break; } } print "\n"; print "\n"; print "With a start of 2 (get the third element)\n"; $searchAccount = new SearchAccount(); $searchAccount->setStart(2); $accountList = $searchAccount->search(); foreach ($accountList as $account) { printf("Login : %s", $account->login); break; }
Résultat :
Without slice Login : admin Login : all Login : anonymous With a start of 2 (get the third element) Login : anonymous
13.12.11.7 Notes
Cette fonction peut-être utilisée avec SearchAccount::setSlice()
pour faire un tourne page.
13.12.11.8 Voir aussi
13.12.12 SearchAccount::setTypeFilter()
13.12.12.1 Description
void setTypeFilter ( int $type )
Le type utilise la notion de masque binaire. On peut donc rechercher à la fois :
- les utilisateurs,
- les groupes,
- les rôles.
Pour composer une recherche sur plusieurs types, on utilise l'opérateur PHP
binaire |.
13.12.12.1.1 Avertissements
Par défaut, tous les types de comptes sont retournés.
13.12.12.2 Liste des paramètres
- (int)
type -
Le type est un ou une composition des constantes de classes :
- userType : les comptes de type utilisateur,
- groupType : les comptes de type groupe;
- roleType : les comptes de type rôle.
13.12.12.3 Valeur de retour
void
13.12.12.4 Erreurs / Exceptions
Aucune
13.12.12.5 Historique
Aucun
13.12.12.6 Exemple
print "Without any type filter \n-----------------------\n"; $searchAccount = new SearchAccount(); $accountList = $searchAccount->search(); foreach ($accountList as $account) { printf("%s (type : %s)\n", $account->login, $account->accounttype); } print "\nOnly user \n-----------------------\n"; $searchAccount = new SearchAccount(); $searchAccount->setTypeFilter(SearchAccount::userType); $accountList = $searchAccount->search(); foreach ($accountList as $account) { printf("%s (type : %s)\n", $account->login, $account->accounttype); } print "\nGroup and role \n-----------------------\n"; $searchAccount = new SearchAccount(); $searchAccount->setTypeFilter(SearchAccount::groupType | SearchAccount::roleType); $accountList = $searchAccount->search(); foreach ($accountList as $account) { printf("%s (type : %s)\n", $account->login, $account->accounttype); }
Résultat :
Without any type filter ----------------------- admin (type : U) all (type : G) anonymous (type : U) care (type : G) cash (type : R) core_administrator (type : R) gadmin (type : G) security (type : G) surveillant (type : R) veto (type : R) zoo.cashone (type : U) zoo.cashtwo (type : U) zoo.garde (type : U) zoo.veto (type : U)
Only user ----------------------- admin (type : U) anonymous (type : U) zoo.cashone (type : U) zoo.cashtwo (type : U) zoo.garde (type : U) zoo.veto (type : U)
Group and role ----------------------- all (type : G) care (type : G) cash (type : R) core_administrator (type : R) gadmin (type : G) security (type : G) surveillant (type : R) veto (type : R)
13.12.12.7 Notes
Aucune.
13.12.12.8 Voir aussi
13.12.13 SearchAccount::overrideViewControl()
13.12.13.1 Description
void overrideViewControl ( bool $override )
Cette méthode permet d'indiquer s'il faut ajouter ou non une condition qui
filtre les comptes que l'utilisateur courant n'a pas le droit de voir. Un compte
non visible est un compte dont le document associé n'a pas le droit
view.
13.12.13.1.1 Avertissements
Par défaut, tous les comptes sont retournés quelque soit le profil du document associés.
13.12.13.2 Liste des paramètres
- (bool)
override(défaut : true) - Si override est à
truealors le droitviewdu document associé au compte n'est pas pris en compte et l'ensemble des comptes est retourné.
13.12.13.3 Valeur de retour
void
13.12.13.4 Erreurs / Exceptions
Aucune
13.12.13.5 Historique
Cette méthode remplace la méthode useViewControl.
Attention : la méthode useViewControl fonctionnait à l'opposé de la méthode
overrideViewControl, c'est à dire que le booléen positif indiquait que le
droit voir est pris en compte, alors que actuellement il indique qu'il n'est
pas pris en compte.
13.12.13.6 Exemple
print "Without override \n-----------------------\n"; $searchAccount = new SearchAccount(); $accountList = $searchAccount->search(); foreach ($accountList as $account) { printf("%s (type : %s)\n", $account->login, $account->accounttype); } print "\nWith override \n-----------------------\n"; $searchAccount = new SearchAccount(); $searchAccount->overrideViewControl(); $accountList = $searchAccount->search(); foreach ($accountList as $account) { printf("%s (type : %s)\n", $account->login, $account->accounttype); }
Résultat :
Without override ----------------------- care (type : G) cash (type : R) core_administrator (type : R) gadmin (type : G) security (type : G) surveillant (type : R) veto (type : R) zoo.cashone (type : U) zoo.cashtwo (type : U) zoo.garde (type : U) zoo.veto (type : U) With override ----------------------- admin (type : U) all (type : G) anonymous (type : U) care (type : G) cash (type : R) core_administrator (type : R) gadmin (type : G) security (type : G) surveillant (type : R) veto (type : R) zoo.cashone (type : U) zoo.cashtwo (type : U) zoo.garde (type : U) zoo.veto (type : U)
13.12.13.7 Notes
Aucunes
13.12.13.8 Voir aussi
13.13 Classe SearchDoc
La classe SearchDoc permet de chercher des documents sans faire directement du SQL et connaître la structure de la base de données. Cette recherche est basée sur la notion de famille et les structures associées (attributs et héritage).
Attention : La classe SearchDoc possède deux modes de fonctionnement :
13.13.1 Constructeur
new SearchDoc ( '', "FAM_LOGICAL_NAME" )
13.13.1.1 Liste des paramètres
- (string)
dbaccess -
Déprécié. Utilisé pour indiquer les coordonnées de la base, la récupération
des coordonnées est maintenant automatique, il faut passer une chaîne vide
"". - (string|int)
famname -
Identifiant interne ou nom logique de la famille sur laquelle s'effectue la recherche.
Il peut prendre quelques valeurs particulières qui ne sont pas des identifiants de famille :
-
0: (valeur par défaut) : La recherche est alors effectuée sur l'ensemble des documents quelque soit leur famille, -
-1: la recherche est alors effectuée sur les documents familles.
-
13.13.1.2 Propriétés de la classe
- (string|int) fromid
- Identifiant interne ou nom logique de la famille sur laquelle s'effectue la recherche.
- (string|int) dirid
- Identifiant interne ou nom logique d'une collection dans laquelle s'effectue la recherche.
- (bool) recursiveSearch (valeur par défaut
false) - Uniquement applicable dans le cas d'une recherche avec dirid, si il est passé
à
trueet que la collection de base contient d'autres collection alors la recherche est aussi effectuée dans les autres collections. - (int) folderRecursiveLevel
- Uniquement applicable dans le cas d'une recherche avec dirid et recursiveSearch
à
true. Indique le niveau de récursivité qui va être appliqué. Attention : La recherche récursive ne protège pas contre les boucles si le dossier A contient le dossier B et que le dossier B contient le dossier A alors A et B sont ouvert à tour de rôle. - (int) slice
- Indique le nombre maximum de documents retournés par la recherche.
- (int) start
- Indique à partir de combien de documents trouvés commence le retour des documents.
- (bool) only (valeur par défaut
false) - Indique si la recherche est faite dans les familles et les sous-familles.
Sitruela recherche n'est pas faite dans les sous familles. - (bool) distinct (valeur par défaut
false) - Indique si les résultats retournés comprennent toutes les révisions trouvées
ou pas (
falseindique que tous les résultats sont renvoyés). Cette propriété n'a de sens que silatestest àfalse. - (string) trash (valeur par défaut
no) -
Indique si la recherche doit chercher aussi dans les documents supprimés.
La propriétédoctypeest àZsi le document est supprimé.
Valeurs possibles :-
no: Les documents supprimés sont exclus, -
also: Les documents supprimés sont inclus, -
only: Les documents non supprimés sont exclus, seuls les supprimés sont inclus.
-
- (bool) latest (valeur par défaut
true) - Indique si la recherche ne doit retourner que la dernière révision des documents.
- (int) userid
- Indique l'identifiant système de l'utilisateur avec lequel se fait la recherche.
13.13.1.3 Avertissement
Les objets de la classe SearchDoc fonctionne en deux phases :
- Préparation de la requête : lors de cette phase on initialise la requête et on fixe les différents éléments la constituants (filtre, jointure, etc.)
- Exécution de la recherche : lors de cette phase la recherche est exécutée et on exploite les résultats.
Le passage de la phase de préparation à la phase d'exécution se fait via la
méthode SearchDoc::search.
13.13.1.4 Exemples
Recherche sur tous les documents :
$searchDoc = new SearchDoc(); $documents = $searchDoc->search();
Recherche sur toutes les familles :
$searchDoc = new SearchDoc("", -1); $documents = $searchDoc->search();
Recherche sur les documents de la famille IUSER :
$searchDoc = new SearchDoc("", "IUSER"); $documents = $searchDoc->search();
13.13.1.5 Voir aussi
13.13.2 SearchDoc::setObjectReturn()
13.13.2.1 Description
void setObjectReturn ( bool $returnobject = true )
Cette méthode permet de choisir le type de retour que va effectuer la méthode
SearchDoc::search ou SearchDoc::getDocumentList.
Les deux types de retour possibles sont :
13.13.2.1.1 Avertissements
Aucun.
13.13.2.2 Liste des paramètres
- (bool)
returnObject(valeur par défaut :true) - Si le paramètre est à
truealors le retour est un objet documentaire, sinon c'est un résultat brut.
Note : Par défaut un searchDoc retourne des résultats brut.
13.13.2.3 Valeur de retour
void
13.13.2.4 Erreurs / Exceptions
Aucune.
13.13.2.5 Historique
Aucun.
13.13.2.6 Exemples
13.13.2.6.1 Retour de document brut
$s=new SearchDoc("","DIR"); $s->setObjectReturn(false); $rawDocuments=$s->search(); foreach ($rawDocuments as $docid=>$rawDoc) { printf("%d) %s (%s)", $docid, $rawDoc["title"], $rawDoc["ba_desc"]); }
13.13.2.6.2 Retour de document objet
Dans ce cas, les hooks Doc::preAffect() et
Doc::postAffect() sont appelés dans la boucle pour chacun des
documents.
$s=new SearchDoc("","DIR"); $s->setObjectReturn(true); $documentList=$s->search()->getDocumentList(); foreach ($documentList as $docid=>$doc) { printf("%d) %s (%s)", $docid, $doc->getTitle(), $doc->getRawValue(\Dcp\AttributeIdentifiers\Dir::ba_title)); }
13.13.2.7 Notes
Lorsque le retour est de type objet documentaire, les documents fournis par l'itération sont des références internes et cette référence est réutilisée par l'itérateur si le document est de la même famille qu'un document précédent dans l'itération.
S'il est nécessaire de mémoriser un certain document durant l'itération, il est nécessaire de cloner l'objet sinon la variable sera modifiée lors des itérations suivantes.
$s=new SearchDoc("","DIR"); $s->setObjectReturn(true); $documentList=$s->search()->getDocumentList(); $memoFolder=null; foreach ($documentList as $docid=>$doc) { if ($doc->name == "MYFOLDER") { $memoFolder=$doc; // INCORRECT } } if (memoFolder) { // memoFolder n'est pas forcément celui avec le nom "MYFOLDER" printf("%d) %s (%s)", $memoFolder->id, $memoFolder->getTitle(), $memoFolder->getRawValue(\Dcp\AttributeIdentifiers\Dir::ba_title)); }
13.13.2.8 Voir aussi
13.13.3 SearchDoc::setOrder()
13.13.3.1 Description
void setOrder ( string $order, string $orderbyLabel = '' )
13.13.3.1.1 Avertissements
Cette fonction ne produit pas de message d'erreurs si les attributs passés ne sont pas valides.
13.13.3.2 Liste des paramètres
- (string)
order - une chaîne de caractères contenant la liste des colonnes (séparées par une virgule) en fonction desquelles le résultat est ordonné. Le nom des colonnes peut être suffixé par un espace et le mot-clef 'asc' ou 'desc' afin de spécifier l'ordre du tri : ASCendant ou DESCendant (par défaut, la colonne est triée dans l'ordre ASCendant).
- (string)
orderbyLabel - une chaîne de caractères contenant le nom d'une des colonnes spécifiées dans
l'argument #1 (sans le suffixe de tri 'asc' ou 'desc') et pour laquelle le
tri doit être fait non pas sur la valeur de l'attribut, mais sur le label
ou le titre. Les attributs actuellement supportés pour l'ordonnancement par
le label ou le titre sont : Les attributs de type
enum.
Les attributs de type 'docid("X")' déclarés avec une option 'doctitle=auto' ou 'doctitle=xxx'.
Pour les énumérés, les libellés peuvent être différents suivant la locale. L'ordre est alors différent suivant la langue choisie lors de la connexion de l'utilisateur.
13.13.3.3 Valeur de retour
Aucune.
13.13.3.4 Erreurs / Exceptions
Aucune.
13.13.3.5 Historique
Aucun.
13.13.3.6 Exemples
13.13.3.6.1 Exemple de tri en fonction d'un attribut entier :
$searchDoc=new searchDoc($dbaccess, $famId); $searchDoc->setOrder("a_integer desc"); $searchDoc->search();
13.13.3.6.2 Exemple de tri en fonction de deux attributs :
$searchDoc=new searchDoc($dbaccess, $famId); $searchDoc->setOrder("a_integer desc, b_date asc"); $searchDoc->search();
13.13.3.6.3 Exemple de tri en fonction de la valeur d'un énuméré :
$searchDoc=new searchDoc($dbaccess, $famId); $searchDoc->setOrder("a_enum asc"); $searchDoc->search();
13.13.3.6.4 Exemple de tri en fonction du label d'un énuméré :
$searchDoc=new searchDoc($dbaccess, $famId); $searchDoc->setOrder("a_enum asc", "a_enum"); $searchDoc->search();
Dans les exemples ci-dessus, si l'énuméré 'a_enum' est définit avec
1|Accepté,2|Traité,3|Rejeté,4|Clos, alors les documents sont retournés dans
l'ordre ci-dessous :
| setOrder("a_enum") | setOrder("a_enum", "a_enum") |
|---|---|
| 1-Accepté | 1-Accepté |
| 2-Traité | 4-Clos |
| 3-Rejeté | 3-Rejeté |
| 4-Clos | 2-Traité |
13.13.3.6.5 Exemple de tri avec ou sans la fonction de orderBy :
L'énuméré an_sexe a comme définition : M|Masculin,F|Zéminin,H|Hermaphorodite.
function testOfOrderBy(Action & $action) { header('Content-Type: text/plain'); $searchDoc = new searchDoc("", "ZOO_ANIMAL"); $searchDoc->setObjectReturn(); print "Without orderby\n"; foreach ($searchDoc->getDocumentList() as $document) { printf("Title : %s \n\t sexe : %s \n", $document->getTitle(), $document->getTextualAttrValue("an_sexe")); } var_export($searchDoc->getSearchInfo()); print "\n***************\nOrder by without orderbyLabel\n"; $searchDoc->setOrder("an_sexe"); $searchDoc->reset(); foreach ($searchDoc->getDocumentList() as $document) { printf("Title : %s \n\t sexe : %s \n", $document->getTitle(), $document->getTextualAttrValue("an_sexe")); } var_export($searchDoc->getSearchInfo()); print "\n***************\nOrder by with orderbyLabel\n"; $searchDoc->setOrder("an_sexe", "an_sexe"); $searchDoc->reset(); foreach ($searchDoc->getDocumentList() as $document) { printf("Title : %s \n\t sexe : %s \n", $document->getTitle(), $document->getTextualAttrValue("an_sexe")); } var_export($searchDoc->getSearchInfo()); }
Résultat :
Without orderby
Title : Rotor
sexe : Masculin
Title : Séléonore
sexe : Zéminin
Title : Théodor
sexe : Masculin
array (
'count' => 3,
'query' => 'select doc1058.id, owner, title, revision, version, initid, fromid, doctype, locked, allocated, archiveid, icon, lmodify, profid, usefor, cdate, adate, revdate, comment, classname, state, wid, postitid, domainid, lockdomainid, cvid, name, dprofid, views, atags, prelid, confidential, ldapdn, an_nom, an_tatouage, an_espece, an_espece_title, an_ordre, an_classe, an_sexe, an_photo, an_gardien, an_naissance, an_entree, an_enfant, an_pere, an_mere, an_classe_title, an_pere_title, an_mere_title, values, attrids from doc1058 where (doc1058.archiveid is null) and (doc1058.doctype != \'T\') and (doc1058.locked != -1) ORDER BY title LIMIT ALL OFFSET 0;',
'error' => '',
'delay' => '0.005s',
)
***************
Order by without orderbyLabel
Title : Séléonore
sexe : Zéminin
Title : Rotor
sexe : Masculin
Title : Théodor
sexe : Masculin
array (
'count' => 3,
'query' => 'select doc1058.id, owner, title, revision, version, initid, fromid, doctype, locked, allocated, archiveid, icon, lmodify, profid, usefor, cdate, adate, revdate, comment, classname, state, wid, postitid, domainid, lockdomainid, cvid, name, dprofid, views, atags, prelid, confidential, ldapdn, an_nom, an_tatouage, an_espece, an_espece_title, an_ordre, an_classe, an_sexe, an_photo, an_gardien, an_naissance, an_entree, an_enfant, an_pere, an_mere, an_classe_title, an_pere_title, an_mere_title, values, attrids from doc1058 where (doc1058.archiveid is null) and (doc1058.doctype != \'T\') and (doc1058.locked != -1) ORDER BY an_sexe LIMIT ALL OFFSET 0;',
'error' => '',
'delay' => '0.003s',
)
***************
Order by with orderbyLabel
Title : Rotor
sexe : Masculin
Title : Théodor
sexe : Masculin
Title : Séléonore
sexe : Zéminin
array (
'count' => 3,
'query' => 'select doc1058.id, owner, title, revision, version, initid, fromid, doctype, locked, allocated, archiveid, icon, lmodify, profid, usefor, cdate, adate, revdate, comment, classname, state, wid, postitid, domainid, lockdomainid, cvid, name, dprofid, views, atags, prelid, confidential, ldapdn, an_nom, an_tatouage, an_espece, an_espece_title, an_ordre, an_classe, an_sexe, an_photo, an_gardien, an_naissance, an_entree, an_enfant, an_pere, an_mere, an_classe_title, an_pere_title, an_mere_title, values, attrids from doc1058 , (VALUES (\'M\', \'Masculin\'), (\'F\', \'Zéminin\'), (\'H\', \'Hermaphrodite\')) AS map_an_sexe(key, label) where (map_an_sexe.key = doc1058.an_sexe) and (doc1058.archiveid is null) and (doc1058.doctype != \'T\') and (doc1058.locked != -1) ORDER BY map_an_sexe.label LIMIT ALL OFFSET 0;',
'error' => '',
'delay' => '0.002s',
)
13.13.3.7 Notes
Les colonnes de tri sont des noms d'attributs ou de propriétés de documents.
13.13.3.8 Voir aussi
13.13.4 SearchDoc::setPertinenceOrder()
13.13.4.1 Description
void setPertinenceOrder()
Le détail du calcul de l'ordre de pertinence est dans le chapitre de recherche avancé.
Cette pertinence est évaluée sur l'ensemble des valeurs d'attributs et non sur un attribut en particulier.
13.13.4.1.1 Avertissements
Attention si vous utilisez des conditions parenthésées, celles-ci doivent être correctement balancée (toute parenthèse ouvrante doit avoir un parenthèse fermante et vice-versa).
Cette recherche ne fonctionne que pour les textes en langue française.
13.13.4.2 Liste des paramètres
- (string)
keyword(valeur par défaut"") - Si un
SearchDoc::addGeneralFilterest utilisé, vous pouvez juste appeler la fonction sans paramètre alors le choix de la pertinence est celui du filtre. Vous pouvez sinon ajouter une chaîne de caractères pour préciser la recherche la syntaxe est celle de postgreSQL.
13.13.4.3 Valeur de retour
Void.
13.13.4.4 Erreurs / Exceptions
Aucune.
13.13.4.5 Historique
Aucun.
13.13.4.6 Exemples
13.13.4.6.1 Mot simple
$searchDoc=new SearchDoc('',"ANIMAL"); $searchDoc->addGeneralFilter('cheval'); $searchDoc->setPertinenceOrder(); // la pertinence est sur le mot cheval $searchDoc->search();
Dans ce cas, la pertinence est calculé sur les occurences du mot cheval.
13.13.4.6.2 Plusieurs mots
$searchDoc=new SearchDoc('',"ANIMAL"); $searchDoc->addGeneralFilter('cheval OR poulain OR jument'); $searchDoc->setPertinenceOrder('cheval noir'); // la pertinence est sur le mot cheval et noir $searchDoc->search();
Dans ce cas, la pertinence est d'autant plus élevé qu'il y les mots "cheval et noir" qui sont proches.
13.13.4.6.3 Exemple de résultat
Soit le document suivant :
Identification
Nom (TITRE) : Antilope
Classe (RESUMÉ) : Mammalia
Ordre (RESUMÉ) : Artiodactyles
Caractéristique
Continents : Afrique
Poids : 25
Répartition : Inde au sud de l'Himalaya.
Alimentation : Herbivore.
Reproduction : Non saisonnière. La femelle donne naissance à 1 petit.
La gestation est de 6 mois.
Habitat : Des semi-déserts aux bois clairs
Comportement : Harems composés d'1 mâle adulte et de plusieurs femelles:
10 à 20. avec leur jeune. Des groupes de jeunes mâles
vivent à la périphérie des harems.
| Pertinence | Rank | Explication |
|---|---|---|
| antilope artiodactyle | 0.86484 | Poids conjugués du titre et du résumé et proximité |
| antilope | 0.63832 | Le titre est de poids A |
| antilope OR harem | 0.39515 | = (antilope + harem) / 2 |
| antilope OR himalaya | 0.37995 | |
| antilope OR inde | 0.37995 | |
| antilope OR harem OR inde | 0.30396 | |
| antilope harem inde | 0.30320 | |
| antilope inde | 0.30307 | |
| artiodactyle | 0.27357 | Le résumé est de poids B |
| bois clair | 0.19821 | Proximité des 2 mots |
| 10 20 | 0.19700 | |
| harem | 0.15198 | Le mot est présent 2 fois |
| himalaya OR harem | 0.13678 | |
| himalaya | 0.12158 | Texte présent une fois |
| inde | 0.12158 | Texte présent une fois |
| sud | 0.12158 | Texte présent une fois |
| 5 | 0.12158 | Nombre présent une fois |
| antilope himalaya | 0.07838 | |
| bois jeune | 0.01060 | Mots plus éloignés |
| himalaya harem | 0.00082 | |
| antilope clair | 0.00004 | |
| antilope harem | 0.00003 | Mots éloignés (antilope au début et harem à la fin) |
13.13.4.7 Notes
Aucune.
13.13.4.8 Voir aussi
Voir chapitre Recherche avancée.
13.13.5 SearchDoc::setSlice()
13.13.5.1 Description
bool setSlice( int|string $slice )
13.13.5.1.1 Avertissements
La méthode ::count() retourne le nombre de résultats et ne peut
pas excéder la valeur du paramètre $slice.
Il faut toujours définir un ordre à la recherche afin de garantir une fenêtre de résultat non ambiguë.
13.13.5.2 Liste des paramètres
- (int|string)
setSlice - Nombre maximum de résultats retournés. Ce nombre peut-être soit un entier
positif, soit
ALL.ALLindique que tous les résultats sont retournés.
13.13.5.3 Valeur de retour
(bool) : true si le paramètre est appliqué, false sinon.
Note : Le paramètre n'est pas appliqué si il n'est pas un entier ou s'il
n'est pas ALL.
13.13.5.4 Erreurs / Exceptions
Aucun.
13.13.5.5 Historique
Aucun.
13.13.5.6 Exemples
Retourner les 10 premiers résultats.
$searchDoc = new SearchDoc("", "IUSER"); $searchDoc->setOrder('title, initid'); $searchDoc->setSlice(10); $documents = $searchDoc->search();
13.13.5.7 Notes
Aucune.
13.13.5.8 Voir aussi
13.13.6 SearchDoc::setStart()
13.13.6.1 Description
bool setStart ( int $start )
Cette méthode permet de définir que les documents avant le $start sont
ignorés du résultat de la recherche.
Par exemple en admettant que l'on ait 11 documents et que l'on recherche tous
les documents en mettant le $start à 10 alors on trouve 1 document.
13.13.6.1.1 Avertissements
Aucun.
13.13.6.2 Liste des paramètres
- (int)
start - Définit le nième document après lequel la recherche commence.
13.13.6.3 Valeur de retour
bool : true si le paramètre a été appliqué, false sinon.
13.13.6.4 Erreurs / Exceptions
Si jamais $start n'est pas de type int alors le paramètre n'est pas appliqué
et la méthode retourne false.
13.13.6.5 Historique
Aucun.
13.13.6.6 Exemples
Rechercher des utilisateurs et retourner les résultats du 10ième au 35ième.
$searchDoc = new SearchDoc("", "IUSER"); $searchDoc->setOrder('initid'); $searchDoc->setSlice(26); $searchDoc->setStart(9); $documents = $searchDoc->search();
Dans cet exemple les 9 premiers utilisateurs ne font pas partie du résultat.
13.13.6.7 Notes
Aucun.
13.13.6.8 Voir aussi
Voir SearchDoc::setSlice().
13.13.7 SearchDoc::setRecursiveSearch()
13.13.7.1 Description
void setRecursiveSearch( int $recursiveMode = true int $level = 2 )
Lorsque la collection est un dossier, il est possible de faire des recherches
récursives à l'aide de la méthode DocSearch::setRecursiveSearch(). Le niveau
de profondeur de la recherche est défini au moyen de l'argument $level.
13.13.7.1.1 Avertissements
Ceci ne fonctionne que si la recherche est faite dans une collection spécifique
SearchDoc::useCollection() et que cette collection est de
type dossier.
Les recherches contenues dans les sous-dossiers ne sont pas inspectées.
13.13.7.2 Liste des paramètres
- (bool)
recursiveMode(valeur par défaut :true) - Si le paramètre recursiveMode est passé à
truealors la recherche est faite de manière récursive. Un searchDoc est paramétré pour effectuer une recherche non-récursive par défaut. - (int)
level(valeur par défaut :2)3.2.12 - Niveau de profondeur maximum d'inspection des sous-dossier. S'il est égal à zéro, aucun sous-dossier n'est inspecté.
13.13.7.3 Valeur de retour
Void.
13.13.7.4 Erreurs / Exceptions
Exception \Dcp\SearchDoc\Exception si le $level, n'est pas en entier positif
ou égal à zéro.
13.13.7.5 Historique
13.13.7.5.1 Release 3.2.12
Ajout du paramètre $level pour indiquer le niveau de profondeur. Auparavant,
il fallait mettre à jour la propriété folderRecursiveLevel pour indiquer le
niveau.
13.13.7.6 Exemples
Recherche de tous les documents contenus dans le dossier MY_FOLDER jusqu'à
trois niveaux de profondeur.
$search = new \SearchDoc(self::$dbaccess); $search->setObjectReturn(); $search->useCollection("MY_FOLDER"); $search->setRecursiveSearch(true, 3); $search->search();
Recherche de tous les sous-dossiers du dossier MY_FOLDER jusqu'à
trois niveaux de profondeur dont la description contient "important".
$search = new \SearchDoc(self::$dbaccess, "DIR"); $search->setObjectReturn(); $search->useCollection("MY_FOLDER"); $search->setRecursiveSearch(true, 3); $search->addFilter("%s ~ 'important", \Dcp\AttributeIdentifiers\Dir::ba_desc); $search->search();
13.13.7.7 Notes
Aucune.
13.13.7.8 Voir aussi
Voir le chapitre avancé sur la recherche dans les collections.
13.13.8 SearchDoc::useCollection()
13.13.8.1 Description
bool useCollection( int $dirid )
La collection indiquée en entrée dans la fonction peut être soit un dossier, une recherche ou encore un rapport.
13.13.8.1.1 Avertissements
Lorsque la collection indiquée en entrée est une recherche spécialisée,
il est impossible d'utiliser la méthode SearchDoc::addFilter().
13.13.8.2 Liste des paramètres
- (string|int)
dirid - La fonction prend en entrée la référence vers une collection que ça soit par son nom logique ou par son identifiant.
13.13.8.3 Valeur de retour
(bool) true si le paramètre a pu être appliqué false sinon.
13.13.8.4 Erreurs / Exceptions
Si jamais la référence passée en entrée n'est pas valide la fonction retourne
false et enregistre un message d'erreur sur l'objet
(voir SearchDoc::getError)
13.13.8.5 Historique
Aucun.
13.13.8.6 Exemples
Récupérer le contenu d'un dossier
$folderName="MY_FAVORITE_FOLDER"; // identifiant d'un document recherche ou dossier $searchDoc = new SearchDoc(); $searchDoc->setObjectReturn(false); $searchDoc->useCollection($folderName); $rawResults= $searchDoc->search(); if ($searchDoc->searchError()) { $action->exitError(sprintf("search error : %s",$searchDoc->getError())); }
Ceci est équivalent au code suivant :
$folder=new_doc('', "MY_FAVORITE_FOLDER"); $rawResults=$folder->getContent();
Récupérer les sous-dossiers d'un dossier
$folderName="MY_FAVORITE_FOLDER"; // identifiant d'un dossier $searchDoc = new SearchDoc('', 'DIR'); $searchDoc->setObjectReturn(); $searchDoc->useCollection($folderName); $dl=$searchDoc->search()->getDocumentList(); foreach ($dl as $doc) { printf("%d) %s\n", $doc->id, $doc->getTitle()); }
13.13.8.7 Notes
Aucune.
13.13.8.8 Voir aussi
SearchDoc::setRecursiveSearch()- Le chapitre avancé sur la recherche dans les collections.
13.13.9 SearchDoc::addFilter()
13.13.9.1 Description
void addFilter( string $filter, string|int|double $…)
Cette méthode permet de configurer la requête SQL qui va être générée. Elle prend en argument un fragment de SQL et les associe pour créer la requête.
$searchDoc = new SearchDoc("", "IUSER"); $searchDoc->addFilter("title = '%s'", "my user"); $searchDoc->addFilter("id = %d", 12);
Les conditions SQL sont concaténés avec l'opérateur AND, par exemple la
requête ci-dessus cherche les documents de type IUSER dont la propriété
title est strictement égale à my user et la propriété id est égale à
12.
13.13.9.1.1 Avertissements
Les variables sont encodées avec la fonction pg_espace_string afin
de construire correctement les filtres et afin d'éviter l'injection SQL.
Si les variables contiennent du texte, celui-ci doit être encodé en UTF-8.
Cette méthode n'est pas utilisable conjointement avec une recherche spécialisée en tant que collection de base.
13.13.9.2 Liste des paramètres
- (string)
filter -
Partie filtre de la recherche, cette partie doit être soit une chaîne de caractères contenant du SQL, soit une chaîne formatée celle-ci est alors complétée avec les valeurs passées dans les arguments suivants. Attention : Les points suivants sont à prendre en compte :
- injections SQL : le premier argument de la méthode addFilter est ajouté tel quel dans la requête SQL, il est donc possible qu'il puisse déclencher une injection SQL. Les données doivent être échappées (par exemple à l'aide de pg_escape_string),
-
gestion de la multiplicité : les valeurs des attributs multiples (premier et second niveau de multiplicité) sont stockées avec des caractères d'échappement. La création d'une requête les prenant en compte nécessite l'utilisation d'opérateurs propre à postgreSql, il existe plusieurs manières d'aborder le problème :
- recherche à base d'expressions régulières :
"ATTRNAME ~ E'\\\\y%s\\\\y'": il faut remplacer ATTRNAME par le nom de l'attribut.
Limitation : l'opérateur utilisé est une expression régulière avec le séparateur de mot\ycela peut engendrer des faux positifs si jamais la valeur contient elle-même des séparateurs de mot.
Ce type de recherche permet de faire les filtres les plus simples (un parmi, etc.) avec le risque d'avoir des faux positifs. -
recherche à base de conversion en array postgres, deux cas sont à prendre en compte :
- l'attribut a 1 niveau de multiplicité :
(regexp_split_to_array(ATTRNAME, E\'\\n\' )) - l'attribut a 2 niveaux de multiplicité :
(regexp_split_to_array(replace(ATTRNAME, \'<BR>\', E\'\\n\'), E\'\\n\' ))
Dans les deux cas, il faut remplacer
ATTRNAMEpar le nom de l'attribut. Le comparaison se fait ensuite à l'aide des opérateurs propres aux tableaux.Ce type de recherche est plus coûteux en ressource que le premier type mais permet de faire des recherches plus complexes (a des éléments en commun, est contenu par, etc.) et limite le risque de faux positif.
- l'attribut a 1 niveau de multiplicité :
- recherche à base d'expressions régulières :
- (string|int|double)
value - Valeurs qui sont concaténées à la partie
filterà l'aide la fonctionsprintf.
Note : Cet argument peut-être répété autant de fois que souhaité.
Attention : Les paramètres passés parvaluesont échappés à l'aide de la fonction pg_escape_string.
Attention : Dans le cas de l'utilisation d'un opérateur à base d'expression régulière, il faut utiliser la fonction preg_quote sans quoi les valeurs peuvent rendre l'expression régulière invalide.
13.13.9.3 Valeur de retour
void
13.13.9.4 Erreurs / Exceptions
Aucune.
13.13.9.5 Historique
Aucun.
13.13.9.6 Exemples
Recherche de documents dont l'attribut firstname est égal à "George" et
l'attribut lastname à "Abitbol" :
$searchDoc = new SearchDoc("", "IUSER"); $searchDoc->addFilter("firstname = '%s' AND lastname = '%s'", "George", "Abitbol");
Recherche de documents dont l'attribut firstname est égal à "Arthur" et le
lastname à "O'Connor" :
$searchDoc = new SearchDoc("", "IUSER"); $searchDoc->addFilter("firstname = '%s'", "Arthur"); $searchDoc->addFilter("lastname = '%s'", "O'Connor");
Recherche de documents dont la propriété titre commence par "La classe"
$searchDoc = new SearchDoc("", "FILM"); $searchDoc->addFilter("title ~* '^%s'", preg_quote("La classe"));
Note : On utilise ici l'opérateur ~* de postgresql.
Recherche de documents dont une des valeurs de l'attribut multivalué actors
contient "John Wayne" :
$searchDoc = new SearchDoc("", "FILM"); $searchDoc->addFilter("actors ~* E'\\\\y%s\\\\y'", preg_quote("John Wayne"));
Attention : L'expression ci-dessus peut engendrer des faux positifs, par
exemple, si acteur contient John Wayne Junior il est aussi trouvé car \y
désigne un séparateur de mot et espace est un séparateur de mot.
Recherche de documents dont l'attribut multivalué actors contient John Wayne
et Paul Newnam :
$searchDoc = new SearchDoc("", "FILM"); $searchDoc->addFilter("actors ~* E'\\\\y%s\\\\y'", preg_quote("John Wayne")); $searchDoc->addFilter("actors ~* E'\\\\y%s\\\\y'", preg_quote("Paul Newnam"));
Attention : L'expression ci-dessus peut engendrer des faux positifs.
Recherche de documents dont l'attribut multivalué actors contient John Wayne
et Paul Newnam :
$searchDoc = new SearchDoc("", "FILM"); $searchDoc->addFilter("ARRAY[$s] && (regexp_split_to_array(replace(actors, \'<BR>\', E\'\\n\'), E\'\\n\' ))", "'Paul Newnam', 'John Wayne'");
13.13.9.7 Notes
Aucunes.
13.13.9.8 Voir aussi
13.13.10 SearchDoc::addGeneralFilter()
13.13.10.1 Description
void addGeneralFilter ( string $filter, bool $useSpell )
13.13.10.1.1 Avertissements
Cette recherche ne fonctionne que en langue française. Pour les autres langues notamment la langue anglaise, la recherche peut donner des résultats inappropriés. Ceci est du au fait que la lemmatisation, source de l'indexation, est réalisée pour le français .
13.13.10.2 Liste des paramètres
- (string)
filter - Cette chaîne de caractères contient le filtre dans le format de la recherche globale.
- (bool)
useSpell - Indique si une correction orthographique sur les mots de la langue française
doit être appliquée avant la recherche.
Dans ce cas, si le mot n'est pas trouvé alors le filtre retourne le mot et le mot le plus approchant trouvé.
13.13.10.3 Valeur de retour
void
13.13.10.4 Erreurs / Exceptions
3.2.12
Si le filtre indiqué est invalide une exception Dcp\SearchDoc\Exception est
envoyée.
13.13.10.5 Historique
13.13.10.5.1 Release 3.2.12
Si le filtre indiqué est invalide une exception est retournée que soit l'erreur. Auparavant, une exception était retournée que lorsque la vérification de premier niveau détectait l'erreur.
Le type de l'exception est passé de \Dcp\Exception\ à
Dcp\SearchDoc\Exception.
13.13.10.6 Exemples
Recherche de tous les documents contenant les trois mots "crêpes aux fromages". Dans ce cas précis le mot "aux" n'est pas pris en compté car il fait partie des mots non significatifs.
$s=new SearchDoc('',"COOKBOOK"); $s->addGeneralFilter('crêpes aux fromages'); $s->search();
Recherche de tous les documents contenant le mot "crêpe" et soit "champignon" ou soit "fromage".
$s=new SearchDoc('',"COOKBOOK"); $s->addGeneralFilter('crêpes (champignons OR fromage)'); $s->search();
13.13.10.7 Notes
Aucunes.
13.13.10.8 Voir aussi
Voir la recherche globale.
13.13.11 SearchDoc::onlyCount()
13.13.11.1 Description
int onlyCount ()
Cette méthode permet d'avoir uniquement le nombre de documents trouvés par la requête sans pour autant récupérer ces documents de la base de données.
13.13.11.1.1 Avertissements
Un nouvel appel à la base de données est effectué à chaque appel et écrase le
précédent résultat fait par search() ou le précédent onlyCount.
13.13.11.2 Liste des paramètres
Aucun.
13.13.11.3 Valeur de retour
int- Le nombre de documents trouvés par le searchDoc.
Retourne
-1en cas d'erreur.
13.13.11.4 Erreurs / Exceptions
Exception \Dcp\Db\Exception en cas d'erreur de requête sql.
13.13.11.5 Historique
13.13.11.5.1 Release 3.2.18
3.2.18
En cas d'erreur SQL de la requête, la méthode lève une exception de type
\Dcp\Db\Exception.
La valeur -1 est retournée pour toute autre erreur logique (e.g. la famille
sur laquelle porte la recherche n'existe pas).
13.13.11.5.2 Release 3.2.17
En cas d'erreur de requête, la méthode retourne maintenant -1 au lieu de 0.
13.13.11.5.3 Release 3.2.12
La méthode onlyCount() récupère toujours le résultat en envoyant une requête
en base de donnée. Auparavant, si la méthode search() ou onlyCount
étaient préalablement exécutée la méthode ne renvoyait pas de requête mais
récupéré le dernier compte effectué. Il fallait dans ce cas appeler la méthode
reset() pour forcer un recomptage.
13.13.11.6 Exemples
13.13.11.6.1 Exemple de compte :
function testOnlyCount(Action & $action) { header('Content-Type: text/plain'); $searchDoc = new searchDoc(); var_export($searchDoc->onlyCount()); print "\n"; var_export($searchDoc->getSearchInfo()); print "\n"; print "\n"; $searchDoc->addFilter("title = 'toto'"); var_export($searchDoc->onlyCount()); print "\n"; var_export($searchDoc->getSearchInfo()); print "\n"; print "\n"; $searchDoc = new searchDoc(); $searchDoc->search(); var_export($searchDoc->onlyCount()); print "\n"; var_export($searchDoc->getSearchInfo()); print "\n"; print "\n"; $searchDoc->addFilter("title = 'toto'"); var_export($searchDoc->onlyCount()); print "\n"; var_export($searchDoc->getSearchInfo()); print "\n"; print "\n"; }
1493 array ( 'query' => 'select count(docread.id) from docread where (docread.archiveid is null) and (docread.doctype != \'Z\') and (docread.doctype != \'T\') and (docread.locked != -1)', 'delay' => '0.003s', ) 0 array ( 'query' => 'select count(docread.id) from docread where (docread.archiveid is null) and (docread.doctype != \'Z\') and (docread.doctype != \'T\') and (docread.locked != -1) and (title = \'toto\')', 'delay' => '0.001s', ) 1493 array ( 'count' => 1493, 'query' => 'select docread.id, owner, title, revision, version, initid, fromid, doctype, locked, allocated, archiveid, icon, lmodify, profid, usefor, cdate, adate, revdate, comment, classname, state, wid, postitid, domainid, lockdomainid, cvid, name, dprofid, atags, prelid, confidential, ldapdn, values, svalues, attrids from docread where (docread.archiveid is null) and (docread.doctype != \'Z\') and (docread.doctype != \'T\') and (docread.locked != -1) ORDER BY title LIMIT ALL OFFSET 0;', 'error' => '', 'delay' => '0.073s', ) 1493 array ( 'count' => 1493, 'query' => 'select docread.id, owner, title, revision, version, initid, fromid, doctype, locked, allocated, archiveid, icon, lmodify, profid, usefor, cdate, adate, revdate, comment, classname, state, wid, postitid, domainid, lockdomainid, cvid, name, dprofid, atags, prelid, confidential, ldapdn, values, svalues, attrids from docread where (docread.archiveid is null) and (docread.doctype != \'Z\') and (docread.doctype != \'T\') and (docread.locked != -1) ORDER BY title LIMIT ALL OFFSET 0;', 'error' => '', 'delay' => '0.073s', )
13.13.11.6.2 Exemple traitement d'erreur
$s = new SearchDoc("", "IUSER"); $s->addFilter("myColumn = 3 "); // Ici la colonne n'existe pas dans la famille try { $c = $s->onlyCount(); } catch (\Dcp\Db\Exception $e) { print "SQL error:\n"; print "----------\n"; print_r($s->getSearchInfo()); return; } if ($c === -1) { print "Logical error:\n"; print "--------------\n"; print_r($s->getSearchInfo()); return; } printf("Count = %d\n", $c);
Retour :
SQL error:
----------
Array
(
[query] => select count(doc128.id) from doc128 where (doc128.archiveid is null) and (doc128.doctype != 'T')
and (doc128.locked != -1) and (myColumn = 3 )
[error] => ERROR: column "mycolumn" does not exist
LINE 1: ...28.doctype != 'T') and (doc128.locked != -1) and (myColumn =...
^
)
13.13.11.7 Notes
Aucune.
13.13.11.8 Voir aussi
13.13.12 SearchDoc::join()
Cette méthode permet de faire une [jointure][jointure].
13.13.12.1 Description
void join( string $join )
Cette méthode permet d'ajouter via le mécanisme de jointure des critères provenant d'une autre table de manière à établir des filtres complexes.
13.13.12.1.1 Avertissements
Les restrictions suivantes s'appliquent :
- une seule jointure est possible par SearchDoc,
- on ne peut utiliser la jointure que pour établir une recherche plus précise mais pas pour enrichir les résultats,
- on ne peut pas faire de jointure sur la table en cours.
13.13.12.2 Liste des paramètres
- (string)
join - La chaîne attendue doit être au format suivant :
Ce qui donne en BNF :
join ::= attributeName ( ('::'type)| ) (' ')+ operator (' ')+ familyName'('attributeName')'
operator ::= '<' | '>' | '=' | '<=' | '>='
type ::= 'type postgresql'
Note : La syntaxe de la chaîne attendue dans join n'est pas du SQL.
Note : Le type postgreSql de l'attribut doit être modifié pour
être compatible avec le type de l'attribut retourné par la jointure, la fonction
:: permet de modifier le type d'une valeur postgreSql.
13.13.12.3 Valeur de retour
void
13.13.12.4 Erreurs / Exceptions
3.2.12
Exception \Dcp\SearchDoc\Exception si la jointure est syntaxiquement
incorrecte.
13.13.12.5 Historique
13.13.12.5.1 Release 3.2.12
3.2.12
La méthode retourne une exception en cas d'erreur de syntaxe. Auparavant
l'erreur était remontée au niveau de la méthode SearchDoc::search().
13.13.12.6 Exemples
Recherche de tous les animaux dont le gardien a comme prénom "tom" :
function tomAnimals(Action & $action) { header('Content-Type: text/plain'); $searchDoc = new searchDoc("", "ZOO_ANIMAL"); $searchDoc->join("an_gardien::int = zoo_gardien(id)"); $searchDoc->addFilter("zoo_gardien.firstname = 'tom'"); $searchDoc->search(); $err = $searchDoc->getError(); if ($err !== "") { throw new Exception("Error Processing Search ".$err, 1); } var_export($searchDoc->getSearchInfo()); }
13.13.12.7 Notes
Aucune.
13.13.12.8 Voir aussi
Voir la documentation avancée.
13.13.13 SearchDoc::overrideViewControl()
13.13.13.1 Description
void overrideViewControl ( )
Par défaut, la méthode ::search() ajoute un filtre permettant de ne
retourner que les document que l'utilisateur courant peut voir.
Cette méthode permet de ne pas tenir compte du droit view, tous les
documents existants sont alors trouvés que l'utilisateur en cours
n'ait ou pas le droit de le voir.
13.13.13.1.1 Avertissements
Aucun.
13.13.13.2 Liste des paramètres
Aucun.
13.13.13.3 Valeur de retour
Aucune.
13.13.13.4 Erreurs / Exceptions
Aucune.
13.13.13.5 Historique
Anciennement ::noViewControl().
13.13.13.6 Exemples
Soit FILM, une famille décrivant les caractéristiques de films.
Compter le nombre total de film :
$searchDoc = new SearchDoc("", "FILM"); $searchDoc->overrideViewControl(); $numberOfUsers=$searchDoc->onlyCount();
Si la méthode ::overrideViewControl() n'était pas appelée, le compte retourné
serait le nombre de films que l'utilisateur a le droit de voir
13.13.13.7 Notes
Aucune.
13.13.13.8 Voir aussi
13.13.14 SearchDoc::excludeConfidential()
Cette méthode permet d'exclure les documents marqués comme confidentiel.
13.13.14.1 Description
bool excludeConfidential ( bool $exclude = true )
Il est possible de marquer des documents comme confidentiels ceux-ci sont alors
trouvés dans les recherches mais ne sont pas consultables si l'utilisateur n'en
a pas le droit. Cette méthode permet d'exclure ces documents si l'utilisateur
n'a pas le droit confidential sur les documents recherchés.
13.13.14.1.1 Avertissements
Si la recherche est faite avec l'utilisateur "admin" cette méthode est sans effet car "admin" a tous les droits.
Par défaut, la méthode ::search() retourne les documents
confidentiels, même ceux auxquels l'utilisateur n'a pas le droit confidential.
13.13.14.2 Liste des paramètres
- (bool)
exclude(valeur par défaut :true) - Si la valeur est à
truealors les documents confidentiels sont exclus, si la valeur est àfalseils sont inclus. Un objetsearchDocles inclus par défaut.
13.13.14.3 Valeur de retour
void
13.13.14.4 Erreurs / Exceptions
Aucun.
13.13.14.5 Historique
Aucun.
13.13.14.6 Exemples
13.13.14.6.1 Recherche de tous les documents accessibles
Cette exemple retourne les documents accessibles :
- les document non confidentiels
- les document confidentiels où l'utilisateur possède les privilèges suffisants.
$searchDoc = new SearchDoc('', ''); $searchDoc->setObjectReturn(); $searchDoc->excludeConfidential(true); $searchDoc->search(); $s=$searchDoc->getSearchInfo(); print_r($s);
Résultat :
Array
(
[count] => 1631
[query] => SELECT docread.id, owner, title, confidential, ... FROM docread WHERE (docread.archiveid IS NULL) AND (docread.doctype != 'Z') AND (docread.doctype != 'T') AND (docread.locked != -1) AND (confidential IS NULL OR hasaprivilege('{2,11}', profid,1024)) AND (views && '{2,0,11}') ORDER BY title LIMIT ALL OFFSET 0;
[error] =>
[error] =>
[delay] => 0.042s
)
13.13.14.6.2 Recherche de tous les documents visibles y compris les confidentiels
$searchDoc = new SearchDoc('', ''); $searchDoc->setObjectReturn(); $searchDoc->excludeConfidential(false); $searchDoc->search(); $searchInfo=$searchDoc->getSearchInfo(); print_r($searchInfo); $documentList=searchDoc->getDocumentList(); foreach ($documentList as $doc) { if ($doc->isConfidential()) { printf("Confidential : %d) %s\n", $doc->id, $doc->getTitle()); } }
Résultat :
Array
(
[count] => 1634
[query] => SELECT docread.id, owner, title, confidential, ... FROM docread WHERE (docread.archiveid IS NULL) AND (docread.doctype != 'Z') AND (docread.doctype != 'T') AND (docread.locked != -1) AND (views && '{2,0,11}') ORDER BY title LIMIT ALL OFFSET 0;
[error] =>
[delay] => 0.041s
)
Confidential : 1421) document confidentiel Confidential : 1419) document confidentiel Confidential : 1420) document confidentiel
13.13.14.6.3 Recherche de tous les documents confidentiels
$searchDoc = new SearchDoc('', ''); $searchDoc->setObjectReturn(); $searchDoc->addFilter("confidential > 0"); $searchDoc->search(); print_r($searchDoc->getSearchInfo());
Résultat :
Array
(
[count] => 3
[query] => SELECT docread.id, owner, title, confidential, ... FROM docread WHERE (docread.archiveid IS NULL) AND (docread.doctype != 'Z') AND (docread.doctype != 'T') AND (docread.locked != -1) AND (confidential > 0) AND (views && '{2,0,11}') ORDER BY title LIMIT ALL OFFSET 0;
[error] =>
[error] =>
[delay] => 0.006s
)
13.13.14.7 Notes
La méthode Doc::getTitle() retourne "Document confidentiel"
lorsque l'utilisateur courant n'a pas les privilèges suffisants pour accéder au
document.
13.13.14.8 Voir aussi
Le chapitre de sécurité avancé sur la recherche des confidentiels.
13.13.15 SearchDoc::search()
13.13.15.1 Description
array|null|SearchDoc search ( )
Cette méthode exécute la recherche. Elle construit la requête SQL nécessaire
en utilisant les paramètres de la famille recherchée et les conditions insérées
par les différentes méthodes.
13.13.15.1.1 Avertissements
Par défaut certains types de documents sont exclus des résultats de la
recherche. Ces exclusions sont modifiables par les méthodes
::excludeConfidential(),
::overrideViewControl() et les attributs
trash et distinct.
13.13.15.2 Liste des paramètres
Aucun.
13.13.15.3 Valeur de retour
La valeur du retour dépend du type de recherche :
- Résultats bruts : le retour est alors un tableau
array, si la préparation de la recherche à échoué alors le résultat est un tableau vide, - Résultats documents : le retour est alors l'objet
searchDoclui-même ounullsi la préparation de la recherche a échoué.
Note : Le changement du type de recherche se fait uniquement avant que la
recherche ne soit déclenchée avec la méthode
SearchDoc::setObjectReturn().
13.13.15.4 Erreurs / Exceptions
Si la préparation de la recherche a échoué alors si la recherche :
- retourne des résultats brut : le retour est un array vide,
- retourne des documents : le retour est
null.
Exceptions :
-
\Dcp\Db\Exceptionsi la requête n'a pas pu être exécutée. -
\Dcp\SearchDoc\Exception("SD0008")si la méthodeSearchDoc::addFilterest utilisée conjointement avec une recherche spécialisée en tant que [collection de base][core-ref:SearchDoc::useCollection].
13.13.15.5 Historique
Aucun.
13.13.15.6 Exemples
13.13.15.6.1 Recherche simple
Recherche de tous les dossiers que l'utilisateur courant peut voir.
$searchDoc=new SearchDoc("","DIR"); $searchDoc->setObjectReturn(true); $documentList=$searchDoc->search()->getDocumentList(); foreach ($documentList as $docid=>$doc) { printf("%d) %s (%s)", $docid, $doc->getTitle(), $doc->getRawValue(\Dcp\AttributeIdentifiers\Dir::ba_title)); }
13.13.15.6.2 Recherche avec capture d'erreurs
Reprise de l'exemple précédent en ajoutant les tests d'erreurs.
try { $searchDoc=new SearchDoc("","DIR"); $searchDoc->setObjectReturn(true); $searchDoc->search(); if ($err=$searchDoc->searchError()) { throw new \Dcp\SearchDoc\Exception($err); } $documentList=$searchDoc->getDocumentList(); foreach ($documentList as $docid=>$doc) { printf("%d) %s (%s)\n", $docid, $doc->getTitle(), $doc->getRawValue(\Dcp\AttributeIdentifiers\Dir::ba_title)); } } catch (\Dcp\Db\Exception $e) { printf("Database Error: [%s]\n", $e->getMessage()); } catch (\Dcp\SearchDoc\Exception $e) { printf("Search Error: [%s]\n", $e->getMessage()); }
13.13.15.7 Notes
Aucune.
13.13.15.8 Voir aussi
13.13.16 SearchDoc::reset()
13.13.16.1 Description
void reset( )
Cette méthode réinitialise les résultats de la recherche initialisés par la
méthode SearchDoc::search() et SearchDoc::onlyCount().
Elle permet d'ajouter un nouveau filtre afin de relancer une nouvelle itération.
13.13.16.1.1 Avertissements
L'utilisation de SearchDoc::reset durant une itération réinitialise le
pointeur et fait reprendre l'itération à 0.
13.13.16.2 Liste des paramètres
Aucun.
13.13.16.3 Valeur de retour
void
13.13.16.4 Erreurs / Exceptions
Aucune.
13.13.16.5 Historique
Aucun.
13.13.16.6 Exemples
$searchDoc = new searchDoc("", "ZOO_ANIMAL"); $searchDoc->setObjectReturn(); foreach ($searchDoc->getDocumentList() as $document) { printf("Title : %s \n\t date : %s \n", $document->getTitle(), $document->getTextualAttrValue(\Dcp\AttributeIdentifiers\Zoo_Animal::an_date)); } // on ajoute un filtre (date supérieure à l'année dernière) $searchDoc->addFilter("%s > '%s'", \Dcp\AttributeIdentifiers\Zoo_Animal::an_date, date('Y-m-d',strtotime("-1 year")); // on réinitialise pour forcer l'exécution de la recherche. $searchDoc->reset(); foreach ($searchDoc->getDocumentList() as $document) { printf("Title : %s \n\t date : %s \n", $document->getTitle(), $document->getTextualAttrValue(\Dcp\AttributeIdentifiers\Zoo_Animal::an_date)); }
13.13.16.7 Notes
La méthode searchDoc::rewind() réinitialise aussi le pointeur de l'itération
mais ne refait pas la requête.
13.13.16.8 Voir aussi
Aucun.
13.13.17 SearchDoc::count()
13.13.17.1 Description
int count ( )
13.13.17.1.1 Avertissements
La fonction SearchDoc::search doit être exécutée avant la méthode
::count() sinon le résultat retourné est -1. Si le but est simplement de
compter le nombre de résultats, il est préférable d'utiliser
onlyCount qui est optimisé pour faire uniquement le décompte et
ne nécessite pas de récupérer le résultat de la recherche.
Si des nouveaux critères sont ajoutés après l'exécution de la fonction
SearchDoc::search, il faut effectuer de nouveau la fonction
SearchDoc::search pour que la méthode ::count() prenne en compte
les nouveaux critères.
13.13.17.2 Liste des paramètres
Aucun.
13.13.17.3 Valeur de retour
Deux cas :
- soit un entier représentant le nombre de résultat,
- si la fonction
SearchDoc::searchn'a pas été exécutée-1.
13.13.17.4 Erreurs / Exceptions
Aucune.
13.13.17.5 Historique
13.13.17.5.1 Release 3.2.12
3.2.12
Si count() est appelé avant search(), le résultat est -1. Il était
auparavant égal à 0.
Le résultat du count() n'était pas réinitialisé en cas de recherches
successives si le type de retour était "objet documentaire".
Il fallait dans ce cas, appeler la méthode reset() avant l'appel à
search().
13.13.17.6 Exemples
Compte le nombre total de documents :
function countAllTheDoc(Action & $action) { header('Content-Type: text/plain'); $searchDoc = new SearchDoc(); $searchDoc->setObjectReturn(true); $document = $searchDoc->search(); var_export($searchDoc->count()); }
Note : Si le but est simplement de compter le nombre de
résultats, il est préférable d'utiliser onlyCount.
13.13.17.7 Notes
Aucune.
13.13.17.8 Voir aussi
13.13.18 SearchDoc::getDocumentList()
13.13.18.1 Description
DocumentList getDocumentList ( )
13.13.18.1.1 Avertissements
L'exécution de la méthode SearchDoc::search n'est pas nécessaire
avant l'utilisation de ::getDocumentList(). Si cette méthode est appelée avant
l'itération, elle ne sera pas exécutée lors de l'itération. Dans le cas
contraire, la méthode SearchDoc::search sera appelée dès le début de
l'itération.
13.13.18.2 Liste des paramètres
Aucun.
13.13.18.3 Valeur de retour
Un objet de type DocumentList.
13.13.18.4 Erreurs / Exceptions
Aucune.
13.13.18.5 Historique
Aucun.
13.13.18.6 Exemples
13.13.18.7 Retour d'objets documentaires
Récupère la liste des documents de la famille "dossiers" :
$s=new SearchDoc("","DIR"); $s->setObjectReturn(true); $s->search(); $documentList=$s->getDocumentList(); foreach ($documentList as $docid=>$doc) { printf("%d) %s (%s)\n", $docid, $doc->getTitle(), $doc->getRawValue(\Dcp\AttributeIdentifiers\Dir::ba_desc, "Pas de description")); }
Résultat :
3590) mimetypes (Pas de description) 1436) Porte-document (porte-documents de Default Master) 9) Racine (Pas de description)
13.13.18.8 Retour de valeurs brutes
Récupère la liste des données des "dossiers" :
$s=new SearchDoc("","DIR"); $s->setObjectReturn(false); $s->search(); $documentList=$s->getDocumentList(); foreach ($documentList as $docid=>$doc) { printf("%d) %s (%s)\n", $docid, $doc["title"], empty($doc[\Dcp\AttributeIdentifiers\Dir::ba_desc]) ?"Pas de description" :($doc[\Dcp\AttributeIdentifiers\Dir::ba_desc])); }
Résultat :
3590) mimetypes (Pas de description) 1436) Porte-document (porte-documents de Default Master) 9) Racine (Pas de description)
13.13.18.9 Notes
Aucun.
13.13.18.10 Voir aussi
13.13.19 SearchDoc::getError()
13.13.19.1 Description
string getError()
13.13.19.1.1 Avertissements
Aucun.
13.13.19.2 Liste des paramètres
Aucun.
13.13.19.3 Valeur de retour
String- Une chaîne de caractères apportant des informations sur l'erreur.
13.13.19.4 Erreurs / Exceptions
Aucun.
13.13.19.5 Historique
Aucun.
13.13.19.6 Exemples
Utilisation de la méthode getError pour renvoyer une exception si jamais la recherche a échoué :
$searchDoc = new SearchDoc("", "UNKOWN FAMILY"); $searchDoc->setObjectReturn(true); $searchDoc->search(); $err = $searchDoc->getError(); if ($err !== "") { throw new Exception("Error Processing Search ".$err, 1); }
Note : Dans l'exemple, si la famille UNKOWN FAMILY n'existe pas une
exception est déclenchée.
13.13.19.7 Notes
Aucune.
13.13.19.8 Voir aussi
13.13.20 SearchDoc::getIds()
13.13.20.1 Description
array getIds ()
13.13.20.1.1 Avertissements
Cette méthode ne peut être exécutée uniquement qu'après la méthode
SearchDoc::search.
13.13.20.2 Liste des paramètres
Aucun.
13.13.20.3 Valeur de retour
array- Un array contenant la liste des identifiants des documents trouvés.
Ce sont lesiddes documents et non lesinitidqui sont retournés.
13.13.20.4 Erreurs / Exceptions
Aucune.
13.13.20.5 Historique
Aucun.
13.13.20.6 Exemples
Recherche des identifiant ds 5 premiers dossiers créés.
$s=new SearchDoc("","DIR"); $s->setObjectReturn(true); $s->setSlice(5); $s->setOrder('initid'); $s->search(); $ids=$s->getIds(); print_r($s->getIds()); $documentList=$s->getDocumentList(); foreach ($documentList as $docid=>$doc) { printf("%d) %s\n", $docid, $doc->getTitle()); }
Résultat :
Array
(
[0] => 9
[1] => 1006
[2] => 1010
[3] => 1011
[4] => 1046
)
9) Racine
1006) Comptes
1010) Utilisateurs
1011) Administrateurs
1046) FLD_ZOO_CLASSE
13.13.20.7 Notes
Aucun.
13.13.20.8 Voir aussi
13.13.21 SearchDoc::returnsOnly()
Cette méthode permet d'indiquer quels sont les propriétés ou attributs que doit retourner la recherche.
13.13.21.1 Description
void returnsOnly (array $returns)
Cette méthode permet d'accélérer le traitement de la requête en indiquant un sous-ensemble d'attributs ou de propriétés. Ceci a deux avantages :
- Moins de données transférées entre la base de données et le serveur
- Moins de consommation mémoire
L'inconvénient est que les documents retournés ne sont pas complets. Ceci implique que ces documents ne peuvent faire l'objet de modification.
13.13.21.1.1 Avertissements
Si le mode est retour d'objet documentaire, les documents
retournés sont marqués "incomplet" (doctype='I'). Ils ne peuvent pas être
modifiés par la méthode Doc::store().
13.13.21.2 Liste des paramètres
- (array)
returns -
Indique une liste de propriétés ou d'attribut à récupérer.
Si
returnsest vide, les 4 propriétés élémentaires du document sont retournées :- id
- title
- fromid
- doctype
13.13.21.3 Valeur de retour
void
13.13.21.4 Erreurs / Exceptions
Aucune.
13.13.21.5 Historique
Aucun.
13.13.21.6 Exemples
13.13.21.6.1 Retour normal
$s=new SearchDoc("","ZOO_ANIMAL"); $s->setObjectReturn(true); $s->setOrder('initid'); $s->search(); printf("Requête : %s\n",print_r($s->getSearchInfo(), true)); print("Résultats :\n"); $documentList=$s->getDocumentList(); foreach ($documentList as $docid=>$doc) { printf("%d) %-10s : %s\n", $docid, $doc->getTitle(), $doc->getRawValue(\Dcp\AttributeIdentifiers\Zoo_Animal::an_espece)); }
La partie "select" contient toutes les propriétés et tous les attributs de la famille.
Résultat :
Requête : Array
(
[count] => 3
[query] => SELECT doc1053.id, owner, title, revision, version, initid, fromid, doctype, locked, allocated, archiveid, icon, lmodify, profid, usefor, cdate, adate, revdate, comment, classname, state, wid, postitid, domainid, lockdomainid, cvid, name, dprofid, views, atags, prelid, confidential, ldapdn, an_nom, an_tatouage, an_espece, an_espece_title, an_ordre, an_classe, an_sexe, an_photo, an_gardien, an_naissance, an_entree, an_enfant, an_pere, an_mere, an_classe_title, an_pere_title, an_mere_title, VALUES, attrids FROM doc1053 WHERE (doc1053.archiveid IS NULL) AND (doc1053.doctype != 'T') AND (doc1053.locked != -1) AND (views && '{2,0,11}') ORDER BY initid LIMIT ALL OFFSET 0;
[error] =>
[delay] => 0.017s
)
Résultats : 1419) Rotor : 1295 1420) Théodor : 1295 1421) Éléonore : 1295
13.13.21.7 Retour minimaliste
Dans cet exemple, seules les quatre propriétés nécessaires sont retournées.
$s=new SearchDoc("","ZOO_ANIMAL"); $s->setObjectReturn(true); $s->returnsOnly(array()); printf("Retour : %s\n",print_r($s->getReturnsFields(), true)); $s->setOrder('initid'); $s->search(); printf("Requête : %s\n",print_r($s->getSearchInfo(), true)); print("Résultats :\n"); $documentList=$s->getDocumentList(); foreach ($documentList as $docid=>$doc) { printf("%d) %-10s : %s\n", $docid, $doc->getTitle(), $doc->getRawValue(\Dcp\AttributeIdentifiers\Zoo_Animal::an_espece)); }
Résultat :
Retour : Array
(
[0] => id
[1] => title
[2] => fromid
[3] => doctype
)
Requête : Array
(
[count] => 3
[query] => SELECT doc1053.id, title, fromid, doctype FROM doc1053 WHERE (doc1053.archiveid IS NULL) AND (doc1053.doctype != 'T') AND (doc1053.locked != -1) AND (views && '{2,0,11}') ORDER BY initid LIMIT ALL OFFSET 0;
[error] =>
[delay] => 0.003s
)
Résultats : 1419) Rotor : 1420) Théodor : 1421) Éléonore :
Note : Puisque an_espece n'est pas demandé par returnsOnly, sa valeur
n'est pas disponible.
13.13.21.7.1 Retour spécifique
$s=new SearchDoc("","ZOO_ANIMAL"); $s->setObjectReturn(true); $s->returnsOnly(array( 'locked', \Dcp\AttributeIdentifiers\Zoo_Animal::an_classe, \Dcp\AttributeIdentifiers\Zoo_Animal::an_espece )); printf("Retour : %s\n",print_r($s->getReturnsFields(), true)); $s->setOrder('initid'); $s->search(); printf("Requête : %s\n",print_r($s->getSearchInfo(), true)); print("Résultats :\n"); $documentList=$s->getDocumentList(); foreach ($documentList as $docid=>$doc) { printf("%d) %-10s : [lock uid : %d] %d/%d\n", $docid, $doc->getTitle(), $doc->getProperty('locked'), $doc->getRawValue(\Dcp\AttributeIdentifiers\Zoo_Animal::an_classe), $doc->getRawValue(\Dcp\AttributeIdentifiers\Zoo_Animal::an_espece)); }
Résultat :
Retour : Array
(
[0] => id
[1] => title
[2] => fromid
[3] => doctype
[4] => locked
[5] => an_classe
[6] => an_espece
)
Requête : Array (
[query] => SELECT doc1053.id, title, fromid, doctype, locked, an_classe, an_espece FROM doc1053 WHERE (doc1053.archiveid IS NULL) AND (doc1053.doctype != 'T') AND (doc1053.locked != -1) AND (views && '{2,0,11}') ORDER BY initid LIMIT ALL OFFSET 0;
[error] =>
[delay] => 0.003s
)
Résultats : 1419) Rotor : [lock uid : 0] 1291/1295 1420) Théodor : [lock uid : 11] 1291/1295 1421) Éléonore : [lock uid : 0] 1291/1295
Dans ces exemples, le temps
13.13.21.8 Notes
Les quatre propriétés: suivantes sont toujours retournées :
idinitiddoctypefromid
Les champs (propriétés ou attributs) non conforme à la famille sont ignorés. Si la recherche ne porte pas sur une famille spécifique, seules les propriétés peuvent être indiquées dans le paramètre.
La gain de performance est d'autant plus grand que le nombre d'éléments est retourné est important.
Exemple : récupération de tous les documents sur une base de 55084 documents volumineux :
Avec un retour "normal" : > 6 min
Requête : Array
(
[count] => 55084
[query] => SELECT docread.id, owner, title, revision, version, initid, fromid, doctype, locked, allocated, archiveid, icon, lmodify, profid, usefor, cdate, adate, revdate, comment, classname, state, wid, postitid, domainid, lockdomainid, cvid, name, dprofid, atags, prelid, confidential, ldapdn, VALUES, svalues, attrids FROM docread WHERE (docread.archiveid IS NULL) AND (docread.doctype != 'Z') AND (docread.doctype != 'T') AND (docread.locked != -1) ORDER BY initid LIMIT ALL OFFSET 0;
[error] =>
[delay] => 367.984s
)
Avec un retour "minimaliste" : < 200ms
Requête : Array
(
[count] => 55084
[query] => SELECT docread.id, title, fromid, doctype FROM docread WHERE (docread.archiveid IS NULL) AND (docread.doctype != 'Z') AND (docread.doctype != 'T') AND (docread.locked != -1) ORDER BY initid LIMIT ALL OFFSET 0;
[error] =>
[delay] => 0.192s
)
13.13.21.9 Voir aussi
13.13.22 SearchDoc::getSearchInfo()
13.13.22.1 Description
array getSearchInfo()
13.13.22.1.1 Avertissements
Cette méthode est utilisable qu'après avoir exécutée la méthode
search().
13.13.22.2 Liste des paramètres
Aucun.
13.13.22.3 Valeur de retour
- array
-
Le array contient les clefs suivantes :
-
count: nombre de résultats de la requête, -
query: requêteSQLgénérée, -
error: message d'erreur si il y a eu une erreur lors de la préparation de la requête, -
delay: temps d'exécution de la requête.
-
Note : Si la méthode
search() n'a pas été exécutée alors une chaîne vide est retournée.
13.13.22.4 Erreurs / Exceptions
Aucune.
13.13.22.5 Historique
Aucun.
13.13.22.6 Exemples
Recherche des cinq premiers dossiers :
$s=new SearchDoc("","DIR"); $s->setObjectReturn(true); $s->setSlice(5); $s->setOrder('initid'); $s->search(); print_r($s->getSearchInfo());
Résultat :
Array
(
[count] => 5
[query] => SELECT doc2.id, owner, title, ..., ba_title, ba_desc, ... FROM doc2 WHERE (doc2.archiveid IS NULL) AND (doc2.doctype != 'T') AND (doc2.locked != -1) ORDER BY initid LIMIT 5 OFFSET 0;
[error] =>
[delay] => 0.340s
)
13.13.22.7 Notes
Aucune.
13.13.22.8 Voir aussi
13.13.23 SearchDoc::getNextDoc()
13.13.23.1 Description
Doc|array|null getNextDoc()
Cette méthode retourne le document suivant du resultat de la recherche.
13.13.23.1.1 Avertissements
Aucun.
13.13.23.2 Liste des paramètres
Aucun.
13.13.23.3 Valeur de retour
La valeur de retour peut être :
-
array: si le type de recherche n'est pas object, -
Doc: si le type de recherche est object, -
null: si tous les documents ont été parcourus.
13.13.23.4 Erreurs / Exceptions
Aucune.
13.13.23.5 Historique
Anciennement nommé SearchDoc::nextDoc().
13.13.23.6 Exemples
13.13.23.6.1 Itération sur les tous les documents :
$searchDoc = new searchDoc(); $searchDoc->setObjectReturn(true); $searchDoc->search(); $err = $searchDoc->getError(); if ($err !== "") { throw new Exception("Error Processing Search ".$err, 1); } while($document = $searchDoc->getNextDoc()) { print $document->getTitle()."\n"; } var_export($searchDoc->getSearchInfo());
Dans ce cas, les hooks Doc::preAffect() et
Doc::postAffect() sont appelés dans la boucle à chaque appel de
getNextDoc().
13.13.23.6.2 Récupération du premier dossier
Récupération du premier document "dossier" qui a été créé.
$searchDoc = new searchDoc('', "DIR"); $searchDoc->setSlice(1); $searchDoc->setOrder('initid'); $searchDoc->setObjectReturn(true); $searchDoc->search(); if (searchDoc->count() > 0) { $firstFolder=$searchDoc->getNextDoc(); }
13.13.23.7 Notes
La méthode SearchDoc::getDocumentList permets aussi
l'itération des résultats de la recherche.
La méthode SearchDoc::rewind() permet à la méthode SearchDoc::getNextDoc()
de revenir au premier document trouvé.
13.13.23.8 Voir aussi
13.14 Utilitaires de gestion de documents
Ce chapitre aborde quelques fonctions utilitaires pour créer et récupérer des documents.
13.14.1 Notes
Les fonctions de manipulation de documents ne font pas partie d'une classe mais
sont présentes dans le fichier PHP FDL/freedom_util.php qui doit donc être
inclut dans les scripts qui souhaitent les utiliser.
13.14.2 new_Doc
Cette fonction permet de récupérer un document stocké en base.
13.14.2.1 Description
\Dcp\Family\Document new_Doc ( string $dbaccess, int|string $id = "", bool $latest = false )
Cette fonction retourne un objet héritant de la classe \Dcp\Family\Document
en fonction de l'identifiant du document (paramètre $id).
Elle réalise les points suivants :
- récupération des données et des propriétés du documents,
- récupération de son profilage,
- instanciation d'un objet de la classe correspond à la famille du document.
13.14.2.1.1 Avertissements
Pour des raisons de compatibilité avec les versions précédentes de Dynacase, la
fonction new_Doc() retourne un objet de la classe \Dcp\Family\Document si
l'identifiant n'existe pas où n'est pas indiqué.
Cet objet n'est pas utilisable en tant que tel et doit être considéré comme un retour d'erreur.
Cette méthode utilise l'objet de partage de document. Si le document demandé est dans cet objet de partage, le document est récupéré de la zone de partage et non de la base de données.
13.14.2.2 Liste des paramètres
- (string)
dbaccess - Indique les coordonnées de la base de données. Ce paramètre est maintenant obsolète et peut être laissé vide.
- (int|string)
id - Identifiant du document que l'on souhaite récupérer. Cet identifiant est
soit la propriété
iddu document, soit la propriéténame(nom logique) du document. Si l'identifiant désigne un nom logique, la révision courante du document est retournée (l'optionlatestest ignorée). - (string)
latest(défaut :false) - Dans le cas d'un document révisé indique si l'on souhaite récupérer
la version courante (
true) ou la version référencée par le paramètreid.
13.14.2.3 Valeur de retour
Un document héritant de la classe \Dcp\Family\Document, la classe exacte du
document est fonction de la famille du document.
13.14.2.4 Erreurs / Exceptions
Si jamais, le fichier méthode PHP associé à la famille du document
n'existe pas alors null est retourné.
Lorsque il n'existe pas de document correspondant au paramètre $id ou lorsque
le paramètre $id n'est pas passé alors un objet de la classe
\Dcp\Family\Document est retourné. Cet objet doit être considéré comme un
retour d'erreur et n'est pas utilisable, pour détecter ce type de retour vous
pouvez utiliser les fonctions :
Doc::isAlive(): cette méthode vérifie que l'objet existe en base et n'a pas été supprimé,Doc::isAffected(): cette méthode vérifie que l'objet existe en base.
13.14.2.5 Historique
Aucun
13.14.2.6 Exemple
Le document de test de nom logique FF a deux révisions avec les identifiants
1455 et 1460. Il s'agit d'un document de la famille "Demande d'adoption".
Le document 1461 de la famille "Animal" a été supprimé.
require_once "FDL/freedom_util.php"; $docs = array(); $docs["FF"] = new_Doc("", "FF"); $docs[1455] = new_Doc("", 1455); $docs["1455_latest"] = new_Doc("", 1455, true); $docs[1461] = new_Doc("", 1461); $docs["idontexist"] = new_Doc("", "idontexist"); $docs["withoutArgument"] = new_Doc(); foreach ($docs as $key => $doc) { if ($doc->isAlive()) { printf("[%s]: Doc %s (%d : %s) is affected and alive\n", $key, $doc->getTitle(), $doc->getPropertyValue("id"), get_class($doc)); } elseif ($doc->isAffected()) { printf("[%s]: Doc %s (%d : %s) is only affected\n", $key, $doc->getTitle(), $doc->getPropertyValue("id"), get_class($doc)); } else { printf("[%s]: Doesn't exist (the document has the class %s)\n", $key, get_class($doc)); } }
Résultat :
[FF]: Doc ff (1460 : Dcp\Family\Zoo_demandeadoption) is affected and alive [1455]: Doc ff (1455 : Dcp\Family\Zoo_demandeadoption) is affected and alive [1455_latest]: Doc ff (1460 : Dcp\Family\Zoo_demandeadoption) is affected and alive [1461]: Doc supprimé (1461 : Dcp\Family\Zoo_animal) is only affected [idontexist]: Doesn't exist (the document has the class Dcp\Family\Document) [withoutArgument]: Doesn't exist (the document has the class Dcp\Family\Document)
13.14.2.7 Notes
Cette fonction ne doit pas être utilisée pour créer un nouveau document.
La création de document est réalisée par la fonction createDoc().
13.14.2.8 Voir aussi
13.14.3 createDoc
Cette fonction permet de créer un nouveau document.
13.14.3.1 Description
[bool|Doc] createDoc ( string $dbaccess, string $fromid, bool $control = true, bool $defaultvalues = true, bool $temporary = false )
Cette fonction permet de créer un nouveau document. Elle :
- contrôle que la famille de document demandée existe,
- contrôle que l'utilisateur courant a le droit de créer ce type de document (optionnel),
- initialise un objet de la classe correspondant à la famille demandée,
- le paramètre avec les valeurs par défaut (optionnel).
Le document retourné n'est pas inséré en base, c'est à la charge du développeur que de procéder, si besoin est, à cette insertion à l'aide de la méthode store.
13.14.3.1.1 Avertissements
Le document retourné n'est pas inséré en base.
Si le paramètre fromid ne correspond pas à un nom logique de famille un objet
de type \Dcp\Family\Document est retourné, cet objet n'est pas utilisable et
doit être considéré comme un retour d'erreur.
13.14.3.2 Liste des paramètres
- (string)
dbaccess - Coordonnées de la base de données. Cette élément peut-être trouvé grâce à la
fonction
getDbAccess(). - (string)
fromid - Nom logique de la famille du document à créer.
- (bool)
control(défaut : true) - Indique si la fonction doit vérifier si l'utilisateur courant à le droit de créer des documents de cette famille. Par défaut le droit est vérifié.
- (bool)
defaultvalues(défaut : true) - Indique si les valeurs par défaut doivent être initialisées dans le document retourné.
- (bool)
temporary(défaut : false) - Ce paramètre est obsolète et ne doit pas être utilisé. Pour créer un document temporaire, il faut utiliser la focntion createTmpDoc().
13.14.3.3 Valeur de retour
Un document de la classe correspondant à la famille demandée.
Le document retourné n'est pas inséré en base, c'est à la charge du développeur que de procéder, si besoin est, à cette insertion à l'aide de la méthode store.
13.14.3.4 Erreurs / Exceptions
Si le paramètre fromid ne correspond pas à un nom logique de famille un objet
de type \Dcp\Family\Document est retourné, cet objet n'est pas utilisable et
doit être considéré comme un retour d'erreur.
Si l'utilisateur n'a pas le droit de créer le document et que le contrôle est
effectué alors false est retourné.
13.14.3.5 Historique
Aucun
13.14.3.6 Exemple
require_once "FDL/freedom_util.php"; $animal = createDoc(getDbAccess(), "ZOO_ANIMAL"); var_export(get_class($animal)); print("\n"); printf("is alive ? %s", var_export($animal->isAlive(), true)."\n"); $animal->setValue("an_espece", "ZOO_ESP_ALLI"); $err = $animal->store(); if ($err) { print $err; } printf("is alive ? %s", var_export($animal->isAlive(), true)."\n");
Résultat :
'Dcp\\Family\\Zoo_animal' is alive ? false is alive ? true
13.14.3.7 Notes
Aucune
13.14.3.8 Voir aussi
13.14.4 createTmpDoc
Cette fonction permet de créer un nouveau document temporaire.
13.14.4.1 Description
[bool|Doc] createDoc ( string $dbaccess, string $fromid, bool $defaultvalues = true)
Cette fonction permet de créer un nouveau document temporaire. Les documents
temporaires stockés en base sont effacés par le script cleanContext .
13.14.4.1.1 Avertissements
Les documents temporaires n'ont pas de :
- cycle de vie,
- profil,
- contrôle de vue.
Le document retourné n'est pas inséré en base.
Si le paramètre fromid ne correspond pas à un nom logique de famille un objet
de type \Dcp\Family\Document est retourné, cet objet n'est pas utilisable et
doit être considéré comme un retour d'erreur.
13.14.4.2 Liste des paramètres
- (string)
dbaccess - Coordonnées de la base de données. Cet élément peut-être trouvé grâce à la
fonction
getDbAccess. - (string)
fromid - Nom logique de la famille du document à créer.
- (bool)
defaultvalues(défaut : true) - Indique si les valeurs par défaut doivent être initialisées dans le document retourné.
13.14.4.3 Valeur de retour
Un document de la classe correspondant à la famille demandée.
Le document retourné n'est pas inséré en base, c'est à la charge du développeur de procéder, si besoin, à cette insertion à l'aide de la méthode Doc::store().
13.14.4.4 Erreurs / Exceptions
Si le paramètre fromid ne correspond pas à un nom logique de famille un objet
de type \Dcp\Family\Document est retourné, cet objet n'est pas utilisable et
doit être considéré comme un retour d'erreur.
13.14.4.5 Historique
Aucun
13.14.4.6 Exemple
require_once "FDL/freedom_util.php"; $animal = createTmpDoc(getDbAccess(), "ZOO_ANIMAL"); var_export(get_class($animal)); print("\n"); printf("is alive ? %s", var_export($animal->isAlive(), true)."\n"); $animal->setValue("an_espece", "ZOO_ESP_ALLI"); $err = $animal->store(); if ($err) { print $err; } printf("is alive ? %s", var_export($animal->isAlive(), true)."\n");
Résultat :
'Dcp\\Family\\Zoo_animal' is alive ? false is alive ? true
13.14.4.7 Notes
Aucune
13.14.4.8 Voir aussi
Chapitre 14 Actions et zones de référence
Ce chapitre présente les actions et zones de références.
14.1 [ZONE FDL:HTMLHEAD]
14.1.1 Description
Cette zone est l'entête générique des pages générées par Dynacase. Elle contient :
- l'entête de la page : balise
html,headettitle, - insertion des assets : CSS, JS, CSS inline et JS inline,
- la favicon,
- une balise
bodyouvrante ayant la classecore.
14.1.2 Paramètres
- title : La valeur de ce paramètre devient le contenu de la balise
title
14.1.3 Limites
Après avoir utilisé cette zone, il faut penser à fermer les balises body et
html, soit manuellement, soit en utilisant la zone FDL:HTMLFOOT.
14.2 [ZONE FDL:HTMLFOOT]
14.2.1 Description
Cette zone contient la fin de page générique des pages générées par Dynacase. Elle contient :
- une balise
bodyet une balisehtmlfermantes.
14.2.2 Paramètres
Aucun paramètre.
14.2.3 Limites
N/A
14.3 [ZONE FDL:INPUTATTRIBUTE]
14.3.1 Description
Cette zone permet de composer un fragment HTML qui contient la vue en édition de la zone de saisie d'un type d'attribut.
14.3.2 Paramètres
- id
- L'id, au sens attribut
HTML, de l'input généré. Il doit être unique dans la page générée. Il est à noter que l'attributnamede l'input généré est au format_<id>. La valeur que génère le fragment HTML est stockée dans l'input ayant cetid. - type
- Le type d'attribut au sens attribut de document Dynacase qui est
généré. De plus, le type
doclinkpeut-être utilisé, celui-ci crée alors un attribut avec une aide à la saisie permettant de choisir un document. - label
- Le title au sens attribut
HTMLdu fragment généré. - esize
- Le size au sens attribut
HTMLde l'input du fragment généré. - value
- La valeur par défaut de l'attribut généré.
- phpfunc
- Identique à la caractéristique phpfunc.
- phpfile
- Identique à la caractéristique phpfile.
- eformat
- Identique à l'option eformat.
- options
- Les options d'affichage de l'attribut en cours. La liste des options est disponible dans le chapitre sur les attributs.
- jsevent
- Permet d'ajout un attribut au sens
HTMLau fragment généré. La chaîne est directement injectée tel quel dans l'input généré. Attention : Il faut faire un encodeURIComponent, ou assimilé, sur la chaîne. Par exemple, pour inséreronclick='alert("dynacase");', il faut écrireonclick%3D'alert(%22dynacase%22)%3B'. - famid
- Cette option n'est valide que si le type de l'attribut est
doclinket elle indique la famille de référence de l'aide à la saisie.
14.3.3 Limites
Dans le cadre de l'utilisation de cette zone en dehors d'une zone documentaire, il faut :
- ajouter les balises
[JS:REF]et[CSS:CUSTOMREF]pour pouvoir charger les assets nécessaires au fonctionnement du fragment HTML inséré. Il est à noter que la zone[ZONE FDL:HTMLHEAD]insère ces balises, - exécuter la fonction
editmode($action);dans le contrôleur associé à la vue, celle-ci charge les assets (JS et CSS nécessaires au fonctionnement du input).
14.3.4 Exemples
[ZONE FDL:INPUTATTRIBUTE?id=Dynacase&label=Dynacase&jsevent=onclick%3D'alert(%22Dynacase%22)')%3B&value=Dynacase]

Figure 86. Zone de type texte
[ZONE FDL:INPUTATTRIBUTE?id=Ddynacase&type=date]

Figure 87. Zone de type date
14.4 [ZONE FDL:VIEWFRAME]
14.4.1 Description
Cette zone permet de représenter uniquement une frame d'un document en consultation.
14.4.2 Paramètres
- id
- L'id du document source.
- frameid
- L'attrid de la frame que l'on souhaite présenter.
- abstract
-
YouN: Voir seulement les attributs résumés. - target
- Contenu de l'attribut target des liens générés.
- ulink
-
N: Si il est à N les liens ne sont pas rendus et ils sont remplacés par du texte sans hyperlien. - vid
- Si le document est associé à un contrôle de vue et que vid est une vue existante de ce contrôle, alors celle-ci est appliquée sur le document.
14.4.3 Limites
Dans le cadre de l'utilisation de cette zone en dehors d'une zone documentaire, il faut :
- inclure le fichier
JSgénéré par l'action?app=FDL&action=ALLVIEWJS, - inclure la référence
[CSS:CUSTOMREF]ou la zone[ZONE FDL:HTMLHEAD].
14.4.4 Exemples
Définition de la zone : [ZONE FDL:VIEWFRAME?id=1216&frameid=en_contenu]

Figure 88. Frame d'un document du zoo
Définition de la zone : [ZONE FDL:VIEWFRAME?id=1216&frameid=en_contenu&ulink=N]

Figure 89. Frame d'un document du zoo
14.5 [ZONE FDL:EDITFRAME]
14.5.1 Description
Cette zone permet de représenter uniquement une frame d'un document en édition.
14.5.2 Paramètres
- id
- L'id du document source. Facultatif si
classidest déjà fourni. - classid
- Nom logique de famille. Si
idest fourniclassidn'est pas utilisé. - frameid
- L' [attrid][property] de la frame que l'on souhaite présenter.
- vid
- Si le document est associé à un contrôle de vue et que vid est une vue existante de ce contrôle, alors celle-ci est appliquée sur le document.
14.5.3 Limites
Cette zone ne peut-être utilisée que dans le cadre d'une zone documentaire.
14.5.4 Exemple
Définition de la zone : [ZONE FDL:VIEWFRAME?id=1216&frameid=en_contenu]
Figure 90. Frame d'un document du zoo
14.6 [ZONE FDL:VIEWARRAY]
14.6.1 Description
Cette zone permet de représenter uniquement un array d'un document en consultation.
14.6.2 Paramètres
- id
- L'id du document source. Facultatif si
classidest déjà fourni. - classid
- Nom logique de famille. Si
idest fourniclassidn'est pas utilisé. - arrayid
- L' attrid de l'array que l'on souhaite présenter.
- vid
- Si le document est associé à un contrôle de vue et que vid est une vue existante de ce contrôle, alors celle-ci est appliquée sur le document.
- target
- Contenu de l'attribut target des liens générés.
- ulink
-
N: Si il est à N les liens ne sont pas rendus et ils sont remplacés par du texte sans hyperlien.
14.6.3 Limites
Dans le cadre de l'utilisation de cette zone en dehors d'une zone documentaire, il faut :
- inclure la référence
[CSS:CUSTOMREF]ou la zone[ZONE FDL:HTMLHEAD].
14.6.4 Exemples
Définition de la zone : [ZONE FDL:VIEWARRAY?id=1216&arrayid=en_t_animaux]

Figure 91. Array d'un document du zoo
14.7 [ZONE FDL:EDITARRAY]
14.7.1 Description
Cette zone permet de représenter uniquement un array d'un document en édition.
14.7.2 Paramètres
- id
- L'id du document source. Facultatif si
classidest déjà fourni. - classid
- Nom logique de famille. Si
idest fourniclassidn'est pas utilisé. - arrayid
- L' attrid de la frame que l'on souhaite présenter.
- vid
- Si le document est associé à un contrôle de vue et que vid est une vue existante de ce contrôle, alors celle-ci est appliquée sur le document.
- row
- Permet de n'afficher que la Nième ligne du tableau. La numérotation commence à 0. Si le numéro de ligne n'existe pas, alors un tableau vide est affiché (seul l'entête du tableau est affiché).
14.7.3 Limites
Cette zone ne peut-être utilisée que dans le cadre d'une zone documentaire.
14.8 Zones spécifiques d'administration
Cet ensemble de zones est dédié à l'éditions de paramètres qu'ils soient applicatif ou de familles.
En utilisant ces zones, vous pourrez créer des interfaces d'édition de paramètres.
14.8.1 [ZONE FDL:EDITFAMILYPARAMETER]
14.8.1.1 Description
Cette zone permet d'afficher un paramètre en édition quelque soit son type. La
zone est encapsulée dans un élément HTML de type DIV, portant la classe
editfamilyparameter et possédant l'attribut data-parameter qui a pour
valeur l'identifiant du paramètre qui est affiché/modifié. Ce champ a pour
attribut id l'identifiant du paramètre à modifier, et comme attribut name
le même identifiant précédé d'un _ (underscrore).
14.8.1.2 Paramètres
- famid
- Nom logique de la famille dont vous souhaitez éditer le paramètre.
- attrid
- Identifiant du paramètre à modifier
- emptyValue
- Valeur par défaut du formulaire. Si le paramètre n'a pas de valeur, l'interface est initiée avec cette valeur.
- value
- Valeur du formulaire. Quelque soit la valeur du paramètre, l'interface est initiée avec cette valeur.
- submitOnChange
-
yesouno. Valeur par défautno. Si la valeur est passée àyes, le changement de valeur est transmis au serveur auonChangeet auonBlur. - localSubmit
-
yesouno. Valeur par défautyes. Si la valeur est àyesun bouton de soumission est ajouté à côté du champ de saisie. - submitLabel
- Texte. Si cet élément est spécifié et que localSubmit est à
yesalors le bouton de soumission a comme libellé cette valeur.
14.8.1.3 Limites
N/A
14.8.1.4 Exemple
Définition de la zone : [ZONE FDL:EDITFAMILYPARAMETER?famid=ZOO_ENTREE&attrid=ENT_PRIXENFANT&localSubmit=yes&submitOnChange=no]

Figure 92. Modification de paramètre de famille
14.8.2 [ZONE FDL:EDITAPPLICATIONPARAMETER]
14.8.2.1 Description
Cette zone est utilisée pour modifier les paramètres d'une application. En
l'ajoutant vous pourrez modifier tout paramètre d'application, quel que soit
son type. Elle crée un champ input de type texte ou de type select, suivant le
type du paramètre à modifier. Ce champ a pour attribut id l'identifiant du
paramètre à modifier, et comme attribut name le même identifiant précédé
d'un _ (underscore).
14.8.2.2 Paramètres
- appId
- Nom logique de l'application contenant le paramètre
- parameterId
- Identifiant du paramètre de l'application
- emptyValue
- Valeur par défaut du formulaire. Si le paramètre n'a pas de valeur, l'interface est initiée avec cette valeur.
- value
- Valeur du formulaire. Quelque soit la valeur du paramètre, l'interface est initiée avec cette valeur.
- submitOnChange
-
yesouno. Valeur par défautno. Si la valeur est passée àyes, le changement de valeur est transmis au serveur auonChangeet auonBlur. - localSubmit
-
yesouno. Valeur par défautyes. Si la valeur est àyesun bouton de soumission est ajouté à côté du champ saisie. - submitLabel
- Texte. Si cet élément est spécifié et que localSubmit est à
yesalors le bouton de soumission a comme libellé cette valeur.
14.8.2.3 Limites
Seuls les attributs de type text et enum sont présentés.
Le type est déduit du champ kind.
14.8.2.4 Exemple
Définition de la zone : ZONE FDL:EDITAPPLICATIONPARAMETER?appId=ZOO¶meterId=ZOO_NAME
&localSubmit=yes&submitOnChange=no

Figure 93. Modification de paramètre de famille
14.8.3 [ZONE FDL:EDITSUBMIT]
14.8.3.1 Description
Cette zone est utilisée pour faire la sauvegarde de l'ensemble des Zones portant
la classe editfamilyparameter, ou editapplicationparameter, n'ayant pas de
bouton de validation, ni de validation lors de l'activation de l'événement
onchange (submitOnChange=no et localSubmit=no).
Elle crée un bouton qui envoie au serveur les informations des formulaires.
Tout formulaire contenu dans une DIV portant la classe editfamilyparameter
ou editapplicationparameter, n'ayant pas de système de validation (bouton,
input de type submit, envoi lors du onchange...) est envoyé lorsque ce bouton
est cliqué.
Comme les autres Zones de paramétrage, celle ci est encapsulée dans un élément
HTML de type DIV, portant la classe editsubmit. Cet élément ne contient
qu'un input de type submit.
14.8.3.2 Paramètres
- label
- Texte. L'attribut label définit le label du bouton (par défaut "Valider").
14.8.3.3 Limites
N/A
14.9 [ACTION FDL:OPENDOC]
14.9.1 Description
Cette action permet d'avoir la représentation HTML d'un document soit en édition, soit en consultation.
Cette action appelle une autre action suivant le mode demandé :
-
editounew: action GENERIC:GENERIC_EDIT, -
view: action FDL:FDL_CARD.
14.9.2 Paramètres
- id
- L'id du document source. Obligatoire si mode est
viewouedit. - mode
- (
view|edit|new). Si la valeur estviewle document est affiché en consultation. Si elle esteditounewle document est affiché en édition. obligatoire.
14.9.3 Paramètres : mode=view
Dans ce mode l'application appelée est FDL:FDL_CARD et le document est affiché
en consultation.
- latest
-
(
Y|L|P) : Permet de spécifier quelle révision du document est affichée :-
Y: présente la dernière révision du document, -
L: présente l'avant dernière révision du document, -
P: présente la révision précédent celle de l'id, - tout autre valeur : présente la révision correspondant à l'id passé en paramètre.
-
- state
- Nom logique d'un état. Présente le dernier document de la lignée documentaire
ayant cet état. Si
latestetstatesont présents, alors seulstateest pris en compte. - zone
- Nom d'une zone documentaire qui est appliquée au
document. Ce paramètre n'est pas pris en compte si le paramètre
videst valué. - vid
- Nom d'une vue. Si un contrôle de vue est associé à ce document et que ce contrôle de vue contient une vue ayant ce nom, alors celle-ci est appliquée.
- ulink
-
N: Si il est àNles liens ne sont pas rendus et ils sont remplacés par du texte sans hyperlien. - target
- Contenu de l'attribut target des liens générés.
- inline
- (
Y|N) : Si la zone associée au document a l'option:B, alors le fichier généré est envoyé avec unContent-Disposition: inline. (valeur par défaut :N) - unlock
- (
Y|N) : Si la valeur est àYle document est déverrouillé avant sa consultation (défautN). - dochead
- (
N) : Si la valeur est àNl'entête du document n'est pas affiché.
14.9.4 Paramètres : mode=edit
- dirid
-
int: si c'est une création de document (classidoufamidet pas d'id) alors le document est créé dans le dossier référencé par ledirid. - usefor
- (
D|Q) : Si usefor est àDalors c'est l'édition des valeurs par défaut qui est présentée. Si usefor est àQalors c'est l'édition des paramètres qui est présentée. Ce paramètre n'est valide que dans le cas d'une création de document. - mskid
- Nom logique d'un masque. Si cet élément est valué alors ce masque est appliqué à l'interface d'édition.
- zone
- Nom d'une zone documentaire qui est appliquée au
document. Ce paramètre n'est pas pris en compte si le paramètre
videst valué. - vid
- Nom d'une vue. Si un contrôle de vue est associé à ce document et que ce contrôle de vue contient une vue ayant ce nom, alors celle-ci est appliquée.
- rzone
- Nom d'une zone documentaire qui sera utilisée comme
valeur de l'argument
zonepour la page sur laquelle l'utilisateur est redirigé à la fin de l'édition du document. - rvid
- Nom d'une vue qui sera utilisée comme valeur de l'argument
vidpour la page sur laquelle l'utilisateur est redirigé à la fin de l'édition du document. - rtarget
- Nom d'un fenêtre dans laquelle sera affichée la page sur laquelle
l'utilisateur est redirigé à la fin de l'édition du document
(valeur par défaut :
_self). - autoclose
- (yes). Si autoclose est à
yesalors la fenêtre est fermée automatiquement après la modification.
14.9.5 Paramètres : mode=new
Mode utilisé pour la création de document. Le paramètre id n'est pas pris en
compte.
Tous les paramètres du mode edit sont utilisables.
Les paramètres spécifiques sont :
- famid
- Nom logique de la famille de document. Cet élément est utilisé pour créer
un nouveau document. Si un
idest fourni alors ce paramètre est ignoré. Obligatoire siidn'est pas fourni. - classid
- Déprécié. Équivaut à
famid. Siclassidetfamidsont fournis tous les deux, alors seulclassidest utilisé.
En plus de ces paramètres, il est possible d'utiliser les identifiants des attributs comme variable HTTP pour pré-remplir des valeurs dans le formulaire.
?app=FDL&action=OPENDOC&mode=new&famid=1059&an_sexe=F&an_espece=1409
Cet exemple pré-rempli les attributs an_sexe et an_espece.
Pour les valeurs multivaluée, il faut utiliser la notation standard avec les crochets.
?app=FDL&action=OPENDOC&mode=new&famid=1059&an_enfant[]=1433&an_enfant[]=1578
Cet exemple pré-rempli l'attribut an_enfant avec les deux valeurs 1433 et
1578.
3.2.19Le préremplissage est pris en compte si l'attribut à une zone d'édition spécifique.
Important : L'utilisation d'url avec des variables HTTP GET est limité en longueur (variable suivant les configurations du serveurs). Il est déconseillé d'utiliser la notation par URL GET si le nombre de variables et la longueur n'est pas maîtrisé. Il est possible d'utiliser cette même URL avec des variables POST pour contourner cette limite.
14.9.6 Limites
N/A
14.9.7 Notes
La page sur laquelle l'utilisateur est redirigé à la fin de l'édition du
document est : app=FDL&action=FDL_CARD.
14.10 [ACTION FDL:IMPCARD]
14.10.1 Description
Cette action représente un document en consultation HTML sans menu.
14.10.2 Paramètres
- id
- L'identificateur du document source. Obligatoire.
- zone
- Nom d'une zone documentaire qui est appliquée au
document. Ce paramètre n'est pas pris en compte si le paramètre
videst valué. - vid
- Nom d'une vue. Si jamais un contrôle de vue est associé à ce document et que ce contrôle de vue contient une vue ayant ce nom celle-ci est appliquée.
- latest
-
(Y|L|P) : Indique quelle révision du document est affichée :
- Y : présente la dernière révision du document,
- L : présente l'avant dernière révision du document,
- P : présente la révision précédent celle de l'id,
- tout autre valeur : présente la révision correspondante à l'id passé en paramètre.
- state
- Nom logique d'un état. Présente le dernier document de la lignée documentaire
ayant cet état. Si
latestetstatesont présents alors seulstateest pris en compte. - mime
-
Mime type de la page de retour. Principalement utile dans le cas d'un
template binaire
:B. - inline
- Si la première lettre est à
youY(valide pouryes,Yes,Y) et le typemimea une valeur alors la représentation retournée est inline. - ext
- Extension du fichier retourné si le type
mimea une valeur et queinlinen'est pas ày. - view
-
print: si la view est print alors la CSS d'impression est ajoutée à la page.
14.10.3 Limites
N/A
14.11 [ACTION FDL:EXPORTFILE]
14.11.1 Description
Cette action permet de télécharger un fichier du coffre. Soit à l'aide de son identifiant vault, soit de sa référence dans un document.
14.11.2 Paramètres
- inline
-
yes. Si la valeur estyesle fichier est servi inline (affiché dans la page) sinon il est télécharger. (valeur par défaut : vide). - cache
-
yes. Si la valeur estyesle fichier est téléchargé du cache s'il est présent en cache. (valeur par défaut :yes). - width
-
int: Si le mime type du fichier est de type image ou que le type estpngalors dans ce cas le fichier est redimensionné avec la largeur en pixel de width tout en respectant son ratio. - cvViewid 3.2.12
- Identifiant de la vue à utiliser en cas de contrôle de vue. Nécessaire
seulement si l'attribut fichier à la visibilité
Ipar défaut.
14.11.3 Paramètres docid
- docid
- L'identificateur du document source.
- id
- Équivalent de l'argument
docid, il n'est pas pris en compte sidocidest renseigné. - latest
-
(Y|L|P) : Indique quelle [révision][revise] du document est affichée :
- Y : présente la dernière révision du document,
- L : présente l'avant dernière révision du document,
- P : présente la révision précédent celle de l'id,
- tout autre valeur : présente la révision correspondant à l'id passé en paramètre.
- state
- Identifiant d'un état. Présente le dernier document de la lignée documentaire ayant cet état. Si latest et state sont présents alors seul state est pris en compte.
- attrid
- L' attrid de type
fileouimagedu document que l'on souhaite présenter. - index
-
int: Dans le cas d'un attrid référençant un attribut multiple. L'index permet de n'exporter que le n-ième élément. La numérotation commence à 0.
14.11.4 Paramètre pour fichier avec conversion PDF
Ces options ne sont applicables que si l'attribut possède un fichier pdf
calculé par le moteur de transformation. En standard, le moteur de
transformation peut convertir les fichiers bureautique les plus courants (doc,
docx, xls, xlsx, ppt, ...).
- type
- (pdf|png) si le format est
pnglepdfcalculé est ensuite transformé enpng. si le format estpdf, c'est le fichierpdfcalculé qui est retourné. - page
-
int: Si le type estpngalors cet attribut est obligatoire, il indique la page du png demandé.
14.11.5 Paramètres vaultid
Pour récupérer un fichier à l'aide de son identifiant vault.
Ceci n'est applicable que si le fichier a été enregistré dans le coffre en accès libre.
Attention : Si un identifiant vaultid est fourni, les paramètres liés aux
docid ne sont pas pris en compte.
- vaultid
- identifiant vault du fichier à télécharger
14.11.6 Limites
N/A
14.12 [ACTION FDL:FDL_METHOD]
14.12.1 Description
Cette action permet d'exécuter une méthode de la classe associée au document.
Une fois la méthode exécutée un header location contenant
le referer est renvoyé, ce qui dans la majorité des cas équivaut à une
actualisation de la page en cours. Si le referer n'est pas présent alors le header
location contient l'url d'accès en consultation du document référencé par l'id.
Si la méthode exécutée retourne une chaîne de caractère un
AddWarningMsg avec cette chaîne est ajouté.
Attention : La méthode doit avoir le tag @apiExpose dans son commentaire
pour pouvoir être exécutée. Dans le cas contraire, une page avec le message
d'erreur est retournée.
Cette méthode est utilisée par les attributs menu lorsque le lien
est sous la forme ::myMethod().
14.12.2 Paramètres
- id
- L'identificateur du document source.
- method
-
string: Nom de la méthode à exécuter. Cette méthode doit avoir le tag@apiExposepour pouvoir être exécutée. - redirect
-
texte: Si la première lettre de l'argument estnouN( valide pourno,N,No), une page texte est envoyée avec un texte indiquant le statut de l'exécution. - zone
-
texte: Si une zone est présente et que leredirectn'est pas ànalors le redirect ne renvoi pas vers lereferermais vers le document en consultation avec la zone.
14.12.3 Limites
N/A
14.13 Paramétrage du pied de documents
Une représentation standard HTML du document possède trois parties :
- une entête (titre et menu)
- le contenu (attributs affichés)
- un pied de document (footer) - vide par défaut
Le pied de document (document footer) est personnalisable en ajoutant une ou plusieurs zone[zones].
La méthode :
DocumentUserInterface::addDocumentFooterZone(string $index,
string $zone,
bool $edit)
permet d'ajouter ou de remplacer une zone dans le pied de document. Ce paramétrage est effectif pour les interfaces HTML standards de consultation et de modification du document fournies par Dynacase Core.
Les paramètres de cette méthode sont :
- Une chaîne de caractères représentant un nom de référence pour la zone.
- Une chaîne de caractères représentant la définition de la zone
- Un booléen permettant de savoir si la zone déclarer doit être utilisée en mode
de consultation (paramètre à
false) ou en mode d'édition : (paramètre àtrue).
Cette initialisation peut être faite via le fichier de configuration de l'application ou via un script wsh.
14.13.1 Exemple de déclaration de pied de document
Fichier MONAPPLICATION_init.php.in
$app_const = array( "INIT" => "yes", "VERSION" => "@VERSION@-@RELEASE@" ); //Visible en mode de consultation sur tous les documents DocumentUserInterface::addDocumentFooterZone( "MYCUSTOMFOOT", "MONAPPLICATION:ZONE_MONAPPLICATION?id=[id]", false); // View Document Footer //Visible en mode d'édition sur tous les documents. DocumentUserInterface::addDocumentFooterZone( "MYCUSTOMFOOT", "MONAPPLICATION:ZONE_MONAPPLICATION?id=[id]&type=form", true); // Form Document Footer
Cela ajoute la zone de l'application MONAPPLICATION, s'appelant ZONE_MONAPPLICATION dans le pied de document sur l'interface de consultation et de modification.
Des paramètres peuvent être ajoutés pour la zone afin de rendre le contrôleur plus générique.
L'identifiant du document est indiqué avec la variable :
-
[id]: L'identifiant du document
Une fois les zones ainsi déclarées, elles seront disponibles, et affichées sur tous les documents. Le contrôleur de la zone peut rendre conditionnel l'affichage en fonction des arguments qui lui sont fournis.
Si plusieurs zones sont déclarées, elles sont générées les unes à la suite des autres dans l'ordre de leurs déclarations.
14.13.2 Exemple pied de document
Cet exemple montre comment réaliser un exemple complet de pied de document avec le contrôleur, le template ainsi que l'ajout d'une feuille de style et de javascript.
Fichier : MONAPPLICATION/zone_application.php (le contrôleur)
function zone_monapplication(Action &$action) { $docid=$action->getArgument("id"); $type=$action->getArgument("type", "view"); $action->parent->AddCssRef("MONAPPLICATION/Layout/zone_monapplication.css"); $action->parent->AddJsRef("MONAPPLICATION/Layout/zone_monapplication.js"); if ($type === "form") { $action->lay->eset("MYKEY", "Formulaire à remplir"); } else { $action->lay->set("MYKEY", "© My company"); } }
Fichier : MONAPPLICATION/Layout/zone_application.xml (le template)
<footer class="myFoot"> [MYKEY] </footer>
Fichier : MONAPPLICATION/Layout/zone_application.css (la feuille de style)
footer.myFoot { background : yellow; text-align:center; }
Fichier : MONAPPLICATION/Layout/zone_application.js (le code javascript)
console.log("I'm here");
La définition d'un pied de document peut aussi être construite avec un template vide afin de réaliser une simple opération d'ajout de css ou de javascript.
Chapitre 15 Paramètres applicatifs de référence
Les paramètres applicatifs permettent de modifier le fonctionnement de Dynacase. La liste ci-dessous n'est pas exhaustive mais elle présente les paramètres les plus importants d'une installation standard.
15.1 Paramètres d'accès
Les paramètres ci-dessous concernent la phase de routage lors d'une connexion par un utilisateur.
15.1.1 CORE_URLINDEX
15.1.1.1 Description
Le paramètre CORE_URLINDEX permet de spécifier l'URL d'accès à l'index de
Dynacase. Cette URL est utilisée pour composer les URLs présentes sur les
interfaces HTML ou les courriels émis par Dynacase.
- App :
CORE - Portée : Global
- Valeur initiale : (vide)
- Utilisateur : Non
15.1.1.2 Valeurs
La valeur du paramètre doit être une URL sous sa forme normalisée
(e.g. http://www.example.net:8080/dynacase/).
En l'absence de valeur, la valeur du paramètre est calculée à partir du nom d'hôte du serveur.
15.1.1.3 Notes
L'URL ne doit pas contenir de requête (partie de la forme ?a=b&c=d) ou de
hash (partie finale de la forme #anchor).
15.1.2 CORE_MAILACTION
15.1.2.1 Description
Le paramètre CORE_MAILACTION permet de spécifier l'URL d'accès à une
application et une action utilisée pour les liens dans les mails émis par
Dynacase.
- App :
CORE - Portée : Global
- Valeur initiale : (vide)
- Utilisateur : Non
15.1.2.2 Valeurs
La valeur du paramètre doit être une URL, avec une requête, sous sa forme
normalisée (e.g.
http://www.example.net:8080/dynacase/?app=MYAPP&action=MYACTION).
En l'absence de valeur, la valeur du paramètre sera calculée à partir de la valeur du paramètre CORE_URLINDEX.
La valeur par défaut est :
%U%?app=FDL&action=OPENDOC&mode=view&id=%ID%
15.1.2.3 Notes
L'URL doit contenir une chaîne de requête qui référence une application et une
action Dynacase valide (e.g. ?app=MYAPP&action=MYACTION).
3.2.21 Si l'url comporte des
parties variables, ces parties (entre %) sont
remplacées par les valeurs du document.
Exemple :
?app=MYAPP&action=MYACTION&myTitle=%TITLE%&myId=%ID%
Si l'url ne comporte pas de caractère %, l'identifiant du document est ajoutée
à la suite du paramètre avec la variable id.
L'url :
?app=MYAPP&action=MYACTION
sera transformée en :
?app=MYAPP&action=MYACTION&id=%ID%
Si vous utilisez un hash (partie finale de la forme #anchor), l'action
n'aura pas accès à cet id. Cela peut être utile dans le cas ou le routage est
fait coté client. Dans ce cas, il faut utiliser la forme avec des variables.
?app=MYAPP&action=MYACTION#%ID%
15.1.3 CORE_START_APP
15.1.3.1 Description
Le paramètre CORE_START_APP permet de spécifier l'application par défaut qui
est lancée une fois l'utilisateur authentifié sur le système. C'est alors
l'action par défaut de cette application qui est lancée.
- App :
CORE - Portée : Global
- Valeur initiale :
CORE - Utilisateur : Non
15.1.3.2 Valeurs
La valeur du paramètre doit être le nom d'une application Dynacase
(e.g. CORE).
15.1.3.3 Notes
Il n'est pas possible de rediriger vers une action particulière d'une
application. On ne peut re-diriger que vers l'action ROOT.
15.1.4 CORE_ALLOWGUEST
15.1.4.1 Description
Ce paramètre indique l'autorisation d'utiliser le point d'accès guest.php qui
permet d'accéder aux applications en tant qu'utilisateur anonyme (compte
anonymous) sans besoin d'authentification.
- App :
CORE - Portée : Global
- Valeur initiale :
yes - Valeur possible :
yes,no - Utilisateur : Non
15.1.4.2 Valeur
Si la valeur est yes, l'accès à guest.php est autorisé sinon il est
interdit.
15.1.4.3 Notes
Un code HTTP 503 est retourné en cas d'interdiction.
15.2 Système
Les paramètres ci-dessous concernent le fonctionnement global de Dynacase.
15.2.1 CORE_LOGLEVEL
15.2.1.1 Description
Chaque message émis par la classe Log comporte un niveau de log,
et le paramètre applicatif CORE_LOGLEVEL permet de spécifier quels messages
seront journalisés par rapport à ce niveau de log.
Voir classe Log pour la description des niveaux de log.
- App :
CORE - Portée : Global
- Valeur initiale :
IWE - Utilisateur : Non
15.2.1.2 Valeur
La valeur est une chaîne de caractères qui contient la liste des codes de niveau de log qui seront journalisés.
15.2.1.3 Notes
Aucune.
15.2.2 CORE_LOGDURATION
15.2.2.1 Description
Indique le durée de conservation des logs document.
- App :
CORE - Portée : Global
- Valeur initiale :
30(30 jours) - Utilisateur : Non
La suppression des logs document est effectué par le script
cleanContext qui est lancé toutes les nuits.
15.2.2.2 Valeur
La valeur est un nombre indiquant la durée de conservation en jours.
15.2.2.3 Notes
Aucune.
15.2.3 MEMORY_LIMIT
15.2.3.1 Description
Le paramètre MEMORY_LIMIT permet de paramétrer la mémoire maximum qu'une
requête Dynacase est autorisée à allouer.
- App :
CORE - Portée : Global
- Valeur initiale :
64 - Utilisateur : Non
15.2.3.2 Valeur
La valeur du paramètre MEMORY_LIMIT est exprimée par un entier (pour une
quantité exprimée en méga-octets) ou un entier suivi du suffixe G (pour une
quantité exprimée en giga-octets).
Exemple de valeurs :
-
128: pour 128 Mo -
1G: pour 1 Go
15.2.3.3 Notes
Les scripts d'API, lancée par wsh.php, ne sont pas
soumis à cette limite, et leur utilisation mémoire est non-limitée.
15.2.4 CORE_SESSIONTTL
15.2.4.1 Description
Le paramètre CORE_SESSIONTTL permet de spécifier la durée de vie des sessions
sur le navigateur de l'utilisateur.
- App :
CORE - Portée : Global
- Valeur initiale :
0 - Utilisateur : Non
15.2.4.2 Valeur
La valeur est un entier >= 0 qui exprime la durée de vie de la session en secondes.
Si la valeur est égale à 0 (valeur par défaut), alors les sessions seront valides jusqu'à la fermeture du navigateur par l'utilisateur.
Exemple de valeurs :
-
86400: durée de vie de 24 heures -
0: durée de vie jusqu'à la fermeture du navigateur
15.2.4.3 Notes
Aucune.
15.2.5 CORE_SESSIONMAXAGE
15.2.5.1 Description
Durée de conservation d'une session n'ayant plus été utilisée.
- App :
CORE - Portée : Global
- Valeur initiale :
1 week - Utilisateur : Non
Lorsqu'une session est utilisée, sa date d'accès est enregistrée à chaque utilisation. Si une session n'a pas été détruite et n'est plus utilisée depuis ce laps de temps, elle est supprimée lors du garbage collector de session.
15.2.5.2 Valeur
La valeur est une chaîne de caractères qui contient une durée exprimée sous une forme naturelle en anglais.
Les unités possibles sont minute, hour, day, week ou month.
Exemple : 2 days, 1 week, 3 days 12 hours
15.2.5.3 Notes
Voir aussi CORE_SESSIONTTL
15.2.6 CORE_SESSIONGCPROBABILITY
15.2.6.1 Description
Probabilité de déclenchement du nettoyage des sessions non utilisée.
- App :
CORE - Portée : Global
- Valeur initiale :
0.01 - Utilisateur : Non
Le "garbage collector" de session est vérifié à chaque requête avec la probabilité indiquée.
Si la valeur est 0.01, il y a une chance sur 100 de déclencher le nettoyage. En moyenne, toutes les 100 requêtes, un nettoyage est effectué.
15.2.6.2 Valeur
La valeur est un nombre compris entre 0 et 1. Si la valeur est zéro, le déclenchement n'est jamais exécuté. Si la valeur est un, le déclenchement est exécuté à chaque requête.
15.2.6.3 Notes
Voir aussi CORE_SESSIONMAXAGE
15.2.7 CORE_TMPDIR
15.2.7.1 Description
Ce paramètre indique le répertoire temporaire utilisé par Dynacase.
- App :
CORE - Portée : Global
- Valeur initiale :
./var/tmp - Utilisateur : Non
Les fichiers de ce répertoire sont supprimés de façon régulière par le script
cleanContext.
15.2.7.2 Valeur
La valeur doit désigner un répertoire accessible en écriture par le serveur web.
15.2.7.3 Notes
Voir aussi CORE_TMPDIR_MAXAGE.
Lors de la restauration d'une archive de contexte, si la valeur de
CORE_TMPDIR référence un répertoire à l'extérieur du répertoire du contexte,
alors sa valeur est réinitialisée à sa valeur initiale (i.e. ./var/tmp).
15.2.8 CORE_TMPDIR_MAXAGE
15.2.8.1 Description
Ce paramètre indique la durée de conservation des fichiers présents dans le répertoire temporaire.
- App :
CORE - Portée : Global
- Valeur initiale :
2(2 jours) - Utilisateur : Non
15.2.8.2 Valeur
La valeur est un durée exprimée en nombre de jours.
15.2.8.3 Notes
Aucune.
15.2.9 CORE_TMPDOC_MAXAGE
15.2.9.1 Description
3.2.23 Ce paramètre indique la durée de conservation des documents temporaires.
- App :
CORE - Portée : Global
- Valeur initiale :
1(1 jour) - Utilisateur : Non
15.2.9.2 Valeur
La valeur est un durée exprimée en nombre de jours.
15.2.9.3 Notes
Aucune.
15.2.10 FREEDOM_UPLOADDIR
15.2.10.1 Description
Ce paramètre indique le répertoire utilisé pour déposé les archives lors d'une importation.
- App :
CORE - Portée : Global
- Valeur initiale :
./var/tmp - Utilisateur : Non
Par défaut, la valeur est identique au paramètre CORE_TMPDIR.
Dans ce cas, les archives déposées sont supprimées comme les fichiers
temporaires.
Pour conserver les archives, il est nécessaire d'indiquer un autre répertoire
comme par exemple ./var/archive.
15.2.10.2 Valeur
La valeur doit désigner un répertoire accessible en écriture par le serveur web.
15.2.10.3 Notes
Si le répertoire est situé en dehors de l'espace d'installation, son contenu ne sera pas récupéré lors de la constitution d'une archive de contexte.
Lors de la restauration d'une archive de contexte, si la valeur de
FREEDOM_UPLOADDIR référence un répertoire à l'extérieur du répertoire du
contexte, alors sa valeur est réinitialisée à sa valeur initiale (i.e.
./var/tmp).
15.2.11 AUTHENT_PWDMINDIGITLENGTH
15.2.11.1 Description
Le paramètre AUTHENT_PWDMINDIGITLENGTH permet de spécifier le nombre minimum
de chiffres d'un mot de passe.
- App :
AUTHENT - Portée : Global
- Valeur initiale : (vide)
- Utilisateur : Non
15.2.11.2 Valeur
La valeur est un entier >= 0 qui exprime le nombre minimum de chiffre d'un mot de passe.
Si la valeur 0 (valeur par défaut) est spécifiée, alors ce contrôle n'est pas effectué.
15.2.11.3 Notes
Aucune.
15.2.12 AUTHENT_PWDMINLENGTH
15.2.12.1 Description
Le paramètre AUTHENT_PWDMINLENGTH permet de spécifier le nombre minimum de
caractères d'un mot de passe.
- App :
AUTHENT - Portée : Global
- Valeur initiale : (vide)
- Utilisateur : Non
15.2.12.2 Valeur
La valeur est un entier >= 0 qui exprime le nombre minimum de caractères d'un mot de passe.
Si la valeur 0 (valeur par défaut) est spécifiée, alors ce contrôle n'est pas effectué.
15.2.12.3 Notes
Aucune.
15.2.13 AUTHENT_PWDMINLOWERALPHALENGTH
15.2.13.1 Description
Le paramètre AUTHENT_PWDMINLOWERALPHALENGTH permet de spécifier le nombre
minimum de lettres minuscules d'un mot de passe.
- App :
AUTHENT - Portée : Global
- Valeur initiale : (vide)
- Utilisateur : Non
15.2.13.2 Valeur
La valeur est un entier >= 0 qui exprime le nombre minimum de lettres minuscules d'un mot de passe.
Si la valeur 0 (valeur par défaut) est spécifiée, alors ce contrôle n'est pas effectué.
15.2.13.3 Notes
Aucune.
15.2.14 AUTHENT_PWDMINUPPERALPHALENGTH
15.2.14.1 Description
Le paramètre AUTHENT_PWDMINUPPERALPHALENGTH permet de spécifier le nombre
minimum de lettres majuscules d'un mot de passe.
- App :
AUTHENT - Portée : Global
- Valeur initiale : (vide)
- Utilisateur : Non
15.2.14.2 Valeur
La valeur est un entier >= 0 qui exprime le nombre minimum de lettres majuscules d'un mot de passe.
Si la valeur 0 est spécifiée, alors ce contrôle n'est pas effectué.
15.2.14.3 Notes
Aucune.
15.2.15 AUTHENT_ACCOUNTEXPIREDELAY
15.2.15.1 Description
Le paramètre AUTHENT_ACCOUNTEXPIREDELAY permet de spécifier la durée de
validité d'un compte utilisateur.
- App :
AUTHENT - Portée : Global
- Valeur initiale : (vide)
- Utilisateur : Non
15.2.15.2 Valeur
La valeur est un entier >= 0 qui exprime la durée de validité du compte en jours.
Si la valeur 0 est spécifiée, alors ce contrôle n'est pas effectué.
15.2.15.3 Notes
Aucune.
15.2.16 AUTHENT_FAILURECOUNT
15.2.16.1 Description
Le paramètre AUTHENT_FAILURECOUNT permet de spécifier le nombre d'échecs
d'authentification avant la désactivation du compte.
- App :
AUTHENT - Portée : Global
- Valeur initiale : (vide)
- Utilisateur : Non
15.2.16.2 Valeur
La valeur est un entier >= 0 qui exprime le nombre d'échecs d'authentification avant la désactivation du compte.
Si la valeur 0 est spécifiée, alors ce contrôle n'est pas effectué.
15.2.16.3 Notes
Aucune.
15.2.17 CORE_NOTIFY_SENDMAIL
15.2.17.1 Description
3.2.23 Le paramètre CORE_NOTIFY_SENDMAIL
indique dans quels cas une notification doit être affichée à l'utilisateur suite à l'envoi d'un mail.
- App :
CORE - Portée : Global
- Valeur initiale :
always - Utilisateur : Non
15.2.17.2 Valeurs
Les valeurs valides sont
always- une notification est affichée à l'utilisateur à chaque envoi de mail
errors only- une notification est affichée lorsqu'un mail n'a pas pu être envoyé
never- aucune notification n'est affichée à l'utilisateur lors des envois de mail
15.2.17.3 Notes
Ce paramètre est pris en compte lors de l'envoi de mails par la plate-forme.
Lors des envois de mail par du code, ce comportement peut être contourné.
15.2.18 CORE_WSH_MAILTO
15.2.18.1 Description
3.2.23 Le paramètre CORE_WSH_MAILTO
indique à qui doivent être envoyés les mails lors
d'erreurs wsh en mode non interactif.
- App :
CORE - Portée : Global
- Valeur initiale : vide
- Utilisateur : Non
15.2.18.2 Valeurs
La valeur est une liste d'adresses mail séparées par des virgules. Par exemple :
john.doe@example.net, jane.doe@example.net
15.2.18.3 Notes
Le sujet du mail envoyé est défini par le paramètre
CORE_WSH_MAIL_SUBJECT.
15.2.19 CORE_WSH_MAIL_SUBJECT
15.2.19.1 Description
3.2.23 Le paramètre CORE_WSH_MAIL_SUBJECT
indique le sujet des mails envoyés lors
d'erreurs wsh en mode non interactif.
- App :
CORE - Portée : Global
- Valeur initiale : vide
- Utilisateur : Non
15.2.19.2 Valeurs
La valeur est une chaîne de caractère dans laquelle les séquences suivantes sont remplacées :
%h- Le nom d'hôte de la machine (tel que retourné par
php_uname("n")). %c- La valeur du paramètre
CORE_CLIENT. %m- La première ligne du message d'erreur.
%%- le caractère
%
Toute autre séquence de la forme %<texte> sera remplacée par <texte>.
15.2.19.3 Notes
ce paramètre n'est pris en compte que si la valeur du paramètre
CORE_WSH_MAILTO est non vide.
15.3 SMTP
Les paramètres ci-dessous concernent le mécanisme d'envoi de courriels.
15.3.1 SMTP_FROM
15.3.1.1 Description
Le paramètre SMTP_FROM permet de spécifier l'adresse mail utilisée par défaut
lors de l'envoi d'un courriel par Dynacase lorsque l'adresse de l'émetteur n'est pas
spécifiée.
- App :
FDL - Portée : Global
- Valeur initiale : (vide)
- Utilisateur : Non
15.3.1.2 Valeur
La valeur est une adresse mail valide (e.g. jsmith@example.org).
15.3.1.3 Notes
Aucune.
15.3.2 SMTP_HOST
15.3.2.1 Description
Le paramètre SMTP_HOST permet de spécifier le serveur SMTP utilisé par
Dynacase pour l'envoi de courriels.
- App :
FDL - Portée : Global
- Valeur initiale :
localhost - Utilisateur : Non
15.3.2.2 Valeur
La valeur peut être une adresse IP (e.g. 192.168.0.1) ou un nom d'hôte (e.g.
mail.example.net).
Si aucune valeur n'est spécifiée, alors le nom d'hôte localhost est utilisé.
15.3.2.3 Notes
L'adresse IP, ou le nom d'hôte, peut être préfixé par ssl:// afin d'indiquer
l'établissement d'une connexion sécurisée par SSL/TLS (e.g. ssl://192.168.0.1,
ssl://mail.example.net). Le port de connexion est alors spécifié via le
paramètre SMTP_PORT.
15.3.3 SMTP_LOGIN
15.3.3.1 Description
Le paramètre SMTP_LOGIN permet de spécifier le nom d'utilisateur pour la
connexion au serveur SMTP, dans le cas ou ce dernier nécessite d'être
authentifié.
- App :
FDL - Portée : Global
- Valeur initiale : (vide)
- Utilisateur : Non
15.3.3.2 Valeur
La valeur est une chaîne de caractères contenant le login de connexion
(e.g. john.doe).
15.3.3.3 Notes
Aucune.
15.3.4 SMTP_PASSWD
15.3.4.1 Description
Le paramètre SMTP_PASSWD permet de spécifier le mot de passe du
login de connexion au serveur SMTP.
- App :
FDL - Portée : Global
- Valeur initiale : (vide)
- Utilisateur : Non
15.3.4.2 Valeur
La valeur est une chaîne de caractère contenant le mot de passe associé au
login de connexion (e.g. secret).
15.3.4.3 Notes
Aucune.
15.3.5 SMTP_PORT
15.3.5.1 Description
Le paramètre SMTP_PORT permet de spécifier le port TCP de connexion au
serveur SMTP.
- App :
FDL - Portée : Global
- Valeur initiale :
25 - Utilisateur : Non
15.3.5.2 Valeur
La valeur est un entier contenant le port TCP de connexion au serveur SMTP (e.g.
465).
Si aucune valeur n'est spécifiée, alors le port 25 est utilisé.
15.3.5.3 Notes
Aucune.
15.4 TE
Les paramètres ci-dessous concernent le serveur de transformation.
15.4.1 TE_ACTIVATE
15.4.1.1 Description
Le paramètre TE_ACTIVATE permet d'indiquer si le moteur de transformation est
disponible ou non pour Dynacase.
- App :
FDL - Portée : Global
- Valeur initiale :
no - Utilisateur : Non
15.4.1.2 Valeur
La valeur peut être yes pour indiquer que le moteur de transformation est
disponible, ou no pour indiquer que le moteur de transformation n'est pas
disponible.
15.4.1.3 Notes
Aucune.
15.4.2 TE_FULLTEXT
15.4.2.1 Description
Le paramètre TE_FULLTEXT permet d'activer l'indexation des fichiers par
Dynacase, via l'utilisation du moteur de transformation, lors de la sauvegarde
des documents.
- App :
FDL - Portée : Global
- Valeur initiale :
yes - Utilisateur : Non
15.4.2.2 Valeur
La valeur peut être yes pour indiquer d'indexer les fichiers des documents, ou
no pour ne pas indexer les fichiers des documents.
15.4.2.3 Notes
L'indexation des fichiers n'est active que si le moteur de transformation est
disponible (c.f. TE_ACTIVATE).
15.4.3 TE_HOST
15.4.3.1 Description
Le paramètre TE_HOST permet de spécifier le serveur moteur de transformation
utilisé par Dynacase.
- App :
FDL - Portée : Global
- Valeur initiale : (vide)
- Utilisateur : Non
15.4.3.2 Valeur
La valeur peut être une adresse IP (e.g. 192.168.100.1) ou un nom d'hôte (e.g.
te.example.net).
15.4.3.3 Notes
Aucune.
15.4.4 TE_PORT
15.4.4.1 Description
Le paramètre TE_PORT permet de spécifier le port TCP de connexion au serveur
de transformation utilisé par Dynacase.
- App :
FDL - Portée : Global
- Valeur initiale : (vide)
- Utilisateur : Non
15.4.4.2 Valeur
La valeur est un entier contenant le port TCP de connexion au serveur de
transformation (e.g. 51968).
15.4.4.3 Notes
Aucune.
15.4.5 TE_TIMEOUT
15.4.5.1 Description
Le paramètre TE_TIMEOUT permet de spécifier la durée maximale d'attente lors
de la connexion au serveur de transformation.
Une erreur de connexion est retournée si la connexion n'a pu être établie dans ce temps imparti.
- App :
FDL - Portée : Global
- Valeur initiale :
2 - Utilisateur : Non
15.4.5.2 Valeur
La valeur est un réel > 0 indiquant, en secondes, la durée maximale d'attente.
Si aucune valeur n'est spécifiée, la valeur 3 est utilisée.
15.4.5.3 Notes
Aucune.
15.4.6 TE_URLINDEX
15.4.6.1 Description
Le paramètre TE_URLINDEX permet de spécifier l'URL d'accès à l'index de
Dynacase, utilisée par le serveur de transformation pour contacter le serveur
Dynacase.
- App :
FDL - Portée : Global
- Valeur initiale : (vide)
- Utilisateur : Non
15.4.6.2 Valeur
La valeur est une URL sous sa forme normalisée, qui spécifie l'URL d'accès à
l'index de Dynacase (e.g. http://www.example.net:8080/dynacase/).
15.4.6.3 Notes
Aucune.
15.5 Interface client
Les paramètres ci-dessous concernent l'interface utilisateur.
15.5.1 CORE_CLIENT
15.5.1.1 Description
Le paramètre CORE_CLIENT permet de spécifier le titre affiché sur la page de
connexion par défaut et sur certaines interfaces d'accueil.
- App :
CORE - Portée : Global
- Valeur initiale :
<NOM DU CLIENT> - Utilisateur : Non
15.5.1.2 Valeur
La valeur est une chaîne de caractères non HTML (texte simple ligne) et ne
contenant pas le caractère " (double-quote).
15.5.1.3 Notes
La valeur par défaut est remplacée lors de l'installation par la valeur demandée par l'installeur.
15.5.2 CORE_REALM
15.5.2.1 Description
Le paramètre CORE_REALM permet de spécifier le domaine d'authentification.
Ce domaine est utilisé pour l'authentification HTTP Basic et est affiché sur la page de connexion par défaut.
- App :
CORE - Portée : Global
- Valeur initiale :
Dynacase - Utilisateur : Non
15.5.2.2 Valeur
La valeur est une chaîne de caractères (texte simple ligne).
15.5.2.3 Notes
Aucune.
15.5.3 CORE_LOGOCLIENT
15.5.3.1 Description
Le paramètre CORE_LOGOCLIENT permet de spécifier le logo affiché sur la page
de connexion par défaut.
- App :
CORE - Portée : Global
- Valeur initiale :
CORE/Images/logo-mini.png - Utilisateur : Non
15.5.3.2 Valeur
La valeur est un chemin d'accès à un fichier image qui est affiché sur la page
de connexion par défaut. Le chemin d'accès est relatif à l'URL d'accès à l'index
de Dynacase (e.g. CORE/Images/logo-mini.png).
15.5.3.3 Notes
Aucune.
15.5.4 DYNACASE_FAVICO
15.5.4.1 Description
Le paramètre DYNACASE_FAVICO permet de spécifier l'icone qui est présentée
par les pages HTML de Dynacase.
- App :
CORE - Portée : Global
- Valeur initiale :
CORE/Images/dynacase.ico - Utilisateur : Non
15.5.4.2 Valeur
La valeur est un chemin d'accès à un fichier au format favicon
.ico. Le chemin d'accès est relatif à l'URL d'accès à
l'index de Dynacase (e.g. CORE/Images/dynacase.ico).
15.5.4.3 Notes
Exemple d'utilisation de l'icône dans une vue HTML :
<!--STYLESHEETS--> <link rel="icon" href="[DYNACASE_FAVICO]"/> <link rel="shortcut icon" href="[DYNACASE_FAVICO]"/>
Chapitre 16 Scripts CLI de référence
Dynacase est livré avec de nombreux scripts CLI. Vous trouverez dans ce chapitre une explication des plus importants d'entre eux.
16.1 refreshGroups
16.1.1 Description
Ce script permet de recalculer les membres et l'adresse mail (concaténation des adresses mail des membres) des groupes dans le cas ou l'affectation des groupes a été changée sans passer par l'API (mise à jour par requête SQL par exemple).
L'attribut grp_isrefreshed avec la valeur 0 indique un groupe qui n'est pas
à jour. Lorsque le groupe est rafraîchi, l'attribut grp_isrefreshed est
positionné à la valeur 1.
16.1.2 Usage
-
force(defaultno) -
yespour forcer le rafraîchissement de tous les groupes (indépendamment de la valeur de leur attributgrp_isrefreshed).
16.1.3 Limite d'usage
N/A
16.2 manageApplications
16.2.1 Description
Le script manageApplications permet d'installer, ou de mettre à jour, la définition d'une
application Dynacase.
Voir aussi :
16.2.2 Usage
appname(obligatoire)- Le nom de l'application.
-
method(defaultinit) -
Sélectionne l'action à effectuer sur l'application. Les valeurs possibles sont :
init- Initialise (installe) l'application.
update- Met à jour la définition de l'application.
reinit- Re-initialise l'application (dans le cas ou elle a déjà été initialisée
avec la méthode
init). delete- Supprime la définition de l'application.
16.2.3 Limite d'usage
N/A
16.3 cleanFamily
16.3.1 Description
Ce script permet de supprimer tous les attributs en base de données qui ne sont pas définis dans la famille. Les valeurs de ces attributs sont aussi supprimées sur les documents.
16.3.2 Usage
famid(obligatoire)-
Identifiant (ou nom logique) de la famille sur laquelle appliquer le script.
La valeur
0indique que l'opération est à effectuer sur toutes les familles. without-confirm- Ne demande pas de confirmation. En l'absence de ce paramètre, une confirmation est demandée sur stdin.
verify-only- N'effectue pas les changements, liste juste les attributs qui seront supprimées.
16.3.3 Limite d'usage
Attention : Cette opération est irréversible !
Dans le cas de l'application sur une famille qui comporte des familles dérivées, le traitement sera aussi appliqué à ces familles dérivées.
16.4 cleanFamilyParameter
16.4.1 Description
Le script cleanFamilyParameter permet de supprimer les valeurs des paramètres
de famille qui ne sont plus définis.
16.4.2 Usage
verify-only- Affiche seulement les valeurs des paramètres qui seraient supprimés sans faire la modification.
16.4.3 Limite d'usage
N/A
16.5 manageContextCrontab
16.5.1 Description
Le script manageContextCrontab permet d'enregistrer, ou supprimer, des crontabs du contexte
dans l’ordonnanceur cron du système.
16.5.2 Usage
cmd(obligatoire)-
L'opération à effectuer. L'opération peut être :
list- Afficher la liste des fichiers de crontab chargés et actifs pour le contexte.
register- Charger, ou mettre à jour, un fichier de définition de crontab pour le contexte.
unregister- Décharger un fichier de définition de crontab pour le contexte.
unregister-all- Décharger toutes les définitions de crontab pour le contexte.
file-
Permet de spécifier le fichier de crontab à charger/décharger pour le contexte. Le contenu du fichier doit être conforme à la syntaxe des fichiers cron du système (c.f.
man 5 crontab).Cette option est requise pour les opérations
registeretunregister. user- Permet de spécifier le nom de l'utilisateur système sous lequel sont chargés/déchargés les fichiers crontab. Par défaut, l'uid de l'utilisateur courant (utilisateur du process Apache par ex.) est utilisé.
16.5.3 Limite d'usage
N/A
16.6 initializeDocrelTable
16.6.1 Description
Les relations entre documents sont stockées dans un cache, la table docrel.
Le script initializeDocrelTable permet de régénérer ce cache.
16.6.2 Usage
dryrun- Permet d'afficher les requêtes SQL sans les exécuter et donc sans modifier quoi que ce soit.
-
famid(defaultall) -
Permet de spécifier l'identifiant, ou le nom logique, d'une famille pour restreindre le traitement aux relations de cette seule famille.
Par défaut, le traitement s'applique à toutes les familles (
all). transaction-
Permet d'indiquer d'effectuer les modifications dans une transaction
Si l'on utilise une transaction et qu'une des sous-opérations génère une erreur, alors aucune des modifications n'est appliquée.
softclean-
Indique que la table
docrelne sera pas supprimée avant sa reconstruction. La tabledocrelest mise à jour au fur et à mesure du traitement des familles.
Dans le cas contraire, la tabledocrelest supprimée avant d'être intégralement reconstituée.Cette option sera systématiquement activée si une famille est spécifiée via l'option
famid.
16.6.3 Limite d'usage
N/A
16.7 cleanContext
16.7.1 Description
Le script cleanContext permet d'effectuer les opérations de nettoyage
journalières du contexte.
Opérations principales :
- Suppression des messages de log antérieurs à la durée de rétention paramétrée
par
CORE_LOGDURATION. - Suppression des fichiers temporaires antérieurs à la durée de rétention
paramétrée par
CORE_TMPDIR_MAXAGE. - Suppression des documents Dynacase temporaires, et des noms logiques temporaires (générés par l'Exportation des profils par exemple).
- Nettoyage des noms logiques lorsque des documents ont été supprimés à la main en base de données.
16.7.2 Usage
full-
Permet d'effectuer des opérations de nettoyage additionnelles (telles que lancées, la nuit, par la crontab du contexte) :
- Suppression des références à des documents supprimés dans les répertoires
(
DIR). - Suppression des verrous sur les documents.
- Suppression de la définition des attributs pour les familles supprimées à la main en base de données.
- Suppression des références à des documents supprimés dans les répertoires
(
16.7.3 Limite d'usage
N/A
16.8 generateDocumentClass
16.8.1 Description
Le script generateDocumentClass permet de régénérer les classes PHP des
familles Dynacase.
16.8.2 Usage
-
famid(default0) -
Identifiant, ou nom logique, de la famille pour laquelle on souhaite régénérer la classe PHP.
Si aucune famille n'est spécifiée, ou si la valeur
0est spécifiée, le traitement est effectué sur toutes les familles.
16.8.3 Limite d'usage
N/A
16.9 destroyFamily
16.9.1 Description
Le script destroyFamily permet de supprimer complètement une famille et ses
documents.
16.9.2 Usage
famid(obligatoire)- Identifiant, ou nom logique, de la famille sur laquelle appliquer le traitement.
transaction- Permet d'indiquer que l'erreur d'une sous-opération doit annuler
l'ensemble des modifications.
Dans le cas contraire, l'échec d'une sous-opération ne mettra pas en erreur l'ensemble du traitement, qui poursuivra alors son exécution.
16.9.3 Limite d'usage
Attention : La suppression d'une famille entraîne la suppression de tous les documents de cette famille et cette opération est irréversible.
Dans le cas de la suppression d'une famille qui comporte des familles dérivées, il faudra d'abord supprimer les familles dérivées avant de pouvoir supprimer cette famille parente.
16.10 fixMultipleAliveRevision
16.10.1 Description
Le script fixMultipleAliveRevision permet de corriger les erreurs de
« multiple alive revision ».
Une erreur de « multiple alive revision » correspond à un document révisé qui comporte plus d'une révision vivante (un document ne pouvant avoir qu'une et une seule révision vivante).
16.10.2 Usage
Le script ne prend pas d'argument : il recherche et corrige un niveau de révision à chaque exécution de celui-ci.
Le script est à exécuter itérativement jusqu'à ce que ce dernier ne retourne plus aucune erreur à corriger.
16.10.3 Limite d'usage
N/A
16.11 getApplicationParameter
16.11.1 Description
Le script getApplicationParameter permet de récupérer la valeur d'un
paramètre.
16.11.2 Usage
param(obligatoire)- Nom du paramètre dont la valeur doit être retournée.
16.11.3 Limite d'usage
Ne permet de récupérer que les paramètres de type global ou les paramètres de
l'application CORE.
Si le paramètre n'existe pas, n'est pas un paramètre de CORE ou n'est pas un
paramètre global, alors une chaîne vide est renvoyée et un message d'erreur est
enregistré.
16.12 importDocuments
16.12.1 Description
Le script importDocuments permet d'importer des définitions de familles ou
d'importer des documents.
Voir aussi :
16.12.2 Usage
file(obligatoire)-
Le fichier à importer.
Le fichier peut être au format CSV, XML ou bien une archive (si l'option
--archive=yesest utilisée). -
analyze(defaultno) - Permet d'effectuer (
yes) seulement une validation du format et de la structure du fichier importé. -
archive(defaultno) -
Permet d'indiquer si le fichier est une archive (
yes) ou bien un fichier d'importation texte (no).Voir Importation d'archive pour le format de ces archives.
log- Permet de spécifier un fichier de log dans lequel seront inscrits les résultats de l'import.
-
policy(defaultupdate) -
Permet de spécifier le comportement lorsqu'on importe un document qui existe déjà.
La détection des documents existants est spécifiée par la directive d'import
KEYS.Les valeurs possibles pour l'option
policysont :add- Un nouveau document est créé systématiquement, même si un document existant est détecté.
keep- Si un document existant est détecté, alors le document existant est conservé en l'état, et l'importation ne crée pas un nouveau document.
update- Si un document existant est détecté, alors le document existant est mis à jour avec les données du document importé.
-
htmlmode(defaultyes) - Permet de spécifier si les messages du fichier de log doivent être inscrits
au format HTML (
yes) ou au format texte (no). reset[]-
Permet de spécifier les éléments qui doivent être supprimés, ou redéfinis, lors de l'importation d'une définition de famille.
Les valeurs possibles sont celles de l' instruction de
RESET.Cette option peut être utilisée plusieurs fois afin de spécifier plusieurs valeurs.
to- Permet d'envoyer le log au format HTML à l'adresse mail indiquée par cette option.
dir- Identifiant, ou nom logique, d'un répertoire Dynacase dans lequel seront insérés les documents importés.
-
strict(defaultyes) - Permet de spécifier (
yes) si une erreur d'importation d'un document invalide l'importation de tous les documents. Si le mode strict est désactivé (no), alors une erreur sur un document n'empêchera pas les autres documents d'êtres importés. -
csv-separator(default;) 3.2.12 - Dans le cas d'importation en fichier csv permet d'indiquer le caractère de
séparation des champs. Généralement le caractère est
,(virgule) ou;(point-virgule).
Si la valeur estauto, le caractère de séparation parmi,et;est trouvé automatiquement. -
csv-enclosure(defaultvide) 3.2.12 - Dans le cas d'importation en fichier csv permet d'indiquer le caractère de
de délimiteur de texte. Généralement le caractère est
"(double quote) ou'(simple quote)
Si la valeur estauto, le caractère de séparation parmi"et'est trouvé automatiquement. -
csv-linebreak(default "\n- 2 caractères\etn") 3.2.12 - Dans le cas d'importation en fichier csv permet d'indiquer une séquence de
caractère indiquant un retour chariot (CRLF). Si
csv-enclosuren'est pas vide, le retour chariot (caractère"\n") est pris en compte quelque soit la valeur de cet argument. Cet argument permet en plus d'indiquer une séquence qui sera interprétée comme un retour à la ligne.
16.12.3 Limite d'usage
En cas d'importation de fichier CSV, la détection automatique de délimiteur et de séparateur (csv-enclosure=auto et csv-separator=auto) peux être erroné car la détection se base sur des statistiques d'apparition de ces caractères. Si ces paramètres sont connus, il est recommandé de les indiquer explicitement.
16.13 refreshDocuments
16.13.1 Description
Le script refreshDocuments permet d'appliquer une méthode sur les documents
d'une famille donnée.
16.13.2 Usage
famid(obligatoire)- Identifiant, ou nom logique, de la famille des documents sur lesquels s'applique le traitement.
-
method(defaultrefresh) -
La méthode à appliquer sur les documents de la famille.
Par défaut c'est la méthode
refresh()qui est appliquée. arg- Permet de spécifier le premier argument de la méthode.
-
revision(defaultno) - Permet de spécifier si la méthode doit être appliquée sur toutes les
révisions des documents (
yes) ou seulement sur la dernière révision des documents (no). docid- Permet de restreindre le traitement à un seul document dont l'identifiant ou le nom logique est spécifié par cette option.
start-
La liste des documents à traiter est ordonnée par ordre décroissant des identifiants de document (
id). Cette option permet de commencer le traitement à partir d'un indice de document donné. slice-
Permet de limiter le traitement à un nombre donné de documents.
Dans ce cas, seul les
slicepremiers documents (à partir du document désigné parstart) seront traités. fldid-
Permet de restreindre le traitement aux documents présents dans un répertoire ou retournés par une recherche.
fdlidpeut donc être l'identifiant ou le nom logique d'un document Répertoire (DIRou dérivé) ou d'un document Recherche (SEARCHou dérivé). filter- Permet de spécifier un filtre SQL additionnel pour la sélection des documents sur lesquels est appliqué le traitement.
-
save(defaultlight) -
Permet de spécifier si une méthode de post-traitement doit être appliquée pour la sauvegarde des modifications effectuées par la méthode
method.Les valeurs possibles sont :
complete- Appelle la méthode
store()après l'exécution de la méthodemethod. light- Appelle la méthode
modify(true)après l'exécution de la méthodemethod. none- N'appelle aucune autre méthode additionnelle après l'exécution de la
méthode
method.
-
status-file3.2.19 -
Permet de spécifier la création d'un fichier de rapport contenant :
- le nombre de documents sélectionnés pour traitement (ligne
ALL:) ; - le nombre de documents traités (ligne
PROCESSED:) ; - le nombre de documents traités avec erreur (ligne
FAILURE:) ; - le nombre de documents traités avec succès (ligne
SUCCESS:) ;
Si
-(tiret) est spécifié, le fichier de rapport est alors écrit sur le flux de sortie standardSTDOUT.Si le fichier spécifié existe déjà, le fichier est supprimé avant d'être re-créé.
Par défaut aucun fichier de rapport n'est créé.
- le nombre de documents sélectionnés pour traitement (ligne
-
stop-on-error3.2.19 -
Permet de stopper le traitement lorsque la méthode
store()oumodify()d'un document retourne une erreur, ou lorsqu'une exception est levée.Par défaut le comportement est de poursuivre le traitement lorsqu'un document retourne une erreur ou lance une exception.
16.13.3 Limite d'usage
Seul le premier argument de la méthode method peut être spécifié avec l'option
arg. Les autres arguments de la méthode ne seront donc pas positionnés (ce qui
peut restreindre les méthodes utilisable par ce traitement).
16.13.4 Erreurs
3.2.19 Le processus se termine
avec un exit code 0 s'il n'y a pas d'erreurs, ou un exit code différent de
0 lorsque au moins un document a remonté une erreur (erreur de
store()/modify() ou exception lancé par le document).
16.13.5 Changements
16.13.5.1 Version 3.2.19
Depuis la version 3.2.19 les exceptions sont attrapés et traitées comme une
erreur (au même titre qu'une erreur retourné par store() ou modify()) et ne
stoppent donc plus l'exécution du traitement.
Dans les versions précédentes les exceptions n'étaient pas attrapées et interrompaient l'exécution du traitement.
Pour rétablir un fonctionnement similaire a celui des versions précédentes vous
pouvez utiliser l'option --stop-on-error qui interrompt le traitement au
premier document qui retourne une erreur ou une exception.
16.14 setApplicationParameter
16.14.1 Description
Le script setApplicationParameter permet de changer la valeur d'un paramètre
applicatif.
16.14.2 Usage
param(obligatoire)- Nom du paramètre dont la valeur doit être changée.
value- Nouvelle valeur à affecter au paramètre.
appname- Permet de spécifier le nom d'une application pour restreindre la recherche aux seuls paramètres de cette application.
16.14.3 Limite d'usage
Si appname n'est pas précisé et que param se trouve dans plusieurs
applications, un message d'erreur est retourné, demandant de préciser le nom de
l'application.
Si aucun paramètre de ce nom n'est trouvé, un message d'erreur est retourné.
Dans tous les autres cas, la valeur du paramètre sera changée.
Si aucune valeur n'est précisée, alors la valeur du paramètre sera NULL.
16.15 setStyle
16.15.1 Description
Le script setStyle permet de changer le style appliqué à Platform ou
d'actualiser le style actuellement utilisé.
16.15.2 Usage
style-
Chemin d'accès vers un fichier
.stycontenant la description du style à utiliser ou nom du style dans le sous-répertoireSTYLE(STYLE/%s/%s.sty).Si
stylen'est pas spécifié, alors le style actuellement utilisé est actualisé.Voir gestion des styles.
-
verbose(defaultno) - Permet d'indiquer au script d'afficher plus de messages (
yes) durant son exécution, ou d'afficher moins de messages (no).
16.15.3 Limite d'usage
N/A
16.16 checkVault
16.16.1 Description
Le script checkVault permet d'identifier les fichiers du vault qui ne sont
référencés par aucun document Dynacase (fichiers orphelins), ou bien les
documents Dynacase qui référencent des fichiers qui n'existent plus dans le
vault.
Le script permet ensuite de supprimer ces fichiers orphelins.
16.16.2 Usage
-
vault(defaultFREEDOM) - Le nom du vault que l'on souhaite inspecter ou modifier.
test- Permet d'afficher les opérations qui seront effectuées sans modifier quoi que ce soit.
cmd(obligatoire)-
Permet de spécifier l'opération à effectuer. L'opération peut être :
check-all- Rapporte les fichiers du vault qui ne sont référencés par aucun document Dynacase (fichiers orphelins), et rapporte les documents Dynacase qui référencent des fichiers qui n'existent plus dans le vault.
check-noref- Rapporte les fichiers du vault qui ne sont référencés par aucun document Dynacase (fichiers orphelins).
check-nofile- Rapporte les documents Dynacase qui référencent des fichiers qui n'existent plus dans le vault.
clean-unref- Plus utilisable depuis la version
3.2.21.
Le script
cleanVaultOrphanspermet la suppression des fichiers orphelins (fichiers qui ne sont référencés par aucun document Dynacase).
csv- Permet d'afficher le résultat de l'inspection sous la forme d'un fichier CSV avec comme séparateur le point-virgule. (pour utilisation par un outils tiers).
16.16.3 Limite d'usage
La bonne exécution de cette commande peut nécessiter, au préalable, l'exécution
du script d'API
refreshVaultIndex afin de
correctement détecter les incohérences de relations entre les fichiers et les
documents Dynacase.
16.17 refreshVaultIndex
16.17.1 Description
Les associations entre les documents et les fichiers qu'ils référencent sont
stockées dans un cache, la table docvaultindex.
Le script refreshVaultIndex permet de régénérer ce cache.
16.17.2 Usage
dryrun- Permet d'afficher les requêtes SQL sans les exécuter et donc sans modifier quoi que ce soit.
-
famid(defaultall) -
Permet de spécifier l'identifiant, ou le nom logique, d'une famille pour restreindre le traitement aux fichiers de cette seule famille.
Par défaut, le traitement s'applique à toutes les familles (
all). transaction-
Permet d'indiquer que les modifications sont effectuées dans une transaction. Par défaut, aucune transaction n'est utilisée.
Si l'on utilise une transaction et qu'une des sous-opérations génère une erreur, alors aucune des modifications n'est appliquée.
softclean-
Ne supprime pas tous les index au préalable. Par défaut la table
docvaultindexest totalement vidée avant d'être reconstruite.Cette option est systématiquement activée si une famille est spécifiée via l'option
famid.
16.17.3 Limite d'usage
N/A
16.18 cleanVaultOrphans
3.2.18
16.18.1 Description
Le script cleanVaultOrphans permet d'analyser le taux d'occupation du vault
(fichiers utilisés, fichier orphelins et fichiers manquants) et de supprimer
les fichiers orphelins.
16.18.2 Usage
analyze- Permet d'analyser le taux d'occupation du vault et des fichiers orphelins : fichiers présents en base de données mais non référencés par un document.
-
missing-files(nécessite--analyze) - En conjonction avec
--analyze, permet d'analyser les fichiers manquants : fichiers présents en base de données mais non présents sur le système de fichiers du vault. clean-
Permet de nettoyer les fichiers orphelins :
- Suppression de la référence en base de données.
- Suppression du fichier correspondant sur le système de fichiers du vault.
Cette opération est irréversible. Les fichiers sont définitivement supprimés.
Exemple :
./wsh.php --api=cleanVaultOrphans --analyze
* Analyzing... Done.
Analyze
-------
All:
count = 418635
size = 207835025933 (194 GB)
Used:
count = 310387
size = 177660324178 (165 GB) (85.48%)
Orphan:
count = 108248
size = 30174701755 (28 GB) (14.52%)
16.18.3 Limite d'usage
N/A
16.19 wstop
16.19.1 Description
Le script wstop permet de mettre le contexte en mode maintenance.
Le script wstop se trouve à la racine du contexte et n'est donc pas un script
d'API wsh.
Le mode maintenance :
- bloque l'accès des utilisateurs Web en affichant une page leur indiquant que le système est en cours de maintenance ;
- bloque l'exécution des crons de Dynacase.
16.19.2 Usage
N/A
16.19.3 Limite d'usage
N/A
16.19.4 Voir aussi
16.20 wstart
16.20.1 Description
Le script wstart permet de reconfigurer certains éléments du contexte et de
sortir le contexte du mode de maintenance.
Le script wstart se trouve à la racine du contexte et n'est donc pas un
script d'API wsh.
Par défaut, toutes les opérations sont effectués dans l'ordre suivant :
- régénération du cache de l'autoloader de classes ;
- régénération des liens symboliques des images dans le répertoire
Imagesà la racine du contexte ; - suppression des fichiers de cache dans le répertoire
var/cache/image; - incrément du compteur de version
WVERSION; - (déprécié) configuration du mode de connexion à la base de données ;
- régénération des styles ;
- désactivation du mode maintenance du contexte.
Chacune de ces opérations peut être exécutée manuellement en lançant wstart
avec les options décrites ci-dessous.
16.20.2 Usage
-a--all- Lance toutes les opérations (comportement par défaut).
-r--resetAutoloader- Lance la régénération du cache d'autoloader de classes.
-l--links- Lance la régénération des liens symbolique des images dans le
sous-répertoire
Imagesdu contexte. -c--clearFile- Supprime les fichiers
*.png,*.gif,*.xmlet*.srcdans le sous-répertoirevar/cache/imagedu contexte. -u--upgradeVersion- Incrémente le compteur de version
WVERSION. -b--dbconnect- (déprécié) Applique le mode de connexion spécifié par le paramètre
applicatif
CORE_DBCONNECT. -s--style- Lance la régénération des style (voir
setStyle). -m--unStop- Désactive le mode de maintenance.
-v--verbose- Affiche les opérations qui sont effectués (par défaut seuls les messages d'erreurs sont affichés).
16.20.3 Limite d'usage
- Plusieurs options peuvent être spécifiés afin de sélectionner plusieurs opérations à réaliser.
- L'ordre des options n'a pas d'effet sur l'ordre dans lequel les opérations
sélectionnés sont exécutées : les opérations sélectionnés sont exécutées dans
l'ordre décrit au chapitre
Description.
16.20.4 Voir aussi
Chapitre 17 Techniques avancées avec Dynacase
Le but de ces chapitres est d'aborder la conception technique de dynacase pour en faciliter la prise en main et le debug.
17.1 Gestion des styles
17.1.1 Description des styles
17.1.1.1 Éléments de style
Un style est composé de :
- Un fichier de description,
- un fichier css (optionnel)
- des images (optionnel)
Soit le style MONSTYLE.
Les fichiers doivent être publiés sur le serveur avec cette arborescence :
- STYLE
- MONSTYLE
- MONSTYLE.sty
- Layout
- MONSTYLE.css
- Images
- monimage1.png
- monimage2.png
- MONSTYLE
Le fichier de style est MONSTYLE.sty, le fichier css est MONSTYLE.css.
17.1.1.2 Fichier de style
Un fichier de style .sty est un fichier php, déclarant les variables :
$sty_desc(obligatoire)-
La description du style.
C'est un tableau contenant les entrées :
name(obligatoire)- Le nom du style.
description- La description du style
-
parsable(déprécié) - conservé pour compatibilité avec l'ancien système.
$sty_colors(obligatoire)-
Les couleurs de base du style.
C'est un tableau contenant les entrées :
A(obligatoire)B(obligatoire)C(obligatoire)
Ces variables seront utilisées pour générer les paramètres de couleur (de
COLOR_A0àCOLOR_A9, deCOLOR_B0àCOLOR_B9et deCOLOR_C0àCOLOR_C9). $sty_inherit-
le chemin vers un fichier de style parent.
Si défini, alors le style parent sera utilisé comme base, et ses valeurs seront les valeurs par défaut des éléments du style courant.
$sty_const-
Les paramètres propres au style.
C'est un tableau contenant les entrées :
- COLOR_BLACK : couleur du noir
- COLOR_WHITE : couleur du blanc
- CORE_BGIMAGE : image de fond de page
- CORE_BGCOLOR : couleur du fond d'éléments
- CORE_TEXTFGCOLOR : couleur du texte
- CORE_TEXTBGCOLOR : couleur de texte contrasté (pour la mise en évidence)
- CORE_BGCOLORALTERN : couleur de fond secondaire
- CORE_FGCOLOR: couleur de fond utilisé pour le texte contrasté
- CORE_BGCOLORHIGH : couleur utilisée pour la mise en évidence (généralement onmouseover)
- CORE_ACOLOR: couleur de hyperliens (ancres)
- CORE_BGCELLCOLOR: couleurs des cellules de tableaux
- CORE_ERRORCOLOR : couleur des messages d'erreurs
$sty_local-
Les variables à utiliser pour le parsing initial du style.
C'est un tableau. Les clés sont enregistrées comme paramètres volatiles le temps de l'initialisation du style.
$sty_rules- Les règles de style permettant la génération des fichiers css finaux.
17.1.1.3 Règles de style css
Les règles d'un style définissent comment sont produits les fichiers d'un style. Ces fichiers peuvent, par exemple, être la simple copie d'un fichier existant, la concaténation de plusieurs fichiers, la minification d'un fichier, le résultat du parsing d'un fichier, une génération complète, etc.
Les règles sont définies au moyen d'un tableau à plusieurs niveaux.
Par exemple :
array( 'css' => array( // copie simple 'dcp/raw/modern.css' => array( 'src' => 'STYLE/MODERN/Layout/MODERN.css' ), // concaténation simple 'dcp/raw/ext-adapter.css' => array( 'src' => array( "extsystem"=>'STYLE/MODERN/Layout/EXT-ADAPTER-SYSTEM.css', "extuser"=>'STYLE/MODERN/Layout/EXT-ADAPTER-USER.css' ) ), // concaténation avec parsing 'dcp/parse_on_copy/ext-adapter.css' => array( 'src' => array( "extsystem"=>'STYLE/MODERN/Layout/EXT-ADAPTER-SYSTEM.css', "extuser"=>'STYLE/MODERN/Layout/EXT-ADAPTER-USER.css' ), "deploy_parser" => array( "className" => '\Dcp\Style\dcpCssTemplateParser' ) ), // concaténation simple - // le parsing se fait à la volée lors de la requête 'dcp/parse_on_load/ext-adapter.css' => array( 'src' => array( "extsystem"=>'STYLE/MODERN/Layout/EXT-ADAPTER-SYSTEM.css', "extuser"=>'STYLE/MODERN/Layout/EXT-ADAPTER-USER.css' ), 'flags' => Style::RULE_FLAG_PARSE_ON_RUNTIME ), // concaténation avec parsing - // un autre parsing se fait à la volée lors de la requête 'dcp/parse_twice/ext-adapter.css' => array( 'src' => array( "extsystem"=>'STYLE/MODERN/Layout/EXT-ADAPTER-SYSTEM.css', "extuser"=>'STYLE/MODERN/Layout/EXT-ADAPTER-USER.css' ), "deploy_parser" => array( "className" => '\Dcp\Style\dcpCssTemplateParser' ), 'flags' => Style::RULE_FLAG_PARSE_ON_RUNTIME ) ) );
-
L'index de premier niveau correspond au type de fichier produit, parmi :
-
cssTous les fichiers produits seront placés dans le répertoire
cssà la racine du répertoire d'installation.
-
-
L'index de second niveau définit le fichier à produire, au moyen de son chemin relatif à la racine pour ce type de fichier (par exemple, pour
mypath/myfile.css, cela correspond à<document root>/css/mypath/myfile.css).Le tableau correspondant à cet index définit comment sera générée la cible. Les clés significatives de ce tableau sont :
src- le ou les fichier(s) source(s), définis par leur chemin relatif au documentroot ;
flags-
un masque binaire indiquant des options de génération.
les flags actuellement disponibles sont :
Style::RULE_FLAG_PARSE_ON_DEPLOY- Indique que les sources seront envoyées à un parser lors de leur déploiement
Style::RULE_FLAG_PARSE_ON_RUNTIME- Indique que les sources seront envoyées à un parser lors de leur téléchargement par le client
deploy_parser-
La configuration du parser à utiliser pour le déploiement (voir les parsers).
C'est un tableau contenant :
-
à l'index
classNamele nom de la classe (namespaces inclus) à utiliser pour produire le fichieren l'absence de valeur, c'est la classe
\Dcp\Style\dcpCssConcatParserqui est utilisée. à l'index
optionsun tableau d'options qui sera envoyé au parser.
-
runtime_parser-
La configuration du parser à utiliser pour le déploiement (voir les parsers).
Pour le moment, le parsing au runtime ne supporte pas de classe personnalisée.
SiStyle::RULE_FLAG_PARSE_ON_RUNTIMEest positionné, le fichier sera parsé par le moteur de template de Dynacase.
Aussi, positionner une valeur autre quenullà l'index className lèvera une erreur.C'est un tableau contenant :
à l'index
classNamele nom de la classe (namespaces inclus) à utiliser pour produire le fichier.à l'index
optionsun tableau d'options qui sera envoyé au parser.
17.1.1.3.1 Règles locales
Les règles locales sont définies dans la variable $sty_rules du fichier de
définition de style.
17.1.1.3.2 Surcharge de règles pour un style
Lors de son déploiement, le style récupère également toutes les règles
définies dans les fichiers contenus dans le répertoire rules.d
placés à la racine du style. Ces fichiers sont chargés par ordre alphabétique,
et seule leur variable $sty_rules est utilisée, afin de surcharger les règles
locales.
Cela permet notamment
- de rajouter des règles à un style déjà déployé,
- d'altérer les règles d'un style déjà déployé.
17.1.1.3.3 Surcharge de règles pour plusieurs styles
3.2.19
Les styles installée par défaut sont ajoutés dans le répertoire STYLE de la
racine du répertoire d'installation. Chacun des styles dispose de son propre
répertoire.
./STYLE
DEFAULT/
DEFAULT.sty
Images/*.png
MODERN/
MODERN.sty
Images/*.png
Comme indiqué au paragraphe précédent, il est possible d'ajouter des surcharges pour des styles déjà définis.
Exemple :
./STYLE
DEFAULT/
DEFAULT.sty
Images/*.png
rules.d/
CUSTOM1.sty
CUSTOM2.sty
MODERN/
MODERN.sty
Images/*.png
rules.d/
CUSTOM1.sty
Afin d'éviter d'ajouter la même règle sur tous les styles existants, il faut
déposer le fichier de règles dans le répertoire global-rules.d situé au dessus
des répertoires des styles.
L'exemple précédent peut être redéfini avec l'arborescence suivante :
La régle CUSTOM1.sty sera ajouté au style courant quel qu'il soit.
./STYLE
DEFAULT/
DEFAULT.sty
Images/*.png
rules.d/
CUSTOM2.sty
MODERN/
MODERN.sty
Images/*.png
global-rules.d/
CUSTOM1.sty
Cela permet notamment :
- d'ajouter des règles à tous les styles déployés et à venir
- d'altérer les règles pour le style courant sans l'affecter directement
17.1.1.4 Parsers
Les parsers sont des classes implémentant l'interface Dcp\Style\IParser et
celle correspondant au type de fichier produit (pour les css,
Dcp\Style\ICssParser).
Ils implémentent donc
- un constructeur prenant en entrée le(s) fichier(s) source(s), un tableau d'options, ainsi que la configuration complète du style.
- une méthode
genprenant en paramètre le chemin du fichier à produire.
Les parsers fournis par défaut sont :
Dcp\Style\dcpCssConcatParser- un parser faisant uniquement la concaténation de css
Dcp\Style\dcpCssTemplateParser-
un parser faisant la concaténation de css, puis les parsant au moyen du moteur de template de Dynacase.
Les parsers étant chargés au moyen de l'autoloader, il est parfaitement possible de définir de nouvelles classes de parser, tant qu'elles implémentent les interfaces correspondantes.
Dcp\Style\dcpCssCopyDirectory- un parser permettant de copier le contenu d'un répertoire. Ceci est utilisé notamment pour copier un ensemble d'images liées à la css.
3.2.19
Un parser less (Dcp\Style\dcpLessParser) est aussi disponible
en installant le module dynacase-less-installer.
17.1.2 Créer un nouveau style à partir du style par défaut
Le module "Dynacase-core" livre 3 styles situé dans le répertoire STYLE :
-
DEFAULT: Le style de référence -
MODERN: Le style installé par défaut. Il hérite deDEFAULT -
ORIGINAL: Ancien style gardé pour compatibilité. Il hérite deDEFAULT
Il est recommandé d'installer votre répertoire contenant vos règles de styles
dans le répertoire STYLE afin que votre style puisse être surchargé par des
règles globales.
17.1.2.1 Définition des règles par défaut
Les règles par défaut sont celles décrites dans le style DEFAULT.
17.1.2.1.1 Règles interfaces initiales
Les interfaces standards de dynacase utilisent les css suivantes :
- 'dcp/main.css'
-
Cette css est utilisée dans la plupart des interfaces documentaires de haut niveau fournies par le module dynacase-core.
Elle est utilisée pour les interfaces web de documents (consultation et modification) et pour les listes de documents.Elle est composée des éléments suivants :
-
core=> "CORE/Layout/core.css", -
fdl=> "FDL/Layout/freedom.css", -
size=> "WHAT/Layout/size-normal.css", -
style=> "STYLE/DEFAULT/Layout/DEFAULT.css"
-
dcp/core.css-
Cette css est utilisée par défaut sur les interfaces si le template utilisé possède la clef
[CSS:REF].
Elle est utilisée sur les interfaces de core d'importation et de gestion des droits.Elle est composée des éléments suivants :
-
core=> "CORE/Layout/core.css", -
size=> "WHAT/Layout/size-normal.css", -
style=> "STYLE/DEFAULT/Layout/DEFAULT.css"
-
- 'dcp/document-view.css'
-
Cette css est utilisée sur les vues standards de consultation des documents. La vue de consultation utilise aussi la css
dcp/main.css.Elle est composée des éléments suivants :
-
document=> "FDL/Layout/document.css"
-
dcp/document-edit.css-
Cette css est utilisée sur les vues standards de modification des documents
Elle est composée des éléments suivants :
-
edit=> "FDL/Layout/editdoc.css", -
autocompletion=> "FDL/Layout/autocompletion.css", -
popup=> "FDL/Layout/popup.css", -
document=> "FDL/Layout/document.css", -
jscalendar=> "jscalendar/Layout/calendar-win2k-2.css"
-
dcp/system.css-
Cette css est utilisée par défaut sur les interfaces si le template utilisé possède la clef
[CSS:REF]. Elle est utilisée sur les anciennes interfaces de core.Elle est composée des éléments suivants :
-
size=> "WHAT/Layout/size-normal.css", -
style=> "STYLE/DEFAULT/Layout/DEFAULT.css"
-
Toutes ces règles utilisent le parser dcpCssTemplateParse.
17.1.2.1.2 Règles interfaces jquery-ui
Le module dynacase-jqueryui-installer ajoute aussi deux autres règles au style
DEFAULT :
dcp/jquery-ui.css-
Cette css est utilisée dans les interfaces utilisant jquery-ui sauf dans l'interface GENERIC_LIST (liste de documents de ONEFAM) qui utilise une autre version de jquery-ui.
Elle est composée des éléments suivants :
-
jqueryui=> "lib/jquery-ui/css/smoothness/jquery-ui.css"
Cette règle n'utilise pas de parser.
-
dcp/images-
Cette règles permet de copier les images utiles à jquery-ui Elle utilise les images suivantes :
-
jqueryimages=> "lib/jquery-ui/css/smoothness/images"
Cette règle utilise le parser
dcpCssCopyDirectory -
17.1.2.1.3 Description du fichier css
Le fichier css de style est utilisable dans les règles.
En l'absence de parser, ce fichier doit être autonome.
Il doit être composé uniquement de règles css valides.
Les url d'accès aux images doivent être définies par rapport à la cible (par
exemple, si la cible est mypath/mycss.css le fichier produit sera placé dans
le répertoire css/mypath/mycss.css).
Si le parser employé est dcpCssTemplateParser alors les variables définies
dans $sty_const et $sty_local seront utilisables.
Voici un exemple de production de css avec le fichier de style suivant :
$sty_const = array( "COLOR_BLACK" => "#000000", "COLOR_WHITE" => "#FFFFFF" ); // style color variable to compute colors // COLOR_A0 -> COLOR_A9 // COLOR_B0 -> COLOR_B9 // COLOR_C0 -> COLOR_C9 $sty_colors = array( "A" => '#4D4D4D', // gray "B" => '#126ab5', //blue "C" => "#cbc11f"// gold ); // local variable for compose style css $sty_local = array( "input-text-normal-color" => "COLOR_BLACK", "input-text-hover-color" => "yellow",
De plus les 10 nuances de couleurs COLOR_A, COLOR_B et COLOR_C peuvent aussi être utilisées.
| COLOR_A0: #4D4D4D | COLOR_A1: #5F5F5F | COLOR_A2: #717171 | COLOR_A3: #828282 | COLOR_A4: #949494 | COLOR_A5: #A6A6A6 | COLOR_A6: #B8B8B8 | COLOR_A7: #CACACA | COLOR_A8: #DBDBDB | COLOR_A9: #EDEDED |
| COLOR_B0: #126AB5 | COLOR_B1: #157BD1 | COLOR_B2: #1D8BE8 | COLOR_B3: #3999EB | COLOR_B4: #55A8EE | COLOR_B5: #72B6F1 | COLOR_B6: #8EC5F4 | COLOR_B7: #AAD3F7 | COLOR_B8: #C6E2F9 | COLOR_B9: #E3F0FC |
| COLOR_C0: #CBC11F | COLOR_C1: #DED328 | COLOR_C2: #E2D83F | COLOR_C3: #E5DD57 | COLOR_C4: #E9E26F | COLOR_C5: #EDE787 | COLOR_C6: #F0EC9F | COLOR_C7: #F4F0B7 | COLOR_C8: #F8F5CF | COLOR_C9: #FBFAE7 |
Pour un fichier css comme décrit ci-dessous :
input : { color: [input-text-normal-color]; background-color: [COLOR_WHITE]; } input:hover : { color: [input-text-hover-color]; background-color: [COLOR_C5]; }
Le fichier css produit sera :
input : { color: #000000; background-color: #ffffff; } input:hover : { color: yellow; background-color: #EDE787; }
17.1.2.1.4 Fichier css avec flag RULE_FLAG_PARSE_ON_RUNTIME
Si la règle utilise le flag Style::RULE_FLAG_PARSE_ON_RUNTIME alors la css
peut aussi utiliser les variables suivantes :
- "ISIE" : vrai si le navigateur est Internet Explorer
- "ISIE6", vrai si le navigateur est une version 6 d'Internet Explorer
- "ISIE7", vrai si le navigateur est une version 7 d'Internet Explorer
- "ISIE8", vrai si le navigateur est une version 8 d'Internet Explorer
- "ISIE9", vrai si le navigateur est une version 9 d'Internet Explorer
- "ISIE10",vrai si le navigateur est une version 10 d'Internet Explorer
- "ISAPPLEWEBKIT": vrai si le navigateur est basé sur Apple Web Kit (Chrome et Safari entre autre)
- "ISSAFARI" : vrai si le navigateur est basé sur Safari
- "ISCHROME" : vrai si le navigateur est basé sur Google Chrome
Ces variables sont basées sur le User-Agent envoyé par le navigateur.
Le fichier css peut avoir des parties conditionnelles :
input : { color: [input-text-normal-color]; background-color: [COLOR_WHITE]; [IF ISIE]padding:10px;[ENDIF ISIE] [IFNOT ISCHROME]margin:10px;[ENDIF ISCHROME] }
Les règles suivantes :
-
dcp/main.css, -
dcp/core.css, -
dcp/document-edit.css, -
dcp/system.css,
utilisent le flag RULE_FLAG_PARSE_ON_RUNTIME.
17.1.2.2 Surcharge de DEFAULT
17.1.2.2.1 Définir son fichier de style avec héritage
Pour surcharger le style DEFAULT il faut dans le fichier de style .sty l'héritage :
MONSTYLE.sty
$sty_inherit = "STYLE/DEFAULT/DEFAULT.sty";
Ensuite il faut créer son fichier MONSTYLE.css qui doit être dans le répertoire
STYLE/MONSTYLE/Layout.
Les règles de surcharge de style sont :
$sty_rules = array( 'css' => array( 'dcp/main.css' => array( "src" => array( "style" => "STYLE/MONSTYLE/Layout/MONSTYLE.css" ) ) , 'dcp/core.css' => array( "src" => array( "style" => "STYLE/MONSTYLE/Layout/MONSTYLE.css" ) ) , 'dcp/document-edit.css' => array( "src" => array( "jscalendar" => "STYLE/MONSTYLE/Layout/calendar.css" ) ) , 'dcp/system.css' => array( "src" => array( "style" => "STYLE/MONSTYLE/Layout/MONSTYLE.css" ) ) ) );
L'exemple remplace le fichier DEFAULT.css par MONSTYLE.css en réutilisant
l'index style des sources. Il remplace aussi la css du calendrier utilisé
dans la modification de documents.
Il est aussi possible d'ajouter et non de remplacer des éléments de css :
$sty_desc = array( "name" => "SKYBLUE", //Name "description" => N_("Blue Style") , //long description ); $sty_inherit = "STYLE/MODERN/MODERN.sty"; $sty_rules = array( 'css' => array( 'dcp/jquery-ui.css' => array( "src" => array( "blue"=>"STYLE/SKYBLUE/Layout/jquery-blue.css" ) ) , 'dcp/main.css' => array( "src" => array( "blue"=>"STYLE/SKYBLUE/Layout/main-blue.css" ) ) ) );
Cette exemple reprend le style MODERN (fourni par dynacase-core) qui hérite
lui-même de DEFAULT. Dans ce dernier exemple la règle dcp/jquery-ui.css
sera composée de :
-
jqueryui=> "lib/jquery-ui/css/smoothness/jquery-ui.css" -
blue=>"STYLE/SKYBLUE/Layout/jquery-blue.css"
17.1.3 Créer un nouveau style sans héritage
Pour créer un style sans héritage il est nécessaire de déclarer l'ensemble des règles nécessaires aux différentes interfaces :
- dcp/core.css
- dcp/document-edit.css
- dcp/document-view.css
- dcp/jquery-ui.css
- dcp/main.css
- dcp/system.css
17.1.4 Surcharger les templates
Au delà des css, le style peut aussi surcharger les templates des interfaces
des actions de Dynacase. Les templates doivent se trouver dans le répertoire
Layout du style.
Par exemple, l'interface de connexion utilise l'action AUTHENT:LOGINFORM.
Cette action utilise le template AUTHENT/Layout/loginform.xml. Si le style
MONSTYLE publie le fichier STYLE/MONSTYLE/Layout/loginform.xml alors
l'action AUTHENT:LOGINFORM utilisera le template du style pour l'interface de
connexion si le style MONSTYLE est installé.
17.1.5 Surcharger les images
De même, les images peuvent être surchargées. Pour cela il faut publier des
images de même nom dans le répertoire Images du style.
Par exemple la famille Groupe d'utilisateurs utilise l'image igroup.png
comme icone. Si le style MONSTYLE publie l'image
STYLE/MONSTYLE/Images/igroup.png, alors l'icone de la famille sera changée.
La surcharge d'image ne fonctionne que si les templates ont utilisé la balise
[IMG] ou la méthode Action::getImageUrl().
Attention : Le cache du navigateur peut conserver les anciennes images.
17.1.6 Installer un style
Une fois l'arborescence de fichiers installée sur le serveur, il faut utiliser
la commande setStyle depuis la console.
$ ./wsh.php --api=setStyle --style=./STYLE/MONSTYLE/MONSTYLE.sty
Cette commande permet d'appliquer les règles définies dans le style. Les
fichiers css sont alors produits dans le répertoire css à la racine du
répertoire d'installation.
L'option --verbose=yes permet de voir quelles sont les règles prises en compte.
Si le paramètre style n'est pas indiqué, alors la commande setStyle va
régénérer les fichiers composants le style courant.
17.2 Internationalisation
Ce chapitre indique comment utiliser des textes localisés dans vos applications et dans toutes les interfaces homme-machine.
La processus d'internationalisation se déroule en plusieurs étapes :
- extraction des éléments à traduire et production d'un catalogue par langue cible,
- traduction des éléments,
- publication des catalogues dans le contexte.
Une fois ces étapes suivies, les traductions se font dans vos programmes.
17.2.1 Description du principe de traduction
Les traductions utilisent la bibliothèque getText qui est un standard pour la gestion des programmes multilingues.
Lors de l'initialisation d'une action ou d'un script, le
catalogue correspondant à la langue de l'utilisateur est chargé. La langue de
l'utilisateur est choisie lors de sa connexion sur l'écran d'identification. Ce
choix de langue est stockée dans le paramètre applicatif CORE_LANG. Ce
paramètre est modifié à chaque nouvelle connexion de l'utilisateur.
Le catalogue qui est utilisé contient tous les textes traduits de tous les modules installés. Il est dont important d'avoir des textes qui ne sont pas déjà utilisés par un autre module pour éviter d'écraser les traductions d'un autre module, ce qui pourrait dégrader la traduction de ce module.
17.2.2 Utiliser une traduction
Les traductions peuvent être utilisées partout dans une application dynacase.
17.2.2.1 Utiliser une traduction dans un programme PHP
17.2.2.1.1 Utiliser une forme simple
La fonction fournie en standard par PHP et la fonction gettext. Cette fonction permet de rechercher dans un catalogue la traduction correspondante au texte donné en paramètre.
// texte simple print gettext("This is a text"); // texte avec une partie variable printf(gettext("An error : [%s]"), $errorText);
Note : La fonction _ de PHP est un alias de gettext.
// écriture plus lisible en utilisant l'alias. print _("This is a text"); printf(_("An error : [%s]"), $errorText);
Attention : La fonction gettext doit avoir comme argument un texte non vide.
Si le texte est une chaîne vide alors c'est la description du catalogue qui est
retournée.
Le texte à traduire est généralement écrit en anglais (ASCII) et ne comporte pas de caractère accentué. Ceci permet d'éviter les problème d'encodage lors de la génération du catalogue. Il est cependant possible de mettre des textes à traduire avec des accents (voir chapitre suivant).
Dans l'exemple précédent, le texte est très commun et il peut être défini dans un autre module avec une traduction différente.
Deux possibilités permettent de diminuer ce risque de doublon :
-
Utiliser un préfixe :
print _("MyCatalog:This is a text");
-
Utiliser un contexte : 3.2.12
print ___("This is a text", "MyContext");
La différence entre le préfixe et le contexte est que le contexte est explicitement indiqué dans le catalogue tandis que le préfixe est pris comme un texte simple.
La fonction ___ (triple blancs soulignés) est un alias de la fonction
pgettext. Si le contexte est vide, cela est équivalent à l'utilisation de la
fonction _ standard.
Ces fonctions ne sont pas natives de PHP, elles sont ajoutées par Dynacase.
17.2.2.1.2 Utiliser une forme plurielle
3.2.12 Les traductions des formes plurielles sont prises en compte par la bibliothèque gettext.
La forme plurielle est indiquée à l'aide la fonction php standard
ngettext ou de la fonction npgettext et son alias n___ qui
gèrent aussi les contextes.
printf(n___("%d document found", "%d documents found", $num, "MyContext") , $num);
| langue | $num | texte traduit | forme |
|---|---|---|---|
| fr | 0 | 0 document trouvé | singulier |
| fr | 1 | 1 document trouvé | singulier |
| fr | 2 | 2 documents trouvés | pluriel |
| fr | 345 | 345 documents trouvés | pluriel |
| en | 0 | 0 documents found | pluriel |
| en | 1 | 1 document found | singulier |
| en | 2 | 2 documents found | pluriel |
| en | 345 | 345 documents founds | pluriel |
Limitations : La localisation des formes plurielles fonctionne de manière partielle avec les nombres décimaux. En effet, la variable numérique de choix de la traduction doit être un entier. Pour un nombre décimal, seule la partie entière est prise en compte. Ainsi les nombres 1,3 et 1,6 seront pris comme 1. Cela sera correct pour le français qui considère que tout nombre compris entre ]-2, 2[ comme singulier. Mais cela sera incorrect en anglais qui considère que tout nombre différent de 1 ou -1 n'est pas singulier.
17.2.2.2 Utiliser une traduction dans un template
Dans les templates, des textes simples (sans variable) peuvent faire l'objet de traduction.
<h1>[TEXT:Welcome to my page]</h1> <p><label for="myInput">[TEXT:My Label]</label><input id="myInput"/></p>
Les textes indiqués par la syntaxe [TEXT:<clef de traduction>] sont remplacés
par la traduction issue du même catalogue que les textes traduits en PHP. Si la
traduction n'est pas trouvée dans le catalogue, le texte initial est affiché
(sans le '[TEXT:]').
Comme pour les traductions en PHP, il est possible d'utiliser une clef de contexte pour démarquer sa traduction.3.2.12
<h1>[TEXT(my Context):Welcome to my page]</h1> <p><label for="myInput">[TEXT(my Context):My Label]</label><input id="myInput"/></p>
Le contexte doit être écrit entre parenthèses juste après la clef TEXT.
Cette notation est aussi utilisable dans les templates ODT.
17.2.2.3 Traduction des cycles de vies
Les éléments états, transition et activités des [cycles de vie][workflow] sont traduisibles : dynacase recherche automatiquement une traduction correspondant à l'identifiant des états, transition et activités lorsqu'ils sont affichés.
Afin que ces éléments soient traduits, il faut donc vous assurer que des entrées correspondantes soient ajoutées à votre catalogue
17.2.2.4 Utiliser une traduction dans un programme JavaScript
Dynacase core ne fournit pas de fonction Javascript permettant de traduire du texte. Cependant, il est possible d'utiliser la fonction fournie par le module dynacase-datajs, ou d'utiliser les fonctions décrites ci-dessous
17.2.2.4.1 Utilisation de dynacase-datajs
Le module dynacase-datajs fournit une bibliothèque JavaScript permettant d'utiliser des traductions.
// Initialisation du contexte var C=new Fdl.Context({url:'http://www.mydomain.server/'}); if (! C.isConnected()) { alert('error connect:'+C.getLastErrorMessage()); return; } // Authentification if (! C.isAuthenticated()) { var u=C.setAuthentification({login:'mylogin',password:'secret'}); if (!u) alert('error authent:'+C.getLastErrorMessage()); } // C is the context var helloText=C._("my test is ok");
La méthode Fdl.Context::_() retourne la traduction comme pour la fonction _
équivalente de PHP.
La langue choisie est celle de l'utilisateur (paramètre applicatif CORE_LANG).
La récupération du catalogue est une opération JavaScript qui fait un appel Ajax synchrone au serveur, elle bloque donc l'exécution du JavaScript le temps de la récupération des traductions.
17.2.2.4.2 Fonctions de traduction
La fonction suivante peut être utilisée pour créer un translator à partir d'un catalogue :
function translatorFactory(catalog) { var translation = {data: {catalog: {}}}; try { translation = JSON.parse(catalog); } catch (e) { console.error("Locale catalog error : " + e.message); } return { /** * Return key translation * @param text to translate * @returns string */ _: function translator_gettext(key) { if (key && translation.data && translation.data.catalog && translation.data.catalog[key]) { return ranslation.data.catalog[key]; } return key; }, /** * Return key translation in context * @param text to translate * @param context * @returns {*} */ ___: function translator_pgettext(key, ctxt) { if (key && translation.data && translation.data.catalog && translation.data.catalog._msgctxt_ && translation.data.catalog._msgctxt_[ctxt] && translation.data.catalog._msgctxt_[ctxt][key]) { return translation.data.catalog._msgctxt_[ctxt][key]; } return key; } }; }
Le paramètre catalog correspond à un catalogue au format JSON.
Ce catalogue est généré sur le serveur avec le path suivant :
locale/<locale>/js/catalog.js
par exemple :
locale/fr/js/catalog.js
Elle s'utilise de la manière suivante (le catalogue peut être récupéré autrement) :
var translator, translatedText; $.getJSON("locale/fr/js/catalog.js", function (catalog) { translator = getTranslator(catalog); translatedText = translator.___("key", "context"); });
17.2.2.4.2.1 Limitation
Les formes plurielles ne sont pas prises en compte.
17.2.3 Générer et mettre à jour les entrées du catalogue
Le catalogue doit contenir des entrées pour toutes les clés à traduire. Ces clés peuvent se trouver dans eds fichiers php, js, des templates, ainsi qu'à de nombreux autres endroits. Ce chapitre décrit comment extraire toutes les chaînes à traduire, et produire le catalogue correspondant.
Dynacase requiert 2 catalogues par application :
- Un catalogue pour la partie php.
Il contient
- les traductions des fichiers php
- les traductions des workflows
- les traductions des familles de documents
- les traductions des contrôles de vue
- les traductions des templates
- Un catalogue pour la partie javascript.
Il contient
- les traductions des fichiers javascript
Plus de détails sur ces catalogues et leur déploiement peuvent être trouvés dans la partie Publication
17.2.3.1 Utilisation des devtools pour générer l'ensemble des catalogues
Il est possible de générer les catalogues par le programme [dynacase-devtool.phar][devtoolphar].
php dynacase-devtool.phar extractPo -s .
Voir le Quick Start pour plus d'information.
17.2.3.2 Génération manuelle
La génération du catalogue se fait en 2 étapes :
- extraction des clés de traduction depuis les sources (génère un fichier
*.pot) - mise à jour des fichiers
*.poà partir du fichier*.pot
Les chapitres suivants détaillent comment extraire les clés de traduction à partir des sources.
La mise à jour des fichiers *.po relève de l'utilisation de gettext
et n'est pas couverte par cette documentation.
17.2.3.2.1 Extraction des clés pour les fichiers PHP
La génération des catalogues est effectuée traditionnellement par le programme [xgettext][xgettext].
xgettext --language=PHP \
--keyword=___:1 \
--keyword=___:1,2c \
--keyword=n___:1,2 \
--keyword=pgettext:1,2 \
--keyword=n___:1,2,4c \
--keyword=npgettext:1,2,4c \
--keyword='N_' \
--keyword='text' \
--keyword='Text' \
--from-code=utf-8 \
--output=myCatalog.pot \
myFile1.php myFile2.php ...
Cette fonction produit un catalogue de traduction temporaire permettant de servir de base pour réaliser les traductions.
17.2.3.2.1.1 Utilisation de xgettextPhp
Le programme xgettextPhp permet de réaliser la même fonction et récupère en
plus les libellés des [fonctions de recherche][searchLabel].
3.2.12
./buildTools/xgettextPhp --output=myCatalog.pot myFile1.php myFile2.php myCatalog.pot wrote.
Les options de xgettext sont utilisables pour modifier le fichier produit.
./buildtools/xgettextPhp --omit-header --add-location -o myLayouts.pot test.html
Il est possible de déclarer les fichiers d'entrées via le pipe.
find . -name "*php" | ../buildtools/xgettextPhp --output myCatalog.pot -f-
17.2.3.2.2 Extraction des clés pour les workflows
Afin que les clés de traduction soient présentes dans le catalogue de traduction, il est nécessaire de les identifier. Une des solutions consiste à ajouter une fonction factice qui sert à identifier les éléments à traduire.
17.2.3.2.2.1 Exemple
namespace MyTest; class WflTest extends \Dcp\Family\WDoc { public $attrPrefix = "TST"; public $firstState = self::etat_created; //region States const etat_created = "myapp_tst_e1"; const etat_redacted = "myapp_tst_e2"; //endregion //region Transitions const transition_created_redacted = "myapp_tst_t1"; const transition_redacted_created = "myapp_tst_t2"; //endregion // Activities public $stateactivity = array( self::etat_created => "tst:activity:etat_created", self::etat_redacted => "tst:activity:etat_redacted", );
Les clefs des états et des transitions sont leurs identifiants. Il est nécessaire d'identifier ces clefs de traduction pour le programme de génération de catalogue.
private function i18n () { $i18n=_("myapp_tst_e1"); // states $i18n=_("myapp_tst_e2"); $i18n=_("myapp_tst_t1"); // transitions $i18n=_("myapp_tst_t2"); $i18n=_("tst:activity:etat_created"); // activities $i18n=_("tst:activity:etat_redacted"); }
Cette fonction peut être soit une fonction privée du cycle de vie, soit être présente dans un autre fichier qui n'est pas déployé.
17.2.3.2.3 Extraction des clés pour les familles de document
La description de la structure de famille est définie dans une fichier CSV ou ODS. Ce fichier est utilisable pour produire un catalogue de traduction.
Exemple : TestSimple.ods
| BEGIN | Test simple | TST_SIMPLE | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| idattr | idframe | label | T | A | type | ord | vis | need | link | phpfile | phpfunc | |
| ATTR | TST_FR_HTML | Identification | N | N | frame | 100 | W | |||||
| ATTR | TST_TITLE | TST_FR_HTML | Titre | Y | N | text | 110 | W | Y | |||
| ATTR | TST_SIZE | TST_FR_HTML | Taille | N | N | enum | 120 | W | XL| Very large,L | Large,M |Medium,S |
Le programme xgettextFamily permet d'extraire les clefs de traduction depuis un
ou plusieurs fichiers de description de famille (CSV ou ODS).
3.2.12
./buildTools/xgettextFamily -o / TestSimple.ods myLocaleDirectory/TST_SIMPLE.pot wrote.
produit le fichier locale/TST_SIMPLE.pot. L'identifiant de la famille sert
pour le nom du fichier et pour les clefs de traduction.
L'option de sortie -o doit renseigner un répertoire accessible en écriture.
La production du fichier temporaire sert pour construire les catalogues dans les langues voulues.
Il est possible de déclarer les fichiers d'entrées via le pipe.
find . -name "family*.csv" | ../buildtools/xgettextFamily -o myLocaleDirectory -f-
Cela produit un fichier .pot par famille.
Les options de xgettext ne sont pas utilisables pour modifier le fichier produit.
Extrait du fichier généré "TST_SIMPLE.pot" avec la famille décrite ci-dessus :
msgid "" msgstr "" "Project-Id-Version: TST_SIMPLE \n" "Report-Msgid-Bugs-To: \n" "PO-Revision-Date: 2013-10-25T14:59:04+02:00\n" "Last-Translator: Automatically generated\n" "Language-Team: none\n" "MIME-Version: 1.0\n" "Content-Type: text/plain; charset=UTF-8\n" "Content-Transfer-Encoding: 8bit\n" "Language: \n" #, fuzzy, (TestSimple.ods.csv) msgid "TST_SIMPLE#title" msgstr "Test simple" #: TestSimple.ods.csv #, fuzzy, (TestSimple.ods.csv) msgid "TST_SIMPLE#tst_fr_html" msgstr "Cadre 1" #: TestSimple.ods.csv #, fuzzy, (TestSimple.ods.csv) msgid "TST_SIMPLE#tst_title" msgstr "Titre" #: TestSimple.ods.csv #, fuzzy, (TestSimple.ods.csv) msgid "TST_SIMPLE#tst_size" msgstr "Taille" #, fuzzy, (TestSimple.ods.csv) msgid "TST_SIMPLE#tst_size#XL" msgstr "Very large" ...
Les clefs suivantes sont générée :
FAMNAME#title- Titre de la famille FAMNAME
FAMNAME#<attrid>- Libellé de l'attribut
<attrid>de la famille FAMNAME FAMNAME#<attrid>#ENUMVALUE- Libellé de la valeur ENUMVALUE de l'énuméré
<attrid>de la famille FAMNAME. Note : Les traductions des énumérés peuvent être modifiées par l'administrateur depuis l'interface du centre d'administration. Les traductions des énumérés faite par l'interface sont toujours prioritaires aux traductions faites dans les catalogues livrés par le module. FAMNAME#<attrid>#OPTIONKEY- Traduction des valeurs de certaines options d'attributs sensibles à la localisation. Les options prises en compte sont : "elabel", "ititle", "submenu", "ltitle", "eltitle", "elsymbol", "lsymbol", "showempty".
17.2.3.2.4 Extraction des clés pour les contrôles de vues
Les libellés des vues des contrôles de vues peuvent être traduits.
Le programme xgettextFamily permet d'extraire les clefs de traduction depuis un
fichier de description de contrôle de vue.3.2.12
./buildTools/xgettextFamily -o myLocaleDirectory someCVDoc.csv myLocaleDirectory/MYCV.pot wrote
Les options de xgettext ne sont pas utilisables pour modifier le fichier
produit.
L'option de sortie -o doit renseigner un répertoire accessible en écriture.
Le fichier de sortie produit est le nom logique du document de contrôle de vue.
Exemple de fichier de traduction produits :
msgid "" msgstr "" "Project-Id-Version: CV_IUSER_ACCOUNT \n" "Report-Msgid-Bugs-To: \n" "PO-Revision-Date: 2013-10-25T16:08:15+02:00\n" "Last-Translator: Automatically generated\n" "Language-Team: none\n" "MIME-Version: 1.0\n" "Content-Type: text/plain; charset=UTF-8\n" "Content-Transfer-Encoding: 8bit\n" "Language: \n" #: App/Fusers/accountprofil.ods.csv #, fuzzy msgid "CV_IUSER_ACCOUNT#label#EUSER" msgstr "Admin edit" #: App/Fusers/accountprofil.ods.csv #, fuzzy msgid "CV_IUSER_ACCOUNT#label#EGROUP" msgstr "Groupes" #: App/Fusers/accountprofil.ods.csv #, fuzzy msgid "CV_IUSER_ACCOUNT#menu#EGROUP" msgstr "Compte" #: App/Fusers/accountprofil.ods.csv #, fuzzy msgid "CV_IUSER_ACCOUNT#label#ESUBSTITUTE" msgstr "Modifier le suppléant" #: App/Fusers/accountprofil.ods.csv #, fuzzy msgid "CV_IUSER_ACCOUNT#menu#ESUBSTITUTE" msgstr "Compte"
Les clefs suivantes sont générées :
CVNAME#label#IDVUE- Libellé de la vue IDVUE du contrôle de vue CVNAME
CVNAME#menu#IDVUE- Libellé du menu de la vue IDVUE du contrôle de vue CVNAME
17.2.3.2.5 Extraction des clés pour les templates
Le programme xgettextLayout permet d'extraire les clefs de
traduction depuis des fichier de template texte et openDocument Text.3.2.12
./buildTools/xgettextLayout -o myLayouts.pot file1.html file2.xml file3.js file4.odt ...
Les clefs '[TEXT:...]' sont extraites et indiquées dans le fichier .pot produit.
De même les clefs avec contexte |TEXT(ctx):... ] sont aussi extraites avec leur
contexte.
Les options de xgettext sont utilisables pour modifier le fichier produit.
./buildtools/xgettextLayout --omit-header -o myLayouts.pot test.html
Il est possible de déclarer les fichiers d'entrées via le pipe.
find . -name "*xml" | ../buildtools/xgettextLayout -o myLayouts.pot -f-
17.2.3.2.6 Extraction des clés pour les fichiers javascript
La génération des catalogues est effectuée traditionnellement par le programme [xgettext][xgettext].
xgettext --language=JavaScript \
--sort-output \
--from-code=utf-8 \
--no-location \
--indent \
--add-comments=_COMMENT \
--keyword=___:1 \
--keyword=___:1,2c \
--keyword=n___:1,2 \
--keyword=pgettext:1c,2 \
--keyword=n___:1,2,4c \
--keyword=npgettext:1,2,4c \
--keyword="N_" \
--keyword="text" \
--keyword="Text" \
myFile1.js myFile2.js ...
Cette fonction produit un catalogue de traduction temporaire permettant de servir de base pour réaliser les traductions.
17.2.3.2.6.1 Utilisation de xgettextJs
Le programme xgettextJs permet générer le catalogue temporaire.
3.2.12
./buildTools/xgettextJs --output=myCatalog.pot myFile1.js myFile2.js myCatalog.pot wrote.
La nouvelle version de xgettextJs permet aussi d'extraire les
formes avec contexte.3.2.19
17.2.4 Publier et mettre à jour les catalogues
Les catalogues doivent être déposés dans des sous-répertoires de
locale/<lang>/
Le répertoire <lang> est l'identifiant de la locale sur deux lettres :
-
fr: français -
en: anglais - …
17.2.4.1 Catalogues php
Les catalogues sources (.po) doivent être publiés sur le serveur dans le
répertoire :3.2.12
locale/<lang>/LC_MESSAGES/src/
Les catalogues binaires (.mo) doivent être publiés sur le serveur dans le
répertoire :
locale/<lang>/LC_MESSAGES/
Les catalogues sources sont prioritaires aux catalogues binaires. Cela implique que s'il y a des clefs dupliquées, c'est la traduction des fichiers sources qui est utilisée.
17.2.4.2 Catalogues javascript
Les catalogues sources (.po) doivent être publiés sur le serveur dans le
répertoire :
locale/<lang>/js/src/
Les catalogues binaires (.mo) doivent être publiés sur le serveur dans le
répertoire :
locale/<lang>/js/
Les catalogues sources sont prioritaires aux catalogues binaires. Cela implique que s'il y a des clefs dupliquées c'est la traduction des fichiers sources qui sera utilisée.
17.2.4.2.1 Catalogues javascript au format JSON
Lors de la publication, ces fichiers .po servent d'entrées pour la production
du catalogue JSON en utilisant le programme programs/po2js.
Le fichier JSON correspondant est un objet où les clefs de traduction sont les index.
Exemple :
{
"Hello" : "Bonjour",
"The world" : "Le monde"
}
3.2.19 Les traductions avec contexte sont
présentes dans le fichiers catalogue sous l'index _msgctxt_. Cet index contient
des sous-index par contexte.
Exemple : le catalogue correspondant au code javascript suivant :
var message=_("Hello")+_("World"); var other=___("Hello","myFirstContext")+___("Today","myFirstContext"); var alternative=___("Hello","mySecondContext")+___("Clear","mySecondContext");
est :
{
"Hello" : "Bonjour",
"The world" : "Le monde"
"_msgctxt_" : {
"myFirstContext" : {
"Hello" : "Salut"
"Today" : "Aujourd'hui"
},
"mySecondContext" : {
"Hello" : "Bienvenue à tous"
"Clear" : "Temps clair"
}
}
}
17.2.4.3 Prise en compte des nouveaux catalogues
Pour prendre en compte les nouvelles traductions, il faut lancer le programme :
$ ./whattext
sur le serveur depuis le répertoire d'installation.
Ce programme fusionne l'ensemble des catalogues dans un catalogue principal. C'est ce catalogue qui est chargé lors de l'exécution des actions et scripts Dynacase.
Ce programme va également générer les catalogues au format JSON en utilisant le programme programs/po2js.
Ce sont ces catalogues qui sont utilisables dans le code javascript.
17.2.4.4 Header
Lors de la génération du catalogue principal, c'est l'entête utilisée
dans le fichier header.po qui défini l'entête et donc la forme plurielle
utilisée.
Ce fichier définit notamment les formes plurielles au moyen de l'entête Plural-Forms
msgid "" msgstr "" "Project-Id-Version: Test 1.0\n" "POT-Creation-Date: 2013-10-24 17:28+0200\n" "PO-Revision-Date: 2013-10-25 08:53+0200\n" "Last-Translator: FULL NAME <EMAIL@ADDRESS>\n" "Language-Team: LANGUAGE <LL@li.org>\n" "Language: French\n" "MIME-Version: 1.0\n" "Content-Type: text/plain; charset=UTF-8\n" "Content-Transfer-Encoding: 8bit\n" "Plural-Forms: nplurals=2; plural=n>1;\n"
Pour un même langage, la définition des formes plurielles de tous les catalogues doivent être identique. Un catalogue français ne peut donc avoir deux plurielles alors qu'un autre en défini trois.
Pour le français la définition de la forme plurielle doit être :
"Plural-Forms: nplurals=2; plural=n>1;\n"
Pour l'anglais la définition de la forme plurielle doit être :
"Plural-Forms: nplurals=2; plural=n != 1;\n"
17.2.4.5 Remarques
Note : les catalogues binaires peuvent être obtenus par le programme msgfmt et
inversement les catalogues sources peuvent être obtenus par le programme
msgunfmt.
17.2.5 Modifier la langue dans un programme
Par défaut, le catalogue correspondant à la locale de l'utilisateur connecté est
chargé. Il est possible de changer le catalogue en cours d'exécution en
utilisant la fonction setLanguage.
setLanguage('fr_FR'); print ___("Hello", "tstCtx"); // => Bonjour à tous setLanguage('en_US'); print ___("Hello", "tstCtx"); // => Hello everybody
Le paramètre doit être la locale complète sur cinq lettres.
17.2.6 Ajouter une nouvelle langue
Pour disposer d'une nouvelle langue, il faut
- Ajouter un répertoire
locale/<lang>, - ajouter le fichier
locale/<lang>/lang.phpde définition de langue, - ajouter un répertoire
locale/<lang>/LC_MESSAGES, - ajouter le fichier
locale/<lang>/LC_MESSAGES/header.mo(définissant notamment les formes plurielles) - vous assurer que la locale existe sur le serveur
17.2.6.1 Exemple : ajout de l'espagnol
17.2.6.1.1 Fichier locale/es/lang.php
$lang["es_ES"] = array( "label" => "Espagnol", // le label non traduit "localeLabel" => _("Spanish"), // le label traduit "flag" => "es_ES.png", // le nom du fichier de drapeau de la locale "locale" => "es", // le code ISO 639-1 de la locale "dateFormat" => "%d/%m/%Y", // le format de date utilisable par strftime "dateTimeFormat" => "%d/%m/%Y %H:%M", // le format de datetime utilisable par strftime "timeFormat" => "%H:%M:%S", // le format d'heure utilisable par strftime "culture" => "es-ES" // le code RFC 3066 de la locale ); /* ** Include local/override config ** ----------------------------- */ $local_lang = dirname(__FILE__) . DIRECTORY_SEPARATOR . 'local-lang.php'; if (file_exists($local_lang)) { include ($local_lang); }
17.2.6.1.2 Fichier locale/es/LC_MESSAGES/header.mo
Il résulte de la compilation par msgfmt du fichier po suivant :
msgid "" msgstr "" "Project-Id-Version: Dynacase\n" "Report-Msgid-Bugs-To: \n" "PO-Revision-Date: 2013-10-28 08:59+0100\n" "Language: es\n" "Language-Team: Spanish team\n" "MIME-Version: 1.0\n" "Content-Type: text/plain; charset=UTF-8\n" "Content-Transfer-Encoding: 8bit\n" "Plural-Forms: nplurals=2; plural=(n > 1);\n"
17.3 Cinématique de dynacase
Ce chapitre présente l'enchaînement des principales phases qui sont exécutées lors d'une requête au serveur Dynacase.
17.3.1 Cinématique de la requête d'une action
L'accès à Dynacase est fait soit via index.php (par défaut), soit via
guest.php.
17.3.1.1 Accès par index.php
L'accès par index.php (accès par défaut) permet de se connecter avec un
compte utilisateur.
Si le paramètre $useIndexAsGuest est positionné à true (voir Accès
anonyme (invité)) et que l'utilisateur n'est pas authentifié, alors
l'accès sera autorisé et l'identité forcée à l'utilisateur anonymous.
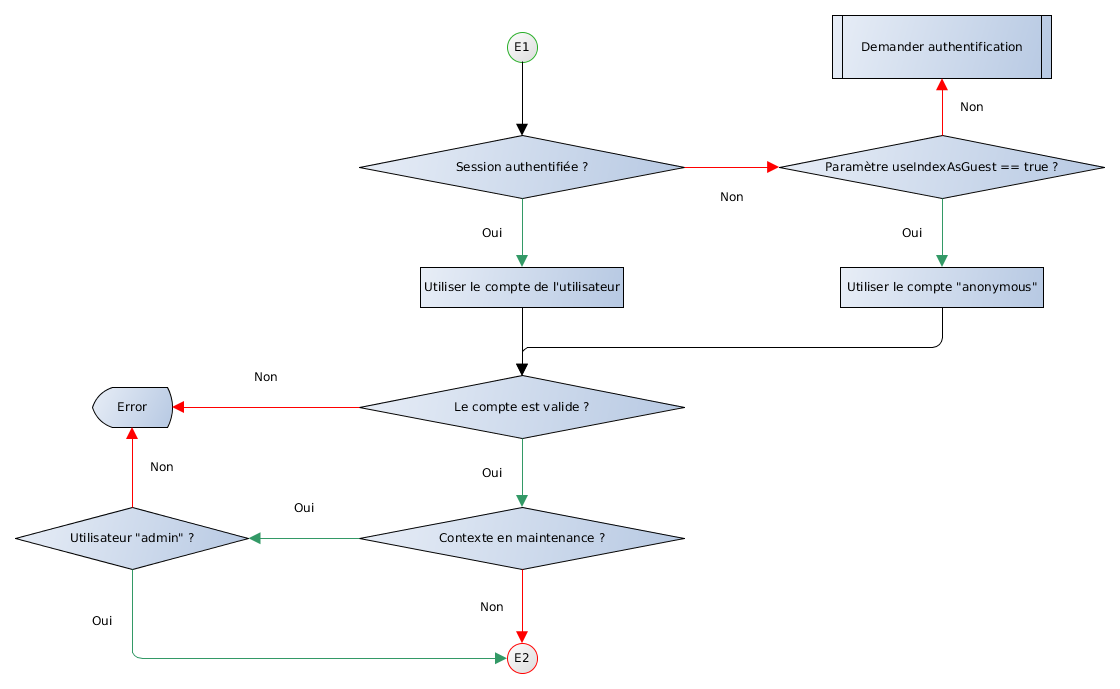
Figure 94. Accès par index.php
17.3.1.2 Accès par guest.php
L'accès par guest.php autorise l'accès et force l'identité à l'utilisateur
anonymous.
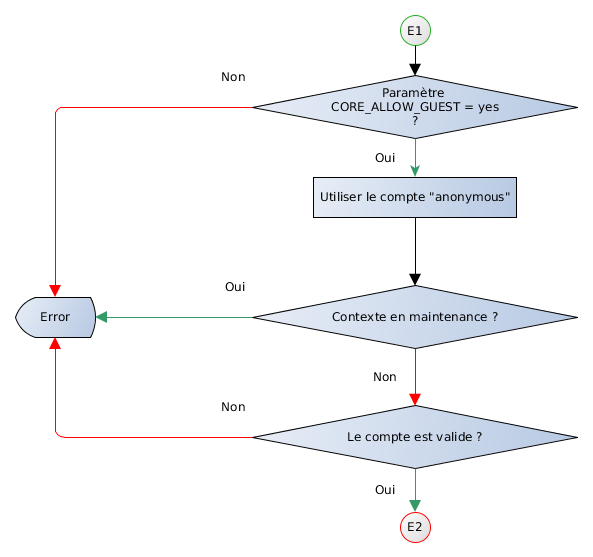
Figure 95. Accès par guest.php
17.3.1.3 Exécution de la requête
Une fois l'identité fixée (anonymous ou compte d'utilisateur), le traitement
de la requête se poursuit pour rechercher l'application et l'action à
exécuter.
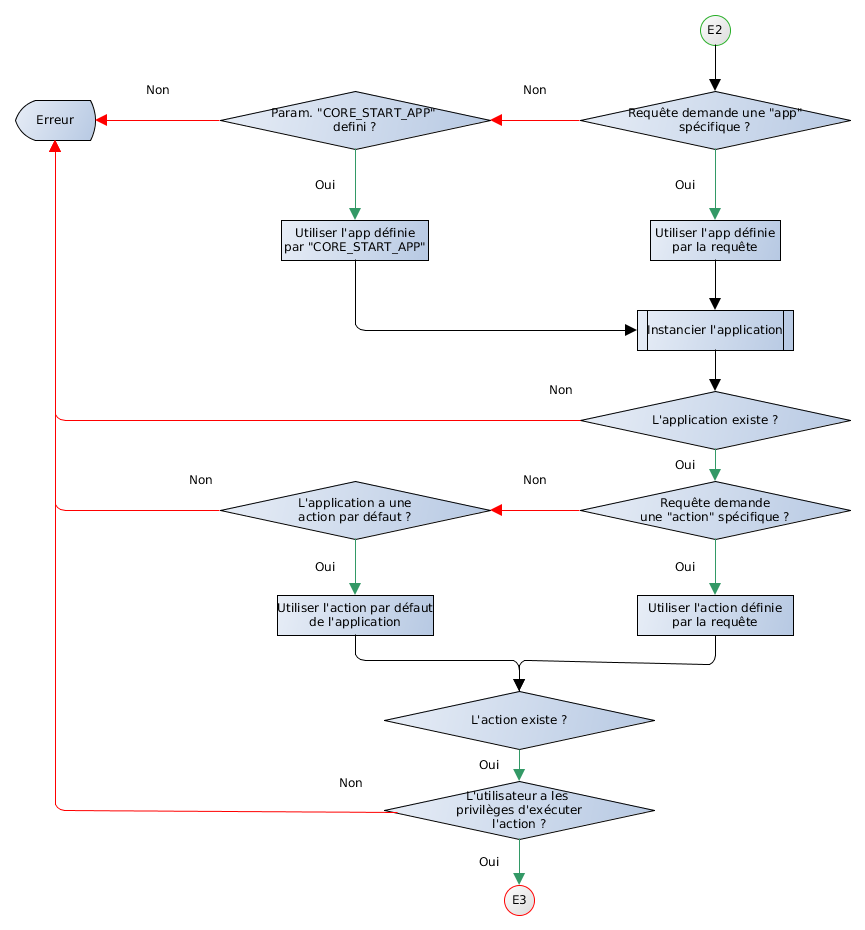
Figure 96. Exécution de la requête
17.3.1.4 Exécution de l'action de la requête
Lorsque l'action de l'application est fixée, l'action est alors exécutée.
L'action contrôle si l'utilisateur a le droit d'exécuter l'action demandée.
Si c'est une action de consultation d'un document (utilisation de
viewcard()), que l'utilisateur est anonymous, et que l'accès au document
n'est pas autorisé (voir profil de documents), alors l'utilisateur est
redirigé vers l'authentification afin de se connecter sous un compte
utilisateur valide (voir Consultation
ci-dessous).
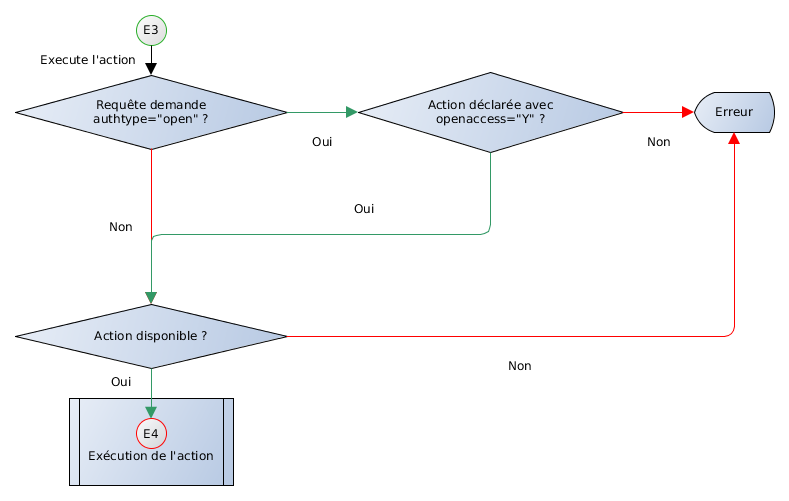
Figure 97. Exécution de l'action de la requête
17.3.2 Cinématique d'une requête d'accès à un document
17.3.2.1 Consultation
La consultation d'un utilise la fonction viewcard().
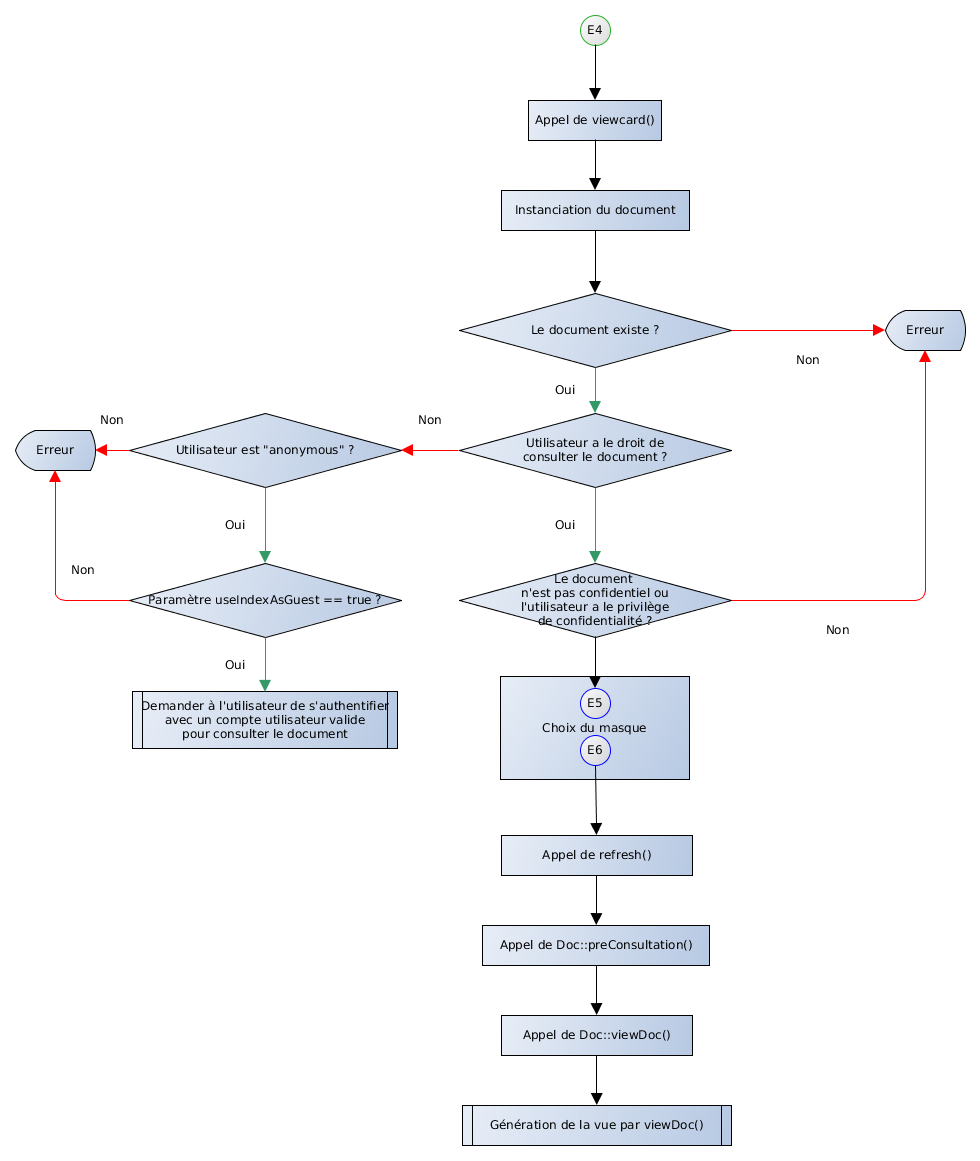
Figure 98. Consultation d'un document
17.3.2.2 Modification
L'affichage du formulaire de création et de modification d'un document utilise
la fonction editcard().
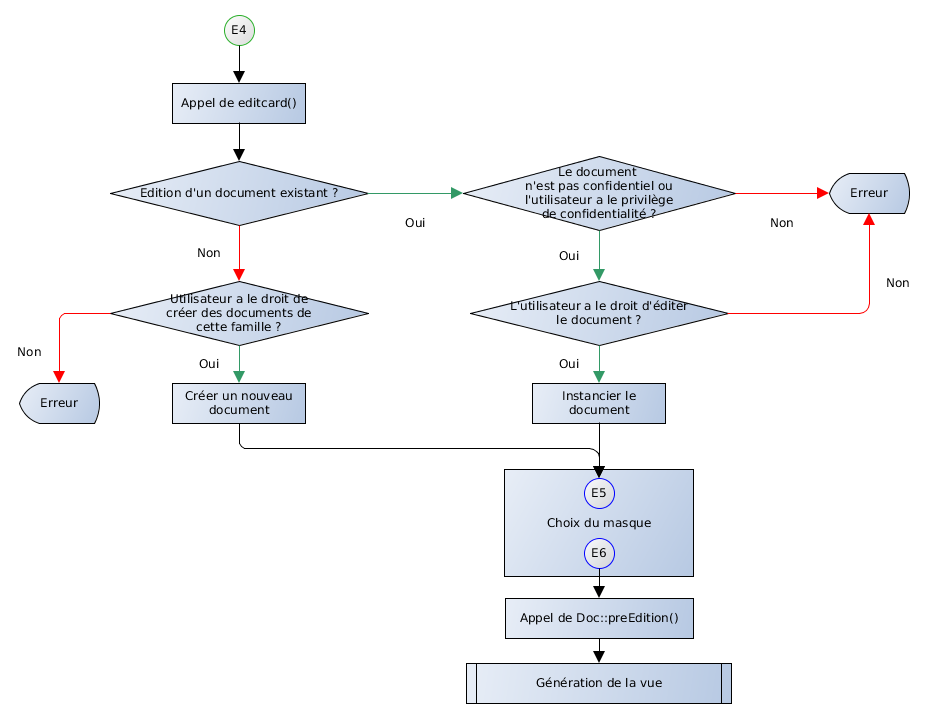
Figure 99. Édition d'un document
17.3.2.3 Détail sur le choix du masque
Le choix du masque à appliquer est fait lors de l'affichage d'un document pour consultation ou modification.
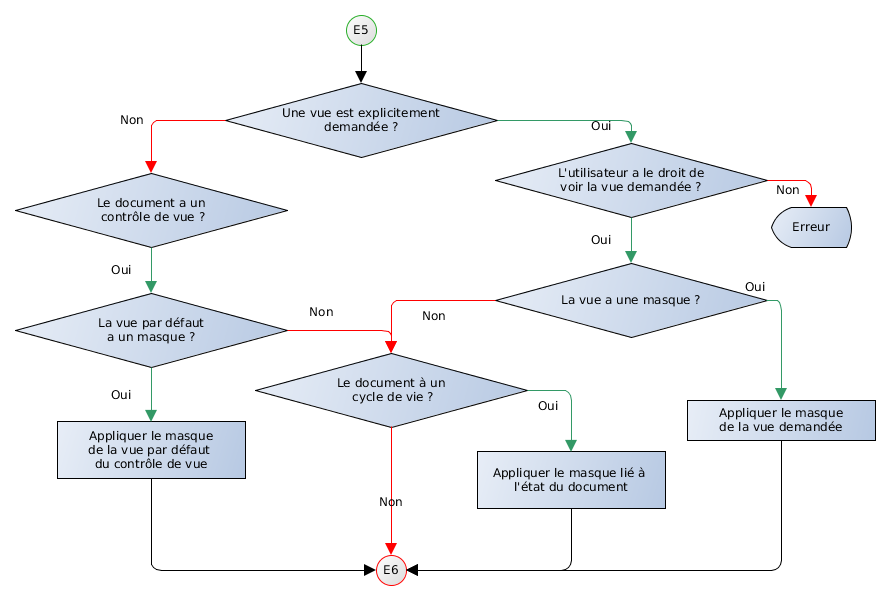
Figure 100. Édition d'un document
17.3.3 Cinématique d'une requête de changement d'état
Le passage d'une transition lorsque le document à un cycle de vie
utilise la fonction modstate().
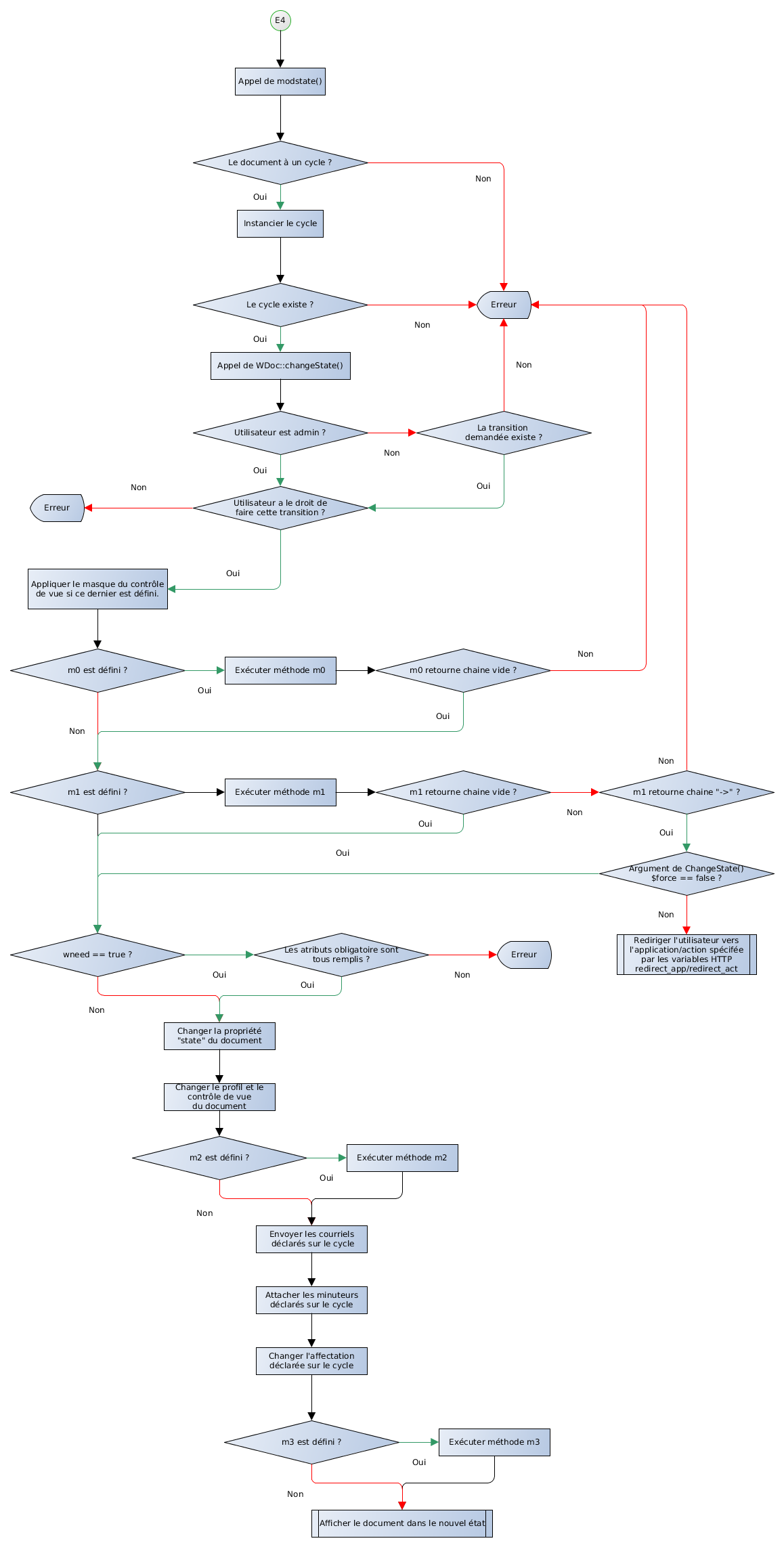
Figure 101. Passage d'une transition d'un document
17.3.4 Cinématique d'un appel CLI (wsh)
L'appel d'un script wsh est effectué en mode console directement sur le serveur sous l'identité du serveur web.
Figure 102. Exécution CLI wsh
17.3.5 Gestion des erreurs et des exceptions
Dynacase a un système permettant de gérer, logger et notifier les exceptions et les erreurs PHP.
Ce système permet d'afficher un message mis en forme à l'utilisateur en cas d'exception et d'enregistrer un contexte le plus précis possible pour aider le développeur à résoudre le problème.
17.3.5.1 Gestion des erreurs
Les erreurs PHP sont interceptées et traitées par la fonction handleFatalShutdown. Celle-ci les présente sous la
forme d'un cadre rouge indiquant une défaillance dans l'exécution de Dynacase. Le log est délégué à PHP.
17.3.5.2 Gestion des exceptions
Les exceptions remontant jusqu'au plus niveau (index.php, guest.php) sont mises en forme et sont logguées ainsi que
leur trace d'exécution dans le fichier de log d'erreur.
17.3.5.3 Fonction de rappel à l'extinction
Si vous déclarez une fonction de rappel pour exécution à l'extinction, à l'aide
de register_shutdown_function(), cette
dernière sera ou non exécutée en fonction des cas suivants :
- Exception
-
Exécution de la fonction rappel : Oui
Lorsqu'une exception est levé et qu'elle est non attrapée, alors votre fonction de rappel est appelée après l'exécution de la fonction de rappel
handleFatalShutdownde Dynacase. - Exit
-
Exécution de la fonction rappel : Oui
Lorsque le script PHP se termine (par appel ou non à la fonction
exit()), la fonction de rappel est appelée. - PHP Fatal error
-
Exécution de la fonction rappel : Oui
Lorsque le script génère une erreur "PHP Fatal" (e.g. "Max execution time exceeded", "Call to undefined function"), la fonction de rappel est appelée.
- Signal
-
Exécution de la fonction rappel : Non
Lorsqu'un signal
SIGINTest reçu par le process, si PHP est dans un syscall (e.g.sleep(),fwrite(), etc.), alors le syscall se termine et retourne une erreur (ou le nombre d'octets écrit pour une fonction commefwrite()). Lors de la réception deSIGTERMetSIGQUIT, le signal est interprété par Apache et la fonction de rappel n'est pas appelée. - Déconnections du client
-
Exécution de la fonction de rappel : Oui (si flush réguliers, sinon exécution en fin de script, voir cas
Exitci-dessus)Par défaut
ignore_user_abortest àOff, et permet donc à PHP de se terminer si le client se déconnecte.Par contre, la prise en compte de la déconnexion ne se fera qu'après que le client ait fait une tentative d'écriture sur le flux de sortie (et que le flux est flushé, sinon la sortie est bufferisée et rien ne se passe non plus).
Si le client n'écrit rien sur le flux de sortie, alors il continue de s'exécuter.
Lorsque le client fait une écriture (
print+ob_flush()+flush()), alors le script se termine et le shutdown handler est exécuté. Dans le shutdown handler on peut alors interrogerconnection_aborted()pour savoir si le client s'est déconnecté ou non).Le
access_loget leerror_logApache ne mentionnent rien tant que le code PHP s'exécute.Quand le code se termine, alors
access_logcontient un "HTTP 200 OK",error_logne mentionne rien.On a donc pas trace de la déconnexion du client sur le serveur si on n'interroge pas
connection_aborted()régulièrement ou dans le shutdown handler.Plusieurs niveaux de bufferisation dans PHP :
print "xxx" | v PHP's userspace output buffer (ob_*) <-- Utiliser ob_flush() | v PHP's system write buffer <-- Utiliser flush() | v Client
17.4 La base de données
Ce chapitre décrit les principales tables utilisées dans la base de données. Il décrit le stockage des documents, des fichiers, des droits, des comptes et des applications.
17.4.1 Accès à la base de données
L'accès à la base donnée est défini à l'aide d'un service Postgresql.
Les coordonnées du service sont obtenues avec la fonction getDbAccess().
$dbAccess = getDbAccess(); printf("Database [%s]\n",$dbAccess);
Résultat :
Database [service='developpement']
L'accès peut être réalisé avec la fonction PHP pg_connect.
$resource = pg_connect($dbAccess); var_dump($resource);
Résultat :
resource(26) of type (pgsql link)
Les classes héritées de DbObj, notamment la classe Doc,
utilisent une abstraction qui permet de gérer l'accès et
l'enregistrement des données en base.
L'accès à la base de données de manière explicite est à réserver pour des besoins spécifiques. La manipulation des documents et autres objets de Dynacase doit être fait à travers leurs classes PHP respectives.
17.4.2 la fonction SimpleQuery
Cette fonction permet d'envoyer une requête sur la base de données.
17.4.2.1 Description
string simpleQuery (string $dbaccess, string $query, array|string|bool &$result = array() , bool $singlecolumn = false, bool $singleresult = false, bool|null $useStrict = null)
Cette fonction permet de récupérer facilement les données directement depuis la base de données.
17.4.2.1.1 Avertissements
La requête est exécutée directement. Il est de la responsabilité du développeur de s'assurer de la validité de la requête et d'éviter les injections.
17.4.2.2 Liste des paramètres
- (string)
dbaccess - Les coordonnées de la base de données. Si cette valeur est vide, ce sont les coordonnées de la base Dynacase qui seront utilisées.
- (string)
query - la requête sql a exécuter
- (array|string|bool)
result -
La forme du résultat dépend des paramètres
singlecolumnetsingleresult:-
singlecolumn = falseetsingleresult = false -
Le résultat est un tableau à deux dimensions.
Chaque rangée de premier niveau contient un tableau indexé avec les noms des colonnes retournées.Si aucun résultat pour la requête n'est trouvé, le résultat est un tableau vide.
-
singlecolumn = falseetsingleresult = true -
Le résultat est un tableau indexé.
L'index correspond aux noms des colonnes retournées.Si aucun résultat pour la requête n'est trouvé, la valeur retournée est un tableau vide.
-
singlecolumn = trueetsingleresult = false -
Le résultat est un tableau.
Chaque élément du tableau contient la valeur de la première colonne duselect.Si aucun résultat pour la requête n'est trouvé, la valeur retournée est un tableau vide.
-
singlecolumn = trueetsingleresult = true -
Le résultat est une chaîne de caractère.
Elle contient la valeur de la première colonne du premier résultat trouvé.Si aucun résultat pour la requête n'est trouvé, la valeur retournée est
false.
-
- (bool)
singlecolumn - Mettre à
truesi une seule colonne doit être retournée. - (bool)
singleresult - Mettre à
truesi un seul résultat doit être retourné. - (bool|null)
useStrict - Si
false: en cas d'erreur pas d'exception déclenchée mais une erreur retournée
Sitrue: en cas d'erreur une exception est déclenchée. Sinull: traitement d'erreur par défaut (se reporter au paramètre applicatifCORE_SQLSTRICT).
17.4.2.3 Valeur de retour
string- Message d'erreur si l'argument
useStrictestfalse.
17.4.2.4 Erreurs / Exceptions
- Si
useStrictestfalsealors un message d'erreur est retourné. Si le message est vide, cela indique que la requête s'est déroulée correctement. - Si
useStrictesttrueune exception\Dcp\Db\Exceptionest déclenchée si la requête échoue. - Si
useStrictestnull(valeur par défaut), le retour d'erreur dépend du paramètre applicatifCORE_SQLSTRICT. Par défaut, la valeurCORE_SQLSTRICTestyes, ce qui est équivalent àuseStrictesttrue.
17.4.2.5 Historique
Aucun.
17.4.2.6 Exemples
17.4.2.6.1 Requête générale
Récupération des identifiants login des 3 premiers comptes trouvés.
$sql = sprintf("SELECT id, login FROM users LIMIT 3"); simpleQuery('', $sql, $results); print_r($results);
Résultat :
Array
(
[0] => Array
(
[id] => 14
[login] => cash
)
[1] => Array
(
[id] => 15
[login] => zoo.garde
)
[2] => Array
(
[id] => 16
[login] => zoo.veto
)
)
17.4.2.6.2 Requête un seul résultat et plusieurs colonnes
Récupérer le login et l'adresse de courriel de l'utilisateur n°14.
$idUser=14; $sql = sprintf("SELECT login, mail FROM users WHERE id=%d", $idUser); simpleQuery('', $sql, $results, false, true); print_r($results);
Résultat :
Array
(
[login] => cash
[mail] => cash@example.net
)
17.4.2.6.3 Requête plusieurs résultats et une seule colonne
Récupération des références des groupes d'utilisateurs :
$sql = sprintf("SELECT login FROM users WHERE accounttype='G'"); simpleQuery('', $sql, $results, true, false); print_r($results);
Résultat :
Array
(
[0] => all
[1] => gadmin
[2] => security
[3] => care
)
17.4.2.6.4 Requête un seul résultat et une seule colonne
Récupérer le login et l'adresse de courriel de l'utilisateur dont le login est zoo.userone.
$userLogin="zoo.userone"; $sql = sprintf("SELECT mail FROM users WHERE login='%s'", pg_escape_string($userLogin)); simpleQuery('', $sql, $result, true, true); printf("mail = [%s]\n",$result);
Résultat :
mail = [one@example.net]
Note : Ne pas oublier d'échapper les chaînes de caractères lors de la composition d'une requête avec des variables de chaîne de caractère.
17.4.2.7 Voir aussi
17.4.3 Description des tables de documents
17.4.3.1 La table Doc
Toutes les informations des documents sont enregistrées dans les tables héritées
de la table doc.
La table doc définie les propriétés des documents ; c'est à dire
tout ce qui est commun à tout type de document.
| Colonne | Type | Définition |
|---|---|---|
| adate | timestamp without time zone | Date de dernier accès au document. |
| allocated | integer | Identifiant système de l'utilisateur auquel le document est affecté. |
| archiveid | integer | Id de l'archive dans laquelle est contenu ce document. |
| atags | text | Balises applicatives. |
| attrids | text | Liste de l'ensemble des attributs ayant une valeur non nulle (calculé par trigger). |
| cdate | timestamp without time zone | Date de création de la révision. |
| classname | text | Nom de la classe PHP associée au document (utilisé dans la table docfam uniquement). |
| comment | text | Obsolète |
| confidential | integer | Indique si le document est confidentiel (>0). |
| cvid | integer | Identifiant du document contrôle de vue associé à ce document. |
| doctype | character(1) | Type de document. |
| domainid | text | pour application offline |
| dprofid | integer | Identifiant du profil dynamique associé à ce document. |
| forumid | integer | Obsolète |
| fromid | integer | Id de la famille d'appartenance. |
| fulltext | tsvector | Ensemble des valeurs du document y compris les textes des fichiers indexés. |
| id | integer | Identifiant unique du document (issue de la séquence seq_id_doc). |
| icon | text | Référence au fichier d'icone du document. |
| initid | integer | Id du premier document de la lignée documentaire. |
| ldapdn | text | Obsolète |
| lmodify | character(1) | Tag de modification. |
| lockdomainid | integer | Pour application offline |
| locked | integer | Indique l'identifiant système de l'utilisateur qui a verrouillé le document. |
| name | text | Nom logique du document. |
| owner | integer | Identifiant système de l'utilisateur ayant créé le document. |
| postitid | text | Identifiant du document post-it associé. |
| prelid | integer | Identifiant du document (dossier) de relation primaire. |
| profid | integer | Identifiant du profil de document. |
| revdate | integer | Date de révision. |
| revision | integer | Numéro d'ordre du document dans sa lignée documentaire. |
| state | text | Étape du document. |
| svalues | text | Liste des valeurs d'attributs recherchables y compris les textes des fichiers indexés. |
| title | character varying(256) | Titre du document. |
| usefor | text | Type d'utilisation du document. |
| values | text | Liste de l'ensemble des valeurs non nulles en corrélation avec attrids. |
| version | text | Libellé de la version : il est vide par défaut. |
| views | integer[] | Liste des identifiants de compte qui ont accès au document. |
| wid | integer | Identifiant du document cycle de vie associé à ce document. |
17.4.3.2 Les tables des documents
Pour chacune des familles enregistrées, une table associée est créée. Cette
table est nommée doc<famid> où <famid> est l'identifiant numérique de la
famille. Une même famille peut avoir un nom de table différent sur différente
installation suivant l'identifiant qui lui a été attribué au moment de la
création. De même si la famille est détruite, une nouvelle table
avec un nom différent lui est attribué.
Exemple :
Figure 103. Héritage des tables de documents
Les tables de documents sont créées avec le schéma public. Pour chacune des familles, une vue est créée avec le nom logique de la famille en même temps que la table réelle. Toutes les vues de documents sont créées sous le schéma family.
SELECT * FROM public.doc1098; -- equivalent à SELECT * FROM family.myfamily;
Important : Ces vues ne sont utilisables qu'en lecture seule. À partir de postgresql 9.3, ces vues sont utilisables en mise à jour.
Note : Les noms des tables en postgresql ne sont pas sensibles à la casse.
La table doc propre ne comprend aucune données.
db# SELECT COUNT(id) FROM ONLY doc ; -- aucun document COUNT ------- 0 db=# SELECT COUNT(id) FROM doc ; -- tous les documents COUNT ------- 15008
Chacune des tables de documents contient en plus des propriétés héritées de la
table doc, une colonne par attributs pouvant contenir une valeur. Cela exclu
les attributs de type tab, frame, array, et menu. Le nom de ces colonnes
sont les identifiants des attributs. Le type de ces colonnes est fonction du
type d'attribut. Le type correspondant en base est indiqué dans
chacun des chapitres décrivant les attributs.
Pour plus de détails sur le mécanisme d'héritage de PostgreSQL :
17.4.3.3 Table de recherche générale
La table docread a les mêmes colonnes que la table doc mais elle n'en
hérite pas. Cette table contient une réplication de l'ensemble des documents
qui sont disséminés dans l'ensemble des tables doc<famid>.
Cette table répliquée a ses propres index globaux et permet dans le cas d'une recherche globale, c'est à dire non liée à une famille particulière, d'être plus rapide.
db=# SELECT id, title FROM doc WHERE id = 1098; id | title ------+--------------------------- 1098 | lecteur de Premier espace (1 ligne) Temps : 24,690 ms db=# SELECT id, title FROM docread WHERE id = 1098; id | title ------+--------------------------- 1098 | lecteur de Premier espace (1 ligne) Temps : 1,037 ms
Cette table est maintenue synchronisée avec le contenu des tables doc<famid>
par des triggers, et ne doit donc être utilisée qu'en lecture seule. Seules
les tables doc<famid> peuvent être utilisées en modification.
17.4.3.4 Indexation des fichiers
Si le moteur de transformation est opérationnel, les contenus des fichiers peuvent être indexés. Un attribut fichier produit trois colonnes dans la table associée à sa famille.
-
- colonne
<attrid> - Contient la référence au fichier :
<vaultId>|<mimeType>|<fileName>.
- vaultId : Identifiant dans le coffre (table
vaultdiskstorage, colonneid_file), - mimeType : type mime du fichier,
- fileName : nom du fichier (basename).
- colonne
- colonne
<attrid>_txt - Contient le contenu textuel (type
text) du fichier qui a été retourné par le moteur de transformation.
- colonne
- colonne
<attrid>_vec - Contient le contenu vectorisé (type
tsvector) de la colonne<attrid>_txt.
- colonne
17.4.3.5 Colonne de recherche générale.
La colonne svalues contient l'ensemble des valeurs recherchables ainsi que les
contenus des colonnes _txt des attributs fichiers. Cette colonne est utilisée
pour les recherches générales utilisant des expressions (partie de
mot).
La colonne fulltext contient la version vectorisée de svalues.
Cette colonne est utilisée pour les recherches globales de mot entier.
Ces deux colonnes sont calculées par trigger. Toutes modifications d'enregistrements sur les tables documentaires déclenchent le recalcul de ces colonnes.
17.4.4 Description de la table des familles de document
La table docfam contient les caractéristiques des familles. Cette
table hérite de la table doc.
Colonnes spécifiques de la table docfam :
| Colonne | Type | Définition |
|---|---|---|
| cprofid | integer | Indique le profil utilisé pour les documents créé de cette famille |
| dfldid | integer | Identifiant du dossier principal |
| cfldid | integer | Identifiant de la recherche principale |
| ccvid | integer | Indique le contrôle de vue qui sera associé aux documents créés avec cette famille |
| ddocid | integer | Obsolète - non utilisé |
| methods | text | Liste des fichiers méthodes (METHOD) |
| defval | text | Valeurs par défaut |
| schar | character(1) | Indique les modalités de révision |
| param | text | Liste des valeurs des paramètres |
| genversion | double precision | Non utilisé |
| maxrev | integer | Nombre maximum de révisions pour les documents de cette famille |
| usedocread | integer | Obsolète - non utilisé |
| configuration | text | Non utilisé |
| tagable | text | Spécifique module Dynacase tags |
Figure 104. Relation d'héritage entre docfam et doc
17.4.5 Description de la table des attributs
La table docattr contient les caractéristiques des attributs des familles.
Lors de l'importation de familles cette table est mise à jour.
Elle sert à produire les classes PHP associées aux familles de
documents.
Composition de la table docattr :
| Colonne | Type | Définition |
|---|---|---|
| id | name | Identifiant de l'attribut |
| docid | integer | Identifiant numérique de la famille |
| frameid | name | Identifiant de l'attribut encadrant (tab, frame ou array) |
| labeltext | text | Libellé de l'attribut |
| title | character(1) | Indicateur appartenance au titre du document: [Y|N] |
| abstract | character(1) | Indicateur appartenance au résumé du document : [Y|N] |
| type | text |
Type d'attribut (avec format) : frame, array, text, docid("MYFAM"), etc. |
| ordered | integer | Ordre de présentation |
| visibility | character(1) | Visibilité de l'attribut |
| needed | character(1) | Indicateur attribut obligatoire : [Y|N] |
| link | text | Définition de l'hyperlien affiché sur la valeur de l'attribut |
| phpfile | text | Nom du fichier PHP utilisé pour l'aide à la saisie |
| phpfunc | text | Déclaration de l'appel à l'aide à la saisie ou au calcul de la valeur de l'attribut |
| elink | text | Définition de l'hyperlien mis sur le bouton supplémentaire affiché sur l'interface de modification de document |
| phpconstraint | text | Déclaration de l'appel à la méthode de contrainte d'enregistrement |
| usefor | character(1) | Catégorie d'attribut : N: attribut normal, Q: paramètre de famille |
| options | text | Liste des options d'attributs |
Cette table n'est pas utilisée par la méthode Doc::getAttribute() car la
définition des attributs par les classes PHP est faite lors de l'importation
des familles. Les modifications sur cette table ne seront prise en compte que
lors de la régénération des familles.
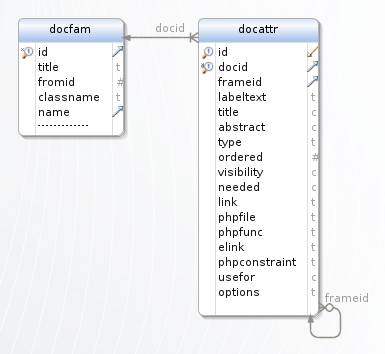
Figure 105. Relation entre docattr et docfam
17.4.6 Description des tables des comptes utilisateurs
Les tables users et groups sont les tables qui contiennent les données
systèmes des comptes utilisateurs.
La tables users contient la définition des utilisateurs, groupes et rôles
utilisés par le système.
Composition de la table users :
| Colonne | Type | Modificateurs |
|---|---|---|
| id | integer | Identifiant unique - Issue de la séquence seq_id_users
|
| lastname | text | Nom |
| firstname | text | Prénom |
| login | text | Identifiant de connexion |
| password | text | Mot de passe crypté |
| isgroup | character(1) | Obsolète |
| substitute | integer | Identifiant du compte qui est suppléant de ce compte (restreint aux utilisateurs) |
| accounttype | character(1) |
U : Utilisateur, G : Groupe, R : Rôle |
| memberof | integer[] | Liste des identifiants des groupes et rôles du compte (calculé à partir de la table groups) |
| expires | integer | Obsolète Non utilisé |
| passdelay | integer | Obsolète Non utilisé |
| status | character(1) |
A : Actif, D : Désactivé |
| text | Adresse principale de courriel | |
| fid | integer | Identifiant du document associé (pointe vers doc128 (Utilisateurs), doc130 (Rôles) ou doc127 (Groupes)) |
Les identifiants inférieurs à 10 sont réservés au système.
| Identifiant | Login | Définition | Nom logique |
|---|---|---|---|
| 1 | admin | Identifiant administrateur | USER_ADMIN |
| 2 | all | groupe "Utilisateur" | GDEFAULT |
| 3 | anonymous | Identifiant accès anonyme | USER_GUEST |
| 4 | gadmin | groupe "Administrateur" | GADMIN |
Les comptes sont liés à un document associé. Ce document constitue l'interface
entre les interfaces d'administration et le compte système. Lorsqu'un document
de compte (famille IUSER, IGROUP ou ROLE) est modifié le compte système
est alors modifié en conséquence.
L'appartenance d'un utilisateur à un groupe ou à un rôle, ou l'appartenance
d'un groupe à un autre groupe ou à un autre rôle, est fait par la table
groups.
Composition de la table groups :
| Colonne | Type | Définition |
|---|---|---|
| iduser | integer | identifiant d'utilisateur ou de groupe (table users) |
| idgroup | integer | identifiant de groupe ou de rôle appartenant à iduser (table users) |

Figure 106. Lien entre les tables users et doc
17.4.7 Descriptions des tables des droits documents et actions
17.4.7.1 Table docperm
Les droits des profils de documents sont enregistrés dans la table
docperm.
Composition de la table docperm :
| Colonne | Type | Définition |
|---|---|---|
| docid | integer | Identifiant du profil |
| userid | integer | Identifiant du compte (utilisateur, groupe ou rôle) ou attribut de document (table vgroup) |
| upacl | integer | Droits du compte pour le profil |
La colonne upacl contient un masque binaire (int4 : 32bits) indiquant les
droits.
| 31 | ... | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| confidential | unlock | modacl | viewacl | modify / icreate | open / create / execute | send | delete | edit | view |
Les droits 11 à 31 peuvent être utilisés pour indiquer des droits spécifiques.
Extrait de la table docperm :
# SELECT docid, userid, upacl::bit(32) FROM docperm; docid | userid | upacl -------+---------+---------------------------------- 4947 | 2 | 00000000000000000000000000100010 15743 | 4 | 00000000000000000000000110000100 15749 | 2 | 00000000000000000000000000100010 15749 | 4 | 00000000000000000000000110000100 15773 | 178 | 11111111111111111111111111111110 2100 | 178 | 11111111111111111111111111111110 15750 | 2 | 00000000000000000000000000100010
Dans cet extrait, la première ligne montre que le compte 2 (groupe all), pour le profil 4967 (document rapport) a le droit de voir et d'exécuter la recherche.
Cette table ne permet pas de savoir directement si un utilisateur a tel ou tel droit sur un document car il faut aussi corréler le résultat au groupe d'appartenance et aux rôles affectés à l'utilisateur.
Pour connaître l'ensemble des documents que l'utilisateur 'john.doe' peut voir,
il est possible d'utiliser la colonne views de la table doc ou
docread.
SELECT docread.id, docread.title, users.memberof FROM docread, users WHERE docread.views && ( users.memberof || '{0}'::INT[] ) AND users.login = 'john.doe';
Note : L'ajout du zéro dans la liste permet à la condition de récupérer aussi
les documents sans profil. Les documents sans profil ont {0} dans la colonne
views.
Pour connaître l'ensemble des documents que l'utilisateur 'john.doe' peut
modifier, il faut s'appuyer sur le contrôle du droit edit (position 2, masque 0x04) et
utiliser la fonction hasaprivilege(userMemberOf, Profid, AccessBinaryMask).
SELECT docread.id, docread.title, profid FROM docread, users WHERE hasaprivilege(users.memberof, docread.profid, 2<<1) AND users.login = 'john.doe' ;
17.4.7.2 Table docpermext
La table docpermext indique les droits étendus. Ces droits sont utilisés
lorsque la liste des droits est variable.
Les cycles de vies et les contrôles de vues utilisent les droits étendus.
Le nom des droits pour les cycles est le nom de la transition. Le nom des droits pour les contrôles de vue est l'identifiant de la vue.
Composition de la table docpermext :
| Colonne | Type | Définition |
|---|---|---|
| docid | integer | Identifiant du profil (document cycle ou contrôle de vue) |
| userid | integer | Identifiant du compte (utilisateur, groupe ou rôle) ou attribut de document (table vgroup) |
| acl | text | Nom du droit |
17.4.7.3 Table permission
La table permission indique les droits applicatifs posés. Ce sont ces
droits qui sont utilisés pour vérifier l'accès à l'exécution d'une
action.
Composition de la table permission :
| Colonne | Type | Définition |
|---|---|---|
| id_user | integer | Identifiant du compte (utilisateur, groupe ou rôle) (table users) |
| id_application | integer | Identifiant de l'application (table application) |
| id_acl | integer | Identifiant de l'acl applicative (table acl) |
| computed | boolean | Cache valeur calculée - vrai si c'est un droit déduit |
Des droits calculés (computed=true) sont enregistrés pour accélérer le
calcul du droit lors des prochaines requêtes.
17.4.7.4 Table acl
La table acl contient la définition des droits utilisées par les
applications.
| Colonne | Type | Définition |
|---|---|---|
| id | integer | Identifiant de l'acl - issus de la séquence seq_id_acl
|
| id_application | integer | Identifiant de l'application (table application) |
| name | text | Nom de l'acl |
| grant_level | integer | Obsolète |
| description | text | Texte descriptif du droit |
| group_default | character(1) | Indique si cette acl est posée par défaut sur le groupe all. Valeurs possibles : [Y|N]. |
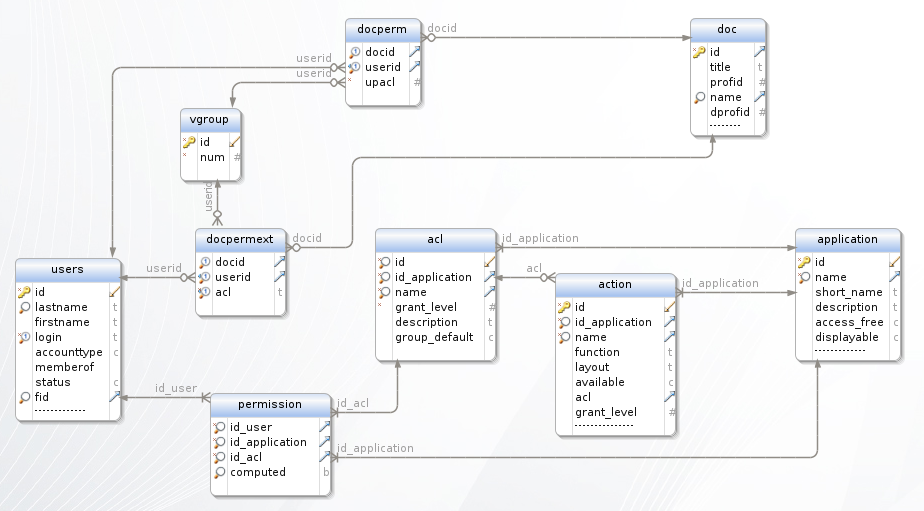
Figure 107. Relations entre les tables mises en œuvre pour la vérification des droits d'accès
17.4.8 Description de la table historique de document
La table dochisto contient les informations notées dans l'historique des
documents.
| Colonne | Type | Description |
|---|---|---|
| id | integer | Identifiant du document (pour une révision donnée) |
| initid | integer | Identifiant initial du document |
| uid | integer | Identifiant de l'utilisateur ayant créé l'entrée |
| uname | text | Nom et prénom de l'utilisateur ayant créé l'entrée |
| date | timestamp without time zone | Date de l'entrée |
| level | integer | Niveau : Notice 1, Information 2, Message 4, Avertissement 8, Erreur 16
|
| code | text | Code de l'entrée. Permet de catégoriser le message |
| comment | text | Message de l'entrée |

Figure 108. Relation entre dochisto et doc
17.4.9 Description de la table log de document
La table doclog contient les informations notées dans le log des
documents.
Les entrées sont ajoutées avec la méthode Doc::addLog().
| Colonne | Type | Description |
|---|---|---|
| id | integer | Identifiant du document (pour une révision donnée) |
| initid | integer | Identifiant initial du document |
| title | text | Message du log |
| uid | integer | Identifiant de l'utilisateur ayant créé le log |
| uname | text | Nom et prénom de l'utilisateur ayant créé le log |
| date | timestamp without time zone | Date du log |
| level | integer | Niveau : Notice 1, Information 2, Message 4, Avertissement 8, Erreur 16
|
| arg | text | Donnée sérializée associé au log |
| comment | text | Commentaire du log |
Figure 109. Relation entre doclog et doc
17.4.10 Description des tables du coffre de fichiers
Ce chapitre définit les tables qui gèrent l'accès aux fichiers attachés aux documents.
17.4.10.1 Table vaultdiskfsstorage
La table vaultdiskfsstorage indique les différents coffres enregistrés.
| Colonne | Type | Définition |
|---|---|---|
| id_fs | int | Identifiant de coffre (issue de la séquence seq_id_vaultdiskfsstorage) |
| fsname | text | Nom du coffre |
| max_size | bigint | Capacité maximum du coffre (en octets) |
| free_size | bigint | Capacité restante en octets (calculé en fonction de la taille des fichiers) |
| subdir_cnt_bydir | integer | Obsolète Non utilisé |
| subdir_deep | integer | Obsolète Non utilisé |
| max_entries_by_dir | integer | Obsolète Non utilisé |
| r_path | character varying(2048) | Chemin absolu d'accès au coffre |
Le répertoire r_path doit être accessible en lecture/écriture à l'utilisateur
du serveur web.
17.4.10.2 Table vaultdiskdirstorage
La table vaultdiskdirstorage indique les différents répertoires utilisés par
les coffres.
Chaque répertoire peut contenir jusqu'à 1000 fichiers.
À chaque ajout d'un fichier dans un répertoire, son free_entries est
décrémenté de 1.
Lorsque le free_entries d'un répertoire arrive à 0, alors un nouveau
répertoire est créé, et sa capacité nominale (free_entries) repart à
1000.
Chaque répertoire ne peut avoir que 100 sous-répertoires. Lorsque tous les répertoires d'un même niveau sont pleins, alors un nouveau répertoire de niveau inférieur est créé.
| Colonne | Type | Définition |
|---|---|---|
| id_dir | integer | Identificateur de répertoire (issue de la séquence `seq_id_vaultdiskdirstorage) |
| id_fs | integer | Identificateur du coffre lié au répertoire |
| free_entries | integer | Nombre d'entrée libre (1000 à l'initialisation) |
| l_path | character varying(2048) | Chemin du répertoire relatif à r_path
|
17.4.10.3 Table vaultdiskstorage
La table vaultdiskstorage stocke les chemins d'accès et les propriétés des
fichiers du coffre.
Les fichiers physiques sont nommés <id_file>.<extension>.
Si id_file=342 et name='mon test.pdf' alors le nom physique est 342.pdf.
Le fichier est placé dans le répertoire r_path/l_path. r_path provient du
coffre lié (id_fs) et l_path provient du répertoire lié (id_dir).
| Colonne | Type | Définition |
|---|---|---|
| id_file | bigint 3.2.21 | Identificateur de fichier (issue de la séquence `seq_id_vaultdiskstorage) |
| id_fs | integer | Identificateur du coffre lié au fichier |
| id_dir | integer | Identificateur du répertoire lié au fichier |
| public_access | boolean | Si vrai, l'accès au fichier est possible sans contrôle du droit d'accès au document |
| size | integer | Taille du fichier (en octets) |
| name | character varying(2048) | Nom du fichier original (basename) |
| mime_t | text | Type mime (humainement lisible, e.g. PDF document, version 1.4) |
| mime_s | text | Type mime système (e.g. application/pdf) |
| cdate | timestamp without time zone | Date d'insertion dans le coffre |
| mdate | timestamp without time zone | Date de modification dans le coffre |
| adate | timestamp without time zone | Date de dernier accès depuis le coffre |
| teng_state | integer | État du fichier converti |
| teng_lname | text | Nom du fichier converti |
| teng_id_file | bigint 3.2.21 | Identifiant du fichier converti |
| teng_comment | text | Message de conversion |
Les attributs de document de type file et image
référencent l'identifiant du fichier. La valeur d'un tel attribut dans un
document est : <Type Mime>|<Identifiant Fichier>|<Nom du fichier>.
L'identifiant fichier référence la colonne id_file de la table
vaultdiskstorage.
3.2.20 Lors de l'ajout d'un
fichier, l'identifiant du fichier est calculé en incrémentant la séquence
seq_id_vaultdiskstorage.
3.2.21 Lors de l'ajout d'un fichier, l'identifiant du fichier est calculé de manière aléatoire dans un ensemble [1 - 2^63].
Sur un serveur 32 bits, l'ensemble possible d'un identifiant de fichier sera limité à [1 - 2^31].

Figure 110. Relations entre les tables des coffres de fichiers
17.4.11 Description des tables des définition des applications
Ce chapitre définit les tables qui contiennent les définitions des applications enregistrées.
17.4.11.1 La table application
La table application contient la partie identification indiquée dans le fichier de
description de l'application.
| Colonne | Type | Définition |
|---|---|---|
| id | integer | Identificateur de l'application (issue de la séquence seq_id_application) |
| name | text | Nom de l'application |
| short_name | text | Description courte |
| description | text | Description longue |
| access_free | character(1) | Obsolète Non utilisé |
| available | character(1) | Valeurs possibles : Y (pour disponible) ou N (non disponible) |
| icon | text | Nom du fichier icône de l'application |
| displayable | character(1) | Valeurs possibles : Y (pour affichable) ou N (non affichable) |
| with_frame | character(1) | Obsolète Non utilisé |
| childof | text | Nom de l'application parente - Vide si pas de parent |
| objectclass | character(1) | Obsolète Non utilisé |
| ssl | character(1) | Obsolète Non utilisé |
| machine | text | Obsolète Non utilisé |
| iorder | integer | Obsolète Non utilisé |
| tag | text | Balise applicative. Permet d'identifier des groupes d'applications |
17.4.11.2 La table action
La table action contient la partie définition des actions indiquée
dans le fichier de description de l'application.
| Colonne | Type | Définition |
|---|---|---|
| id | integer | Identificateur de l'action (issue de la séquence seq_id_action) |
| id_application | integer | Identificateur de l'application associée |
| name | text | Nom de l'action |
| short_name | text | Description courte |
| long_name | text | Description longue |
| script | text | Fichier PHP du contrôleur |
| function | text | Fonction du contrôleur |
| layout | text | Template de l'action |
| available | character(1) | Valeurs possibles : Y (pour disponible) ou N (non disponible) |
| acl | text | Nom de l'acl nécessaire pour exécuter l'action |
| grant_level | integer | Obsolète Non utilisé |
| openaccess | character(1) | Valeurs possibles : Y (pour utilisation possible en authentification par jetons) ou N (dans le cas contraire) |
| root | character(1) | Valeurs possibles : Y (action principale) ou N (action non principale) |
| icon | text | Icône de l'action |
| toc | character(1) | Obsolète Non utilisé |
| father | integer | Obsolète Non utilisé |
| toc_order | integer | Obsolète Non utilisé |
17.4.11.3 La table acl
La table acl contient la partie définition des acl indiquée
dans le fichier de description de l'application.
Se reporter au chapitre Descriptions des tables des droits.
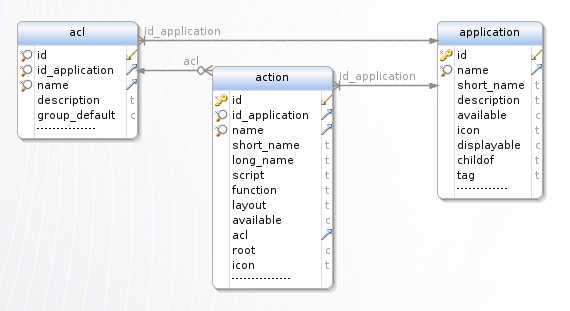
Figure 111. Relations entre les tables définissant les applications
17.4.12 Description des tables de paramètres applicatif
Ce chapitre décrit les tables qui définissent où sont enregistrés les définitions et les valeurs des paramètres applicatifs.
17.4.12.1 Table paramv
La table paramv contient les valeurs des paramètres applicatifs. Elle contient
notamment les valeurs des paramètres applicatifs de référence.
Les valeurs des paramètres sont gérés à travers la classe de Gestion des paramètres.
| Colonne | Type | Définition |
|---|---|---|
| name | character varying(50) | Nom du paramètre |
| type | character varying(21) | Type du paramètre : G (global), A (applicatif), U<uid> (utilisateur) |
| appid | integer | Identifiant de l'application |
| val | text | Valeur du paramètre |
Un paramètre, s'il est global et non utilisateur, ne peut avoir qu'un seule valeur.
Si le paramètre est applicatif et non utilisateur, il ne peut avoir qu'une seule valeur par application.
Si le paramètre est utilisateur, il peut avoir une valeur par utilisateur.
Dans ce cas le type est composé du caractère U suivi de l'identifiant de
l'utilisateur (id table users).
17.4.12.2 Table paramdef
La table paramdef contient les définitions des paramètres
applicatifs.
| Colonne | Type | Définition |
|---|---|---|
| name | text | Nom du paramètre |
| isuser | character varying(1) | Valeurs possibles : Y (paramètre utilisateur), N (paramètre non utilisateur) |
| isstyle | character varying(1) | Utilisé pour paramètre de style (usage interne) |
| isglob | character varying(1) | Valeurs possibles : Y (paramètre global), N (paramètre applicatif) |
| appid | integer | Identifiant de l'application |
| descr | text | Description du paramètre |
| kind | text | Type text, enum, color, password, static ou readonly
|

Figure 112. Relations entre les tables définissant les paramètres
17.5 Mécanismes de persistance
Ce chapitre décrit les classes PHP utilisables pour manipuler les données issues de la base de données.
17.5.1 Manipulation des classes DbObj
Ce chapitre a pour but de montrer par l'utilisation les méthodes et fonctions les plus courantes de manipulations des objets provenant des classes DbObj (Database Object) telles que DocHisto, DocLog, Account.
La classe DbObj est la base du système de persistance de données de Dynacase. Cette classe fourni des méthodes pour faire les opérations basiques de manipulations de données (CRUD).
17.5.1.1 CREATE : Création d'un objet
La méthode DbObj::add() permet de créer une nouvelle entrée dans la table.
Exemple d'ajout d'une entrée dans la table dochisto.
La table dochisto a comme id_fields l'attribut id uniquement.
$h = new DocHisto($this->dbaccess); $h->id = 1009 $h->initid = 1009 $h->comment = "Hello world"; $h->date = date("d-m-Y H:i:s"); $h->uname = sprintf("%s %s", $action->user->firstname, $action->user->lastname); $h->uid = $action->user->id; $h->level = DocHisto::INFO; $h->code = 'TESTING'; $err = $h->add();
La méthode DbObj::add() retourne un message d'erreur en cas d'échec. Cette
méthode appelle les hameçons (hook) DbObj::preInsert() et
DbObj::postInsert(). La méthode DbObj::preInsert() abandonne la création si
elle retourne un message d'erreur.
17.5.1.2 READ : Récupération d'un objet
Les objets sont identifiés par les champs référencés par l'attribut id_fields.
Le constructeur attend des valeurs référencées par cet attribut. Si cet attribut
est un tableau de plusieurs champs alors il faut indiquer l'ensemble des champs
référencés. Les références ne sont pas toujours des clefs uniques pour les
objets de la classe.
//premier histo du document n°1004 $histo=new DocHisto("",1004); // premier log du document n°1004 $log=new DocLog("",10); // permissions du document 1004 pour l'utilisateur 14 (identifiant système) $perm=new DocPerm("",array(1004,14)); // caractéristiques de l'utilisateur n°1 (admin). $user=new Account("",1);
Pour savoir si l'objet a été récupéré depuis la base de données (si la référence existe), il faut utiliser la méthode ::isAffected().
$user=new Account("",1); if ($user->isAffected()) { print_r($user->getValues()); // on affiche toutes les valeurs de l'objet print $user->login; // on affiche un des attributs de l'objet }
L'accès à un des attributs de l'objet se fait directement en utilisant le nom de l'attribut.
17.5.1.3 UPDATE : Mise à jour d'un d'un objet
La mise à jour d'un objet se fait à l'aide de la méthode DbObj::modify().
Avant d'effectuer cette méthode, il faut vérifier que l'objet récupéré existe
réellement à l'aide de la méthode DbObj::isAffected()
$user=new Account("",1); if ($user->isAffected()) { $user->firstName = "McClane"; $user->modify(); }
La méthode DbObj::modify() retourne un message d'erreur en cas d'échec. Cette
méthode appelle les hameçons (hook) DbObj::preUpdate() et
DbObj::postUpdate(). La méthode DbObj::preUpdate() abandonne la mise à jour
si elle retourne un message d'erreur.
17.5.1.4 DELETE : Suppression d'un objet
La méthode DbObj::delete() permet de supprimer toutes les entrées
correspondant aux champs id_fields. Si les champs id_fields correspondent à
une clef unique, une seule entrée sera supprimée.
Exemple d'ajout d'une entrée dans la table dochisto.
$h = new DocHisto($this->dbaccess, 1009); if ($h->isAffected()) { // suppression de toutes les entrées dont "dochisto.id=1009" $err = $h->delete(); }
La méthode DbObj::delete() retourne un message d'erreur en cas d'échec. Cette
méthode appelle les hameçons (hook) DbObj::preDelete() et
DbObj::postDelete(). La méthode DbObj::preDelete() abonne la suppression si
elle retourne un message d'erreur.
17.5.2 Recherche d'objets : QueryDb
La recherche d'objets est réalisée par la classe QueryDb. Elle permet
d'effectuer des requêtes sur un type d'objet.
Le constructeur attend le nom de la classe en deuxième paramètre du constructeur. Le premier paramètre optionnel doit contenir les coordonnées de la base de données.
$query=new QueryDb("", "DocHisto"); $query->addQuery("id=1004"); $result=$q->query(0,0,"ITER"); foreach ($result as $histo) { print_r($histo->getValues()); }
L'exemple ci-dessus donne tous les objets DocHisto du document
1004. Ceci est l'équivalent de ce qui est fait avec la méthode
doc::addHistoryEntry().
La méthode QueryDb::addQuery($filter) permet d'ajouter un filtre sql à la
requête.
La méthode QueryDb:query($start, $slice, $mode) lance la requête et retourne
les résultats.
Les paramètres sont :
- $start : c'est l'offset à partir de combien d'éléments le retour commence, si jamais $start est à 10 les 10 premiers résultats trouvés par la requête ne sont pas retournés,
- $slice : c'est le nombre maximum de résultat à retourner,
- $mode : il peut avoir soit les valeurs
$result=$query->query(0,0,"TABLE"); foreach ($result as $histo) { print_r($histo); }
Résultat :
Array ( [id] => 1004 [initid] => 1004 [uid] => 1 [uname] => "Default Master" [date] => "14/12/2010 14:49:47" [level] => 2 [code] => [comment] => "Mise à jour par importation" ) Array ( [id] => 1004 [initid] => 1004 [uid] => 1 [uname] => "Default Master" [date] => "14/12/2010 14:49:46" [level] => 2 [code] => CREATE [comment] => "Création du document" )
17.5.3 Transactions et savePoint
Des transactions et des points de sauvegarde de base de donnés peuvent être utilisés afin de confirmer ou de revenir à un point de sauvegarde.
Ces transactions n'ont aucun effet sur l'objet mémoire manipulé.
Les méthodes DbObj::savePoint(), DbObj::rollbackPoint() et
DbObj::commitPoint() permettent de gérer les transactions et les points de
retours.
Ces méthodes utilisent, les fonctions savepoint,
rollback to savepoint, release savepoint de Postgresql.
La méthode savePoint() ouvre automatiquement une transaction (BEGIN), si
celle-ci n'est pas encore ouverte. Les méthodes rollbackPoint() et
commitPoint() ferment la transaction si le point de sauvegarde est le premier
des points posés.
Les points de sauvegarde ne sont pas liés à un objet mais impactent toutes les requêtes utilisant la même ressource de connexion à la base. Dynacase n'ouvre qu'une seule ressource de connexion, par conséquent toutes les requêtes utilisant l'api sont impactées (Doc::store(), simpleQuery, DbObj::modify(), ...).
Lorqu'un premier savePoint est déclaré, il faut obligatoirement avoir un
commitPoint ou un rollbackPoint du premier point. Dans le cas contraire
toutes les modifications sur la base de données, depuis le premier point de
sauvegarde, sont abandonnées.
Les méthodes de point de sauvegarde sont accessibles depuis tout objet héritant
de DbObj notamment les classes Doc et Action.
17.5.3.1 savePoint()
string savePoint(string $point)
Cette méthode ouvre une transaction (BEGIN) si une transaction n'est
pas déjà en cours.
Elle ajoute un point de sauvegarde avec l'identifiant donné en paramètre.
Elle retourne une erreur (erreur donnée par postgresSql) si le point de sauvegarde n'a pas pu être posé.
Note : Comme indiqué dans la documentation de postgresql, si le même nom est utilisé, l'index du point de sauvegarde est déplacé.
17.5.3.2 commitPoint()
string commitPoint(string $point)
Cette méthode libère le point de sauvegarde de l'identifiant donné en paramètre.
Si le point de sauvegarde est le premier point alors la transaction est
confirmée (COMMIT);
Elle retourne une erreur si le point de sauvegarde n'a pas été posé au préalable.
17.5.3.3 rollbackPoint()
string rollbackPoint(string $point)
Cette méthode retourne au point de sauvegarde de l'identifiant donné en paramètre.
Si le point de sauvegarde est le premier point alors la transaction est
abandonnée (ROLLBACK);
Elle retourne une erreur si le point de sauvegarde n'a pas été posé au préalable.
Attention : les documents en mémoires et ceux dans le cache ne sont pas
affectés par cette méthode. Il est conseillé de les ré-initialiser et de vider
le cache après utilisation de cette méthode via la fonction clearCacheDoc().
17.5.3.4 lockPoint() Verrouillage de la transaction
string lockPoint( int $exclusiveLock ,
string $exclusiveLockPrefix = '')
3.2.18 La méthode lockPoint
indique que la transaction devient exclusive. Un verrou
(pg_advisory_xact_lock) est posé sur ce point et un autre
processus doit attendre sur ce même point que les données liées à la transaction
soient enregistrées sur la base de données. Les paramètres exclusiveLock et
exclusiveLockPrefix sont les conditions d'acquisition du verrou. Le paramètre
exclusiveLock identifie une ressource (forme numérique) et le paramètre
exclusiveLockPrefix indique un contexte (chaîne limitée à 4 caractères).
L'appel de cette méthode doit obligatoirement être fait dans une transaction
savePoint. Dans la cas contraire, une exception de type Dcp\Db\Exception est
levée.
Le verrou est enlevé lors de la fin de la transaction, c'est à dire lors du commit ou du rollback du premier point.
Ce verrou joue le rôle d'un sémaphore, il bloque l'accès concurrent à une même portion de code.
Exemple :
$document=new_doc("", 1234); $action->savePoint("myUpdate", $document->initid, "MyUp"); $action->lockPoint($document->initid, "MyUp"); // Un seul processus peut exécuter cette partie pour ce document $document->setValue("my_reference", 234); $document->myRecomputeCriticalRelation(); $action->commitPoint("myUpdate"); // Le verrou est relaché s'il s'agit du commit du premier save point
17.5.3.5 setMasterLock()
string setMasterLock($useLock)
3.2.18 Le but de cette méthode est
d'éviter un nombre important de verrou applicatif. Chaque verrou consomme
environ 200 octets de mémoire partagée et la limite
max_locks_per_transaction indiqués par postgresql impose que
le nombre de verrous soit maîtrisé.
La méthode setMasterLock pose un verrou maître (pg_advisory_lock) et non un
"pg_advisory_xact_lock" comme pour le lockPoint. Ce verrou inhibe la pose des
verrous activés par l'appel à la méthode lockPoint pour le processus ayant
posé le verrou maître. Tous les verrous posés par la méthode lockPoint des
autres processus sont bloqués (en attente de la libération du verrou maître). Le
verrou maître doit être débloqué par l'appel à la méthode setMasterLock avec en
paramètre "false".
Exemple de code possible:
$action->setMasterLock(true); // Activation du verrou - ou attente s'il est posé par un autre processus for ($i=0;$i<10000;$i++) { $action->lockPoint($i,"TST"); // pas de pose réelle de lock pour le processus ayant acquis le verrou maître // Mais blocage pour les autres processus qui demande un verrou } $action->setMasterLock(false); // Désactivation du verrou
Dynacase Core n'utilise pas ce verrou dans son code.
17.5.3.6 Exemples
17.5.3.6.1 Annulation d'une requête intermédiaire
include_once("FDL/Class.Doc.php"); $document = new_doc("",8160); // Doc dérive de DbObj $document->savePoint("One"); $document->setValue("us_lname","Test one"); $document->store(); // modification en base doc n°8160 à comme nom "Test One" $document->savePoint("Two"); $document->setValue("us_lname","Test two"); $document->store();// modification en base doc n°8160 à comme nom "Test Two" $document->rollbackPoint("Two"); // annulation de toutes les requêtes depuis le point "Two" $document->commitPoint("One"); // acquittement des requêtes depuis le point "One" // le document en BdD a maintenant comme nom "Test One" // ATTENTION : le document conserve en mémoire sa dernière valeur "Test two".
17.5.3.6.2 Avec plusieurs documents
include_once("FDL/Class.Doc.php"); $document1 = new_doc("",8160); // Doc dérive de DbObj $document1->savePoint("One"); $document1->setValue("first_title","Test one"); $document1->store(); // modification en base doc n°8160 à comme nom "Test One" $document2 = new_doc("",6829); $document2->savePoint("two"); $document2->setValue("second_title","Test two"); $document2->store();// modification en base doc n°6829 à comme nom "Test Two" $document3 = new_doc("",9345); $document3->setValue("third_title","Test three"); $document3->store();// modification en base doc n°9345 à comme nom "Test three" $document1->rollbackPoint("Two"); // annulation de toutes les requêtes depuis le point "Two" $document1->commitPoint("One"); // acquittement des requêtes depuis le point "One" // le document1 en BdD a maintenant comme nom "Test One" // les document2 et document3 n'ont pas été modifiés
Note : Comme indiqué précédemment, ces méthodes ne sont pas liées à l'objet. Le même exemple peut être écrit en utilisant l'action courante ce qui rend moins ambiguë la portée de cette méthode.
include_once("FDL/Class.Doc.php"); $action->savePoint("One"); // Premier point $document1 = new_doc("",8160); // Doc dérive de DbObj $document1->setValue("first_title","Test one"); $document1->store(); // modification en base doc n°8160 à comme nom "Test One" $action->savePoint("Two");// Second point $document2 = new_doc("",6829); $document2->setValue("second_title","Test two"); $document2->store();// modification en base doc n°6829 à comme nom "Test Two" $document3 = new_doc("",9345); $document3->setValue("third_title","Test three"); $document3->store();// modification en base doc n°9345 à comme nom "Test three" $action->rollbackPoint("Two"); // annulation de toutes les requêtes depuis le point "Two" $action->commitPoint("One"); // acquittement des requêtes depuis le point "One" // le document1 en BD a maintenant comme nom "Test One" // les document2 et document3 n'ont pas été modifiés
17.5.3.6.3 Confirmation du point d'entrée initial
Néanmoins, il n'est pas obligatoire d'appliquer un commit ou un rollback sur tous les points, mais il est obligatoire de le faire au moins sur le premier.
$document->savePoint("One"); $document->setValue("us_lname","Test one"); $document->store(); $document->savePoint("Two"); $document->setValue("us_lname","Test two"); $document->store(); $document->savePoint("Three"); $document->setValue("us_lname","Test three"); $document->store(); $document->rollbackPoint("Two"); // on retourne au point Two, le point Three est effacé $document->commitPoint("One"); // on confirme le point One, le point Two est effacé
le document a maintenant comme nom "Test One"
17.5.3.7 Avertissements
17.5.3.7.1 Importation de documents
Ce mécanisme est utilisé lors de l'importation de documents afin d'annuler l'ensemble de l'importation lorsqu'une erreur est détectée. Les hameçons (hooks) utilisés lors de l'importation sont donc exécutés dans une transaction.
17.5.3.7.2 Modification de profil dynamique
Lorqu'un profil dynamique est modifié, tous les documents liés à ce profil ont leurs permissions recalculées.
Chacun calcul de permission est effectuée dans une transaction avec un verrou afin d'interdire la modification simultanée de permission pour un même document.
Si ce calcul de permission est fait dans une transaction déjà mise en place, la
table docperm est verrouillée et les locks unitaires des
permissions ne sont pas activés afin d'éviter de dépasser le nombre maximum de
verrous imposé par postgresql. Dans ce cas précis, toutes les demandes de
modification de permission sont mises en attente le temps de la transaction.
17.5.3.7.3 Interblocage
L'utilisation des verrous peut engendrer des problèmes d'interblocage (deadlock). Il est nécessaire d'être familier avec le système de sémaphores afin de minimiser le risque d'interblocage. Si toutefois un interblocage survient, une des deux connexions Postgresql est tuée par le serveur de base de données.
Exemple minimaliste de 2 programmes lancés en parallèle pouvant aboutir à un interblocage.
Programme 1 :
$document1 = new_doc("",8160); $document->savePoint("One"); $document->lockPoint(32,"my"); $document->setValue("my_title","Test one"); // ICI POSSIBLE SECTION INTERBLOQUE $document->store(); $document->lockPoint(45,"my"); // Bloqué par processus 2 $document->commitPoint("One");
Programme 2 :
$document1 = new_doc("",8162); $document->savePoint("Two"); $document->lockPoint(45,"my"); $document->setValue("my_title","Test two"); // ICI POSSIBLE SECTION INTERBLOQUE $document->store(); $document->lockPoint(32,"my"); // Bloqué par processus 1 $document->commitPoint("Two");
17.5.3.8 Points de sauvegarde utilisée par le système
Les points de sauvegarde des méthodes ci-dessus sont libérés à la fin de la méthode elle-même.
| Méthode | Contexte d'utilisation | Composition de la clef | Composition du verrou |
|---|---|---|---|
| Doc::convert() | Conversion d'un document d'une famille vers une autre famille | "dcp:convert" + Doc::id |
Pas de verrou |
| Doc::revise() | Révision de document / Changement d'état | "dcp:revise" + Doc::id |
Pas de verrou |
| Doc::updateVaultIndex() | Enregistrement de nouveaux fichiers dans le document | uniqid("dcp:updateVaultIndex") |
Doc::initid, "UPVI"
|
| DocCtrl::computeDProfil() | Enregistrement d'un document ayant un profil dynamique | uniqid("dcp:docperm") |
Doc::initid, "PERM"
|
| DocRel::initRelations() | Enregistrement d'un document ayant des relations modifiées | uniqid("dcp:initrelation") |
Doc::initid, "IREL"
|
| UpdateAttribute::beginTransaction() | Mise à jour par lot d'attribut de document avec option de transaction | "dcp:updateattr" |
Pas de verrou |
| ImportDocuments::importDocuments | Importation d'une liste de document en mode strict (annulation si une erreur détectée) | "dcp:importDocument" |
Pas de verrou |
| DetailSearch::isValidPgRegex | Vérification des critères de recherche lors de l'enregistrement d'une recherche ou d'un rapport | "dcp:isValidPgRegex" |
Pas de verrou |
17.6 Manipulation des comptes utilisateur
Ce chapitre a pour but de montrer, par l'utilisation des méthodes et fonctions les plus courantes, la manipulation des utilisateurs "interne".
Ce chapitre ne décrit pas la manipulation des utilisateurs réseaux disponibles avec le module "dynacase-networkuser".
17.6.1 Création d'un utilisateur
La création d'un utilisateur peut être fait à l'aide de la famille
IUSER.
Les comptes utilisateurs sont gérés par la classe Account. La famille IUSER
permet de faire le lien entre le compte "système" (classe Account) et le
document (famille IUSER).
Un utilisateur est identifié par un numéro unique. Ce numéro est renseigné par
l'attribut us_whatid du document IUSER. Il correspond à l'attribut
"id" de la classe Account.
Code minimaliste pour créer un utilisateur via les documents.
include_once("FDL/Class.Doc.php"); $iUser=createDoc("",'IUSER'); if ($iUser) { $iUser->setValue("us_login","jean.martin"); $iUser->setValue("us_lname","martin"); $iUser->setValue("us_fname","jean"); $iUser->setValue("us_passwd1","secret"); $iUser->setValue("us_passwd2","secret"); // nécessaire de doubler à cause des contraintes $err=$iUser->store(); if (!$err) { print "nouvel utilisateur n°".$iUser->getValue("us_whatid"); // affichage de l'identifiant système } else { print "\nerreur:$err"; } }
17.6.2 Correspondance entre compte User et document IUSER
Pour récupérer le compte système à partir du document IUSER :
$user=$userDoc->getAccount(); if ($user->id != $doc->getValue("us_whatid") ) { // ce n'est pas normal }
Si vous ne disposez que de l'identifiant documentaire vous pouvez aussi utiliser la méthode setFid de la classe Account:
$user=new Account(); $user->setFid($docUserId); if ($user->isAffected()) { print $user->login; }
A l'inverse pour récupérer l'objet documentaire à partir du compte système, vous pouvez utiliser l'attribut "fid".
$user=new Account(); $user->setLoginName("john.doe"); if ($user->isAffected()) { $doc=new_doc("", $user->fid); }
Attributs de correspondance : Compte User ⇔ Document IUSER
| Compte User | Document IUSER
|
|---|---|
| id | us_whatid |
| login | us_login |
| us_mail | |
| firstname | us_fname |
| lastname | us_lname |
| fid | id |
Exemple de création d'utilisateur via la classe Account
$user=new Account(); $user->login='jean.dupond'; $user->firstname='Jean'; $user->lastname='Dupond'; $user->password_new='secret'; $err=$user->add(); if ($err) { error_log($err); } else { print "Nouvel utilisateur n°".$user->id; }
17.6.3 Groupe d'utilisateurs
La famille IGROUP permet de rajouter des utilisateurs dans des groupes.
La famille IGROUP comme la famille IUSER utilise la classe Account pour
identifier les groupes "système".
Comme la famille IUSER, la famille IGROUP dispose de la méthode
IGROUP::getAccount() pour récupérer l'objet Account correspondant
17.6.3.1 Correspondance Compte Groupe ⇔ Document IGROUP
| Compte Groupe | Document IGROUP
|
|---|---|
| id | us_whatid |
| login | us_login |
| lastname | grp_name |
| fid | id |
Le compte "Account" d'un groupe a toujours son attribut "accounttype" à "G".
17.6.3.2 Ajout d'un utilisateur à un groupe
Utilisation de Dcp\Family\IGROUP::insertDocument().
Ajout de l'utilisateur n°1009 dans le groupe GDEFAULT :
include_once("FDL/Class.Doc.php"); $dbaccess = getDbAccess(); $group = new_Doc($dbaccess,"GDEFAULT"); $user = new_Doc($dbaccess,1009); // 1009 est la référence documentaire de l'utilisateur printf("ajout de l'utilisateur %s [%d] au groupe %s [%d]\n", $user->getTitle(),$user->id,$group->getTitle(),$group->id); printf("liste des groupes avant\n"); print_r($user->getTValue("us_idgroup")); $err=$group->insertDocument($user->initid); print "Error:$err\n"; printf("liste des groupes apres\n"); print_r($user->getTValue("us_idgroup"));
17.6.3.3 Suppression d'utilisateur dans un groupe
Utilisation de Dcp\Family\IGROUP::removeDocument().
include_once("FDL/Class.Doc.php"); $dbaccess=getDbAccess(); $group=new_Doc($dbaccess,"GDEFAULT"); $user=new_Doc($dbaccess,1009); printf("suppression de l'utilisateur %s [%d] du groupe %s [%d]\n", $user->getTitle(),$user->id,$group->getTitle(),$group->id); printf("liste des groupes avant\n"); print_r($user->getTValue("us_idgroup")); $err=$group->removeDocument($user->initid); print "Error:$err\n"; printf("liste des groupes apres\n"); print_r($user->getTValue("us_idgroup"));
17.6.3.4 Récupération des membres d'un groupe
À partir de l'objet "Account" d'un groupe : Account::getAllMembers().
Exemple d'utilisation :
$docGroup=new_Doc("", "GDEFAULT"); $group=$docGroup->getAccount(); $members=$group->getAllMembers(); $userDocIdList=array(); foreach ($members as $user) { printf("%s) %s\n", $user["id"],$user["login"]); $userDocIdList[]=$user["fid"]; } print "---\n"; // recherche des documents `IUSER` correspondants $documentList=new DocumentList(); $documentList->addDocumentIdentificators($userDocIdList); foreach ($documentList as $docid=>$docIUser) { printf("%s)%s\n", $docIUser->id, $docIUser->getTitle()); }
17.6.4 Rôles
La famille ROLE permet d'associer des rôles à des utilisateurs ou à des
groupes.
La famille ROLE comme la famille IUSER utilise la classe Account pour
identifier les groupes "système".
Comme la famille IUSER, la famille ROLE dispose de la méthode
ROLE::getAccount() pour récupérer l'objet Account correspondant
17.6.4.1 Correspondance Compte Rôle ⇔ Document ROLE
| Compte Rôle | Document ROLE
|
|---|---|
| id | us_whatid |
| login | role_login |
| lastname | role_name |
| fid | id |
17.6.5 Récupération des utilisateurs associés à un rôle
Comme pour les groupes, à partir de l'objet "Account" d'un rôle :
Account::getAllMember().
Exemple d'utilisation :
$docRole=new_Doc("", "TST_ROLE"); $members=$docRole->getAccount()->getAllMembers(); $userDocIdList=array(); foreach ($members as $user) { printf("%s) %s\n", $user["id"],$user["login"]); $userDocIdList[]=$user["fid"]; } print "---\n"; // recherche des documents `IUSER` correspondants $documentList=new DocumentList(); $documentList->addDocumentIdentificators($userDocIdList); foreach ($documentList as $docid=>$docIUser) { printf("%s)%s\n", $docIUser->id, $docIUser->getTitle()); }
17.6.6 Récupération des rôles d'un utilisateur
À partir de l'objet "Account" , méthode Account::getAllRoles()
Exemple d'utilisation :
$user=new Account(''); $user->setLoginName('john.doe'); if ($user->isAffected()) { $roles=$user->getAllRoles(); foreach ($roles as $aRole) { printf("%d)%s\n", $aRole["id"],$aRole["login"]); } }
17.6.7 Suppléants et titulaires
Affectation d'un suppléant à un utilisateur et récupérations des titulaires.
$user=new Account(); $user->setLoginName("j1"); if ($user->isAffected()) { $err=$user->setSubstitute("j2"); // J1 est le titulaire de J2 //(J2 est suppléant de J1) } $user->setLoginName("j3"); if ($user->isAffected()) { $err=$user->setSubstitute("j2");// J3 est le titulaire de J2 } $user->setLoginName("j2"); $incumbents=$user->getIncumbents(); // J2 a comme titulaire J1 et J3 foreach ($incumbents as $key=> $aIncumbent) { printf("%d)%s\n", $key,Account::getDisplayName($aIncumbent)); }
Résultat :
www-data@luke:~$ ./wsh.php --api=testSubstitute 0)j1 Doe 1)j3 Doe
17.6.8 Recherche de comptes
Il est possible de rechercher les comptes suivant leurs critères d'appartenance
à des rôles ou des groupes. La classe SearchAccount permet de
réaliser facilement la recherche de compte. Le résultat de cette recherche peut
retourner des utilisateurs, des groupes ou des rôles.
17.6.8.1 Recherche des utilisateurs par rôle
Pour indiquer le filtre d'un rôle, il faut utiliser, la méthode
::addRoleFilter(). Cette méthode prend en argument la référence du rôle. La
référence correspond à l'attribut 'role_login' du document ou à l'attribut login
de l'objet Account. Il ne correspond pas au nom logique du document.
$searchAccount = new SearchAccount(); $searchAccount->addRoleFilter('writter'); $searchAccount->setObjectReturn($searchAccount::returnAccount); /** * @var \AccountList $accountList */ $accountList = $searchAccount->search(); /** * @var \Account $account */ foreach ($accountList as $account) { $login = $account->login; print "$login\n"; }
Pour rechercher à partir du nom logique du document rôle, il faut utiliser la méthode ::docName2login de correspondance fournie par la classe.
$searchAccount->addRoleFilter($searchAccount->docName2login('TST_ROLEWRITTER'));
La méthode SearchAccount::setObjectReturn() permet d'indiquer le type de
résultat obtenu par la méthode SearchAccount::search(). Par défaut cela
retourne un objet AccountList qui est un itérateur sur des objets Account. Il
est possible d'indiquer SearchAccount::returnDocument, pour que la méthode
SearchAccount::search() retourne un objet DocumentList qui
donnera les documents correspondants
$searchAccount = new SearchAccount(); $searchAccount->addRoleFilter($searchAccount->docName2login('TST_ROLEWRITTER')); $searchAccount->setObjectReturn($searchAccount::returnDocument); /** * @var \DocumentList $documentList */ $documentList = $searchAccount->search(); /** * @var \Doc $doc */ foreach ($documentList as $doc) { $login = $doc->getValue("us_login"); print "$login\n"; }
Si on précise plusieurs rôles séparés par un espace, cela indiquera une disjonction (OU).
$searchAccount->addRoleFilter("writter controller");
indique que les comptes recherchés ont le rôle "writter" ou "controller".
Cette écriture est équivalente à :
$searchAccounts->addRoleFilter("writter"); $searchAccount->addRoleFilter("controller");
La condition d'appartenance à plusieurs rôles n'est pas disponible avec cette méthode. Ce filtre peut retourner des groupes ou des utilisateurs.
17.6.8.2 Recherche des utilisateurs par groupe
La méthode ::addGroupFilter() est équivalent à ::addRoleFilter(). Elle permet de
rechercher parmi les comptes qui appartiennent à différents groupes. Si cette
méthode est combinée à la méthode ::addRoleFilter() cela indique tous les
comptes qui appartiennent à un des groupes cités ou à un des rôles cités.
$searchAccounts->addGroupFilter("all"); // tous les utilisateurs du groupe "all"
La recherche par groupe recherche aussi les comptes dans les sous-groupes. Ce filtre peut retourner des groupes ou des utilisateurs.
17.6.8.3 Recherche sur des critères de compte
La méthode ::addFilter() permet d'ajouter des filtres sur les caractéristiques des comptes:
- login
- firstname
- lastname
- accounttype
- status
$mailExpr='test'; $searchAccount = new SearchAccount(); $searchAccount->addFilter("mail ~ '%s'", $mailExpr); // filtre les mail qui contiennent test $accountList = $searchAccount->search(); foreach ($accountList as $account) { printf("%s => %s\n ", $account->login, $account->mail); }
La méthode SearchAccount::addFilter() ajoute une condition supplémentaire sur
le filtre. Le premier argument est la partie statique du filtre et les suivants
sont les arguments du filtre comme pour sprintf.
Au contraire de SearchAccount::addGroupFilter() ou
SearchAccount::addRoleFilter() les filtres sont autant de critères ajoutés à la
condition finale.
La méthode SearchAccount::setTypeReturn() permet de préciser le type de compte
à retourner : Utilisateur, Groupe ou Rôle.
$searchAccount->setTypeFilter($searchAccount::userType) ; // limité aux utilisateurs $searchAccount->setTypeFilter($searchAccount::userType | $searchAccount::groupType ) ;// limité aux utilisateurs et aux groupes $searchAccount->setTypeFilter($searchAccount::roleType) ; // limité aux rôles
Le paramètre est une combinaison des 3 constantes userType, groupType et roleType.
Par défaut, les comptes retournés ne sont pas liés aux privilèges du document
associé. Si on désire ne rechercher que parmi les comptes que l'utilisateur
courant a le droit de voir il faut rajouter l'appel à la méthode
SearchAccount::useViewControl() avant l'appel à SearchAccount::search().
$searchAccount->useViewControl(true);
17.6.9 Spécialisation des documents utilisateurs
Les documents système "utilisateur" (famille IUSER) peuvent être dérivés pour
ajouter des informations fonctionnelles ou pour ajouter des informations
techniques dans le cas d'un backend d'authentification spécifique.
La famille IUSER n'impose pas de contrainte de syntaxe sur le login. La seule
contrainte est que ce "login" doit être unique parmi tous les comptes
(utilisateurs, groupes et rôles). Si vous voulez ajouter une contrainte de
syntaxe sur votre famille "utilisateur" dérivé de IUSER vous devez surcharger
la méthode IUSER::constraintLogin() qui est une méthode contrainte.
Exemple :
// constraint to limit login to 6 characters public function constraintLogin($login) { //only six alpha num $err = ''; if (!preg_match("/^[a-z0-9]{6}$/i", $login)) { $err = _("the login must have six characters"); } // must verify unicity also if (!$err) return parent::constraintLogin($login); return $err; }
Attention: lorsque la famille IUSER est dérivée, il faut reprendre et adapter
le paramétrage en terme de sécurité (profil, contrôle de vue) en fonction de vos
besoins.
17.7 Migration de modules
17.7.1 Scripts de pré-migration et de post-migration
Lors de la mise à jour d'un module, il est possible d'exécuter des scripts pour effectuer des opérations de migrations ou des traitements spécifiques.
Ces scripts de migration ne peuvent être utilisés que dans le cadre de mise à
jours d'application.
Un module sans application ne peut pas utiliser cette mécanique de migration.
Deux types de scripts sont possibles :
- scripts de pré-migration (premigr) : les scripts de pré-migration (premigr) sont prévus pour être exécutés avant que l'application et les familles en base de données soient mis-à-jour,
- scripts de post-migration (postmigr) : les scripts de post-migration (postmigr) sont prévus pour être exécutés après que l'application et les familles en base de données aient été mis-à-jour.
Les scripts doivent être situés dans le sous-répertoire de l'application et leur nom doit être de la forme :
- scripts de pré-migration (premigr) :
${APPNAME}_premigr_${VERSION} - scripts de post-migration (postmigr) :
${APPNAME}_postmigr_${VERSION}
Remarques :
- Le script peut être écrit dans n'importe quel langage que peut exécuter la plateforme hébergeant le contexte sur lequel il est exécuté. Toutefois, il ne doit pas avoir d'extension, il faut donc utiliser la notation shebang en première ligne de script pour indiquer le langage d'exécution,
- les scripts de migration sont exécutés sur les changements de VERSION sans tenir compte des RELEASE. On ne peut donc pas exécuter de script de migration lors d'un changement de RELEASE,
- les scripts de migration doivent être exécutables.
17.7.2 Exécution des scripts
Le lancement de ces scripts est commandé dans le fichier info.xml du module
par l'utilisation d'une directive
<process command="programs/(pre|post)_migration ${APPNAME}" />
dans la section <post-upgrade/>.
Exemple de déclaration type pour le lancement de scripts de pré-migration et de post-migration :
<module name="FOO" version="VERSION" release="1"> ... <post-upgrade> <process command="programs/pre_migration FOO" /> <process command="programs/record_application FOO" /> <process command="programs/app_post FOO U" /> <process command="programs/post_migration FOO" /> <process command="programs/update_catalog" /> </post-upgrade> </module>
Les programmes pre_migration et post_migration exécutent tous les scripts de
"premigr" ou "postmigr" dont la version est comprise entre la version de
l'application actuellement installé, et la version de l'application mise-à-jour.
| Version sur le contexte | Version dans le paquet | Version du script | Exécution |
|---|---|---|---|
| 1.0.0 | 2.0.0 | 1.1.0 | Oui |
| 1.0.0 | 1.0.0 | 1.0.0 | Non |
| 3.0.0 | 2.0.0 | 1.0.0 | Non |
| 1.0.0 | 2.0.0 | 1.0.0 | Non |
| 1.0.0 | 2.0.0 | 2.0.0 | Oui |
17.7.3 Variables d'environnement
Lorsque les scripts "premigr" et "postmigr" sont exécutés, les variables d'environnement suivantes sont disponibles :
| Variable | Valeur | Exemple |
|---|---|---|
| wpub | Le chemin d'accès au contexte sur lequel est effectué la mise-à-jour. | "/var/www/dynacase" |
| httpuser | L'UID du process httpd/Apache. | "www-data" |
| pgservice_core | Le nom du service PostgreSQL d'accès à la base de données Dynacase. | "dynacase" |
| MODULE_VERSION_FROM | La version du module actuellement installée (de la forme "VERSION-RELEASE"). Cette version n'est pas forcément égale à la version de l'application | "1.2.3-4" |
| MODULE_VERSION_TO | La nouvelle version du module (de la forme "VERSION-RELEASE"). | "2.3.4-5" |
| WIFF_CONTEXT_NAME | Le nom du contexte sur lequel est effectué la mise-à-jour. | "dynacase" |
| WIFF_CONTEXT_ROOT | Le chemin d'accès au contexte sur lequel est effectué la mise-à-jour. | "/var/www/dynacase" |
| WIFF_ROOT | Le chemin d'accès au répertoire dans lequel est installé dynacase-control. | "/var/www/dynacase-control" |
17.7.4 Création de script PHP utilisant l'API de Dynacase
Les scripts de migrations doivent pouvoir être de bas niveau comme ceux présentés ci-dessus. Il s'exécute en ayant un minium de dépendances et permettent de faire des mise à jour sur des parties très bas niveau de Dynacase (base de données, mécanisme de persistances, etc.). Toutefois, dans le cas d'une application, il est souvent plus pratique d'utiliser les API de Dynacase soit via les scripts, soit via les applications actions.
Pour ce faire, vous pouvez utiliser l'exemple suivant :
#!/bin/bash set -o errexit set -o nounset ME=$(basename "$0") function wsh_api { logger -t "$ME" -- "BEGIN:$@" "$wpub/wsh.php" "$@" logger -t "$ME" -- "END:$@" } # Pour un script CLI wsh_api --api=[NOM_DU_SCRIPT_CLI] --from="$MODULE_VERSION_FROM" --to="$MODULE_VERSION_TO" # Pour une action wsh_api --app=[NOM_APPLICATION] --action=[NOM_ACTION] --from="$MODULE_VERSION_FROM" --to="$MODULE_VERSION_TO"
Le code ci-dessus appelle une action ou un script cli en passant en paramètres entrant les numéros de version (le passage des numéros de version est facultatif).
Note : Pour comparer les numéros de version passés en paramètres, vous pouvez
utiliser la fonction version_compare.
17.7.5 Comparaison de versions pour les scripts bash
Il peut être nécessaire, pour un script de migration, d'effectuer des opérations
différentes en fonction de la version de départ du module. Pour cela, la
variable d'environnement $MODULE_VERSION_FROM peut-être utilisée pour obtenir
la version du module actuellement installé. Ensuite, pour comparer des versions
représentés sous forme de chaîne de caractères, il vous faudra utiliser la
fonction bash versionCompare déclarée dans le fichier bash $wpub/libutil.sh :
Syntaxe :
versionCompare $V1 $V2
La fonction prend deux arguments, qui sont les versions à comparer, et affiche sur STDOUT un entier : inférieur à 0 si $V1 est inférieur à $V2 supérieur à 0 si $V1 est supérieur à $V2 égal à 0 si $V1 est égal à $V2
Il faut ensuite utiliser les opérateurs de comparaison arithmétique ("-lt", "-gt", "-le", "-ge", "-eq", "-ne") de bash :
#!/bin/bash . "$wpub/libutil.sh" CMP=$(versionCompare "$MODULE_VERSION_FROM" "1.0.0") if [ $CMP -lt 0 ]; then echo "La version de départ est inférieure à 1.0.0" else echo "La version de départ est supérieure ou égale à 1.0.0" fi
17.8 Mécanismes de recherche
La recherche de documents est une fonctionnalité essentielle à la gestion des documents. Cette recherche permet de trouver des documents sur divers critères tels que :
- critère d'appartenance à une famille,
- critère sur les propriétés de documents,
- critère sur les attributs de documents,
- critère sur les droits du document,
- critère sur l'appartenance à un dossier,
- critère sur les relations entre document,
- critère sur les activités ou état lié à un cycle de vie.
Les chapitres suivants détaillent les techniques permettant d'effectuer des recherches de documents.
17.8.1 Recherche de documents
17.8.1.1 Recherche de documents issus d'une même famille
La recherche de documents en fonction d'une famille est réalisée avec la classe
SearchDoc.
Exemple basique : recherche de tous les utilisateurs (document de la famille
IUSER)
$s=new SearchDoc(getDbAccess(), \Dcp\Family\Iuser::familyName); $results=$s->search(); print_r($results);
Le retour par défaut est sous la forme de tableau indexé par les noms des propriétés et des attributs du document.
Exemple de retour :
Array ( [0] => Array ( [id] => 1009 [owner] => 1 [title] => anonymous guest ....les attributs de la famille IUSER [us_lname] => anonymous [us_fname] => guest [us_mail] => [us_extmail] => [us_meid] => 1009 [us_login] => anonymous ... ) [1] => Array ( [id] => 5835 [owner] => 1 [title] => Dogue Robert ...
L'utilisation de ce type de retour peut être utilisé avec les
templates. Dans le cadre d'une recherche de document pour
réaliser un retour sur une interface, la classe
formatCollection permet de récupérer de manière optimisée
les données affichables des documents recherchés.
17.8.1.2 Récupération du résultat de la recherche
Par défaut les résultats suivants sont exclus :
- les documents supprimés (
doctype = 'Z'), - les documents figés (
locked = -1), - les documents temporaires (
doctype='T'), - les documents archivés (
archiveid is null), - les documents non visibles par l'utilisateur courant (droit
view).
17.8.1.2.1 Retour de documents bruts
Si la méthode ::setObjectReturn() n'est pas utilisée ou
utilisée avec l'argument false la méthode
SearchDoc::search() retourne un tableau à 2 dimensions. Le
tableau de deuxième niveau contient les valeurs brutes des propriétés et des
attributs du document indexé par leur nom.
Avec une boucle foreach.
$s=new SearchDoc("","IUSER"); $rawDocuments=$s->search(); foreach ($rawDocuments as $k=>$rawDoc) { print "$k)".$rawDoc["title"]."(".getv($rawDoc,"us_mail","nomail").")\n"; }
Avec une boucle while en utilisant la méthode SearchDoc::nextDoc() :
$s=new SearchDoc("","IUSER"); $s->search(); $k=0; while ($rawDoc=$s->nextDoc()) { print "$k)".$rawDoc["title"]."(".getv($rawDoc,"us_mail","nomail").")\n"; $k++; }
Note : La fonction getv retourne la valeur d'un élément du document brut.
Cette fonction permet aussi d'extraire des valeurs pour des attributs
spécifiques aux sous-familles si la recherche comporte de tels documents.
17.8.1.2.2 Retour d'objets documentaires
Ce programme permet d'écrire tous les titres des documents accessibles de la
famille "utilisateur". Ici, on n'a utilisé que le critère d'appartenance à une
famille. L'appel à la méthode DocSearch::setObjectReturn()
indique que la méthode DocSearch::Search() doit retourner des objets
documentaires (attention, pour des raisons évidentes de performance, ce retour
n'est pas un tableau).
Dans ce cas, il est possible d'appliquer les méthodes des objets sur les retours
(exemple Doc::getRawValue).
$s=new SearchDoc('',"IUSER"); $s->setObjectReturn(); // retour d'objets documentaires $s->addFilter('us_extmail is not null'); $s->search(); // déclenchement de la recherche $c=$s->count(); print "count $c\n"; $k=0; while ($doc=$s->nextDoc()) { print "$k)".$doc->getTitle()."(".$doc->getRawValue("US_MAIL","nomail").")\n"; $k++; }
17.8.1.2.3 Utilisation des itérateurs
Pour récupérer la liste des documents, il est aussi possible d'utiliser un itérateur PHP afin de parcourir la liste des documents.
$s=new SearchDoc("","IUSER"); $s->setObjectReturn(); // retour d'objets documentaires $s->addFilter('us_extmail is not null'); // retour d'objets documentaires $s->search(); // déclenchement de la recherche $dl=$s->getDocumentList(); foreach ($dl as $docid=>$doc) { print "$docid)".$doc->getTitle()."(".$doc->getRawValue("us_mail","nomail").")\n"; }
La méthode ::getDocumentList() retourne un objet DocumentList qui implémente
l'interface Iterator. Il est ainsi possible d'utiliser le
résultat dans une boucle classique "foreach".
17.8.1.3 Recherche avec critères sur des attributs de document
Dans le cas où une famille d'appartenance est précisée, il est possible d'utiliser les attributs de cette famille comme critères.
$searchedName='jean'; $s=new SearchDoc("","MY_CONTACT"); // recherche sur les document de la famille "MY_CONTACT" $s->addFilter("my_firstname ~* 'jean'"); // prénom contient jean $s->setObjectReturn(true); $s->search(); while ($doc=$s->nextDoc()) { print "$k)".$doc->getTitle()."(".$doc>getRawValue("my_mail","nomail").")\n"; }
L'exemple ci-dessus montre la recherche de toutes les personnes dont le prénom
contient jean. Les filtres ajoutés au moyen de la méthode addFilter
établissent une conjonction de conditions (opérateur and). Pour établir une
disjonction, il faut l'écrire manuellement en SQL en utilisant l'opérateur
logique or.
Les opérateurs sql utilisés doivent être compatibles avec les types des attributs stockés en base de données.
$s=new SearchDoc("","MY_CONTACT");// famid : toute famille $s->addFilter("my_firstname ~* 'jean|patrick'"); // prénom contient jean ou patrick // mail fini par .org ou cp commence par 31// $s->addFilter("(my_mail ~ '\.org$') or (my_postalcode ~ '^31')"); $s->setObjectReturn(true); $s->search(); while ($doc=$s->nextDoc()) { print "$k)".$doc->title."(".$doc->getRawValue("my_mail","nomail").':'. $doc->getRawValue("my_postalcode").")\n"; }
Note : Les types docid sont enregistrés au format text dans la
base de données.
17.8.1.3.1 Recherche sur des attributs de type énumérés (getKindDoc)
Pour rechercher des documents suivant des attributs de type énumérés, une
fonction simplifiée de recherche existe. Cette fonction getKindDoc() a pour
but de construire la règle de filtrage adéquate en tenant compte de la
hiérarchie dans ce type d'attribut.
include_once("FDL/Class.Doc.php"); include_once("FDL/Lib.Dir.php"); $tdoc=getKindDoc("", "USER", // nom de la famille "us_type", // attribut énuméré sur lequel s'applique le filtrage "chefserv" // clef à rechercher ); while (list($k, $v) = each($tdoc)) { print "$k)".$v["title"]."(".getv($v,"us_mail","nomail").")\n"; }
Cet exemple permet de sélectionner la liste des chefs de service. Le chef de service a pour clef 'chefserv'.
17.8.1.3.2 Recherche dans un array
Pour une famille avec un tableau contenant une liste de valeur, le filtre Postgresql suivant permet de filtrer les documents dont une des valeurs est égale à une valeur précise :
$s->addFilter("string_to_array(%s,E'\\n') && '{%s}'", $attrId, $expectedValue);
Si le tableau contient une liste d'identifiants de document, le filtre Postgresql suivant peut être utilisé pour retourner tous les documents contenant cet identifiant :
$s->addFilter("%s ~ E'\\\\y%d\\\\y'", $attrId, $expectedInitid);
Ce filtre ne peut être utilisé qu'avec des valeurs qui n'ont pas d'espace. Le filtre précédent fonctionne aussi mais il est un peu moins performant.
17.8.1.3.3 Recherche avec jointure
Il est possible d'ajouter des critères portant sur une autre table en utilisant un mécanisme de jointure. Ce mécanisme ne permet pas de récupérer des données provenant de cette autre table mais permet de les utiliser comme critère de recherche.
Exemple : recherche des documents qui ont dans l'historique un ordre de suppression émis par l'utilisateur courant
$s=new searchDoc(); $s->trash='only'; // recherche dans les documents supprimés (mis dans la corbeille) $s->join("id = dochisto(id)"); $s->addFilter("dochisto.uid = %d",$this->getSystemUserId()); $s->addFilter("dochisto.code = 'DELETE'"); $s->distinct=true; $result= $s->search();
Il est notamment possible d'utiliser, entre autres, les tables dochisto,
docutag ou docrel pour établir un critère de jointure.
Attention : On ne peut utiliser qu'un seul ordre "join" par requête.
Il est aussi possible de créer un critère sur une famille liée :
$s=new SearchDoc($dbaccess,"ZOO_ANIMAL"); // la famille ZOO_ANIMAL est liée à la famille ZOO_ESPECE via l'attribut AN_ESPECE $s->join("an_espece::int = zoo_espece(initid)"); $s->addFilter("zoo_espece.es_ordre='Rongeur'"); $s->setObjectReturn(true); $s->search(); while ($doc=$s->nextDoc()) { print $doc->getTitle()."\n"; }
Dans l'exemple décrit on recherche les animaux dont l'ordre déclaré dans
l'espèce est 'Rongeur'. Attention à bien lier les deux famille à travers
l'identificateur initial (initid) dans le cas des relations créées avec les
options par défaut.
17.8.1.3 Recherche de famille
Pour rechercher des familles, il faut utiliser la valeur "-1" lors de la construction de l'objet recherche.
$sd=new SearchDoc("", -1); // toutes les familles $sd->search();
17.8.1.4 Recherche de document depuis leur identifiant
Si vous disposez d'une liste d'identifiant de document, il n'est pas conseillé de réaliser une boucle avec l'appel au constructeur new_doc car cela se révèle lent et consommateur en mémoire. Il est conseillé dans ce cas d'utiliser l'itérateur de document.
$dl=new DocumentList(); $dl->addDocumentIdentifiers(array(1112, 1110, 1120, 2034)); foreach ($dl as $fam) { print $fam->getTitle()."\n"; }
La méthode DocumentList::addDocumentIdentifiers() permet de renseigner la
liste des identifiants de document.
Si dans la liste un ou plusieurs identifiant n'existe pas alors l'itérateur ne les retourne pas. Dans ce cas le nombre de documents retourné est inférieur au nombre d'identifiants donnés.
Par défaut seuls les document que l'utilisateur a le droit de voir sont retournés.
Si vous voulez affiner les critères de recherche vous pouvez le faire en utilisant la recherche stockée dans l'iterateur.
$dl=new DocumentList(); $dl->addDocumentIdentifiers(array(1180, 3852, 3853)); $dl->getSearchDocument()->addFilter("title ~ 'Doe'"); $dl->getSearchDocument()->overrideViewControl();
Cela ne retournera que les documents dont le titre contient Doe parmi les
trois documents donnés sans tenir compte des droits de visibilités. Il est aussi
possible d'utiliser la fonction de callback pour l'appliquer à l'ensemble
de la liste (voir DocumentList::listMap()).
17.8.1.5 Recherche de document contenu dans une collection
La classe SearchDoc permet de faire des recherches dans une
collection spécifique (dossier ou recherche) au moyen de la méthode
SearchDoc::useCollection().
Cette recherche n'est pas récursive par défaut, c'est à dire qu'elle ne recherche que dans la collection indiquée.
Lorsque la collection est un dossier, il est possible de faire des recherches
récursives à l'aide de la méthode
DocSearch::setRecursiveSearch(). Le niveau de profondeur
de la recherche est ensuite défini au moyen de la propriété
DocSearch::folderRecursiveLevel, positionné à 2 par défaut.
Note : Le setRecursiveSearch fait référence au niveau de récursivité. par
exemple, folderRecursiveLevel=0 veut dire que l'on recherche dans le dossier,
alors que folderRecursiveLevel=1 indique de rechercher dans le dossier et ses
sous-dossiers.
Lorsque la collection est une recherche, il n'est pas possible de faire la recherche récursivement.
$dirid=2345; // identifiant d'un document recherche $searchDoc = new SearchDoc(); $searchDoc->setObjectReturn(); $searchDoc->useCollection($dirid); $searchDoc->search(); if ($searchDoc->searchError()) { $action->exitError(sprintf("search error : %s",$searchDoc->getError())); }
17.8.1.6 Recherche en fonction des droits
17.8.1.6.1 Recherche sans tenir compte des droits
Par défaut, seuls les documents que l'utilisateur a le droit de voir sont
retournés. Pour retourner tous les documents sans vérifier les droits, il faut
utiliser la méthode overrideViewControl().
$s=new SearchDoc(getDbAccess(), $familyId); $s->overrideViewControl(); // pas de control de droit voir
Note : Si la recherche est faite sous l'identité admin, aucun droit n'est
vérifié.
17.8.1.6.2 Recherche et documents confidentiels
Les documents confidentiels sont les documents dont la propriété 'confidential'
est égale à 1. L'accès à ces documents doit être contrôlé par l'application qui
décide quelles parties elle veut montrer. À la différence du droit voir
('view') des documents, la recherche retourne les documents confidentiels par
défaut. Le filtrage est à faire du côté de l'application avec un post-
traitement. Cependant, il est possible de rajouter un filtre permettant de ne
pas retourner les documents confidentiels que l'utilisateur n'a pas le droit de
voir (droit : 'confidential'). Pour cela, il faut appeler la méthode
excludeConfidential().
$sd=new SearchDoc($dbaccess, $familyId); $sd->excludeConfidential(); $sd->search();
17.8.1.7 Recherche sur les propriétés du document
17.8.1.7.1 Recherche et révision
Par défaut seule la dernière révision du document est retournée. Pour chercher
sur l'ensemble des révisions, il faut mettre la propriété latest a false.
$s=new SearchDoc(getDbAccess(), $familyId); $s->setObjectReturn(true); $s->latest=false; // toutes les révisions
Si la propriété locked = -1, cela indique que le document est figé.
17.8.1.7.2 Recherche sur les propriétés
Cet exemple montre la recherche de document par le titre. Ici, tout type de document est retourné si son titre contient 'jean' en majuscule ou minuscule. Les opérateurs utilisables sont les opérateurs SQL de PostgreSQL.
$nom="jean"; $s=new SearchDoc();// famid : toute famille $s->addFilter("title ~* '%s'",$nom); // titre contient jean $s->setObjectReturn(); $dl=$s->search()->getDocumentList(); foreach ($dl as $k=>$doc) print "$k)".$doc->getTitle()."\n"; }
Dans la cas où on recherche une valeurs dans n'importe quel attribut du
document, on utilisera la propriété svalues. Cet attribut contient
la concaténation des valeurs des autres attributs séparés par le caractère £.
$searchExpression='myWord'; $s=new SearchDoc();// famid : toute famille $s->addFilter("svalues ~* '%s'", $searchExpression);
17.8.1.7.3 Recherche sur les états d'un document lié à un cycle de vie
La recherche des documents en fonction de leur activité ou de leur état est
faite en filtrant sur la propriété state. La clef correspondante est
l'identifiant indiqué dans les propriétés e1 et e2 du cycle.
La recherche suivant l'activité est forcément effectuée sur les dernières révisions.
/** * @var WDoc $wdoc */ $wdoc=new_doc("","ZOO_CYCLEDA" ); // Cycle sur les demandes d'adoption $s=new SearchDoc("", "ZOO_DEMANDEADOPTION"); // Famille demande d'adoption $s->addFilter("state = '%s'", $wdoc->getFirstState()); // recherche des document étant dans la première activité $s->search();
La recherche sur l'état est effectuée sur les révisions passées.
$s=new SearchDoc("", "ZOO_DEMANDEADOPTION"); // Famille demande d'adoption $s->addFilter("state = '%s'", \Zoo\WDemandeAdoption::submittedState); // recherche des document ayant été soumis $s->latest=false; // toutes les révisions $s->addFilter("locked = -1"); // révisions passés uniquement $s->search();
17.8.1.8 Recherche des relations d'un document
Pour trouver les documents qui sont lié à un autre, il faut utiliser la classe DocRel.
La méthode DocRel::getIRelations() donne la liste des documents liés vers un document.
include_once("FDL/Class.Doc.php"); $docrelation=new DocRel(); $doc=new_doc("", 5835 , true); $docrelation=new DocRel($doc->initid); $toMeRelation=$docrelation->getIRelations(); $fromMeRelation=$docrelation->getRelations(); print "\n# --------- Relation vers moi\n"; print_r($toMeRelation); print "\n# --------- Relation depuis moi\n"; print_r($fromMeRelation);
La méthode DocRel::getIRelations() retourne les caractéristiques des documents liés.
-
sinitid: identifiant initial source (celui qui pointe vers la cible), -
cinitid: identifiant initial cible (la cible pointé par la source), -
stitle: titre de la source, -
ctitle: titre de la cible, -
sicon: icone de la source, -
cicon: icone de la cible, -
type: type de lien (nom de l'attribut ayant établi le lien), -
doctype: doctype du document source.
Résultat :
# --------- Relation vers moi
Array
(
[0] => Array
(
["sinitid"] => 5973
["cinitid"] => 5835
["ctitle"] => "Dogue Robert"
["cicon"] => "ugarde.png"
["stitle"] => "Théodor"
["sicon"] => "animal.png"
["type"] => "an_gardien"
["doctype"] => "F"
)
[1] => Array
(
["sinitid"] => 5835
["cinitid"] => 5835
["ctitle"] => "Dogue Robert"
["cicon"] => "ugarde.png"
["stitle"] => "Dogue Robert"
["sicon"] => "ugarde.png"
["type"] => "us_meid"
["doctype"] => "F"
)
)
|
# --------- Relation depuis moi
Array
(
[0] => Array
(
["sinitid"] => 5835
["cinitid"] => 5830
["ctitle"] => "Surveillants"
["cicon"] => "igroup.png"
["stitle"] => "Dogue Robert"
["sicon"] => "ugarde.png"
["type"] => "us_idgroup"
["doctype"] => "F"
)
[1] => Array
(
["sinitid"] => 5835
["cinitid"] => 1010
["ctitle"] => "Utilisateurs"
["cicon"] => "igroup.png"
["stitle"] => "Dogue Robert"
["sicon"] => "ugarde.png"
["type"] => "us_idgroup"
["doctype"] => "F"
)
[2] => Array
(
["sinitid"] => 5835
["cinitid"] => 5832
["ctitle"] => "Gardien surveillant"
["cicon"] => "role.png"
["stitle"] => "Dogue Robert"
["sicon"] => "ugarde.png"
["type"] => "us_roles"
["doctype"] => "F"
)
|
Pour exploiter les résultats, il est possible d'utiliser un objet DocumentList.
$ids=array_map( function ($r) { return $r["sinitid"]; }, $toMeRelation ); $dl=new DocumentList(); $dl->addDocumentIdentifiers($ids); /** * @var Doc $doc */ foreach ($dl as $doc) { printf("%s %s '%d'\n", $doc->getFamilyDocument()->getTitle(), $doc->getTitle(), $doc->id); }
Résultat :
Gardien Dogue Robert '5835' animal Théodor '5973'
L'objet $dl contient alors les documents pointant vers la cible.
17.8.1.9 Callback et itérateur
17.8.1.9.1 Callback sur un itérateur
Il est possible d'appliquer une fonction sur chacun des documents d'une liste de documents provenant d'un itérateur.
$s=new SearchDoc("","IUSER"); $s->setObjectReturn(); // retour d'objets documentaires $s->addFilter('us_extmail is not null'); $s->search(); // déclenchement de la recherche $dl=$s->getDocumentList(); $test=1; $callback=function (&$doc) use ($test) { if ($test) { // test for fun $doc->lock(); // lock document } }; $dl->listMap($callback); foreach ($dl as $docid=>$doc) { print "$docid)".$doc->getTitle()."(".$doc->getProperty("locked").")\n"; }
Dans cet exemple l'ensemble des documents sera verrouillé. Attention : La fonction de mapping est appelée sur chacun des documents lors de l'itération. S'il n'y a pas d'itération la fonction de mapping ne sera pas appelée.
17.8.1.9.2 Callback sur un itérateur avec filtrage
La fonction de callback permet aussi d'exclure des documents de l'itérateur. Si
la méthode retourne le booléen false alors le document sera exclu de la liste.
Tout autre retour que le booléen false, retournera le document, même s'il n'y
a pas de retour explicite.
$s=new SearchDoc("","MY_DOCS"); $s->setObjectReturn(); // retour d'objets documentaires $s->search(); // déclenchement de la recherche $dl=$s->getDocumentList(); $callback=function (&$doc) { if (! $doc->isLocked()) { $doc->lock(); return true; } return false; }; $dl->listMap($callback); foreach ($dl as $docid=>$doc) { print "$docid)".$doc->getTitle()."(".$doc->getProperty("locked").")\n"; }
Cet exemple ne verrouillera que les document non verrouillés et ne retournera que les documents venant d'être verrouillés.
17.8.1.10 Compter le nombre de résultats
Le nombre de résultats peut être obtenu avec la méthode
DocSearch::count() après avoir effectué la recherche (appel
DocSearch::search()).
$s = new SearchDoc('', 'ANIMAL'); $s->addGeneralFilter("cheval noir"); $s->setObjectReturn(); $s->search(); $c=$s->count(); // retourne le nombre de résultat
Si seul le nombre vous intéresse, la méthode DocSearch::count() n'est
pas la plus performante car la requête est lancée et l'ensemble des résultats
est récupéré. Pour des performances accrues, il faut utiliser la méthode
SearchDoc::onlyCount(). Ceci effectue la recherche en ne
retournant que le nombre de documents correspondants.
$s = new SearchDoc('', 'ANIMAL'); $s->addGeneralFilter("cheval noir"); $s->setObjectReturn(); // pas d'appel à Doc::Search $c=$s->onlyCount();// retourne le nombre de résultat
Attention, le premier appel à une des méthodes
DocSearch::search() ou SearchDoc::onlyCount()
lance une requête au serveur de base de données. Le résultat est mis en cache
pour être exploité par les itérateurs.
$s = new SearchDoc('', 'ANIMAL'); $s->addGeneralFilter("cheval noir"); $s->setObjectReturn(); // pas d'appel à Doc::Search $c=$s->onlyCount();// retourne le nombre de résultat $s->addFilter("cdate > '%s'", date("Y-m-d")); // ajoute un critère $s->search(); // relance le recherche
17.8.1.11 Traitement des erreurs
Si la requête échoue suite à des erreurs SQL (souvent liées à un filtre mal
formé), une exception de type Dcp\Db\Exception ou Dcp\SearchDoc\Exception
est retournée. Ces deux types d'erreur hérite de Dcp\Exception.
Les autres erreurs de configuration sont accessibles en utilisant la méthode
::getError().
try { $s=new SearchDoc(getDbAccess(), \Dcp\Family\Iuser::familyName); $s->addFilter('us_extmail is not null'); $s->addFilter("pas bon"); // ici une erreur de filtre $results=$s->search(); if ($s->getError()) { // autre erreur de configuration printf("search error : %s",$s->getError()); } } catch (\Dcp\Exception $e) { print($e->getMessage()); }
Résultat :
{DB0005} query prepare error : ERROR: syntax error at or near "bon"
LINE 1: ...cked != -1) and (us_extmail is not null) and (pas bon) ORDER...
La classe SearchDoc permet de récupérer les informations sur la requête afin de
débugguer votre recherche. Ces informations sont consultables avec la méthode
DocSearch::getSearchInfo() après avoir exécuté la recherche.:
$s=new SearchDoc("","IUSER"); $s->addFilter('us_extmail is not null'); $s->search(); print_r($s->getSearchInfo())
Résultat :
Array
(
[count] => 4
[query] => select doc128.id, owner, title, ... us_accexpiredate, values, attrids from doc128
where (doc128.archiveid is null) and (doc128.doctype != 'T') and (doc128.locked != -1)
and (us_extmail is not null)
ORDER BY title LIMIT ALL OFFSET 0;
[error] =>
[delay] => 0.008s
)
17.8.1.12 Recherche globale
La classe SearchDoc peut aussi être utilisée pour rechercher des
valeurs sur l'ensemble des attributs des documents. Pour cela il faut utiliser
la méthode ::addGeneralFilter(). Cette méthode prend en
argument un ou plusieurs mots. Ce filtre ne tient pas compte de la casse. Il
n'est pas possible de filtrer sur un mot en tenant compte de sa casse.
$s=new SearchDoc('',"ANIMAL"); $s->addGeneralFilter('cheval'); $s->search();
L'exemple ci-dessus permet de rechercher dans la famille "Animal" tous les documents dont au moins une valeur contient le mot "cheval". Dans cet exemple cela permet aussi de retrouver les documents contenant leur forme plurielle, dans ce cas : "chevaux". Par contre cette recherche ne retournera pas les documents contenant "chevaleresques". Cette recherche ne tient pas compte des accents.
17.8.1.12.1 Terme exact
Pour rechercher un terme exact il faut le mettre entre " (double quotes). Ainsi
$s->addGeneralFilter('"cheval"');
retourne les documents contenant le mot "cheval" mais pas "chevaux", cette recherche tient aussi compte des accents.
$s->addGeneralFilter('"cheval blanc"');
retourne tous les documents contenant exactement le terme cheval blanc (attention, ici, blanc doit être positionné immédiatement à la suite de cheval).
17.8.1.12.2 Partie de mot
Pour rechercher une partie de mot, il faut utiliser le caractère * devant la
partie à rechercher.
$s->addGeneralFilter('cheva*');
retourne tous les documents contenant des mots commençant par cheva, comme
cheval, chevalier, chevaux, etc.
$s->addGeneralFilter('*vage');
retourne tous les documents contenant des mots se terminant par vage, comme élevage, gavage, pavage, etc.
17.8.1.12.3 Plusieurs mots
Pour rechercher plusieurs mots il suffit de les indiquer en les séparant par un
espace ou le mot clef AND en majuscule.
$s->addGeneralFilter('cheval noir'); $s->addGeneralFilter('cheval AND noir'); // forme équivalente avec AND
Cet exemple recherche tous les documents dont un attribut contient le mot "cheval" et aussi le mot "noir" (sur le même attribut ou un autre). Attention le filtre suivant
$s->addGeneralFilter('"cheval noir"');
recherche les documents contenant "cheval" suivi de "noir"
La disjonction est aussi disponible en utilisant le mot clef OR en majuscule
entre deux mots
$s->addGeneralFilter('cheval OR poulain');
Différentes combinaisons peuvent ensuite être utilisées pour réaliser un filtre plus complexe
$s->addGeneralFilter('(cheval noir) OR (jument blanche)');
Cet exemple recherche les chevaux noirs ou les juments blanches.
17.8.1.12.4 Utilisation de l'option de correction d'orthographe
La méthode SearchDoc::addGeneralFilter() dispose d'une option (deuxième paramètre) pour vérifier l'orthographe des mots en français.
$s->addGeneralFilter('méson',true);
Cet exemple lance une recherche sur les mots "méson" ou "maison". Cette
vérification n'est pas effectuée sur les termes exacts (avec double quote) ni
sur les expressions (usage du * ).
17.8.1.12.5 Ordonnancement par pertinence
Par défaut les documents retournés par SearchDoc sont triés par titre. Il est possible de les trier par pertinence.
Le calcul de la pertinence est effectué par PostgreSql. Elle prend en compte l'information lexicale, la proximité et la structure ; en fait sont considérés
- le nombre de fois où les termes de la requête apparaissent dans le document,
- la proximité des termes de la recherche avec ceux de la requête,
- l'importance du passage du document où se trouvent les termes du document.
Les poids des mots sont en fonction de l'endroit où le terme est trouvé.
- poids A : titre du document,
- poids B : attributs résumés,
- poids C : autres attributs non résumé,
- poids D : contenu des fichiers attachés (si indexation activé).
Si le terme recherché est de poids A, la pertinence sera plus élevée que s'il
est trouvé avec un poids B. Si on a utilisé une recherche générale sans
expression ni mot exact, on peut utiliser la méthode
::setPertinenceOrder() sans argument :
$s=new SearchDoc('',"ANIMAL"); $s->addGeneralFilter('cheval'); $s->setPertinenceOrder(); $s->search();
Dans ce cas, les clefs d'ordonnancement sont celles du filtre. Le résultat est trié par pertinence sur le mot "cheval" (ou "chevaux"). Si on utilise le mot exact, la pertinence sera équivalente à la recherche par mot. On obtiendra le même ordre avec un calcul sur la forme lemmatisé de "cheval" (incluant "chevaux").
$s->addGeneralFilter('"chevaux"'); $s->setPertinenceOrder(); // la pertinence est sur le mot cheval
La pertinence sans argument ne peut pas être utilisée avec une recherche d'expression. Si on veut maîtriser plus précisément la pertinence, il est possible d'utiliser ses propres mots.
$s=new SearchDoc('',"ANIMAL"); $s->addFilter("an_description ~ * 'Equus'"); $s->setPertinenceOrder('cheval poulain jument'); $s->search();
Dans ce cas, la recherche étant sur des attributs précis, il faut préciser explicitement le critère de pertinence. Dans cet exemple, la pertinence se fera sur les occurrences des mots "cheval", "poulain" ou "jument" trouvés dans les documents retournés qui contiennent 'Equus' dans leur description.
17.8.1.12.6 Mise en évidence des mots trouvés
La méthode SearchDoc::getHighlightText() permet de retourner la partie où le
texte recherché a été rencontré. Cette fonctionnalité ne peut être utilisée
qu'avec une recherche de mots. Cela ne fonctionne pas avec les expressions ni
avec les mots exacts.
$s = new SearchDoc('', 'ANIMAL'); $s->addGeneralFilter("cheval noir"); $s->setObjectReturn(true); $s->search(); $dl = $s->getDocumentList(); foreach ($dl as $doc) { $ht = $dl->getSearchDocument()->getHighLightText($doc); printf("%d) %s : %s\n"),$doc->id, $doc->getTitle(), $ht); }
Les mots trouvés sont par défaut entourés des balises <strong> et
</strong>;. Elles peuvent être modifiées avec les arguments optionnels de
la méthode.
17.8.2 Recherche détaillée
17.8.2.1 Enregistrement d'une recherche détaillée
17.8.2.1.1 Création d'une recherche par famille
La recherche détaillée (famille DSEARCH) a pour but de rechercher
des documents d'une famille donnée. Elle permet d'être utilisée depuis
l'interface graphique ou depuis la classe SearchDoc pour avoir
une liste de document suivant des critères pré- établis.
/** * @var \Dcp\Family\Dsearch $rd */ $rd= createDoc("", \Dcp\Family\Dsearch::familyName); $rd->setValue(\Dcp\AttributeIdentifiers\Dsearch::se_famid, \Dcp\Family\Iuser::familyName); $rd->store(); // Récupération du contenu $content=$rd->getContent(); foreach ($content as $rawDocument) { printf("Document %s (%d)\n", $rawDocument["title"], $rawDocument["id"]); }
De façon similaire, la classe SearchDoc peut utiliser une recherche détaillée.
/** * @var \Dcp\Family\Dsearch $rd */ $rd= createDoc("", \Dcp\Family\Dsearch::familyName); $rd->setValue(\Dcp\AttributeIdentifiers\Dsearch::se_famid, \Dcp\Family\Iuser::familyName); $rd->store(); $s=new SearchDoc(); $s->useCollection($rd->initid); // utilisation de la recherche stockée $s->setObjectReturn(true); $dl=$s->search()->getDocumentList(); // Récupération du contenu foreach ($dl as $docid => $doc) { printf("Document %s (%d)\n", $doc->getTitle(), $docid); }
L'affectation des critères est effectuée en valorisant les attributs du tableau
se_t_detail de la famille DSEARCH.
use \Dcp\AttributeIdentifiers as Attribute; /** * @var \Dcp\Family\Dsearch $rd */ $rd= createDoc("", \Dcp\Family\Dsearch::familyName); $rd->setAttributeValue(Attribute\Dsearch::se_famid, \Dcp\Family\Iuser::familyName); $rd->setAttributeValue(Attribute\Dsearch::ba_title, "Search Active Users with email"); $criteria=array( array(Attribute\Dsearch::se_attrids => Attribute\Iuser::us_status, Attribute\Dsearch::se_funcs => "=", Attribute\Dsearch::se_keys =>"A"), array(Attribute\Dsearch::se_attrids => Attribute\Iuser::us_extmail, Attribute\Dsearch::se_funcs => "is not null", Attribute\Dsearch::se_keys => "") ); $rd->setAttributeValue(Attribute\Dsearch::se_t_detail, $criteria); $rd->store();
17.8.2.1.2 Enregistrement d'une recherche détaillée avec SearchDoc
La recherche détaillée peut aussi être enregistrée avec une requête arbitraire.
La méthode DocSearch::addStaticQuery() permet de modifier la requête issue des
critères du document recherche.
$s=new SearchDoc("", \Dcp\Family\Iuser::familyName); $s->addFilter('us_extmail is not null'); $sql=$s->getOriginalQuery(); /** * @var \Dcp\Family\Dsearch $rd */ $rd= createDoc("", \Dcp\Family\Dsearch::familyName); $rd->setValue(\Dcp\AttributeIdentifiers\Dsearch::ba_title, "my Search"); $rd->store(); // on remplace la requête qui sera utilisée par celle produite par SearchDoc $rd->addStaticQuery($sql);
Dans ce cas, le document produit s'il est modifié par l'interface perd ses caractéristiques spécifiques au dépend des nouveaux critères présents sur l'interface graphique.
La méthode DocSearch::addStaticQuery() ne peut être utilisée que si le
document est déjà enregistré en base de données.
La requête sql enregistrée ne doit pas tenir compte des droits. Ces critères de droits sont ajoutés lors de l'utilisation de la recherche détaillée.
17.8.2.2 Utilisation de méthodes dans l'interface de recherche détaillée
Lors de la création d'une recherche détaillée, il est possible de choisir pour un critère une méthode comme valeur.
Exemple : ma_date > ::getDate(-7)
Cet exemple indique que le critère sera la date courante - 7 jours. La méthode doc::getDate() est une méthode statique de la classe doc.
Les méthodes utilisables dans les recherches détaillées sont les méthodes de la
classe de la famille sur laquelle porte la recherche qui ont un commentaire (au
format DocBlock et qui contiennent les tags @searchLabel et
@searchType. Vous pouvez ainsi déclarer votre propre méthode, utilisable comme
critère de recherche, dans le fichier méthode de votre famille et ajouter les
commentaires DocBlock adéquats. Cette méthode est généralement statique car elle
ne doit pas faire appel à des valeurs de document. Par contre vous pouvez bien
entendu utiliser des paramètres de la famille. La valeur de retour de cette
méthode sera utilisé comme valeur du critère. Cela ne peut être appliqué que sur
des opérateurs nécessitant une seule valeur. Cette méthode spécifique sera
utilisable pour des recherches détaillées portant sur la famille en question.
Exemple de déclaration de méthode :
/** * Get a random integer between 1 and 10 * * @searchLabel Random integer between 1 and 10 * @searchType int * @searchType double * @searchType money */ public function getRandomNumber() { return mt_rand(1, 10); }
Le tag @searchLabel permet de spécifier le libellé qui sera présenté lors de
l'affichage de la liste des méthodes compatibles. Ce libellé sera traduit via le
mécanisme de localisation.
Le tag @searchType permet de spécifier les types d'attributs sur lesquels
cette méthode est utilisable. L'interface de composition des critères de la
recherche détaillée ne présentera alors que les méthodes compatibles avec
l'attribut du critère.
Pour des besoins plus complexes de sélection des méthodes compatibles, vous
pouvez surcharger la méthode Doc::getSearchMethods() pour enlever ou ajouter
des méthodes à la liste générée par défaut. Les méthodes que vous ajoutez
devront aussi avoir les tags @searchLabel et @searchType positionnée.
Exemple de surcharge de Doc::getSearchMethods :
public function getSearchMethods($attrId, $attrType) { $methods = parent::getSearchMethods($attrId, $attrType); if ($attrType == 'date' || $attrType == 'timestamp') { /* * Ajouter avant-hier et après-demain * pour les attributs de type 'date' et 'timestamp' */ $methods = array_merge( $methods, array( array( 'label' => _("Day before yesterday"), 'method' => '::getDate(-2)' ), array( 'label' => _("Day after tomorrow"), 'method' => '::getDate(2)' ) ) ); } return $methods }
17.8.3 Rapports
Les rapports (famille REPORT) héritent de la famille recherche détaillée
(famille DSEARCH).
17.8.3.1 Création d'un rapport
17.8.3.1.1 Critères de recherche
L'enregistrement de la requête est identique à celle de la recherche détaillée.
use \Dcp\AttributeIdentifiers as Attribute; /** * @var \Dcp\Family\Report $report */ $report = createDoc("", \Dcp\Family\Report::familyName); $report->setAttributeValue(Attribute\Report::ba_title, "Report With toview Tag"); $report->setAttributeValue(Attribute\Report::se_famid, \Dcp\Family\Iuser::familyName); $report->setAttributeValue(Attribute\Report::ba_title, "Report on Active Users with email"); $criteria = array( array(Attribute\Report::se_attrids => Attribute\Iuser::us_status, Attribute\Report::se_funcs => "=", Attribute\Report::se_keys => "A"), array(Attribute\Report::se_attrids => Attribute\Iuser::us_extmail, Attribute\Report::se_funcs => "is not null", Attribute\Report::se_keys => "") ); $report->setAttributeValue(Attribute\Report::se_t_detail, $criteria);
17.8.3.2 Présentation du rapport
Les colonnes à afficher sont indiquées par l'attribut rep_idcols. Cet attribut
doit contenir un identifiant d'attribut ou de propriété.
$columns = array( array(Attribute\Report::rep_lcols => "Utilisateurs", Attribute\Report::rep_idcols => "title", Attribute\Report::rep_foots => "CARD"), array(Attribute\Report::rep_lcols => "Utilisateurs", Attribute\Report::rep_idcols => Attribute\Iuser::us_whatid), array(Attribute\Report::rep_lcols => "Courriel", Attribute\Report::rep_idcols => Attribute\Iuser::us_mail), array(Attribute\Report::rep_lcols => "Groupes", Attribute\Report::rep_idcols => Attribute\Iuser::us_idgroup), array(Attribute\Report::rep_lcols => "Identifiant groupes", Attribute\Report::rep_displayoption => "docid", Attribute\Report::rep_idcols => Attribute\Iuser::us_idgroup) ); $report->setAttributeValue(Attribute\Report::rep_tcols, $columns); $report->setAttributeValue(Attribute\Report::rep_style, "standard1"); $report->store();
L'attribut rep_lcols (libellé) n'est pas utilisé lors de la génération. Le
libellé affiché correspond au libellé de l'attribut ou de la propriété.
Pour le cas particulier des attribut de type docid et de type
account, si l'attribut rep_displayoption vaut docid, alors
ce sont les identifiants des documents qui sont affichés au lieu des titres des
documents.
Pour la propriété title, des précautions doivent être prise en
cas de surcharge du titre.
17.8.4 Recherche spécialisée
Pour toute recherche non prévue en standard par l'interface, il est possible de programmer des recherches spécifiques. Elles pourront ensuite être utilisées comme une recherche “normale” depuis l'interface grâce à la famille “recherche spécialisée”. Lorsque vous éditez une recherche spécialisée, vous devez renseigner
-
le fichier php où se trouve la fonction de recherche.
Ce fichier devra être dans le répertoire
EXTERNALSdu contexte. -
Le nom de cette fonction.
Cette fonction prend les 3 arguments suivants :
- start : start index pour la recherche,
- slice : nombre max d'éléments à retourner,
- userid : utilisateur courant.
Des arguments supplémentaires peuvent également être fournis.
Exemple : fichier EXTERNALS/mytest.php :
namespace My; /** * function use for specialised search * return all document tagged TOVIEWDOC by current user * * @param int $start start cursor * @param int $slice offset ("ALL" means no limit) * @param int $userid user system identifier (NOT USED in this function) */ function myToViewTags($start="0", $slice="ALL", $userid=0) { $tag="TOVIEWDOC"; $s=new \SearchDoc(); $s->setObjectReturn(false); $s->join("id = docutag(id)"); $s->setSlice($slice); $s->setStart($start); $s->addFilter("docutag.uid = %d",$userid); $s->addFilter("docutag.tag = '%s'",$tag); return $s->search(); }
17.8.4.1 Enregistrement d'une recherche spécialisée
L'enregistrement se fait en créant un document de la famille SSEARCH. Les
attributs se_phpfile et se_phpfunc permettent d'indiquer la fonction à
utiliser.
use \Dcp\AttributeIdentifiers as Attribute; /** * @var \Dcp\Family\Ssearch $rd */ $sd = createDoc("", \Dcp\Family\Ssearch::familyName); $sd->setValue(Attribute\Ssearch::ba_title, "Search TOVIEWDOC Tag"); $sd->setValue(Attribute\Ssearch::se_phpfile, "mytest.php"); // EXTERNALS/mytest.php $sd->setValue(Attribute\Ssearch::se_phpfunc, "My\\myToViewTags"); $sd->store();
17.8.4.2 Arguments supplémentaires de la fonction
Des arguments supplémentaires peuvent être ajoutés dans l'attribut 'Argument
PHP' (se_phparg). Il sont ajoutés dans l'appel à partir de la quatrième
position. Pour rajouter plusieurs arguments, il faut les séparer par une virgule
(exemple : 1234,ceci est un test,dernier argument).
Dans ces arguments, il est possible de référencer
-
N'importe quel attribut ou propriété du document recherche lui même, au moyen de la notation
%ATTRID%ou%PROPID%.Par exemple,
%TITLE%pour avoir le titre de la recherche, ou%SE_IDCFLD%pour avoir l'identifiant du dossier dans lequel s'exécute la recherche. L'objet recherche lui-même au moyen du mot clé
%THIS%.
17.8.4.3 Retour de la fonction
La fonction de recherche doit retourner un tableau de documents bruts ( type
array et non object). Ce type est celui retourné par la classe SearchDoc en
utilisant la méthode ::setObjectReturn(false).
17.9 Authentification
17.9.1 Présentation
Le mécanisme d'authentification utilisé par Dynacase est paramétrable et permet de choisir :
-
l'Authenticator
C'est le mode d'interaction avec l'utilisateur pour la saisie des information de connexion (formulaire HTML, authentification HTTP Basic, etc.) ;
-
le Provider
C'est le mode de validation de ces informations de connexion (base locale Dynacase, serveur LDAP, fichier texte à plat, etc.).
Dynacase fournit par défaut les Authenticators et Providers suivants :
-
Authenticator
html- formulaire HTML (
Class.htmlAuthenticator.php) ; basic- authentification HTTP Basic
(
Class.basicAuthenticator.php) ; open- authentification par jeton (
Class.openAuthenticator.php) ;
-
Provider
freedom- authentification sur la base locale Dyancase
(
Class.freedomProvider.php).
Un Authenticator peut utiliser un ou plusieurs Provider. Dans ce cas, ils seront utilisés successivement : si le premier Provider autorise l'accès, l'utilisateur est connecté ; sinon on passe au Provider suivant, et ainsi de suite.
Le paramétrage de l'Authenticator, et des Provider à utiliser, s'effectue dans
le fichier conf/local-dbaccess.php.
17.9.2 Workflow d'authentification
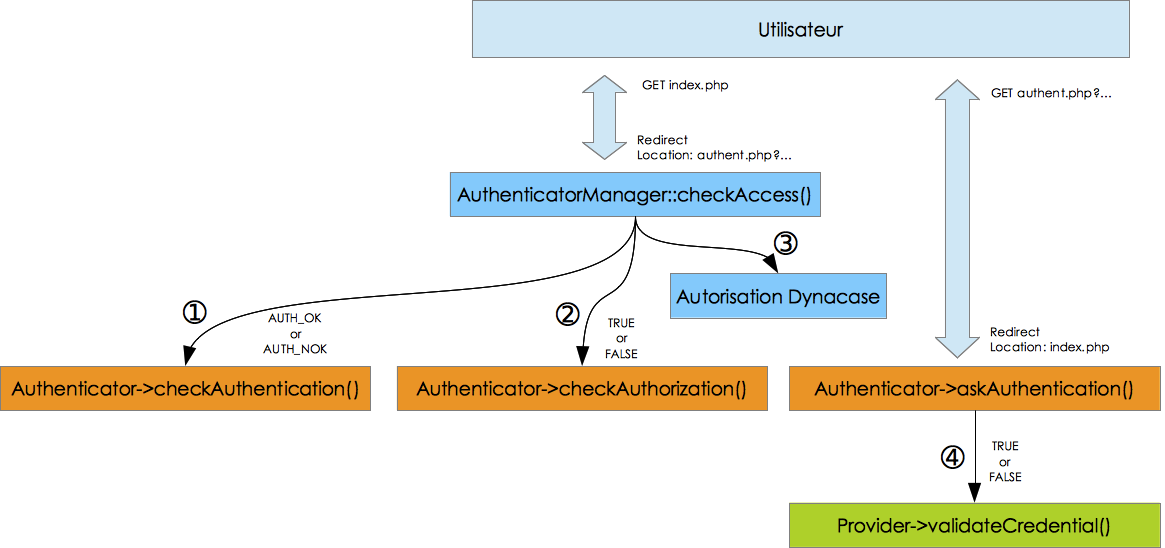
Figure 113. Workflow d'authentification
Lorsque l'utilisateur demande une page, un appel est effectué à la méthode
checkAuthentication() (1) de l'Authenticator qui vérifie si l'utilisateur
est déjà authentifié ou non.
Si l'utilisateur n'est pas authentifié, alors il est redirigé vers la méthode
askAuthentication() qui est en charge de dérouter l'exécution vers le code
nécessaire à la demande des informations de connexion.
L'utilisateur rentre les informations d'authentification qui sont ensuite
validées auprès des Providers configurés via l'appel de la méthode
validateCredential() du Provider (4).
Une fois l'utilisateur authentifié, un contrôle d'autorisation est effectué avec
d'une part un premier contrôle auprès du Provider via l'appel de la méthode
checkAuthorization() de l'Authenticator (2), et d'autre part, un deuxième
contrôle d'autorisation final auprès de Dynacase (3).
Si l'authentification réussie, la page est redirigée sur l'url initialement demandée. Cette redirection entraine le contrôle d'accès à l'action demandée.
Si l'authentification échoue, la page de demande d'authentification est de nouveau affichée.
17.9.3 Paramétrage Authenticator et Provider
L'Authenticator et les Provider utilisés sont paramétrés dans le fichier
config/local-dbaccess.php.
Le fichier config/local-dbaccess.php permet de surcharger le fichier de
configuration config/dbaccess.php livré par défaut par dynacase.
Exemple de fichier config/dbaccess.php livré par dynacase :
<?php $pgservice_core = "dynacase"; $pgservice_freedom = "dynacase"; $freedom_context = "default"; $dbpsql = $pgservice_core; $useIndexAsGuest = false; /* * Authentication mode : apache / basic / html / open * -------------------------------------------------- */ $freedom_authtype = 'html'; $freedom_authtypeparams = array( 'html' => array( 'cookie' => 'freedom_auth', 'auth' => array( 'app' => 'AUTHENT', 'action' => 'LOGINFORM', 'args' => '' ) , 'username' => 'auth_user', 'password' => 'auth_pass', ) , 'open' => array() , 'basic' => array( 'realm' => 'freedom', ) , ); /* * Providers : how username / password tuple is validated * ------------------------------------------------------ */ $freedom_authprovider = 'freedom'; $freedom_providers = array( 'freedom' => array( 'connection' => 'service=' . $pgservice_core, ) , 'file' => array( 'authfile' => '@prefix@/.freedompwd', ) , ); /* * Include local/override config * ----------------------------- */ $local_dbaccess = dirname(__FILE__) . DIRECTORY_SEPARATOR . 'local-dbaccess.php'; if (file_exists($local_dbaccess)) { include ($local_dbaccess); }
Exemple de fichier config/local-dbaccess.php pour la surcharge du paramétrage :
<?php $freedom_authprovider = 'freedom,freedomNu'; $freedom_providers['freedomNu'] = array( 'allowAutoFreedomUserCreation' => 'no', 'fix_euro' => 'no', 'convert_to_utf8' => 'no', 'options' => array( LDAP_OPT_REFERRALS => 0 ) );
Les éléments de configuration utilisables dans ce fichier sont :
$freedom_authtype-
L'authenticator.
Il permet de spécifier quel authenticator est utilisé pour demander les informations de connexion à l'utilisateur (login / password la plupart du temps) et lui transmettre le résultat de l'authentification.
Les différents authenticator disponibles par défaut sont :
html-
Ce mode fournit une interface HTML pour la saisie des informations de connexion (login + mot de passe), et une session par cookie est ouverte afin de valider les accès ultérieurs.
C'est l'Authenticator utilisé par défaut.
apache-
Ce mode spécifie que toute la mécanique d'authentification est déléguée à Apache. Dynacase ne s'occupe pas d'authentifier les utilisateurs, et Apache lui fournit les utilisateurs qui viennent de se connecter via la variable PHP
$_SERVER['PHP_AUTH_USER'].Dans ce mode, le paramètre
$freedom_authprovidern'est pas utilisé. basic-
Ce mode fournit une authentification HTTP Basic.
Dans ce mode, dynacase gère lui même l'authentification au format HTTP Basic, et l'utilisateur rentre son login et son mot de passe dans la boite de dialogue native affichée par le navigateur.
open-
Ce mode fournit une interface basée sur la validation de jetons (voir détails Authentification par jetons).
Ce mode ne présente pas d'interface pour la saisie du login et du mot de passe, mais se base sur un jeton présent dans l'URI.
Dans ce mode, le paramètre
$freedom_authprovidern'est pas utilisé.
$freedom_authprovider-
Ce paramètre spécifie le ou les Provider (séparés, le cas échéant, par des
,) à utiliser pour valider les logins et mots de passe.Par défaut, dynacase fournit les Provider suivants :
freedom-
Ce Provider implémente la validation du login et du mot de passe sur la base locale des utilisateurs de dynacase.
C'est le Provider utilisé par défaut.
17.9.3.1 Configuration des Authenticators
Chaque Authenticator peut avoir des paramètres pour définir son fonctionnement.
Les paramètres des Authenticator sont spécifiés dans la variable
$freedom_authtypeparams.
html-
L'Authenticator
htmldispose des paramètres suivants :auth-
un tableau définissant l'application et l'action (au sens dynacase) utilisées pour gérer la demande des informations de connexion (formulaire HTML) et la soumission/validation de ces informations.
Ce tableau est composé des clés :app- L'application
action- l'action
args- les arguments
cookie- le nom du cookie de la session d'authentification ;
username- Le nom du champ dans lequel est envoyé le login ;
password- Le nom du champ dans lequel est envoyé le mot de passe.
Configuration par défaut :
<?php $freedom_authtypeparams['html'] = array( 'cookie' => 'freedom_auth', 'auth' => array( 'app' => 'AUTHENT', 'action' => 'LOGINFORM', 'args' => '' ) , 'username' => 'auth_user', 'password' => 'auth_pass', );
apache- L'Authenticator
apachene possède pas de paramètres. basic-
L'Authenticator
basicdispose des paramètres suivants :realm- le REALM de connexion pour l'authentification HTTP Basic.
Configuration par défaut :
<?php $freedom_authtypeparams['basic'] = array( 'realm' => 'freedom' );
open- L'Authenticator
openne possède pas de paramètres.
17.9.3.2 Configuration des Providers
Chaque Provider peut avoir des paramètres pour définir son fonctionnement.
freedom-
Le provider
freedomdispose des paramètres suivants :connection- la chaîne de connexion à la base de donnée PostgreSQL.
Configuration par défaut :
<?php $freedom_providers['freedom'] = array( 'connection' => 'service=' . $pgservice_core );
17.9.3.3 Sélection dynamique de l'authenticator
Il a été vu que l'authentification passe par un unique Authenticator, couplé à plusieurs Providers.
Dans certains cas il peut-être utile de pouvoir se connecter sur un même
contexte dynacase via deux Authenticator différents.
Cela passe alors par la définition dynamique de $freedom_authtype.
Par exemple dans le cas d'un contexte dynacase authentifié par CAS, il
peut-être utile de pouvoir se connecter sur ce système sous le compte admin
local (Master Default) sans devoir avoir un compte admin existant sur CAS.
Pour cela, on peut implémenter un « aiguillage » dans le fichier
config/local-dbaccess.php afin de sélectionner le mode d'authentification en
fonctions d'éléments de la requête (comme le champ Host: des requêtes HTTP).
Exemple de fichier config/local-dbaccess.php avec « aiguillage » par
VirtualHost :
<?php if( $_SERVER['HTTP_HOST'] == 'admin-ged.example.net' ) { return; } $freedom_authtype = 'cas'; $freedom_authtypeparams['cas'] = array( 'cookie' => 'freedom_auth', 'cas_version' => 'CAS_VERSION_2_0', 'cas_server' => 'localhost', 'cas_port' => 8443, 'cas_uri' => '/cas-server-webapp-3.4' ); $freedom_authprovider = 'freedomNu'; $freedom_providers['freedomNu'] = array( 'allowAutoFreedomUserCreation' => 'yes', 'fix_euro' => 'no', 'convert_to_utf8' => 'no' );
Dans cet exemple, si on se connecte sur l'URL http://admin-ged.example.net,
alors c'est le mécanisme d'authentification défini par défaut dans le
config/dbaccess.php qui sera appliqué, et dans le cas contraire, on appliquera
l'authentification CAS.
De cette manière, les utilisateurs se connectent par CAS sur leur URL
habituelle (ged.example.net par ex.), et l'administrateur local peut se
connecter sur l'hôte admin-ged.example.net.
17.9.4 Authentification par jetons
L'authentification en mode open permet d'effectuer une requête authentifiée
sans fournir l'identifiant ni le mot de passe mais en fournissant un jeton
d'authentification.
Cette clef d'authentification est associée à un utilisateur défini. Elle permet d'exécuter les actions qui sont déclarées "openaccess" (valeur "Y").
// Fichier MYAPP.app $action_desc = array( array( "name" => "MY_OPENACTION", "acl" => "MY_ACL", "openaccess" => "Y", "short_name" => "Open access test" ) );
17.9.4.1 Obtenir un jeton d'authentification
La méthode Account::getUserToken permet de générer un jeton pour un
utilisateur donné.
string Account::getUserToken(int $expireDelay = -1, bool $oneshot = false, array $context = array(), string $description = "", bool $forceCreate=false)
Cette méthode retourne un jeton sous forme de chaîne de caractères hexadécimaux.
- $expireDelay (int): Délai de validité du jeton en secondes.
- Mettre "-1" (ou
false) pour indiquer un délai infini.
3.2.23 -1 est supporté depuis cette version. Dans les versions antérieures, il fallait indiquer "false", pour l'infini. - $oneshot (bool): Mettre "true" pour indiquer que le jeton sera valide une seule fois
- Le jeton est supprimé une fois consommée.
- $context (array): Tableau indexé (clef/valeur)
- Indique que les paramètres qui sont obligatoires dans l'url
- $description (string): Texte informatif sur le jeton
- Visible lors de l'utilisation de la gestion des jetons dans le centre d'administration
- $forceCreate (bool): 3.2.23 Pour forcer la création d'un nouveau jeton
- Si cette méthode est appelée avec les
mêmes arguments plusieurs fois et avec l'option
oneshotàfalseetforceCreateàfalse, le jeton n'est pas créé si un jeton avec les mêmes caractéristiques existe déjà. Dans ce cas, c'est le même jeton qui est fourni.
Exemple : Construction d'un jeton utilisable à vie pour l'utilisateur "john.doe"
$a=new account(); $a->setLoginName("john.doe"); $t=$a->getUserToken(); print $t; // > cad68f8e1848f12df16e44857c595f9a72124f41
Ce jeton permet d'exécuter toutes les actions déclarées en "openaccess".
Exemple : Construction d'un jeton utilisable à vie pour l'utilisateur "john.doe" restreinte à l'action "MY_OPENACTION" de l'application "MYAPP"
$a=new account(); $a->setLoginName("john.doe"); $t=$a->getUserToken(false, false, ["app"=>"MYAPP", "action"=>"MY_OPENACTION"]);
Exemple : Construction d'un jeton utilisable pour une heure pour l'utilisateur "john.doe" restreinte à l'action "MY_OPENACTION" de l'application "MYAPP"
$a=new account(); $a->setLoginName("john.doe"); $t=$a->getUserToken(3600, false, ["app"=>"MYAPP", "action"=>"MY_OPENACTION"]);
17.9.4.2 Requête pour exécuter une action avec l'authentification "open"
Le jeton doit être indiqué dans l'url avec la variable dcpopen-authorization. Elle peut
aussi être indiquée par une variable dans un formulaire (méthode HTTP POST).
L'url doit contenir la variable "dcpopen-authorization".
Exemple d'URL :
?dcpopen-authorization=e2bb65612c70e7ac78d5ccbfe12aa234&app=FOO&action=BAR
3.2.23La variable privateid utilisée dans les
versions précédentes est dépréciée au profit de la variable dcpopen-authorization.
Si la variable privateid est utilisée alors il faut aussi indiquer explicitement la variable "authtype`.
(déprécié) ?authtype=open&privateid=e2bb65612c70e7ac78d5ccbfe12aa234&app=FOO&action=BAR
Dans ce cas, le cookie de session, s'il est émis, est ignoré.
Le paramètre système de "CORE_OPENURL" est utilisé pour construire les urls. Il doit contenir l'url d'accès à l'application. S'il n'est pas valué (par défaut), c'est la valeur du paramètre "CORE_URLINDEX" qui est utilisé.
Le jeton peut aussi être indiqué dans le header HTTP :
GET ?app=FOO&action=BAR Authorization: DcpOpen e2bb65612c70e7ac78d5ccbfe12aa234
Dans ce cas, le paramètre authtype est optionnel.
Par contre, si le jeton est indiqué et qu'un cookie de session est émis, le cookie de session est ignoré. Le terme "DcpOpen" est le "HTTP Authentication Scheme" pour identifier le mode d'autorisation.
3.2.18 L'authentification par jeton ne donne plus lieu à l'émission d'un cookie de session (l'authentification étant portée par le jeton et non par une session HTTP). Par le passé, l'envoi d'une requête avec authentification par jeton déclenchait systématiquement l'émission d'un nouveau cookie de session bien que ce dernier ne soit pas utilisé.
Pour plus de détails sur la création des jetons : voir la documentation du
fichier de la classe Class.UserToken.php.
En cas de jeton invalide, le statut HTTP retourné est 403.
17.9.5 Authentification HTTP Basic
L'Authenticator basic ne présente aucune interface pour la saisie du login et
du mot de passe, mais se base sur le mécanisme d'authentification HTTP
Basic.
La sélection du mode d'authentification basic s'effectue avec la variable GET
authtype=basic, qui permet alors d'indiquer de ne pas utiliser l'Authenticator par défaut (html par exemple).
Exemple d'URL avec Authenticator basic :
/index.php?authtype=basic&app=FOO&action=BAR
17.9.5.1 Accès avec mot de passe
3.2.23 L'accès peut être effectué en indiquant le login et le mot de passe dans le header HTTP.
GET ?app=CORE&action=BLANK Authorization: Basic am9obi5kb2U6c2VjcmV0
Dans ce cas, le header doit contenir la méthode utilisée (Basic) suivi de la représentation en Base64 du nom de l'utilisateur et du mot de passe séparés par le caractère « : » (deux-points).
En console, l'accès peut être fait avec le programme curl :
curl --user "john.doe:secret" "http://www.example.net/?app=CORE&action=BLANK"
17.9.6 Accès anonyme (invité)
L'accès anonyme permet d'accéder à des actions dynacase sans être authentifié.
Les accès sont alors automatiquement fait sous l'identité de l'utilisateur
anonymous.
Les applications et actions accessibles en mode anonyme sont alors gérées par
les accessibilités de l'utilisateur anonymous.
- Accès anonyme par
guest.php - L'accès anonyme effectué par
guest.php, lance les actions demandés sous l'identité de l'utilisateuranonymous.
Cet accès anonyme peut être désactivé en indiquant `no` dans le paramètre
applicatif `CORE_ALLOW_GUEST` de l'application _CORE_.
Exemple :
/guest.php?app=FOO&action=BAR
- Accès anonyme par
index.phpetuseIndexAsGuest -
Le mode anonyme est aussi accessible via le point d'entré standard
index.phplorsque le paramètre$useIndexAsGuestest positionné à la valeurtruedans le fichierconfig/local-dbaccess.php:<?php $useIndexAsGuest = true;
Dans ce mode de fonctionnement, si l'utilisateur
anonymousa le droit d'exécuter l'action demandée, alors l'accès est autorisé et fait sous l'identitée du compteanonymous.Par contre, si l'action demandée n'est pas accessible par l'utilisateur
anonymous, alors l'authentification est automatiquement demandée afin que l'utilisateur ouvre une session authentifiée pour pouvoir exécuter cette action.C'est donc un mode mixte, et automatique, qui donne l'accès par défaut en tant que
anonymous(commeguest.php), mais qui bascule en mode authentifié lorsque les droits deanonymousne sont pas suffisants pour exécuter l'action demandée.Pour ouvrir explicitement une session de consultation authentifiée, il faut accéder à l'URL de l'application d'authentification spécifique de l'Authenticator utilisé. Par exemple pour l'Authenticator
html:authent.php?app=AUTHENT&action=LOGINFORM
17.9.7 Créer son propre Provider
Un Provider doit hériter de, et implémenter les méthodes définies dans, la
classe WHAT/Class.Provider.php.
Les méthodes à implémenter obligatoirement sont :
- abstract function validateCredential($username, $password)
Les méthodes optionnelles sont :
- public function validateAuthorization($opt)
- public function __construct($authProviderName, $parms)
- public function initializeUser($username)
17.9.7.1 Méthodes
17.9.7.1.1 validateCredential()
Cette méthode prend en entrée deux arguments qui sont :
-
$username: le login entré par l'utilisateur ; -
$password: le mot de passe entré par l'utilisateur.
La méthode doit retourner :
-
truesi le couple login/mot de passe est correct ; -
falsesi le couple login/mot de passe est incorrect.
17.9.7.1.2 validateAuthorization()
Une fois le couple login/password validé, cette méthode permet de contrôler si l'utilisateur est autorisé à se connecter.
Cette méthode est optionnelle, et peut ne pas être fournit par le Provider s'il n'a pas de contrôles d'autorisation supplémentaires à faire.
Cette méthode prend entrée un argument :
-
$opt: une structure contenant le nom de l'utilisateur.$opt = array( 'username' => $username, 'dcp_account' => $Account );
'username': le login de l'utilisateur authentifié.-
'dcp_account' : l'objet Account de l'utilisateur authentifié.
La méthode retourne :
-
truesi l'utilisateur est autorisé à se connecter ; -
falsedans le cas contraire.
17.9.7.1.3 __construct()
C'est le constructeur du Provider que l'on peut étendre si celui-ci nécessite une initialisation particulière.
Cette méthode prend en entrée deux arguments qui sont :
-
$authProviderName: le nom du provider ; -
$parms: un array contenant les paramètres du provider.
17.9.7.1.4 initializeUser()
Si le compte de l'utilisateur n'existe pas dans dynacase, cette méthode est utilisée pour créer le compte de l'utilisateur dans dynacase.
Cette méthode prend en entrée le login de l'utilisateur :
-
$username: le login de l'utilisateur.
La méthode retourne :
-
"": une chaîne vide s'il n'y a pas eu d'erreur à la création du compte. -
"Error message …": une chaîne non vide contenant le message d'erreur rencontré.
Cette méthode spécifique implémente la recherche des informations de l'utilisateur à partir du login sur le système d'authentification utilisé, et la création du compte utilisateur dynacase avec les informations obtenus.
17.9.7.2 Exemple
Dans l'exemple ci-dessous, nous allons écrire un Provider pour valider les mots
de passe des utilisateurs auprès d'un service PAM à l'aide de
la commande checkpassword-pam
Ce module ne supportera pas la création d'utilisateurs à la volée.
17.9.7.2.1 Fichier config/local-dbaccess.php
On va déclarer dans le fichier config/local-dbaccess.php que l'on utilise en
premier notre Provider pam, et ensuite le Provider freedom si l'utilisateur
n'est pas reconnu par le Provider pam.
Notre Provider pam aura un paramètre nommé service qui contiendra le nom du
service PAM auprès duquel seront validés les logins et mots de passe (c'est le
nom du fichier situé dans /etc/pam.d).
<?php $freedom_authprovider = 'pam,freedom'; $freedom_providers['pam'] = array( 'service' => 'dynacasepam' );
17.9.7.2.2 Fichier WHAT/providers/Class.pamProvider.php
Notre Provider est donc décrit dans le fichier Class.pamProvider.php situé
dans le sous-répertoire WHAT/providers de l'installation dynacase.
Celui-ci fournit une classe pamProvider qui étend la classe Provider, et
nous allons décrire nos méthodes spécifiques validateCredential() et
validateAuthorization().
Dans validateCredential() nous allons récupérer le paramètre service de
notre provider, et utiliser la commande checkpassword-pam pour valider le
username et le password reçu.
Pour simplifier l'exemple, la méthode validateAuthorization() retournera
true systématiquement (elle pourrait aussi ne pas être implémentée, ce qui
donnerait le même résultat).
<?php include_once('WHAT/Class.Provider.php'); Class pamProvider extends Provider { public function validateCredential($username, $password) { $service = 'freedom'; if( array_key_exists('service', $this->parms) ) { $service = $this->parms['service']; } return $this->checkpassword_pam($username, $password, $service); } public function validateAuthorization($opt) { $username = $opt['username']; return true; } public function checkpassword_pam($username, $password, $service) { $cmd = sprintf("checkpassword-pam --service %s --no-chdir-home --noenv", escapeshellarg($service)); $proc = proc_open($cmd, array(3=>array('pipe', 'r')), $pipes); if( ! is_resource($proc) ) { error_log(__CLASS__."::".__FUNCTION__." ".sprintf("Error running checkpassword-pam")); return false; } fwrite($pipes[3], sprintf("%s\0%s\0timestamp\0", $username, $password )); fclose($pipes[3]); $ret = proc_close($proc); if( $ret === 0 ) { return true; } error_log(__CLASS__."::".__FUNCTION__." ". sprintf("Authentication failed for user '%s' and service '%s'.", $username, $service ) ); return false; } }
17.9.7.2.3 Fichier /etc/pam.d/dynacase
Pour finir, le fichier associé au paramètre service de notre Provider. Celui-
ci contiendra les règles que l'on souhaite voir appliqué pour la validation des
comptes. Dans cet exemple, on utilisera une authentification des comptes sur la
base locale des utilisateurs Unix du serveur.
auth sufficient pam_unix.so auth required pam_deny.so account required pam_permit.so session required pam_permit.so
17.10 Contrôles d'accès
Ce paragraphe décrit comment sont réalisés les contrôles d'accès aux actions, aux documents et aux fichiers.
17.10.1 Vérification des privilèges pour exécuter une action
L'exécution d'une action est contrôlé par les acl.
L'attribution d'un privilège est fait en fonction des rôles et des groupes d'appartenance de l'utilisateur suivant les règles de propagation des droits.
Le graphique suivant précise la partie vérification des privilèges du chapitre exécution de la requête.
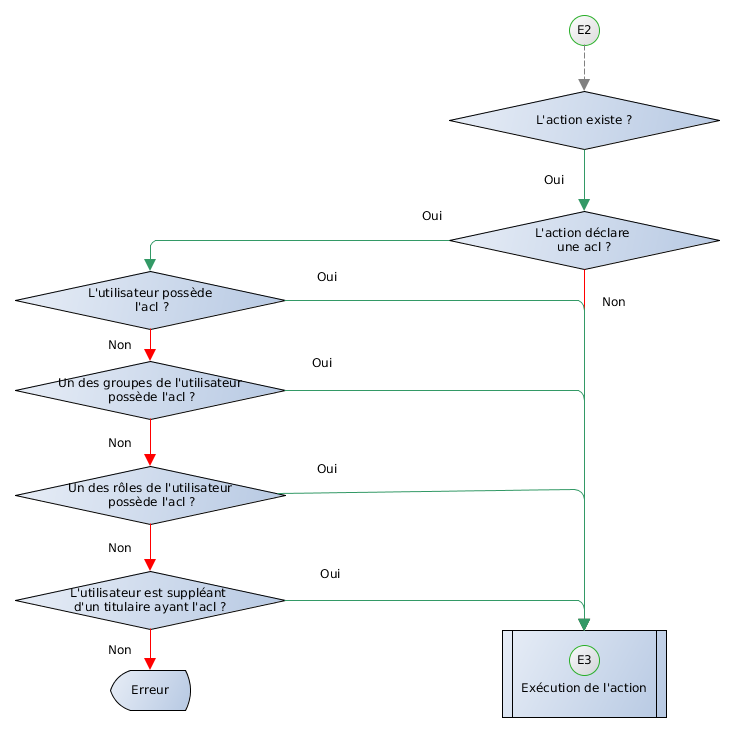
Figure 114. Contrôle de l'exécution d'une action
17.10.2 Vérification des droits pour accéder à un document
La consultation des documents est contrôlée par les profils de documents.
Le contrôle d'accès au document est fait par les interfaces de haut-niveau. La
classe Doc et notamment la fonction new_Doc() ne vérifie pas les
accès. Ces vérifications doivent être fait par les actions avec la
méthode Doc::hasPermission().
Le schéma suivant décrit les contrôles de l'action FDL:OPENDOC et précise la cinématique de l'accès à un document.
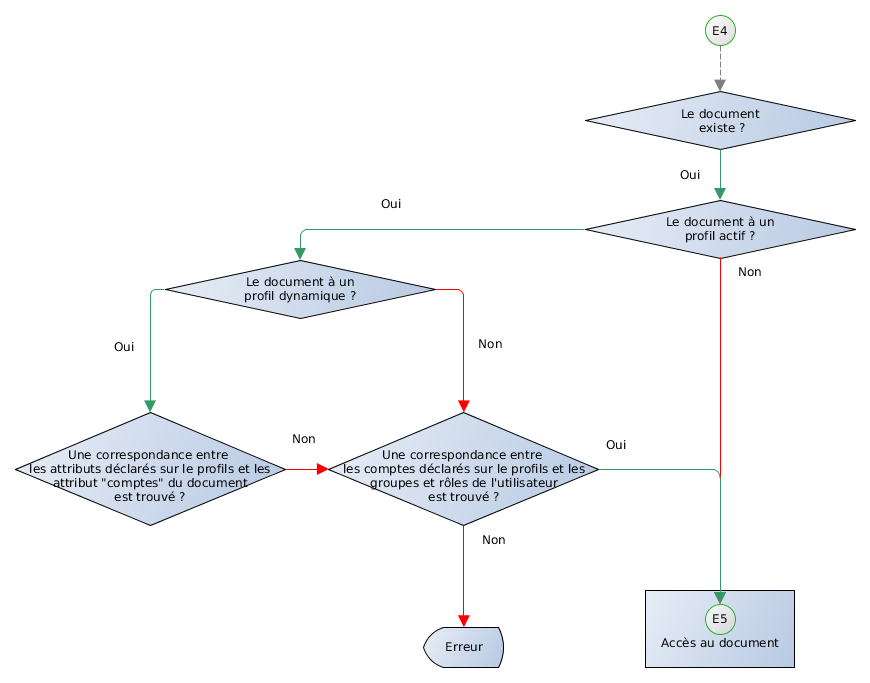
Figure 115. Contrôle de l'affichage d'un document
17.10.3 Vérification des droits pour télécharger un fichier d'un document
L'accès au téléchargement d'un fichier se fait avec l'action
FDL:EXPORTFILE.
Le fichier physique enregistré dans le coffre n'est pas accessible
directement. L'accès aux répertoires des coffres est contrôlé par le serveur web
qui interdit leur accès (fichier .htaccess).
Certains fichiers peuvent être en accès libre. Cela concerne notamment les icônes personnalisées des familles, dossiers et recherches.
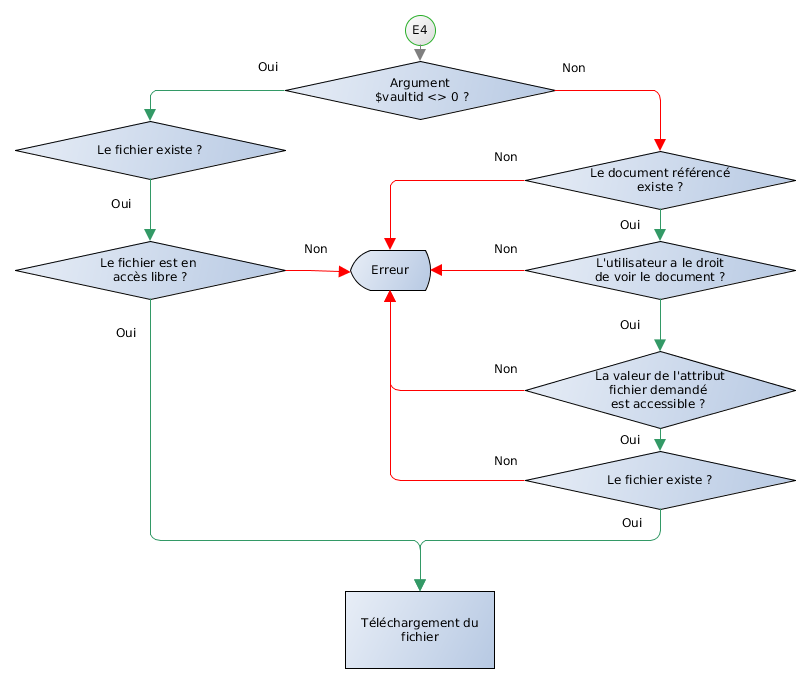
Figure 116. Contrôle du téléchargement d'un fichier
17.10.4 Documents confidentiels
Un document confidentiel est un document dont l'affichage est soumis à un
droit spécifique : le droit confidential.
La propriété confidential indique la caractère confidentiel d'un
document. S'il est supérieur à zéro, le document est considéré comme
confidentiel.
Les interfaces d'affichage standards de document comme FDL:OPENDOC
prennent en compte cette propriété afin d'indiquer que le document est
confidentiel et ne montre pas son contenu.
Les interfaces standards d'affichage de liste de document comme
GENERIC:GENERIC_LIST n'affichent pas les documents confidentiels.
Pour afficher un document confidentiel, il faut que l'utilisateur dispose du
droit view et du droit confidential.
Attention : La classe SearchDoc de recherche de document retourne par
défaut les documents confidentiels. Il faut explicitement utiliser la méthode
DocSearch::excludeConfidential() pour les filtrer. Dans le
cas contraire, le développeur a en charge de montrer que les parties voulues
sur l'interface cliente.
17.11 Usage avancé des templates
Ce chapitre aborde l'usage avancé du moteur de template. Il est d'abord conseillé de lire le chapitre sur les représentations.
Le moteur de template a plusieurs usages avancés que nous allons aborder :
- textuel : répétable à plusieurs niveaux, mutualisation de code avec l'utilisation du système des vues,
- odt (openDocument Text): mise en page complexe.
De plus, nous allons aborder un élément qui n'utilise pas directement le moteur de template mais qui permet de mettre en forme une liste ou une collection de documents pour l'utiliser comme source de données soit pour communiquer avec une application tierce, soit pour construire des interfaces avancées.
17.11.1 Représentations textuelles
Ce chapitre aborde les techniques avancées des représentations textuelles.
17.11.1.1 Répétable à plusieurs niveaux
Les répétables à multi-niveaux permettent de construire des représentations qui nécessitent des listes d'éléments de profondeur variable.
Pour mettre en pratique cette fonctionnalité, nous allons prendre un exemple : la réalisation d'une table de multiplication.
Le résultat suivant doit être obtenu :
Table de multiplications -------------------------------------------- x| 1| 2| 3| 4| 5| 6| 7| 8| 9| 10| ============================================ 1) 1| 2| 3| 4| 5| 6| 7| 8| 9| 10| ---+---+---+---+---+---+---+---+---+---+---+ 2) 2| 4| 6| 8| 10| 12| 14| 16| 18| 20| ---+---+---+---+---+---+---+---+---+---+---+ 3) 3| 6| 9| 12| 15| 18| 21| 24| 27| 30| ---+---+---+---+---+---+---+---+---+---+---+ 4) 4| 8| 12| 16| 20| 24| 28| 32| 36| 40| ---+---+---+---+---+---+---+---+---+---+---+ 5) 5| 10| 15| 20| 25| 30| 35| 40| 45| 50| ---+---+---+---+---+---+---+---+---+---+---+ 6) 6| 12| 18| 24| 30| 36| 42| 48| 54| 60| ---+---+---+---+---+---+---+---+---+---+---+ 7) 7| 14| 21| 28| 35| 42| 49| 56| 63| 70| ---+---+---+---+---+---+---+---+---+---+---+ 8) 8| 16| 24| 32| 40| 48| 56| 64| 72| 80| ---+---+---+---+---+---+---+---+---+---+---+ 9) 9| 18| 27| 36| 45| 54| 63| 72| 81| 90| ---+---+---+---+---+---+---+---+---+---+---+ 10) 10| 20| 30| 40| 50| 60| 70| 80| 90|100| ---+---+---+---+---+---+---+---+---+---+---+
Le système de template peut être utilisé dans diverses parties de Dynacase
(document, script, action, fichier php tiers, etc.). Ce système utilise la
classe Layout.
L'exemple ci-dessous fonctionne dans une action :
<?php function multiplication(Action & $action) { $usage = new ActionUsage($action); $max = $usage->addOption("max", "max", array() , 10); $lines = array(); // tableau pour le contenu $firstLine = array(); // tableau pour l'entête (premiere ligne) for ($i = 1; $i <= $max; $i++) { // construction l'entete du tableau (liste des chiffres) $firstLine[] = array( "X" => sprintf("%3d", $i) ); // construction du corps du tableau $lines[] = array( "CURRENT_LINE_NUMBER" => "$i", "CURRENT_LINE_NUMBER_FIRST_COL" => sprintf("%3d", $i) ); $currentLine = array(); // nouvelle ligne de resultat for ($j = 1; $j <= $max; $j++) { $currentLine[] = array( "RESULT" => sprintf("%3d", $i * $j) ); } //enregistrement de la nouvelle ligne avec le meme nom que celui d'appel dans le template $action->lay->setBlockData("LINE_$i", $currentLine); } $action->lay->setBlockData("LINES", $lines); $action->lay->setBlockData("FIRST_LINE", $firstLine); header('Content-Type: text/plain'); }
Le code ci-dessus met en place les blocs suivants :
-
FIRST_LINE: un bloc pour la première ligne, celui-ci contient les numéros de 1 à$max(le maximum), -
LINES: un bloc qui contient la liste des lignes, celui-ci contient la référence à la ligne en cours et le numéro de la ligne, -
LINE_$i: un bloc qui contient le contenu de chaque ligne, celui-ci contient les résultats pour chaque ligne et est enregistré avec une clef permettant au contenu du blocLINESde l'appeler.
Table de multiplications ----[BLOCK FIRST_LINE]----[ENDBLOCK FIRST_LINE] x|[BLOCK FIRST_LINE][X]|[ENDBLOCK FIRST_LINE] ====[BLOCK FIRST_LINE]====[ENDBLOCK FIRST_LINE] [BLOCK LINES][CURRENT_LINE_NUMBER_FIRST_COL])[BLOCK LINE_[CURRENT_LINE_NUMBER]][RESULT]|[ENDBLOCK LINE_[CURRENT_LINE_NUMBER]] ---+[BLOCK LINE_[CURRENT_LINE_NUMBER]]---+[ENDBLOCK LINE_[CURRENT_LINE_NUMBER]] [ENDBLOCK LINES]
Le template ci-dessus contient les éléments suivants :
- une première ligne de présentation qui duplique autant de fois que nécessaire
le pattern
----, - une seconde ligne qui présente les numéros de 1 à
$max(le maximum) séparés par|, - une troisième ligne de présentation qui duplique autant de fois que nécessaire
le pattern
====, - un bloc
LINESqui va dupliquer autant de fois que nécessaire les résultats, ce bloc appel un blocLINE_[CURRENT_LINE_NUMBER]qui contient le résultat, il produit en outre une ligne de présentation qui duplique autant de fois que nécessaire le pattern---+.
Lorsqu'on appelle l'action soit :
- en http :
?app=[APP_NAME]&action=[ACTION_NAME]&max=10, - en cli :
./wsh.php --app=[APP_NAME] --action=[ACTION_NAME] --max=10.
Le résultat obtenu est le suivant :
Table de multiplications -------------------------------------------- x| 1| 2| 3| 4| 5| 6| 7| 8| 9| 10| ============================================ 1) 1| 2| 3| 4| 5| 6| 7| 8| 9| 10| ---+---+---+---+---+---+---+---+---+---+---+ 2) 2| 4| 6| 8| 10| 12| 14| 16| 18| 20| ---+---+---+---+---+---+---+---+---+---+---+ 3) 3| 6| 9| 12| 15| 18| 21| 24| 27| 30| ---+---+---+---+---+---+---+---+---+---+---+ 4) 4| 8| 12| 16| 20| 24| 28| 32| 36| 40| ---+---+---+---+---+---+---+---+---+---+---+ 5) 5| 10| 15| 20| 25| 30| 35| 40| 45| 50| ---+---+---+---+---+---+---+---+---+---+---+ 6) 6| 12| 18| 24| 30| 36| 42| 48| 54| 60| ---+---+---+---+---+---+---+---+---+---+---+ 7) 7| 14| 21| 28| 35| 42| 49| 56| 63| 70| ---+---+---+---+---+---+---+---+---+---+---+ 8) 8| 16| 24| 32| 40| 48| 56| 64| 72| 80| ---+---+---+---+---+---+---+---+---+---+---+ 9) 9| 18| 27| 36| 45| 54| 63| 72| 81| 90| ---+---+---+---+---+---+---+---+---+---+---+ 10) 10| 20| 30| 40| 50| 60| 70| 80| 90|100| ---+---+---+---+---+---+---+---+---+---+---+
17.11.1.2 Zone applicatives
Ce chapitre aborde la construction de zones applicatives. Cette mécanique est notamment utilisée pour pouvoir mutualiser un élément d'interface entre différentes parties d'une application. Il est à noter que cet élément est très proche des zones documentaires.
Pour créer une zone, il faut deux éléments :
- un template obligatoire, celui-ci doit être dans le sous répertoire
Layoutde l'action et porter le même nom que celui de la zone avec l'extensionxml, - un contrôleur, celui-ci doit être contenu dans un fichier
phpqui porte le même nom que la zone et que la fonction.
Note : La casse et le format des fichiers sont similaires aux zones documentaires.
Il est de plus possible de passer des paramètres aux zones, veuillez consulter le chapitre des zones documentaires pour plus d'informations sur ce point.
L'exemple que l'on va prendre consiste à injecter un entête sur toutes les pages, cet entête contient le nom du client et la date du jour.
Soit les fichiers suivants :
APP/header.php
<?php function begin(Action $action) { $date = date("D, d M Y H:i:s"); $action->lay->set("DATE",$date); }
APP/Layout/header.xml
Cogip ([DATE])
Dans le template de l'action, la zone est appelée de la manière suivante
[ZONE APP:HEADER]
La zone est inclue dans le template précédent :
Table de multiplications ----[BLOCK FIRST_LINE]----[ENDBLOCK FIRST_LINE] x|[BLOCK FIRST_LINE][X]|[ENDBLOCK FIRST_LINE] ====[BLOCK FIRST_LINE]====[ENDBLOCK FIRST_LINE] [BLOCK LINES][CURRENT_LINE_NUMBER_FIRST_COL])[BLOCK LINE_[CURRENT_LINE_NUMBER]][RESULT]|[ENDBLOCK LINE_[CURRENT_LINE_NUMBER]] ---+[BLOCK LINE_[CURRENT_LINE_NUMBER]]---+[ENDBLOCK LINE_[CURRENT_LINE_NUMBER]] [ENDBLOCK LINES]
Voici le résultat obtenu :
Cogip (Mon, 04 Nov 2013 12:49:00) Table de multiplications -------------------------------------------- x| 1| 2| 3| 4| 5| 6| 7| 8| 9| 10| ============================================ 1) 1| 2| 3| 4| 5| 6| 7| 8| 9| 10| ---+---+---+---+---+---+---+---+---+---+---+ 2) 2| 4| 6| 8| 10| 12| 14| 16| 18| 20| ---+---+---+---+---+---+---+---+---+---+---+ 3) 3| 6| 9| 12| 15| 18| 21| 24| 27| 30| ---+---+---+---+---+---+---+---+---+---+---+ 4) 4| 8| 12| 16| 20| 24| 28| 32| 36| 40| ---+---+---+---+---+---+---+---+---+---+---+ 5) 5| 10| 15| 20| 25| 30| 35| 40| 45| 50| ---+---+---+---+---+---+---+---+---+---+---+ 6) 6| 12| 18| 24| 30| 36| 42| 48| 54| 60| ---+---+---+---+---+---+---+---+---+---+---+ 7) 7| 14| 21| 28| 35| 42| 49| 56| 63| 70| ---+---+---+---+---+---+---+---+---+---+---+ 8) 8| 16| 24| 32| 40| 48| 56| 64| 72| 80| ---+---+---+---+---+---+---+---+---+---+---+ 9) 9| 18| 27| 36| 45| 54| 63| 72| 81| 90| ---+---+---+---+---+---+---+---+---+---+---+ 10) 10| 20| 30| 40| 50| 60| 70| 80| 90|100| ---+---+---+---+---+---+---+---+---+---+---+
Note : Il est possible d'appeler des zones dans des zones ce qui permet de composer des interfaces complexes.
17.11.2 Encodage pour format HTML et XML
17.11.2.1 Introduction
Lors de la génération d'une page HTML ou XML contenant des données externes, il est important d'encoder correctement les données externes de tel manière que celles-ci ne soient pas considérée comme une partie du XML ou du HTML mais bien comme du texte.
Le moteur de template de Dynacase met à disposition deux méthodes permettant d'encoder du texte : Layout::eSet(), Layout::eSetBlockData().
Ces méthodes permettent d'encoder les chaînes de caractères intégrées dans un template pour que celles-ci ne soient pas considérées comme du XML valide mais comme du texte.
On peut donc les considérer comme une protection contre les failles de types XSS.
17.11.2.2 Avertissements
Les méthodes Layout::eSet(), Layout::eSetBlockData() ne doivent être utilisées que dans le cas d'affectation d'une variable dont on sait que le contenu est du texte. Si le contenu attendu est du HTML ou XML, il faut utiliser set.
Dans le cas de la production de XML, il faut penser à ajouter les entités nécessaires.
De plus, les & dans les URL doivent être encodés en &
17.11.2.3 Exemple
Soit une action permettant de montrer à un utilisateur le titre de son animal préféré, le code est le suivant :
Code PHP :
require_once "FDL/freedom_util.php"; function zoo_favorite(Action & $action) { $doc = new_Doc("", "FAVORITE"); $action->lay->set("TITRE", $doc->getTitle()); }
Layout :
<!doctype html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Document</title> </head> <body> Bonjour ! Ceci est le titre de votre document animal préféré : <strong>[TITRE]</strong>. </body> </html>
Si le nom du document animal favoris est Clovis.
La page suivante est obtenue :
<!doctype html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Document</title> </head> <body> Bonjour ! Ceci est le titre de votre document animal préféré : <strong>Clovis</strong>. </body> </html>
Maintenant, si le nom est : <a>Mon Préféré
La page suivante est obtenue :
<!doctype html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Document</title> </head> <body> Bonjour ! Ceci est le titre de votre document animal préféré : <strong><a>Mon Préféré</strong>. </body> </html>
Ce qui donne :

Figure 117. Html mal encodé
Cette page a deux défauts :
- lorsqu'elle est rendu, on ne voit plus le
<a>car il a été interprété comme du HTML, - ce n'est pas du HTML valide car elle contient une balise
<a>mais pas de balise fermante</a>.
Nous allons faire évoluer notre code PHP, en utilisant au lieu de Layout::set() la méthode Layout::eSet().
On a donc le PHP suivant :
require_once "FDL/freedom_util.php"; function zoo_favorite(Action & $action) { $doc = new_Doc("", "FAVORITE"); $action->lay->eSet("TITRE", $doc->getTitle()); }
Et on génère le HTML suivant :
<!doctype html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Document</title> </head> <body> Bonjour ! Ceci est le titre de votre document animal préféré : <strong><a>Mon Préféré</strong>. </body> </html>
Ce qui donne :

Figure 118. Html bien encodé
La partie <a> a été encodée et apparaît dans le HTML comme <a> et est
rendue sous la forme suivante <a>.
17.11.3 Liste des balises utilisables en texte
17.11.3.1 Valeurs atomiques
Syntaxe :
[V_<attr-name>] [<tag>]
La valeur est la valeur positionnée par la méthode set().
Si la balise est de la forme V_<attr-name> et que <attr-name> est un
attribut du document, alors la valeur est celle de l'attribut <attr-name> du
document.
17.11.3.2 Valeurs multiples
Syntaxe :
[BLOCK <tag>]...[ENDBLOCK <tag>]
Les balises contenues dans une balise de bloc prennent les valeurs spécifiés
par la méthode setBlockData().
L'évaluation d'un bloc est récursive, et les blocs résultants de l'évaluation d'un bloc sont alors évalués à leur tour.
17.11.3.3 Conditions
Syntaxe :
[IF <tag>]...[ENDIF <tag>] [IFNOT <tag>]...[ENDIF <tag>]
Le contenu des balises conditionnelles est évalué, ou non, en fonction de la
valeur du TAG positionnée par la méthode set().
La valeur positionnée par set() doit être une valeur booléenne PHP :
true ou false.
17.11.3.4 Internationalisation de texte
Syntaxe :
[TEXT:<msg-id>]
La valeur est le message d'internationalisation correspondant à la clef
<msg-id>.
17.11.3.5 Images
Syntaxe :
[IMG:<img-filename>] [IMG:<img-filename>|<img-width>]
La valeur est une URL permettant d'accéder à l'image <img-filename>
spécifiée.
Le chemin <img-filename> peut être le chemin d'un fichier image relatif à la
racine du contexte, ou bien un nom de fichier qui sera recherché de la manière
suivante :
- recherche dans le répertoire
Imagesde l'application courante (e.g.img.pngest alors cherché dansFOO/Imagespour l'application couranteFOO) ; - si le fichier n'est pas trouvé et que l'application à des applications
parentes, alors le fichier est recherché dans le répertoire
Imagesdes applications parentes. - si le fichier n'est pas trouvé, alors le fichier est recherché dans le
répertoire
Imagesà la racine du contexte (e.g.Images/img.png) - si le fichier n'est pas trouvé, alors l'image
CORE/Images/noimage.pngest utilisé à la place.
Si |<width> est présent, alors l'image est redimensionnée à la largeur
width demandée. Les proportions sont conservés par le redimensionnement.
17.11.3.6 Zone
Syntaxe :
[ZONE <app-name>:<action-name>?<arg>=<val>&...]
La valeur est le résultat de l'exécution de l'action <action-name> de
l'application <app-name> avec les arguments (<arg>=<val>&...) spécifiés.
17.11.3.7 JavaScript
Syntaxe :
[JS:REF] [JS:CODE] [JS:CODENLOG]
Pour [JS:REF], la valeur est un ensemble d'éléments HTML
<script type="text/javascript" language="JavaScript" src="..." /> pour
charger le script logmsg.js et les scripts JavaScript ajoutés via la méthode
addJsRef().
Pour [JS:CODE], la valeur est une chaîne de caractère contenant les
instructions JavaScript ajouté via la méthode addJsCode, et un
code permettant d'afficher une alerte JavaScript des messages de log retournés
par l'action. L’élément HTML <script type="text/javascript" language="JavaScript"/>
n'est pas présent dans la valeur, par conséquent, il faut vous entouriez cet
élément par les tables HTML <script> et </script> (e.g.
<script ...>[JS:CODE]</script>).
Pour [JS:CODENLOG], la valeur retournée est identique à [JS:CODE] à
l'exception du code permettant d'afficher l'alerte JavaScript des messages de
log retournés par l'action qui n'est pas présent.
17.11.3.8 Règles de style CSS
Syntaxe :
[CSS:REF] [CSS:CUSTOMREF] [CSS:CODE]
Pour [CSS:REF], la valeur est un ensemble d'éléments HTML <link
rel="stylesheet" ... /> pour charger le fichier CSS css/dcp/system.css et les
fichiers CSS ajoutés via la méthode addCssRef().
Pour [CSS:CUSTOMREF], la valeur est identique à [CSS:REF] à l'exception du
fichier CSS css/dcp/system.css qui n'est pas présent.
Pour [CSS:CODE], la valeur est une chaîne de caractère contenant les règles
CSS ajoutés via la méthode addCssCode(). L'élément HTML
<style/> n'est pas présent dans la valeur, par conséquent, il faut que vous
entouriez cet élément par les tags HTML <style> et </style>
(e.g. <style>[CSS:CODE]</style>).
17.11.4 Représentations openDocument Text (odt)
Ce chapitre fait suite au chapitre Vue de document ODT et il aborde les éléments de mise en page avancés.
17.11.4.1 Utilisation d'un contrôleur spécifique pour odt
Il est possible d'utiliser un contrôleur spécifique pour pouvoir mieux contrôler ce qui est inclut dans un template, notamment en composant de nouvelles clefs ou en ajoutant des répétables.
Les principes de fonctionnement sont décrits dans le chapitre contrôle de vue des layouts.
Le contrôleur spécifique peut être soit :
- dans une méthode de la classe associée pour un ODT qui est associé à un document,
- dans un fichier dans le cas d'une zone applicative.
Dans les vues de document, le contrôleur par défaut est le même
que pour les vues standards. Les variables [V_XXX] sont générées pour être
utilisées dans un template ODT. L'argument target de la méthode
Doc::viewAttr() générant ces variables doit être égale à ooo pour
produire des valeurs conformes à l'insertion dans un template ODT.
Exemple d'un contrôleur spécifique d'une vue de document appelant la création des variables associées aux valeurs d'attributs.
public function myOdtController($target) { $this->viewAttr($target); // l'argument $target sera égale à `ooo` lors de // l'appel de cette méthode dans le cadre d'une vue // de document ODT $this->lay->eSet("my_key", "Hello"); }
17.11.4.2 Utilisation du contrôleur pour template ODT
17.11.4.2.1 Précautions d'usage
Les templates ODT manipulent des données XML. La syntaxe des template XML est plus rigoureuse que les template HTML. Les fichiers générés peuvent être invalides si les données insérées ne sont pas conformes aux contraintes imposées par le format XML.
Voir la liste des limitations des ODT.
17.11.4.2.2 Affectation de variables
La classe PHP de manipulation de template est la classe OooLayout qui dérivé de la
classe Layout.
Les précautions d'usages sont les suivantes :
-
lors de l'affectation d'une variable, il ne faut pas que celle-ci corrompe le XML pour ce faire, on peut :
-
utiliser la fonction d'affectation dédiée :
$this->lay->eSet("VAR", $var);
-
encoder par avance la valeur avant de l'insérer :
$society = $this->lay->xmlEntities("Bob & Compagnie"); $this->lay->set("SOCIETY",$society);
-
ou encore si la valeur provient d'un document :
$myAnimal = new_Doc("", "MY_ANIMAL"); $name = $myAnimal->getValue("animal_name"); $name = $myAnimal->getOooValue($myAnimal->getAttribute("the_name"), $name); $this->lay->set("MY_ATTR",$name);
-
Note : La méthode set permet d'insérer du
XML dans l'ODT, comme dans l'exemple ci-dessous :
$society="Bob <text:line-break/> Compagnie" ; $this->lay->set("SOCIETY",$society) ; // insertion d'un retour à la ligne
Note : La valeur null est considérée comme non-instanciée, comme dans
l'exemple ci-dessous :
$this->lay->set("KEY",null) ; // [KEY] non remplacé $this->lay->set("KEY",'') ; // [KEY] effacé
17.11.4.2.3 Affectation des répétables
Les templates ODT peuvent gérer les éléments multiples. Le chapitre répétables des vues ODT indique les différentes possibilités d'emplacement des répétables.
L'affectation de valeurs multiples passe par deux méthodes :
-
OOoLayout::setColumn: Cette méthode prend en entrée une clef et un array. Si la clef est déclarée dans une liste ou un tableau alors une entrée est ajoutée par valeur dans le tableau, -
OOoLayout::setRepeatable: Cette méthode prend une matrice en entrée (array de array). La méthode rend alors toutes les colonnes du tableau à la même taille que la plus grande des colonnes et ajoute les colonnes ainsi créées grâce àOOoLayout::setColumn.
/** * @templateController */ public function viewtest() { $repeatable[] = array( "V_X1"=>'A', "V_X2"=>'1', "V_X3"=>"La" ); $repeatable[] = array( "V_X1"=>'B', "V_X4"=>'2', "V_X3"=>"Si" ); $repeatable[]=array( "V_X1"=>'C', "V_X2"=>'3', "V_X3"=>"Do" ); $this->lay->setRepeatable($repeatable); $columnsValue = array('a','b','c','d'); $this->lay->setColumn("V_XXX",$columnsValue); }
Le template :

Figure 119. template
donne le fichier :
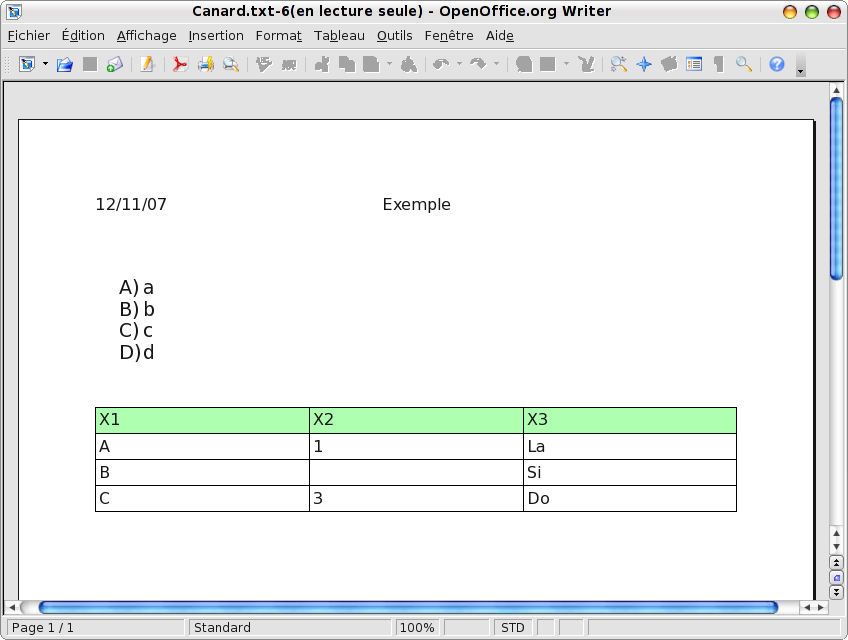
Figure 120. résultat
17.11.4.2.4 Utilisation du type Htmltext
Il n'y a pas de concordances entre les balises HTML et l'openText. Seul un sous ensemble des balises HTML est supporté, ci-dessous est présentée la table d'équivalence présentant les balises supportées et leur équivalent ODT.
| balise HTML | balise ODT | description | restriction |
|---|---|---|---|
p |
text:p |
Insère un paragraphe | La balise <p> doit être au premier niveau. |
div |
text:p |
Insère un paragraphe | Pour les <div> de premier niveau. |
div > div |
text:span |
Insère un texte | Pour les <div> de niveau inférieur. |
br |
text:line-break |
Insère un retour à la ligne | Doit être dans une balise <p> ou <td>
|
em/i |
text:span |
Insèrent un texte avec le style "italique" | Doit être dans une balise <p> ou <td>
|
strong/b |
text:span |
Insèrent un texte avec le style "gras" | Doit être dans une balise <p> ou <td>
|
u |
text:span |
Insère un texte avec le style "souligné" | Doit être dans une balise <p> ou <td>
|
sup |
text:span |
Insère un texte avec le style "exposant" | Doit être dans une balise <p> ou <td>
|
sub |
text:span |
Insère un texte avec le style "index" | Doit être dans une balise <p>
|
a |
text:a |
Insère un hyperlien | Doit être dans une balise <p> ou <td>
|
h1 |
text:h |
Insère un titre de niveau 1 | Le style du texte sera celui de "Titre 1" |
h2 |
text:h |
Insère un titre de niveau 2 | Le style du texte sera celui de "Titre 2" |
h3 |
text:h |
Insère un titre de niveau 3 | Le style du texte sera celui de "Titre 3" |
h4 |
text:h |
Insère un titre de niveau 4 | Le style du texte sera celui de "Titre 4" |
li |
text:list-item |
Insère un élément de liste | Doit être dans une balise <ul> ou <ol>
|
ul |
text:list |
Insère une liste à puces non numérotée | Doit être dans une balise <p> ou <td>
|
ol |
text:list |
Insère une liste à puces numérotée | Doit être dans une balise <p> ou <td>
|
table |
table:table |
Insère un tableau | Les tables ne doivent pas contenir de rowspan et colspan, chaque rangée doit avoir le même nombre de cellule. |
tr |
table:table-row |
Insère une rangée tableau | |
th |
table:table-cell |
Insère une cellule entête de tableau | Les cellules de header doivent être dans la première rangée du tableau |
td |
table:table-cell |
Insère une cellule tableau | Les colspan et rowspan et autres attributs de l'attribut html ne sont pas pris en compte. |
img |
draw:frame |
Insère une image | Seules les images présentes sur les paragraphes de premier niveau sont prises en compte. Pas d'image dans les cellules de tableau. |
17.11.4.2.4.1 Restrictions supplémentaires pour les images
3.2.19
Seules les propriétés de style width et height sont prises en compte. Pour
ces deux propriétés de style, seules les unités "px", "mm" et "cm" sont prises
en compte.
La taille d'une image sur un document openDocument ne peut pas être exprimée en "px" (pixel). Les "px" seront convertis en "mm" avec le ratio suivant "1px => 0.1875 mm". Seule la partie entière des millimètres est conservées.
Les images sont ancrées au texte comme caractère.
Pour les images issues de fichiers internes (fichier image inséré dans un
attribut de type image), ces images sont inclues dans le fichier
openDocument produit. Si au moment de la production du fichier, les images
internes n'existent plus ou si elles ne sont pas autorisées à la lecture pour
l'utilisateur courant une image de substitution sera affichée à la place.
Si l'image interne est modifiée, elle ne sera pas modifiée sur le fichier déjà produit. La nouvelle image ne pourra être visible sur le fichier résultat qu'en cas de regénération de celui-ci.
Pour les images dont la source est externe à Dynacase, l'image insérée est liée à l'image cible, elle n'est pas copiée. Cela induit que l'image doit être accessible depuis le poste où le fichier produit est lu.
De même, si le fichier résultat est utilisée pour une transformation PDF via le moteur de transformation. il est nécessaire que le serveur openOffice est accès à l'image externe pour l'insérer dans le fichier PDF produit.
17.11.4.2.4.2 Gestion des caractères de contrôle
Conformément à la spécification XML, certains caractères de contrôle ne sont pas supportés. Dynacase remplace ces caractères par le pictogramme unicode leur correspondant.
17.11.4.2.4.3 Exemple 1 - Paragraphe
Le code HTML
<p>Bonjour</p>
donne le code XML suivant :
<text:section text:style-name="Secttxt_text" text:name="Sectiontxt_text" aid="txt_text"> <text:p>Bonjour</text:p> </text:section>
17.11.4.2.4.4 Exemple 2 - Liste à puces
Le code HTML
<ul> <li>élement 1</li> <li>élement 2</li> </ul>
donne le code XML suivant :
<text:section text:style-name="Secttxt_text" text:name="Sectiontxt_text" aid="txt_text"> <text:list text:style-name="LU"> <text:list-item> <text:p text:style-name="L1">élement 1</text:p> </text:list-item> <text:list-item> <text:p text:style-name="L1">élement 2</text:p> </text:list-item> </text:list> </text:section>
17.11.4.2.4.5 Exemple 3 - Division
Le code HTML
<div>Bonjour</div>
donne le code XML suivant :
<text:section text:style-name="Secttxt_text" text:name="Sectiontxt_text" aid="txt_text"> <text:p>Bonjour</text:p> </text:section>
17.11.4.2.4.6 Exemple 4 - Gras et italique
Le code HTML
<div> <strong>Bonjour</strong> <br/> <em>le monde</em> </div>
donne le code XML suivant :
<text:section text:style-name="Secttxt_text" text:name="Sectiontxt_text" aid="txt_text"> <text:p> <text:span text:style-name="Tbold">Bonjour</text:span> <text:line-break/> <text:span text:style-name="Titalics">le monde</text:span> </text:p> </text:section>
17.11.4.2.4.7 Exemple 5 - Titre de niveau
Le code HTML
<h1>Titre 1</h1> <h2>Titre 2</h2> <p>Mon paragraphe</p>
donne le code XML suivant :
<text:section text:style-name="Secttxt_text" text:name="Sectiontxt_text" aid="txt_text"> <text:h text:outline-level="1">Titre 1</text:h> <text:h text:outline-level="2">Titre 2</text:h> <text:p>Mon paragraphe</text:p> </text:section>
17.11.4.2.4.8 Exemple 6 - Tableau
Le code HTML
<table> <tbody> <tr> <td>Cellule un</td> <td>Cellule deux</td> </tr> </tbody> </table>
donne le code XML suivant :
<text:section text:style-name="Secttxt_text" text:name="Sectiontxt_text" aid="txt_text"> <table:table table:name="Table1" table:style-name="Table1"> <table:table-column table:style-name="Table1.A" table:number-columns-repeated="2"/> <table:table-row> <table:table-cell table:style-name="Table1.A1"> <text:p>Cellule un</text:p> </table:table-cell> <table:table-cell table:style-name="Table1.A1"> <text:p>Cellule deux</text:p> </table:table-cell> </table:table-row> </table:table> </text:section>
17.11.4.2.4.9 Exemple 7 - Image
3.2.19 Le code HTML
<p>Début <img alt="" src="file/64367/4181/img_file/-1/dialog-yes.png?cache=no&inline=no" style="height:16px; width:16px" /> et fin. </p>
donne le code XML suivant :
<text:section text:style-name="Secttxt_text" text:name="Sectiontxt_text"> <text:p text:style-name="P1">Début <draw:frame draw:style-name="fr1" draw:name="htmlgraphic" text:anchor-type="as-char" svg:width="3mm" svg:height="3mm" draw:z-index="0"> <draw:image xlink:href="Pictures/dcp4181.png" xlink:type="simple" xlink:show="embed" xlink:actuate="onLoad"/> </draw:frame>et fin. </text:p> </text:section>
17.11.4.2.4.10 Exemple 8 - Cas d'erreur
Le code HTML
<div> <div class="my-class">Bonjour</div> <div>le monde</div> </div>
donne le code XML suivant :
<text:section text:style-name="Secttxt_text" text:name="Sectiontxt_text" aid="txt_text"> <text:p> <text:p>Bonjour</text:p> <text:p>le monde</text:p> </text:p> </text:section>
Ce code XML n'est pas conforme au schéma d'un document openDocument Text. Un paragraphe ne peut pas contenir d'autres paragraphes.
17.11.4.3 Répétables multi-niveaux
Il est possible d'insérer plusieurs niveaux de structures multiples. Ce contrôle des répétables s'appuie sur les méthodes présentées dans le chapitre affectation des répétables.
17.11.4.3.1 Possibilités et limitations
Il est possible d'avoir :
- des tableaux dans des tableaux,
- des tableaux dans des sections,
- des sections dans des tableaux,
- des listes dans des tableaux,
- des listes dans des sections.
Il n'est pas possible d'avoir :
- des listes avec des sous/listes,
- des tableaux dans des listes,
- des sections dans des listes.
17.11.4.3.2 Exemples
Les deux exemples suivant montrent comment réaliser des templates à plusieurs niveaux d'imbrications.
Le premier exemple illustre comment insérer des tables et des sous-tables. Le deuxième exemple montre comment utiliser les sections openDocument pour produire des paragraphes avec leur sous-paragraphes.
17.11.4.3.2.1 Exemple à deux niveaux d'imbrications :
public function testfruit($target) { $this->lay->set("TODAY", $this->getTimeDate()); $repeatColor[] = array( "COLOR"=>"jaune", "VEGETABLE"=>array("pomme","banane"), "DESCR"=>array("pommier", "bananier") ); $repeatColor[] = array( "COLOR"=>"rouge", "VEGETABLE"=>array("cerise","fraise"), "DESCR"=>array("Cerisier","Fraisier") ); $repeatColor[] = array( "COLOR"=>"vert", "VEGETABLE"=>array("concombre","cornichon","poivron"), "DESCR"=>array("Plante potagère", "Condiment","Capsicum annuum")); $this->lay->setRepeatable($repeatColor); }
Le template :

Figure 121. template
donne le fichier :

Figure 122. résultat
17.11.4.3.2.2 Exemple à trois niveaux d'imbrications :
/** *@templateController */ function testfruit($target) { $this->lay->set("TODAY",$this->getTimeDate()); $repeatColor[] = array( "COLOR" => "jaune", "VEGETABLE" => array("pomme","banane"), "VARIETY" => array( array("granny", "fuji","golden"),array("plantain") ) ); $repeatColor[] = array( "COLOR" => "rouge", "VEGETABLE" => array("cerise","fraise"), "VARIETY" => array( array("bigarreau","griotte"), array("mara des bois","agate","anabelle") ) ); $repeatColor[] = array( "COLOR"=>"vert", "VEGETABLE"=>array("concombre","cornichon","poivron"), "VARIETY"=>array( array("gynial","Cucumis sativus"), array("vert de paris"), array("doux sonar","jericho") ) ); $this->lay->setRepeatable($repeatColor); }
Le template :
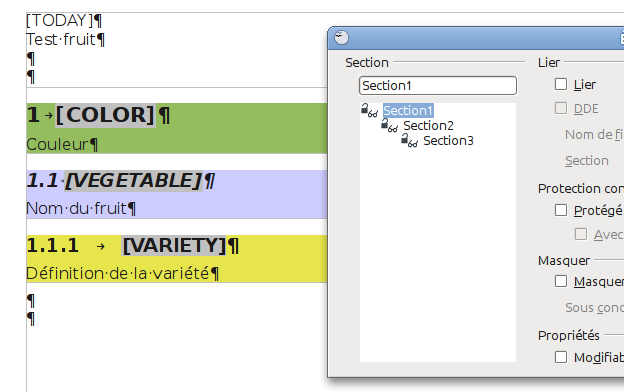
Figure 123. template
donne le fichier :
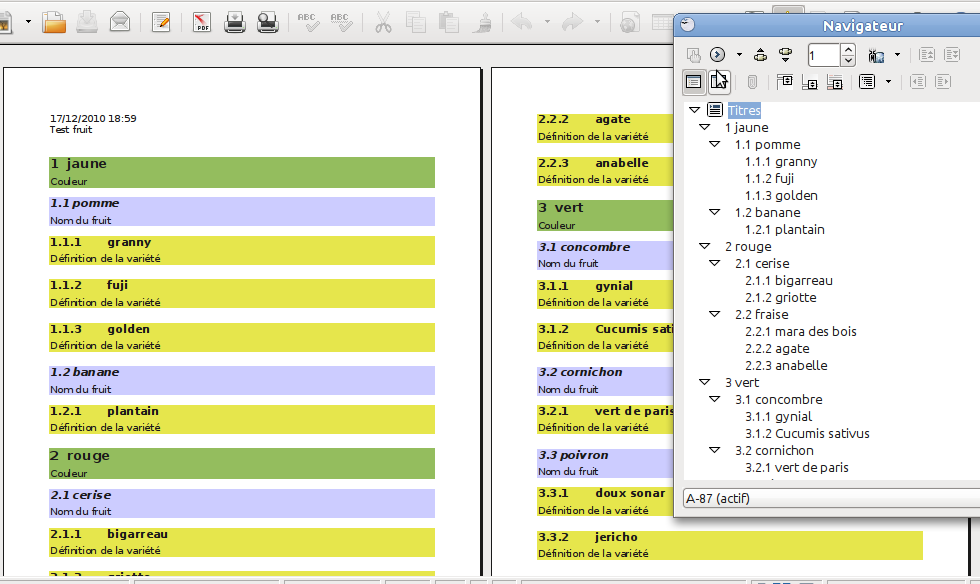
Figure 124. résultat
Note : Ici il faut bien imbriquer les sections pour être conforme à la
structure du répétable défini dans le code (Niveau 1 : COLOR, Niveau 2 :
VEGETABLE, Niveau 3 : VARIETY).
17.11.4.4 Mise à jour des propriétés du document
Les variables [V_XXX] sont interprétées dans les propriétés du document OpenOffice (titre, sujet, commentaires, propriétés personnalisées, etc.). Ils sont pris en compte et remplacés à la génération.
Note : les propriétés sont dans le fichier meta.xml d'une archive
openDocument.
17.11.4.4.1 Limitation
Les répétables ne sont pas gérés dans les propriétés du document.
17.11.5 Vues de consultation avec transformation
Il est conseillé de lire le chapitre sur les vues avant ce chapitre.
Il est possible de déclencher un mécanisme de transformation d'une vue après sa consultation. C'est à dire d'utiliser le moteur de transformation pour convertir le format d'une vue binaire ou textuel dans un autre format (par exemple convertir un odt produit en pdf).
17.11.5.1 Pré-requis
Il faut que le contexte sur lequel on souhaite mettre en place cette technique
puisse accéder à un moteur de transformation qui possède le
engine nécessaire pour effectuer cette transformation.
17.11.5.2 Mise en place
Il suffit d'ajout en suffixe de l'URL d'appel l'engine voulu. Ce qui donne :
?app=FDL&action=FDL_CARD&id=9&zone=FDL:viewperson.odt:B:pdf
Ce qui permet de voir le document ayant l'identifiant n°9 avec la vue définie
par viewperson.odt en binaire (fichier openDocument Text) et converti en pdf.
Note : l'option B dans le nom de la zone est obligatoire pour utiliser la
transformation, car la vue utilisée doit retourner un nom de fichier et non un
contenu.
Par défaut le moteur de transformation met à disposition les
engines suivants :
-
pdf: il peut être utilisé pour convertir un odt ou un HTML en pdf. Attention : toutefois la conversion du HTML reste assez basique et l'ensemble des propriétés CSS ne sont pas supportées, -
pdfa: il a les mêmes possibilités que le moteur pdf mais fourni un pdf prêt pour archivage (avec inclusion des polices de caractères).
17.11.6 Mise en forme d'une collection de documents
17.11.6.1 Collection de documents
Les collections de documents sont, comme évoqués dans le chapitre d'introduction, des ensembles de documents statiques (répertoires) ou dynamiques (recherches).
17.11.6.2 Classe de formatage
La classe FormatCollection facilite la mise en forme de ces ensembles de
documents pour leur utilisations ultérieures (exportation ou interface homme-
machine).
17.11.6.3 Liste des paramètres entrants
Le classe prend en entrée des objets DocumentList
Exemple pour le formatage des documents 9 et 12.
$documentList=new DocumentList(); $documentList->addDocumentIdentifiers(array(9,12)); // $formatCollection =new FormatCollection(); $formatCollection->useCollection($documentList); $render=$formatCollection->render();
: les objets
DocumentList peuvent être initialisés soit avec des id,
soit avec des objets SearchDoc.
17.11.6.4 Sortie
Le résultat du "render" donne un tableau avec une entrée par document formaté.
Par défaut seul le titre et l'identifiant (id) sont retournés, aucun attribut
n'est utilisé. Chaque entrée contient un champ "properties" indiquant les
propriétés et un champ "attributes" contenant les attributs. Ce dernier est
vide si aucun attribut n'a été indiqué dans le formatage.
Array ( [0] => Array ( ["properties"] => Array ( ["id"] => 12 ["title"] => "les profils" ) ) [1] => Array ( ["properties"] => Array ( ["id"] => 9 ["title"] => "Racine" ) ) )
3.2.18 Les documents ayant des
attributs en visibilité I ne sont pas exportés par défaut. La
méthode ::setVerifyAttributeAccess(false) permet d'exporter sans tenir compte
de la visibilité I.
17.11.6.5 Formatage des propriétés
Les propriétés accessibles sont les suivantes :
les propriétés brutes : ensemble des propriétés d'un document,
les propriétés formatées :
-
url: URL d'accès en visualisation du document, -
family: informations sur la famille du document, cette structure contient le- titre de la famille (
title), - le nom logique (
name), - l'identifiant (numérique) (
id), - l'adresse de téléchargement de l'icône (
icon),
- titre de la famille (
-
creationDate: date de création de la lignée documentaire, -
createdBy: informations sur le créateur de la lignée documentaire, cette structure contient- le nom du créateur (
title), - le nom logique du document lié au compte du créateur (
name), - l'identifiant (numérique) (
id), - l'adresse de téléchargement de l'icône (
icon) du document représentant le créateur,
- le nom du créateur (
-
revisionData: informations sur la révision du document, cette structure contient :- un booléen indiquant si le document a été modifié (
isModified) depuis sa dernière révision, - son identifiant (
id), - son numéro de révision (
number), - les informations sur le créateur de la révision (
createdBy), cette structure est similaire àcreatedBy,
- un booléen indiquant si le document a été modifié (
-
viewController: informations sur la vue en cours d'application, cette structure contient- l'identifiant du contrôle de vue (
id), - son titre (
title),
- l'identifiant du contrôle de vue (
-
workflow: informations sur le cycle de vie associé au document, cette structure contient- l'identifiant (
id), - le titre du cycle de vie (
title),
- l'identifiant (
-
tags: tag documentaire associés au document, cette structure est une liste de valeurs, -
security: information liées aux droits du documents, cette structure contient-
lock: verrou. La propriété contient :-
ididentifiant du verrou, -
temporary: indique si le verrou est temporaire ou permanent, -
lockedBy: identifiant du compte de l'utilisateur ayant verrouillé le document,
-
-
readOnly: un booléen indiquant si le document est en lecture seule , -
fixed:un booléen indiquant si le document est figé , -
profil: profil associé au document :-
id: identifiant du profil, -
icon: l'adresse de téléchargement de l'icône du profil , -
type: type :linked(lié) ouprivate(privé), -
activated: un booléen indiquant si le profil est activé , -
title: titre du profil,
-
-
confidentiality: sa confidentialité,
-
-
status: information sur le statut du document, trois valeurs sont possibles-
deleted: document supprimé, -
fixed: document figé, -
alive: document vivant,
-
-
note: liste des post-it associés au document, -
type: type du document, les valeurs suivantes sont possibles :-
document: document standard, -
folder: dossier : collection statique de documents, -
search: recherche : collection dynamique de documents, -
family: famille : définition d'une famille de documents, -
profil: profil : document de modèle de profil, -
workflow: document de cycle de vie,
-
-
state: état du document, cette structure contient :-
reference: clef de l'étape, -
color: couleur de l'étape, -
activity: activité de l'étape (vide si document est figé, - ancienne révision - ), -
stateLabel: libellé de l'état de l'étape, -
displayValue: libellé de l'étape. Il est égal à l'activité si le document est en dernière révision et si l'activité est déclarée sinon il est égal au libellé de l'état,
-
-
usage: Usage du document. Les valeurs suivantes sont possibles :-
normal: usage normal, -
system: document de configuration (exemple cycle de vie, profil).
-
Exemple :
$searchDoc=new SearchDoc('',"ZOO_TEST"); $searchDoc->setObjectReturn(); $documentList=$searchDoc->getDocumentList(); $formatCollection=new FormatCollection(); $formatCollection->useCollection($documentList); $formatCollection->addProperty($formatCollection::propState); $r=$formatCollection->render(); print_r($r);
Le résultat est :
["properties"] => Array ( ["id"] => 67978 ["title"] => "Nouga" ["state"] => statePropertyValue Object ( ["reference"] => "zoo_transmited" ["color"] => "#A8DF78" ["activity"] => "Vérification de l'adoption" ["stateLabel"] => "Transmis" ["displayValue"] => "Vérification de l'adoption" ) )
Un exemple de rendu de l'ensemble des propriétés sérialisé en JSON :
{ "id": 1289, "title": "2013-05-07", "adate": "2014-12-16 16:51:42", "affected": { "id": 0, "title": "" }, "allocated": null, "atags": null, "cdate": "2014-12-16 16:51:42", "confidential": null, "createdBy": { "id": 1008, "title": "Master Default", "icon": "resizeimg.php?img=Images%2Fdynacase-iuser.png&size=24" }, "creationDate": "2014-12-16 16:51:42", "cvid": null, "doctype": "F", "dprofid": "0", "family": { "title": "Entrée", "name": "ZOO_ENTREE", "id": 1059, "icon": "resizeimg.php?img=Images%2Fentree.gif&size=24" }, "fromid": "1059", "icon": "resizeimg.php?img=Images%2Fentree.gif&size=24", "initid": 1289, "lastAccessDate": "2014-12-16 16:51:42", "lastModificationDate": "2014-12-16 16:52:06", "lmodify": "Y", "locked": 0, "name": null, "note": { "id": 0, "title": "" }, "owner": "1", "postitid": null, "prelid": null, "profid": "1084", "revdate": "2014-12-16 16:52:06", "revision": 0, "revisionData": { "isModified": true, "id": 1289, "number": 0, "createdBy": { "id": 1008, "title": "Master Default", "icon": "resizeimg.php?img=Images%2Fdynacase-iuser.png&size=24" } }, "security": { "lock": { "id": 0 }, "readOnly": false, "fixed": false, "profil": { "id": 1084, "icon": "resizeimg.php?img=Images%2Fprofil.gif&size=24", "type": "linked", "activated": true, "title": "Caisse" }, "confidentiality": "public" }, "status": "alive", "tags": [], "type": "document", "usage": "normal", "usefor": "N", "version": null, "viewController": { "id": 0, "title": "" }, "wid": null, "workflow": { "id": 0, "title": "" } }
17.11.6.6 Formatage des attributs
Les valeurs des attributs se placent dans le tableau "attributes". Chacun des attributs a un champ "value" qui indique la valeur brute et "displayValue" qui indique la valeur affichable. Pour ajouter les attributs à formater, il faut utiliser la méthode "addAttribute".
$formatCollection=new FormatCollection(); $formatCollection->useCollection($documentList); $formatCollection->addAttribute("tst_title")->addAttribute("tst_double"); $r=$formatCollection->render();
Extrait de la partie "attributes"
[attributes] => Array ( ["tst_title"] => textAttributeValue Object ( ["value"] => "Le tour du monde" ["displayValue"] => "Le tour du monde" ) ["tst_double"] => doubleAttributeValue Object ( ["value"] => 3.14 ["displayValue"] => "3,14" )
: Si un attribut n'a pas de valeur, le formatage sera "null" quelque soit le type d'attribut.
Si un attribut n'existe pas la structure (value, displayValue) sera remplie avec la variable identifiée par la méthode "::setNc()".
$searchDoc=new SearchDoc('',"DIR"); $searchDoc->setObjectReturn(); $documentList=$searchDoc->search()->getDocumentList(); $formatCollection=new FormatCollection(); $formatCollection->useCollection($documentList); $formatCollection->setNc("nc"); $formatCollection->addProperty($formatCollection::propState); $formatCollection->addAttribute("tst_title")->addAttribute("ba_desc"); $r=$formatCollection->render();
Exemple avec un attribut "vide" (ba_desc) et un attribut inexistant.
[attributes] => Array ( ["tst_title"] => unknowAttributeValue Object ( ["value"] => "nc" ["displayValue"] => "nc" ) ["ba_desc"] => null )
Si l'option "showempty" est indiquée dans l'attribut, le rendu d'une valeur
nulle sera remplacée par la valeur de l'option.
17.11.6.7 Rendu des attributs
17.11.6.7.1 type text
["tst_text"] => textAttributeValue Object ( ["value"] => "Testing" ["displayValue"] => "before Testing" )
La valeur formatée tient compte du format mis dans le type dans cet exemple : text("before %s")
17.11.6.7.2 type int
[tst_int] => intAttributeValue Object ( ["value"] => 10 ["displayValue"] => "0010" )
La valeur formatée tient compte du format mis dans le type. Dans cet exemple : int("%04d"). La valeur est de type "int".
17.11.6.7.3 type double
[tst_double] => doubleAttributeValue Object ( ["value"] => 0 ["displayValue"] => "0,00" )
La valeur formatée tient compte du format mis dans le type. Dans cet exemple : double("%.02f"). Le point est transformé en virgule si la locale est "fr_FR". La valeur est de type "double".
17.11.6.7.4 type date
[tst_date] => dateAttributeValue Object ( ["value"] => "2012-06-08" ["displayValue"] => "08/06/2012" )
La valeur formatée tient compte du format mis dans le type. S'il n'y a pas de format, cela dépend du format de la locale de l'utilisateur.
17.11.6.7.5 type timestamp
[tst_ts] => dateAttributeValue Object ( ["value"] => "2012-06-13 11:27:00" ["displayValue"] => "13/06/2012 11:27" )
La valeur formatée tient compte du format mis dans le type. S'il n'y a pas de format, cela dépend du format de la locale de l'utilisateur.
17.11.6.7.6 type file
["tst_file"] => fileAttributeValue Object ( ["size"] => 572 ["creationDate"] => "2014-10-14 11:44:20" ["fileName"] => "iuserplus.csv" ["url"] => "file/13502/807/fi_ofile/1/iuserplus.csv?cache=no&inline=yes" ["mime"] => "text/plain" ["icon"] => "resizeimg.php?img=CORE%2FImages%2Fmime-txt.png&size=14" ["value"] => "text/plain|807|iuserplus.csv" ["displayValue"] => "iuserplus.csv" )
La valeur formatée est le titre du fichier.
Éléments retournés :
-
size: taille en octets du fichier -
creationDate: date d'enregistrement du fichier -
fileName: nom du fichier -
url: url de téléchargement du fichier -
mime: type mime du fichier -
icon: icône représentant le type de fichier -
value: valeur brute (référence au fichier) -
displayValue: nom du fichier
17.11.6.7.7 type image
["tst_img"] => imageAttributeValue Object ( ["thumbnail"] => "file/13505/810/img_file/-1/tree.jpg?cache=no&inline=yes&width=48" ["size"] => 584894 ["creationDate"] => "2014-10-14 13:59:30" ["fileName"] => "tree.jpg" ["url"] => "file/13505/810/img_file/-1/tree.jpg?cache=no&inline=yes" ["mime"] => "image/jpeg" ["icon"] => "resizeimg.php?img=CORE%2FImages%2Fmime-image.png&size=24" ["value"] => "image/jpeg|810|tree.jpg" ["displayValue"] => "tree.jpg" )
Éléments retournés :
-
thumbnail: url de téléchargement de la miniature de l'image -
size: taille en octets de l'image -
creationDate: date d'enregistrement de l'image -
fileName: nom de l'image -
url: url de téléchargement de l'image -
mime: type mime de l'image -
icon: icône représentant le type de l'image -
value: valeur brute (référence à l'image) -
displayValue: nom de l'image
Note : La largeur de la miniature peut être définie avec l'attribut
imageThumbnailSize de la classe FormatCollection. Elle est de 48px par défaut.
17.11.6.7.8 type docid - account
["tst_relation"] => docidAttributeValue Object ( ["familyRelation"] => "TST_FMTCOL" ["url"] => "?app=FDL&OPENDOC&mode=view&id=84412&latest=Y" ["icon"] => "resizeimg.php?img=Images/test.png&size=14" ["revision"] => -1 ["initid"] => 84412 ["value"] => "84412" ["displayValue"] => "Test 1" )
-
familyRelation: indique le format du type de relation. -
url: L'url permet d'accéder à la page de consultation du document. -
icon: La taille de l'icône du document pointé est par défaut de 14px. Elle peut être modifiée avec l'attributrelationIconSizede la classeFormatCollection. -
revision: 3.2.21 Contient le numéro de la révision si l'option "docrev=fixed".
Contient "state:<état>" si l'option est "docrev=state(<état>)".
Sinon contient-1pour indiquer que c'est la dernière révision qui doit être utilisée. -
initid: 3.2.21La propriétéinitiddu document cible -
value: La valeur brute indique l'identifiant numérique du document stocké. Il est généralement différent de l'initiden cas de lien vers une révision spécifique. -
displayValue: La valeur formatée indique le titre du document pointé.
17.11.6.7.9 type enum
["tst_enum"] => enumAttributeValue Object ( ["value"] => 1 ["displayValue"] => "Un" ["exists"] => true )
La valeur formatée donne le libellé de l'énuméré.
3.2.21 La propriété "exists" indique
si la valeur fait partie du référenciel de l'énuméré. Cette propriété peut être
false dans le cas de l'option etype=free : autorisation de pose
d'un autre choix par l'utilisateur.
17.11.6.7.10 type htmltext
Si le flag stripHtmlTags (méthode stripHtmlTags) est à true les balises
HTML sont supprimées dans la displayValue.
17.11.6.7.11 type longtext
3.2.18 Si l'attribut est dans un
array les séparateurs de cellules sont des sauts de lignes \n). Vous pouvez
les configurer à l'aide de la méthode setLongtextMultipleBrToCr.
17.11.6.7.12 Autres types
["x_attr"] => standardAttributeValue Object ( ["value"] => "12:20:00" ["displayValue"] => "12:20:00" )
La valeur et la valeur formatée sont égales.
17.11.6.8 Rendu des attributs multiples
Les attributs multiples sont rendus dans des tableaux de structure. Exemple avec deux valeurs de l'attribut "tst_colors".
["tst_colors"] => Array ( [0] => standardAttributeValue Object ( ["value"] => "#80CCFF" ["displayValue"] => "#80CCFF" ) [1] => standardAttributeValue Object ( ["value"] => "#FFD77A" ["displayValue"] => "#FFD77A" ) )
La même structure à deux niveaux est rendue pour les multiples dans les tableaux. Cela est limité à l'attribut docid.
[tst_relation_multiple] => Array ( [0] => Array ( [0] => docidAttributeValue Object ( ["familyRelation"] => "TST_FMTCOL" ["url"] => "?app=FDL&action=OPENDOC..." ["icon"] => ["initid"] => 84412 ["revision"] => -1 ["value"] => "84412" ["displayValue"] => "Test 1" ) ) [1] => Array ( [0] => docidAttributeValue Object ( ["familyRelation"] => "TST_FMTCOL" ["url"] => ?"app=FDL&action=OPENDOC..." ["icon"] => ["initid"] => 84412 ["revision"] => -1 ["value"] => "84412" ["displayValue"] => "Test 1" ) [1] => docidAttributeValue Object ( ["familyRelation"] => "TST_FMTCOL" ["url"] => "?app=FDL&action=OPENDOC..." ["icon"] => ["initid"] => 86854 ["revision"] => -1 ["value"] => "86854" ["displayValue"] => "Test 2" )
17.11.6.9 Hook de rendu
3.2.18 Le rendu proposé par la classe n'est pas toujours le rendu attendu par un outil externe, il est possible de modifier celui-ci en utilisant les hook de rendu.
17.11.6.9.1 Hook de document
Il est possible d'inscrire un hook qui est appliqué après le rendu de chaque document pour modifier le tableau formaté produit.
Exemple, ajout d'une URI particulière :
$formatCollection->setDocumentRenderHook(function ($values, \Doc $document) { $values["uri"] = sprintf("http://api.example.net/%s", $document->getPropertyValue("initid"); return $values; });
Le hook s'ajoute à l'aide de la fonction setDocumentRenderHook celle-ci prend
en entrée un callable et l'exécute à chaque rendu de document. La fonction
reçoit en entrée :
- values : le tableau de valeur calculé,
- document : l'objet document en cours.
Elle doit retourner l'objet values modifié.
17.11.6.9.2 Hook d'attribut
Il est possible d'inscrire un hook qui est appliqué après le rendu de chaque attribut pour modifier le rendu d'attribut produit.
Exemple, uniformisation des valeurs vides :
$formatCollection->setAttributeRenderHook(function ($attributeValue, $attribute) { if ($attributeValue === null) { /** * @var \NormalAttribute $attribute */ if ($attribute->isMultiple()) { $attributeValue = array(); } else { $attributeValue = new \StandardAttributeValue($attribute, null); } } return $attributeValue; });
Le hook s'ajoute à l'aide de la fonction setAttributeRenderHook celle-ci prend
en entrée un callable et l'exécute à chaque rendu d'attribut. La fonction reçoit
en entrée :
- attributeValue : la valeur de l'attribut calculé,
- attribute : l'objet attribut en cours,
- document : l'objet document en cours.
Elle doit retourner l'objet attributeValue modifié.
17.11.6.9.3 Hook de propriété
Il est possible d'inscrire un hook qui est appliqué après le rendu de chaque propriété pour modifier le rendu de la propriété.
Exemple, passage à false de la propriété state pour les documents n'ayant
pas d'état :
$formatCollection->setPropertyRenderHook(function ($propertyValue, $propertyId) { if ($propertyId === "state" && !$propertyValue->reference) { $propertyValue = false; } return $propertyValue; });
Le hook s'ajoute à l'aide de la fonction setPropertyRenderHook celle-ci prend
en entrée un callable et l'exécute à chaque rendu de propriété. La fonction
reçoit en entrée :
- propertyValue : la valeur de la propriété calculée,
- propertyId : identifiant de la propriété en cours,
- document : l'objet document en cours.
Elle doit retourner l'objet propertyValue modifié.
17.12 Les autres familles systèmes
Ce chapitre décrit les familles systèmes mise en place avec Dynacase.
17.12.1 Processus
La famille Processus (nom logique EXEC) permet de définir des tâches/
traitements à exécuter de manière récurrente.
Le traitement est soit :
- une actions,
- un script CLI.
17.12.1.1 Paramétrage
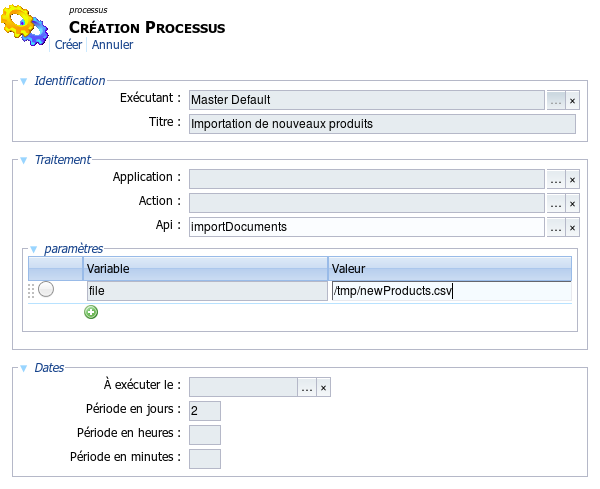
Figure 125. Formulaire de création de processus
Dans cette interface, vous pouvez définir les différentes options de lancement de l'action ou du script, ses références et ses paramètres d'exécutions.
De plus, il est possible de définir une première date d'exécution et une périodicité.
En outre, il est aussi possible de ne pas indiquer de date d'exécution et d'exécuter manuellement la tâche.
Attention : Si on exécute manuellement une tâche qui a une date automatique d'exécution alors celle-ci ne s'exécute plus automatiquement, pour relancer l'exécution automatique il faut éditer et sauvegarder le document processus.
17.12.1.2 Limites
Les limites sont les suivantes :
- la périodicité ne peut être inférieure à 5 minutes,
- le calcul de la périodicité prend en compte la fin de l'exécution de la tâche. Par exemple, si on définit une tâche démarrant le 31/12 à 00h00, ayant une périodicité de 1 jour et durant 2H00. Cette tâche s'exécute le 31/12 à 00H00, le 01/01 à 02h00, le 02/01 à 04h00 car le calcul de la périodicité de 1 jour ne commence qu'après la fin de la tâche.
17.12.1.3 Gestion des erreurs
Lorsqu'un shell non interactif[^core-ref:shell non interactif] sort en erreur, un mail contenant le détail de l'erreur peut être envoyé.
Ce mail est envoyé uniquement si le paramètre CORE_WSH_MAILTO est non vide.
17.13 Autoloader
Le mécanisme d'autoloader de Dynacase parcourt tous les fichiers PHP (extension
.php) du contexte pour indexer toutes les classes définies dans ces fichiers.
La liste des classes, avec leur fichier source d'inclusion, est alors stockée
dans le fichier .autoloader.cache à la racine du contexte Dynacase.
Le fichier de cache .autoloader.cache est automatiquement re-généré lorsqu'il
est inexistant (et donc lors du premier appel à l'autoloader faisant suite à la
suppression de ce fichier) ou qu'une classe demandée n'est pas trouvée dans le
cache. Suite à cette re-génération, si la classe demandée n'est toujours pas
présente dans le cache, alors une exception est levée indiquant que la classe
demandée n'existe pas.
De plus, l'autoloader est mis à jour à chaque déploiement d'une application.
Une même classe PHP (la comparaison est insensible à la casse) ne peut être livrée par deux fichiers PHP distincts, et une exception est levée lorsque deux fichiers PHP distincts définissant une même classe PHP sont trouvés.
17.13.1 Utilisation
17.13.1.1 Ajout d'une nouvelle classe
Pour ajouter une nouvelle classe, il suffit de livrer le fichier PHP qui définit cette classe et d'utiliser normalement cette classe.
L'autoloader lancera automatiquement une régénération du cache lors de la première utilisation de cette classe.
17.13.1.2 Déplacement d'une classe
Pour déplacer une classe d'un fichier PHP dans un nouveau fichier PHP (en
conservant le nom de la classe), il faut déplacer la classe dans le nouveau
fichier et supprimer le fichier de cache .autoloader.cache ce qui a pour
effet de régénérer ce dernier lors de la prochaine utilisation d'une classe.
17.13.1.3 Suppression d'une classe
Pour supprimer une classe d'un fichier PHP il faut supprimer la classe de son
fichier et supprimer le fichier de cache .autoloader.cache ce qui a pour
effet de régénérer ce dernier lors de la prochaine utilisation d'une classe.
17.13.1.4 Charger et activer manuellement l'autoloader Dynacase
Par défaut, l'autoloader est chargé et actif sur tout code PHP exécuté par Dynacase (Action, scripts CLI, etc.).
Cependant, dans le cas où vous voulez exécuter un code PHP tiers (non intégré
comme Action ou scripts CLI) qui utilise des
classes Dynacase, il faut inclure le fichier WHAT/autoload.php afin de charger
et activer l'autoloader Dynacase :
require_once 'WHAT/autoload.php';
17.13.2 Personnalisation
17.13.2.1 Exclusion
Par défaut, l'autoloader indexe tous les fichiers PHP du contexte.
Pour exclure des répertoires (ou des fichiers) de l'indexation de l'autoloader, il faut déclarer ces éléments dans un fichier d'autoloader-ignore.
Les fichiers d'autoloader-ignore se trouvent dans le répertoire
.autoloader-ignore.d situé à la racine du contexte et contiennent une liste de
motifs (au format shell glob) des éléments à ignorer.
Format :
Les lignes commençant par un
#(dièse) sont des commentaires et sont ignorés ;Les lignes vides ou ne contenant que des espaces sont ignorés ;
-
Les espaces en début et en fin de motif sont conservés et interprétés comme tels lors de la correspondance avec les fichiers.
Ainsi,
MYAPP/lib/*correspond aux chemins de fichiers qui commencent parMYAPP/libet qui se terminent par un espace). Les motifs (au format shell glob) sont appliqués sur les chemins des fichiers PHP relatifs à la racine du contexte Dynacase (i.e.
MYAPP/lib/foo.php).
Exemple de fichier .autoloader-ignore.d/myapp :
# Ceci est un commentaire # Ne pas indexer les fichiers PHP sous `MYAPP/data` MYAPP/data/* # Idem. pour `MYAPP/lib` MYAPP/lib/*
17.13.2.2 Prévention des doublons de classes
Pour se prémunir d'erreurs de doublons de classes (une même classe PHP livrée
par deux fichiers PHP distinct), vous pouvez utiliser le programme
programs/check_autoloader dans les phases de <post-install/> et
<post-upgrade/> (du info.xml du module) afin de vérifier qu'il n'y a pas de
doublons de classes.
Exemple d'utilisation dans info.xml :
<module name="foo" version="1.2.3" release="4">
[...]
<post-upgrade>
<process command="programs/check_autoloader">
<label lang="en">Check autoloader</label>
</process>
[...]
</post-upgrade>
</module>
17.13.3 Chemins d'inclusion (include_path)
Le paramètre include_path est défini en ajoutant le répertoire d'installation.
3.2.21Le répertoire d'installation est prioritaire aux autres chemins définis par votre configuration PHP. Les chemins sont :
DEFAULT_PUBDIR-
DEFAULT_PUBDIR/WHAT - Include path configuré par PHP
17.14 MIME
17.14.1 Détection des type MIME
Lors de l'insertion d'un fichier dans le vault, son type MIME est détecté et
stocké en base de données aux côtés de son identifiant dans le vault (vid).
On distingue deux notions sous le terme de type MIME :
- type MIME textuel (e.g.
OpenDocument Text) : description du type du fichier dans un format "humain", - type MIME système (e.g.
application/vnd.oasis.opendocument.text) : type MIME du fichier au format "machine" (tel que défini par le registre IANA par exemple).
Ce chapitre détaille les fonctions de détection du type MIME des fichiers.
17.14.1.1 Type MIME textuel (getTextMimeFile())
Le type MIME textuel est obtenu via l'utilisation de la fonction
getTextMimeFile() qui prend les arguments suivants :
- (string)
filePath - Le chemin d'accès du fichier dont on souhaite obtenir le type MIME
textuel (e.g.
/tmp/123DF423/rapport-FZ447BV.doc). - (string)
fileName(optionnel) -
Le nom du fichier (e.g.
rapport.doc).Par défaut, le nom est vide.
La détection se base en premier sur le nom du fichier (voir
Paramétrage de la détection par le nom du fichier ci-
dessous). Si le type MIME ne peut pas être déduit à partir du nom du fichier,
alors la détection se base sur le contenu du fichier (via la commande système
file).
17.14.1.2 Type MIME système (getSysMimeFile())
Le type MIME système est obtenu via l'utilisation de la fonction
getSysMimeFile() qui prend les arguments suivants :
- (string)
filePath - Le chemin d'accès au fichier dont on souhaite obtenir le type MIME
textuel (e.g.
/tmp/123DF423/rapport-FZ447BV.doc). - (string)
fileName(optionnel) -
Le nom du fichier (e.g.
rapport.doc).Par défaut, le nom est vide.
La détection se base en premier sur le nom du fichier (voir
Paramétrage de la détection par le nom du fichier ci-
dessous). Si le type MIME ne peut pas être déduit à partir du nom du fichier,
alors la détection se base sur le contenu du fichier (via la commande système
file).
17.14.1.3 Paramétrage de la détection par le nom du fichier
La détection du type MIME textuel et du type MIME système est paramétrable via des règles appliquées sur l'extension du nom du fichier.
Ces règles sont décrites au format XML dans le fichier config/user-mime.conf.
Un fichier d'exemple est fournit par défaut dans config/user-mime.conf.sample.
Exemple de définition des types MIME textuel et système pour les fichiers
d'extension .foo et .bar :
<?xml version="1.0" encoding="utf-8"?> <mimes> <mime ext="foo" sys="application/foo" text="Foo file" /> <mime ext="bar" sys="application/bar" text="Bar file" /> </mimes>
Chaque règle est décrite à l'aide d'un élément <mime/> comportant l'extension
(sans le point de l'extension) sur laquelle elle s'applique (attribut ext) et
le type MIME textuel et système correspond qui est retourné (attribut text et
sys).
Les règles sont évaluées dans l'ordre d'écriture dans le fichier XML. La détection s'arrête à la première règle qui correspond à l'extension du fichier.
Les règles du fichier config/user-mime.conf sont évaluées en
priorités par rapport au jeu de règles fournit par défaut par Dynacase
(consultable dans le fichier config/mime.conf).
17.14.2 Contrôle des types MIME servis inline
Lors de l'utilisation des fonctions Http_Download() et Http_DownloadFile(),
il est possible de demander que le téléchargement soit fait en mode
attachment ou en mode inline.
Le mode attachment permet d'indiquer au navigateur que le contenu doit être
sauvegardé dans une fichier. Ce mode déclenche l'ouverture d'une boite de
dialogue par le navigateur afin que l'utilisateur choisisse le nom du fichier
dans lequel sera enregistré le contenu.
Le mode inline permet d'indiquer au navigateur qu'il peut interpréter et
rendre le contenu directement s'il sait le gérer (e.g. images, HTML, etc.). Si
le navigateur ne sait pas gérer le contenu, alors le fichier sera enregistré
comme avec le mode attachment.
Cependant, l'utilisation du mode inline peut poser des problèmes de sécurité
dans le cas ou la donnée ou le fichier servit provient d'un utilisateur tiers.
Afin de limiter ces problèmes de sécurité, certains type MIME sont donc
interdits d'êtres servis en mode inline lors de l'utilisation des fonctions
Http_Download() et Http_DownloadFile(), même lorsque le mode inline est
explicitement demandé.
La configuration des types MIME autorisés/interdits en inline est décrite
dans la section Paramétrage des téléchargements inline
ci-dessous.
17.14.2.1 Paramétrage des téléchargements inline
Afin de réduire le risque d'exécution de contenus malveillants qui pourraient être contenus dans des fichiers, certains type MIME de fichiers ne sont pas autorisés à être servis en mode « inline », et sont donc forcés en mode « attachment » afin que le navigateur présente une boite de dialogue pour sauver le fichiers.
Dynacase fournit par défaut une liste de type MIME autorisés/interdits a être
servis en inline dans le fichier de configuration statique
config/file-mime.xml.
Pour modifier la liste de ces types MIME autorisés/interdits, il faut créer un
fichier config/file-mime-user.xml avec les règles, pour un type donné, à
remplacer ou à ajouter par rapport au fichier statique par défaut
config/file-mime.xml.
Exemple de fichier config/file-mime-user.xml :
<?xml version="1.0" encoding="utf-8"?> <rules> <inline> <deny type="text/html" comment="HTML" /> <deny type="application/xhtml+xml" comment="XHTML" /> <deny type="image/svg" comment="SVG" /> <deny type="image/svg+xml" comment="SVG" /> <deny type="application/hta" comment="Microsoft HTML Application" /> <deny type="application/x-xpinstall" comment="Mozilla XPI extensions" /> <deny type="application/vnd.mozilla.xul+xml" comment="Mozilla XUL" /> <deny type="application/x-shockwave-flash" comment="Adobe Flash" /> <allow type="*/*" /> </inline> </rule>
Les types MIME autorisés ou interdits à être servis en « inline » sont décrit à
l'aide d'un élément <allow /> (autoriser) ou <deny /> (interdire) avec le
type MIME correspondant déclaré dans la propriété type.
La propriété type doit être de la forme suivante :
-
[type] . "/" . [subtype]: pour cibler un type et son subtype. Ex. :application/foo; -
[type] . "/*": pour ne cibler d'un type (en acceptant n'importe quel subtype). Ex.application/*; -
"*/*": pour cibler n'importe quel type et subtype. Ex.*/*.
Lees règles sont évalués par ordre décroissant de spécificité du type MIME et l'évaluation s'arrête au premier type MIME qui correspond.
Ordre de spécificité de type :
* "xxx/xxx" : évalué en premier ;
* "xxx/" : évalué en second ;
* "/*" : évalué en derner.
17.15 Installation et ou mise à jour d'applications et de familles
17.15.1 Introduction
Le déploiement d'une application (ou d'une famille) est le terme utilisé pour le processus d'installation d'applications (ou de familles) dans un contexte Dynacase.
Le déploiement s’effectue à l'aide de dynacase-control soit en mode Web soit en mode CLI en installant un module.
Un module est une archive dans un format spécifique (nommé webinst) qui
contient les éléments à déployer et les directives pour l'initialisation et/ou
le chargement de ces éléments.
Techniquement, un module est une archive TAR compressée GZIP avec l'extension
.webinst qui contient les fichiers suivants :
- Un fichier
content.tar.gz -
Ce fichier est une archive TAR compressée GZIP contenant l'ensemble des fichiers (applications et familles) à déployer dans le contexte Dynacase.
Cette archive contient donc tous les fichiers qui seront déployés dans le contexte, les chemins de ces fichiers sont relatifs à la racine du contexte et suivent l'organisation et la structure d'un contexte Dynacase.
- Un fichier
info.xml - Ce fichier contient les informations sur le module (nom, version, etc.) et
les directives d'initialisation et/ou de chargement des éléments livrés par
content.tar.gzci-dessus.
Voir :
17.15.2 Structure d'un contexte Dynacase
Un contexte Dynacase suit une structure déterminée de répertoires.
<context-root>-
La racine du contexte contient les fichiers
index.phpetadmin.phpqui sont les points d'entrés pour l'accès Web à Dynacase.Vous n'avez pas à livrer de contenu dans la racine même du contexte.
<context-name>/<APPNAME>-
Les répertoires en majuscules (e.g.
MYAPP) dans la racine du contexte contiennent les fichiers des applications Dynacase.C'est dans ces répertoires que vous devez livrer les fichiers de classe de vos familles, les fichiers d'actions et les layouts de vos applications.
Voir :
<context-root>/EXTERNALS-
Ce répertoire contient les fichiers d'aides à la saisie.
C'est dans ce répertoire que vous devez livrer les fichiers d'aides à la saisie de vos familles.
Voir :
<context-root>/API-
Ce répertoire contient les scripts d'API exécutables par la commande CLI
wsh.C'est dans ce répertoire que vous devez livrer vos scripts d'API.
Voir :
<context-root>/Images-
Ce répertoire contient les icônes des familles.
C'est dans ce répertoire que vous devez livrer les icônes de vos familles.
Voir :
-
<context-name>/locale/fr/LC_MESSAGES/srcet<context-root>/locale/en/LC_MESSAGE/src -
Ce répertoire contient les fichiers source (
<APPNAME>.po) de localisation des applications.C'est dans ce répertoire que vous devez livrer vos fichiers source de localisation
.po.Voir :
17.15.3 Déploiement des applications
17.15.3.1 Architecture de l'application sur le serveur
Comme vue précédemment dans structure d'un contexte Dynacase, une application est composée d'un répertoire nommé avec le nom de l'application en majuscule.
Ce répertoire MYAPP doit contenir au moins :
- Un fichier
MYAPP.app(nom de l'application en majuscule + extension.app) -
contenant la déclaration du nom, description, etc. de l'application (variable
$app_desc) et les éventuelles actions de l'application (variable$action_desc).Exemple fichier
MYAPP/MYAPP.app:<?php $app_desc = array( "name" => "MYAPP", "short_name" => "Mon application", "description" => "Mon application de test", "icon" => "myapp.png", "displayable" => "Y", "childof" => "ONEFAM" ); $action_desc = array( array( "name" => "MYACTION1", "short_name" => N_("MYAPP:action one"), "acl" => "MYAPPACL1" "root" => "Y" ) );
- Un fichier
MYAPP_init.php(nom de l'application en majuscule +_init.php) -
contenant la version et la déclaration des éventuels paramètres de l'application (variables
$app_const).Exemple fichier
MYAPP/MYAPP_init.php:<?php $app_const = array( "VERSION" => "1.0.3-1", // Paramètre minimum obligatoire "MYAPP_PARAM_FOO" => array( "val" => "1", "descr" => N_("MYAPP:Description of parameter foo"), "global" => "Y", "user" => "N" ) );
L'icône myapp.png référencée par la variable $app_desc['icon']
est à placer dans le répertoire MYAPP/Images.
Le fichier MYAPP/myaction1.php de l'action MYACTION1 déclarée :
<?php function myactions1(Action & $action) { $action->lay->eSet("MESSAGE", "Hello world."); }
Le fichier de layout MYAPP/Layout/myaction1.xml de l'action MYACTION1 :
<html> <title>My Action 1</title> <body> <p>[MESSAGE]</p> </body> </html>
Si l'application est localisée, alors les fichiers de locale doivent être dans
le sous-répertoire locale en suivant le format GNU gettext
décrit dans le chapitre Internationalisation.
Exemple fichier locale/en/LC_MESSAGES/src/MYAPP.po :
msgid "" msgstr "" "Content-Type: text/plain; charset=UTF-8\n" "Content-Transfer-Encoding: 8bit\n" "Plural-Forms: nplurals=2; plural=n>1\n" msgid "MYAPP:Description of parameter foo" msgstr "Paramètre foo" msgid "MYAPP:action one" msgstr "Action Un"
Exemple fichier locale/fr/LC_MESSAGES/src/MYAPP.po :
msgid "" msgstr "" "Content-Type: text/plain; charset=UTF-8\n" "Content-Transfer-Encoding: 8bit\n" "Plural-Forms: nplurals=2; plural=n>1\n" msgid "MYAPP:Description of parameter foo" msgstr "Parameter foo" msgid "MYAPP:action one" msgstr "Action One"
Une fois la structure de l'application établie, vous pouvez générer l'archive
content.tar.gz avec le contenu de votre application (répertoire MYAPP) et
les éventuelles locales (répertoire locale).
Remarques :
- La notion de modules et de versions de modules n'a de sens qu'au sein de dynacase-control. De la même manière, la notion d'applications et de versions d'applications n'a de sens qu'au sein de Dynacase.
- La version de l'application peut ne pas être la même que la version du module.
- Un module d'une version donnée peut livrer plusieurs applications avec chacune leur version distincte.
- C'est la version de l'application est utilisée pour déclencher les scripts de pre-migration et de post-migration (voir Mettre à jour une application ci-dessous).
Voir :
17.15.3.2 Enregistrer une application
Une fois les fichiers à livrer empaquetés dans l'archive content.tar.gz, il
faut créer le fichier info.xml avec les instructions nécessaires au chargement
de ces éléments.
Après que l'application contenue dans l'archive content.tar.gz ait été
décompressée dans le contexte, il faut enregistrer cette dernière auprès de
Dynacase lors de l'installation du module et lors de l'upgrade du module.
L'enregistrement d'une application auprès de Dynacase s'effectue à l'aide de la
commande program/record_application qui
prend en argument :
<APPNAME>- Le nom de l'application que l'on souhaite enregistrer.
-
IouU -
Ipour l'enregistrement lors de l'installation (Install) etUpour l'enregistrement lors de la mise à jour (Upgrade).
Cette commande ne peut être exécutée que dans l'environnement de dynacase- control. Voir Exécution manuelle ci-dessous pour exécuter manuellement ces commandes.
Si des catalogues de locales sont livrées, il faut alors les prendre en compte à
l'aide de la commande programs/update_catalog (qui
ne prend pas d'arguments).
Exemple de fichier info.xml :
<xml version="1.0" encoding="utf-8"> <module name="my-module" version="1.0.3" release="1"> <requires> <module name="dynacase-core" comp="ge" version="3.2.0" /> </requires> <post-install> <process command="programs/record_application MYAPP I" /> <process command="programs/update_catalog" /> </post-install> </module>
Enfin, on peut générer le module final my-module-1.0.3-1.webinst en
empaquetant le fichier content.tar.gz et le fichier info.xml.
Voir :
17.15.3.3 Mettre à jour une application
On dit qu'un module est mis à jour lorsque la version déclarée dans la propriété
version dans le fichier info.xml est supérieure à la version du module
actuellement installé.
Dans ce, c'est la section <post-upgrade/> qui est exécutée et non plus la
section <post-install/>.
Pour mettre à jour une application, lors de la mise à jour d'un module, il faut
alors ré-enregistrer l'application pour mettre à jour sa définition par rapport
au niveaux fichiers livrés (<APPNAME>/<APPNAME>.app et
<APPNAME>/<APPNAME>_init.php).
Pour cela il faut donc ajouter une section <post-upgrade/> dans le fichier
info.xml contenant les instructions nécessaires pour ré-enregistrer
l'application :
<post-upgrade> <process command="programs/record_application MYAPP U" /> <process command="programs/update_catalog"/> </post-upgrade>
Ce qui donne alors le fichier info.xml suivant :
<xml version="1.0" encoding="utf-8"> <module name="my-module" version="1.0.4" release="1"> <requires> <module name="dynacase-core" comp="ge" version="3.2.0" /> </requires> <post-install> <process command="programs/record_application MYAPP I" /> <process command="programs/update_catalog" /> </post-install> <post-upgrade> <process command="programs/record_application MYAPP U" /> <process command="programs/update_catalog"/> </post-upgrade> </module>
Régénérer enfin le module avec la nouvelle version des éléments à déployer.
17.15.3.4 Migrer une application
Dans certains cas, l'application peut nécessiter des traitements spécifiques en base de donnée ou sur des fichiers.
Ces traitements sont alors appelés scripts de "migration" car il vont devoir manipuler des éléments pour monter en version l'application depuis la version actuellement installée et la nouvelle version qui est déployée.
Deux types de scripts sont possibles :
- scripts de pré-migration (premigr) : les scripts de pré-migration (premigr) sont prévus pour être exécutés avant que l'application et les familles en base de données soient mis-à-jour,
- scripts de post-migration (postmigr) : les scripts de post-migration (postmigr) sont prévus pour être exécutés après que l'application et les familles en base de données aient été mis-à-jour.
Les scripts doivent être situés dans le sous-répertoire de l'application et leur nom doit être de la forme :
- scripts de pré-migration (premigr) :
<APPNAME>_premigr_<VERSION> - scripts de post-migration (postmigr) :
<APPNAME>_postmigr_<VERSION>
Remarques :
- Un module sans application ne peut pas utiliser cette mécanique de migration.
- Le script peut être écrit dans n'importe quel langage que peut exécuter la plateforme hébergeant le contexte sur lequel il est exécuté. Toutefois, il ne doit pas avoir d'extension, il faut donc utiliser la notation [shebang][wikiShebang] en première ligne de script pour indiquer le langage d'exécution,
- les scripts de migration sont exécutés sur les changements de VERSION sans tenir compte des RELEASE. On ne peut donc pas exécuter de script de migration lors d'un changement de RELEASE,
- les scripts de migration doivent être exécutables.
Le lancement de ces scripts est commandé dans le fichier info.xml du module
par l'utilisation d'une directive
<process command="programs/{pre,post}_migration <APPNAME>" />
dans la section <post-upgrade/>.
Exemple de déclaration type pour le lancement de scripts de pré-migration et de post-migration :
<xml version="1.0" encoding="utf-8"> <module name="my-module" version="1.0.5" release="1"> <requires> <module name="dynacase-core" comp="ge" version="3.2.0" /> </requires> <post-install> <process command="programs/record_application MYAPP I" /> <process command="programs/update_catalog" /> </post-install> <post-upgrade> <process command="programs/pre_migration MYAPP" /> <process command="programs/record_application MYAPP U" /> <process command="programs/post_migration MYAPP" /> <process command="programs/update_catalog" /> </post-upgrade> </module>
Les programmes programs/pre_migration et
programs/post_migration exécutent tous les scripts
de "premigr" ou "postmigr" dont la version est comprise entre la version de
l'application actuellement installé, et la version de l'application mise-à-jour.
| Version sur le contexte | Version dans le paquet | Version du script | Exécution |
|---|---|---|---|
| 1.0.0 | 2.0.0 | 1.1.0 | Oui |
| 1.0.0 | 1.0.0 | 1.0.0 | Non |
| 3.0.0 | 2.0.0 | 1.0.0 | Non |
| 1.0.0 | 2.0.0 | 1.0.0 | Non |
| 1.0.0 | 2.0.0 | 2.0.0 | Oui |
Voir :
17.15.4 Déployer une famille
17.15.4.1 Organisation de la famille
Le déploiement et le paramétrage d'une famille implique l'utilisation de
fichiers de description de famille qui doivent être
chargés suivant un ordre déterminé.
En effet, un fichier d'import ne doit référencer que des éléments connus au moment de son import. Par conséquent, il vous faut mettre en place un ordre de chargement des éléments afin d'importer en premier lieu un fichier N qui définirait les éléments qui seraient ensuite utilisés par les éléments définis dans un fichier N+1, et ainsi de suite.
L'ordre de chargement des éléments doit généralement être du type :
- importer les données d'initialisation (e.g. utilisateurs, groupes et rôles) ;
- importer la structure des familles ;
- importer le paramétrage des familles (e.g. affecter les profils aux familles);
Pour éviter les références cycliques, comme dans le cas d'une famille qui utilise un cycle qui lui même est dynamique sur la famille (donc référence à son tour la famille), on procédera par l'import des familles seule (sans références à leurs cycles), puis des cycles qui référencent les familles, et enfin par l'import du paramétrage des familles qui va mettre en place leurs cycles.
17.15.4.2 Installer une famille
Les fichiers de description des familles peuvent être placés dans le sous- répertoire de l'application, ou bien, en l'absence d'application, dans un sous- répertoire qui permettra d'éviter que les éléments déployés n'entrent en conflit avec d'autres éléments.
Déclarer dans le fichier info.xml le chargement, et l'ordre de chargement, de
ces fichiers à l'aide de la commande wsh.php --importDocuments :
<?xml version="1.0" encoding "utf-8"?> <module name="my-module" version="1.0.0" release="1"> <post-install> <process command="wsh.php --api=importDocuments --file=MYFAMS/init_users.csv" /> <process command="wsh.php --api=importDocuments --file=MYFAMS/init_groups.csv" /> <process command="wsh.php --api=importDocuments --file=MYFAMS/init_roles.csv" /> <process command="wsh.php --api=importDocuments --file=MYFAMS/struct_fam1.csv" /> <process command="wsh.php --api=importDocuments --file=MYFAMS/struct_fam2.csv" /> <process command="wsh.php --api=importDocuments --file=MYFAMS/param_fam1.csv" /> <process command="wsh.php --api=importDocuments --file=MYFAMS/param_fam2.csv" /> </post-install> <post-upgrade> <process command="wsh.php --api=importDocuments --file=MYFAMS/struct_fam1.csv" /> <process command="wsh.php --api=importDocuments --file=MYFAMS/struct_fam2.csv" /> <process command="wsh.php --api=importDocuments --file=MYFAMS/param_fam1.csv" /> <process command="wsh.php --api=importDocuments --file=MYFAMS/param_fam2.csv" /> </post-upgrade> </module>
Générer le module avec l'archive content.tar.gz et le fichier info.xml.
17.15.4.3 Mettre à jour une famille
La mise à jour d'un famille se fait en important le nouveau fichier de définition de famille.
Cependant, certains cas peuvent nécessiter une migration de données comme par exemple dans le cas d'un attribut de type timestamp (qui regroupe date + heure) qu'on voudrait migrer sous la forme de deux attributs distincts : un de type date et l'autre de type time.
Dans ce cas il faut utiliser un script de migration afin de migrer la valeur de l'attribut timestamp dans les deux attributs date et time à l'aide d'instructions SQL.
Comme indiqué précédemment, pour pouvoir utiliser de tels scripts de migration, il faut avoir une application afin de pouvoir déclencher les scripts de pré- migration et de post-migration lorsque la version de l'application est modifiée.
Admettons que la nouvelle version de l'application soit la 2.0.0, alors le
script de post-migration des familles doit être déclaré dans un script nommé
MYAPP/MYAPP_postmigr_2.0.0.
Exemple de script de post-migration MYAPP/MYAPP_postmigr_2.0.0 (en Bash) pour
la migration d'un attribut de type timestamp sous la forme de deux attributs :
#!/usr/bin/env php <?php require('FDL/freedom_util.php'); require('WHAT/Lib.Common.php'); /* * Obtenir l'identifiant de la famille 'FAM_1' */ $famId = getIdFromName('', 'FAM_1'); if ($famId <= 0) { printf("Error: could not get id from name '%s'.\n", 'YUSER'); exit(1); } /* * Mettre à jour la table de la famille MYFAM pour scinder les valeurs * 'attr_timestamp' dans deux attributs : 'attr_date' et 'attr_time' */ printf("Migrating table 'doc%d'...\n", $famId); $sql = sprintf("UPDATE doc%d SET attr_date = attr_timestamp::date, attr_time = attr_timestamp::time", $famId); $err = simpleQuery('', $sql, $res, false, false, false); if ($err !== '') { printf("Error: %s\n", $err); exit(1); } printf("Done.\n"); exit(0);
Rendre le script MYAPP/MYAPP_postmigr_2.0.0 exécutable.
Régénérer l'archive content.tar.gz avec les éléments à livrer (MYAPP et
MYFAMS).
Fichier info.xml correspondant complet :
<?xml version="1.0" encoding "utf-8"?> <module name="my-module" version="2.0.0" release="1"> <requires> <module name="dynacase-core" comp="ge" version="3.2.0" /> </requires> <post-install> <!-- Enregistrer l'application MYAPP --> <process command="programs/record_application MYAPP I" /> <!-- Charger les familles --> <process command="wsh.php --api=importDocuments --file=MYFAMS/struct_fam1.csv" /> [...] <process command="wsh.php --api=importDocuments --file=MYFAMS/param_wdoc2.csv" /> <!-- Mettre à jour le catalogue de langue --> <process command="programs/update_catalog" /> </post-install> <post-upgrade> <!-- Lancer les scripts de pre-migration de l'application MYAPP --> <process command="programs/pre_migration MYAPP" /> <!-- Enregistrer la nouvelle définition de l'application --> <process command="programs/record_application MYAPP" /> <!-- Charger les nouvelles définitions des familles --> <process command="wsh.php --api=importDocuments --file=MYFAMS/struct_fam1.csv" /> [...] <process command="wsh.php --api=importDocuments --file=MYFAMS/param_wdoc2.csv" /> <!-- Lancer les scripts de post-migration de l'application MYAPP --> <process command="programs/post_migration MYAPP" /> <!-- Mettre à jour le catalogue de langue --> <process command="programs/update_catalog" /> </post-upgrade> </module>
Régénérer enfin le module avec la nouvelle version des éléments à déployer.
Le script MYAPP/MYAPP_postmigr_2.0.0 est alors exécuté lors de l'upgrade du
module my-module-2.0.0-1.webinst lorsque la version installée de l'application
MYAPP est < 2.0.0.
Remarques :
- En l'absence d'application, il n'est pas possible d'utiliser le mécanisme de
pre-migration et post-migration tel que décrit ci-dessus. Dans un tel cas, il
vous faudra, par exemple, livrer un script d'API et exécuter celui-ci avec une
directive
<process command="wsh.php --api=migrate-my-fams-2.0.0" />.
Voir :
17.15.5 Mettre à jour le catalogue de langue
La mise à jour du catalogue de langue s'effectue en exécutant le programme
program/update_catalog en post-install et post-upgrade.
<post-install> [...] <process command="program/update_catalog" /> </post-install> <post-upgrade> [...] <process command="program/update_catalog" /> </post-upgrade>
Voir :
17.15.6 Programmes utiles pour les déploiements
Un ensemble de programmes utiles pour les déploiements sont fournis par
dynacase-core dans le sous-répertoire programs du contexte Dynacase.
Ces programmes sont prévus pour être exécutés par dynacase-control et ne peuvent donc pas être directement exécutés manuellement sans cet environnement.
Si vous souhaitez exécuter ces programmes manuellement, voir Exécution manuelle ci-dessous.
17.15.6.1 Commande programs/app_post
Prototype :
programs/app_post <APPNAME> I|U
Utilisable dans les phases :
post-installpost-upgrade
Conditions d'utilisation :
- Dans la phase
post-install, le programme doit être exécuté après le programmerecord_application - Dans la phase
post-upgrade, le programme doit être exécuté aprèspre_migrationet avant le programmerecord_application
Le programme app_post recherche et exécute, s'il est présent, le script
<APPNAME>/<APPNAME>_post qui peut contenir des instructions pour un
traitement d'initialisation ou d'upgrade particulière.
Le module peut donc fournir son propre script nommé
<APPNAME>/<APPNAME>_post qui sera exécuté par l'appel à
programs/app_post.
Les arguments sont :
- Le nom de l'application (le script exécuté sera alors
<APPNAME>/<APPNAME>_post) -
I|U: Le nom de la phase d'initialisation a exécuter (Ipour install,Upour upgrade)
Exemple :
<post-install> [...] <process command="programs/record_application MYAPP I" /> <process command="programs/app_post MYAPP I" /> [...] </post-install> <post-upgrade> [...] <process command="programs/pre_migration MYAPP" /> <process command="programs/record_application MYAPP U" /> <process command="programs/app_post MYAPP U" /> <process command="programs/post_migration MYAPP" /> [...] </post-upgrade>
Le script <APPNAME>/<APPNAME>_post est alors exécuté par app_post avec un
seul argument qui est l'argument I ou U suivant qu'on est dans une
installation ou un upgrade.
"programs/app_post MYAPP I" --(execute)--> "MYAPP/MYAPP_post I"
"programs/app_post MYAPP U" --(execute)--> "MYAPP/MYAPP_post U"
17.15.6.2 Commande programs/record_application
Prototype :
programs/record_application <APPNAME> I|U
Utilisable dans les phases :
post-installpost-upgrade
Conditions d'utilisation :
- Le programme doit être exécuté après le programme
app_post
Les arguments sont :
- Le nom de l'application (correspondant aux fichiers
<APPNAME>/<APPNAME>_init.phpet<APPNAME>/<APPNAME>.app) -
I|U: Le nom de la phase d'initialisation a exécuter (Ipour install,Upour upgrade)
Le programme record_application est utilisé pour enregistrer, ou mettre à
jour, la définition de l'application en base de données.
Exemple :
<post-install> [...] <process command="programs/record_application MYAPP I" /> [...] </post-install> <post-upgrade> [...] <process command="programs/record_application MYAPP U" /> [...] </post-install>
17.15.6.3 Commande programs/update_catalog
Prototype :
programs/update_catalog
Utilisable dans les phases :
post-installpost-upgrade
Conditions d'utilisation :
- Le programme doit être exécuté à la fin de la phase
Le programme update_catalog est utilisé pour ré-générer le catalogue des
messages de localisation.
Exemple :
<post-install> [...] <proccess command="programs/update_catalog" /> </post-install> <post-upgrade> [...] <process command="programs/update_catalog" /> </post-upgrade>
17.15.6.4 Commande programs/pre_migration
Prototype :
programs/pre_migration
Utilisable dans les phases :
post-upgrade
Conditions d'utilisation :
- Le programme doit être exécuté au début de la phase, avant le programme
app_postetrecord_application.
Les arguments sont :
- Le nom de l'application
Le programme pre_migration est utilisé pour exécuter les scripts de
pre-migration (<APPNAME>/<APPNAME>_premigr_<VERSION>) d'un module lors de sa
mise-à-jour.
Tous les scripts <APPNAME>/<APPNAME>_premigr_<VERSION> dont la version est
supérieure à la version de l'application précédemment enregistré sont exécutes
dans l'ordre des versions.
Exemple :
<post-upgrade> [...] <process command="programs/pre_migration MYAPP" /> <process command="programs/record_application MYAPP U" /> <process command="programs/app_post MYAPP U" /> <process command="programs/post_migration MYAPP" /> [...] </post-upgrade>
Voir :
- [Scripts de pré-migration et de post-migration][#core-ref:fd259229-b279-469a-8e3c-d737fabcf9d5]
17.15.6.5 Commande programs/post_migration
Prototype :
programs/post_migration
Utilisable dans les phases :
post-upgrade
Conditions d'utilisation :
- Le programme doit être exécuté après le programme
record_application, et avant leupdate_catalog
Les arguments sont :
- Le nom de l'application
Le programme post_migration est utilisé pour exécuter les scripts de
post-migration (<APPNAME>/<APPNAME>_postmigr_<VERSION>) d'un module lors de sa
mise-à-jour.
Tous les scripts <APPNAME>/<APPNAME>_postmigr_<VERSION> dont la version est
supérieure à la version de l'application précédemment enregistré sont exécutes
dans l'ordre des versions.
Exemple :
<post-upgrade> [...] <process command="programs/pre_migration MYAPP" /> <process command="programs/record_application MYAPP U" /> <process command="programs/app_post MYAPP U" /> <process command="programs/post_migration MYAPP" /> [...] </post-upgrade>
Voir :
- [Scripts de pré-migration et de post-migration][#core-ref:fd259229-b279-469a-8e3c-d737fabcf9d5]
17.15.6.6 Commande programs/set_param
Prototype :
programs/set_param <DYNACASE_PLATFORM_PARAM_NAME> <DYNACASE_CONTROL_MODULE_PARAM_NAME>
Utilisable dans les phases :
post-installpost-upgrade
Le programme programs/set_param permet de positionner la valeur d'un paramètre
applicatif global d'une application Dynacase avec la valeur d'un paramètre de
module.
Exemple :
<parameters> <param name="myapp_favorite_color" label="What is your favorite color?" type="text" default="blue" onupgrade="W"/> </parameters> <post-install> [...] <process command="programs/set_param MYAPP_GLOBAL_FAVCOLOR myapp_favorite_color" /> [...] </post-install>
17.15.6.7 Commande wsh.php
Prototype :
wsh.php
Utilisable dans les phases :
post-installpost-upgrade
Conditions d'utilisation :
- Le programme peut être utilisé à n'importe quel moment en fonction des besoins
Le programme wsh.php est utilisé pour exécuter des méthodes sur des classes
documentaires et exécuter des API Dynacase.
Exemple :
<process command="wsh.php --api=refreshDocuments --method=postModify --famid=FOO" />
Voir :
17.15.6.8 Exécution manuelle
Pour pouvoir exécuter manuellement ces programmes, il faut initialiser un environnement d'exécution compatible comme suit :
Le répertoire courant d'exécution doit être la racine du contexte.
La variable d'environnement
WIFF_ROOTdoit contenir le chemin absolu d'accès à la racine de dynacase-control.La variable d'environnement
WIFF_CONTEXT_ROOTdoit contenir le chemin absolu d'accès à la racine du contexte.La variable d'environnement
WIFF_CONTEXT_NAMEdoit contenir le nom du contexte tel que déclaré auprès de dynacase-control.Si le programme est exécuté dans le cadre de la mise à jour d'un module, la variable d'environnement
MODULE_VERSION_FROMdoit contenir la version du module actuellement installé dans le contexte etMODULE_VERSION_TOdoit contenir la version du nouveau module.Si le programme est exécuté dans le cadre de l'installation d'un module, la variable d'environnement
MODULE_VERSION_FROMne doit pas être définie etMODULE_VERSION_TOdoit contenir la version du module en cours d'installation.
Exemple d'initialisation d'un tel environnement en Bash :
# /var/www/dynacase-control/wiff context foo exec /bin/bash --login $ export WIFF_ROOT=/var/www/dynacase-control $ export WIFF_CONTEXT_ROOT=$PWD $ export WIFF_CONTEXT_NAME=foo $ export MODULE_VERSION_FROM=1.0.0 $ export MODULE_VERSION_TO=2.0.0
17.16 Utilisation des documents partagés du noyau
17.16.1 Introduction
Dynacase core utilise un objet de partage de documents lors de l'exécution des
actions. Cet objet de partage permet d'adresser le même objet document lorsque
la fonction new_doc est appelée plusieurs fois pour récupérer le même document.
Le noyau utilise cette fonction pour ses besoins internes et le peuplement de cet objet de partage est fait pour répondre au besoin du noyau.
Cependant, lorsqu'on utilise la fonction new_doc, l'objet document
récupéré peut être celui du partage ou un nouvel objet peuplé avec les valeurs
de la base de données.
Seule la fonction new_doc utilise la fonction de partage pour
récupérer des documents de cet objet de partage. Cette fonction récupère le
document dans l'objet de partage s'il a été enregistré avec son identifiant. Si
le document n'est pas dans cet objet de partage, un nouvel objet document est
créé avec les données de la base de données et il est ajouté à l'objet de
partage si la limite n'est pas atteinte.
Le document n'est pas récupéré de la zone de partage par la fonction
new_doc si :
- le document est un cycle de vie instancié
- le document est un profil dynamique (ceci inclus les contrôles de vue avec profilage dynamique)
17.16.2 Cas de modification de l'objet de partage
Le noyau modifie cet objet de partage dans les fonctions suivantes :
new_doc()- Cette fonction ajoute le document dans le partage s'il n'y est pas déjà et si le document n'est pas complet (seulement en cas d'installation de famille)
Doc::postInsert()-
Cette méthode ajoute le document si ce n'est pas une famille.
La méthodeDoc::postInsertest appelée à chaque création (Doc::store()) d'un nouveau document en base et à chaque enregistrement d'une nouvelle révision.Note : avec un cycle de vie, une révision est créée à chaque passage de transition. Une révision constitue une nouvelle entrée mais n'efface pas l'ancienne.
Doc::convert()- Ceci constitue une utilisation moins commune qui consiste à convertir un document d'une famille à une autre. Dans ce cas, le document partagé s'il existe est mis à jour avec le résultat de la conversion.
17.16.3 Limite de stockage
Cet objet de partage est limité en nombre d'éléments à garder en mémoire. Si la limite est atteinte aucun nouvel ajout dans le partage n'est effectué.
Par défaut la limite est de 20 (define MAXGDOCS).
17.16.4 Méthodes de gestion du partage de document
| Méthode 3.2.21 | Description |
|---|---|
Doc Dcp\Core\SharedDocuments::get(int $id) |
Récupère un document de l'objet de partage référencé par son identifiant (propriété id). Retourne null si inexistant |
bool Dcp\Core\SharedDocuments::set(int $id,Doc $doc) |
Ajoute ou remplace un document, la clef de partage est l'identifiant du document. Retourne false si non ajouté (limite atteinte) |
bool Dcp\Core\SharedDocuments::exists(int $id) |
Vérifie que la clef de partage existe |
bool Dcp\Core\SharedDocuments::remove(int $id) |
Supprimer le partage d'un document |
bool Dcp\Core\SharedDocuments::clear() |
Enlève le partage de tous les documents partagés |
int Dcp\Core\SharedDocuments::getLimit() |
Retourne la limite de nombre de document partagé |
void Dcp\Core\SharedDocuments::setLimit(int $limit) |
Modifie la limite de nombre de document partagé |
bool Dcp\Core\SharedDocuments::isShared(int $id,Doc $doc) |
Vérifie si le document référencé par son identifiant est dans le partage |
17.16.5 Exemple
Pour mieux comprendre, la constitution de ce partage et son utilisation, l'exemple suivant va illustrer ce partage. L'exemple présuppose que la limite n'est jamais atteinte.
$docX=new_doc("", 1234)
| Clefs | Objets |
|---|---|
| 1234 | $docX |
Ajout de la clef 1234.
$docY=new_doc("", 2345):
| Clefs | Objets |
|---|---|
| 1234 | $docX |
| 2345 | $docY |
Ajout de la clef 2345.
$docW=createDoc("","MY_FAMILY");
| Clefs | Objets |
|---|---|
| 1234 | $docX |
| 2345 | $docY |
Rien de modifié. La méthode Doc::Store() n'est pas encore appelée
$docW->store()// acquisition d'un nouvel identifiant 5688
| Clefs | Objets |
|---|---|
| 1234 | $docX |
| 2345 | $docY |
| 5688 | $docW |
Ajout de la clef 5688 via le Doc::postInsert() appelé depuis le Doc::store()
$docZ=new_doc("", 1234):
| Clefs | Objets |
|---|---|
| 1234 | $docX, $docZ |
| 2345 | $docY |
| 5688 | $docW |
La variable $docZ récupère la clef de partage 1234. Maintenant $docX === $docZ.
print $docX->getValue("x"); // print 21 (on suppose que 21 est la valeur initiale de ce document)
$docZ->setValue("x", 3);
print $docZ->getValue("x"); // print 3
print $docX->getValue("x"); // print 3
$docZ->store();
| Clefs | Objets |
|---|---|
| 1234 | $docX, $docZ |
| 2345 | $docY |
| 5688 | $docW |
Aucune modification. Le Doc::store() ne fait pas de création.
$docZ->revise(); // acquisition d'un nouvel identifiant 5689
| Clefs | Objets |
|---|---|
| 1234 | $docX, $docZ |
| 2345 | $docY |
| 5688 | $docW |
| 5689 | $docX, $docZ |
La révision créé un nouvel identifiant. Le Doc::postInsert() qui est appelé via le Doc::revise() ajoute une nouvelle entrée 5689. L'entrée 1234 n'est pas enlevée.
print $docX->id; // print 5689
$docX->setValue("x", 52);
print $docZ->getValue("x"); // print 52
$docL=new_doc("", 1234, true); // Dernière révision => 5689
print $docL->getValue("x"); // print 52
| Clefs | Objets |
|---|---|
| 1234 | $docX, $docZ, $docL |
| 2345 | $docY |
| 5688 | $docW |
| 5689 | $docX, $docZ, $docL |
L'appel new_doc("", 1234, true) est équivalent à l'appel new_doc("", 5689).
La variable $docL contient le document partagé avec la clef 5689.
Maintenant $docX === $docZ === $docL.
$docX=new_doc("", 1234);
print $docX->getValue("x"); // print 3 (valeur de la révision précédente)
| Clefs | Objets |
|---|---|
| 1234 | $docX |
| 2345 | $docY |
| 5688 | $docW |
| 5689 | $docZ $docL |
La fonction "new_doc" remplace la référence au partage car la clef a changé. Cet appel a demandé une révision ancienne du document.
17.17 Mise à jour d'attribut sur des collections de documents
17.17.1 Présentation
Afin de modifier une valeur d'attribut sur un ensemble de document vous pouvez utiliser une itération sur la liste en question comme le montre l'exemple ci- dessous
$s = new \SearchDoc('', 'TST_MYFAMILY'); $s->setObjectReturn(); $s->setOrder('initid'); $s->setSlice(1000); $dl=$s->search()->getDocumentList(); foreach ($dl as $doc) { $doc->setValue('tst_example','my new value'); $err=$doc->store(); }
Plus le nombre de documents est important, plus le temps de modification sera conséquent. L'utilisateur ayant déclenché ce programme risque de perdre patience.
La classe UpdateAttribute permet de réaliser un traitement équivalent
de manière optimisée.
$s = new \SearchDoc('', 'TST_MYFAMILY'); $s->setObjectReturn(); $s->setOrder('initid'); $s->setSlice(1000); $dl=$s->search()->getDocumentList(); $ua = new \UpdateAttribute(); $ua->useCollection($dl); $ua->setValue('tst_example','my new value'); $err=$ua->getError();
Ceci ne réalise pas tout à fait la même action. En effet dans la version optimisée les post-traitement spécifiques et internes ne sont pas réalisés. Cela veut dire que le titre, le profil, les attributs calculés ne sont pas mis à jour.
En contrepartie, le temps de traitement est bien moindre. Sur une mise à jour "classique" pour un temps de réponse d'environ 45 secondes pour 1000 documents, la version optimisée réalise le traitement en moins de 2 secondes.
17.17.2 Paramétrage général
17.17.2.1 Réviser les documents
Les documents peuvent être révisés avant la modification. Cela est indiqué par
la méthode ::addRevision().
$ua = new \UpdateAttribute(); $ua->useCollection($dl); $ua->addRevision('my revision'); $ua->setValue('tst_example','my new value');
La révision est faite sur les documents qui seront modifiés. Dans le cas du setValue si la valeur est déjà celle que l'on veut mettre, la révision ne sera pas effectuée. De manière générale si le document ne subit pas de modification, il ne sera pas révisé.
L'activation de ce paramètre va entraîner un temps de réponse plus important car cela entraîne de nombreuses écritures supplémentaires pour les révisions.
17.17.2.2 Recalculer le profil
Si vos documents sont lié à un profil dynamique et que la modification est faite
sur un attribut lié au profil, vous devez ajouter l'appel à la méthode
::useProfileUpdating().
$ua = new \UpdateAttribute(); $ua->useCollection($dl); $ua->useProfileUpdating(); $ua->setValue('tst_redactor','MY_NEWREDACTOR');
17.17.2.3 Ajouter un commentaire d'historique
Un commentaire spécifique, avec la méthode ::addHistoryComment() peut être
ajouté dans l'historique sur chacun des documents. À la différence de la
révision, il est appliqué sur tous les documents qu'il soit changé ou non.
$ua = new \UpdateAttribute(); $ua->useCollection($dl); $ua->addHistoryComment("my message"); $ua->setValue('tst_example','my new value');
17.17.2.4 Activer le mode transactionnel
Le mode transactionnel, permet d'éviter de faire un traitement partiel en cas d'erreur. Par défaut ce mode n'est pas activé.
$ua = new \UpdateAttribute(); $ua->useCollection($dl); $ua->useTransaction(true); $ua->setValue('tst_example','my new value');
S'il y a une exception levée ou si ::getError() n'est pas vide le traitement
sera abandonné.
17.17.2.5 Récupérer les statuts
Lorsque le traitement est fini, le statut de chacun des documents est donné par
la méthode ::getResults(). Cela donne une table avec pour chacun des éléments,
des indications sur ce qui a été fait, l'index du tableau est l'initid du
document.
- [
changed] => est à vrai si le document a subit une modification - [
revisionError] => message d'erreur de la révision (si révision) - [
profilingError] => message d'erreur du recalcul de profil - [
profiled] => est à vrai si le document a été reprofilé - [
revised] => est à vrai si le document a été révisé - [
historyUpdated] => est à vrai si l'historique a été mis à jour
$ua = new \UpdateAttribute(); $ua->useCollection($dl); $ua->setValue('tst_example','my new value'); $status=$ua->getResults(); $changed=$unChanged=0; foreach ($status as $initid=>$aStatus) { if ($aStatus->changed) $changed++; else $unChanged++; } printf("%d document changed, %d document unchanged\n", $changed,$unChanged);
17.17.2.6 Estimation des temps de réponse
Ces temps sont donnés à titre indicatif pour le traitement de 1000 documents. Ces temps peuvent fluctuer en fonction de votre configuration serveur et de la configuration de la famille.
| Pour 1000 documents | Temps en secondes |
|---|---|
| setValue par boucle traditionnelle | 45,64 |
| setValue seul | 1,27 |
| setValue + revision | 68,83 |
| setValue + profiling | 1,84 |
| setValue + historique | 1,41 |
| setValue + revision + profiling | 73,30 |
17.17.3 Fonctions de modifications
Les quatre fonctions de modification permettent de réaliser des modifications sur un attribut en particulier pour l'ensemble des documents donné.
17.17.3.1 setValue
La méthode ::setValue() permet de changer de manière systématique la valeur
d'un attribut. Si la valeur d'un document est déjà celle choisie, alors le
document n'est pas modifié.
Si l'attribut est dans un tableau, c'est toute la colonne qui est modifiée. Il est possible d'indiquer un tableau de valeur dans la cas d'un attribut multiple ou d'un attribut qui est dans un tableau.
17.17.3.2 replaceValue
La méthode ::replaceValue() permet de changer une valeur par une autre.
Si la valeur à changer n'est pas présente, le document ne sera pas changé.
Pour les attributs multiples, le test de remplacement se fait sur chacune des valeurs du multiple. De même, pour les multiples dans les tableaux, le test de remplacement se fera sur les valeurs finales.
$ua = new \UpdateAttribute(); $ua->useCollection($dl); $ua->replaceValue('tst_example','my old value','my new value');
17.17.3.3 removeValue
La méthode ::removeValue() permet de supprimer une certaine valeur d'un
attribut. Cela ne permet pas de supprimer la valeur de l'attribut de manière
systématique. Si la valeur à supprimer n'est pas présente le document ne sera
pas changé.
Comme pour ::replaceValue(), pour les attribut multiple, le test de
suppression se fait chacune des valeurs du multiple.
$ua = new \UpdateAttribute(); $ua->useCollection($dl); $ua->removeValue('tst_example','value to remove');
Lorsque l'attribut est dans un tableau, cela laissera un vide dans le tableau où la valeur se située.
17.17.3.4 addValue
La méthode ::addValue() ne fonctionne qu'avec les attributs "multiples". Elle
permet d'ajouter une nouvelle valeur à la liste des valeurs de l'attribut. Si
l'attribut est déclaré multiple alors seuls les documents n'ayant pas encore
cette valeur seront changés. Si c'est un attribut simple qui est dans un tableau
alors une nouvelle rangée sera ajoutée au tableau.
Si c'est un attribut multiple qui est dans un tableau alors la valeur sera ajoutée à tous les éléments du multiple.
$ua = new \UpdateAttribute(); $ua->useCollection($dl); $ua->addValue('tst_multiple','value to add');
17.17.4 Éxécution en tâche de fond
Comme ces tâches peuvent être longues, il est possible de les lancer en tâche de fond. Cela est fait en remplaçant l'appel des fonctions de modification par leur équivalent en tâche de fond.
::bgSetValue()::bgReplaceValue()::bgRemoveValue()::bgAddValue()
$ua = new \UpdateAttribute(); $ua->useCollection($dl); $fileStatus=$ua->bgAddValue('tst_multiple','value to add');
À la différence des fonctions lancées en synchrone, cette fonction retourne un chemin vers un fichier qui sera mis à jour au fur et à mesure de l'avancement par le processus lancé en tâche de fond. L'exploitation de ce fichier se fait via la classe UpdateAttributeStatus. Elle permet de contrôler l'avancement de la tâche.
$sua= new UpdateAttributeStatus($statusFile); while (! $sua->isFinished()) { print_r($sua->getLastMessage()); sleep(1); } if ($err=$sua->getError()) { print "Process failed : ".$err; } else { $status=$sua->getResults(); $changed=$unChanged=0; foreach ($status as $initid=>$aStatus) { if ($aStatus->changed) $changed++; else $unChanged++; } printf("%d document changed, %d document unchanged\n", $changed,$unChanged); }
La méthode ::getLastMessage() retourne un objet UpdateAttributeStatusLine
avec les informations suivantes :
-
date: date d'exécution (format ISO 8601) -
processCode: nom de la méthode utilisée -
message: message d'information
Extrait du fichier de status :
2012-06-28T16:16:30 setValue BEGIN 2012-06-28T16:16:30 setValue traitement [219656,220655,220656,220657,220658,220659,220660,220661,220662,220663,220664,22066 5,220666,220667,220668,220669,220670,22067 1,220672,220673,220674,220675,220676,220677,220678,220679,220680,220681] 2012-06-28T16:16:30 executeRevision traitement des révisions pour 28 documents 2012-06-28T16:16:32 executeRevision 10/28 révisions effectuées 2012-06-28T16:16:34 executeRevision 20/28 révisions effectuées 2012-06-28T16:16:35 executeRevision 28/28 révisions effectuées 2012-06-28T16:16:35 executeRevision traitement des révisions effectué 2012-06-28T16:16:35 executeSetValue traitement d'affectation de valeur pour 28 documents 2012-06-28T16:16:35 executeSetValue argument tst_redactor=>1181 2012-06-28T16:16:35 executeSetValue 28 documents mis à jour 2012-06-28T16:16:35 executeProfiling 10/28 mise à jour de profils effectués 2012-06-28T16:16:36 executeProfiling 20/28 mise à jour de profils effectués 2012-06-28T16:16:36 executeProfiling 28/28 mise à jour de profils effectués ... 2012-06-28T16:16:36 setValue END
Liste des illustrations
- 1. Schéma théorique de famille
- 2. Exemple de schéma de cycle de vie
- 3. Déroulement d'une transition
- 4. Sécurité : résumé
- 5. Sécurité : profil
- 6. account simple - consultation html
- 7. account simple - Modification html
- 8. account simple - consultation odt
- 9. array - consultation html
- 10. array - Modification html
- 11. array - consultation odt
- 12. color - consultation html
- 13. color - Modification html
- 14. date - consultation html
- 15. date - Modification html
- 16. date - consultation odt
- 17. docid simple - consultation html
- 18. docid simple - Modification html
- 19. docid simple - consultation odt
- 20. double - consultation html
- 21. double - Modification html
- 22. double - consultation odt
- 23. enum - consultation html
- 24. enum - Modification html
- 25. enum - consultation odt
- 26. file - consultation html
- 27. file - Modification html
- 28. file - FDL_OLDFILEINPUTCOMPAT Modification html
- 29. file - consultation odt
- 30. frame - consultation html
- 31. frame - Modification html
- 32. htmltext - consultation html
- 33. htmltext - Modification html
- 34. toolbar Simple
- 35. toolbar Basic
- 36. toolbar Default
- 37. toolbar Full
- 38. image - consultation html
- 39. image - Modification html
- 40. image - Modification html
- 41. image - consultation odt
- 42. integer - consultation html
- 43. integer - Modification html
- 44. integer - consultation odt
- 45. longtext - consultation html
- 46. longtext - Modification html
- 47. longtext - consultation odt
- 48. menu - consultation html
- 49. money - consultation html
- 50. money - Modification html
- 51. money - consultation odt
- 52. password - consultation html
- 53. password - Modification html
- 54. tab - consultation html
- 55. tab - Modification html
- 56. text - consultation html
- 57. text - Modification html
- 58. text - consultation odt
- 59. time - consultation html
- 60. time - modification time
- 61. time - consultation odt
- 62. timestamp - consultation html
- 63. timestamp - Modification html
- 64. timestamp - consultation odt
- 65. Export CSV
- 66. champ utilisateur
- 67. nom de l'image
- 68. template
- 69. résultat
- 70. template
- 71. résultat
- 72. Erreur de structure
- 73. Exportation de documents
- 74. Options d'importation de comptes
- 75. Options d'exportation de comptes
- 76. Sécurité : Exemple de hiérarchie
- 77. Graphe du cycle à 3 états
- 78. Processus d'affichage du menu des transitions
- 79. Processus de demande des paramètres
- 80. Processus de transition
- 81. image non trouvée
- 82. Usage de Doc::editAttr()
- 83. Affichage dans un tableau avec Doc::editAttr()
- 84. Variante d'affichage dans un tableau avec Doc::editAttr()
- 85. Usage de Doc::viewAttr()
- 86. Zone de type texte
- 87. Zone de type date
- 88. Frame d'un document du zoo
- 89. Frame d'un document du zoo
- 90. Frame d'un document du zoo
- 91. Array d'un document du zoo
- 92. Modification de paramètre de famille
- 93. Modification de paramètre de famille
- 94. Accès par index.php
- 95. Accès par guest.php
- 96. Exécution de la requête
- 97. Exécution de l'action de la requête
- 98. Consultation d'un document
- 99. Édition d'un document
- 100. Édition d'un document
- 101. Passage d'une transition d'un document
- 102. Exécution CLI wsh
- 103. Héritage des tables de documents
- 104. Relation d'héritage entre docfam et doc
- 105. Relation entre docattr et docfam
- 106. Lien entre les tables users et doc
- 107. Relations entre les tables mises en œuvre pour la vérification des droits d'accès
- 108. Relation entre dochisto et doc
- 109. Relation entre doclog et doc
- 110. Relations entre les tables des coffres de fichiers
- 111. Relations entre les tables définissant les applications
- 112. Relations entre les tables définissant les paramètres
- 113. Workflow d'authentification
- 114. Contrôle de l'exécution d'une action
- 115. Contrôle de l'affichage d'un document
- 116. Contrôle du téléchargement d'un fichier
- 117. Html mal encodé
- 118. Html bien encodé
- 119. template
- 120. résultat
- 121. template
- 122. résultat
- 123. template
- 124. résultat
- 125. Formulaire de création de processus
- Figure 126.
Licence

Ce document est publié sous licence CC http://creativecommons.org/licenses/by-nc-sa/2.0/fr/
Vous êtes libres :
- de reproduire, distribuer et communiquer cette création au public
- de modifier cette création
Selon les conditions suivantes :
- Paternité — Vous devez citer le nom de l'auteur original de la manière indiquée par l'auteur de l'œuvre ou le titulaire des droits qui vous confère cette autorisation (mais pas d'une manière qui suggérerait qu'ils vous soutiennent ou approuvent votre utilisation de l'œuvre).
- Pas d'Utilisation Commerciale — Vous n'avez pas le droit d'utiliser cette création à des fins commerciales.
- Partage des Conditions Initiales à l'Identique — Si vous modifiez, transformez ou adaptez cette création, vous n'avez le droit de distribuer la création qui en résulte que sous un contrat identique à celui-ci.
Édition
Manuel de référence
© Anakeen, Anakeen Labs <labs@anakeen.com>
Module Core, version 3.2
Édition 13
Publié le 21/02/2019
Ce livre a été produit avec easybook 4.8, logiciel libre et open source développé par Javier Eguiluz à l'aide de différents composants Symfony.